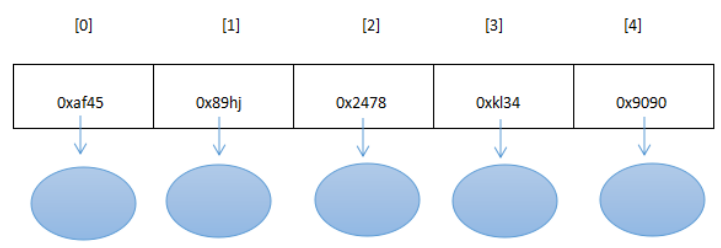
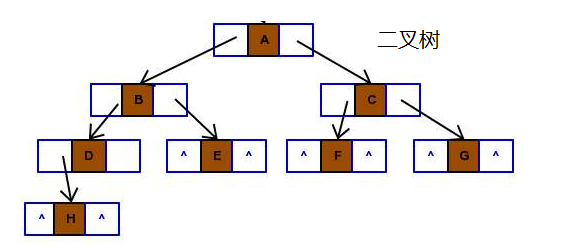
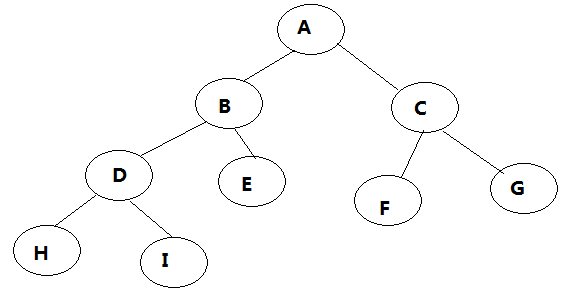
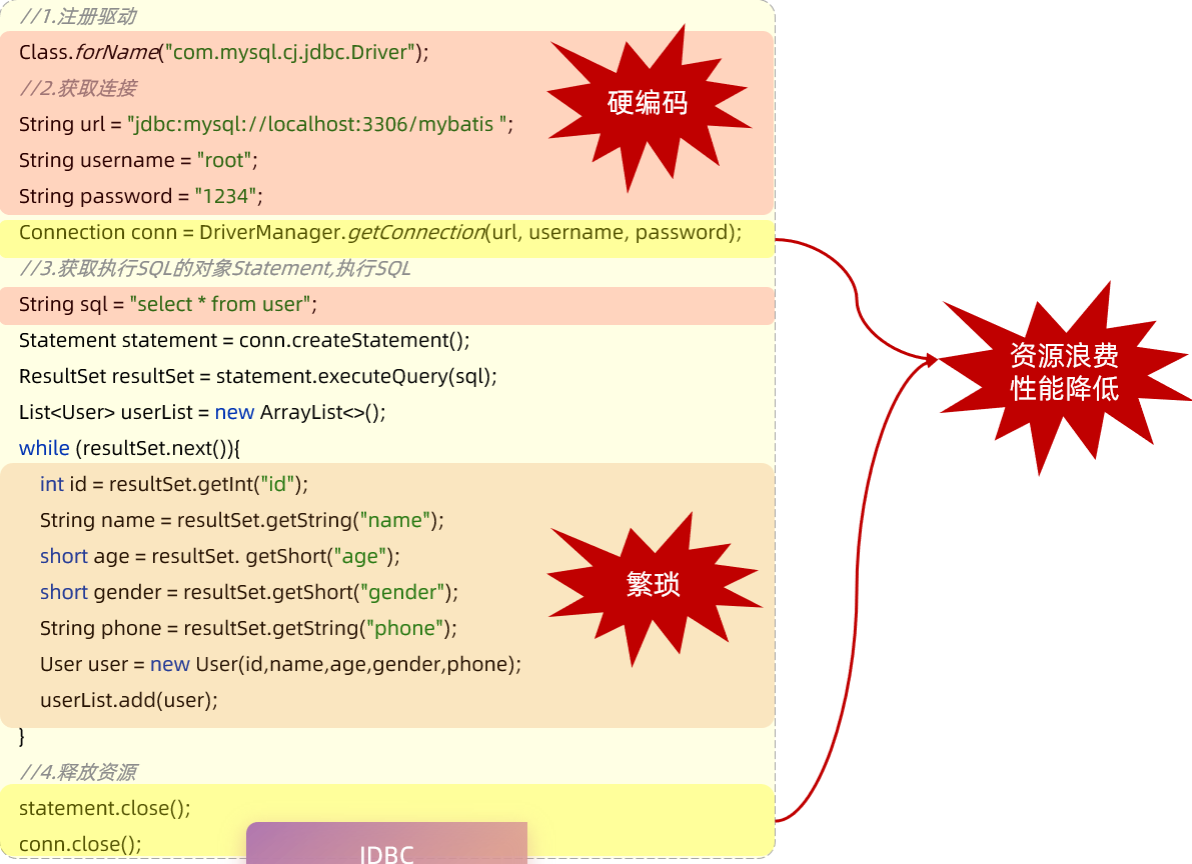
List<User> userList = new ArrayList<>();//集合对象(用于存储User对象) //4. 处理SQL执行结果 while (rs.next()){ //取出一行记录中id、name、age、gender、phone下的数据 int id = rs.getInt("id"); String name = rs.getString("name"); short age = rs.getShort("age"); short gender = rs.getShort("gender"); String phone = rs.getString("phone"); //把一行记录中的数据,封装到User对象中 User user = new User(id,name,age,gender,phone); userList.add(user);//User对象添加到集合 } //5. 释放资源 statement.close(); connection.close(); rs.close();
//遍历集合 for (User user : userList) { System.out.println(user); } } }
@Data //getter方法、setter方法、toString方法、hashCode方法、equals方法 @NoArgsConstructor //无参构造 @AllArgsConstructor//全参构造 public class User { private Integer id; private String name; private Short age; private Short gender; private String phone; }
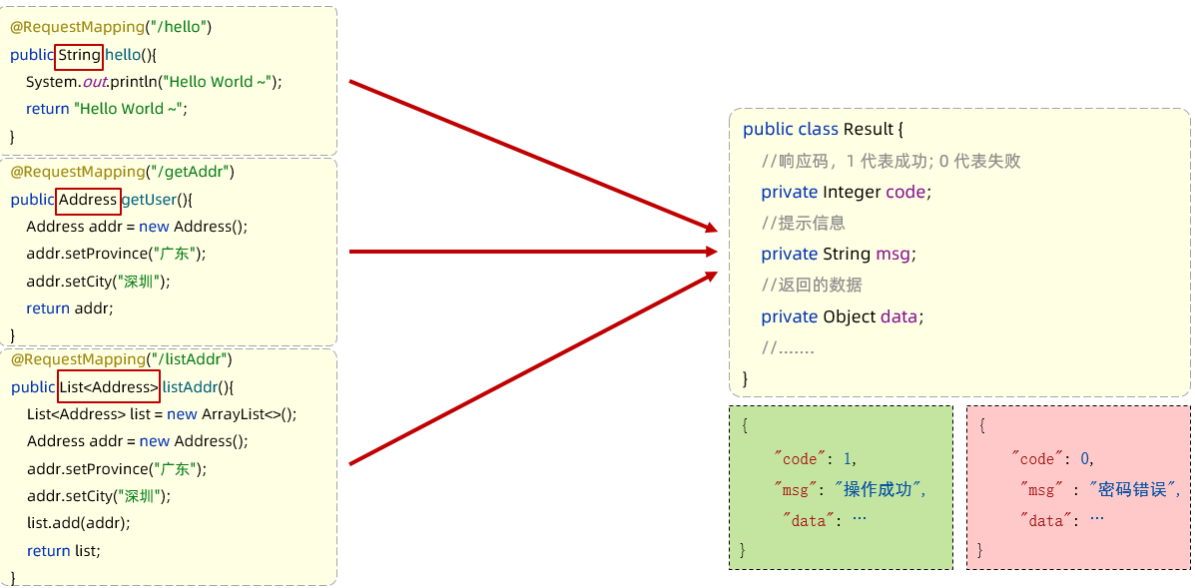
@RestController publicclassHelloController{ @RequestMapping("/hello") public String hello(){ System.out.println("Hello World ~"); return"Hello World ~"; } }
@RestController publicclassResponseController{ //响应统一格式的结果 @RequestMapping("/hello") public Result hello(){ System.out.println("Hello World ~"); //return new Result(1,"success","Hello World ~"); return Result.success("Hello World ~"); }
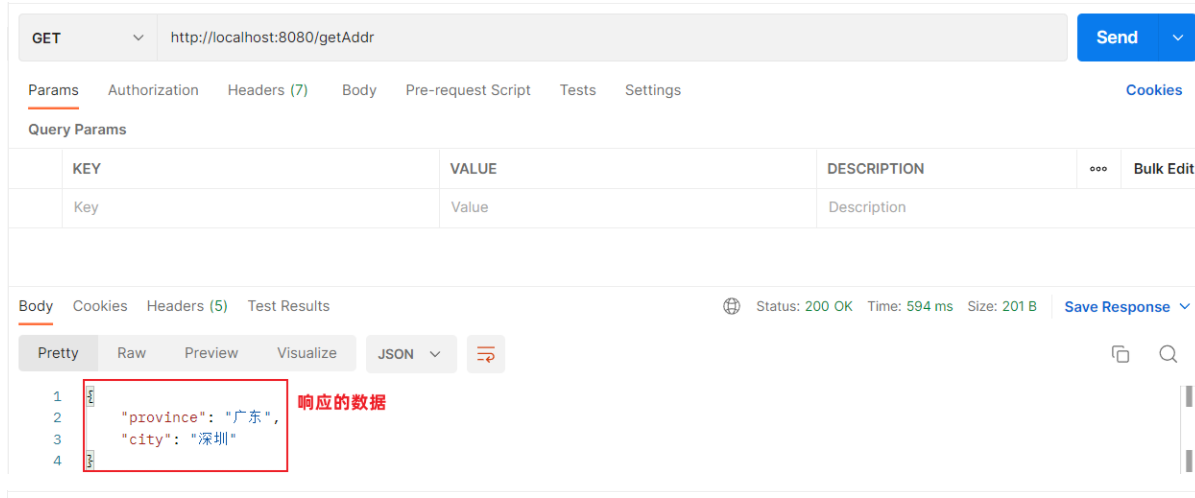
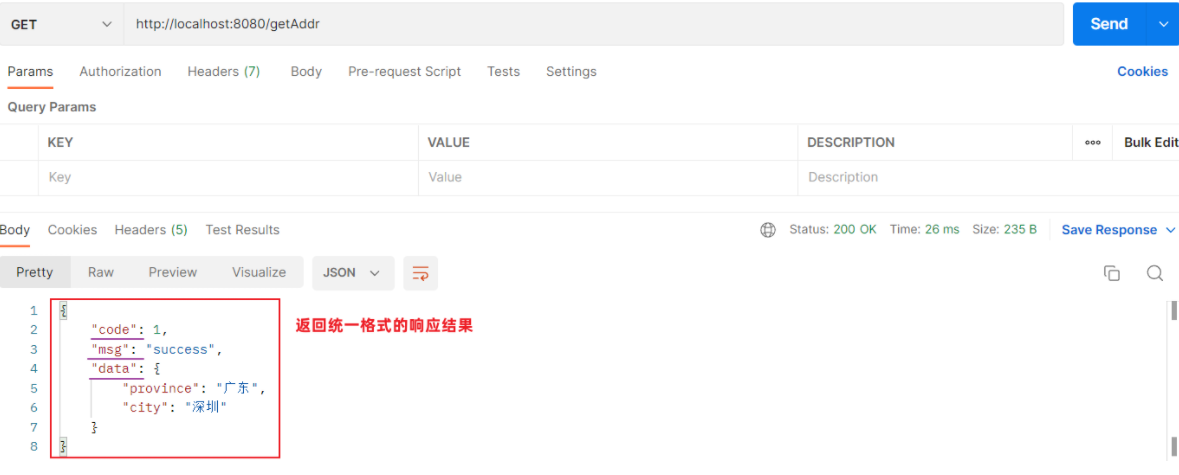
//响应统一格式的结果 @RequestMapping("/getAddr") public Result getAddr(){ Address addr = new Address(); addr.setProvince("广东"); addr.setCity("深圳"); return Result.success(addr); }
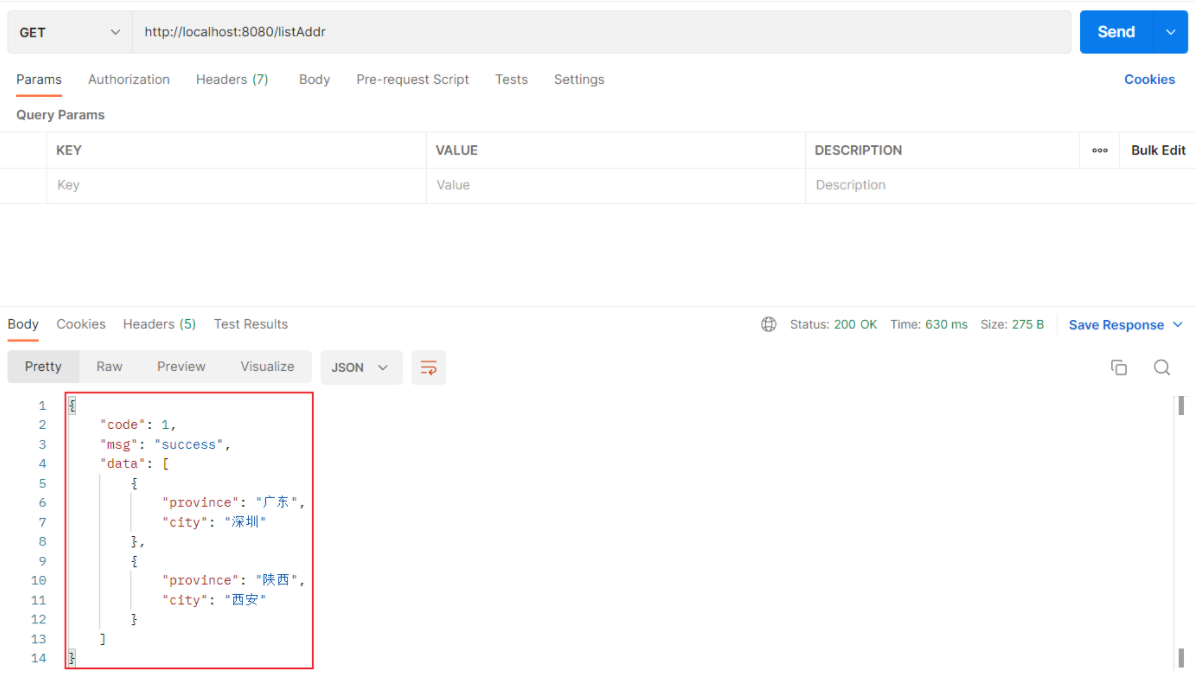
//响应统一格式的结果 @RequestMapping("/listAddr") public Result listAddr(){ List<Address> list = new ArrayList<>();
Address addr = new Address(); addr.setProvince("广东"); addr.setCity("深圳");
Address addr2 = new Address(); addr2.setProvince("陕西"); addr2.setCity("西安");
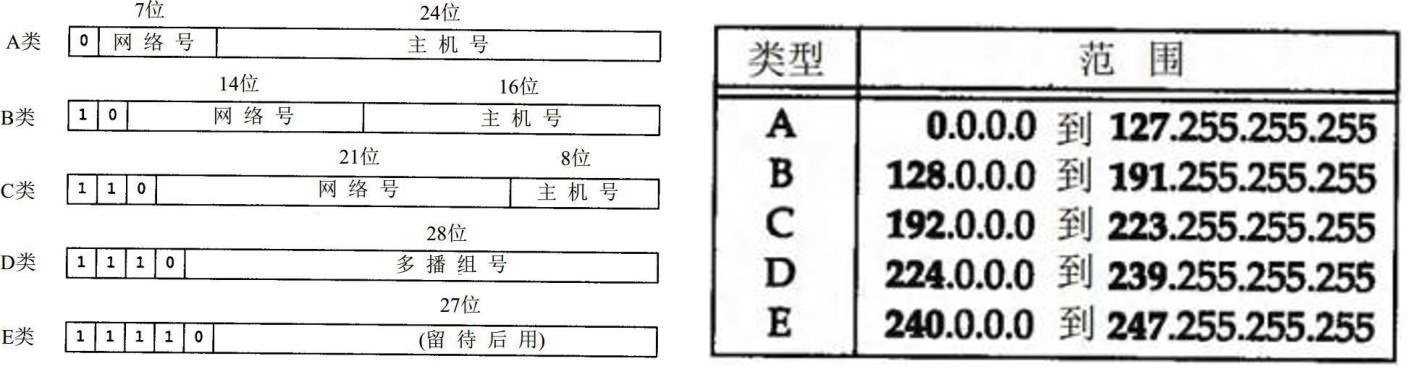
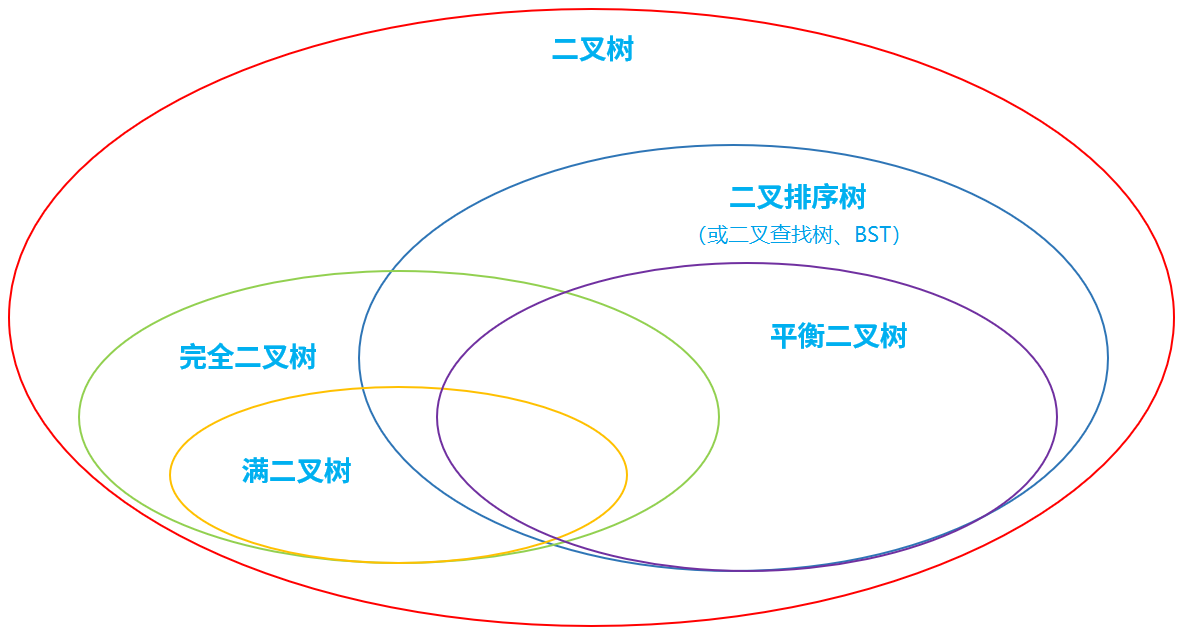
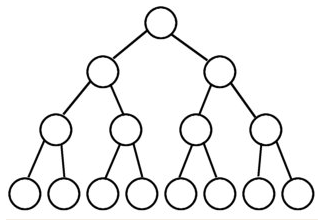
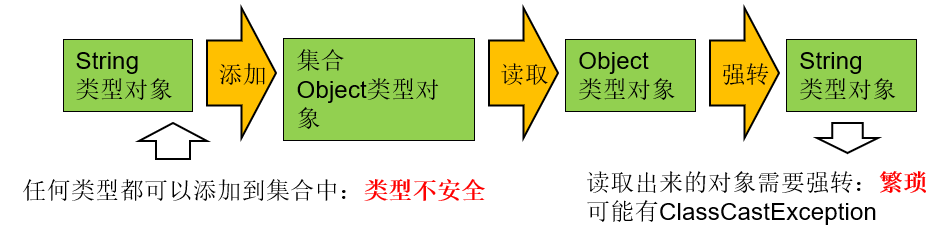
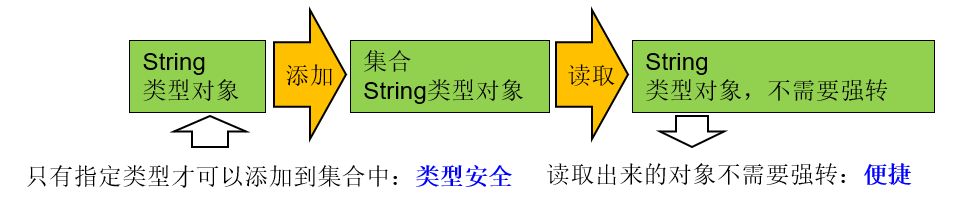
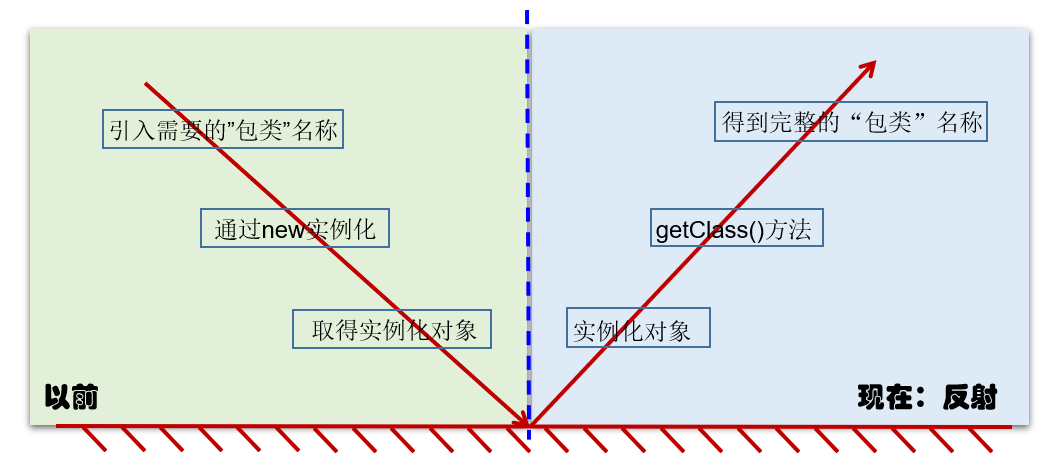
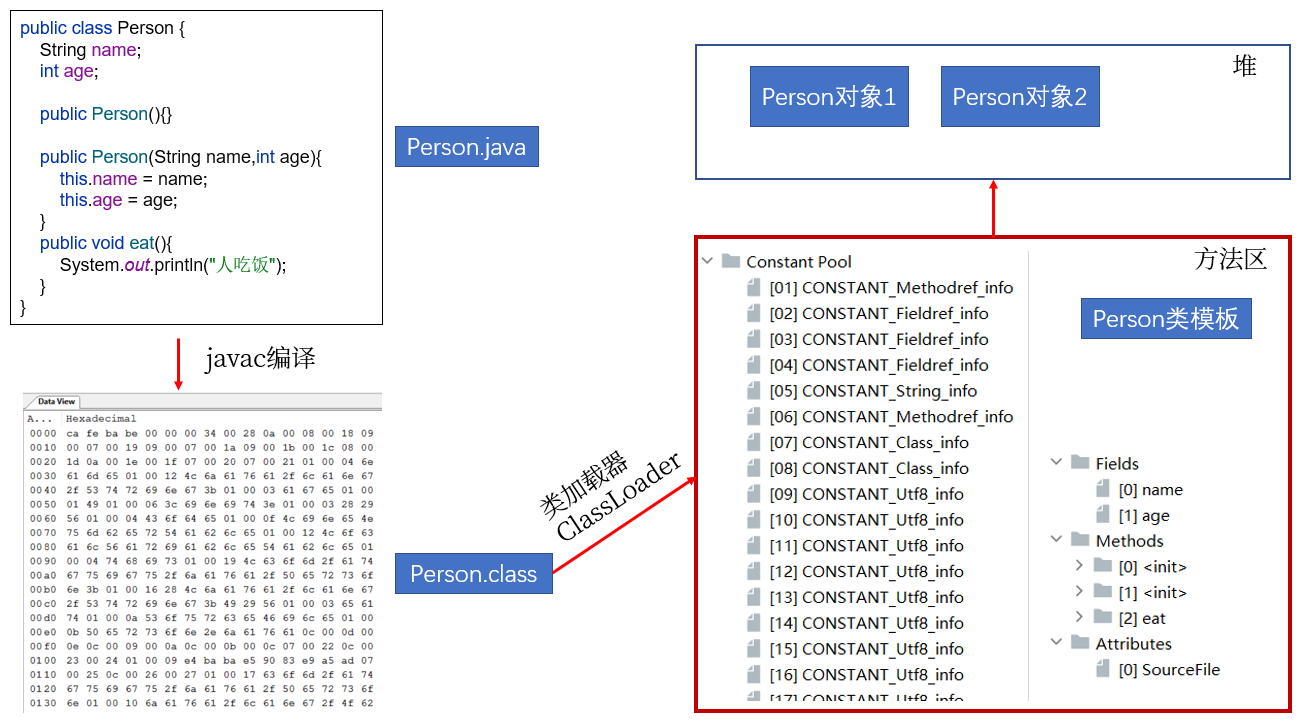
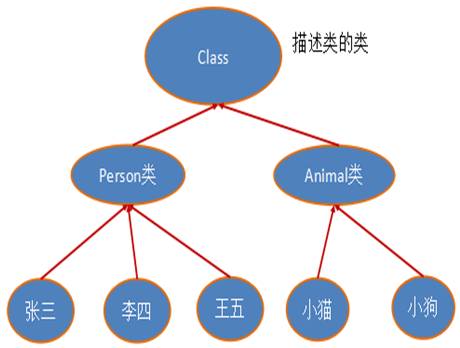
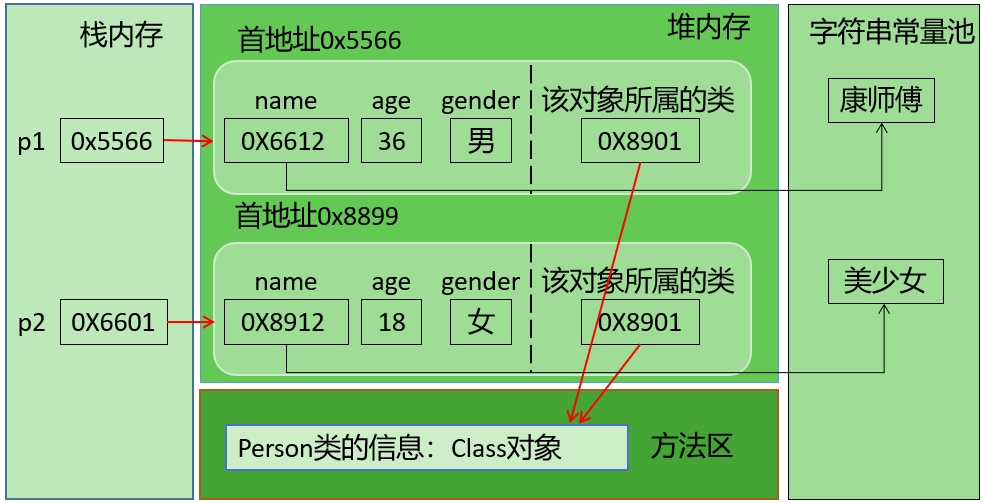
对象照镜子后可以得到的信息:某个类的属性、方法和构造器、某个类到底实现了哪些接口。 对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个 Class 对象包含了特定某个结构(class/interface/enum/annotation/primitive type/void/[])的有关信息。
Class c1 = Object.class; Class c2 = Comparable.class; Class c3 = String[].class; Class c4 = int[][].class; Class c5 = ElementType.class; Class c6 = Override.class; Class c7 = int.class; Class c8 = void.class; Class c9 = Class.class; //测试是否是一个Class int[] a = newint[10]; int[] b = newint[100]; Class c10 = a.getClass(); Class c11 = b.getClass(); // 只要元素类型与维度一样,就是同一个Class System.out.println(c10 == c11);
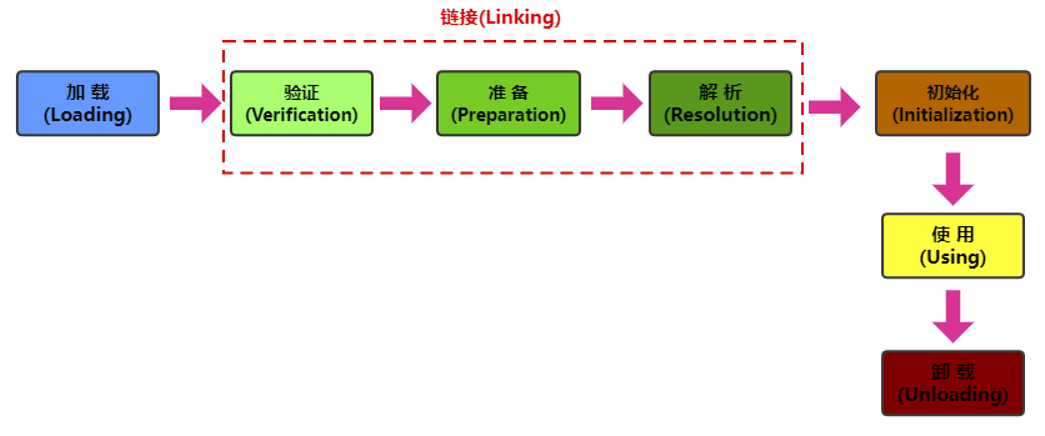
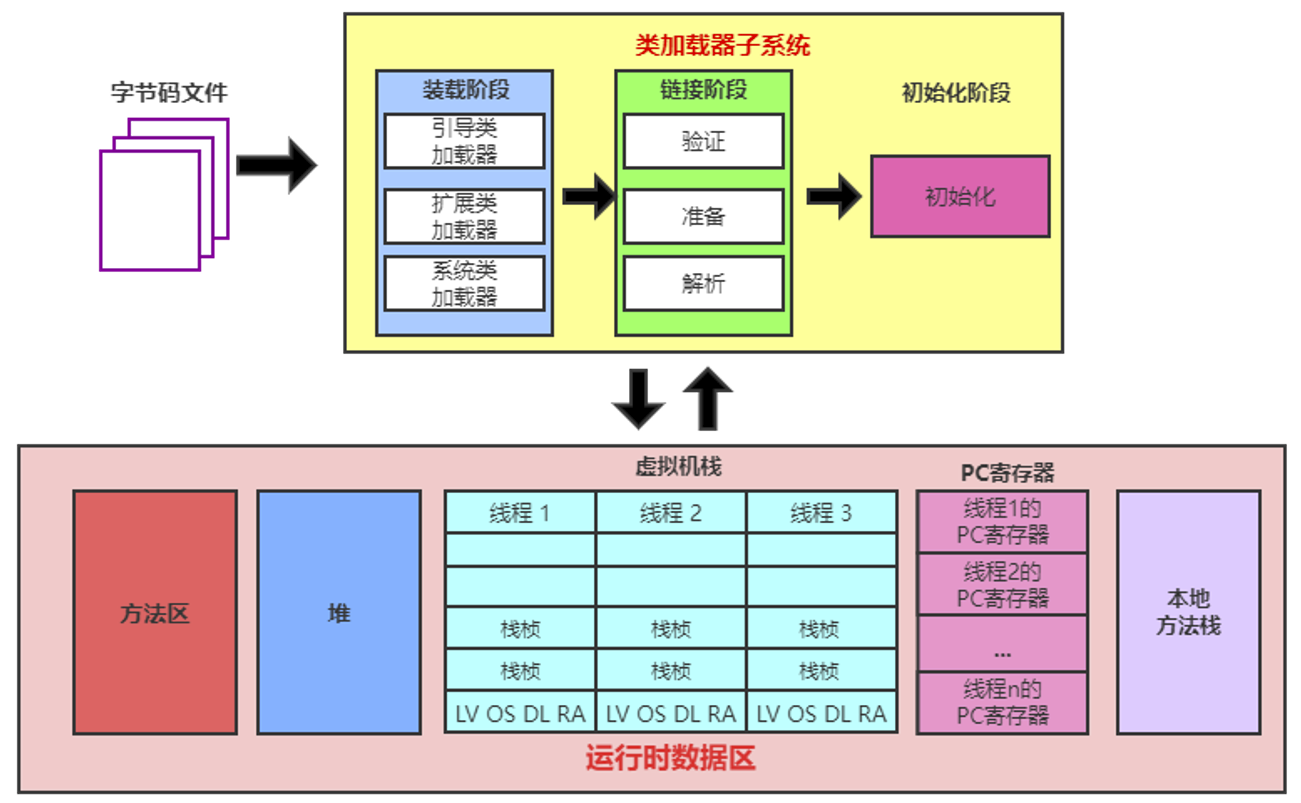
2.4 Class类的常用方法
方法名
功能说明
static Class forName(String name)
返回指定类名name的Class 对象
Object newInstance()
调用缺省构造函数,返回该Class对象的一个实例
getName()
返回此Class对象表示的实体(类/接口/数组类/基本类型/void)名称
Class getSuperClass()
返回当前Class对象的父类的Class对象
Class [] getInterfaces()
获取当前Class对象的接口
ClassLoader getClassLoader()
返回该类的类加载器
Class getSuperclass()
返回表示此Class所表示的实体的超类的Class
Constructor[] getConstructors()
返回一个包含某些Constructor对象的数组
Field[] getDeclaredFields()
返回Field对象的一个数组
Method getMethod(String name,Class … paramTypes)
返回一个Method对象,此对象的形参类型为paramType
举例:
1 2 3 4 5 6 7 8 9 10 11
String str = "test4.Person"; Class clazz = Class.forName(str);
Object obj = clazz.newInstance();
Field field = clazz.getField("name"); field.set(obj, "Peter"); Object name = field.get(obj); System.out.println(name);
//需要掌握如下的代码 @Test publicvoidtest5()throws IOException { Properties pros = new Properties(); //方式1:此时默认的相对路径是当前的module // FileInputStream is = new FileInputStream("info.properties"); // FileInputStream is = new FileInputStream("src//info1.properties");
//方式2:使用类的加载器 //此时默认的相对路径是当前module的src目录 InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("info1.properties");
//1.实现的全部接口 public Class<?>[] getInterfaces() //确定此对象所表示的类或接口实现的接口。
//2.所继承的父类 public Class<? Super T> getSuperclass() //返回表示此 Class 所表示的实体(类、接口、基本类型)的父类的 Class。
//3.全部的构造器 public Constructor<T>[] getConstructors() //返回此 Class 对象所表示的类的所有public构造方法。 public Constructor<T>[] getDeclaredConstructors() //返回此 Class 对象表示的类声明的所有构造方法。
//Constructor类中: //取得修饰符: publicintgetModifiers(); //取得方法名称: public String getName(); //取得参数的类型: public Class<?>[] getParameterTypes();
//4.全部的方法 public Method[] getDeclaredMethods() //返回此Class对象所表示的类或接口的全部方法 public Method[] getMethods() //返回此Class对象所表示的类或接口的public的方法
//Method类中: public Class<?> getReturnType() //取得全部的返回值 public Class<?>[] getParameterTypes() //取得全部的参数 publicintgetModifiers() //取得修饰符 public Class<?>[] getExceptionTypes() //取得异常信息 //5.全部的Field public Field[] getFields() //返回此Class对象所表示的类或接口的public的Field。 public Field[] getDeclaredFields() //返回此Class对象所表示的类或接口的全部Field。 //Field方法中: publicintgetModifiers() //以整数形式返回此Field的修饰符 public Class<?> getType() //得到Field的属性类型 public String getName() //返回Field的名称。 //6. Annotation相关 get Annotation(Class<T> annotationClass) getDeclaredAnnotations() //7.泛型相关 //获取父类泛型类型: Type getGenericSuperclass() //泛型类型:ParameterizedType //获取实际的泛型类型参数数组: getActualTypeArguments() //8.类所在的包 Package getPackage()
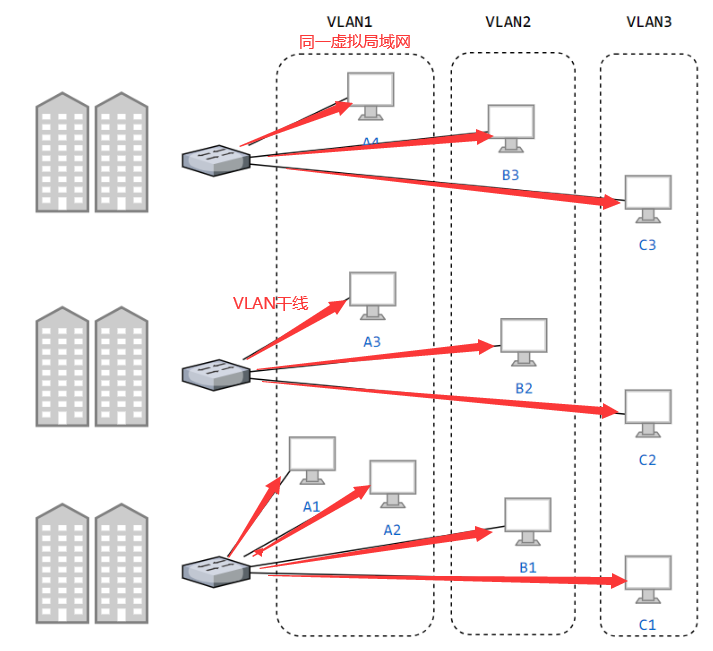
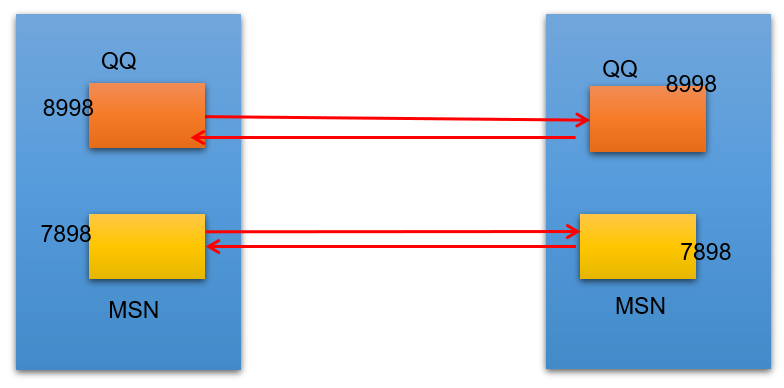
目前,使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
以太网帧格式:
类型 :标记上层使用的协议;
数据 :长度在 46-1500 之间,如果太小则需要填充;
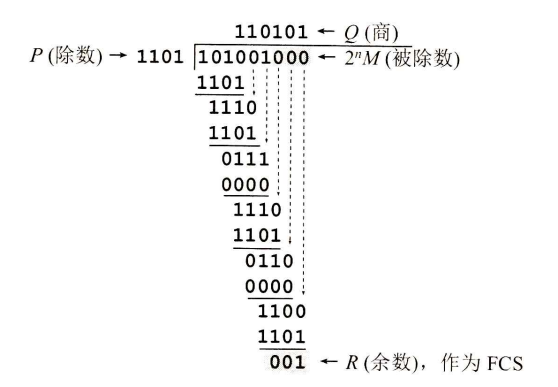
FCS :帧检验序列,使用的是 CRC 检验方法;
3.7 交换机
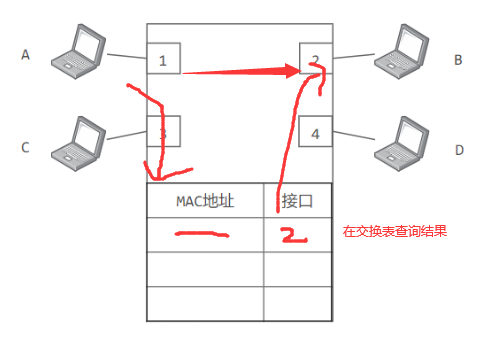
交换机学习交换表内容(存储MAC地址到接口的映射)
由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射
