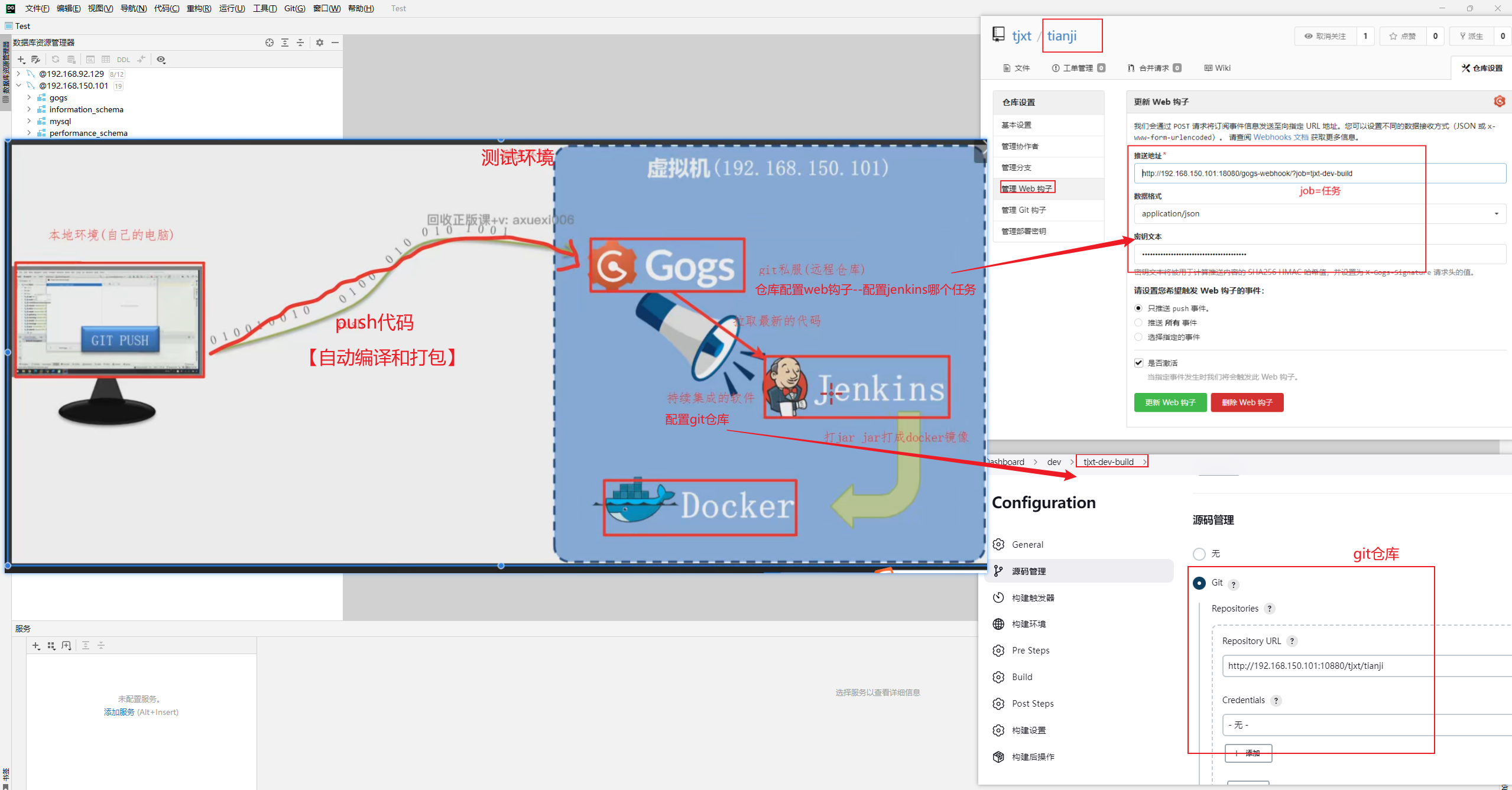
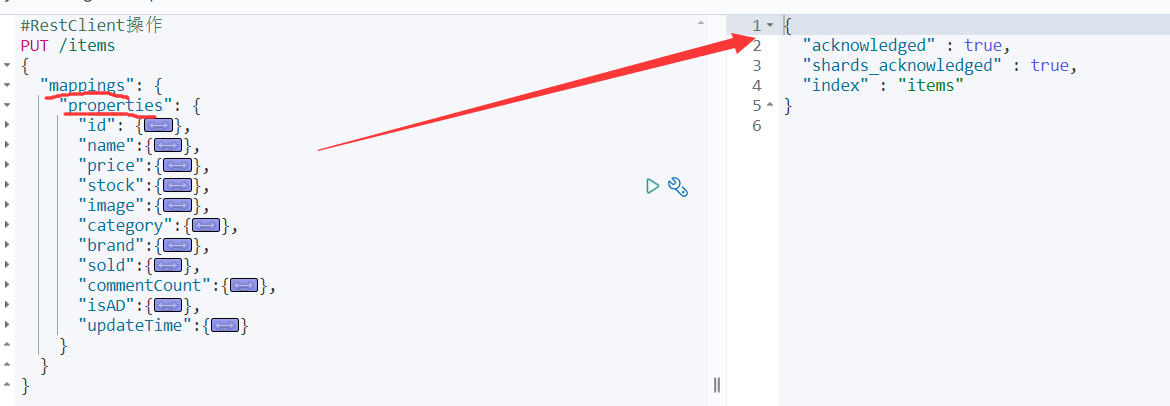
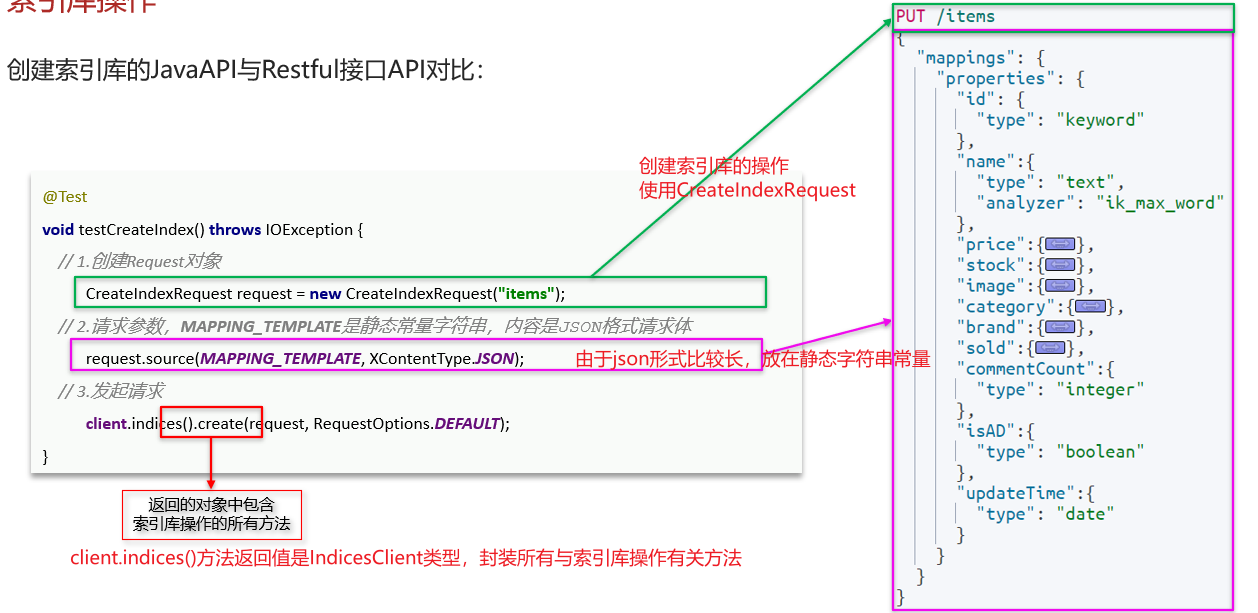
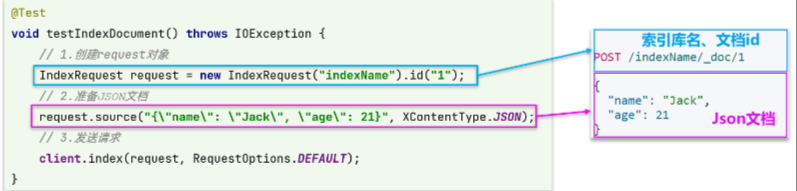
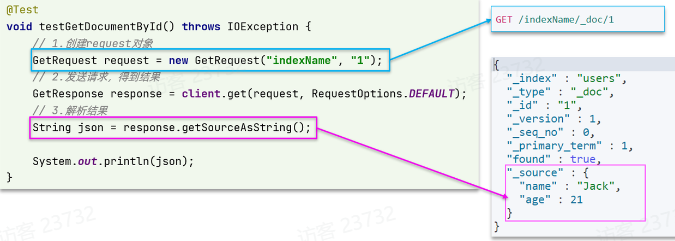
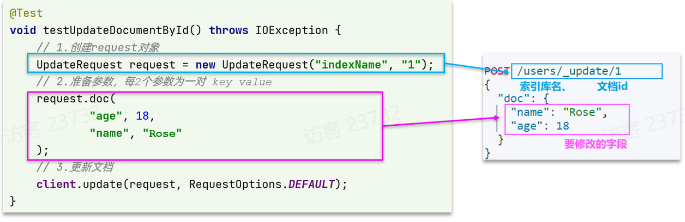
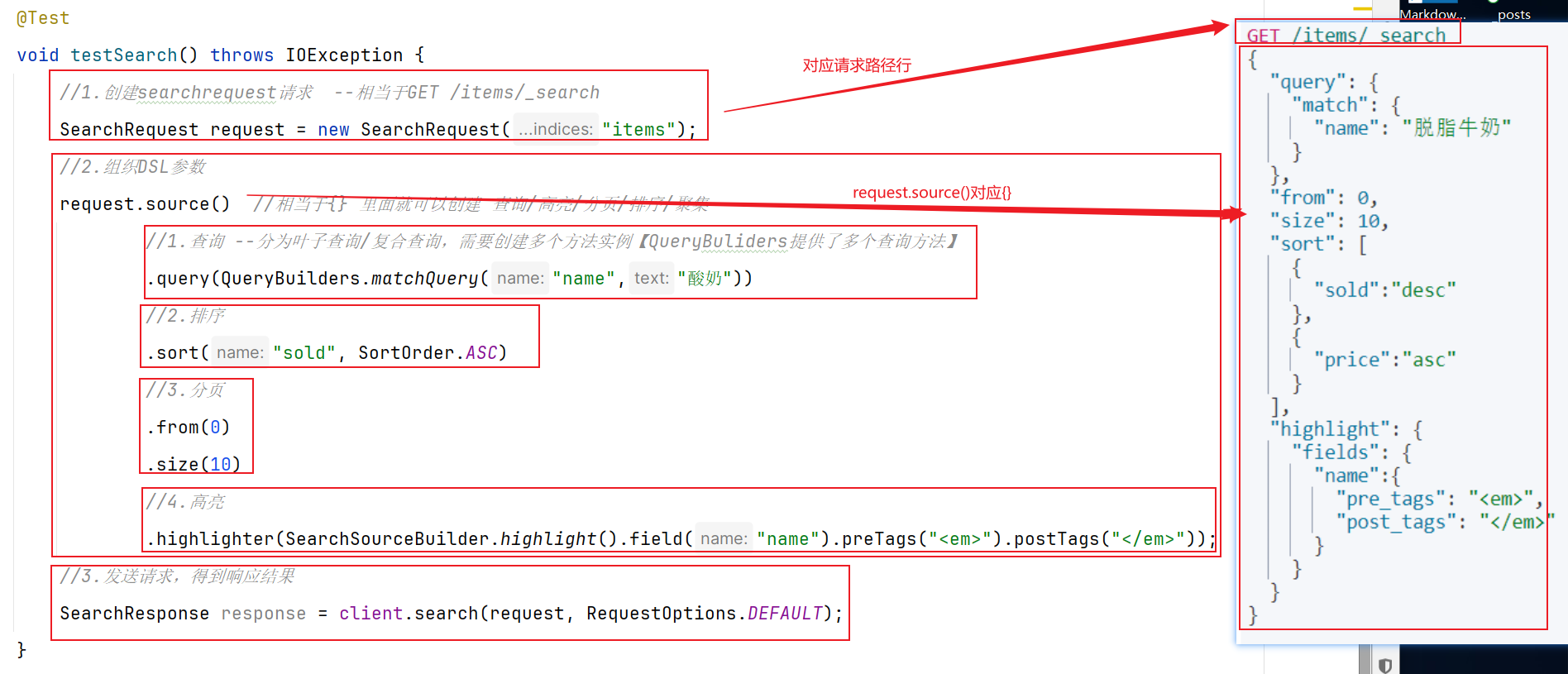
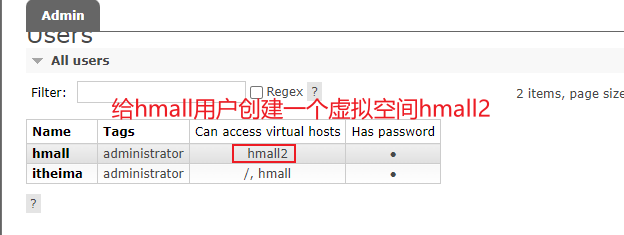
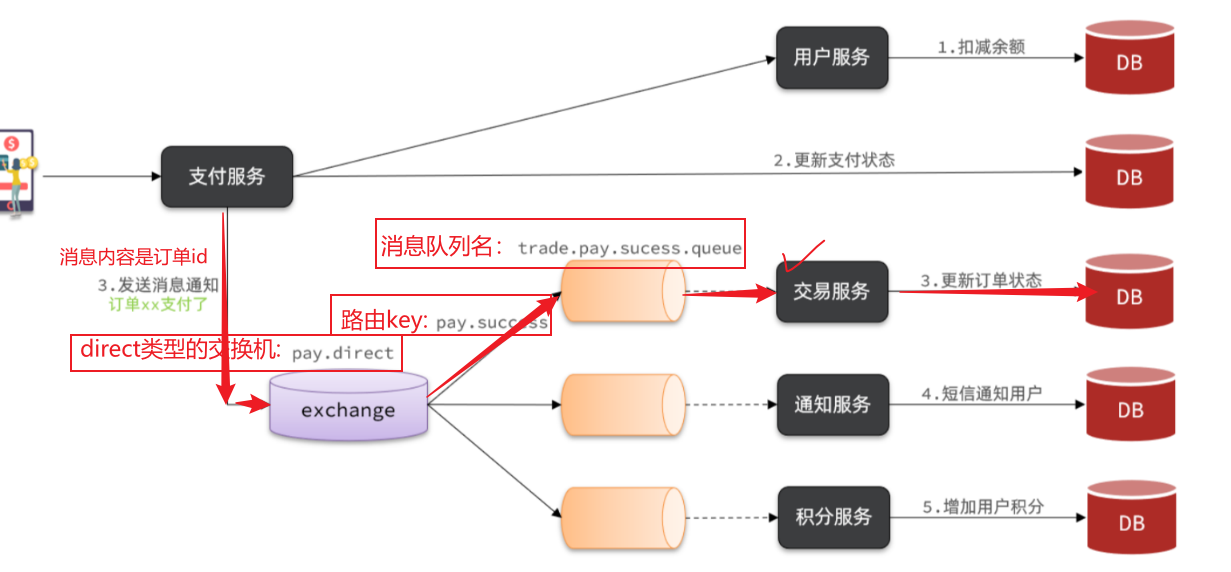
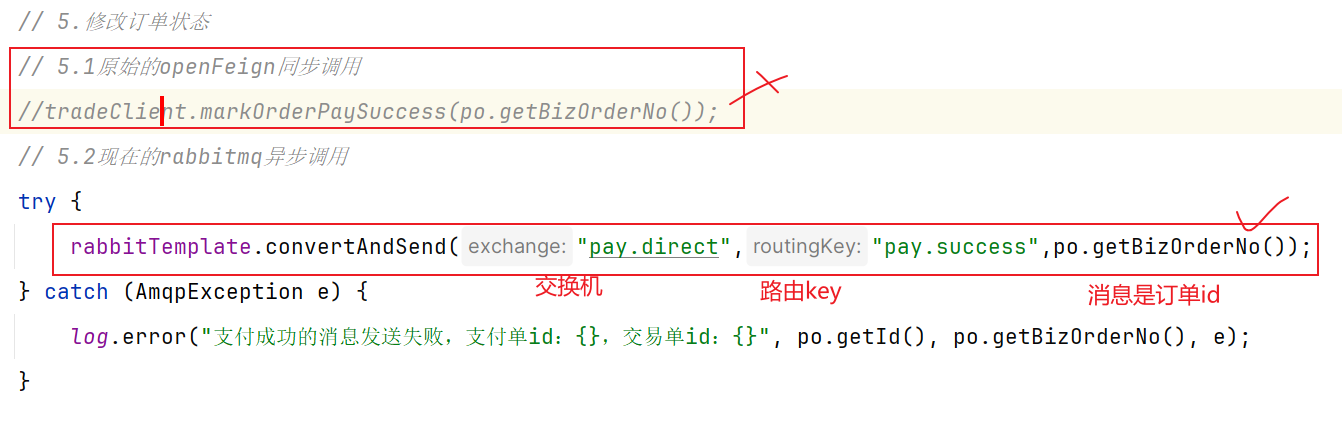
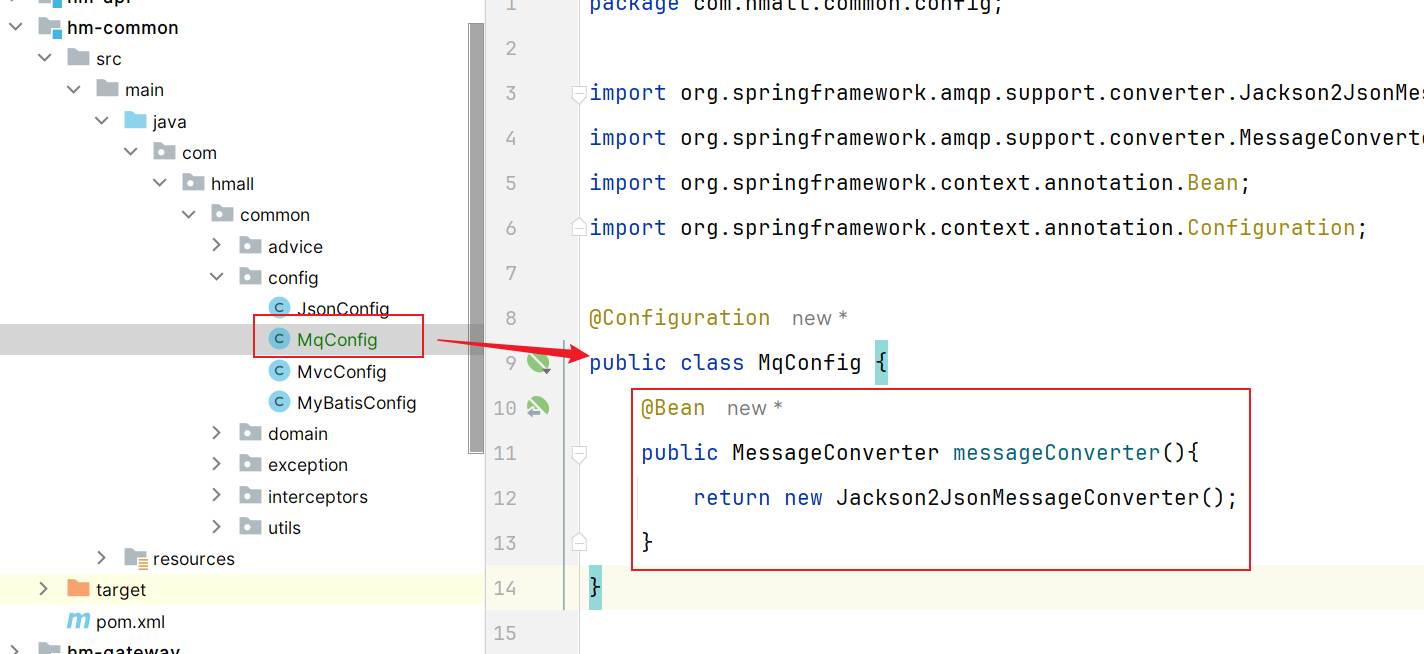
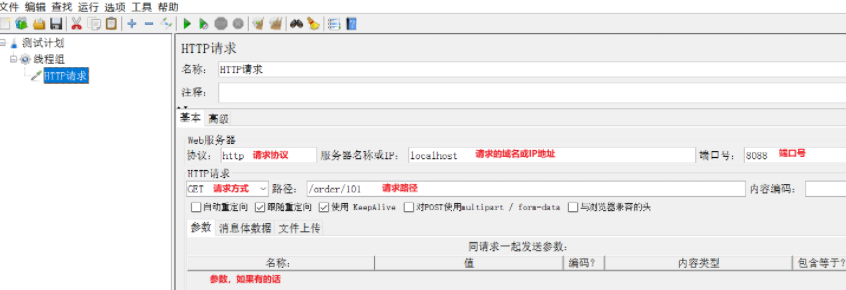
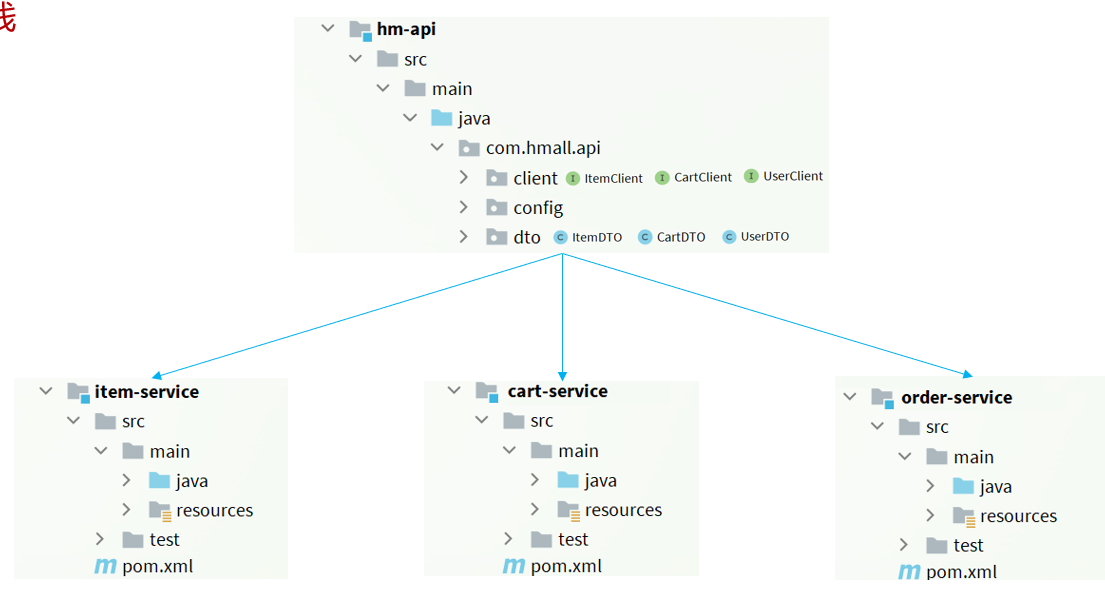
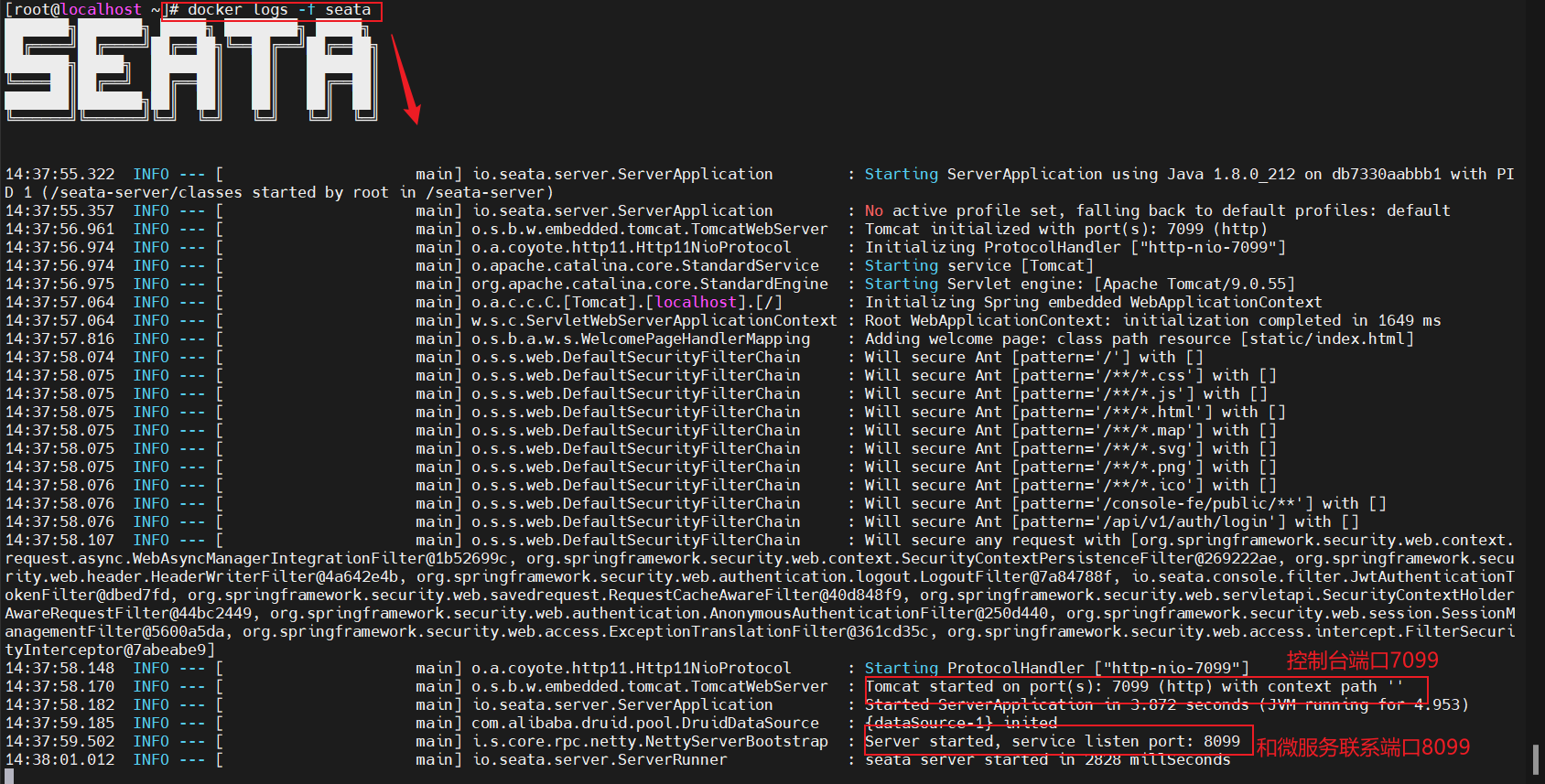