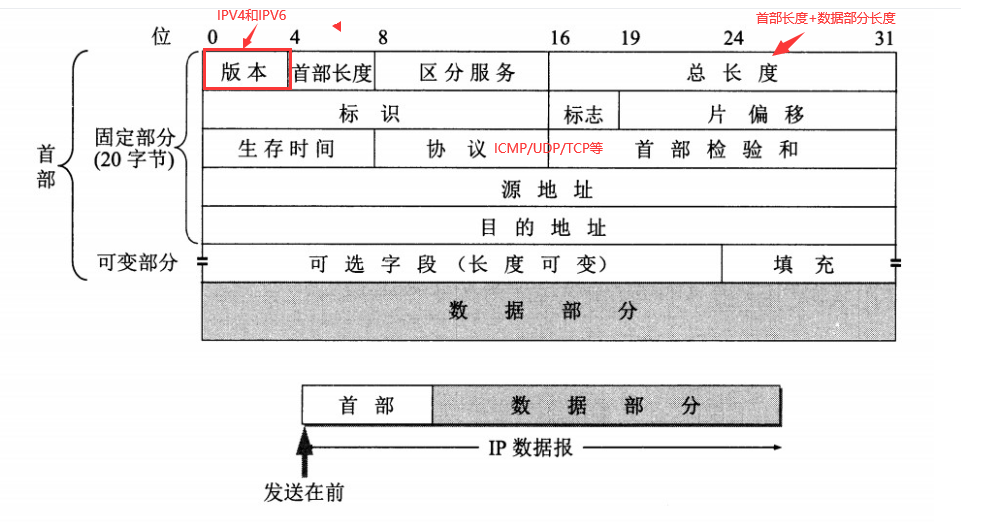
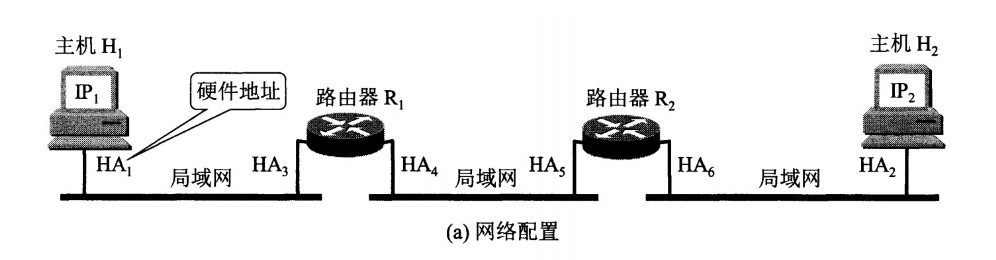
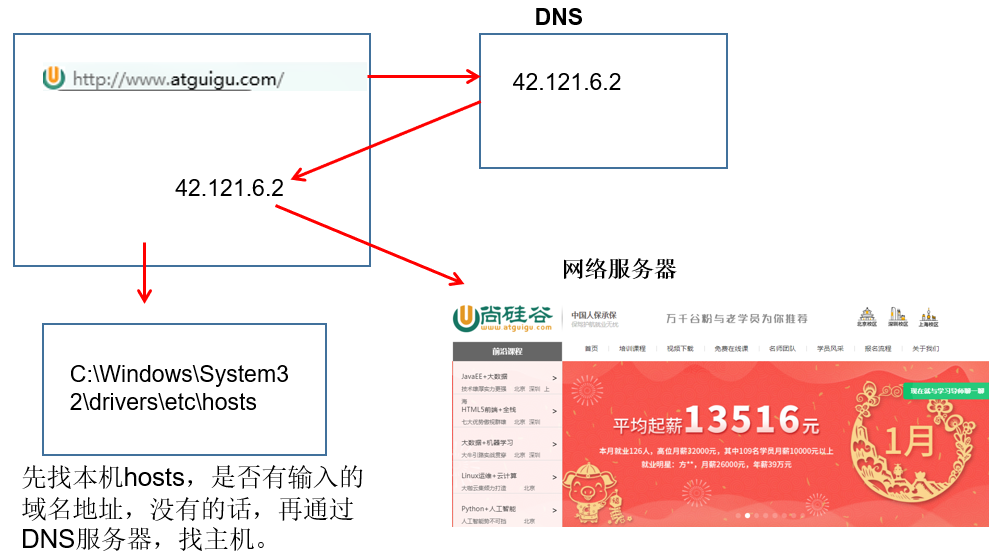
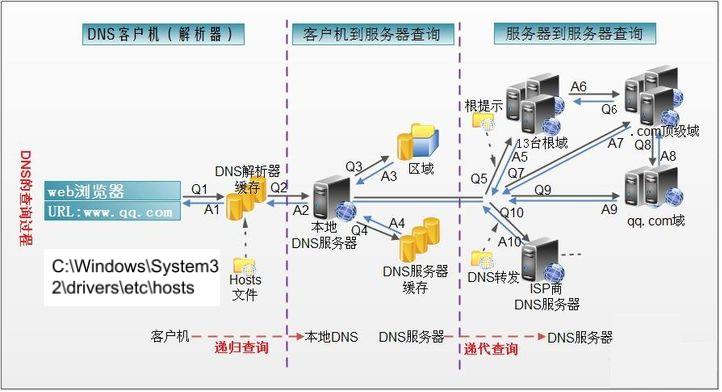
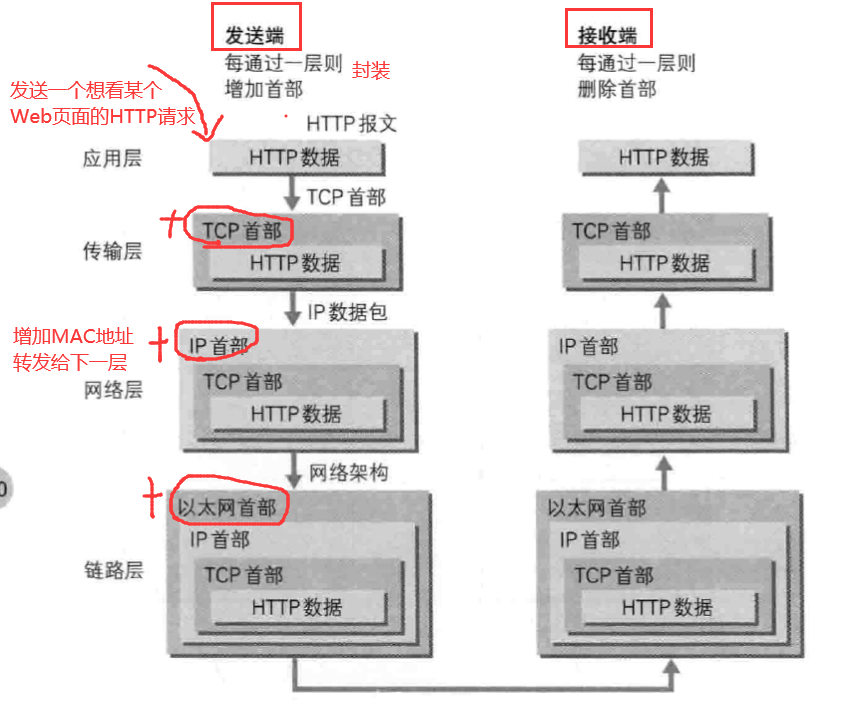
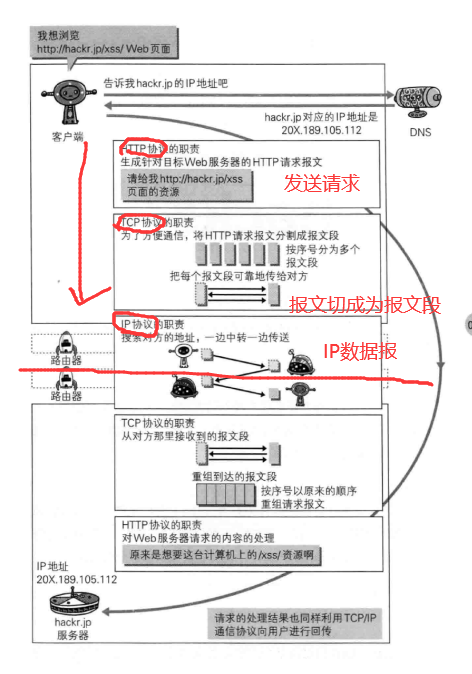
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
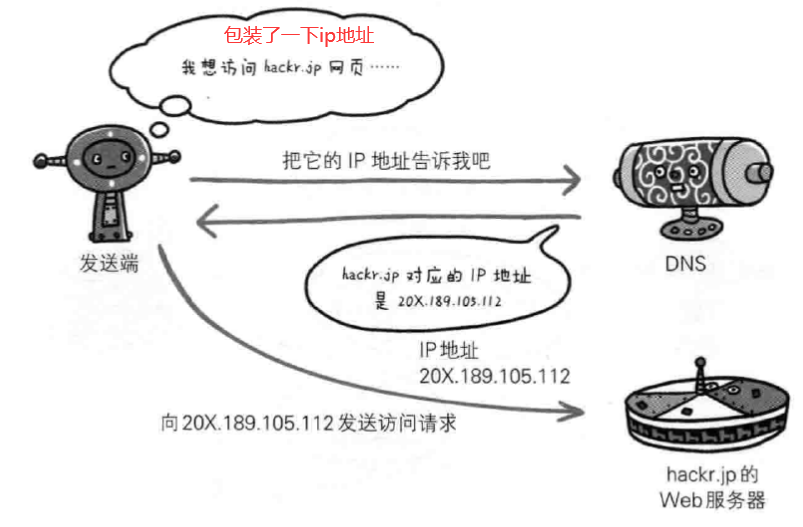
ARP 实现: IP 地址 –> MAC 地址
每个主机都有一个 ARP 高速缓存(局域网上的各主机和路由器的 IP 地址到 MAC 地址)映射表。
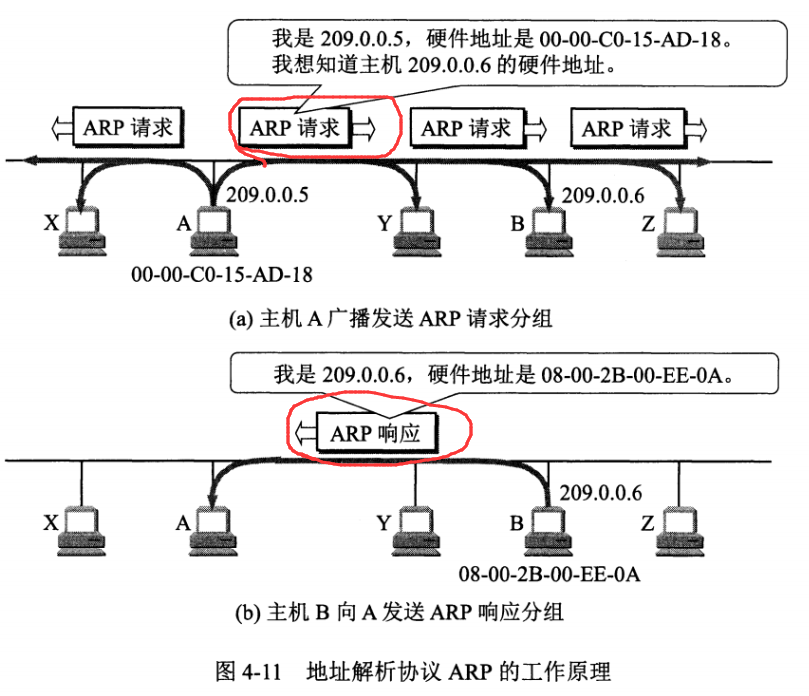
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
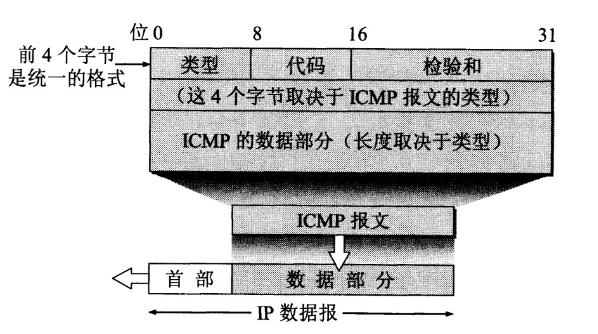
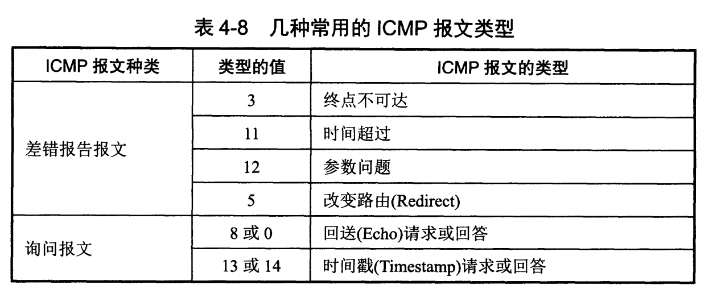
4.3 ICMP 网际控制报文协议
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会 ICMP封装在 IP 数据报中,但是不属于高层协议
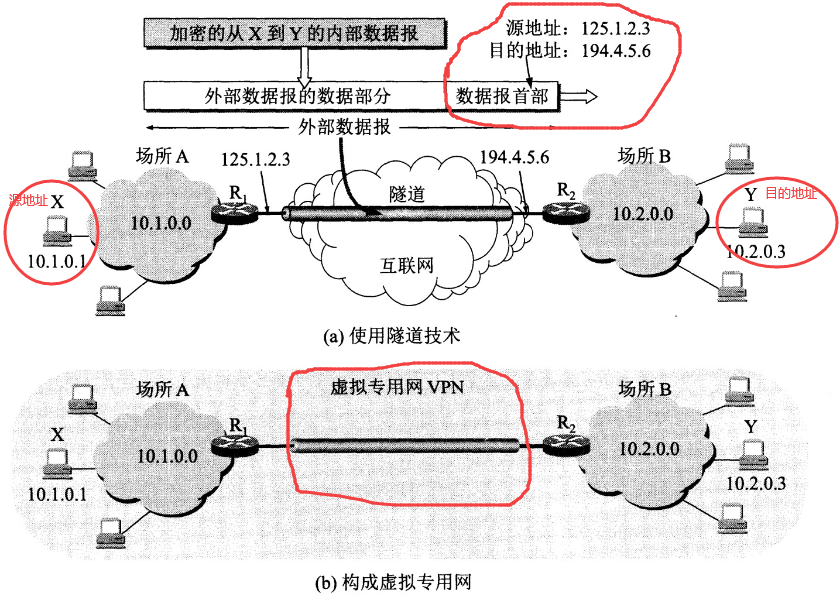
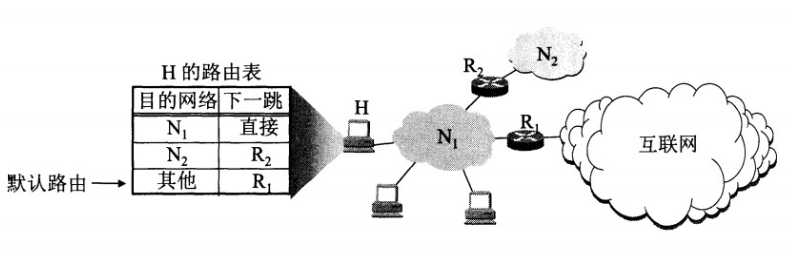
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP –> 全球 IP。
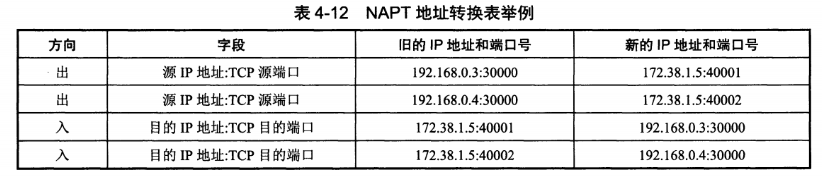
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT
4.6 路由器
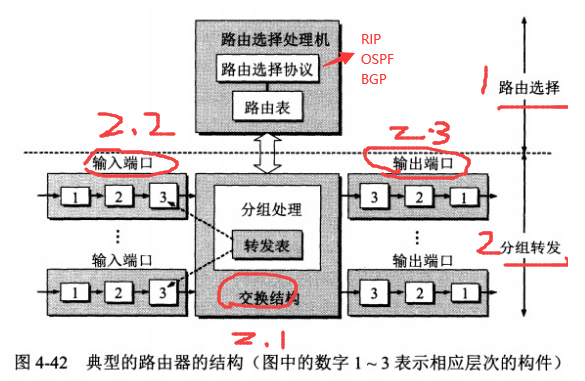
4.6.1 路由器的结构
功能划分
组成
路由选择
内部网关协议 RIP 内部网关协议 OSPF 外部网关协议 BGP
分组转发
交换结构 一组输入端口 一组输出端口
4.6.2 路由选择-三大协议
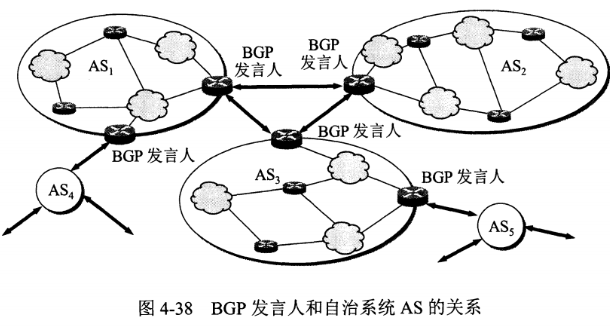
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
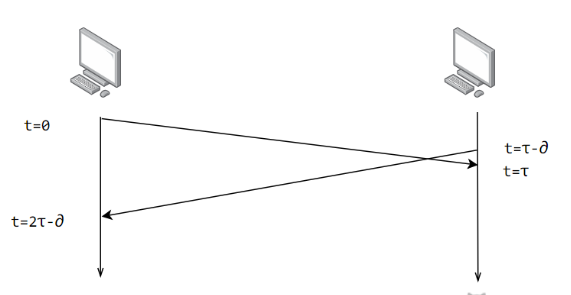
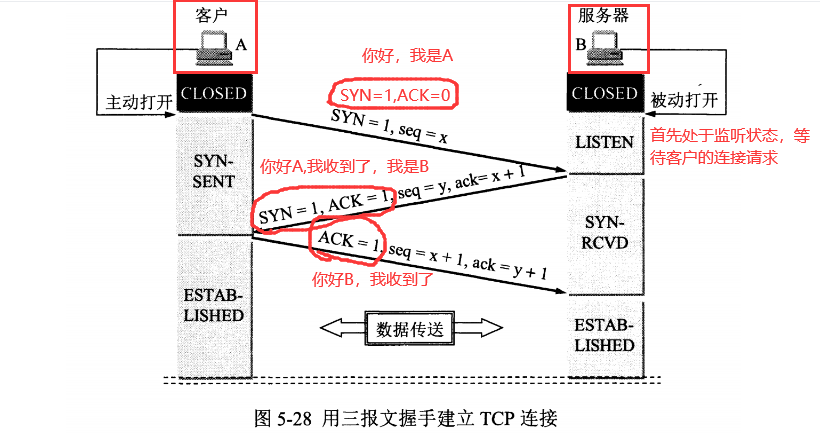
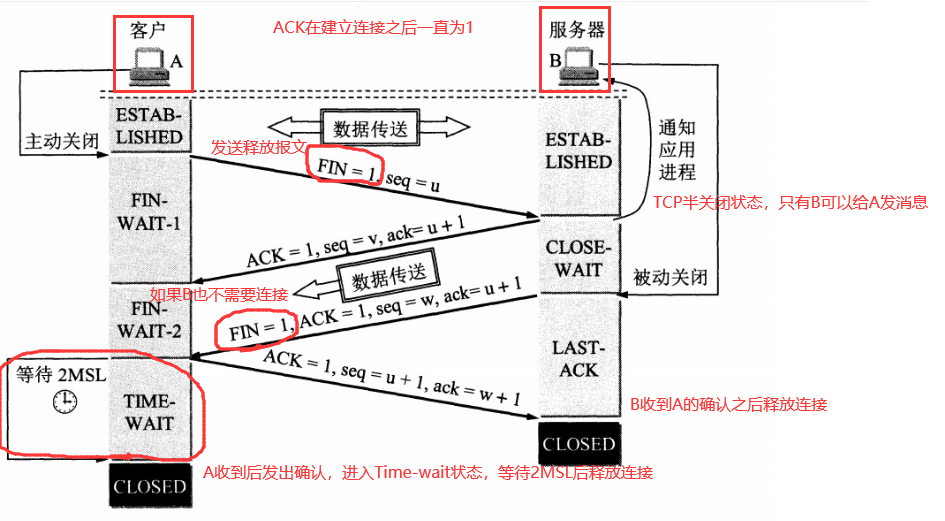
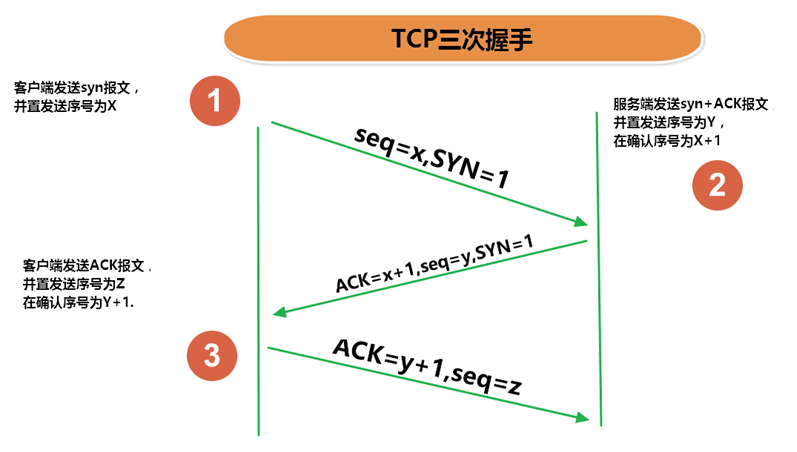
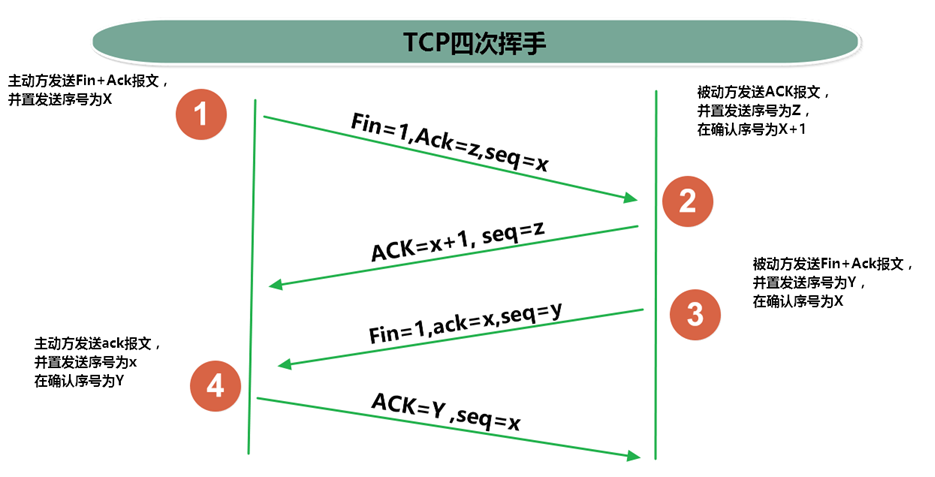
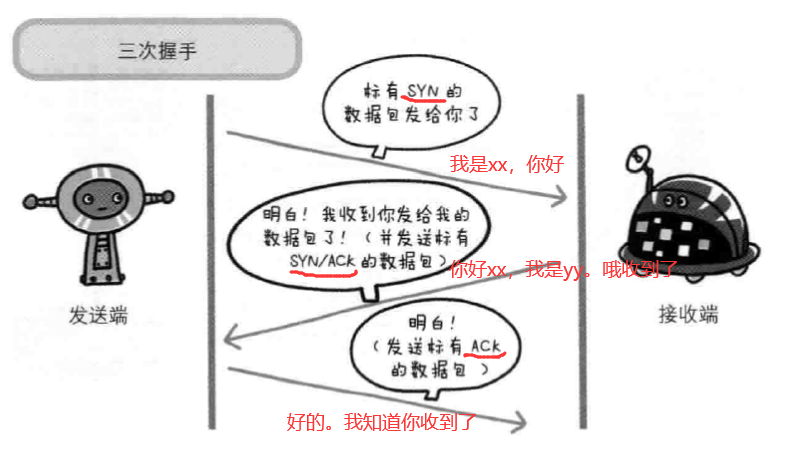
假设 A 为客户端,B 为服务器端 1.首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。 2.第一次握手: A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。 3.第二次握手: B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。 4.第三次握手: A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。 5.最终结果: B 收到 A 的确认后,连接建立。
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。 A 发送连接释放报文,FIN=1。 B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。 当 B 不再需要连接时,发送连接释放报文,FIN=1。 A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。 B 收到 A 的确认后释放连接。
第四次挥手是因为客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态(这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文)
其中TIME_WAIT状态:
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
确保A给B发送的最后一个确认报文B收到了。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
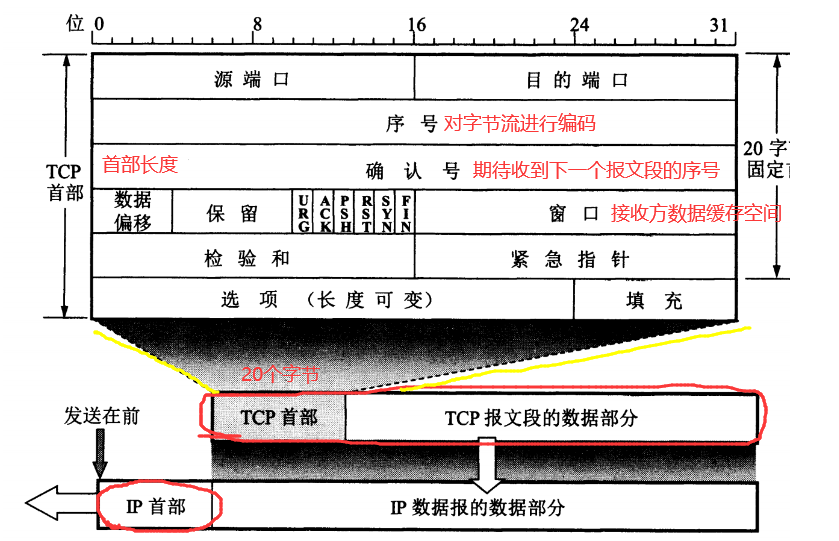
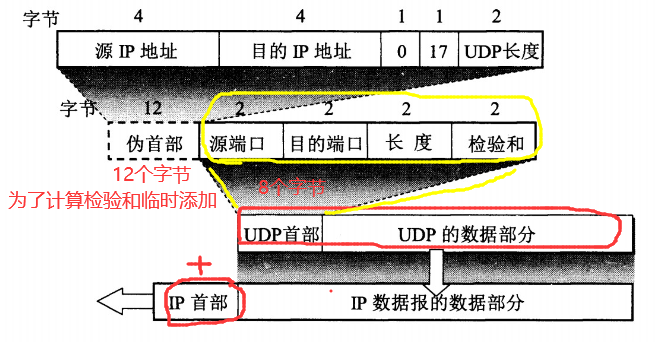
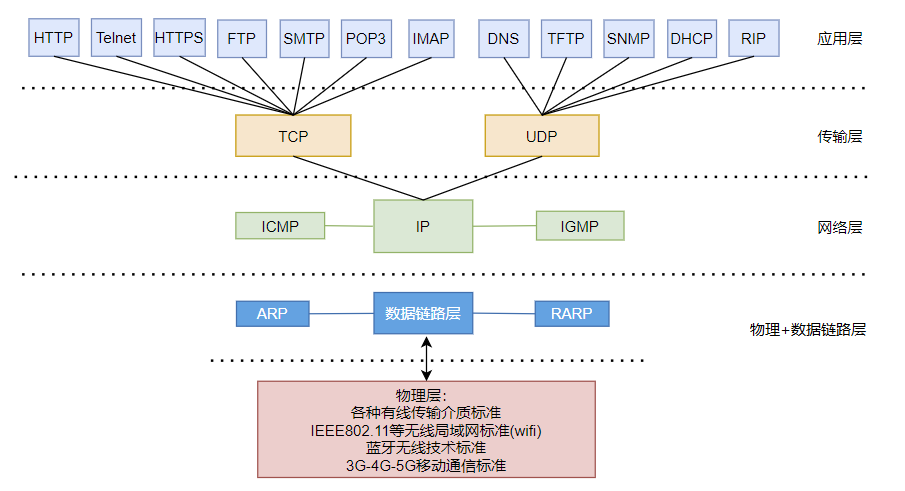
传输层:主要使网络程序进行通信,在进行网络通信时,可以采用TCP协议,也可以采用UDP协议。TCP(Transmission Control Protocol)协议,即传输控制协议,是一种面向连接的、可靠的、基于字节流的传输层通信协议。UDP(User Datagram Protocol,用户数据报协议):是一个无连接的传输层协议、提供面向事务的简单不可靠的信息传送服务。
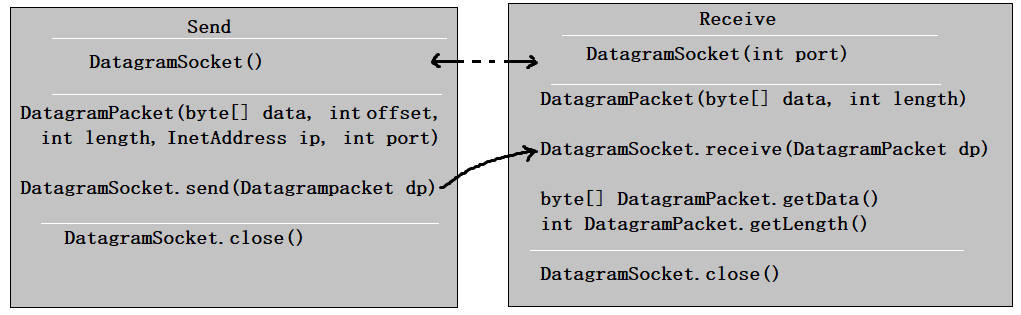
public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
public void close()关闭此数据报套接字。
public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时,DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
public InetAddress getLocalAddress()获取套接字绑定的本地地址。
public int getLocalPort()返回此套接字绑定的本地主机上的端口号。
public InetAddress getInetAddress()返回此套接字连接的地址。如果套接字未连接,则返回 null。
public int getPort()返回此套接字的端口。如果套接字未连接,则返回 -1。
3.3.4 DatagramPacket类
DatagramPacket类的常用方法:
public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。
public InetAddress getAddress()返回某台机器的 IP 地址,此数据报将要发往该机器或者是从该机器接收到的。
public int getPort()返回某台远程主机的端口号,此数据报将要发往该主机或者是从该主机接收到的。
public byte[] getData()返回数据缓冲区。接收到的或将要发送的数据从缓冲区中的偏移量 offset 处开始,持续 length 长度。
public int getLength()返回将要发送或接收到的数据的长度。
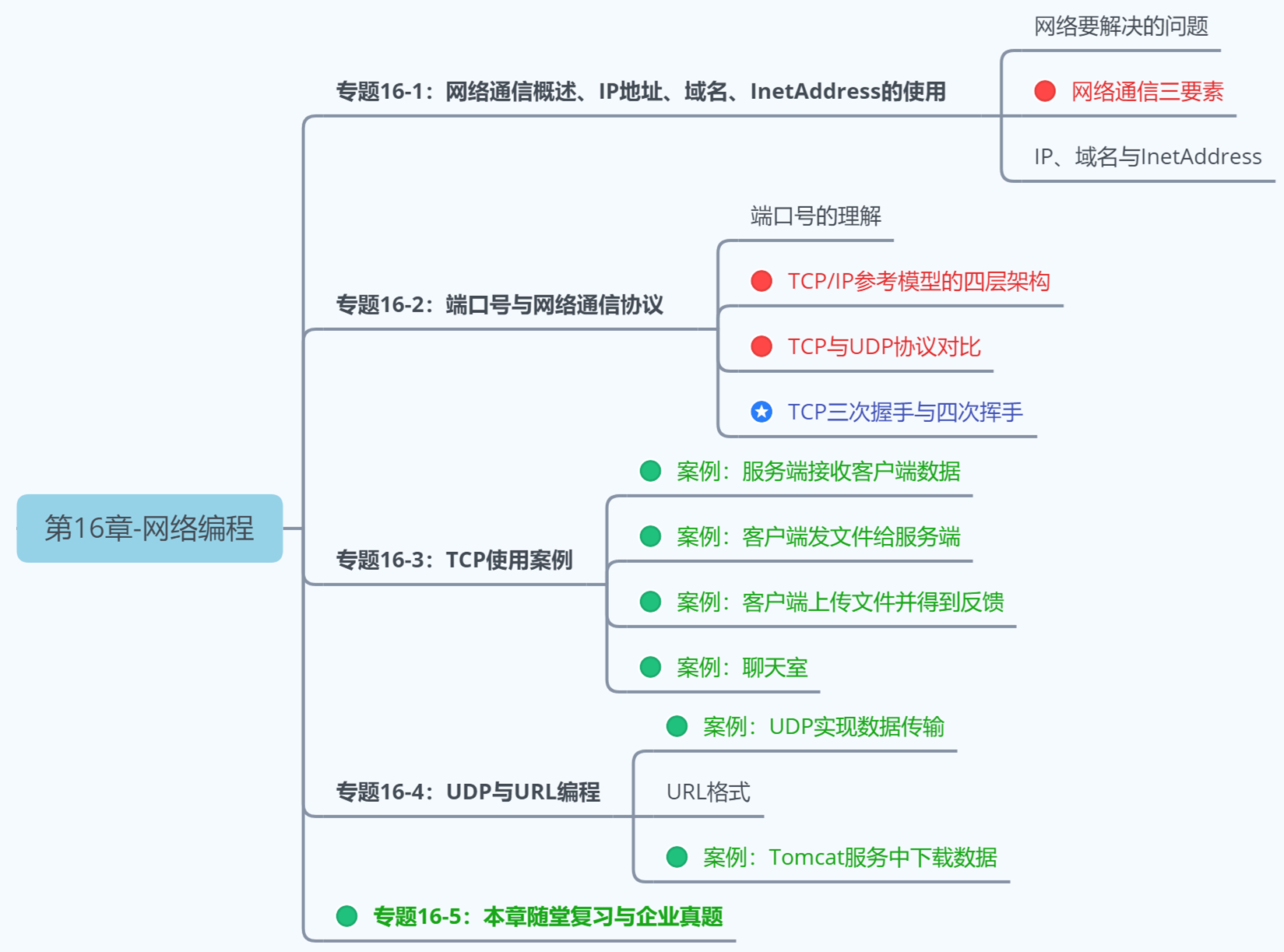
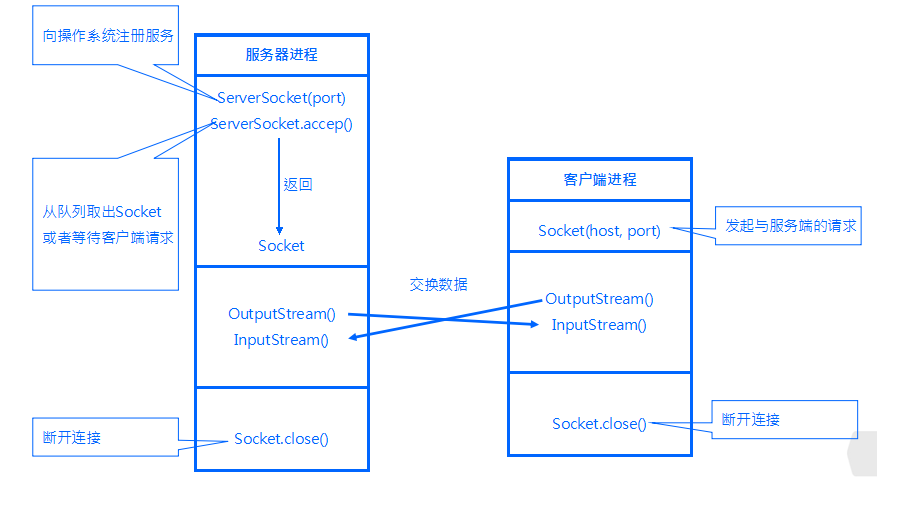
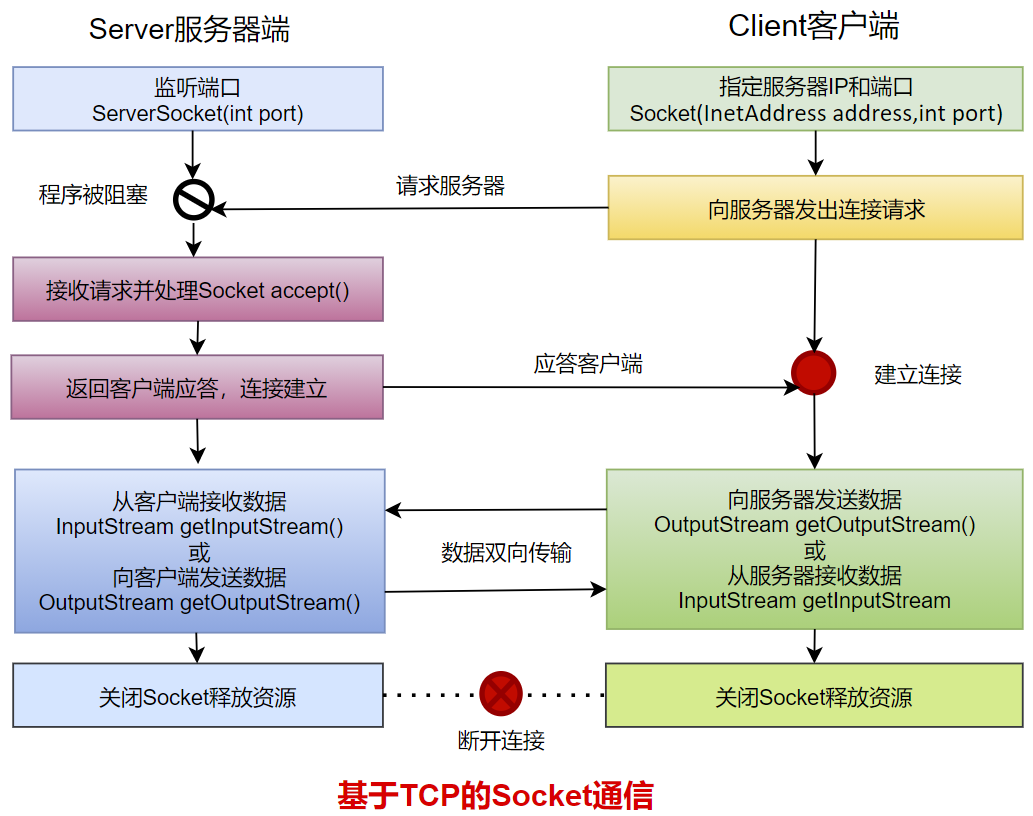
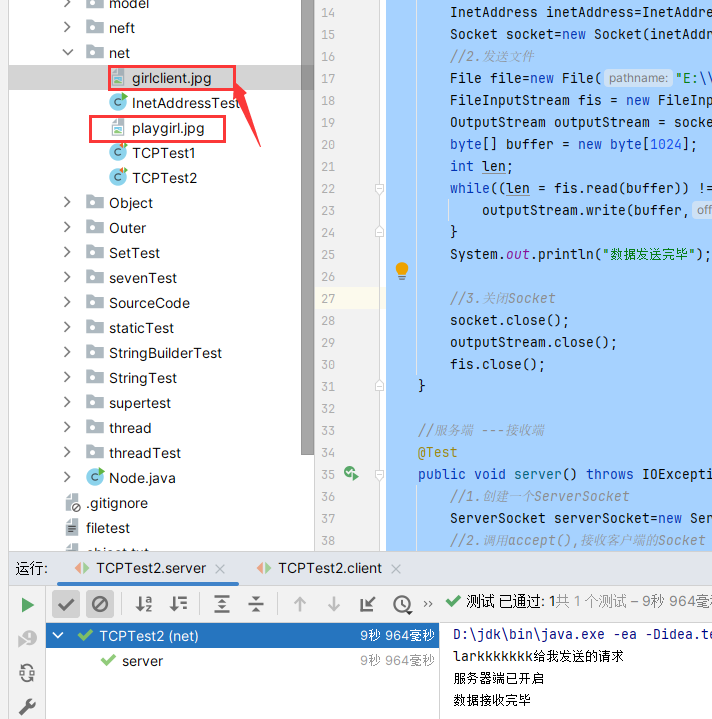
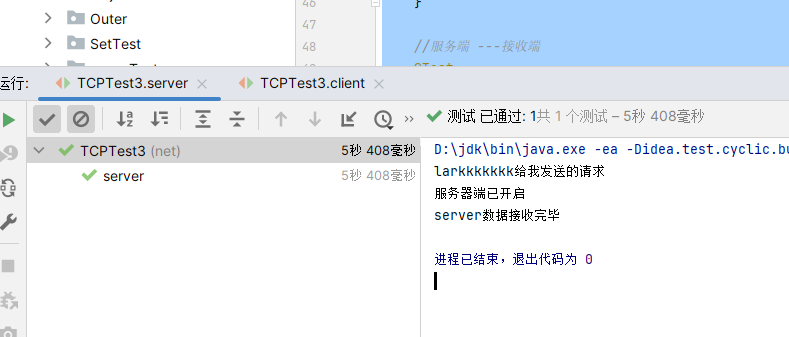
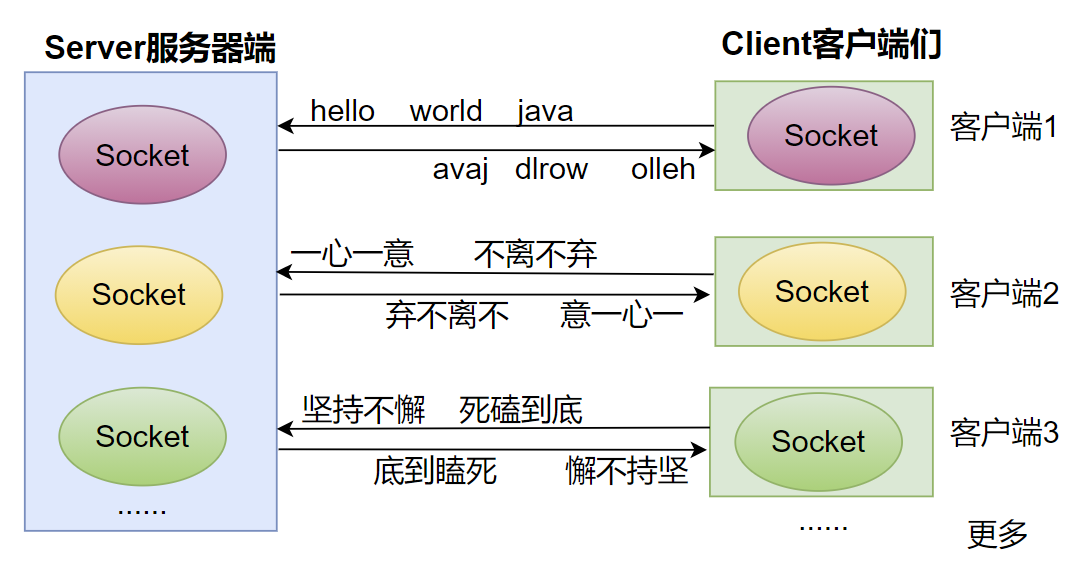
4. TCP网络编程
4.1 通信模型
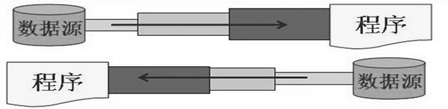
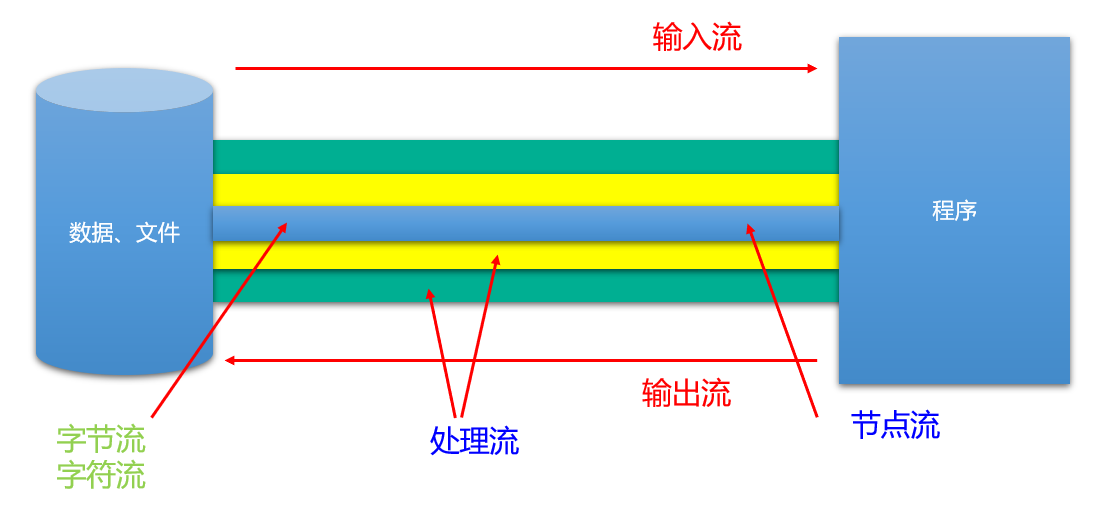
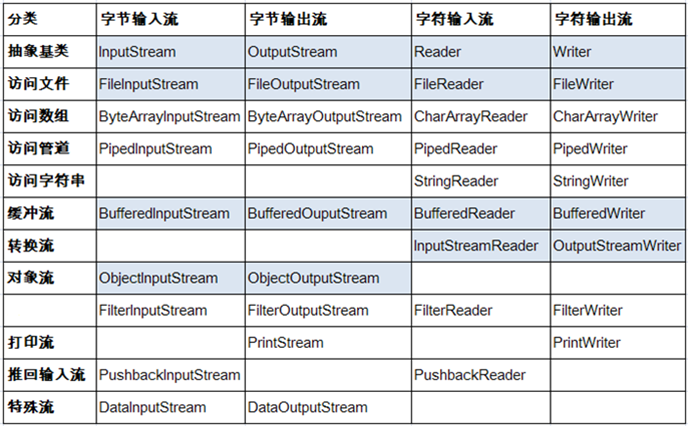
Java语言的基于套接字TCP编程分为服务端编程和客户端编程,其通信模型如图所示:
4.2 开发步骤
客户端程序包含以下四个基本的步骤 :
创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
//要发送的数据 ArrayList<String> all = new ArrayList<String>(); all.add("尚硅谷让天下没有难学的技术!"); all.add("学高端前沿的IT技术来尚硅谷!"); all.add("尚硅谷让你的梦想变得更具体!"); all.add("尚硅谷让你的努力更有价值!");
//接收方的IP地址 InetAddress ip = InetAddress.getByName("127.0.0.1"); //接收方的监听端口号 int port = 9999; //发送多个数据报 for (int i = 0; i < all.size(); i++) { // 2、建立数据包DatagramPacket byte[] data = all.get(i).getBytes(); DatagramPacket dp = new DatagramPacket(data, 0, data.length, ip, port); // 3、调用Socket的发送方法 ds.send(dp); }
- public Object getContent( ) throws IOException - public int getContentLength( ) - public String getContentType( ) - public long getDate( ) - public long getLastModified( ) - public InputStream getInputStream ( ) throws IOException - public OutputSteram getOutputStream( )throws IOException
public ObjectOutputStream(OutputStream out): 创建一个指定的ObjectOutputStream。
1 2
FileOutputStream fos = new FileOutputStream("game.dat"); ObjectOutputStream oos = new ObjectOutputStream(fos);
ObjectOutputStream中的方法:
public void writeBoolean(boolean val):写出一个 boolean 值。
public void writeByte(int val):写出一个8位字节
public void writeShort(int val):写出一个16位的 short 值
public void writeChar(int val):写出一个16位的 char 值
public void writeInt(int val):写出一个32位的 int 值
public void writeLong(long val):写出一个64位的 long 值
public void writeFloat(float val):写出一个32位的 float 值。
public void writeDouble(double val):写出一个64位的 double 值
public void writeUTF(String str):将表示长度信息的两个字节写入输出流,后跟字符串 s 中每个字符的 UTF-8 修改版表示形式。根据字符的值,将字符串 s 中每个字符转换成一个字节、两个字节或三个字节的字节组。注意,将 String 作为基本数据写入流中与将它作为 Object 写入流中明显不同。 如果 s 为 null,则抛出 NullPointerException。
public void writeObject(Object obj):写出一个obj对象
public void close() :关闭此输出流并释放与此流相关联的任何系统资源
ObjectInputStream中的构造器:
public ObjectInputStream(InputStream in): 创建一个指定的ObjectInputStream。
1 2
FileInputStream fis = new FileInputStream("game.dat"); ObjectInputStream ois = new ObjectInputStream(fis);
package com.atguigu.java; // MyInput.java: Contain the methods for reading int, double, float, boolean, short, byte and // string values from the keyboard
import java.io.*;
publicclassMyInput{ // Read a string from the keyboard publicstatic String readString(){ BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
// Declare and initialize the string String string = "";
// Get the string from the keyboard try { string = br.readLine();
// 栈帧,永远指向栈顶部元素 // 那么这个默认初始值应该是多少。注意:最初的栈是空的,一个元素都没有。 //private int index = 0; // 如果index采用0,表示栈帧指向了顶部元素的上方。 //private int index = -1; // 如果index采用-1,表示栈帧指向了顶部元素。 privateint index;
publicclassTreeMap<K,V> { privatetransient Entry<K,V> root; privatetransientint size = 0; staticfinalclassEntry<K,V> implementsMap.Entry<K,V> { K key; V value; Entry<K,V> left; Entry<K,V> right; Entry<K,V> parent; boolean color = BLACK;
/** * Make a new cell with given key, value, and parent, and with * {@code null} child links, and BLACK color. */ Entry(K key, V value, Entry<K,V> parent) { this.key = key; this.value = value; this.parent = parent; } } }
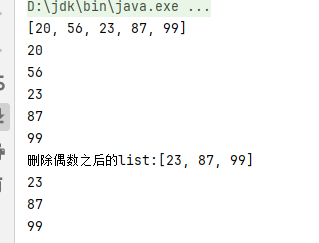
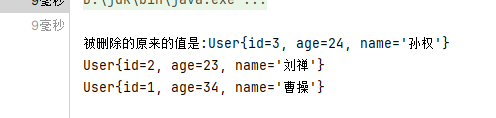
//方法:remove()相关方法 public E remove(int index){ rangeCheck(index); //判断index是否在有效的范围内
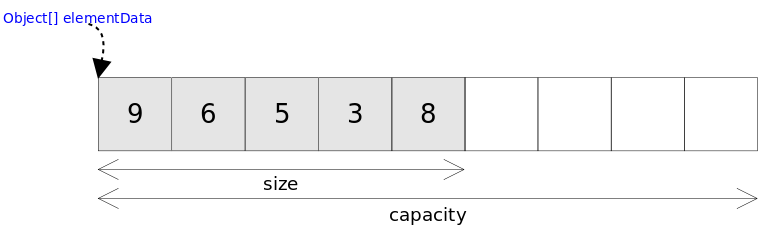
modCount++; //修改次数加1 //取出[index]位置的元素,[index]位置的元素就是要被删除的元素,用于最后返回被删除的元素 E oldValue = elementData(index);
int numMoved = size - index - 1; //确定要移动的次数 //如果需要移动元素,就用System.arraycopy移动元素 if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); //将elementData[size-1]位置置空,让GC回收空间,元素个数减少 elementData[--size] = null;
return oldValue; }
privatevoidrangeCheck(int index){ if (index >= size) //index不合法的情况 thrownew IndexOutOfBoundsException(outOfBoundsMsg(index)); }
E elementData(int index){ //返回指定位置的元素 return (E) elementData[index]; }
//方法:set()方法相关 public E set(int index, E element){ rangeCheck(index); //检验index是否合法 //取出[index]位置的元素,[index]位置的元素就是要被替换的元素,用于最后返回被替换的元素 E oldValue = elementData(index); //用element替换[index]位置的元素 elementData[index] = element; return oldValue; }
//方法:get()相关方法 public E get(int index){ rangeCheck(index); //检验index是否合法
return elementData(index); //返回[index]位置的元素 }
//方法:indexOf() publicintindexOf(Object o){ //分为o是否为空两种情况 if (o == null) { //从前往后找 for (int i = 0; i < size; i++) if (elementData[i]==null) return i; } else { for (int i = 0; i < size; i++) if (o.equals(elementData[i])) return i; } return -1; }
//方法:lastIndexOf() publicintlastIndexOf(Object o){ //分为o是否为空两种情况 if (o == null) { //从后往前找 for (int i = size-1; i >= 0; i--) if (elementData[i]==null) return i; } else { for (int i = size-1; i >= 0; i--) if (o.equals(elementData[i])) return i; } return -1; }
//方法:remove()相关方法 publicbooleanremove(Object o){ return removeElement(o); } publicsynchronizedbooleanremoveElement(Object obj){ modCount++; //查找obj在当前Vector中的下标 int i = indexOf(obj); //如果i>=0,说明存在,删除[i]位置的元素 if (i >= 0) { removeElementAt(i); returntrue; } returnfalse; }
//方法:indexOf() publicintindexOf(Object o){ return indexOf(o, 0); } publicsynchronizedintindexOf(Object o, int index){ if (o == null) {//要查找的元素是null值 for (int i = index ; i < elementCount ; i++) if (elementData[i]==null)//如果是null值,用==null判断 return i; } else {//要查找的元素是非null值 for (int i = index ; i < elementCount ; i++) if (o.equals(elementData[i]))//如果是非null值,用equals判断 return i; } return -1; }
//j是要移动的元素的个数 int j = elementCount - index - 1; //如果需要移动元素,就调用System.arraycopy进行移动 if (j > 0) { //把index+1位置以及后面的元素往前移动 //index+1的位置的元素移动到index位置,依次类推 //一共移动j个 System.arraycopy(elementData, index + 1, elementData, index, j); } //元素的总个数减少 elementCount--; //将elementData[elementCount]这个位置置空,用来添加新元素,位置的元素等着被GC回收 elementData[elementCount] = null; /* to let gc do its work */ }
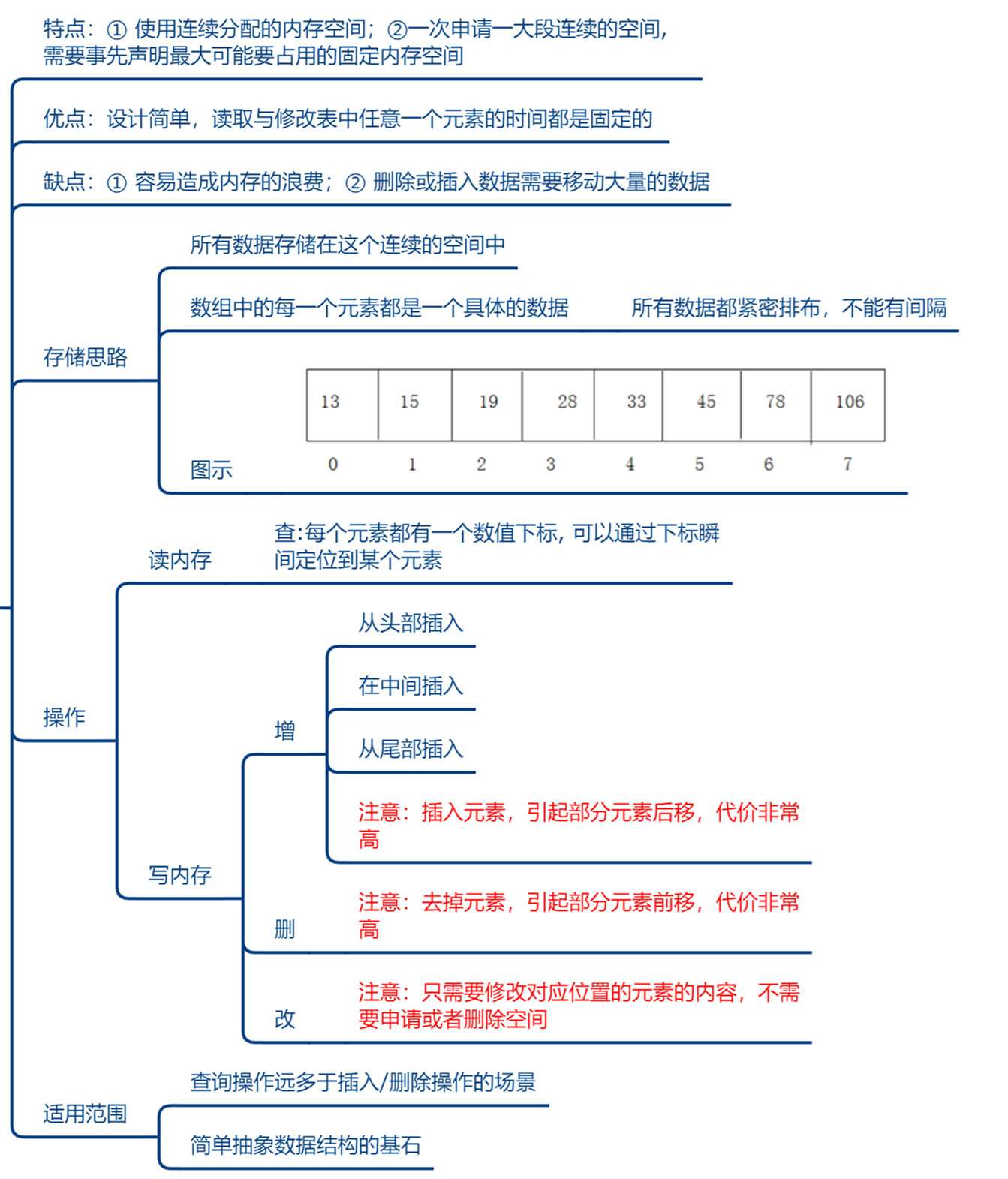
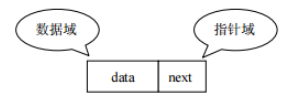
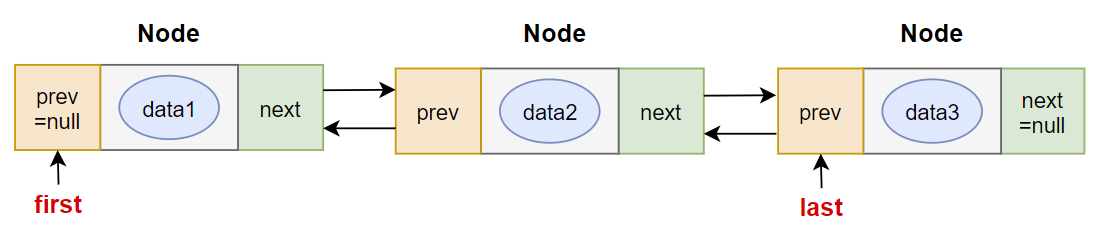
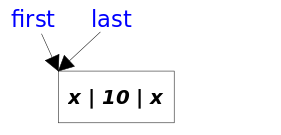
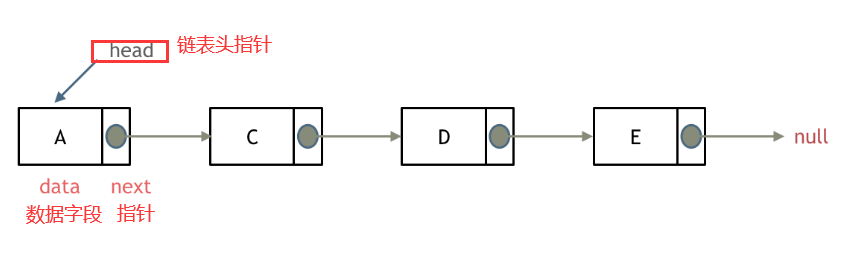
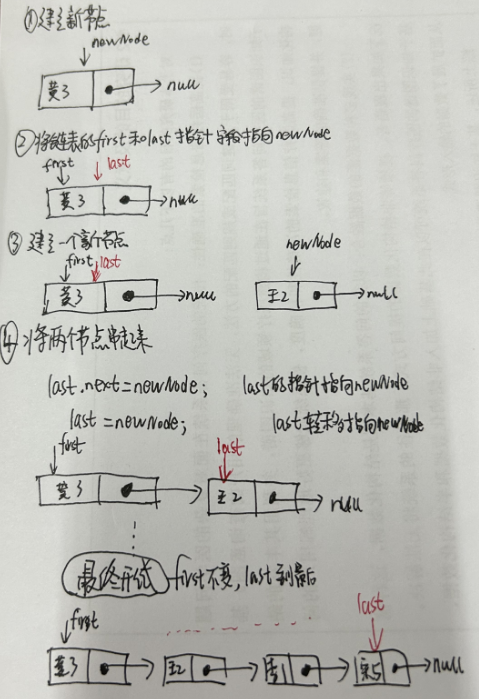
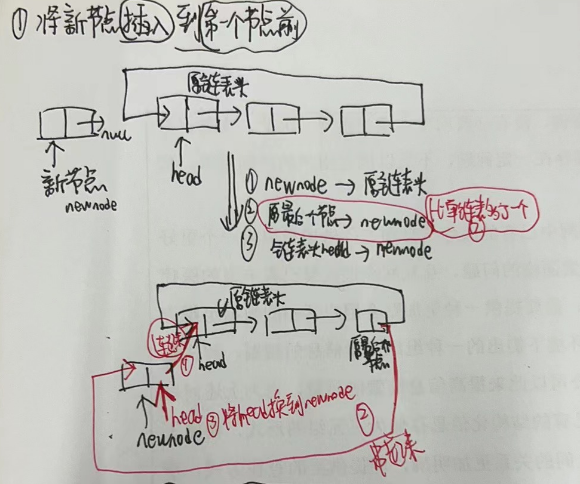
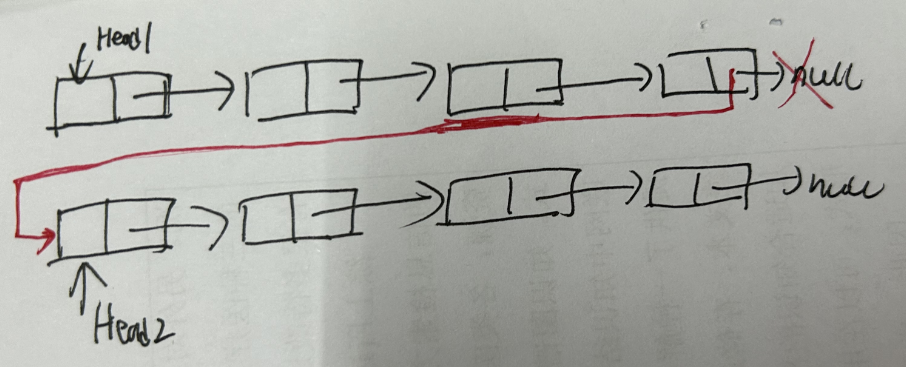
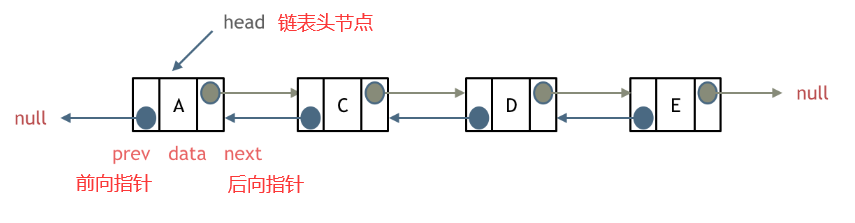
voidlinkLast(E e){ final Node<E> l = last; //用 l 记录原来的最后一个结点 //创建新结点 final Node<E> newNode = new Node<>(l, e, null); //新节点链接到前一个节点 新节点没有链接到后一个节点 //现在的新结点是最后一个结点了 last = newNode; //如果l==null,说明原来的链表是空的 if (l == null) //那么新结点同时也是第一个结点 first = newNode; else //否则把新结点链接到原来的最后一个结点的next中 l.next = newNode; //元素个数增加 size++; //修改次数增加 modCount++; }
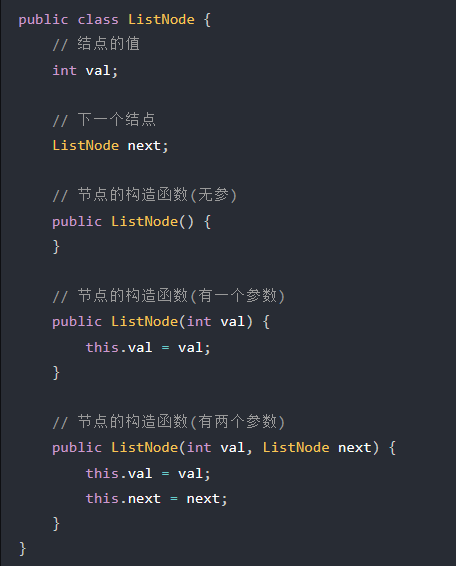
Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } } //方法:获取get()相关方法 public E get(int index){ checkElementIndex(index); return node(index).item; }
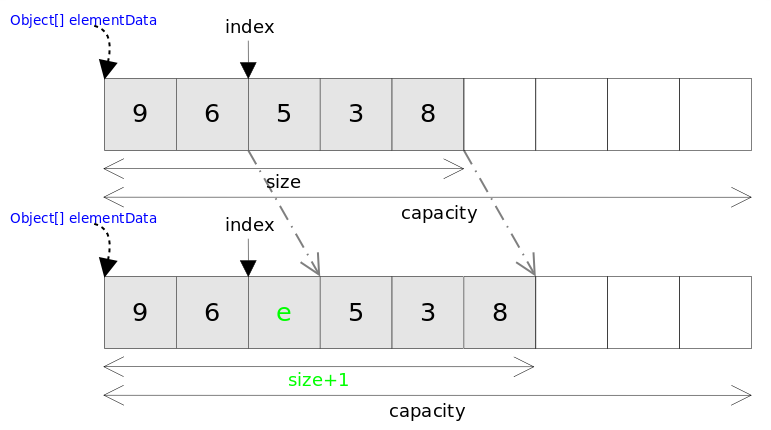
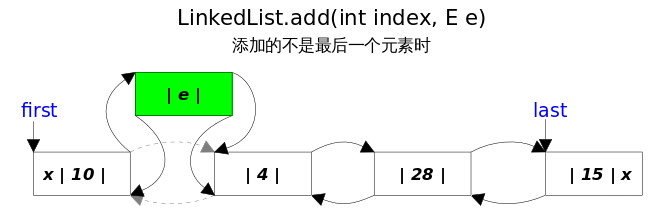
//方法:插入add()相关方法 publicvoidadd(int index, E element){ checkPositionIndex(index);//检查index范围
if (index == size)//如果index==size,连接到当前链表的尾部 linkLast(element); else linkBefore(element, node(index)); }
Node<E> node(int index){ // assert isElementIndex(index); /* index < (size >> 1)采用二分思想,先将index与长度size的一半比较,如果index<size/2,就只从位置0 往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部 分不必要的遍历。 */ //如果index<size/2,就从前往后找目标结点 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else {//否则从后往前找目标结点 Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
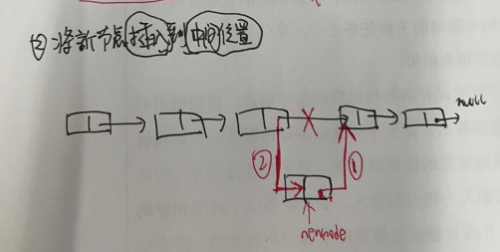
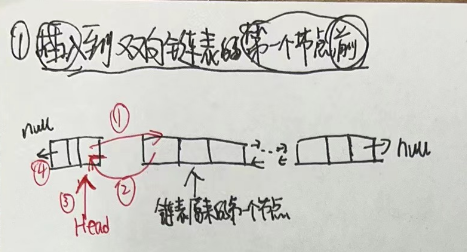
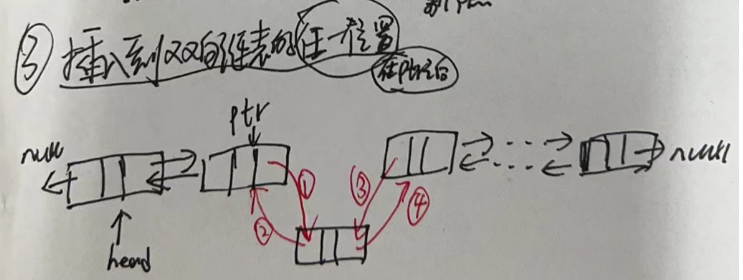
//把新结点插入到[index]位置的结点succ前面 voidlinkBefore(E e, Node<E> succ){//succ是[index]位置对应的结点 // assert succ != null; final Node<E> pred = succ.prev; //[index]位置的前一个结点
//新结点的prev是原来[index]位置的前一个结点 //新结点的next是原来[index]位置的结点 final Node<E> newNode = new Node<>(pred, e, succ);
//[index]位置对应的结点的prev指向新结点 succ.prev = newNode;
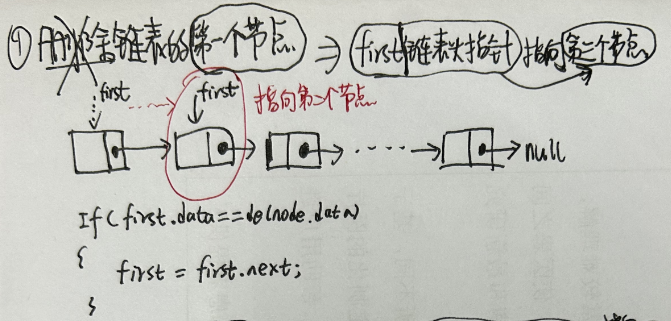
//如果原来[index]位置对应的结点是第一个结点,那么现在新结点是第一个结点 if (pred == null) first = newNode; else pred.next = newNode;//原来[index]位置的前一个结点的next指向新结点 size++; modCount++; }