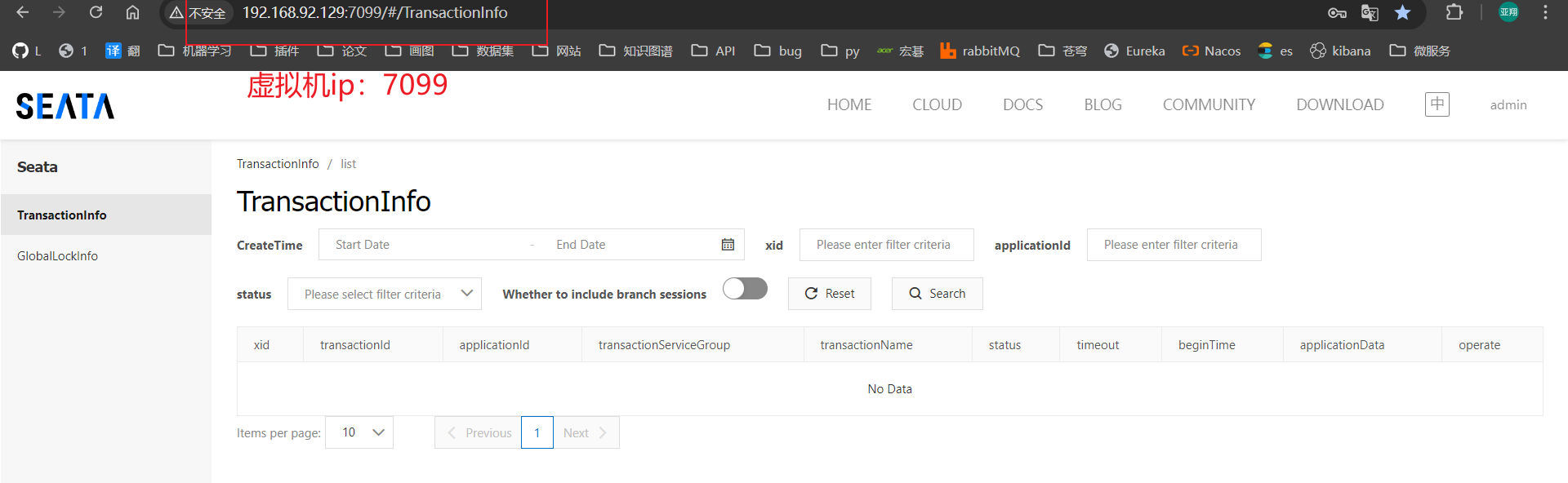
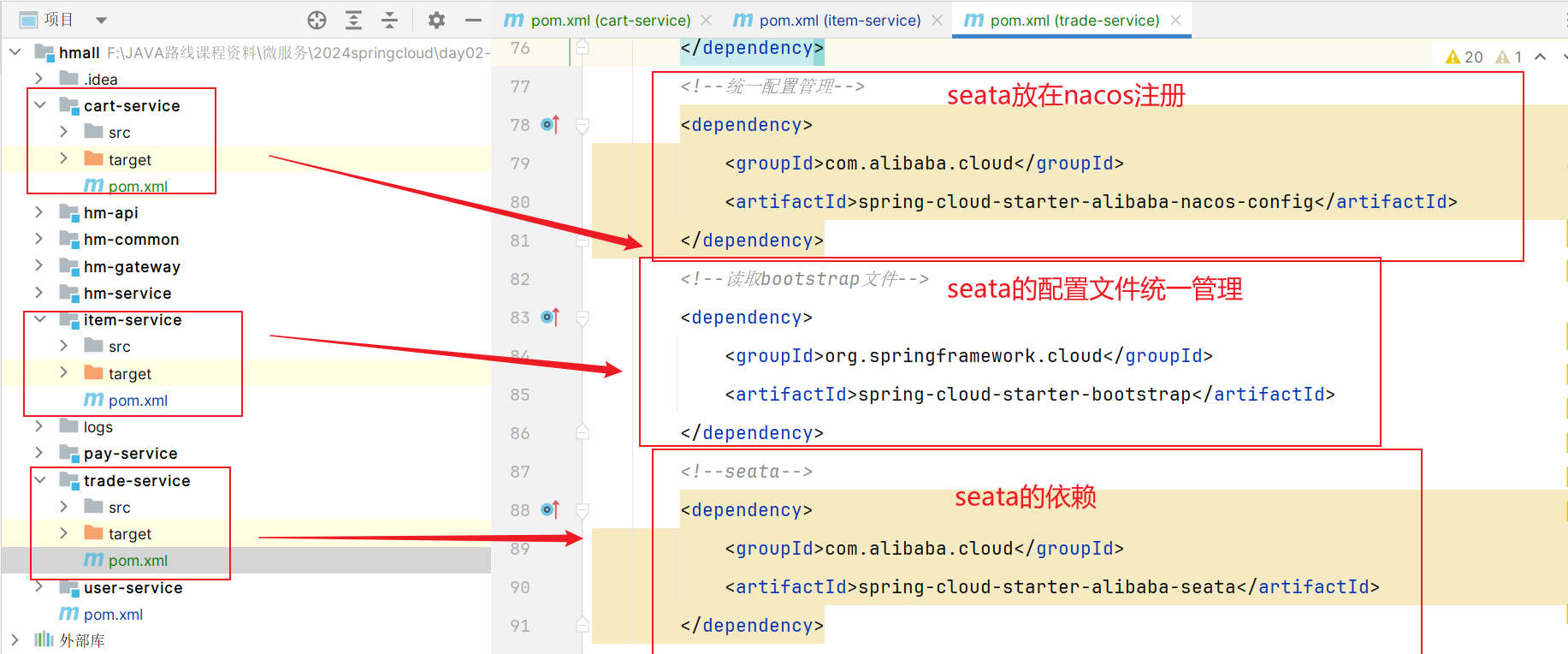
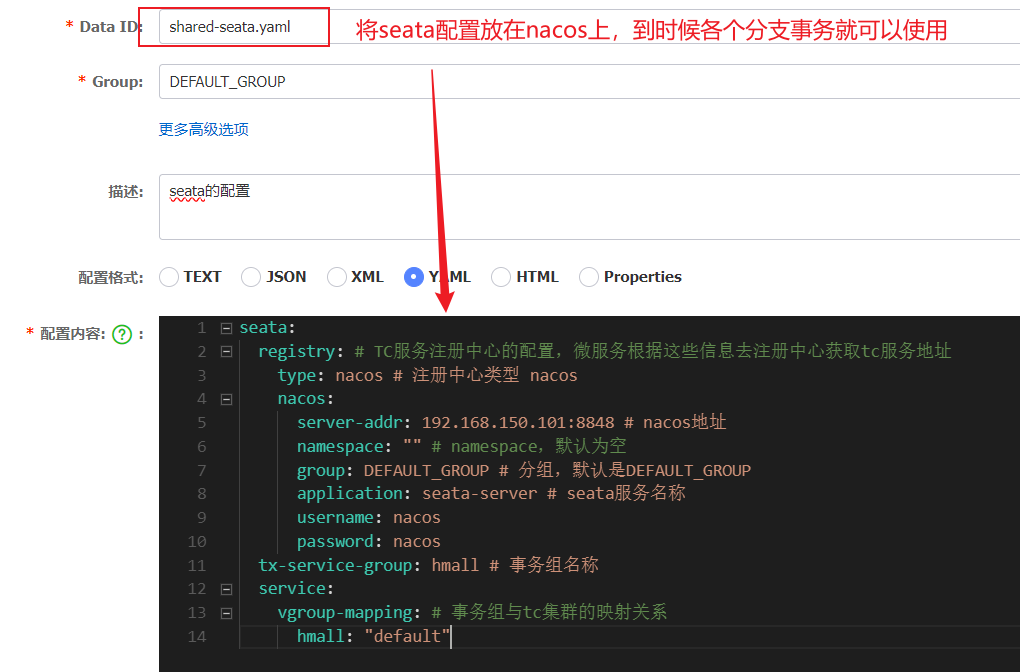
前提:我们以单体架构的黑马商城为例
代码结构如下:
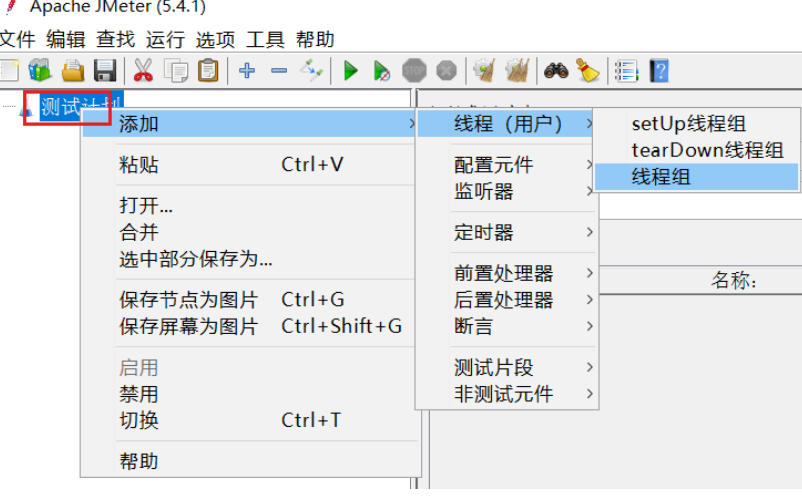
==服务拆分–各个模块各司其职== 1.微服务拆分 拆分工程结构有两种:
1.独立project:总黑马商城设置一个空项目(各个模块都在这个目录下) –不怎么美观和使用
2.Maven聚合:总黑马商城设置一个空项目(各个模块成为一个module模块,根据maven管理) –只是代码放一起但是各自可以打包开发编译
我们以第二种Maven聚合方式进行拆分
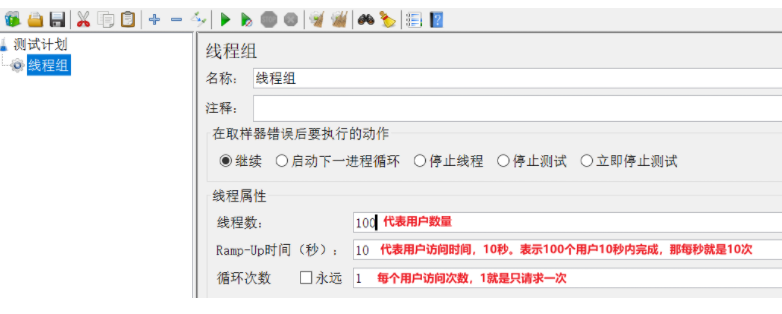
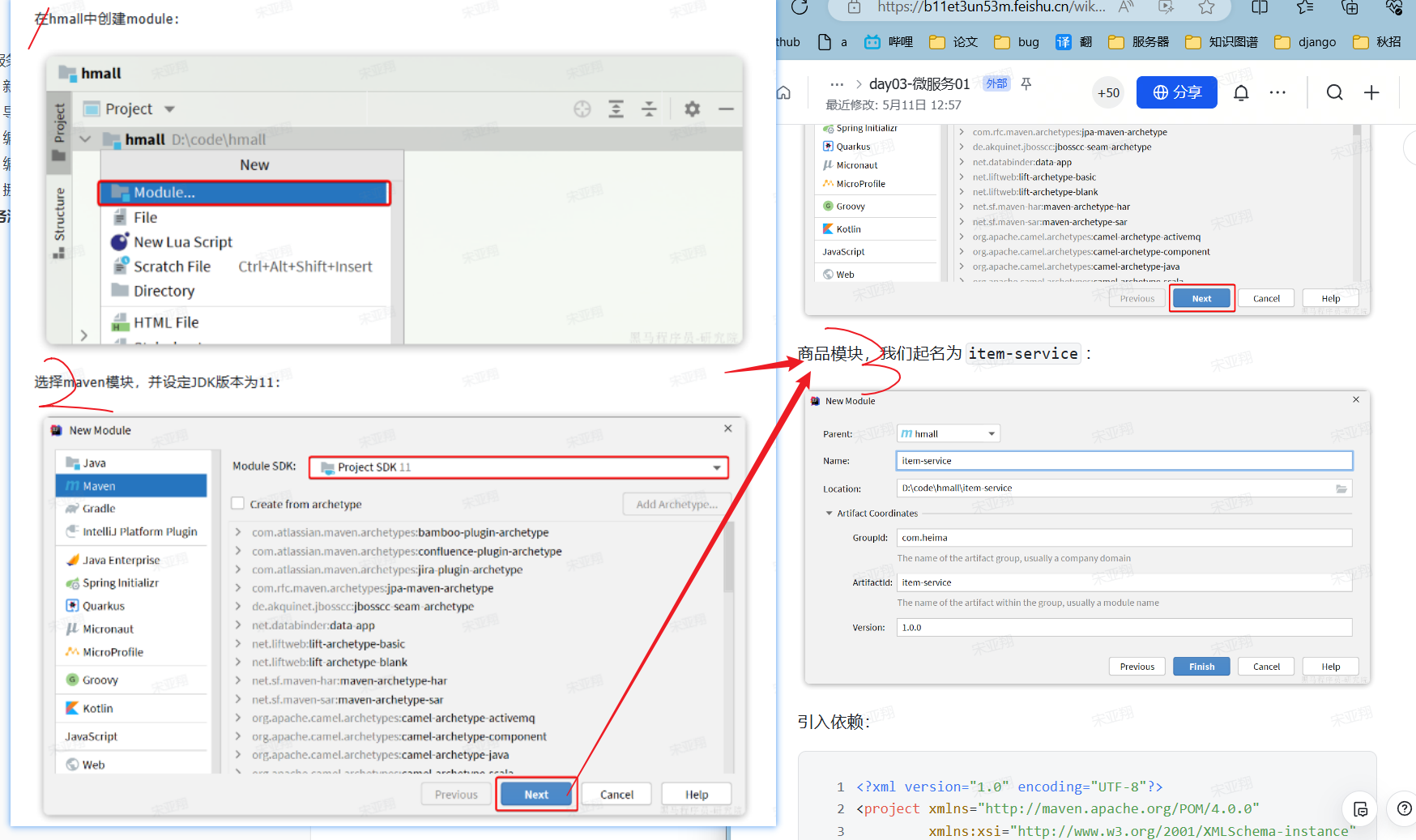
1.1 新建项目
1.2 导入依赖 直接从hm-service中导入,然后删除一些不需要的依赖
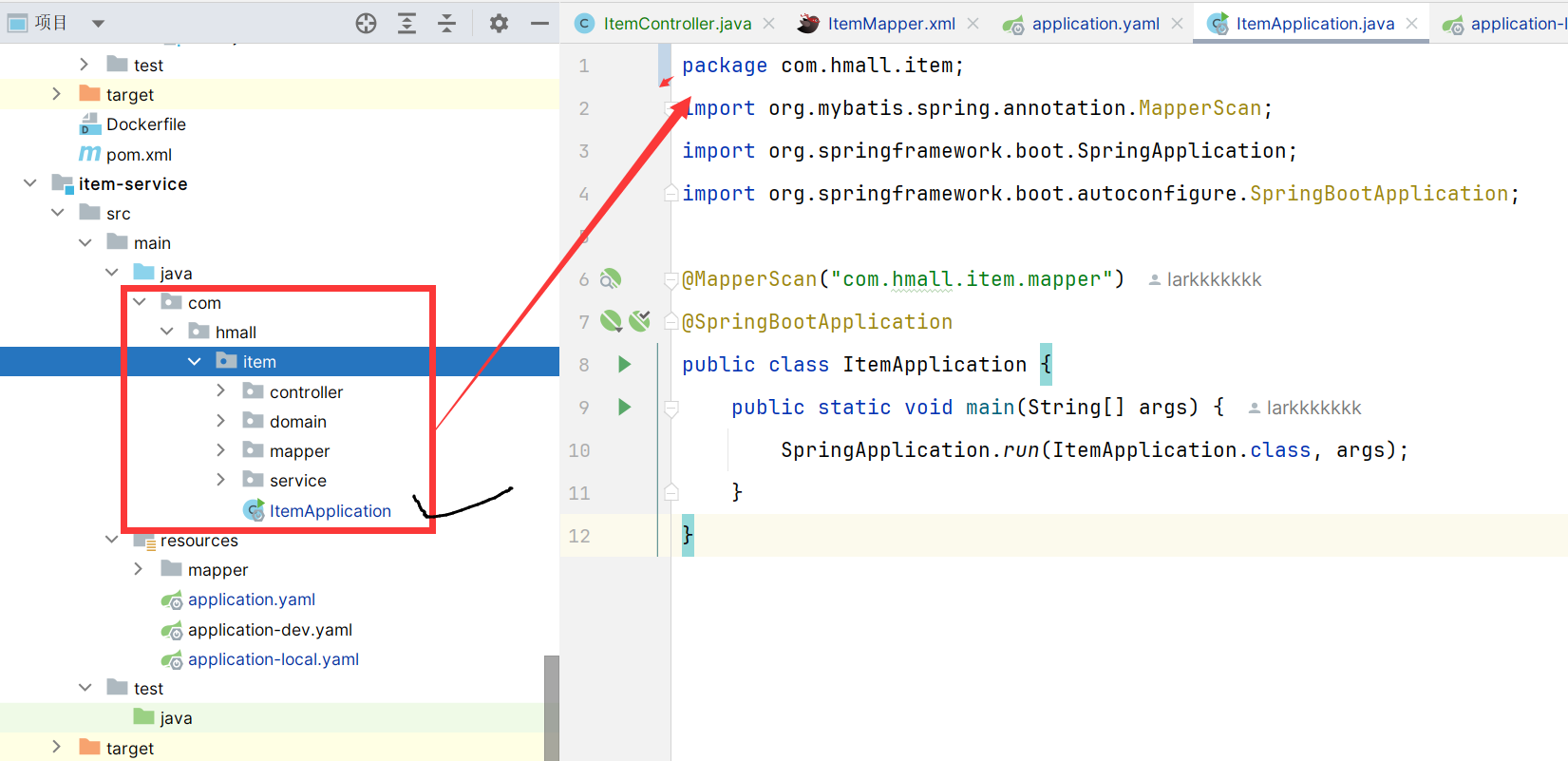
1.3 编写启动类 一定记得和其他包是同一级,不然他妈的扫描不到报bean冲突!!!!!
1.4 编写yml配置文件 直接从hm-service中导入,然后删除和修改一些配置
1.5 挪动代码 挪动步骤:
①domain实体,
②mapper数据库打交道的,
③service和serviceimpl,
④controller
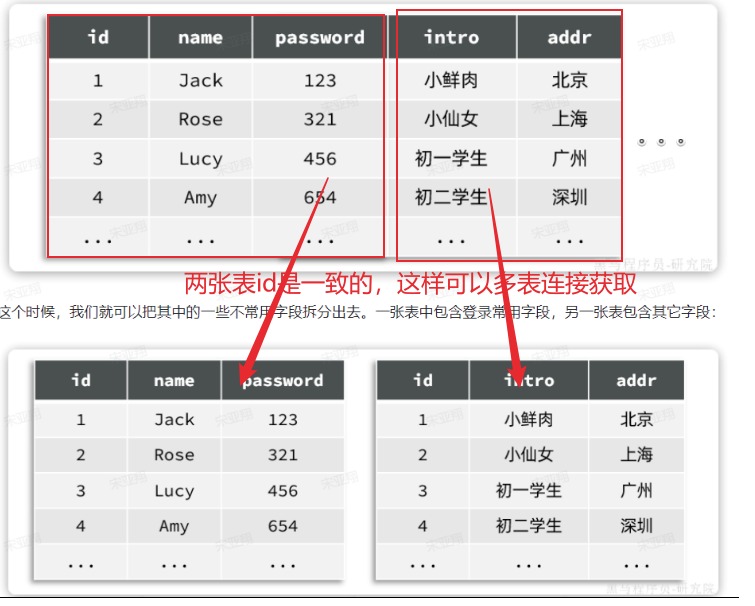
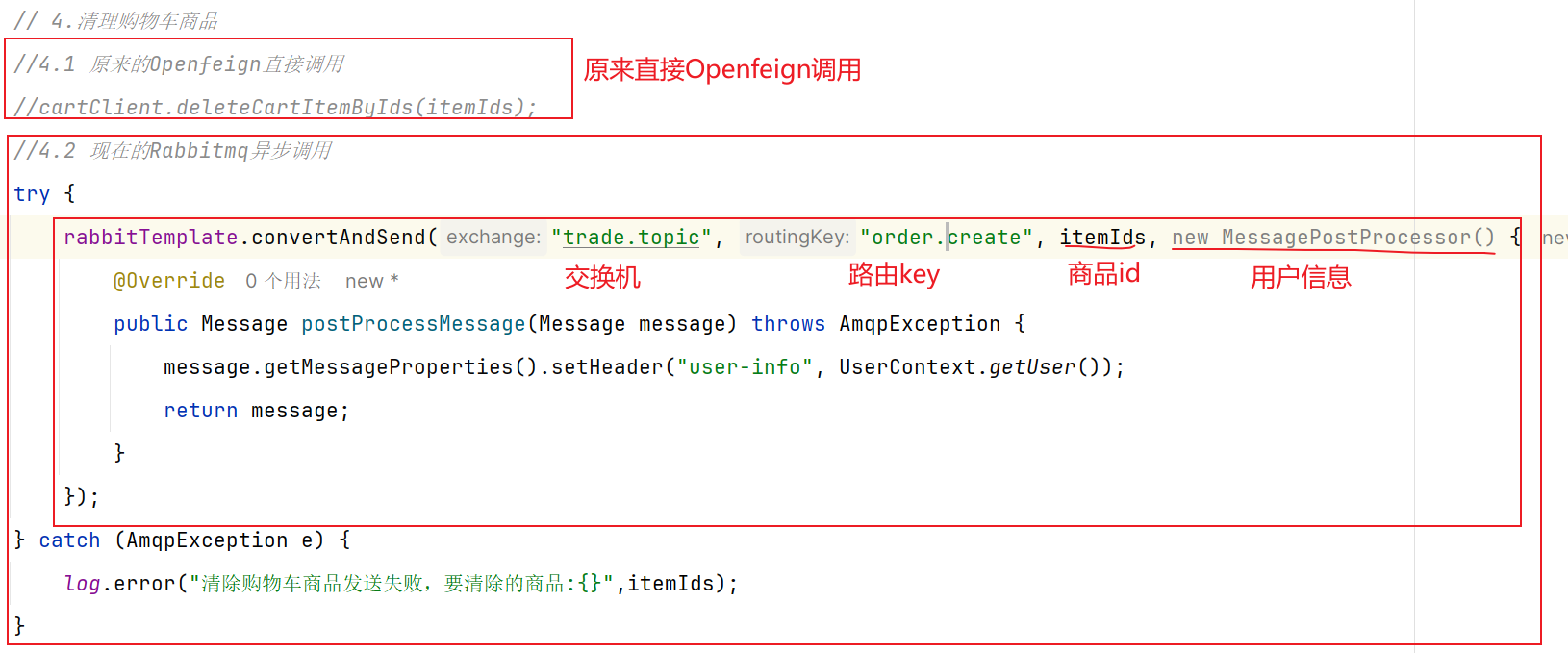
==在这一步拆分多个子项目之后,我们可能会发现cart购物车服务会调用查询item商品服务,之前我们可以在一个模块中直接调用mapper,但是分开之后只能发送请求访问==
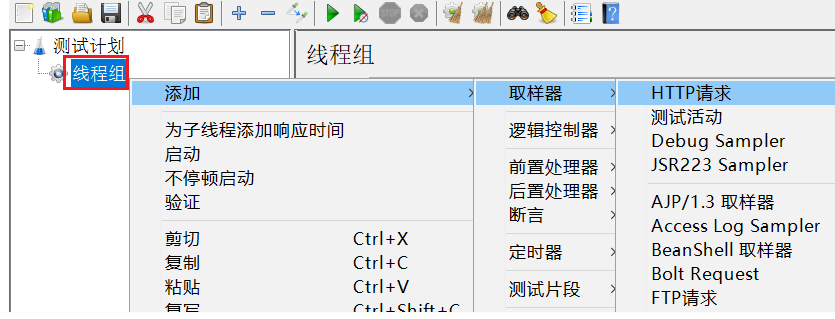
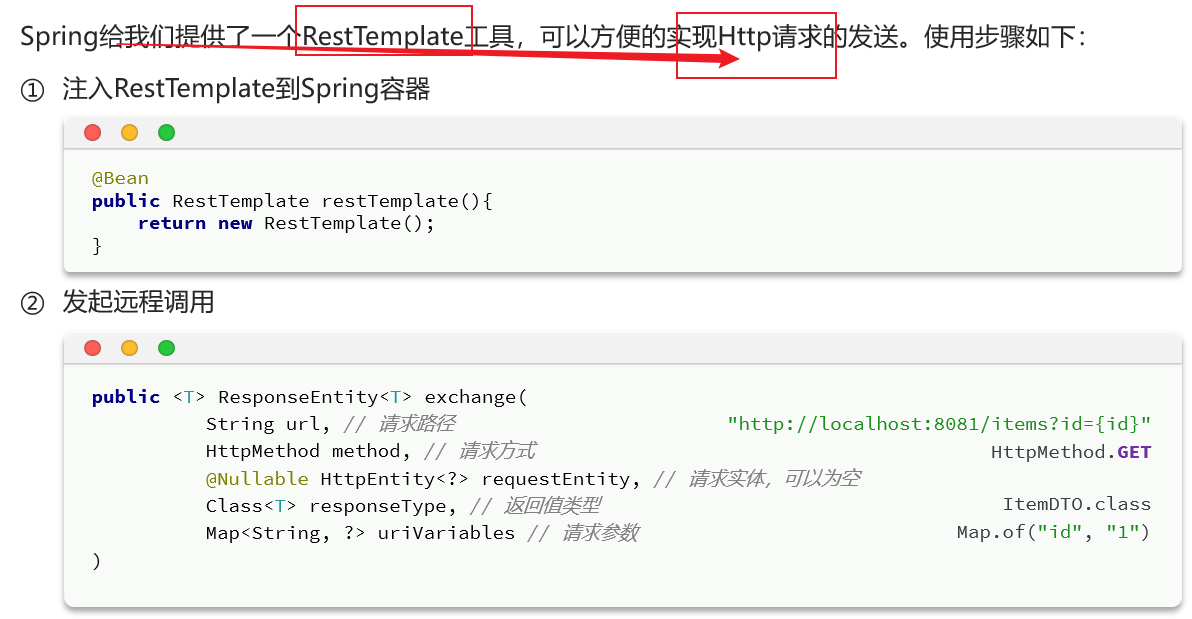
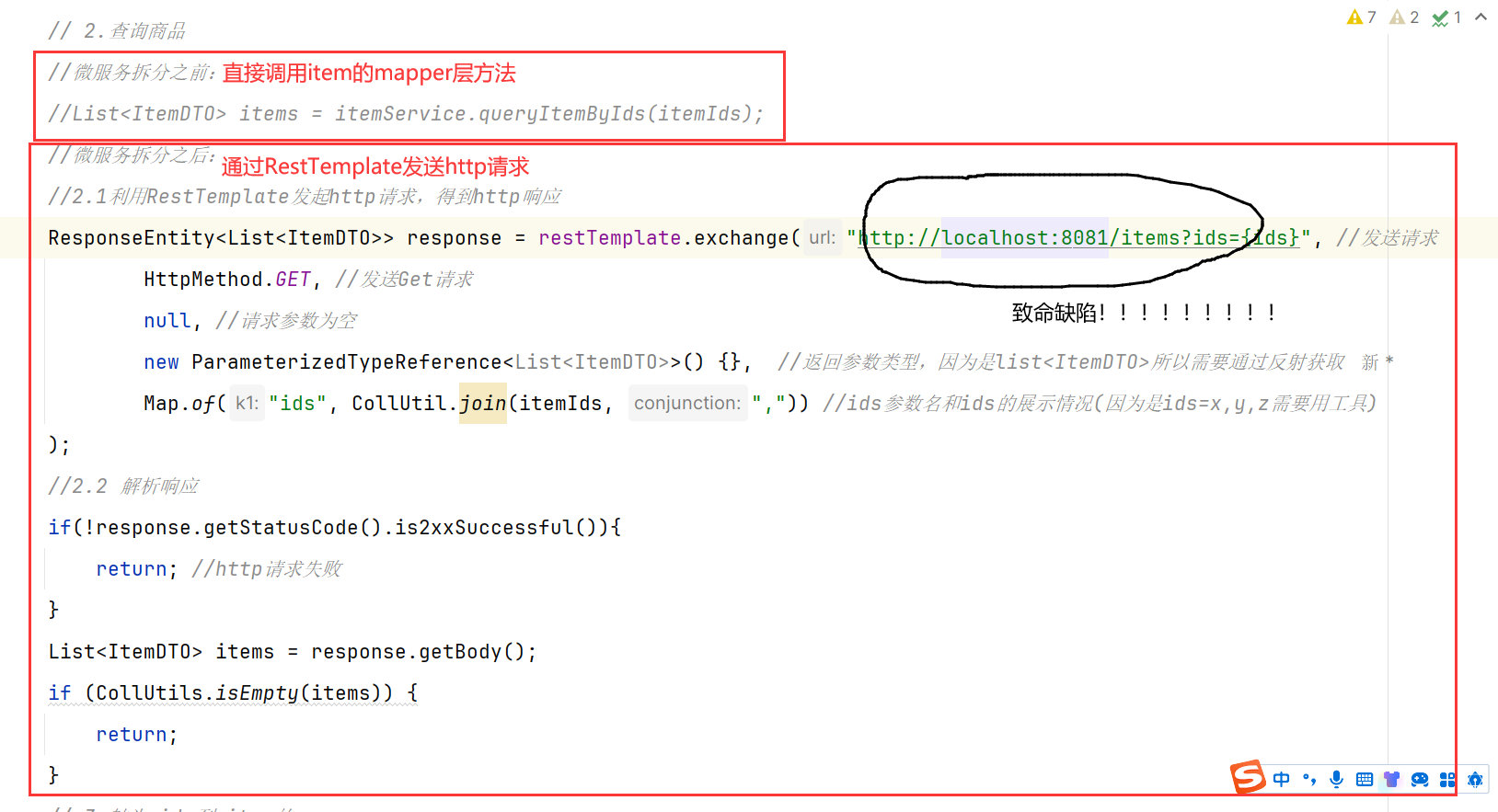
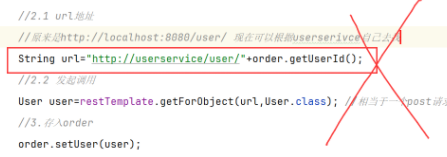
2.远程调用-RestTemplate 之前通过调用item的mapper层方法即可,现在需要通过RestTemplate发送http请求给item服务获取数据。【但是有个致命问题是,exchange方法的url是写死的就很麻烦】
使用方法:
具体操作:
==服务治理–更高效管理调用者和被调用者== 1.注册中心(+调用中间商) 为了解决RestTemplate发送http请求时会写死url问题【如果被调用服务有多台负载均衡,就会报错更改也很麻烦】。==其实注册中心就相当于docker中的数据卷一样,我们可以当做中间商然后把调用者(服务调用者)和被调用者(服务注册者)联系起来。==
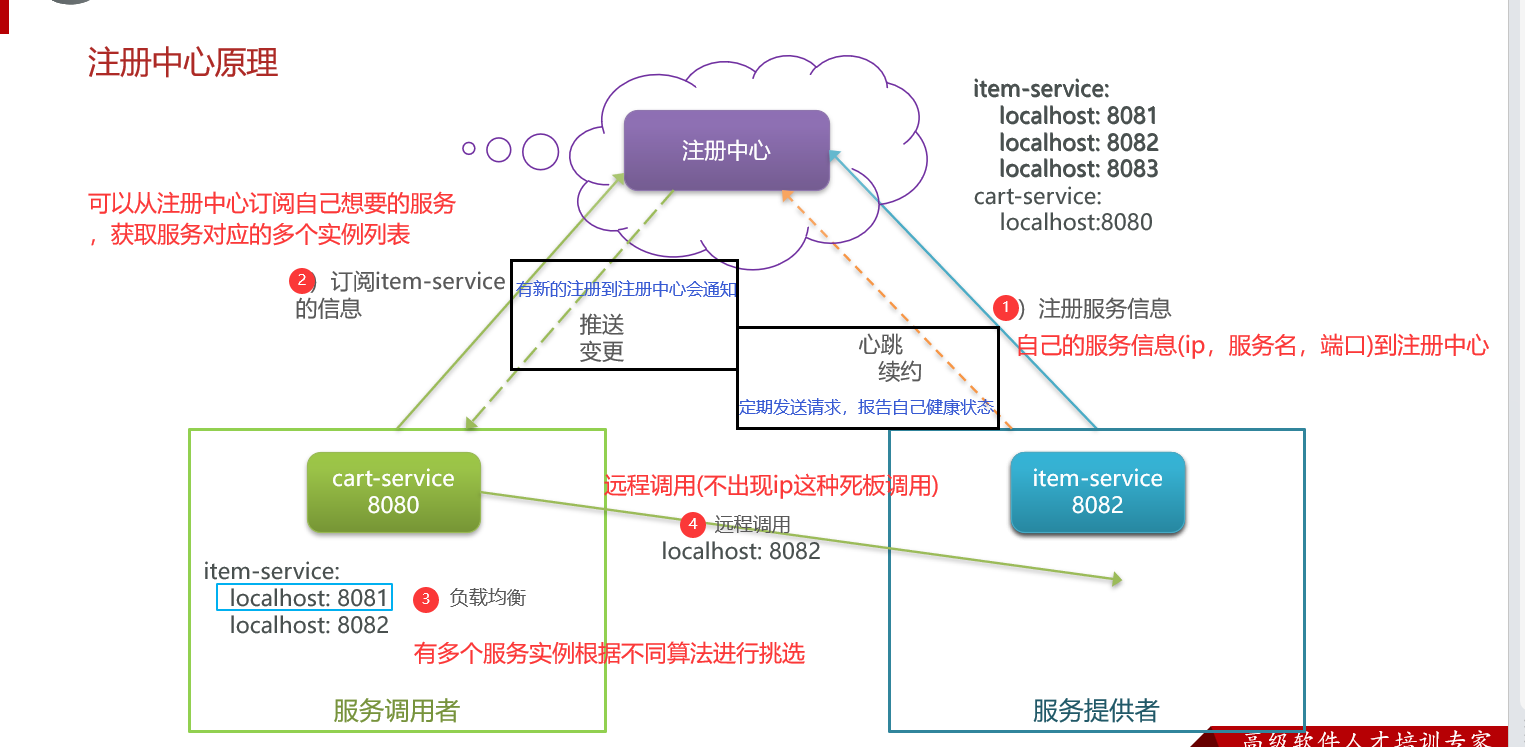
1.1 注册中心原理 流程如下:
服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心 –让注册中心知道我可以被调用
调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署) –让调用者知道有哪些可以调用
调用者自己对实例列表负载均衡,挑选一个实例 –让调用者选一个被调用者
调用者向该实例发起远程调用 –远程调用
服务提供者:暴露服务接口,供其它服务调用
服务消费者:调用其它服务提供的接口
注册中心:记录并监控微服务各实例状态,推送服务变更信息
服务提供者会在启动时注册自己信息到注册中心,消费者可以从注册中心订阅和拉取服务信息
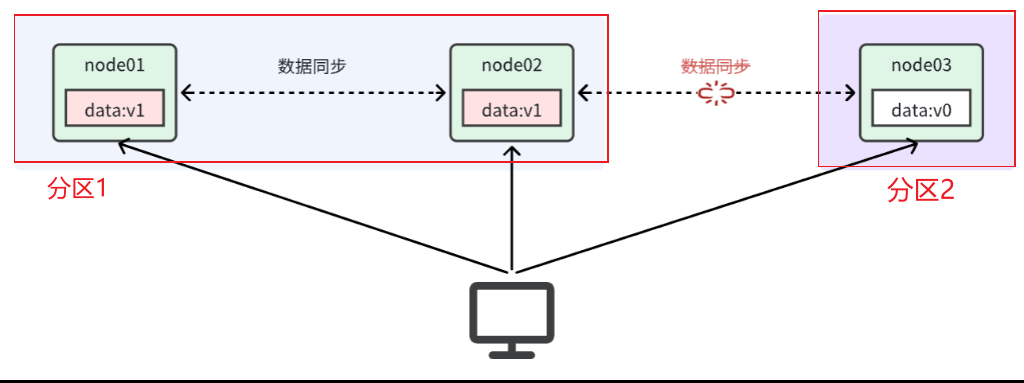
消费者如何得知服务状态变更?【Nacos会15s检测一次,30s删除一次 】
服务提供者通过心跳机制向注册中心报告自己的健康状态,当心跳异常时注册中心会将异常服务剔除,并通知订阅了该服务的消费者
消费者通过负载均衡算法,从多个实例中选择一个【==以前SpringMVC默认是Ribbon负载均衡,后来默认是loadbalancer负载均衡==】
1.2 注册中心方式 1.1.1 Eureka(之前使用) 具体使用可以去SpringCloud篇笔记查找
1.1.2 Nacos(目前使用) 1.角色1-注册中心
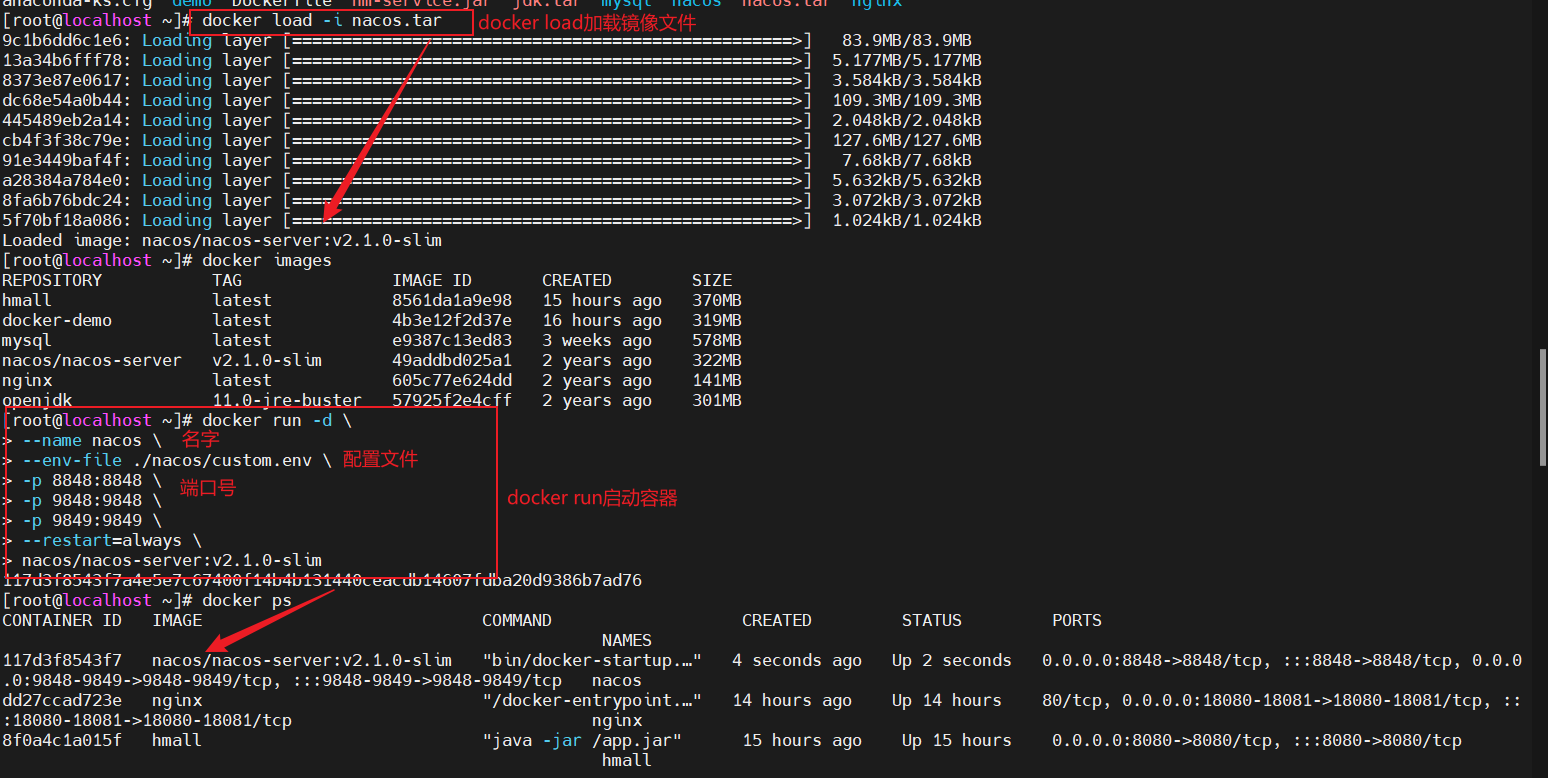
1.准备配置文件和tar包
2.linux服务器docker容器启动
3.可以在windows系统下访问
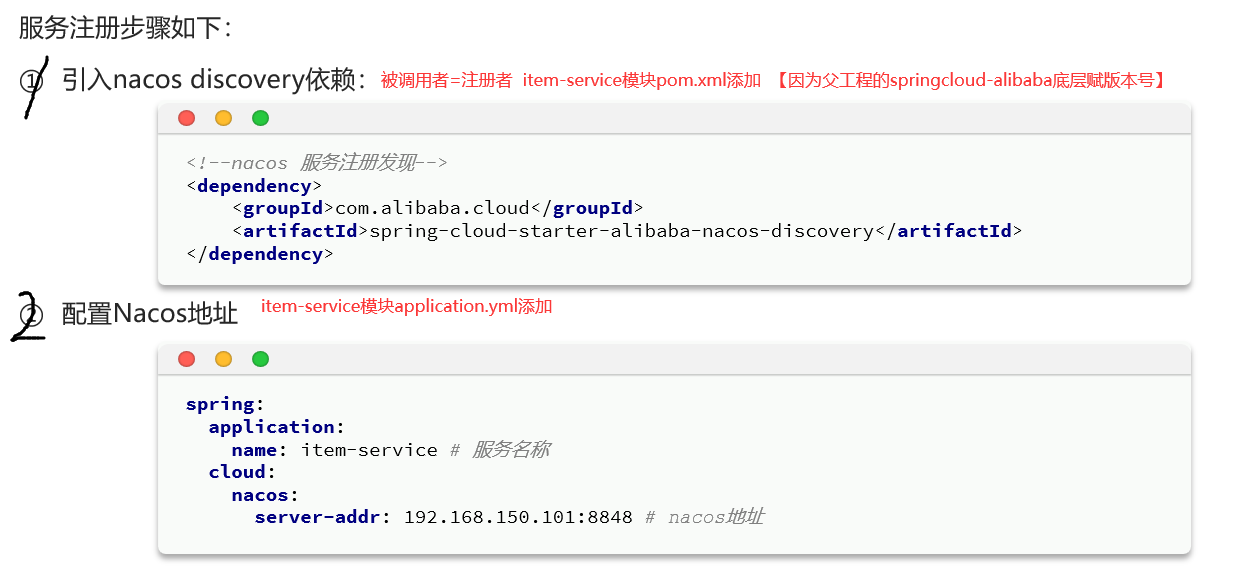
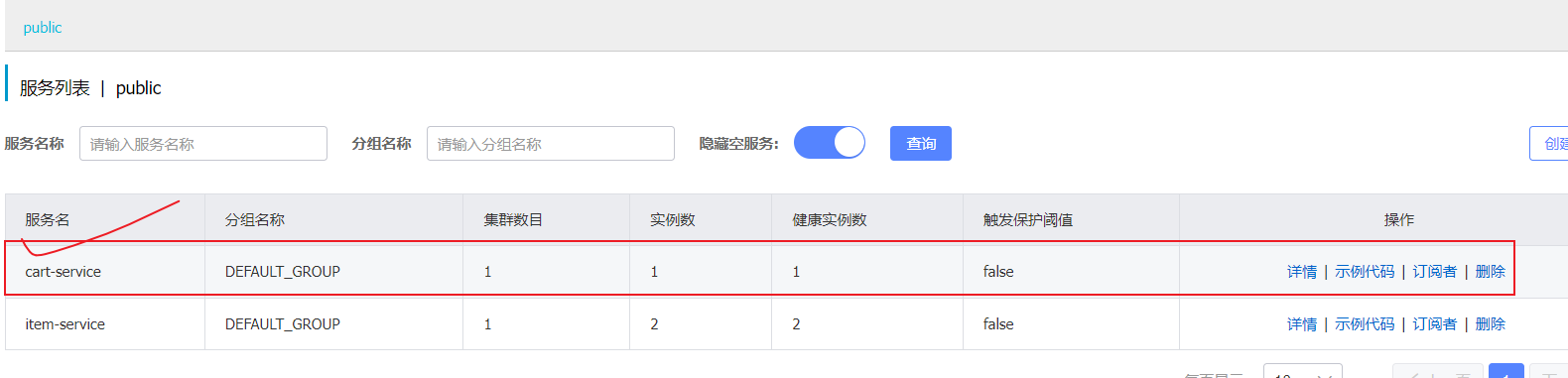
2.角色2-服务注册 主要用于对服务提供者进行信息注册,注册到nacos中。
1.在pom.xml中导入依赖和在application.yml文件中配置nacos地址
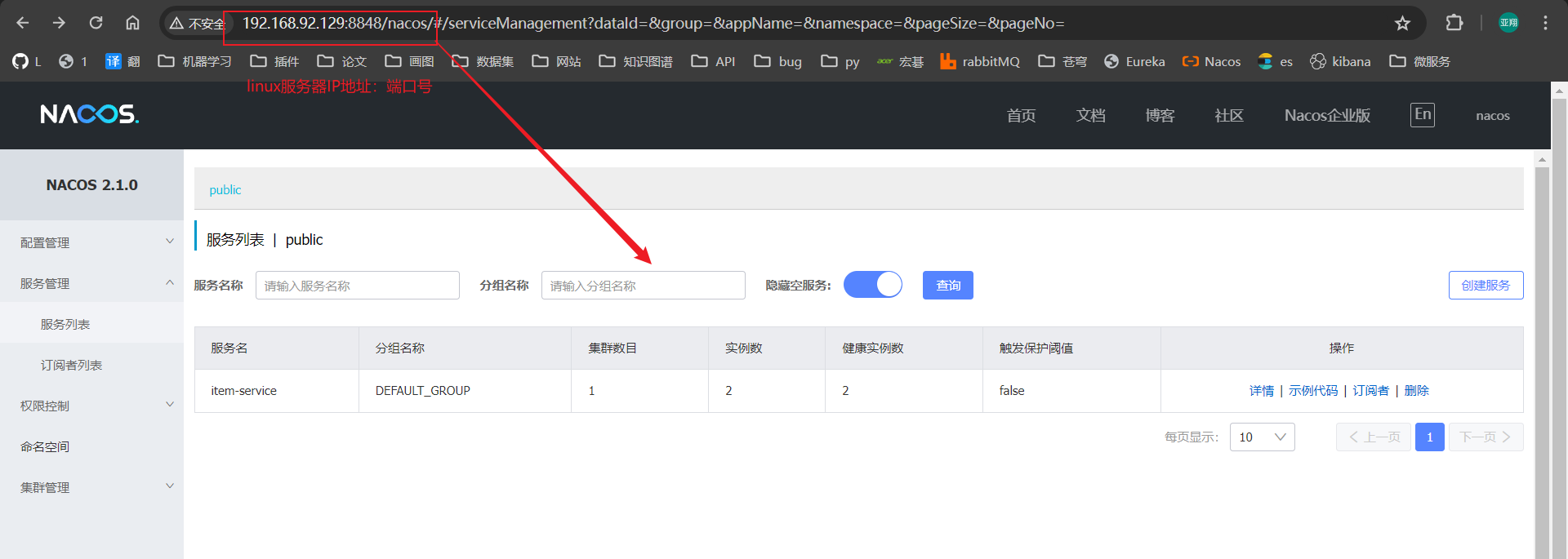
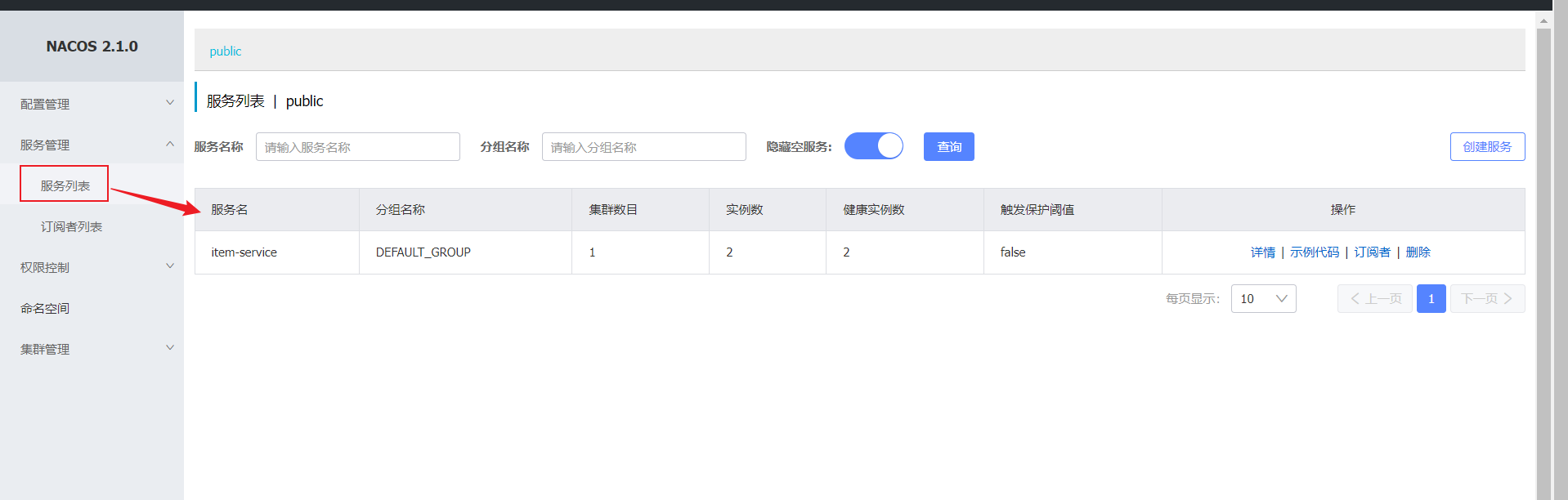
2.我们添加完成之后可以刷新nacos地址,就可以在网页中看到
3.角色3-服务发现
2.我们添加完成之后可以刷新nacos地址,就可以在网页中看到
==服务调用–更高效发送http请求== 1.OpenFeign(优化发送http请求) 之前使用的RestTemplate发起远程调用的代码:
存在下面的问题:
• 代码可读性差,编程体验不统一
• 参数复杂URL难以维护