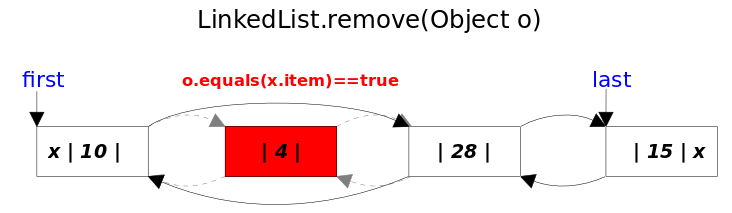
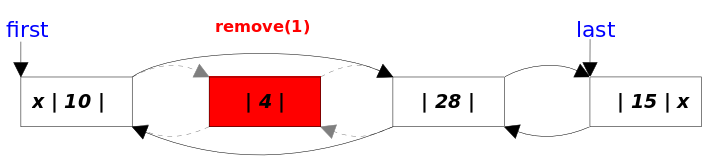
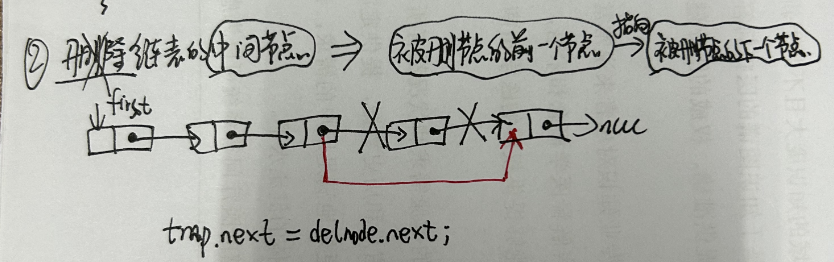
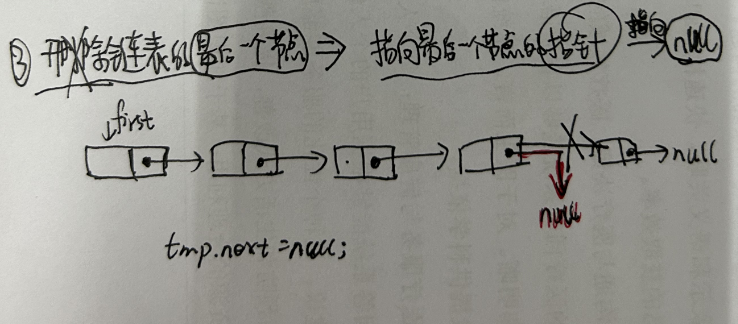
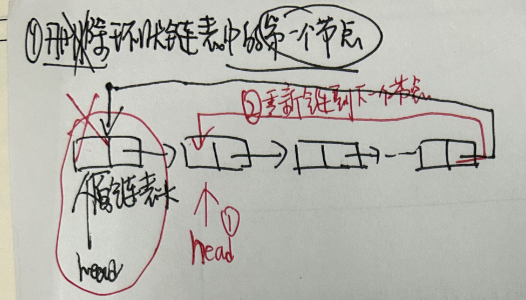
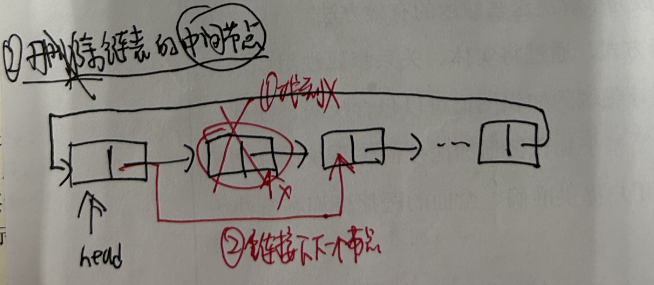
//方法:remove()相关方法 publicbooleanremove(Object o){ //分o是否为空两种情况 if (o == null) { //找到o对应的结点x for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x);//删除x结点 returntrue; } } } else { //找到o对应的结点x for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x);//删除x结点 returntrue; } } } returnfalse; } E unlink(Node<E> x){//x是要被删除的结点 // assert x != null; final E element = x.item;//被删除结点的数据 final Node<E> next = x.next;//被删除结点的下一个结点 final Node<E> prev = x.prev;//被删除结点的上一个结点
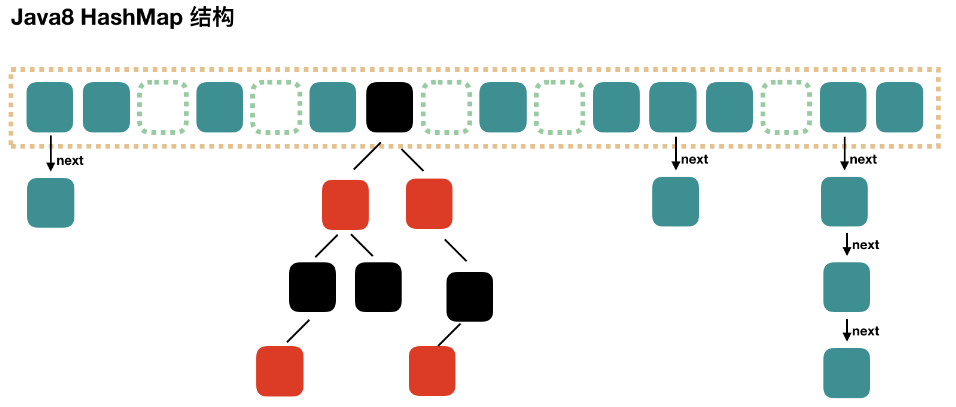
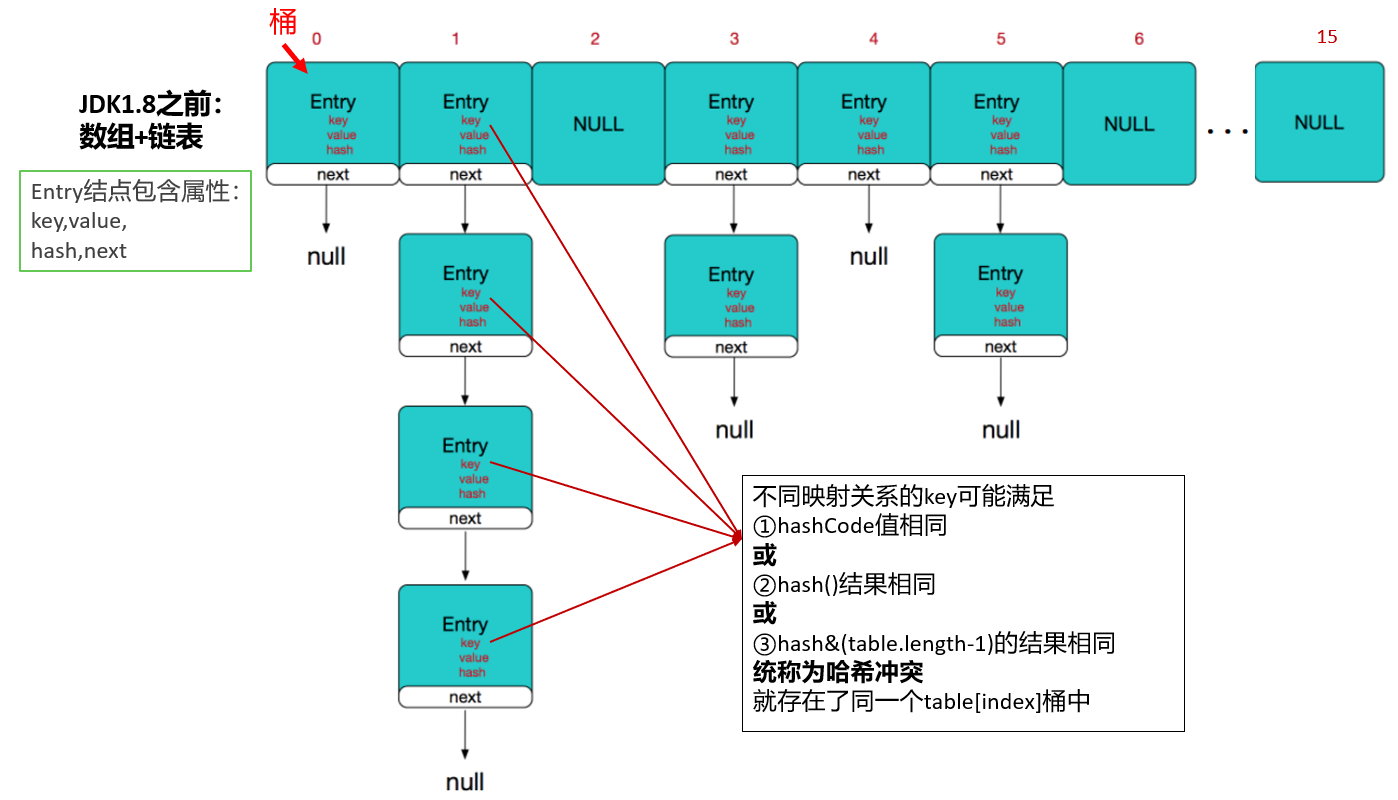
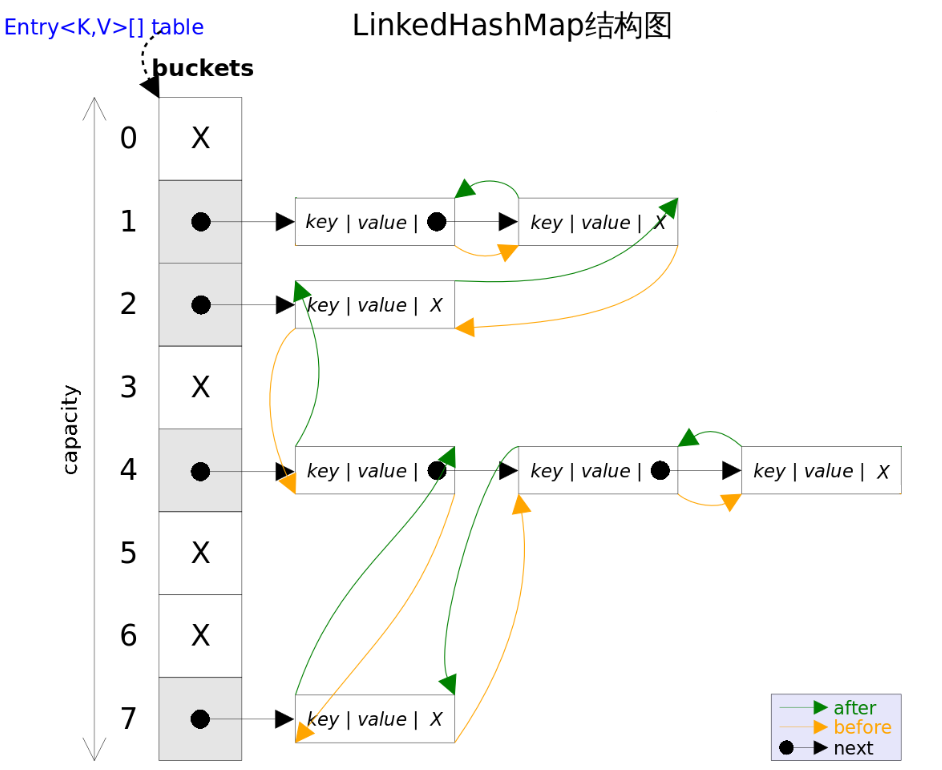
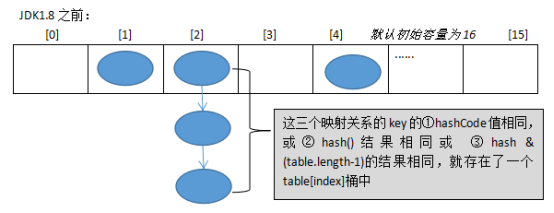
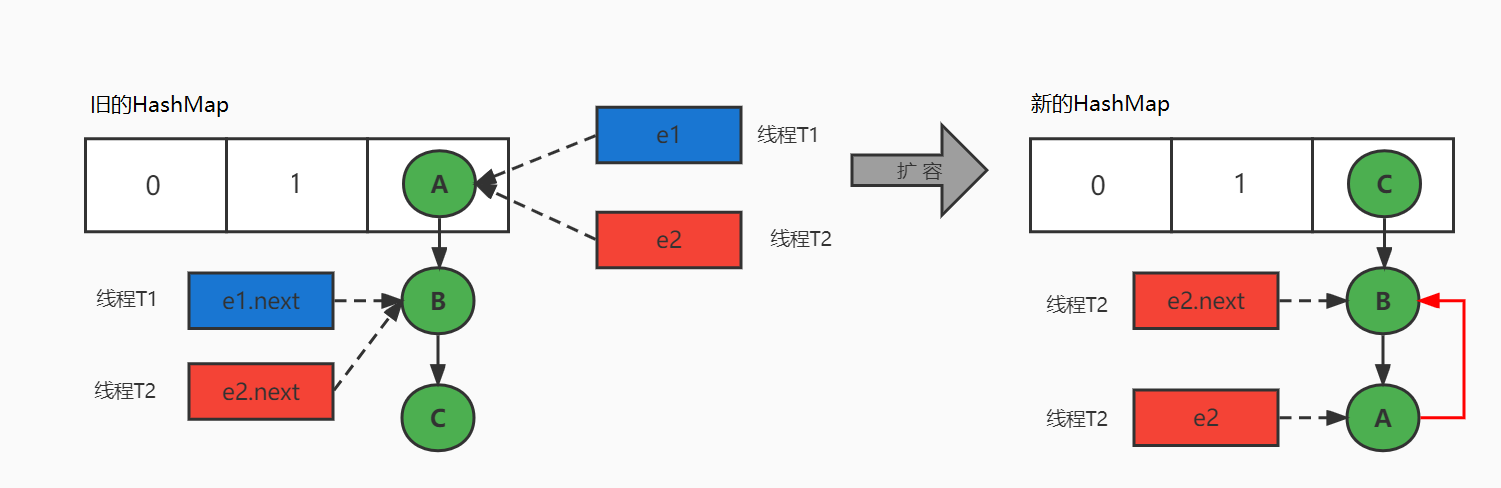
补充:jdk7源码中定义的: staticclassEntry<K,V> implementsMap.Entry<K,V> map.get(key1); ① 计算key1的hash值,用这个方法hash(key1) ② 找index = table.length-1 & hash; ③ 如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就返回它的value map.remove(key1); ① 计算key1的hash值,用这个方法hash(key1) ② 找index = table.length-1 & hash; ③ 如果table[index]不为空,那么就挨个比较哪个Entry的key与它相同,就删除它,把它前面的Entry的next的值修改为被删除Entry的next
publicclassHashMap<K,V>{ transient Entry<K,V>[] table; staticclassEntry<K,V> implementsMap.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; //使用key得到的哈希值2进行赋值。
/** * Creates new entry. */ Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } //略 } }
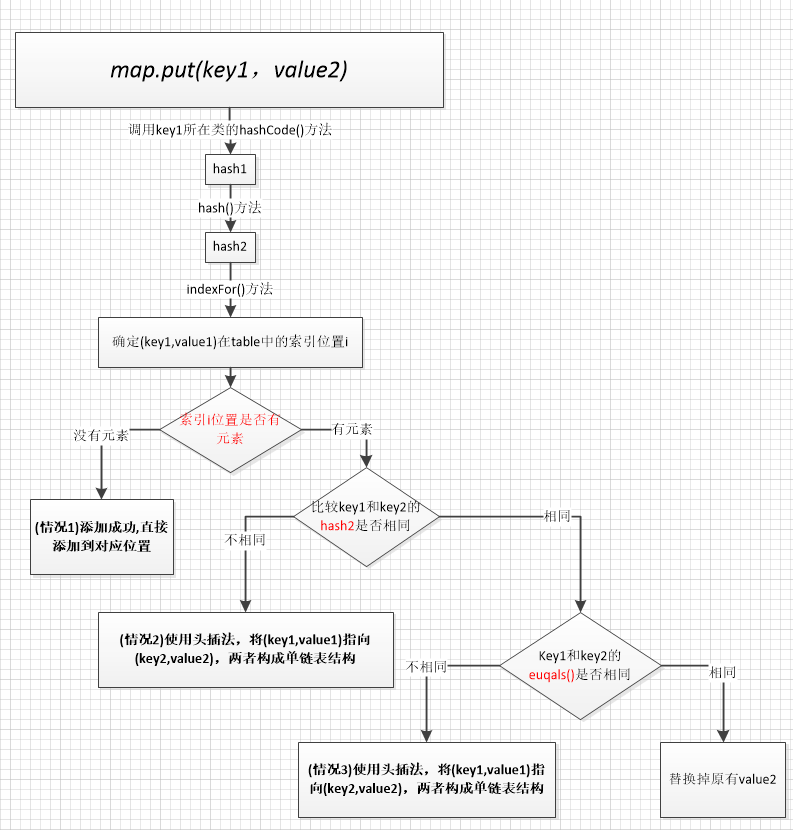
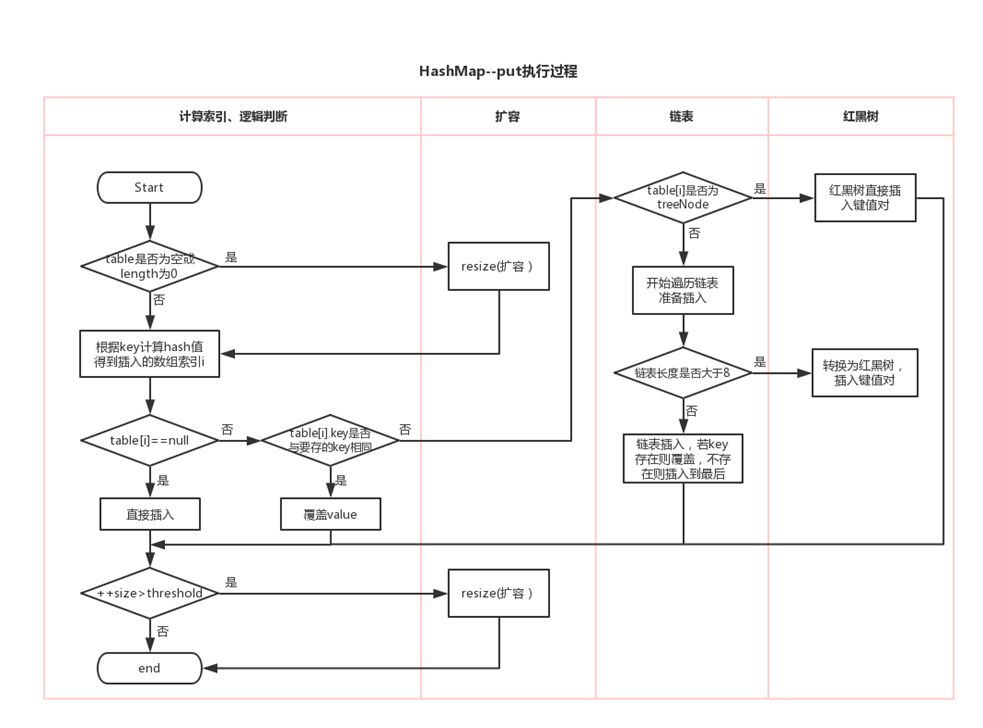
public V put(K key, V value){ //如果key是null,单独处理,存储到table[0]中,如果有另一个key为null,value覆盖 if (key == null) return putForNullKey(value); //对key的hashCode进行干扰,算出一个hash值 /* hashCode值 xxxxxxxxxx table.length-1 000001111 hashCode值 xxxxxxxxxx 无符号右移几位和原来的hashCode值做^运算,使得hashCode高位二进制值参与计算, 也发挥作用,降低index冲突的概率。 */ int hash = hash(key); //计算新的映射关系应该存到table[i]位置, //i = hash & table.length-1,可以保证i在[0,table.length-1]范围内 int i = indexFor(hash, table.length); //检查table[i]下面有没有key与我新的映射关系的key重复,如果重复替换value for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果hash不相同,就不进入if语句,那样就一直e=e.next然后调用addEntry()最终使用头插法 --情况2 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { //左边false那就情况2 左边true就判断后面的就是情况3 V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; //如果put是修改操作,会返回原有旧的value值。 } } //如果当前索引位置i没有元素 e==null --情况1 modCount++; //添加新的映射关系 addEntry(hash, key, value, i); //将key,value封装为一个Entry对象,并将此对象保存在索引i位置。 returnnull; //如果put是添加操作,会返回null. }
其中,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
//如果key是null,直接存入[0]的位置 private V putForNullKey(V value){ //判断是否有重复的key,如果有重复的,就替换value for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //把新的映射关系存入[0]的位置,而且key的hash值用0表示 addEntry(0, null, value, 0); returnnull; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
finalinthash(Object k){ int h = 0; if (useAltHashing) { if (k instanceof String) { return sun.misc.Hashing.stringHash32((String) k); } h = hashSeed; }
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
1 2 3
staticintindexFor(int h, int length){ return h & (length-1); //相当于用哈希值2&15 那只考虑最低四位&1111 效率要比整体取模要高很多 -->得到0-15的值 }
staticintindexFor(int h, int length){ // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); //此处h就是hash }
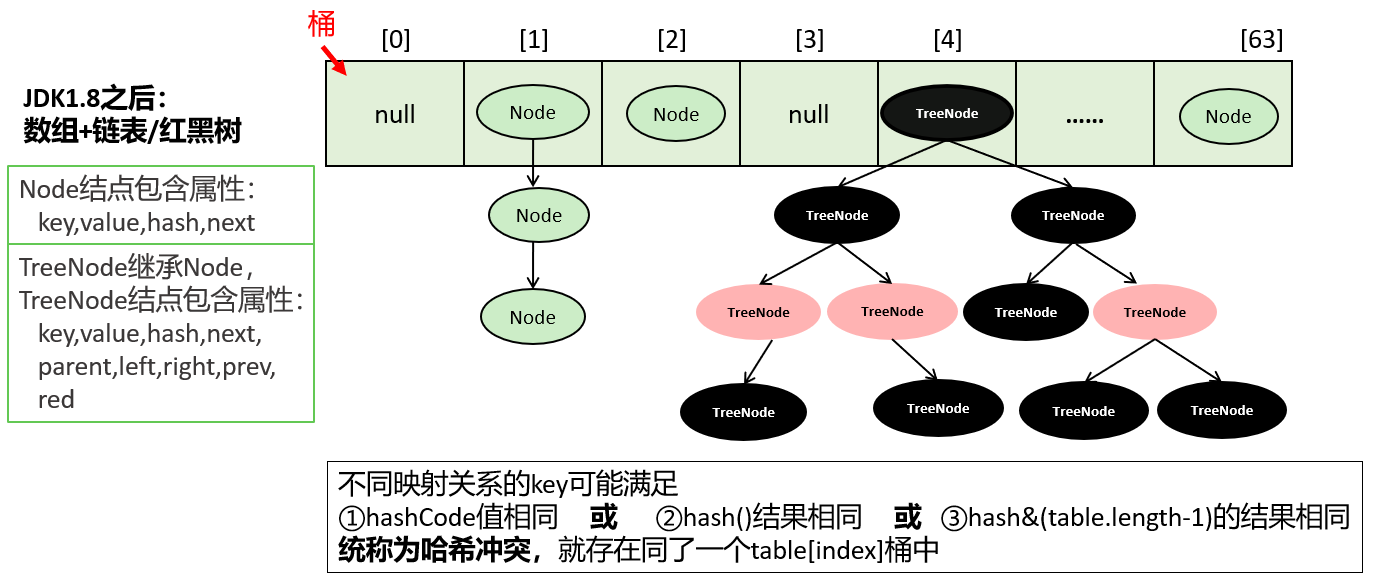
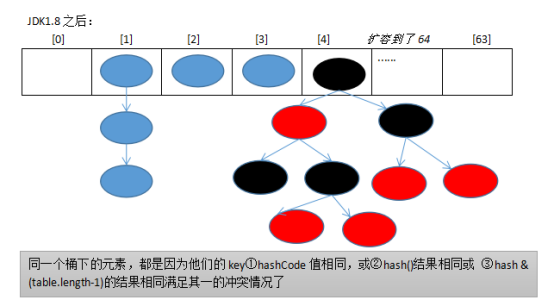
JDK1.8:
1 2 3 4 5 6 7 8
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict){ Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) // i = (n - 1) & hash tab[i] = newNode(hash, key, value, null); //....省略大量代码 }
//泛型在List中的使用 @Test publicvoidtest1(){ //举例:将学生成绩保存在ArrayList中 //标准写法: //ArrayList<Integer> list = new ArrayList<Integer>(); //jdk7的新特性:类型推断 ArrayList<Integer> list = new ArrayList<>();
//测试类 publicclassTestHasGeneric{ publicstaticvoidmain(String[] args){ CircleComparator1 com = new CircleComparator1(); System.out.println(com.compare(new Circle(1), new Circle(2)));
publicclassTestRectangle{ publicstaticvoidmain(String[] args){ Rectangle[] arr = new Rectangle[4]; arr[0] = new Rectangle(6,2); arr[1] = new Rectangle(4,3); arr[2] = new Rectangle(12,1); arr[3] = new Rectangle(5,4);
System.out.println("排序之前:"); for (Rectangle rectangle : arr) { System.out.println(rectangle); }
定义个泛型类 DAO<T>,在其中定义一个Map 成员变量,Map 的键为 String 类型,值为 T 类型。
分别创建以下方法: public void save(String id,T entity): 保存 T 类型的对象到 Map 成员变量中 public T get(String id):从 map 中获取 id 对应的对象 public void update(String id,T entity):替换 map 中key为id的内容,改为 entity 对象 public List<T> list():返回 map 中存放的所有 T 对象 public void delete(String id):删除指定 id 对象
定义一个 User 类: 该类包含:private成员变量(int类型) id,age;(String 类型)name。
定义一个测试类: 创建 DAO 类的对象, 分别调用其 save、get、update、list、delete 方法来操作 User 对象, 使用 Junit 单元测试类进行测试。
@Override public String toString(){ return"User{" +"id=" + id +", age=" + age +", name='" + name + '\'' +'}'; }
@Override publicbooleanequals(Object o){ if (this == o) returntrue; if (o == null || getClass() != o.getClass()) returnfalse; User user = (User) o; return id == user.id && age == user.age && Objects.equals(name, user.name); }
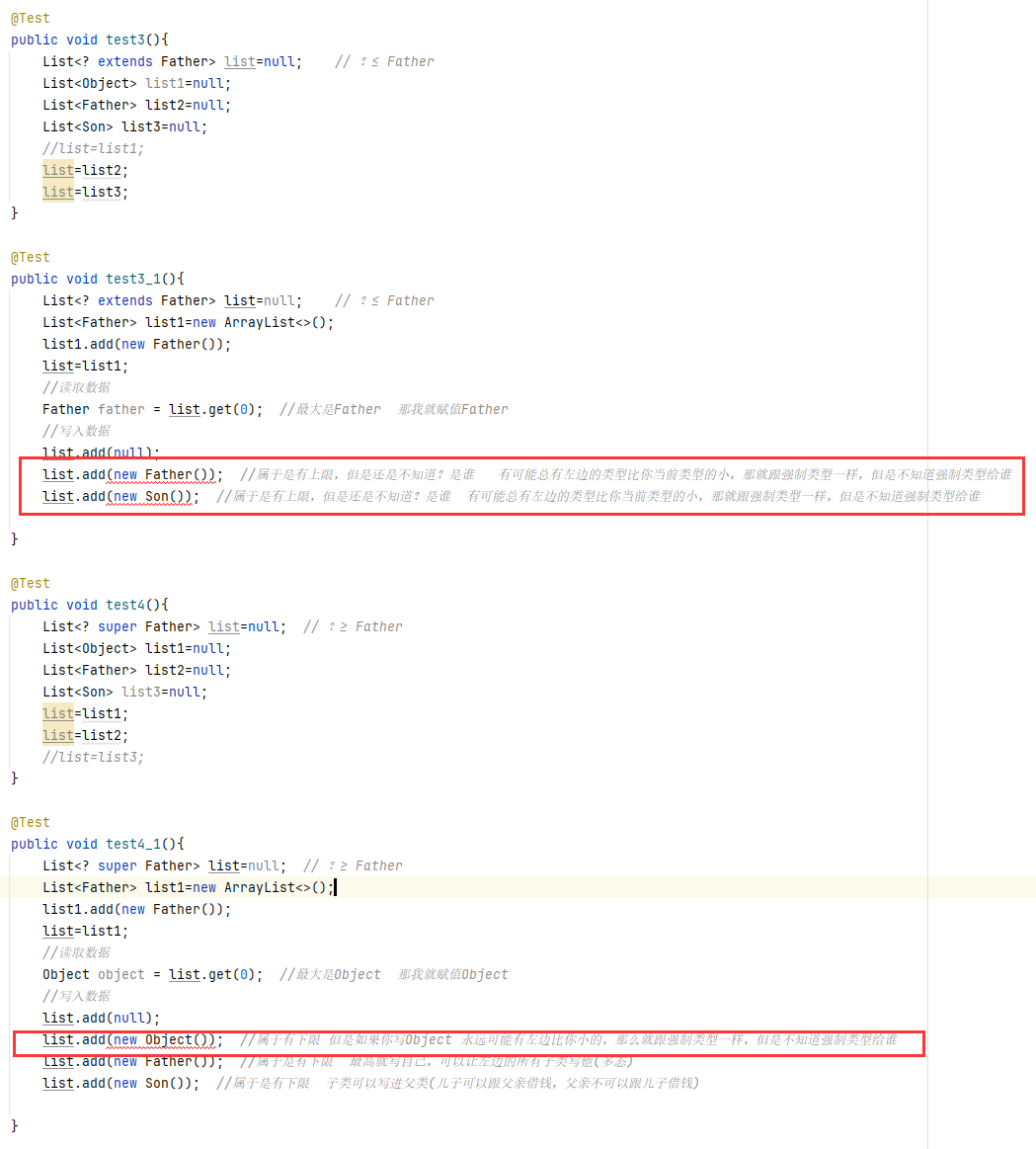
publicstaticvoidmain(String[] args){ List<?> list = null; list = new ArrayList<String>(); list = new ArrayList<Double>(); // list.add(3);//编译不通过 list.add(null);
List<String> l1 = new ArrayList<String>(); List<Integer> l2 = new ArrayList<Integer>(); l1.add("尚硅谷"); l2.add(15); read(l1); read(l2); }
publicstaticvoidread(List<?> list){ for (Object o : list) { System.out.println(o); } }
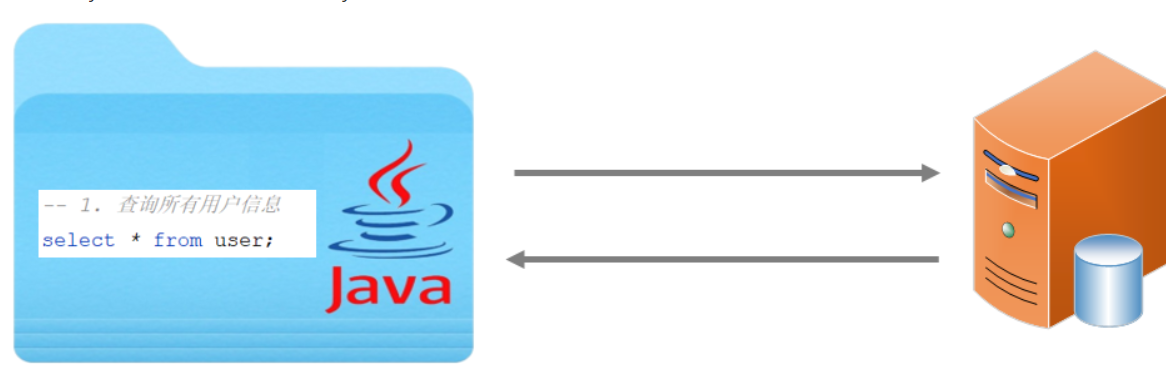
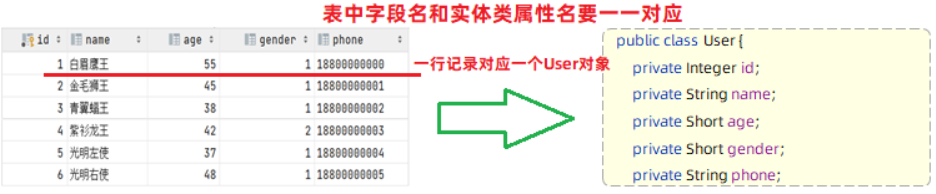
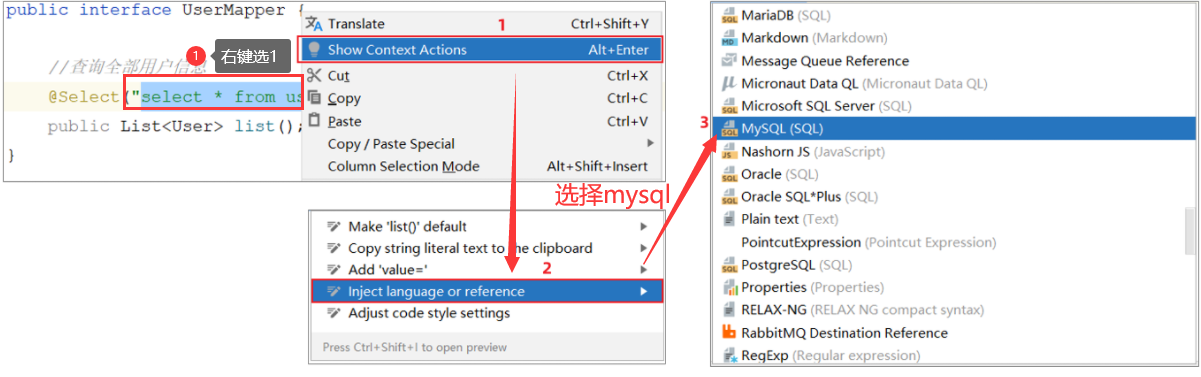
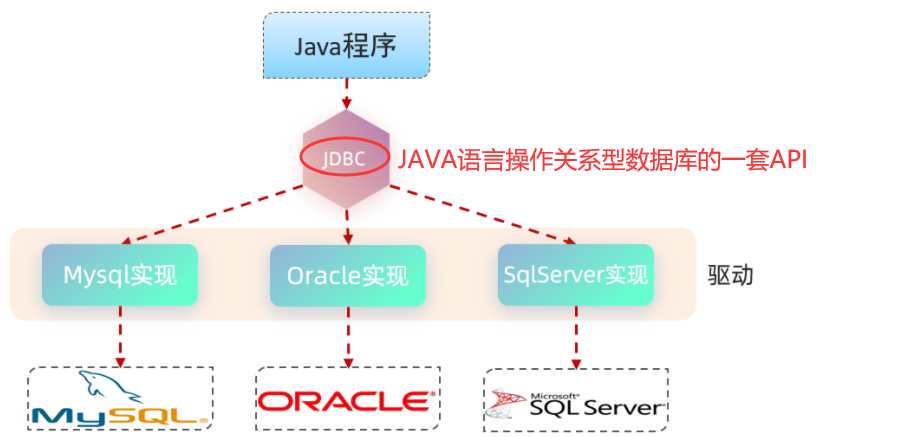