==Feign==是一个声明式的http客户端。其作用是帮助我们优雅地实现http请求发送,解决了上述的问题
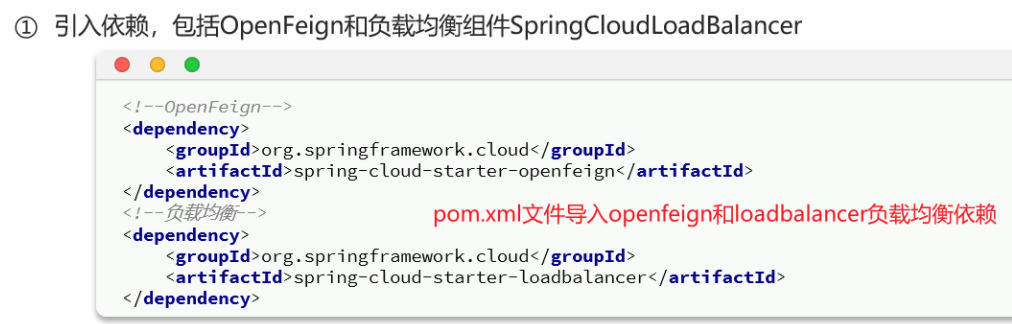
1.1 使用步骤
这里只需要声明接口,无需实现方法[OpenFeign动态代理实现 ]。接口中的几个关键信息:
@FeignClient("item-service") :声明服务名称@GetMapping :声明请求方式@GetMapping("/items") :声明请求路径@RequestParam("ids") Collection<Long> ids :声明请求参数List<ItemDTO> :返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。我们只需要直接调用这个方法,即可实现远程调用了。
4.服务发现方直接远程调用
总而言之,OpenFeign替我们完成了服务拉取、负载均衡、发送http请求的所有工作
1.2 连接池 ==Feign底层发起http请求,依赖于其它的框架==。其底层客户端实现包括:
URLConnection:[默认]不支持连接池
Apache HttpClient :支持连接池
OKHttp:支持连接池
以HttpClient为例:
①pom.xml文件引入依赖
1 2 3 4 5 <!--httpClient的依赖 --> <dependency> <groupId>io.github.openfeign</groupId> <artifactId>feign-httpclient</artifactId> </dependency>
②yml配置文件
1 2 3 4 5 6 feign: httpclient: enabled: true # 开启feign对HttpClient的支持 #线程池的核心值需要压测和实际情况调整!!!!!!!!!!!1 max-connections: 200 # 最大的连接数 max-connections-per-route: 50 # 每个路径的最大连接数
1.3 最佳实践方案 我们在2.1的使用步骤其实只是模拟了一种调用,但可能多个模块之间互相调用这种方式就有很大弊端。
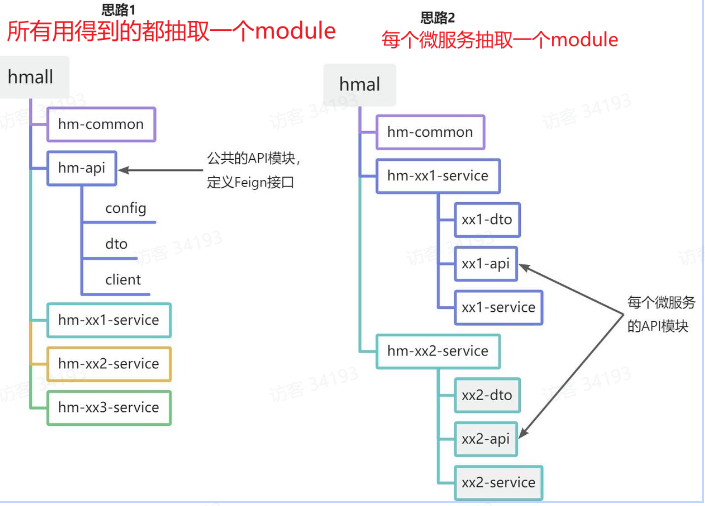
因此可以提出继承方式和抽取方式:
方案1抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
1.3.1 两种抽取方式 1.继承方式 就是将所有用得到的dto,po,vo啥的都放到一个微服务里面。
2.抽取方式 每个微服务存放自己需要的dto,po,vo啥的。只有需要的放到对应微服务。
1.3.2 抽取Feign客户端 就是将cart-service关于调用的代码和vo,dto等挪到hm-api公共模块内。
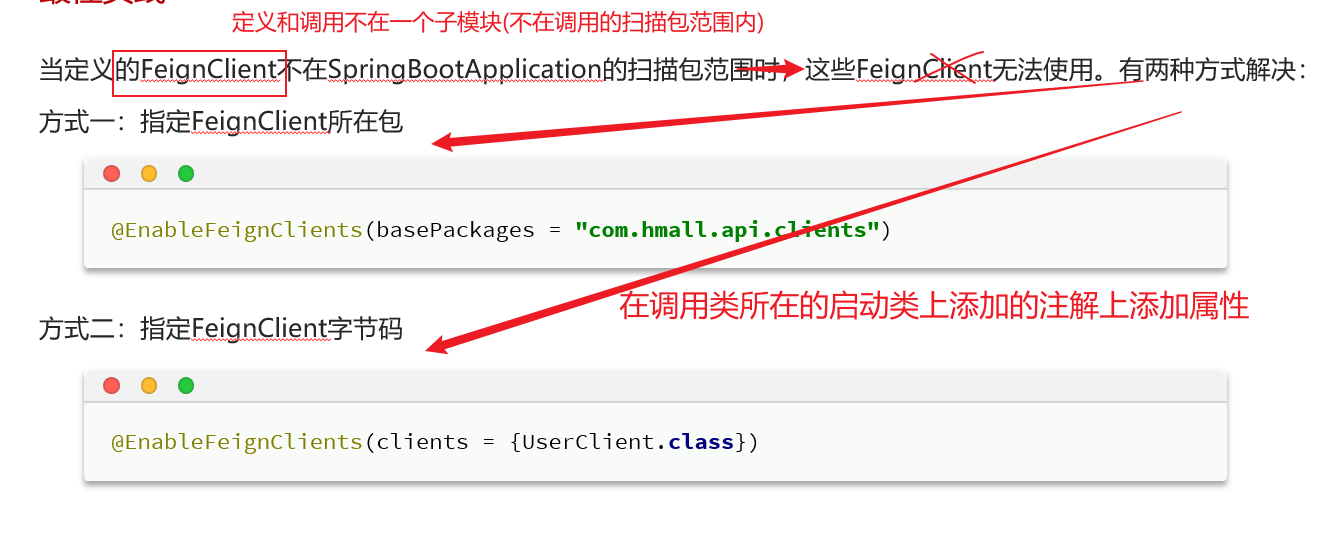
1.3.3 扫描包 一般情况下,如果调用feign和注册feign不在一个微服务内,那就可能出现扫描包扫描不到报错。就需要进行设置扫描包:
1.4 日志管理 OpenFeign只会在FeignClient所在包的日志级别为DEBUG 时,才会输出日志。而且其日志级别有4级:
NONE :不记录任何日志信息,这是默认值。BASIC :仅记录请求的方法,URL以及响应状态码和执行时间HEADERS :在BASIC的基础上,额外记录了请求和响应的头信息FULL :记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。
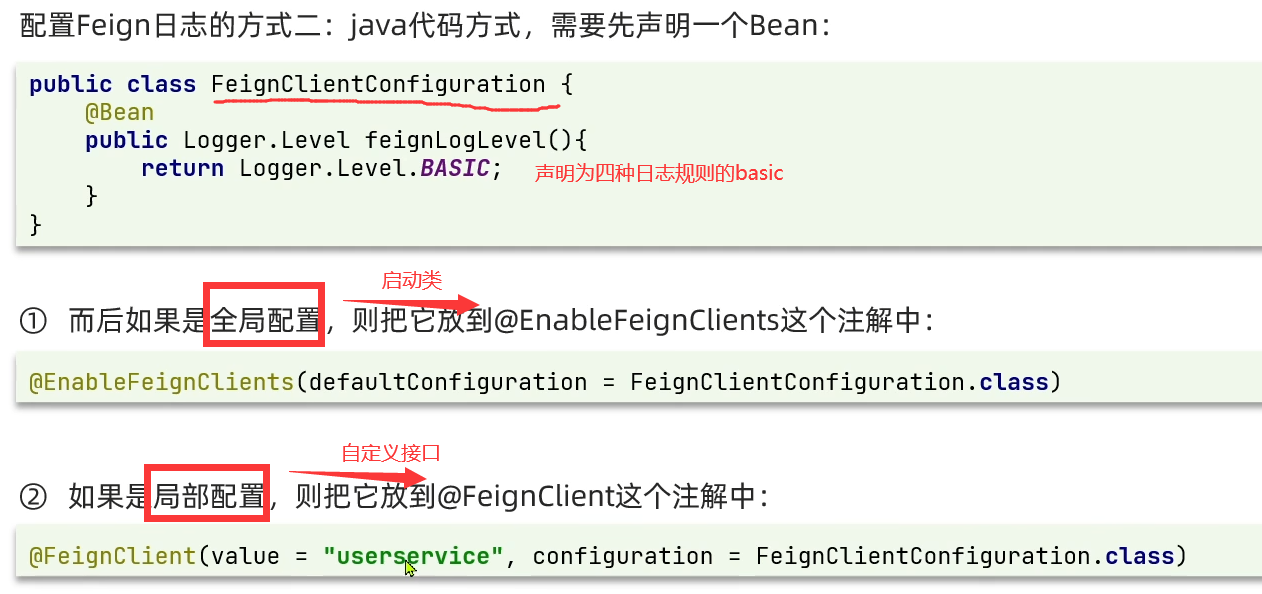
1.4.1 配置文件yml方式
1.4.2 Java代码方式
提出一些问题:
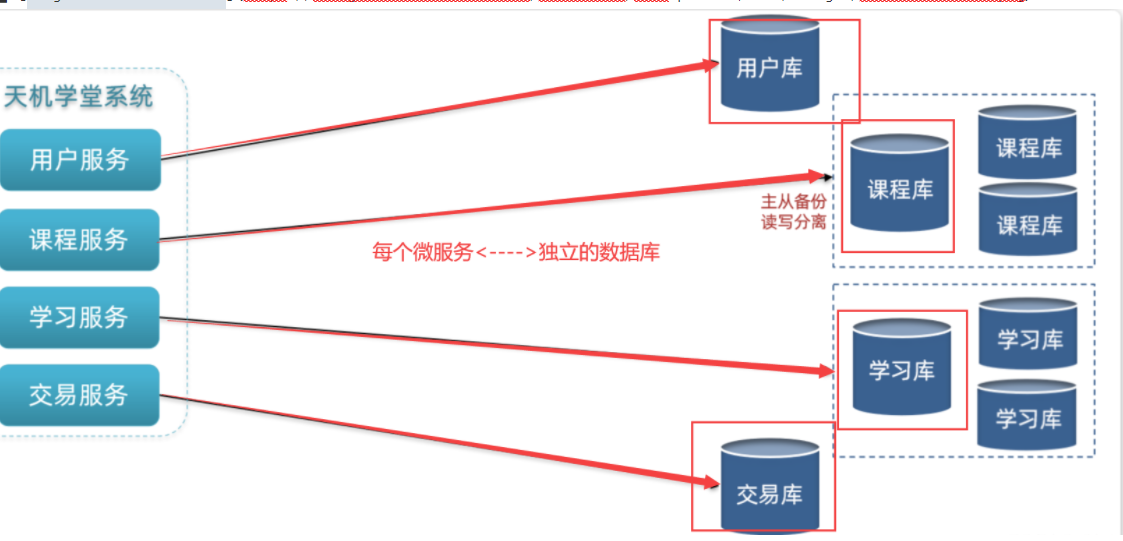
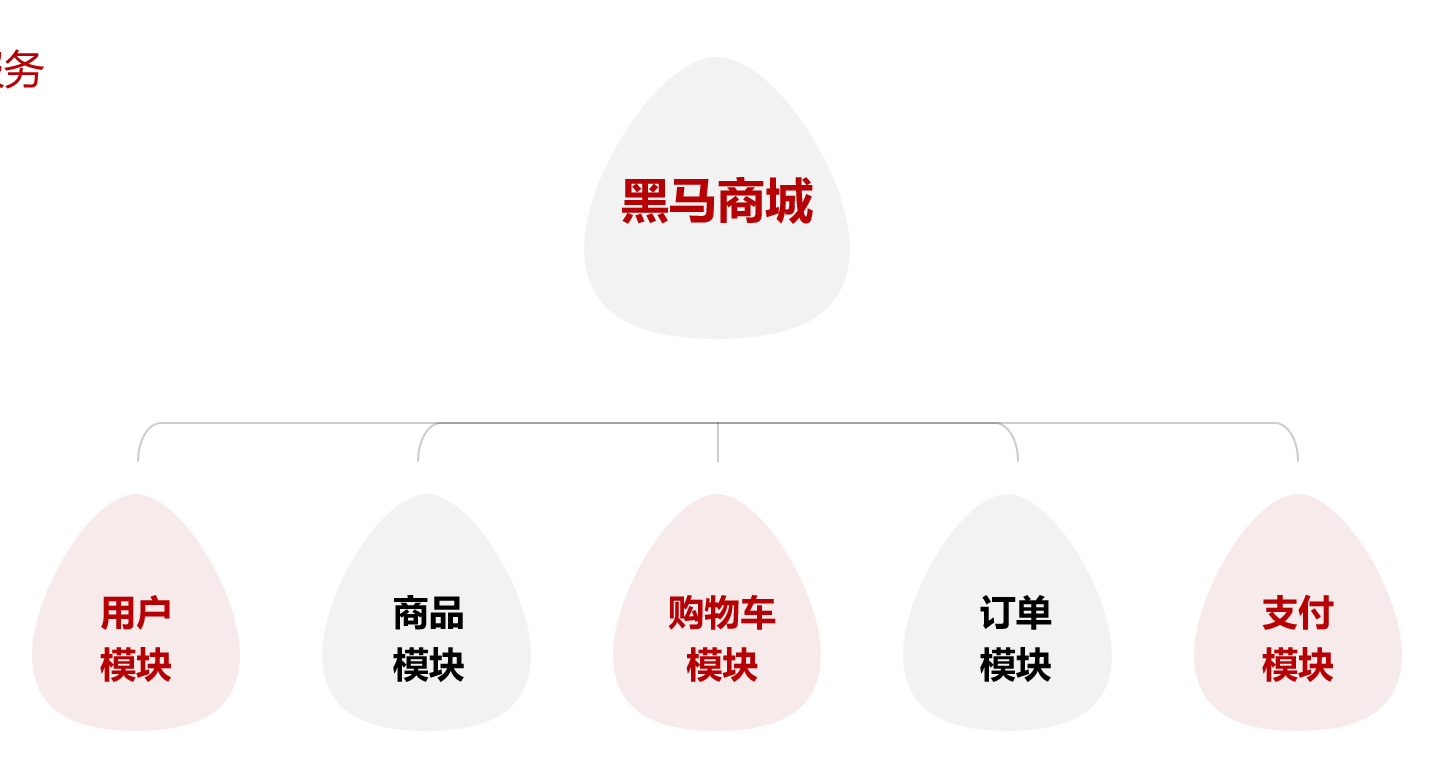
我们将黑马商城拆分为5个微服务:
用户服务
商品服务
购物车服务
交易服务
支付服务
由于每个微服务都有不同的地址或端口,入口不同,在与前端联调的时候发现了一些问题:
请求不同数据时要访问不同的入口,需要维护多个入口地址,麻烦
前端无法调用nacos,无法实时更新服务列表
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,这就存在一些问题:
每个微服务都需要编写登录校验、用户信息获取的功能吗?
当微服务之间调用时,该如何传递用户信息?