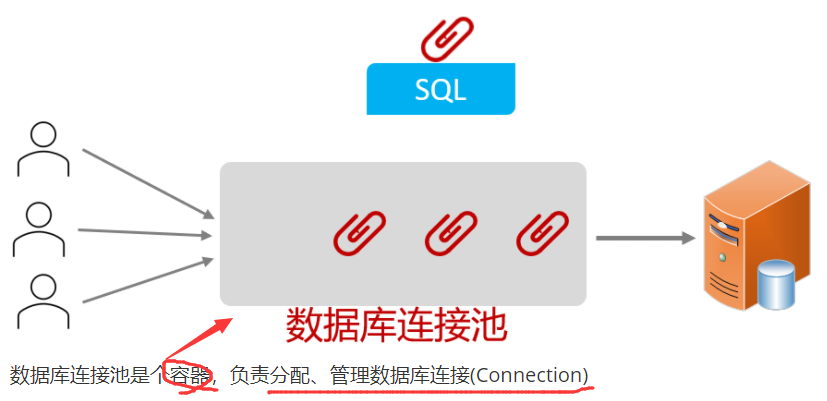
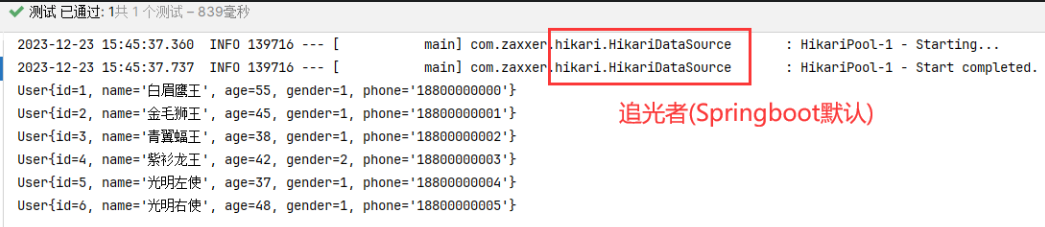