通过==网关==技术解决上述问题。笔记分为3章:
第一章:网关路由,解决前端请求入口的问题。
第二章:网关鉴权,解决统一登录校验和用户信息获取的问题。
第三章:统一配置管理,解决微服务的配置文件重复和配置热更新问题。
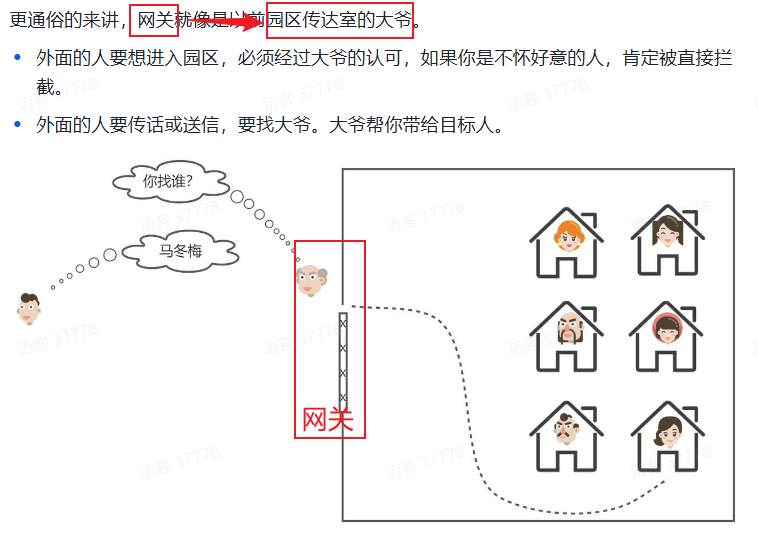
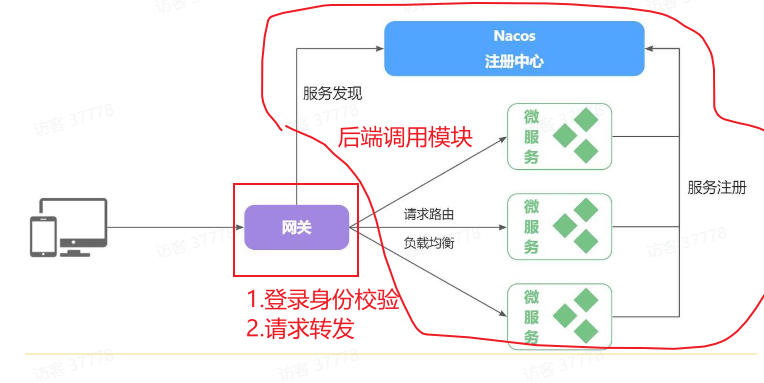
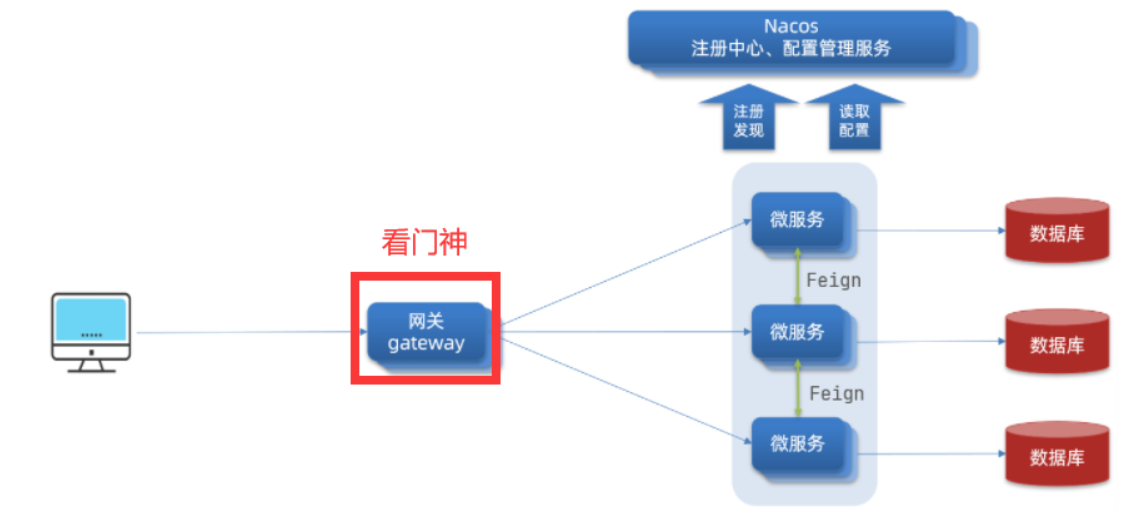
==服务管理–帮助前后端联调,全局门卫== 1.网关路由 1.1 网关概述(门卫) 顾明思议,网关就是网络的==关口==。数据在网络间传输,当一个网络 –传输–> 另一网络时,就需要经过网关来做数据的路由 ,转发 ,数据安全的校验 。
现在,微服务网关就起到同样的作用。前端请求不能直接访问微服务,而是要请求网关:
网关可以做安全控制,也就是登录身份校验 ,校验通过才放行
通过认证后,网关再根据请求转发 到想要访问的微服务
在SpringCloud当中,提供了两种网关实现方案:
Netflix Zuul:早期实现,目前已经淘汰
SpringCloudGateway:基于Spring的WebFlux技术,完全支持响应式编程,吞吐能力更强
1.2 在项目中的地位
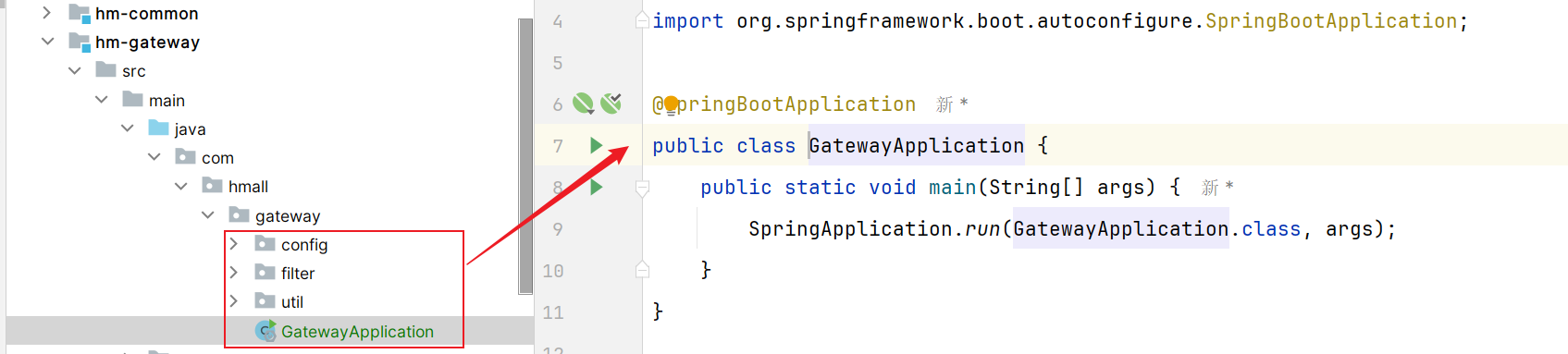
1.3 快速入门 1.3.1 创建项目 创建一个微服务hm-gateway项目:
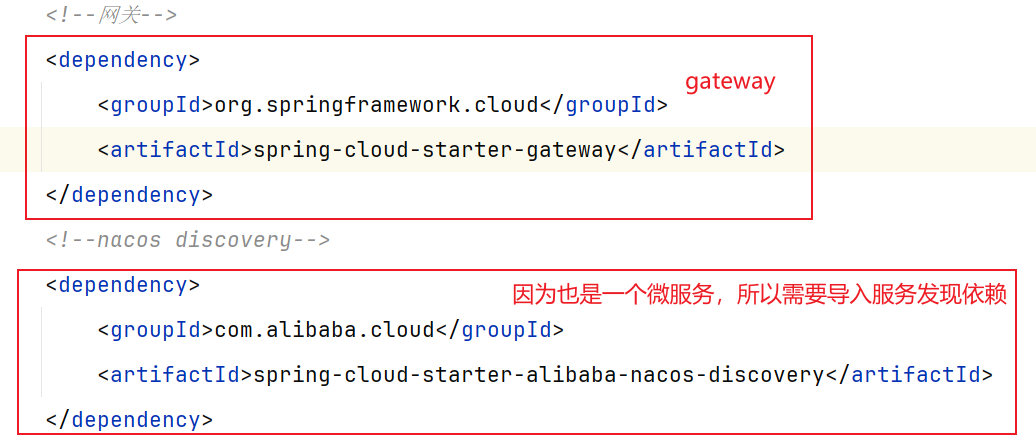
1.3.2 引入依赖 pom.xml文件引入依赖:
1.3.3 启动类 创建启动类【一定要注意启动类位置和其他包在同一级,不然启动类扫描注解就报错】:
1.3.4 配置路由 ==(目前最全,直接挪进去改改)==
接下来,在hm-gateway模块的resources目录新建一个application.yaml文件,内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 #端口信息 server: port: 8087 #spring配置 spring: application: name: gateway #微服务名称(用于nacos微服务注册) cloud: nacos: server-addr: 192.168.92.129:8848 #微服务nacos地址 #路由过滤 gateway: #1.路由过滤 routes: #第一个微服务 - id: item # 路由规则id,自定义,唯一 uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表 predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务 - Path=/items/**,/search/** # 这里是以请求路径作为判断规则 #第二个微服务 - id: cart uri: lb://cart-service predicates: - Path=/carts/** #第三个微服务 - id: user uri: lb://user-service predicates: - Path=/users/**,/addresses/** #第四个微服务 - id: trade uri: lb://trade-service predicates: - Path=/orders/** #第五个微服务 - id: pay uri: lb://pay-service predicates: - Path=/pay-orders/** #2.默认过滤器 default-filters: # 默认过滤项 - AddRequestHeader=Truth,Itcast is freaking awesome! #3.跨域问题 globalcors: add-to-simple-url-handler-mapping: true #解决options请求被拦截问题 cors-configurations: '[/**]': #拦截一切请求 allowedOrigins: # 允许哪些网站的跨域请求 - "http://localhost:8090" allowedMethods: # 允许的跨域ajax的请求方式 - "GET" - "POST" - "DELETE" - "PUT" - "OPTIONS" allowedHeaders: "*" # 允许在请求中携带的头信息 allowCredentials: true # 是否允许携带cookie maxAge: 360000 # 这次跨域检测的有效期
==配置文件概述:==
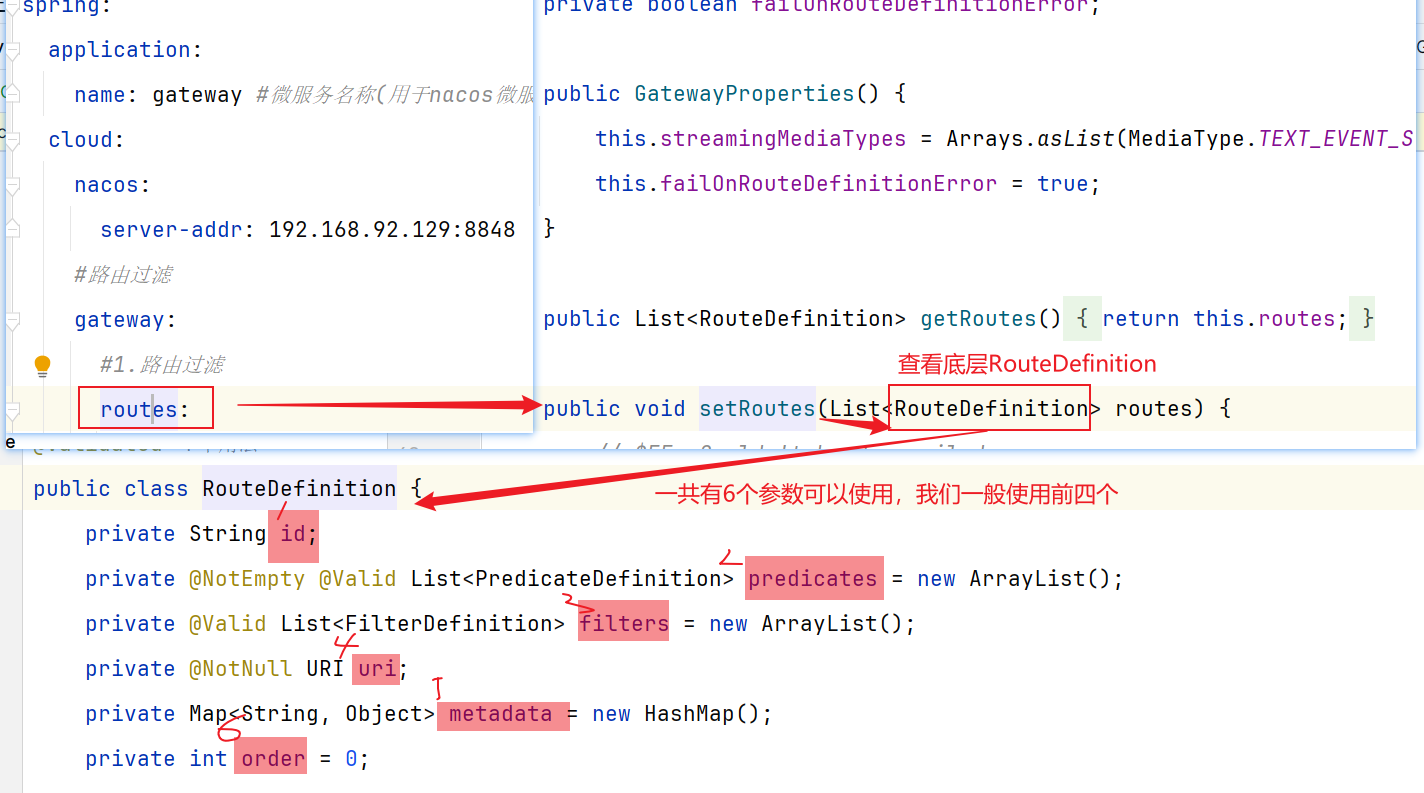
其中,路由规则的定义语法如下:
1 2 3 4 5 6 7 8 spring: cloud: gateway: routes: - id: item uri: lb://item-service predicates: - Path=/items/**,/search/**
四个属性含义如下:
id:路由的唯一标示predicates:路由断言【判断是否符合条件】 –>十一种,但是只用Path这一类filters:路由过滤条件【请求时添加信息】 –>三大类过滤器(执行顺序:默认过滤器,路由过滤器,全局过滤器)uri:路由目标地址,lb://代表负载均衡,从注册中心获取目标微服务的实例列表,并且负载均衡选择一个访问。
其中yml配置中的routes可以查看源码(底层其实就是我们配置的6个属性,其中我们常用其中4个):
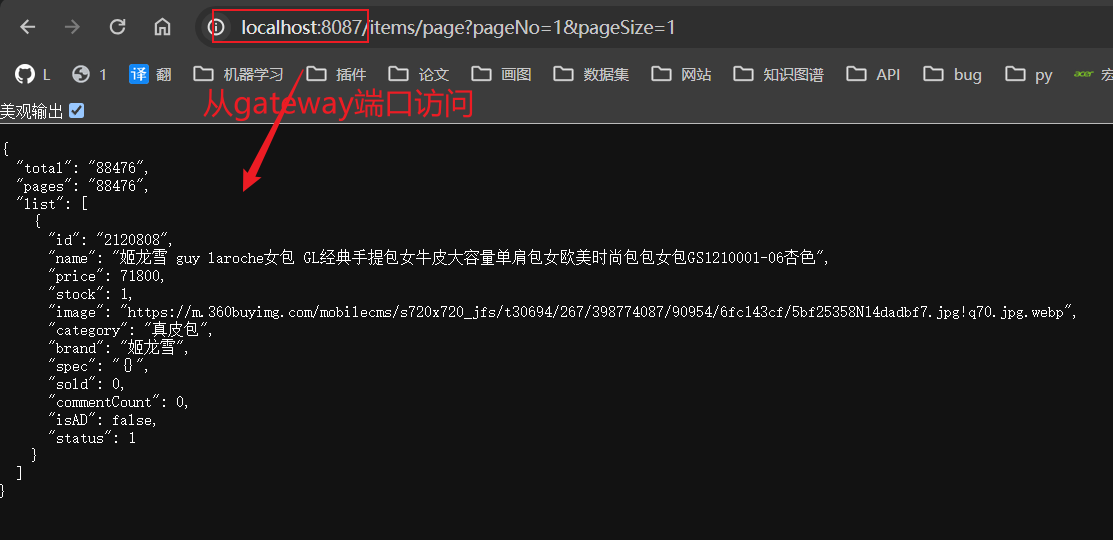
1.3.5 测试 2.网关鉴权(+登录校验)
单体架构,我们只需要完成一次用户登录,身份校验就可以在所有业务中获取到用户信息。
微服务架构,每个微服务都需要做用户登录校验就不太合理了
2.1 鉴权思路分析 我们的登录是基于JWT来实现的,校验JWT的算法复杂,而且需要用到秘钥。如果每个微服务都去做登录校验,这就存在着两大问题:
每个微服务都需要知道JWT的秘钥,×不安全
每个微服务重复编写登录校验代码、权限校验代码,×麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关。我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就解决了:
只需要在网关和用户服务保存秘钥
只需要在网关开发登录校验功能
【顺序:登录校验 –> 请求转发到微服务】
因此,①JWT登录校验 —->② 网关请求转发(gateway内部代码实现)
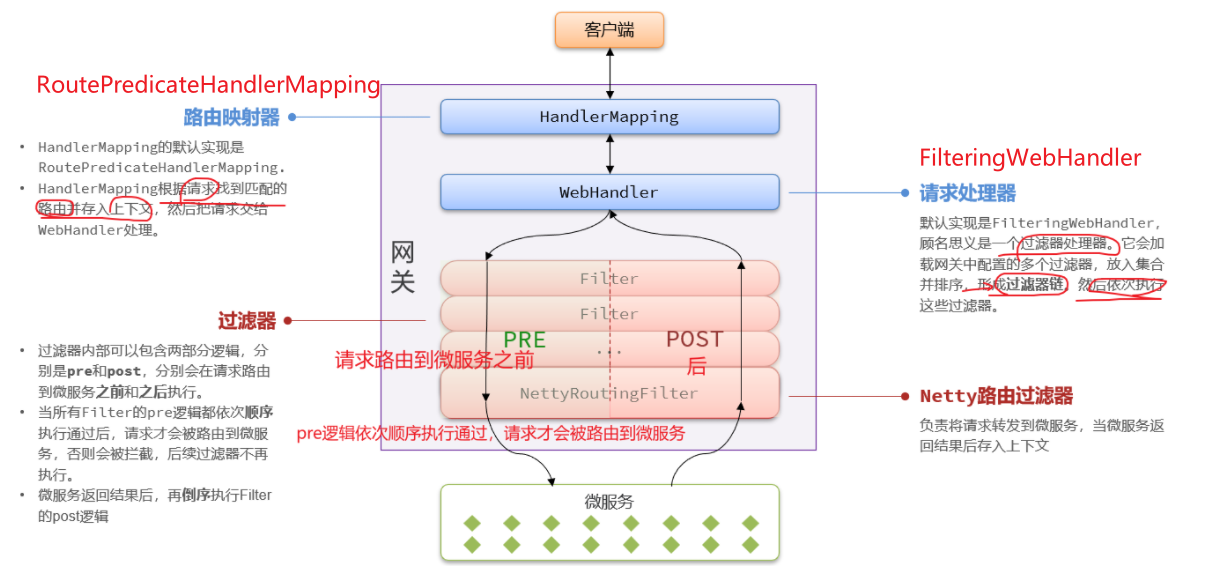
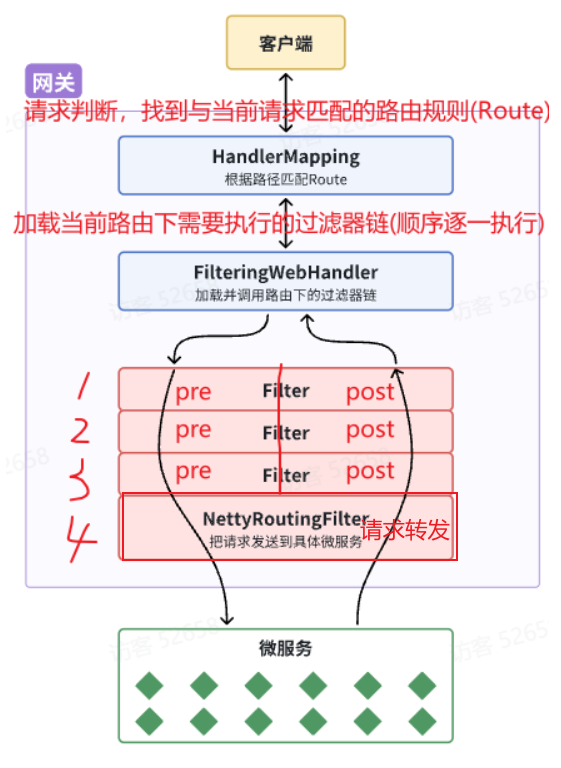
2.2 Gateway内部工作基本原理 登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
如图所示:
客户端请求进入网关后由HandlerMapping对请求做判断,找到与当前请求匹配的路由规则(RouteWebHandler去处理。
WebHandler则会加载当前路由下需要执行的过滤器链(Filter chainFilter图中Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前 和之后 被执行。
只有所有Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务。
微服务返回结果后,再倒序执行Filter的post逻辑。
最终把响应结果返回。
==总结:==
如图所示,最终请求转发是有一个名为NettyRoutingFilter的过滤器来执行的,而且这个过滤器是整个过滤器链中顺序最靠后的一个。
如果我们能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器执行顺序定义到NettyRoutingFilter之前 ,这就符合我们的需求。
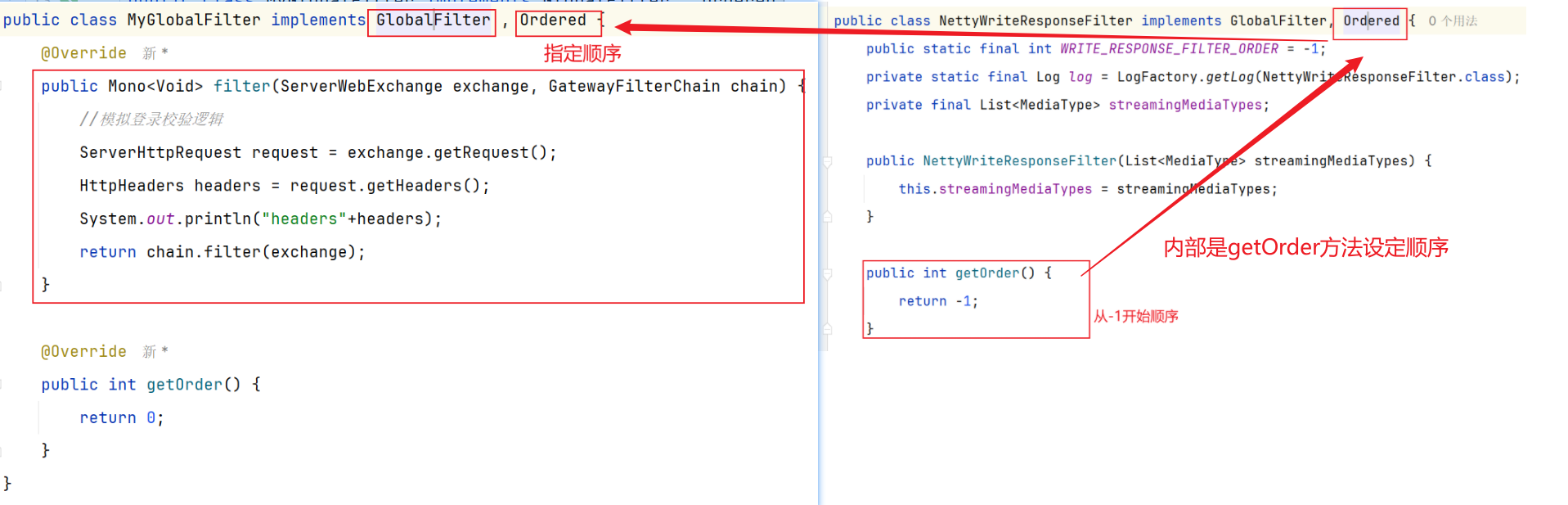
2.3 网关过滤链-三种过滤器 网关过滤器链中的过滤器有两种:
GatewayFilter路由过滤器 (gateway自带),作用范围比较灵活,可以:【指定的路由Route】 –一般自定义的话比较麻烦【直接yml配置】GlobalFilter全局过滤器 ,作用范围:【所有路由】,不可配置。 –一般使用这个好弄HttpHeadersFilter处理传递到下游微服务的请求头
其实GatewayFilter和GlobalFilter这两种过滤器的方法签名完全一致:
1 2 3 4 5 6 7 Mono<Void> filter (ServerWebExchange exchange, GatewayFilterChain chain) ;
工作基本原理的第二步WebHandler:FilteringWebHandler请求处理器在处理请求时,会将②GlobalFilter装饰为①GatewayFilter,然后放到同一个过滤器链中,排序以后依次执行。
2.4 自定义过滤器 2.4.1 GatewayFilter Gateway内置的GatewayFilter过滤器使用起来非常简单,无需编码,只要在yaml文件中简单配置即可。而且其作用范围也很灵活,配置在哪个Route下,就作用于哪个Route
方式一-yml文件配置 例如,有一个过滤器叫做AddRequestHeaderGatewayFilterFacotry,顾明思议,就是添加请求头的过滤器,可以给请求添加一个请求头并传递到下游微服务。
使用只需要在application.yaml中这样配置:【配置到gateway-routes下面就表明属于一个route】
1 2 3 4 5 6 7 8 9 10 11 spring: cloud: gateway: routes: - id: test_route uri: lb://test-service predicates: -Path=/test/** #过滤器 filters: - AddRequestHeader=key, value # 逗号之前是请求头的key,逗号之后是value
如果想作用于全部路由,则可以配置:【配置到gateway下面就表明不属于任何一个route,属于全部路由】
1 2 3 4 5 6 7 8 9 10 11 12 13 spring: cloud: gateway: routes: #在这里配置只在部分route下有效 - id: test_route uri: lb://test-service predicates: -Path=/test/** #默认过滤器【全部路由】 default-filters: # default-filters下的过滤器可以作用于所有路由 - AddRequestHeader=key, value
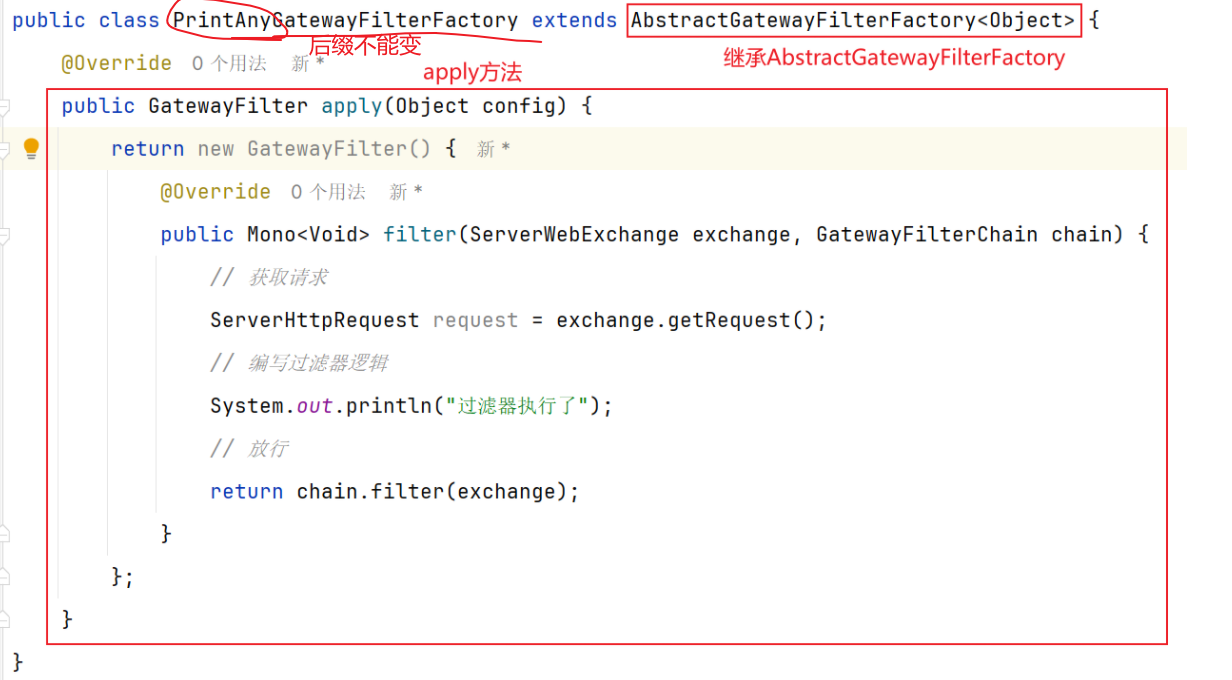
方式二-自定义类 自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。
【注意:该类的名称一定要以GatewayFilterFactory为后缀!】
然后在yml配置中使用:
1 2 3 4 5 spring: cloud: gateway: default-filters: - PrintAny #直接写自定义GatewayFilterFactory类名称中前缀类声明过滤器
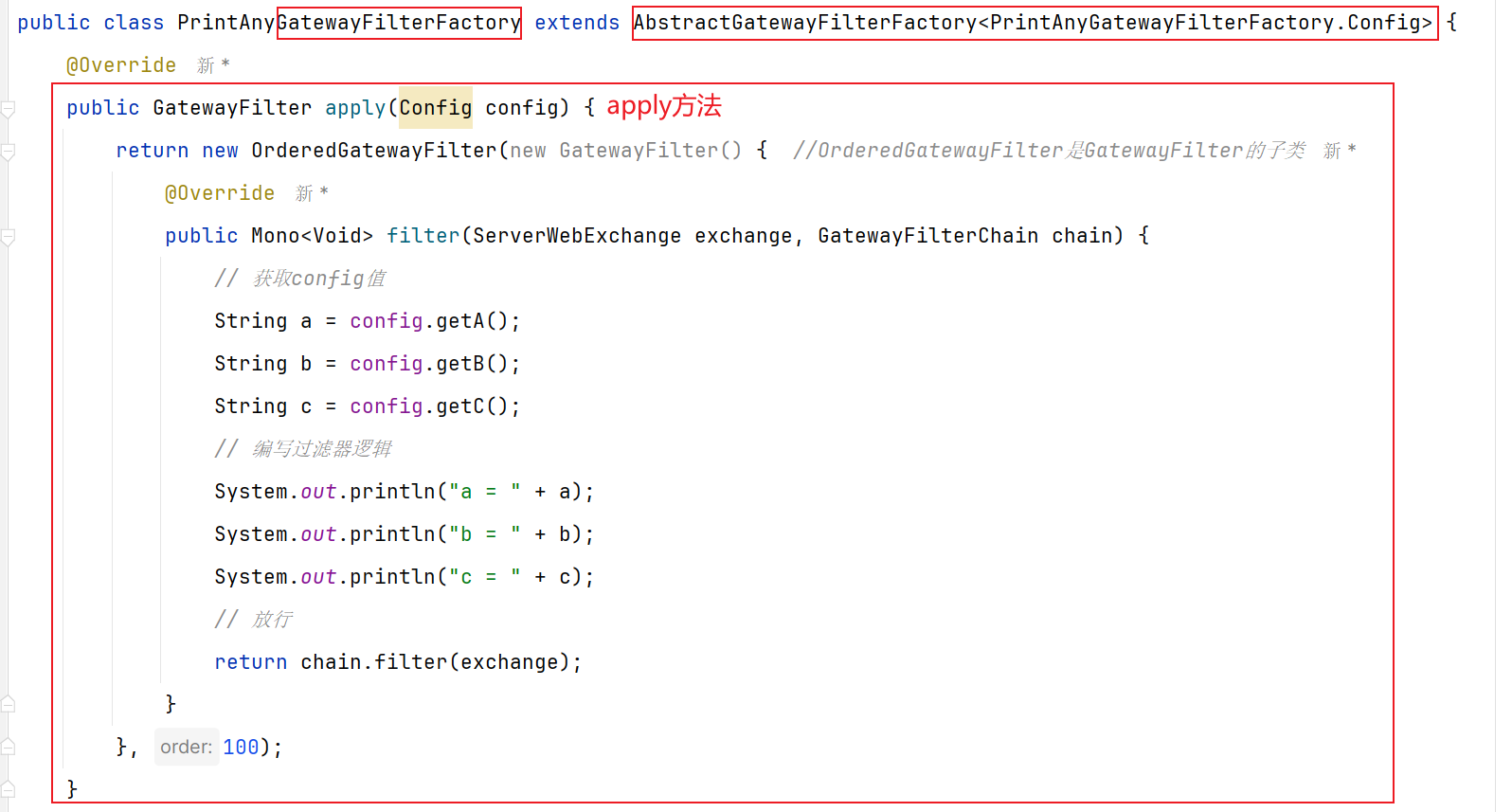
第二种 :自定义过滤器+动态配置参数【比较复杂不建议】
然后在yml配置中使用:
1 2 3 4 5 spring: cloud: gateway: default-filters: - PrintAny=1,2,3
上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
1 2 3 4 5 6 7 8 9 spring: cloud: gateway: default-filters: - name: PrintAny args: a: 1 b: 2 c: 3
第二种方法的总体图对比:
2.4.2 GlobalFilter 自定义GlobalFilter则简单很多,直接实现GlobalFilter即可,而且也无法设置动态参数[因为默认是全局路由]:
2.5 问题一-怎么进行登录校验 现在我们知道可以通过定义两种过滤器,定义到NettyRoutingFilter之前就行。
我们以自定义GlobalFilter来完成登录校验:
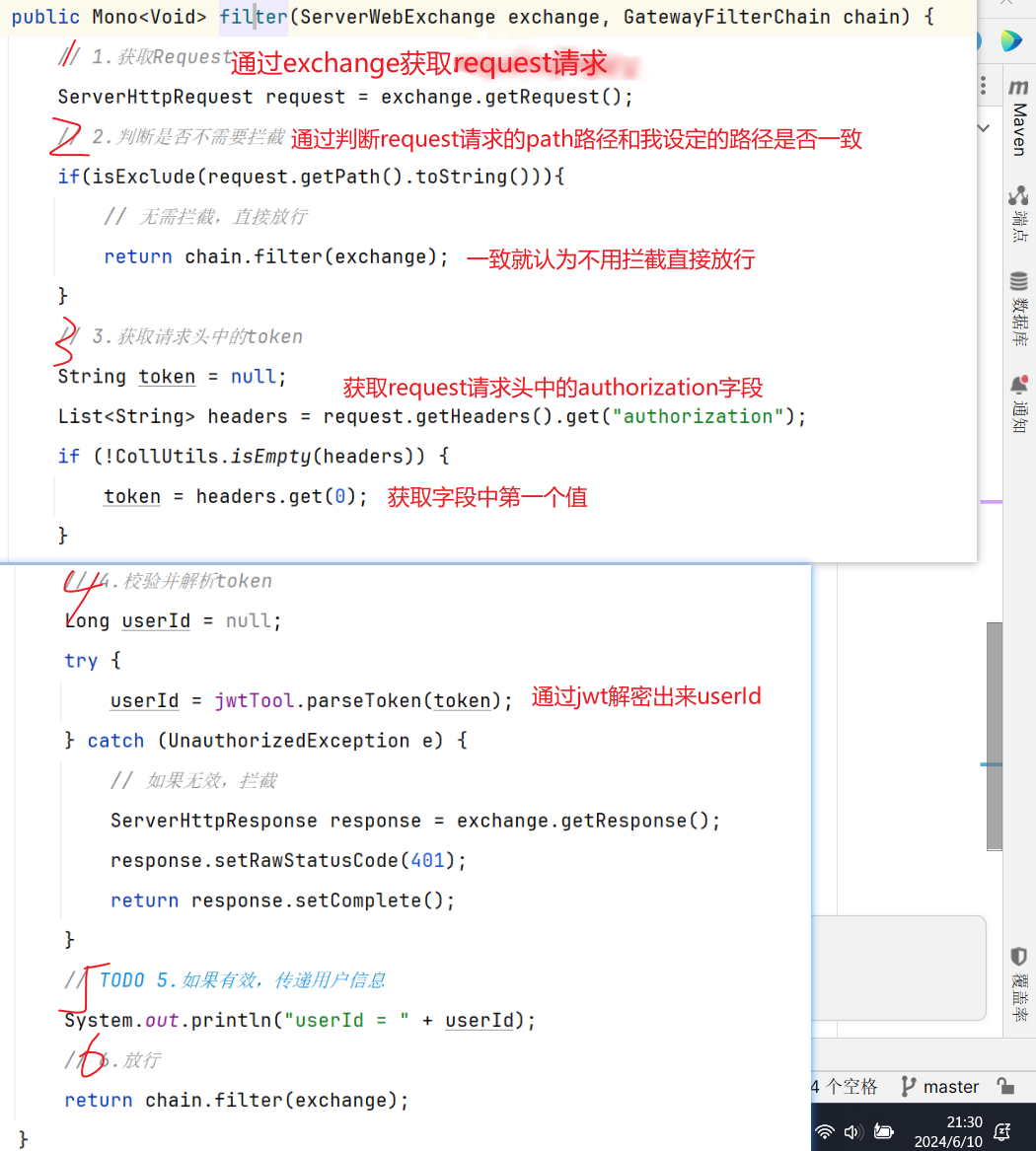
完整代码如下:
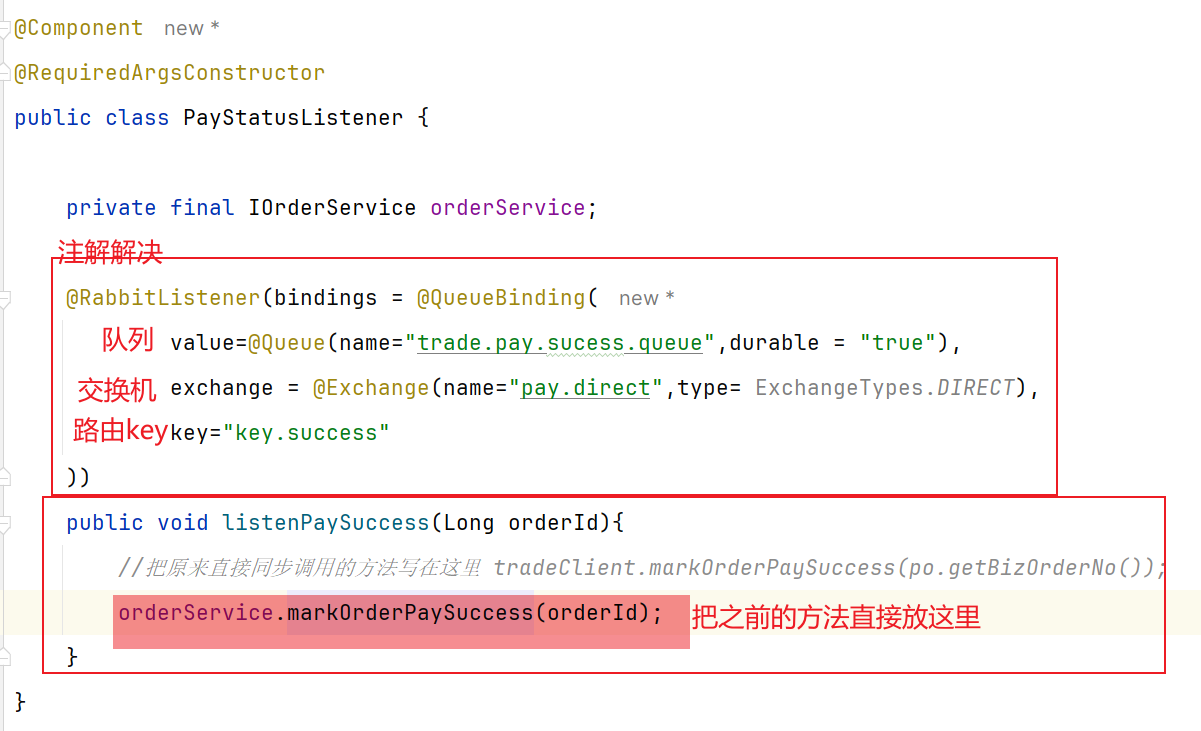
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 package com.hmall.gateway.filter; import com.hmall.common.exception.UnauthorizedException; import com.hmall.gateway.config.AuthProperties; import com.hmall.gateway.util.JwtTool; import lombok.RequiredArgsConstructor; import org.springframework.boot.context.properties.EnableConfigurationProperties; import org.springframework.cloud.gateway.filter.GatewayFilterChain; import org.springframework.cloud.gateway.filter.GlobalFilter; import org.springframework.core.Ordered; import org.springframework.http.server.reactive.ServerHttpRequest; import org.springframework.http.server.reactive.ServerHttpResponse; import org.springframework.stereotype.Component; import