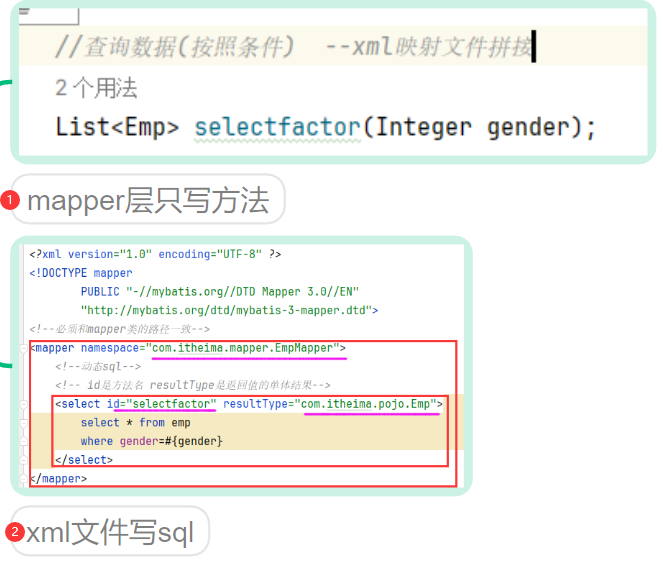
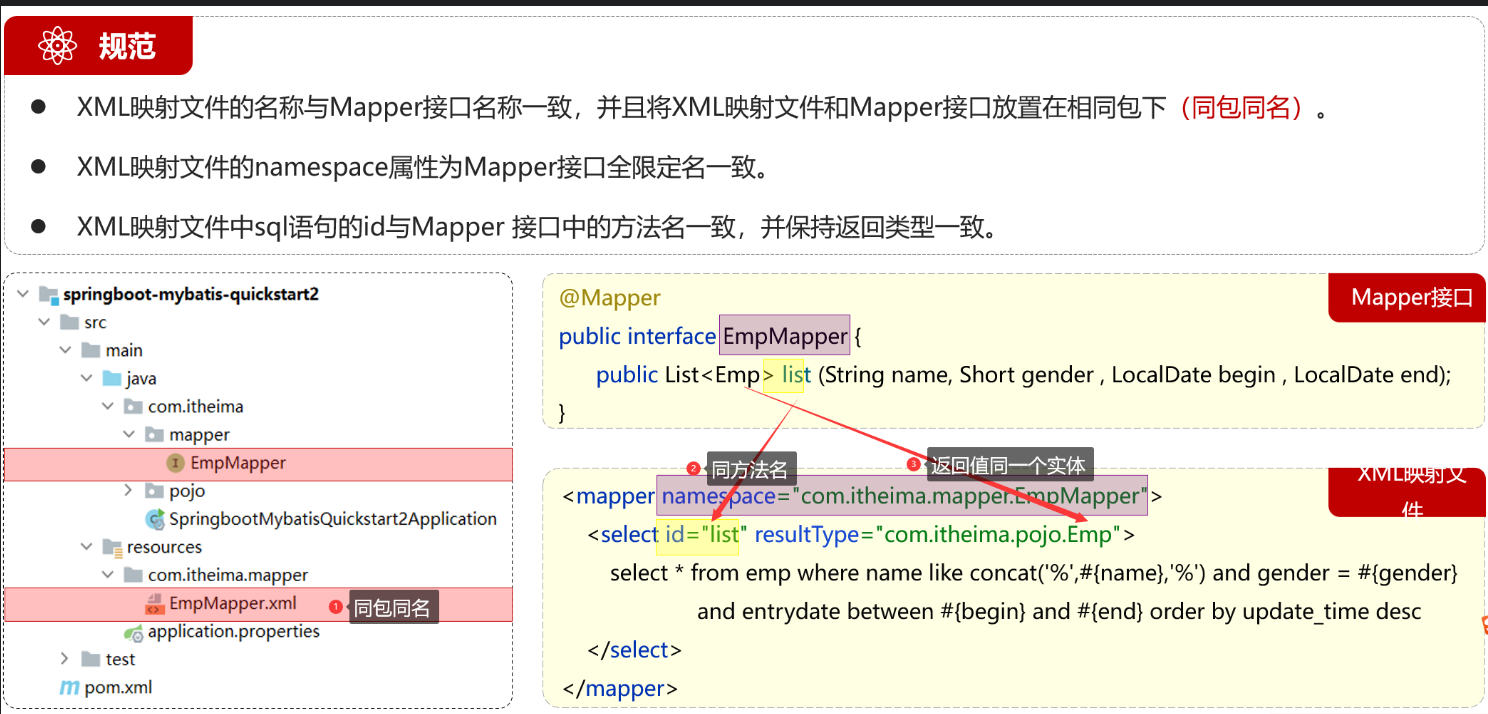
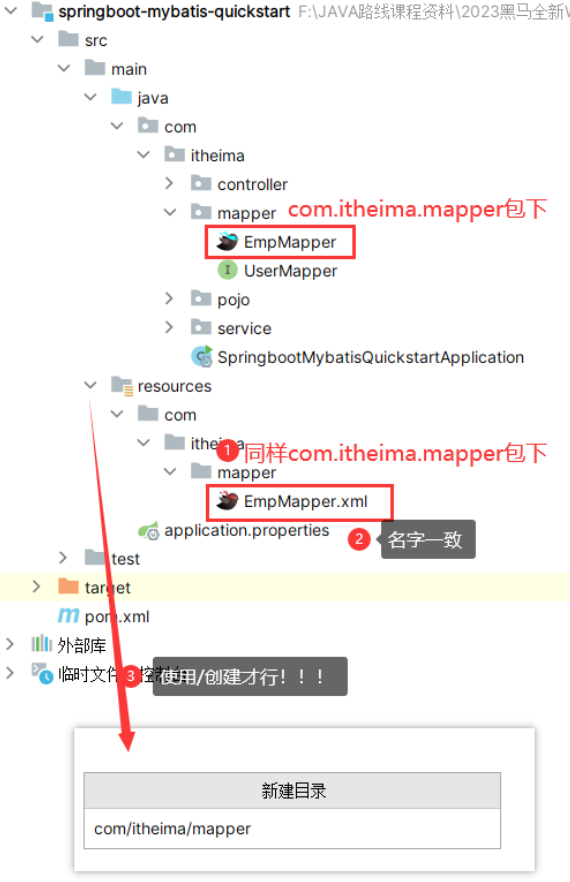
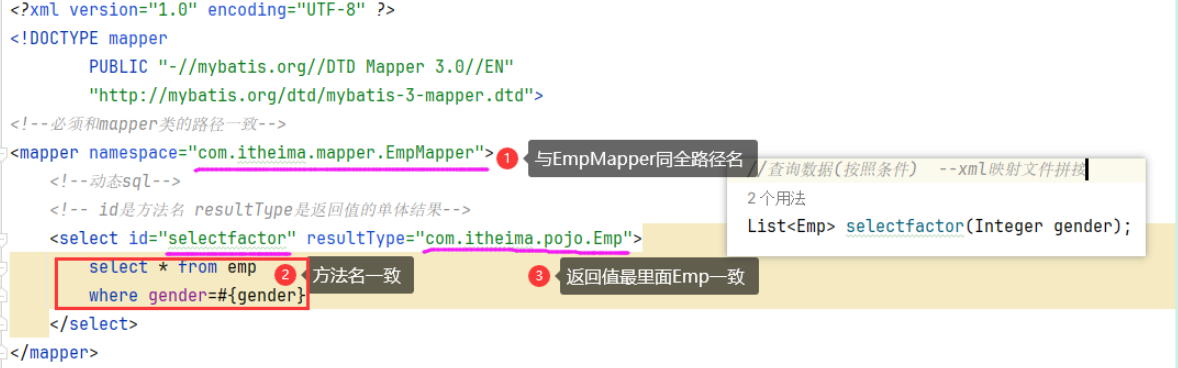
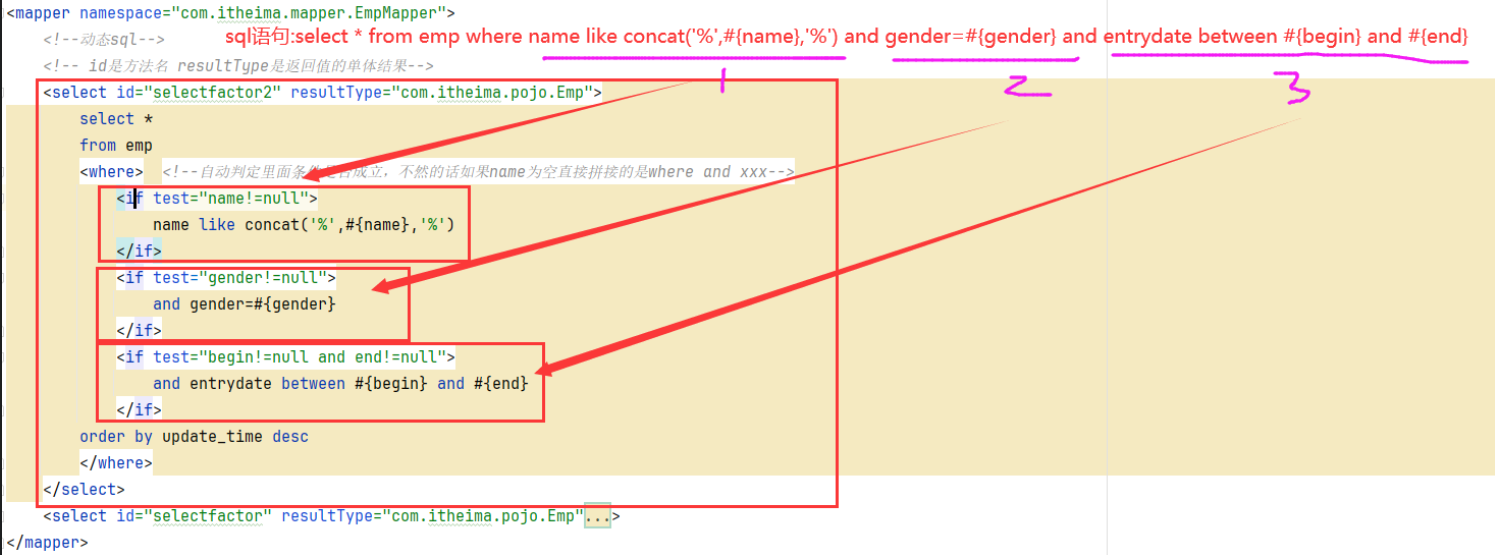
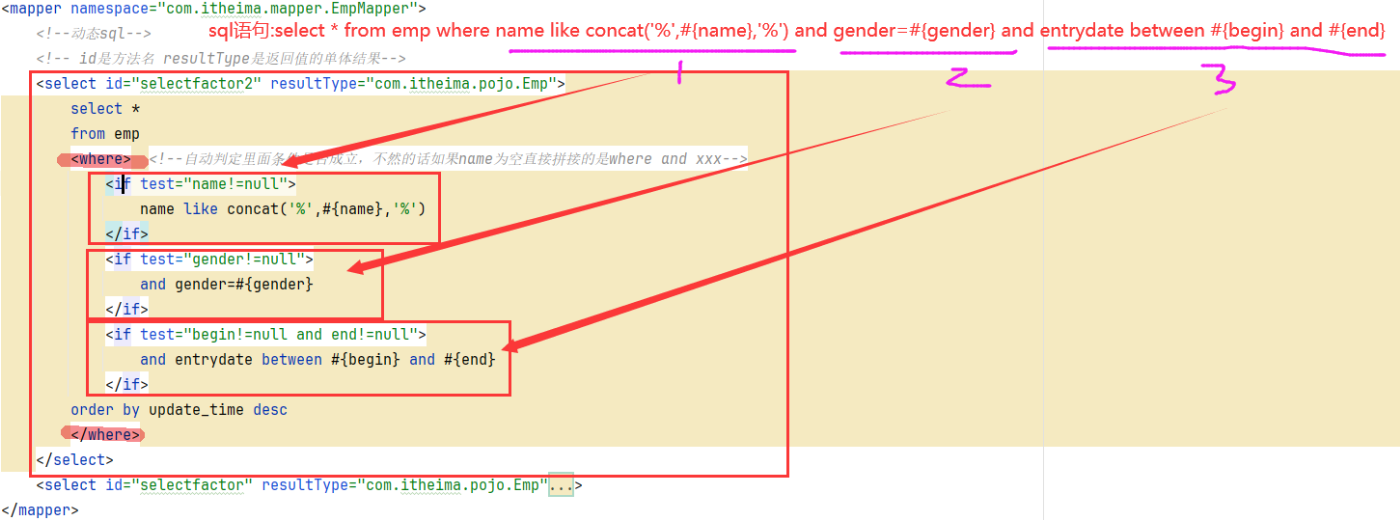


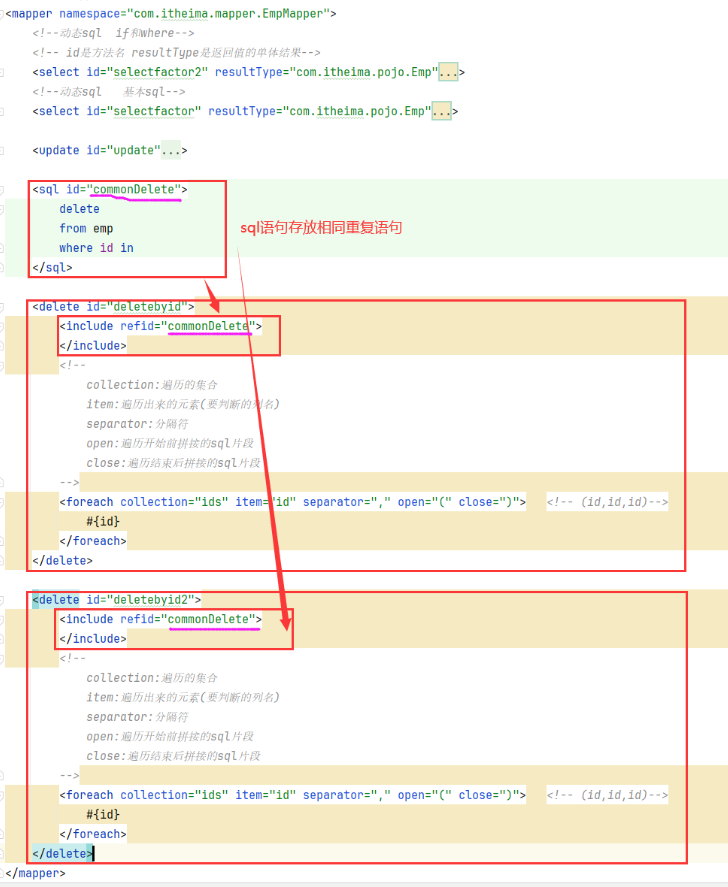

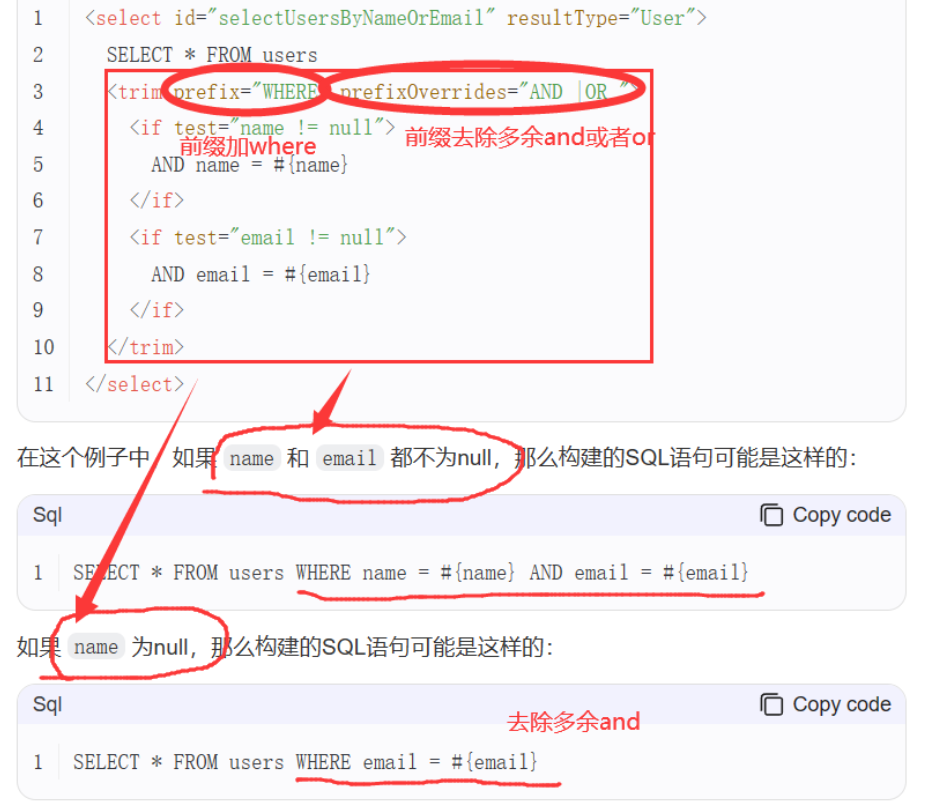

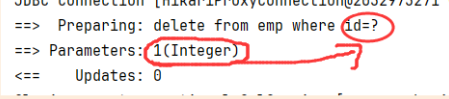
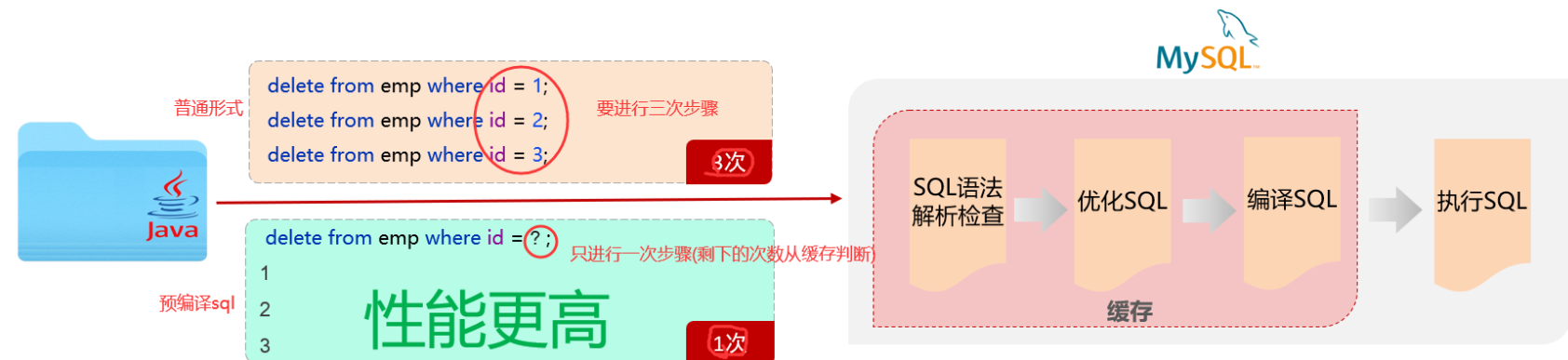
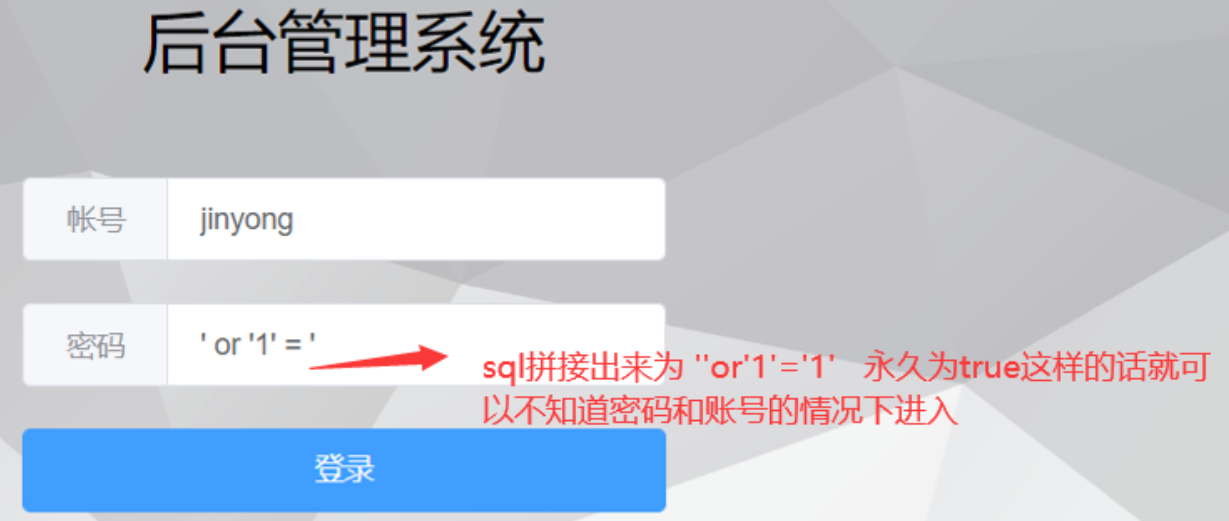


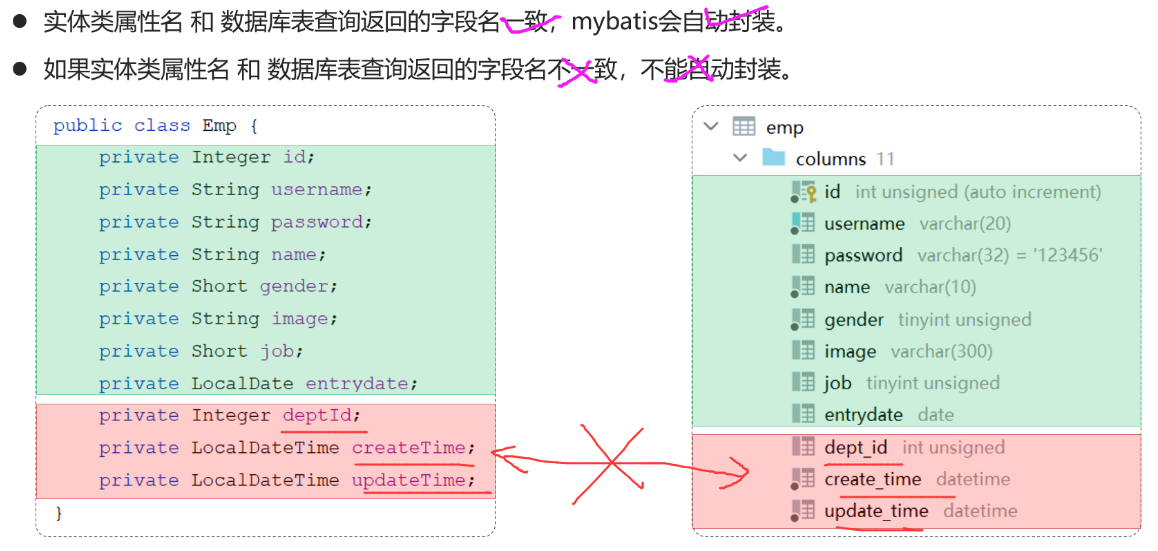
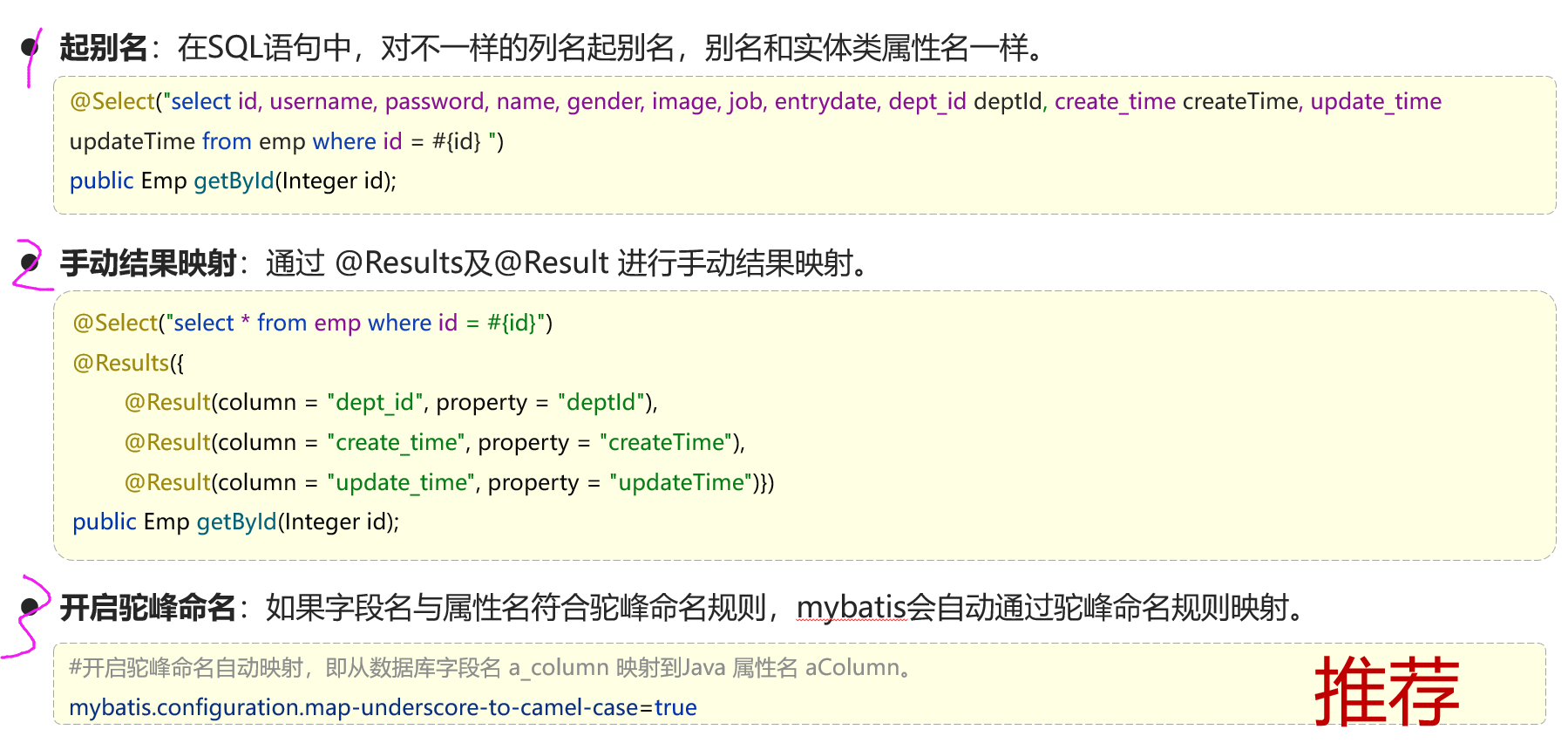



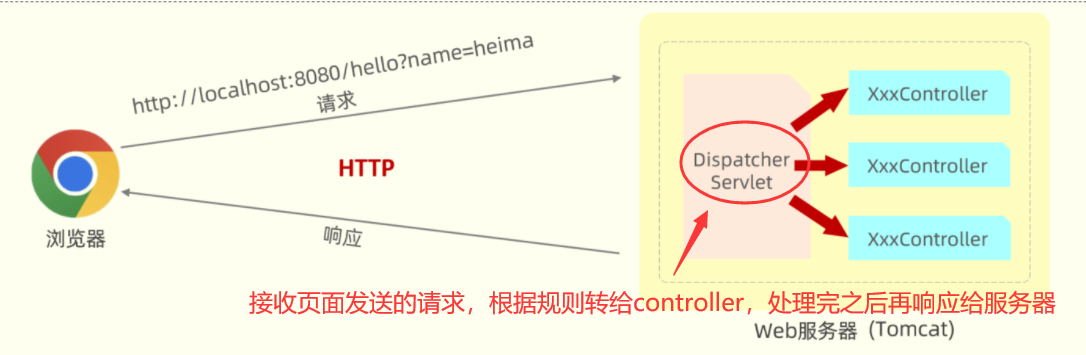
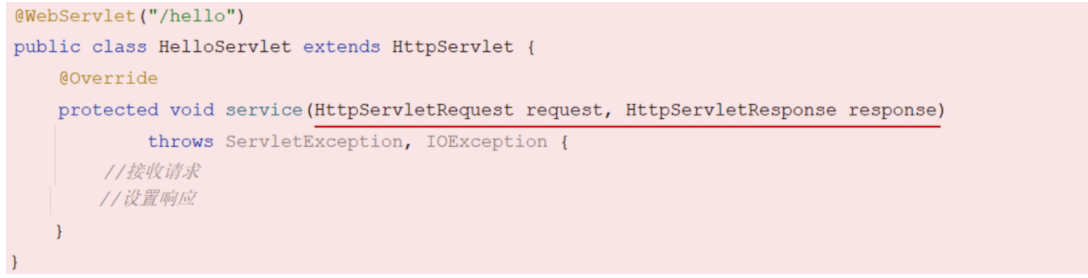