org.springframework.util.AntPathMatcher; import org.springframework.web.server.ServerWebExchange; import reactor.core.publisher.Mono; import java.util.List; @Component @RequiredArgsConstructor @EnableConfigurationProperties(AuthProperties.class) public class AuthGlobalFilter implements GlobalFilter, Ordered { private final JwtTool jwtTool; private final AuthProperties authProperties; //因为不需要拦截的路径有/** 所以我们使用这种特殊matcher类进行匹配 private final AntPathMatcher antPathMatcher = new AntPathMatcher(); @Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { // 1.获取Request ServerHttpRequest request = exchange.getRequest(); // 2.判断是否不需要拦截 if(isExclude(request.getPath().toString())){ //yml配置的不需要拦截的路径和request的路径进行判断 // 无需拦截,直接放行 return chain.filter(exchange); } // 3.获取请求头中的token String token = null; List<String> headers = request.getHeaders().get("authorization"); if (headers!=null && !headers.isEmpty()) { token = headers.get(0); } // 4.校验并解析token Long userId = null; try { userId = jwtTool.parseToken(token); } catch (UnauthorizedException e) { // 如果无效,拦截 ServerHttpResponse response = exchange.getResponse(); response.setRawStatusCode(401); return response.setComplete(); } // TODO 5.如果有效,传递用户信息 System.out.println("userId = " + userId); // 6.放行 return chain.filter(exchange); } private boolean isExclude(String antPath) { for (String pathPattern : authProperties.getExcludePaths()) { if(antPathMatcher.match(pathPattern, antPath)){ return true; } } return false; } @Override public int getOrder() { return 0; } }
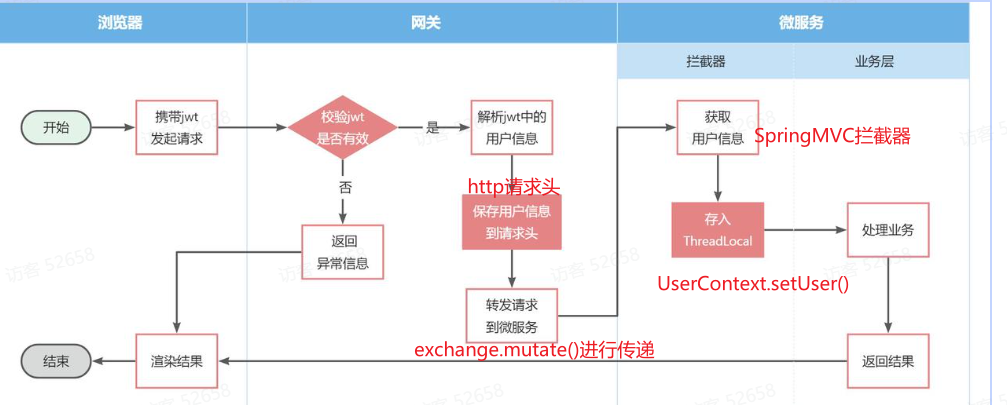
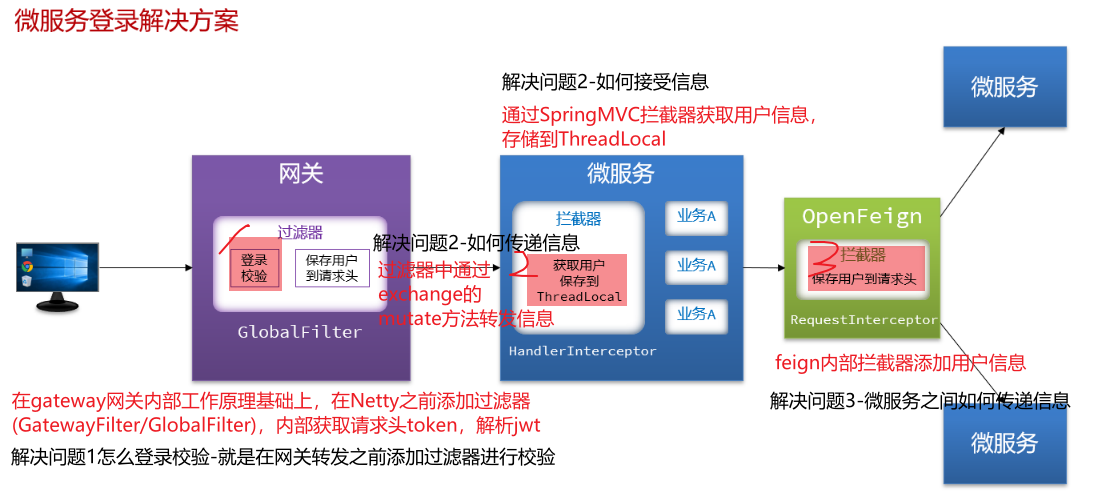
2.6 问题二-网关怎么传递用户信息 截止到2.5,网关已经可以完成登录校验并获取登录用户身份信息。
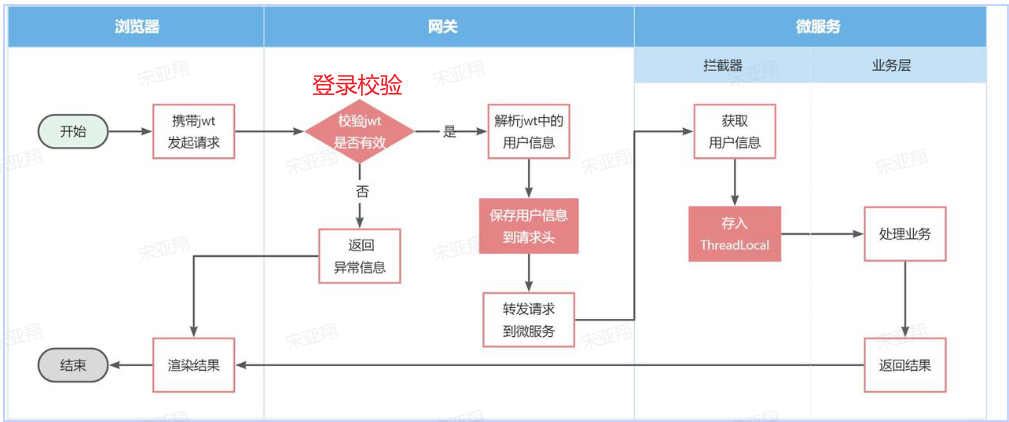
但是当网关将请求转发到微服务时,微服务又该如何获取用户身份呢?由于网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头 的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器 来获取登录用户信息,并存入ThreadLocal ,方便后续使用。
据图流程图如下:
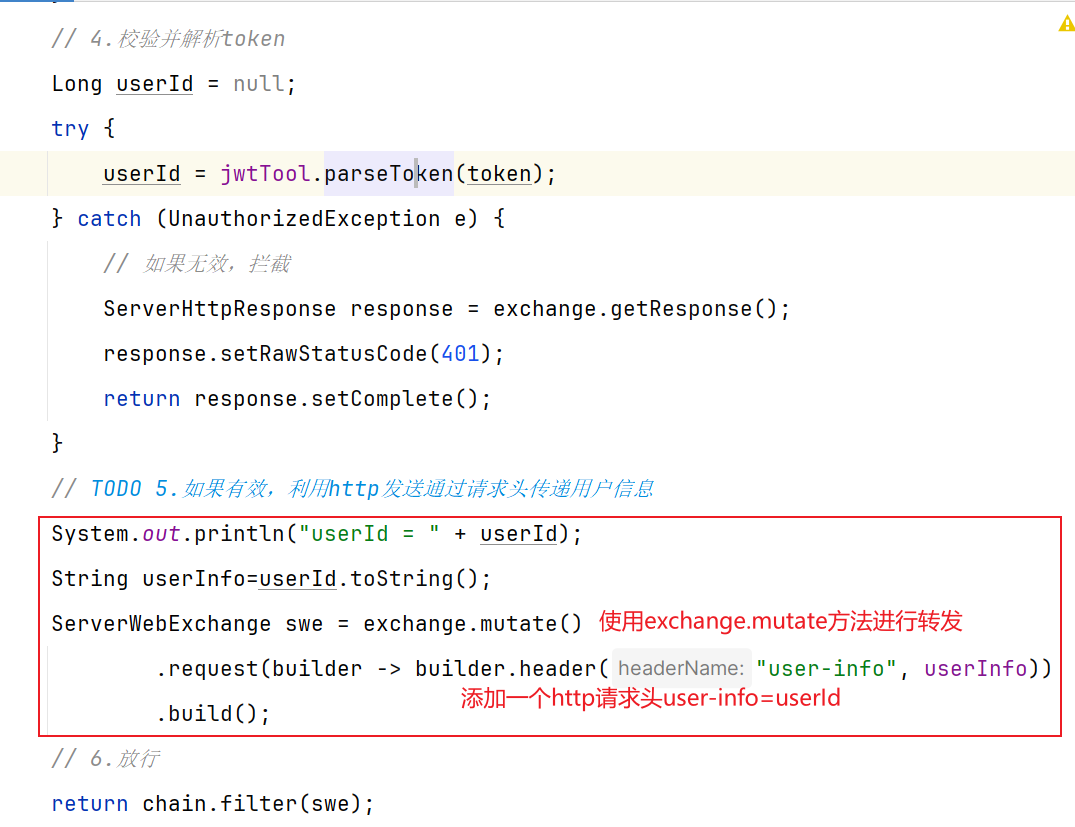
2.6.1 网关如何转发用户信息 网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头 的方式传递到下游微服务。
具体操作:【在2.5校验器实现的登录校验里面将jwt解析出来的UserId以请求头方式传递】
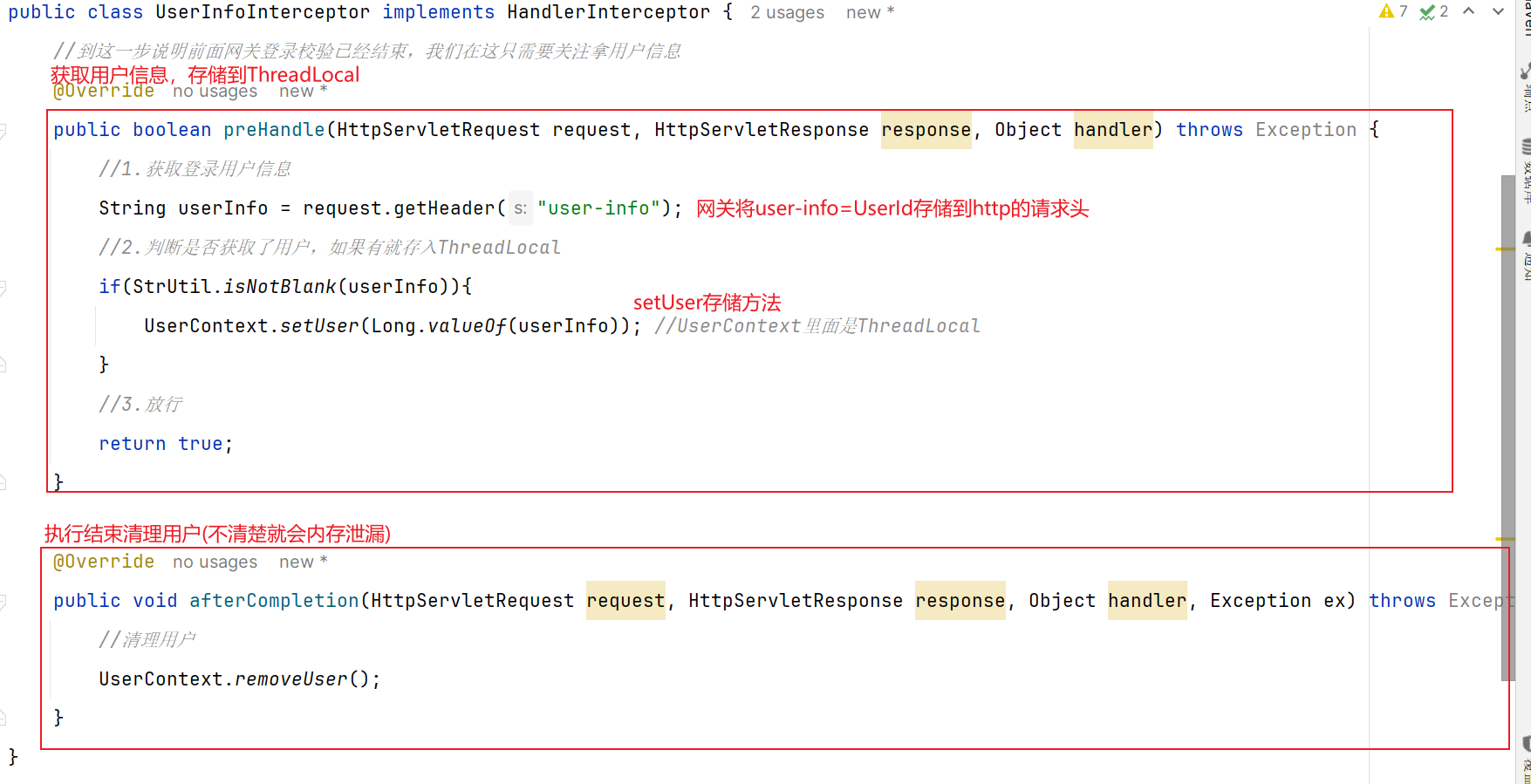
2.6.2 下游微服务怎么获取用户信息 微服务可以从请求头中获取登录用户信息。利用SpringMVC的拦截器 来获取登录用户信息,并存入ThreadLocal ,方便后续使用。
据图流程图如下:【==编写微服务拦截器,拦截请求获取用户信息,保存到ThreadLocal后放行==】
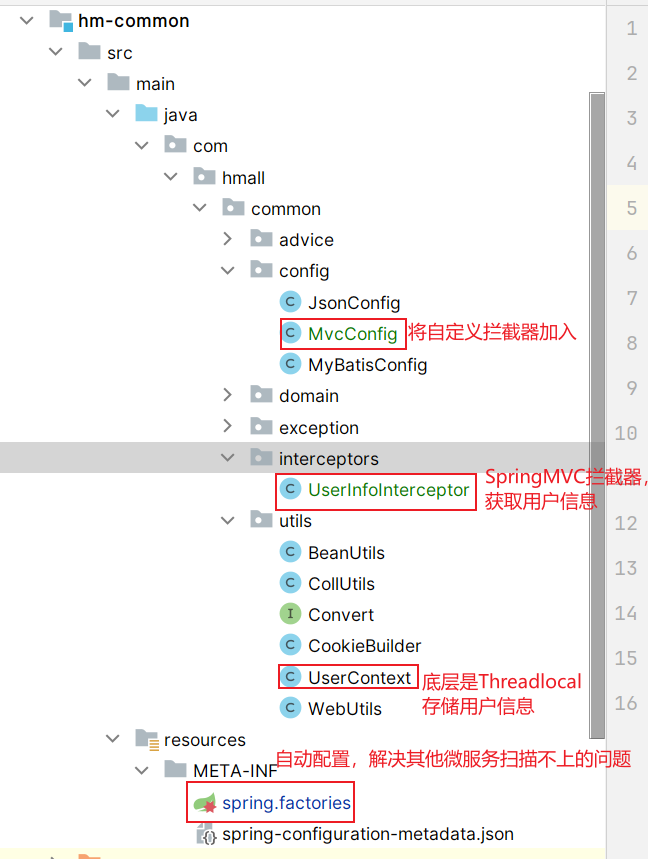
整体代码结构:
具体操作:
因为当前用户ID会在多个微服务中使用,所以我们可以在hm-common 微服务中编写:
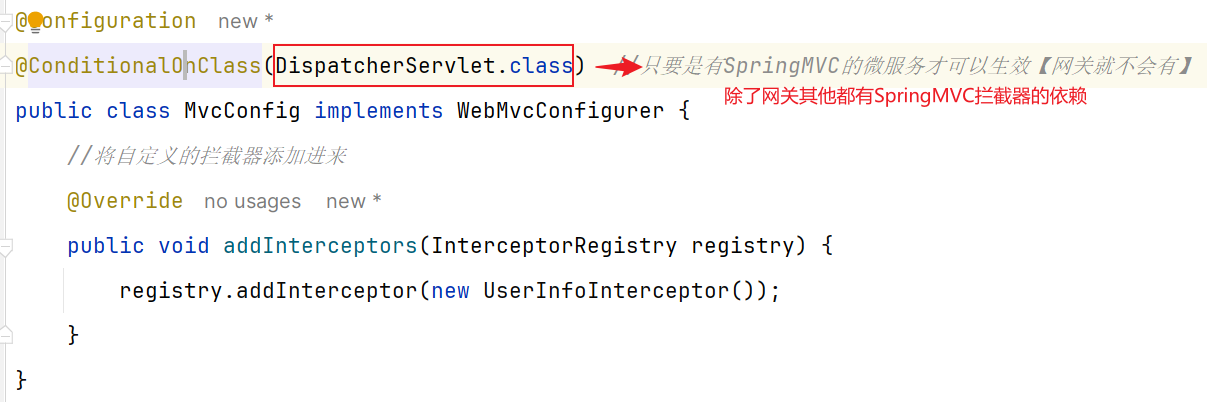
1.根据SpringMvc拦截器创建规则创建自定义拦截器
3.可以修改之前写死的位置业务逻辑,这样可以在通过Threadlocal获取信息
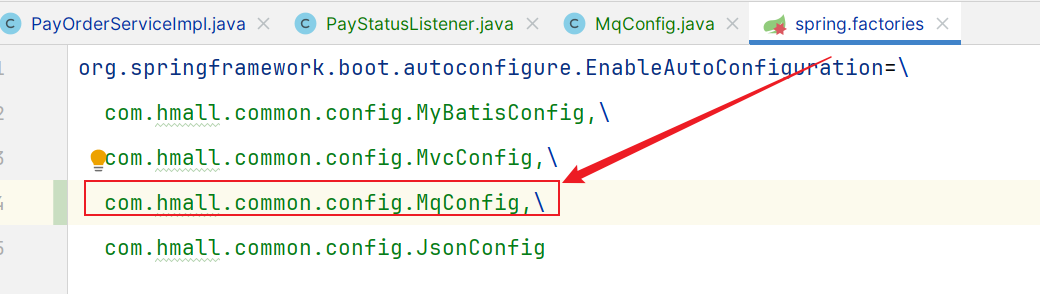
4.需要注意的是:因为是写在hm-common微服务,这个配置类默认不会生效(和其他微服务的扫描包不一致,无法扫描到,因此无法生效)。基于SpringBoot自动装配原理 ,我们可以将其添加到resources目录下的META-INF/Spring.factories文件中:
5.如果我们需要保证其他微服务获取这个拦截器,而网关不获取(登录校验了,所以没必要获取啊),就可以添加注解
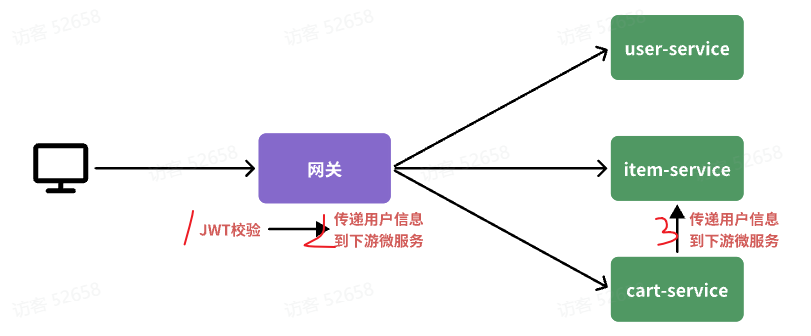
2.7 问题三-微服务之间怎么传递用户信息 前端发起的请求都会经过网关再到微服务,由于我们之前编写的过滤器和拦截器功能,微服务可以轻松获取登录用户信息。
但有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务。
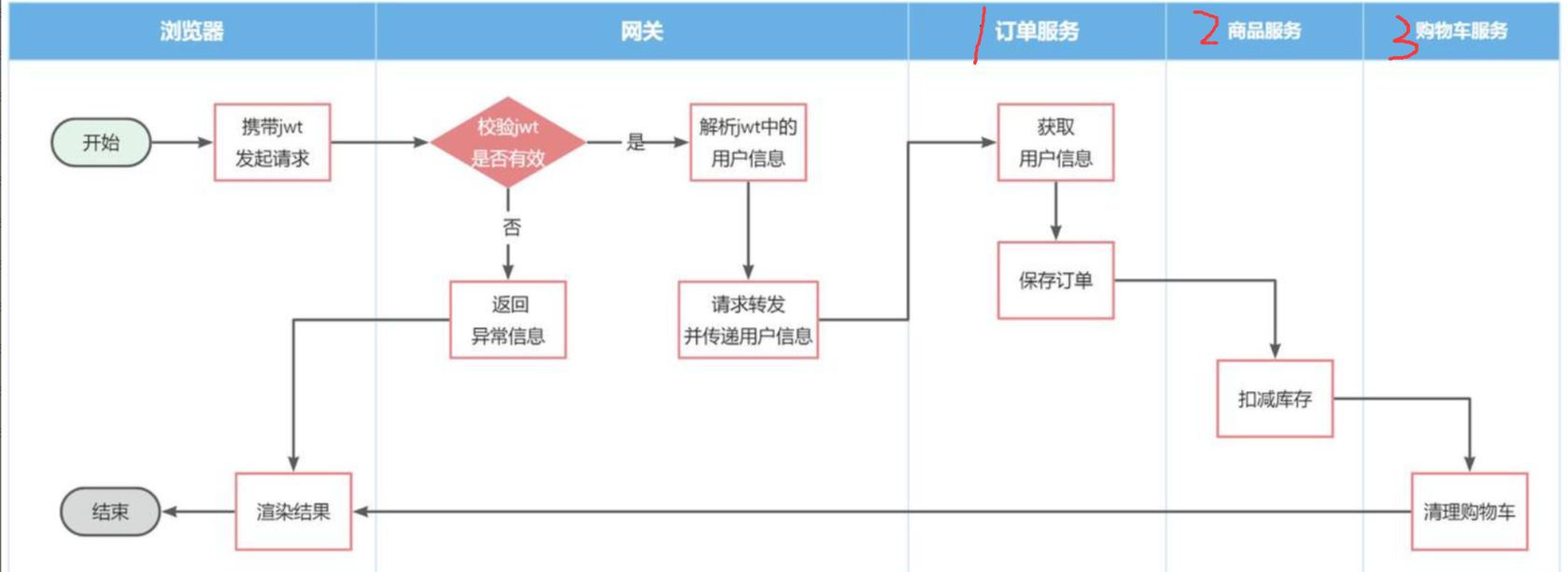
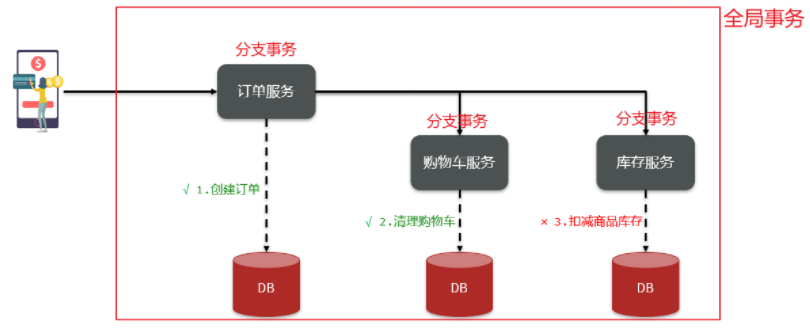
比如下单业务 ,流程如下:
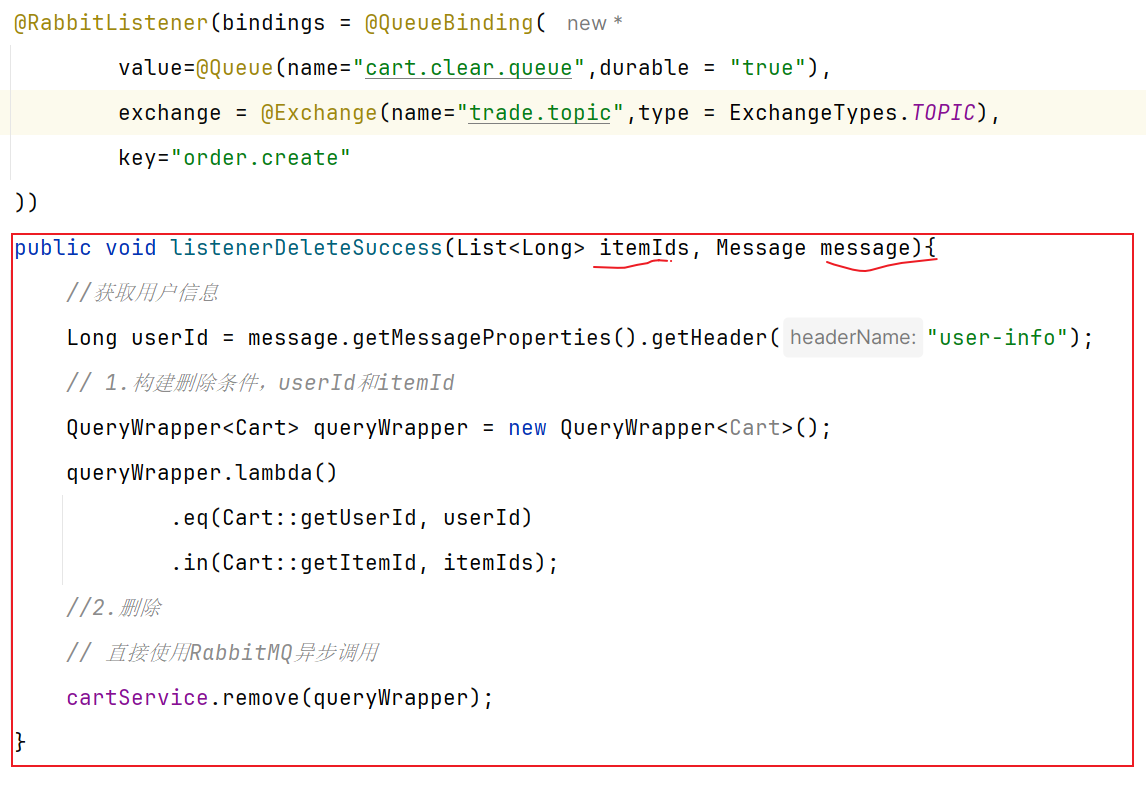
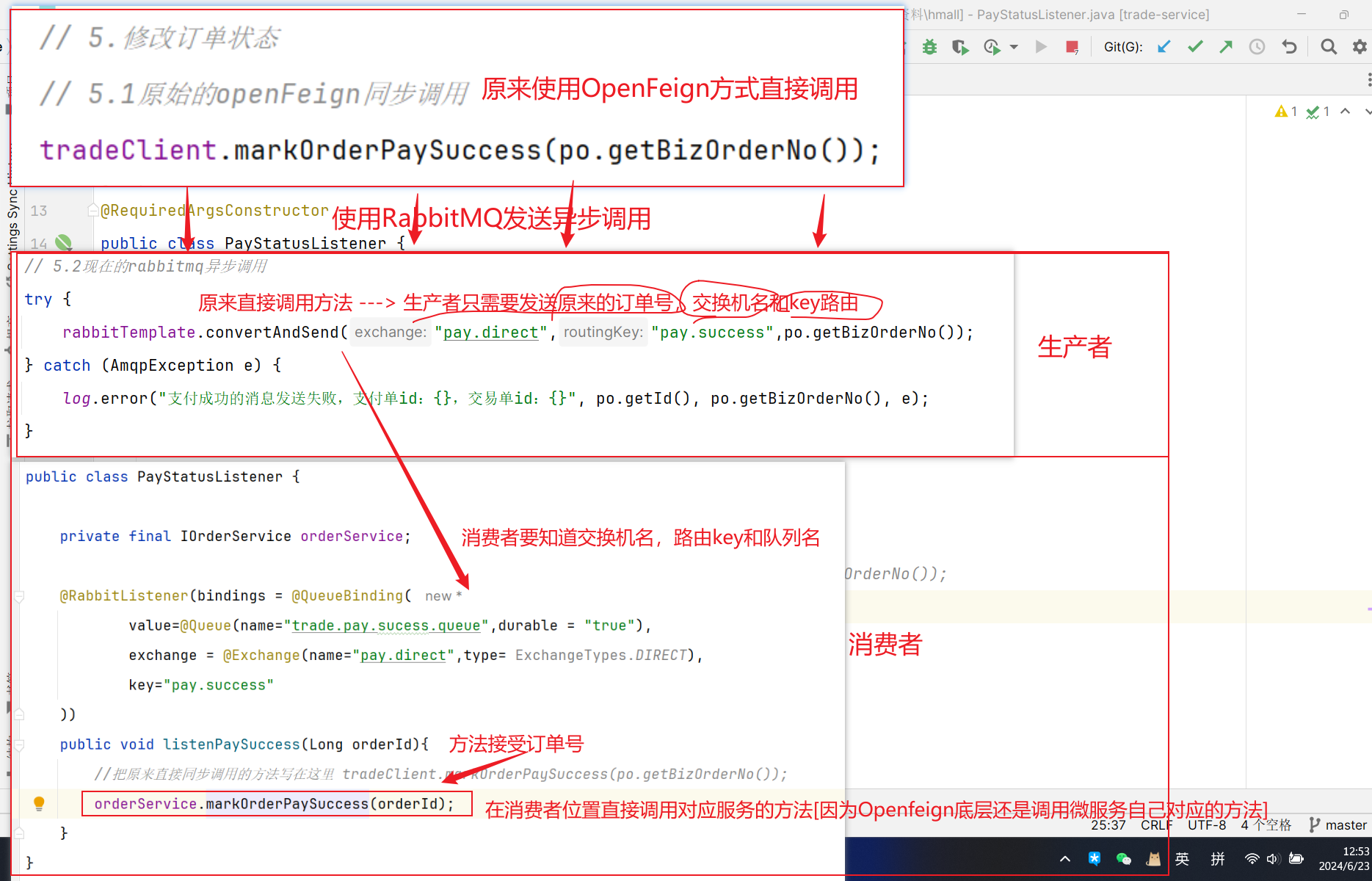
下单的过程中,需要调用商品服务扣减库存,调用购物车服务清理用户购物车。而清理购物车时必须知道当前登录的用户身份。但是,订单服务调用购物车时并没有传递用户信息 ,购物车服务无法知道当前用户是谁!