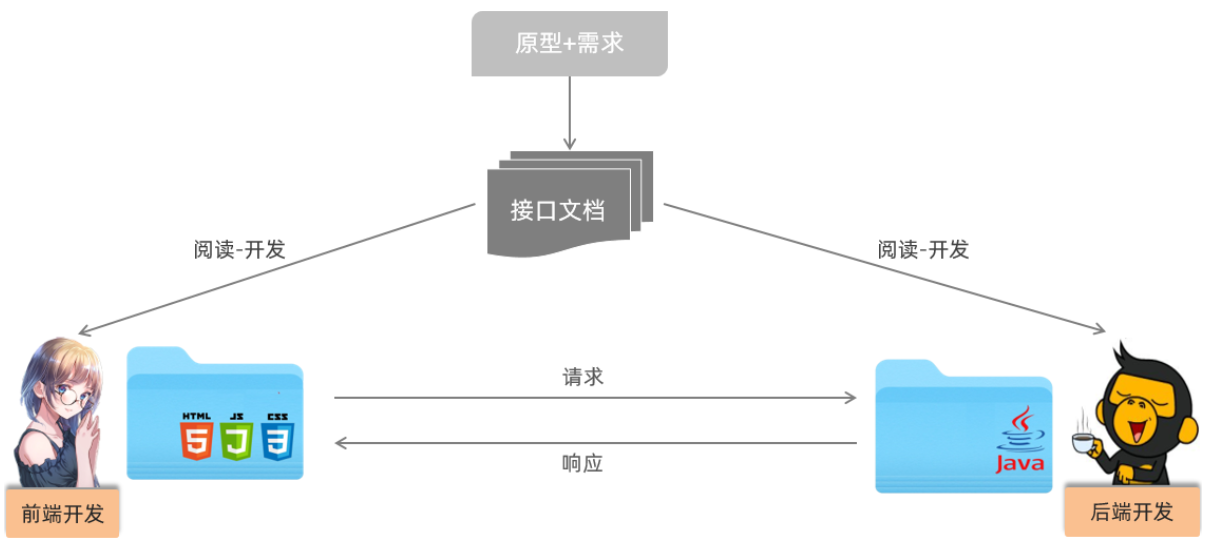

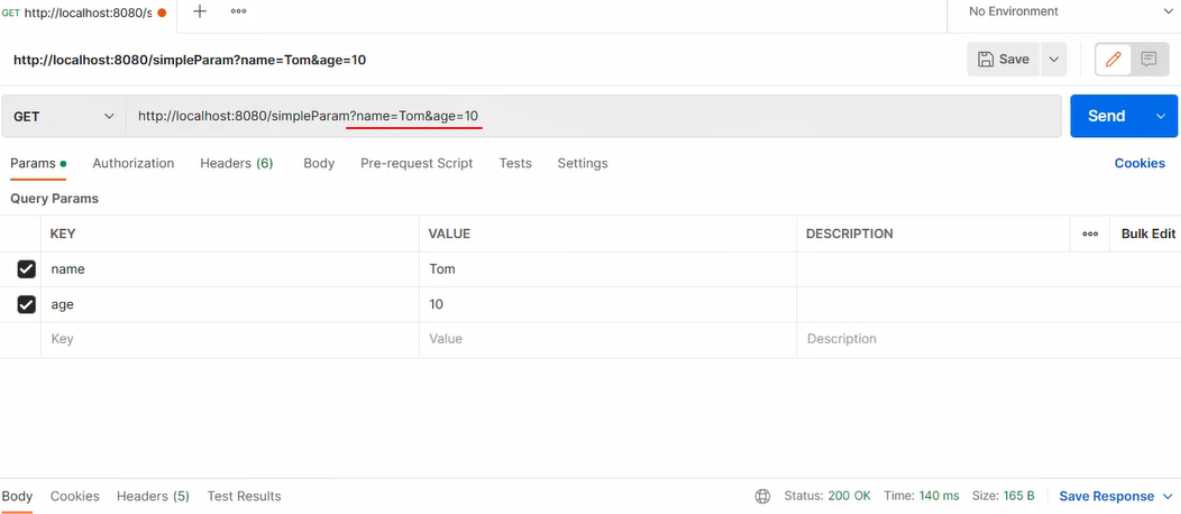
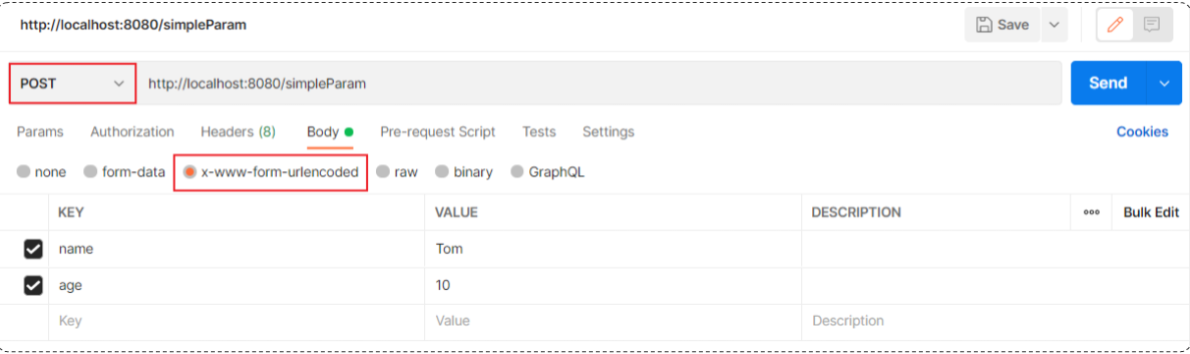
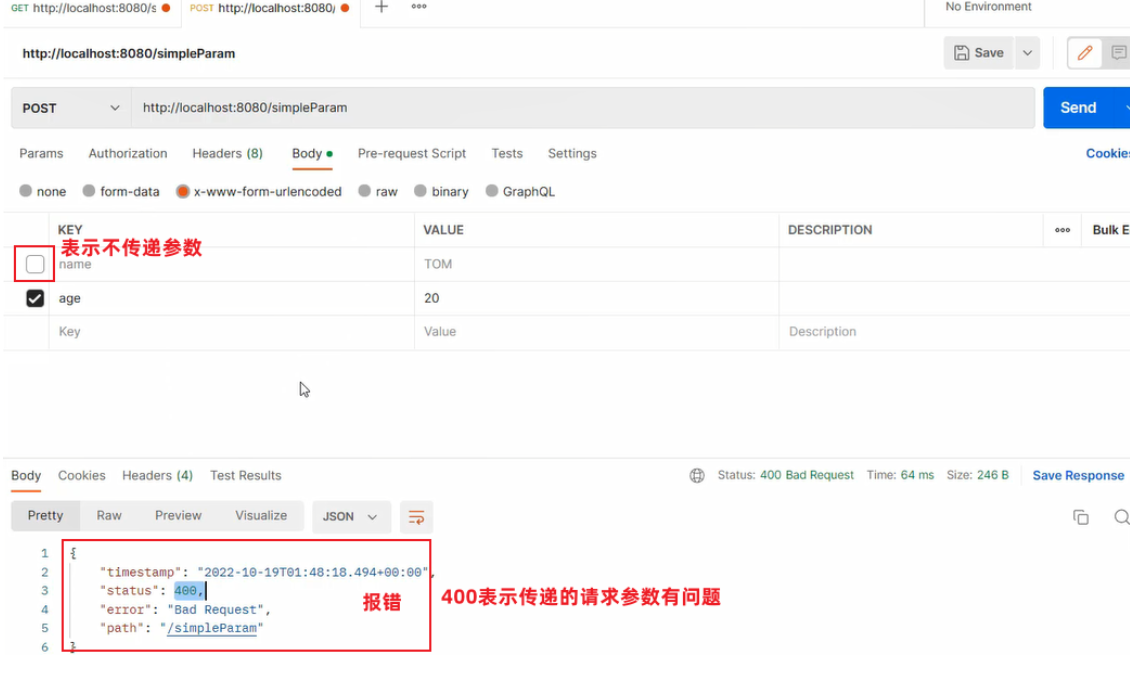
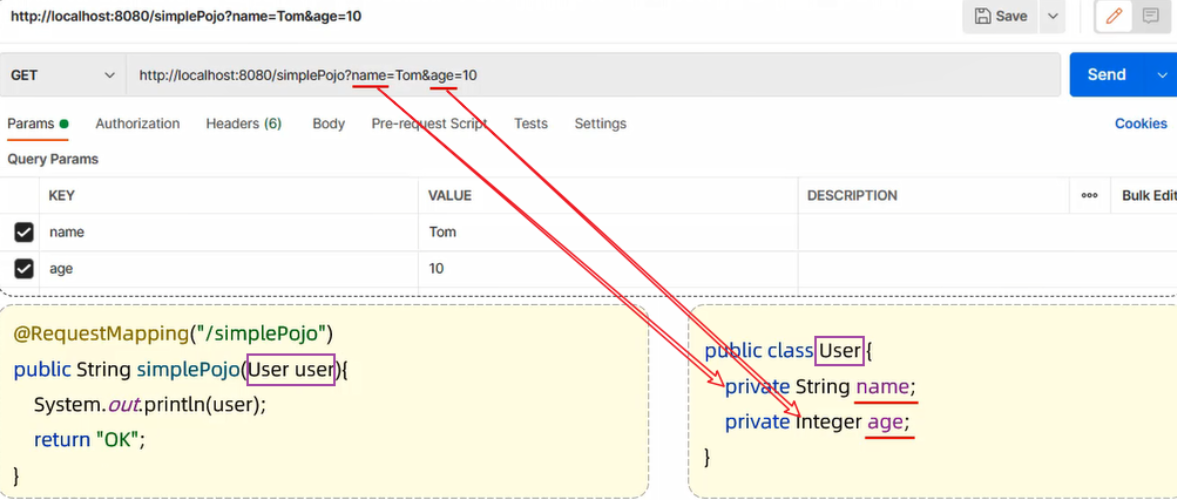
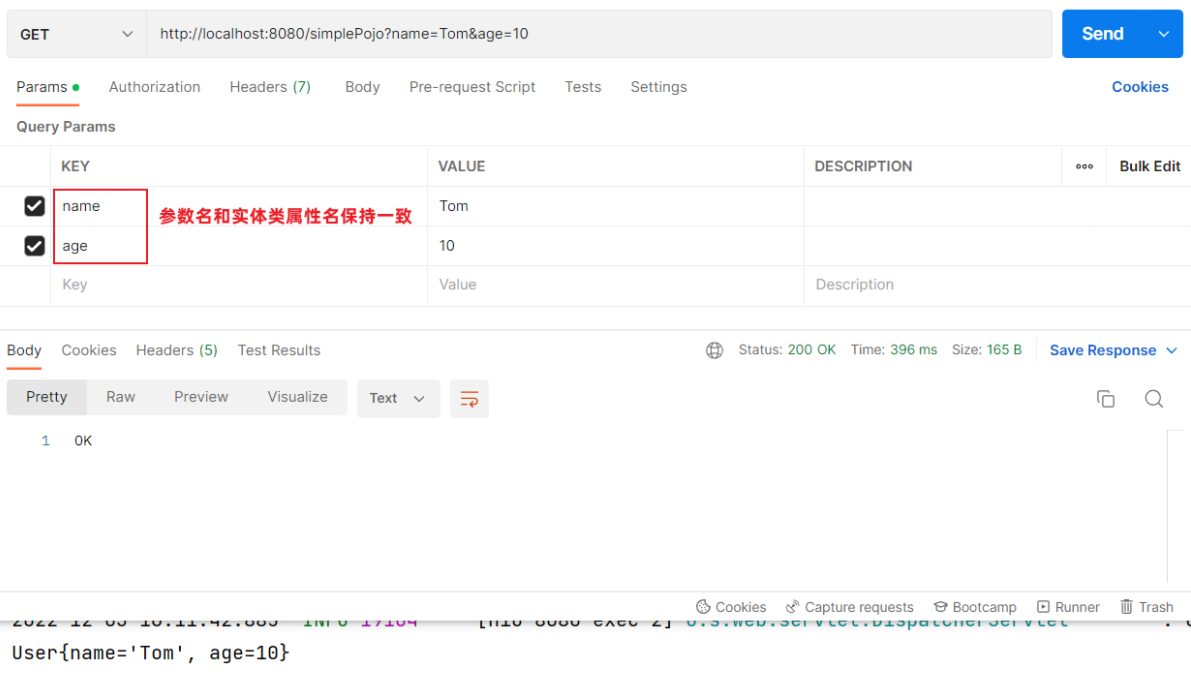
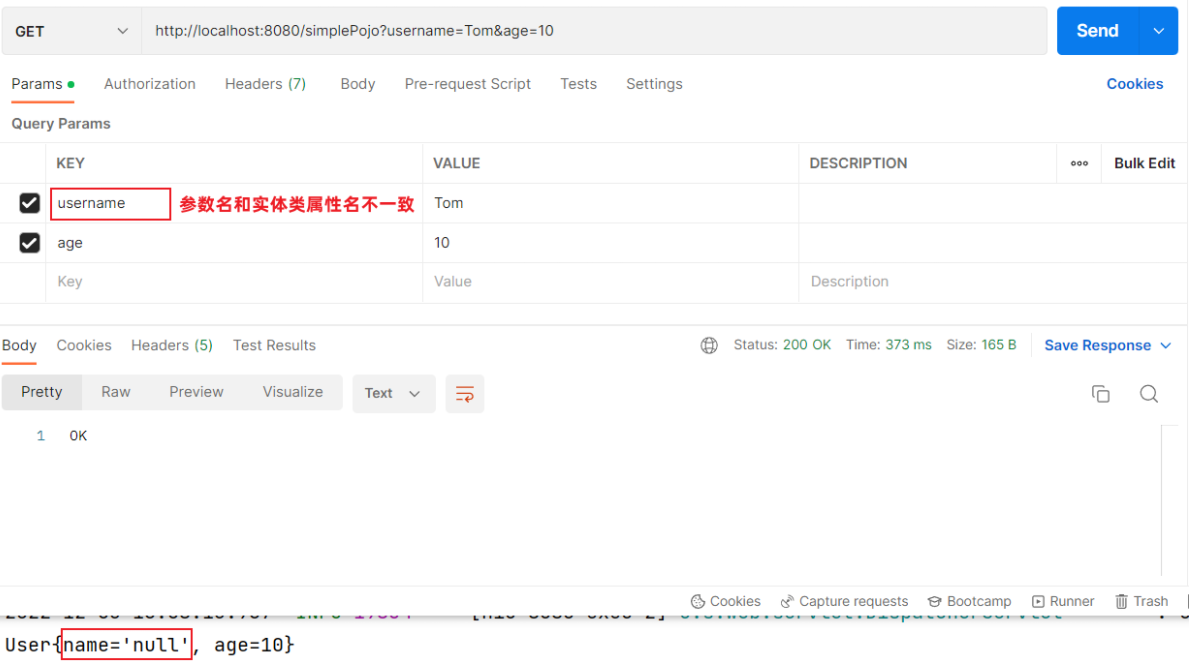
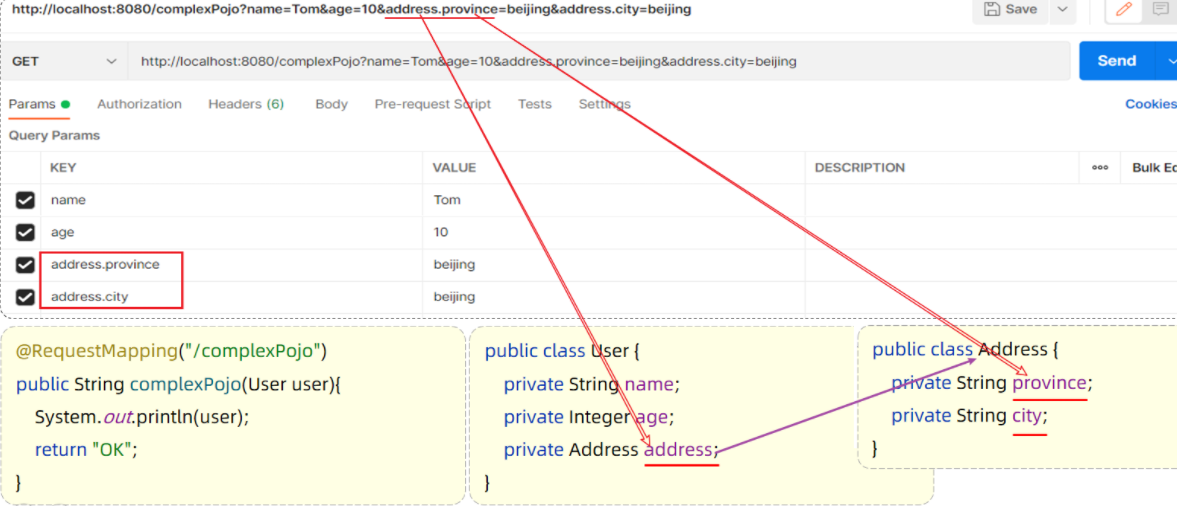
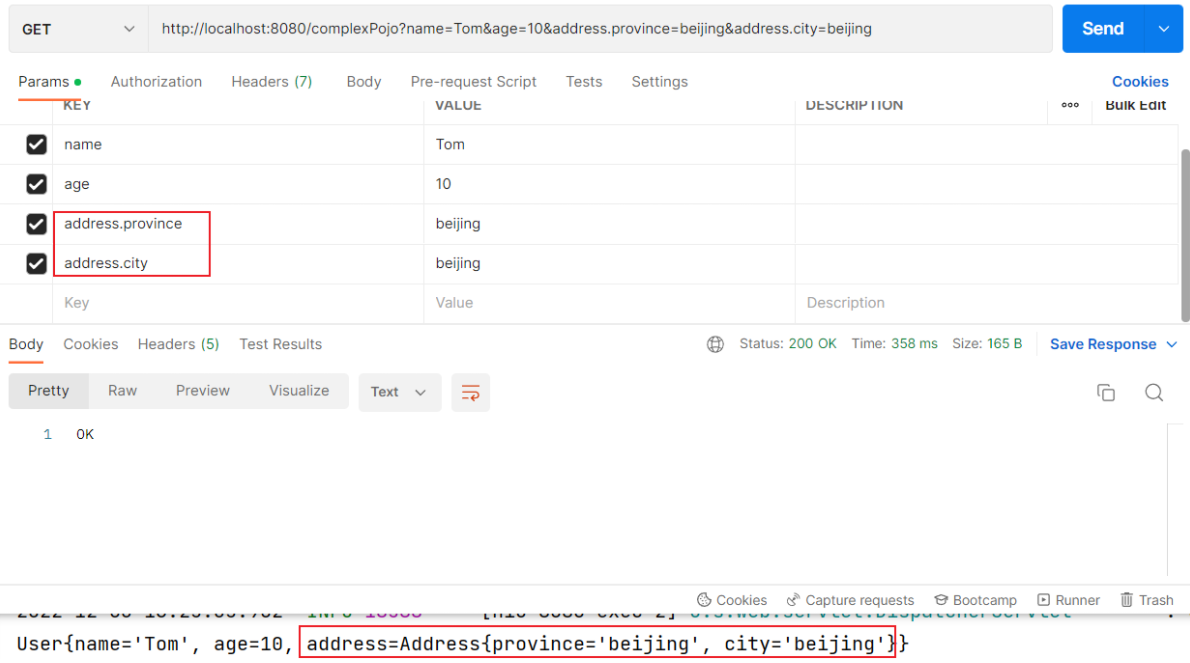
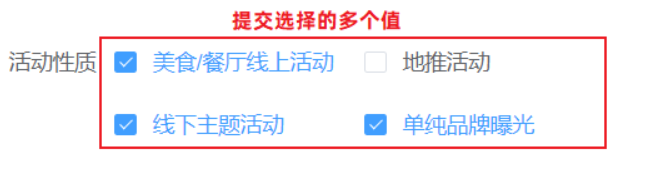

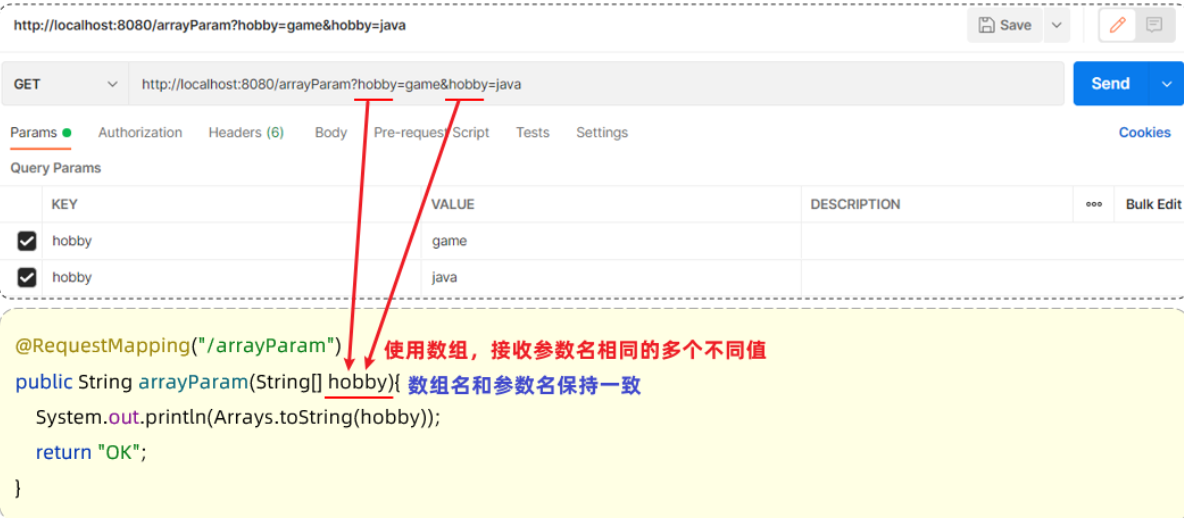
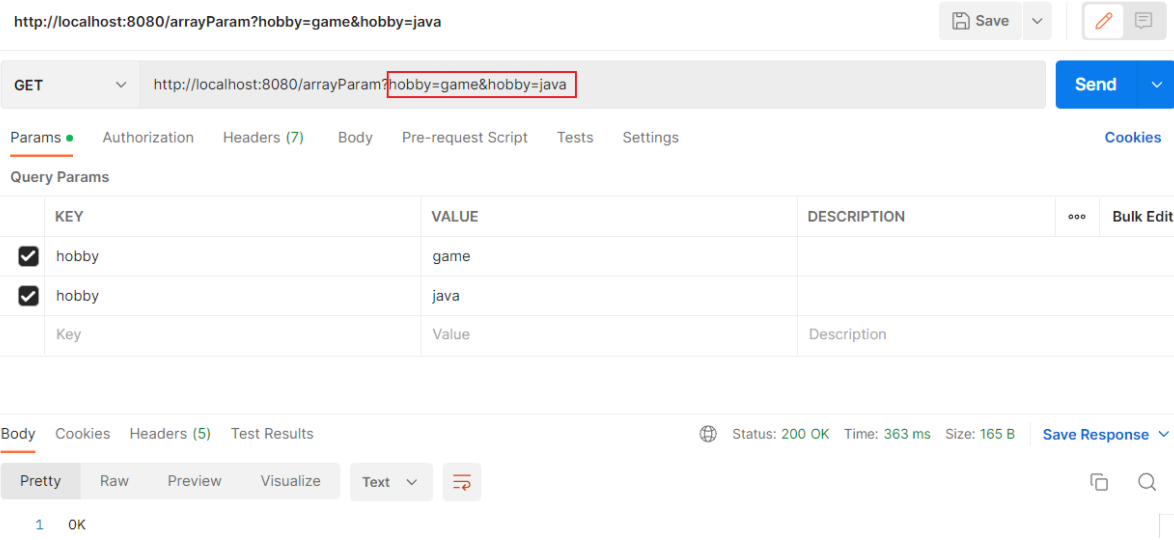
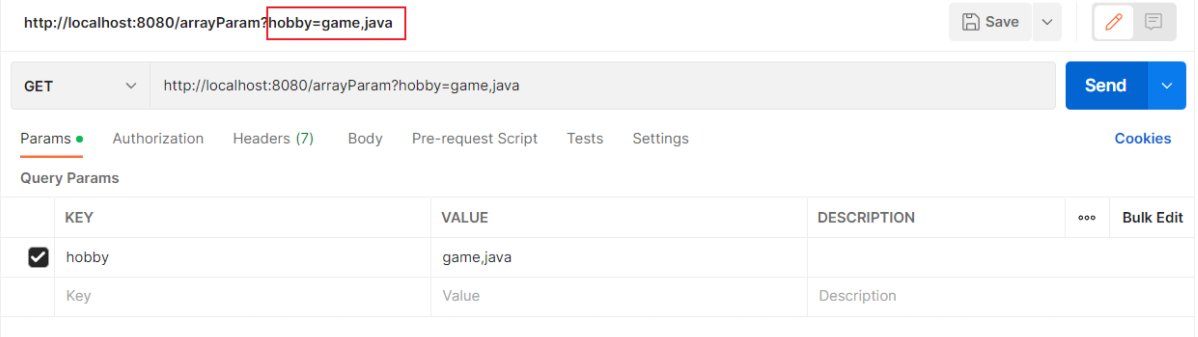
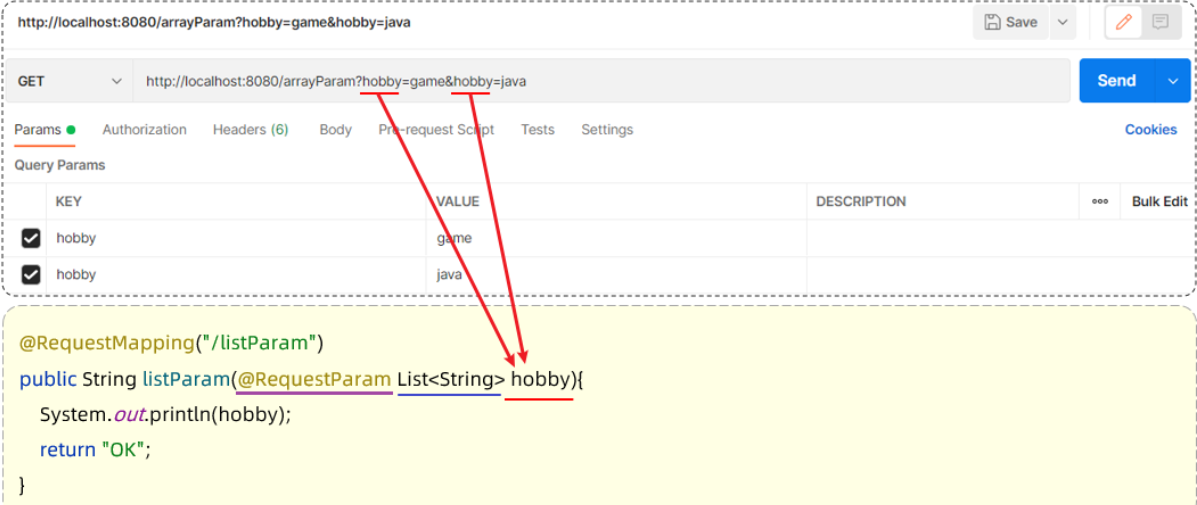

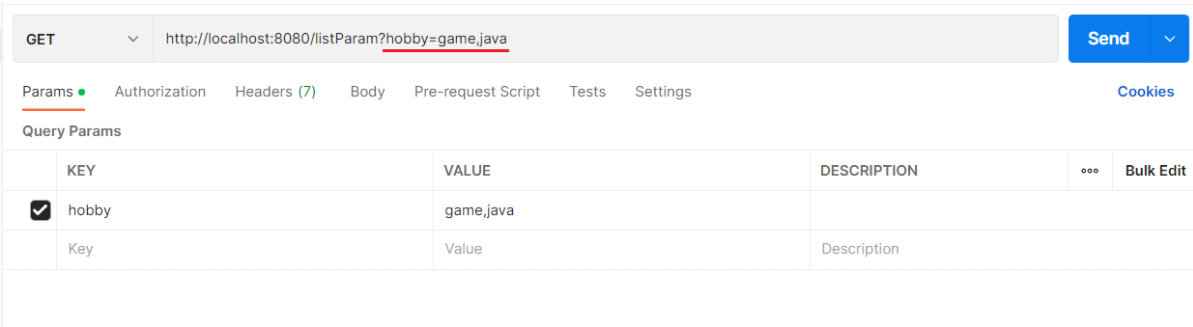

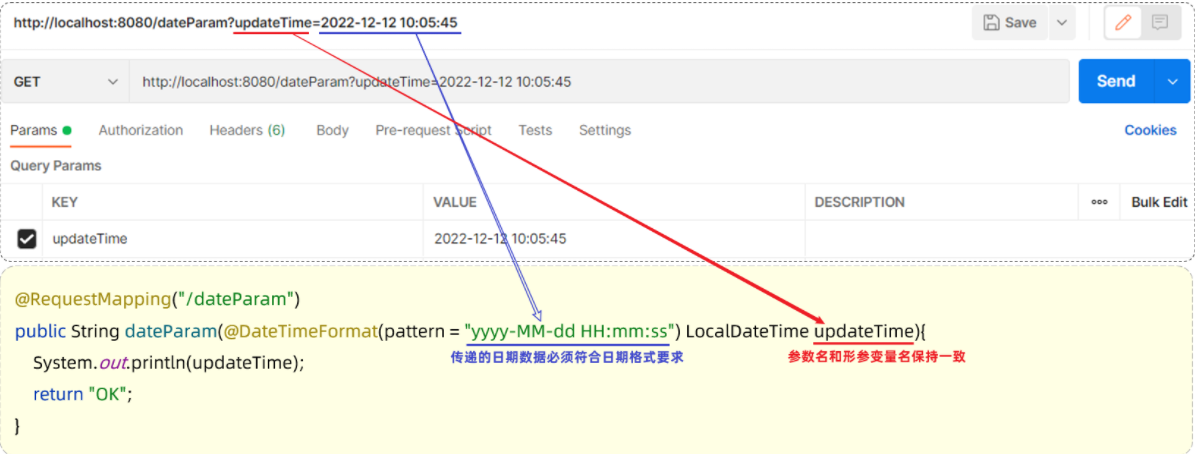

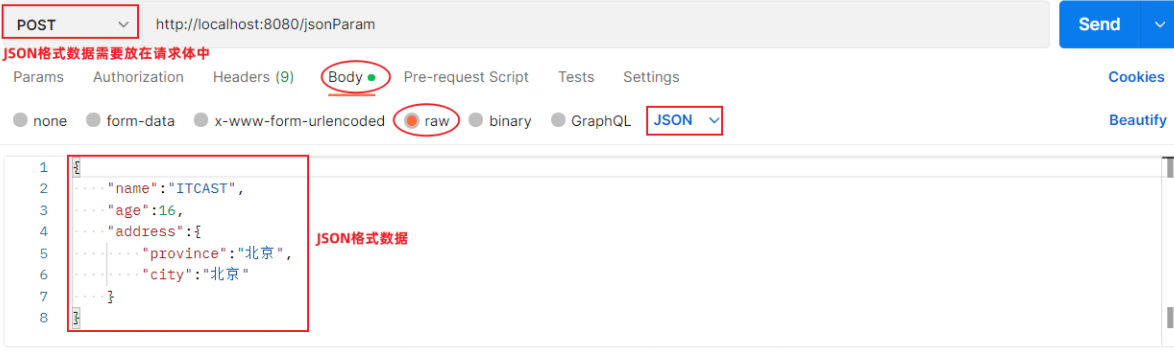
 @RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)
@RequestBody注解:将JSON数据映射到形参的实体类对象中(JSON中的key和实体类中的属性名保持一致)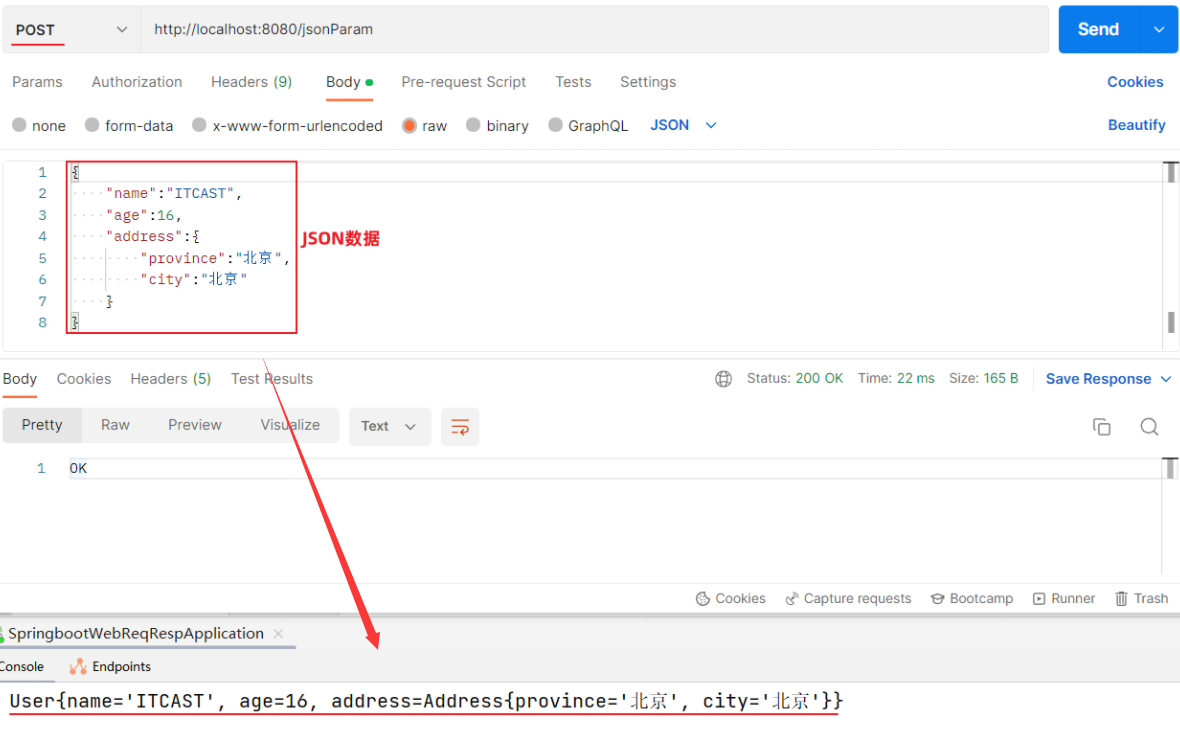










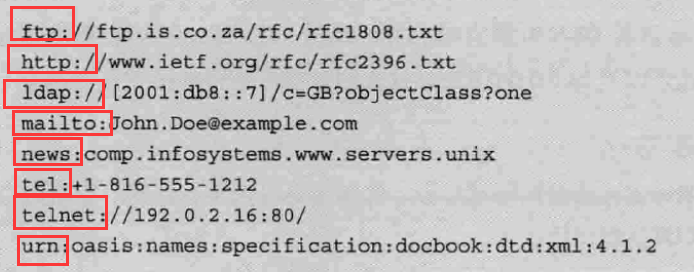

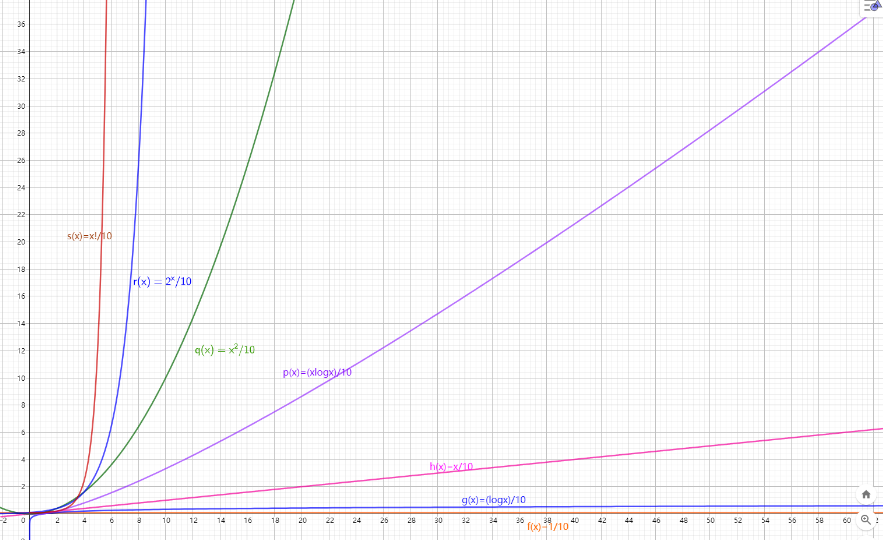






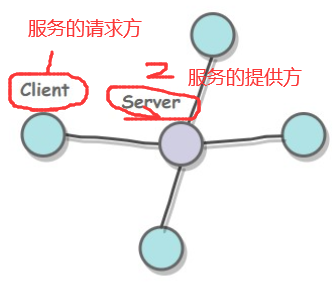
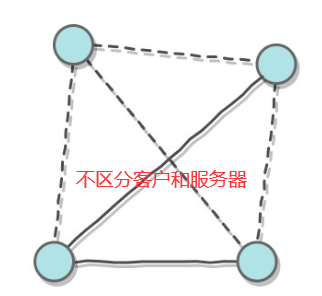
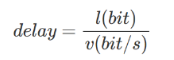 ,其中l代表数据帧长度,v代表传输速率
,其中l代表数据帧长度,v代表传输速率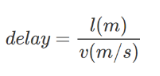 ,其中l代表信道长度,v代表电磁波在信道上传播速度
,其中l代表信道长度,v代表电磁波在信道上传播速度