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头 。
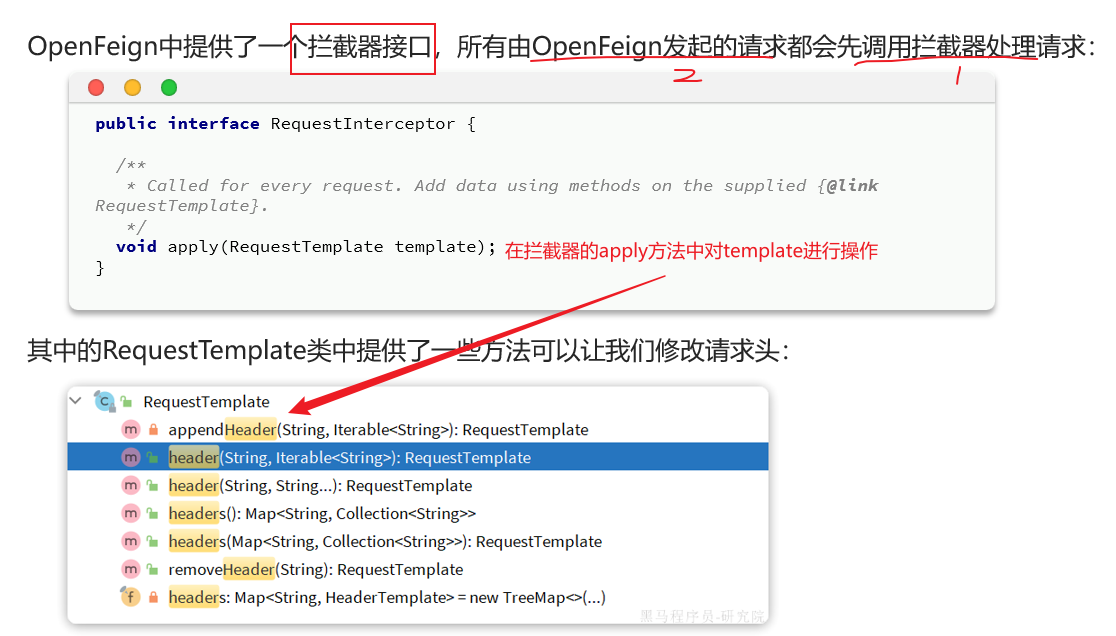
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?–借助Feign中提供的一个拦截器接口:RequestInterceptor
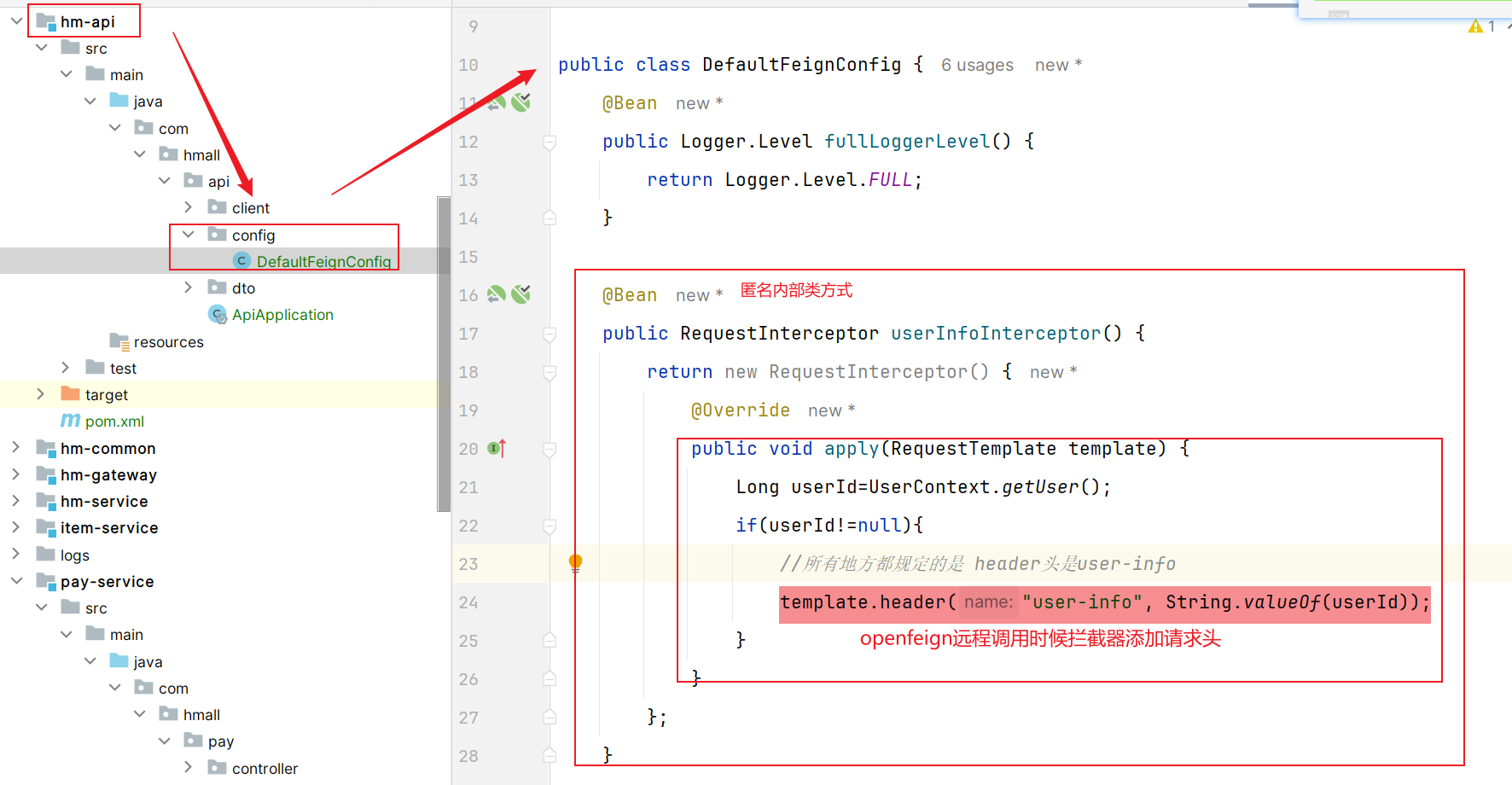
我们只需要==实现这个接口,然后实现apply方法,利用RequestTemplate类来添加请求头,将用户信息保存到请求头中==。这样以来,每次OpenFeign发起请求的时候都会调用该方法,传递用户信息。
具体实现:
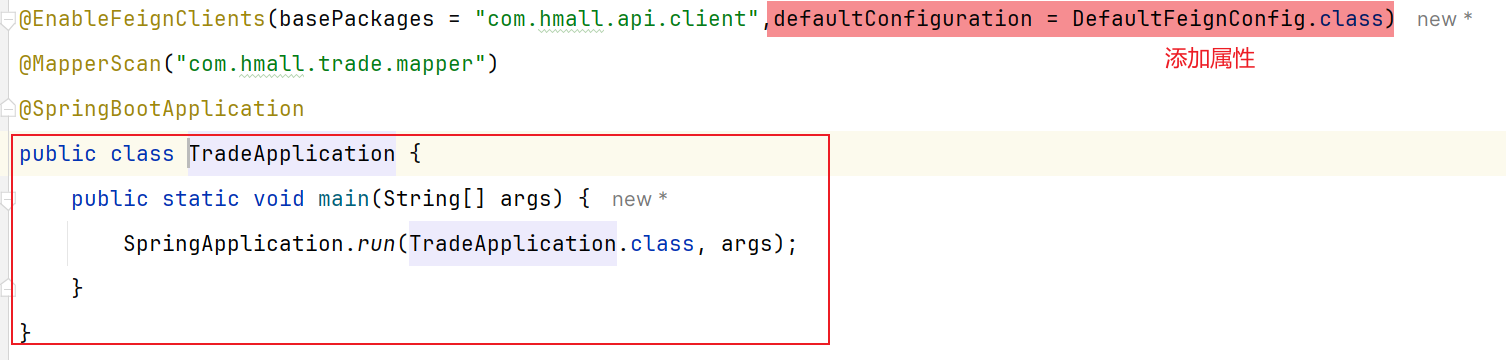
这样注入bean之后如果要使用,就要在Openfeign远程调用的启动类添加:
==总结:网关解决传递信息的三大问题==
1.怎么做到先校验?后转发(网关路由是配置的,请求转发是Gateway内部代码) —在gateway内部工作基本原理的NettyRoutingFilter过滤器前面定义一个过滤器(①路由过滤器②全局过滤器),过滤器中进行校验JWT信息,然后通过mutate方法转发用户信息。
2.怎么做到网关给用户传递用户信息 —网关到微服务通过API添加用户信息到http请求头,微服务通过SpringMVC拦截器获取用户信息,将用户信息存储到ThreadLocal中
3.怎么做到用户之间调用传递用户信息 —就是利用发送http请求(Openfeign)时通过提供的拦截器添加
[JWT里面传递UserId信息,网关添加过滤器进行校验token同时将UserId添加到请求头,通过mutate方法传递给微服务,微服务通过SpringMVC拦截器获取UserId信息,然后存储到ThreadLocal,业务就可以使用。如果微服务之间调用就通过OpenFeign发送http请求的时候添加拦截器保存UserId]
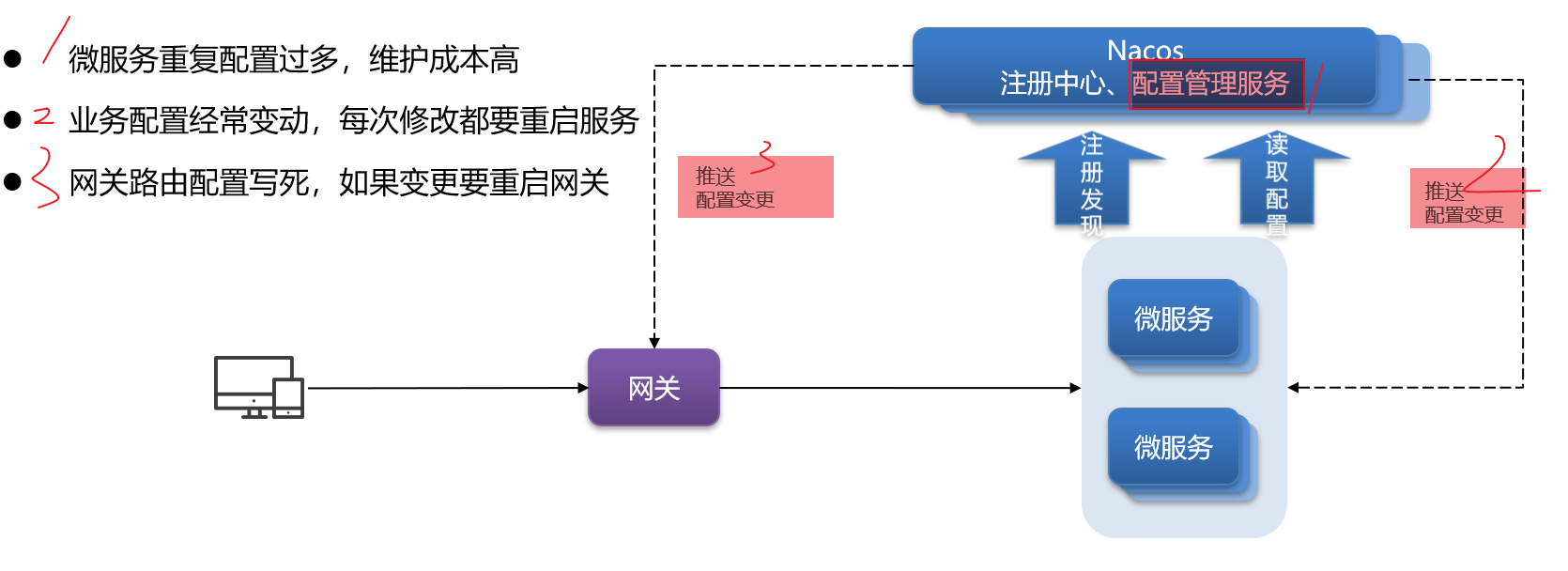
==配置管理–高效维护配置和动态变更属性== 1.微服务重复配置过多,维护成本高 —-> 共享配置
2.业务配置经常变动,每次修改都要重启服务 —-> 热更新
3.网关路由配置写死,如果变更就要重启网关 —-> 热更新
这些问题都可以通过统一的配置管理器服务[Nacos第二大特性] 解决 —–Nacos不仅仅具备注册中心功能,也具备配置管理的功能:
微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。
网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
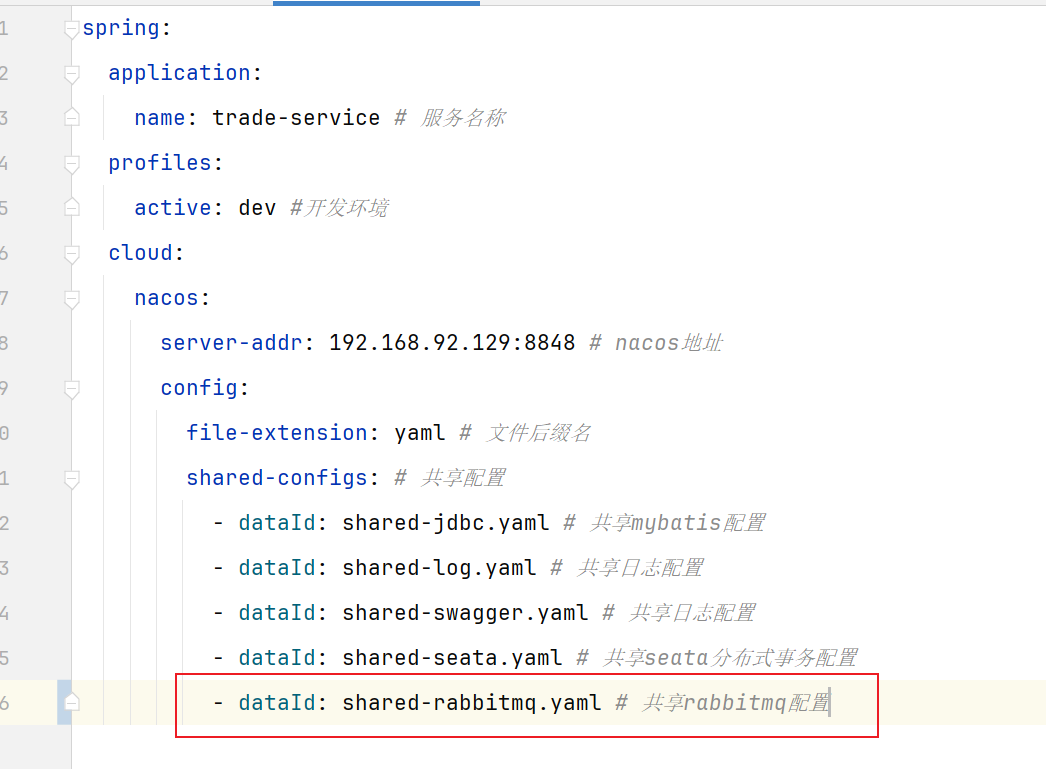
1.配置共享 我们可以把微服务共享的配置抽取到Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
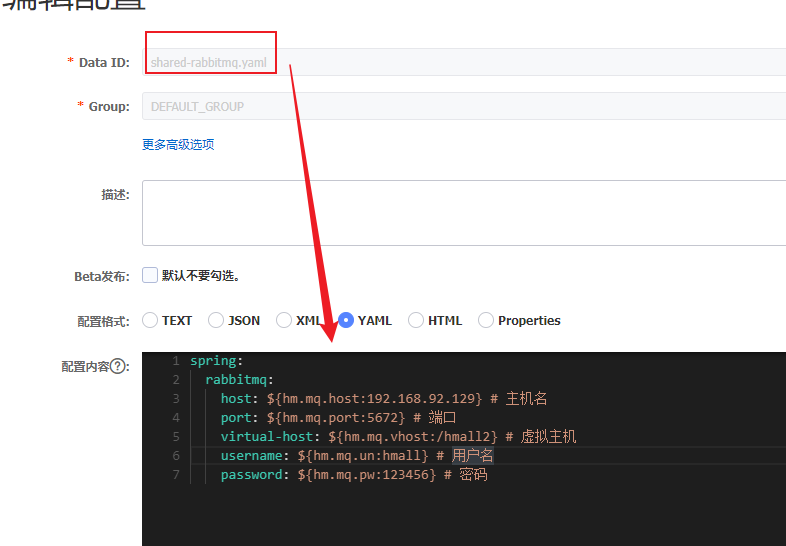
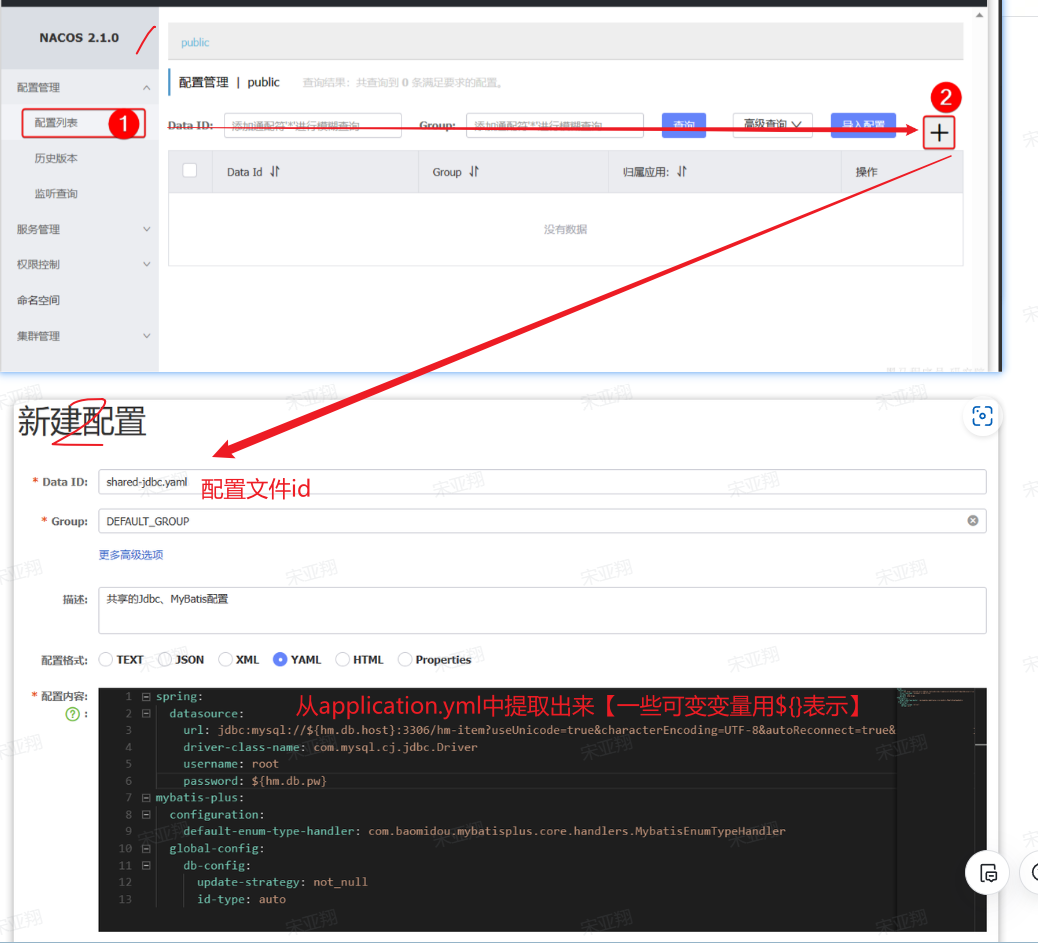
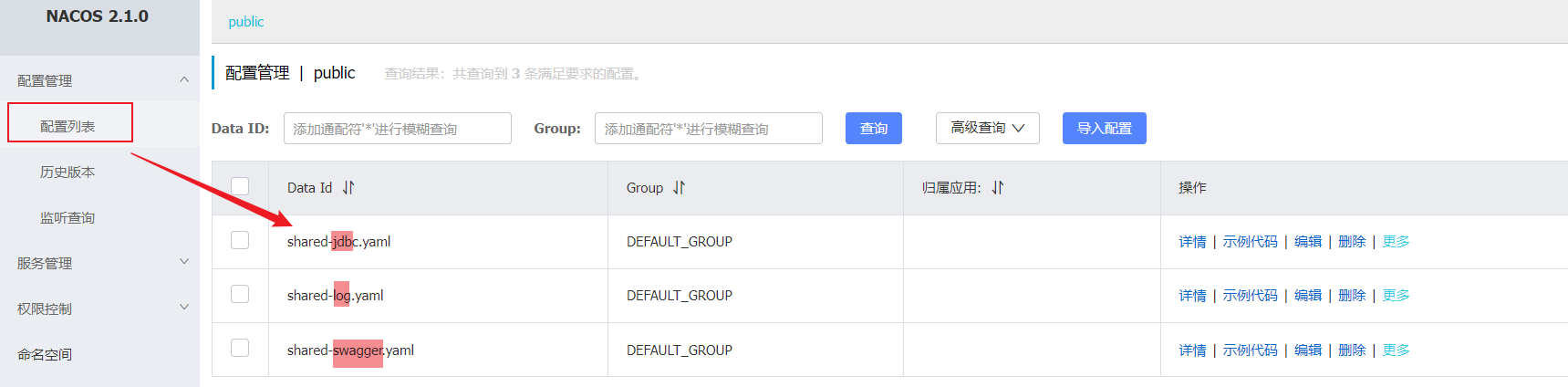
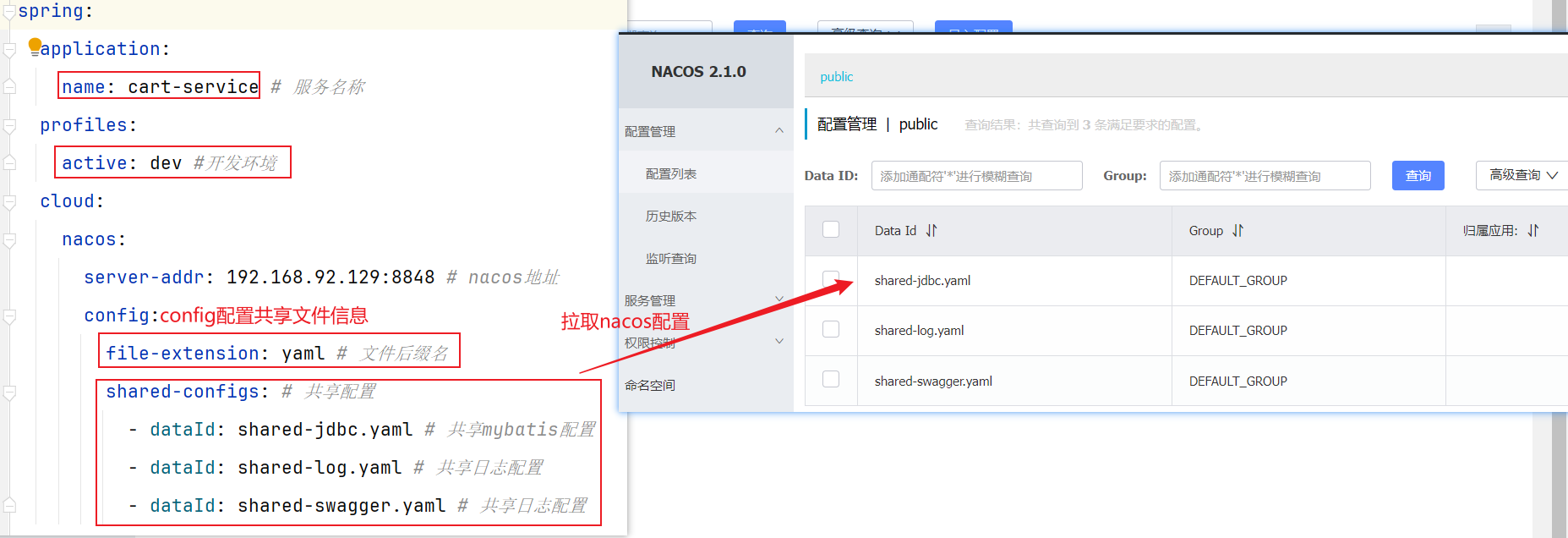
1.1 添加共享配置 在nacos控制台分别添加微服务共同配置:
最终形成多个yaml文档:
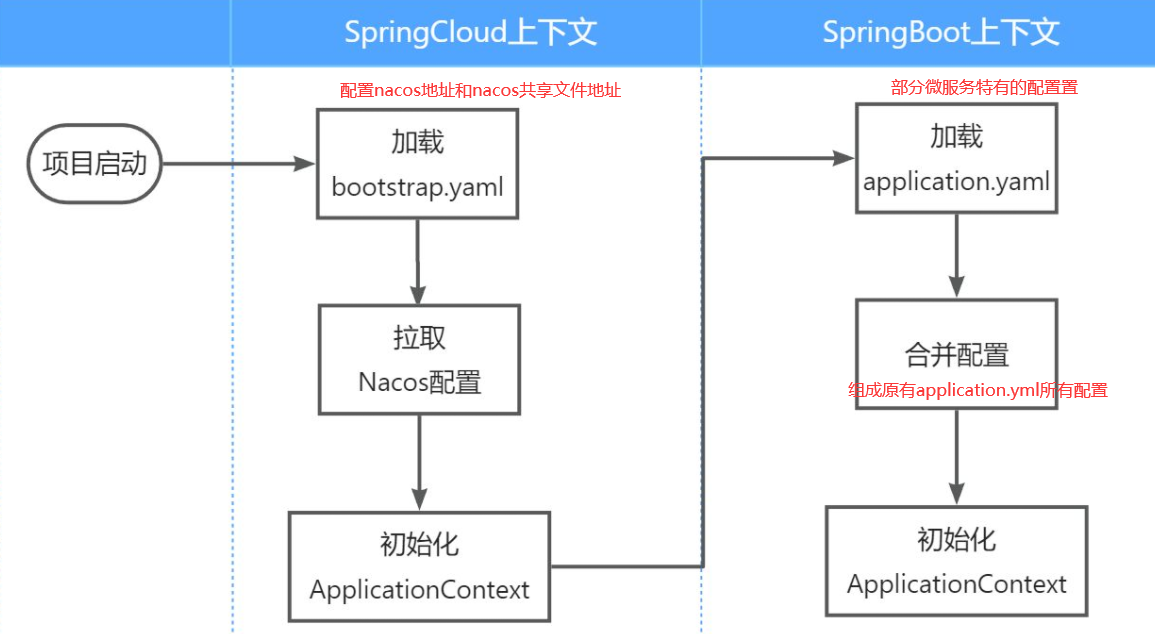
1.2 拉取共享配置 将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
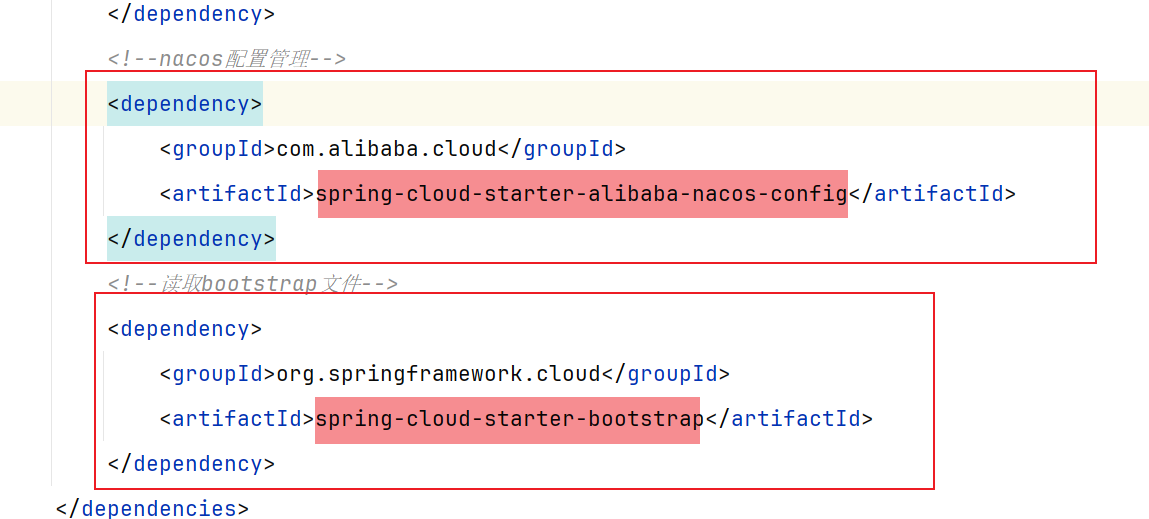
1.2.1 文件读取顺序 1.2.2 拉取步骤
1 2 3 4 5 6 7 8 9 10 <!--nacos配置管理--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> <!--读取bootstrap文件--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-bootstrap</artifactId> </dependency>
1.3 多配置文件读取顺序 可能不同环境下有不同的yaml文件[像单体架构的时候properties,yml,yaml等情况],因此当出现相同属性时就有优先级:==名字越长越牛逼==
1.4 配置共享整理总结 其实就是把原来的application.yml文件拆分成三个部分:①application公共配置;②Nacos地址和读取①文件配置;③application个性化配置
①nacos空间多个共享文件:原来application.yml中多个微服务可共享的信息
②新建bootstrap.yml文件:原来application.yml里面关于nacos的配置+添加config信息(读取nacos配置的多个共同部分yml文件);
③application.yml:保留一部分自己特有的属性和①nacos里面${}需要的属性
2.配置热更新(无需重启) 这就要用到Nacos的配置热更新能力了,分为两步:
在Nacos中添加配置[配置属性]
在微服务读取配置[bootstrap.yml文件拉取配置,具体业务位置使用]
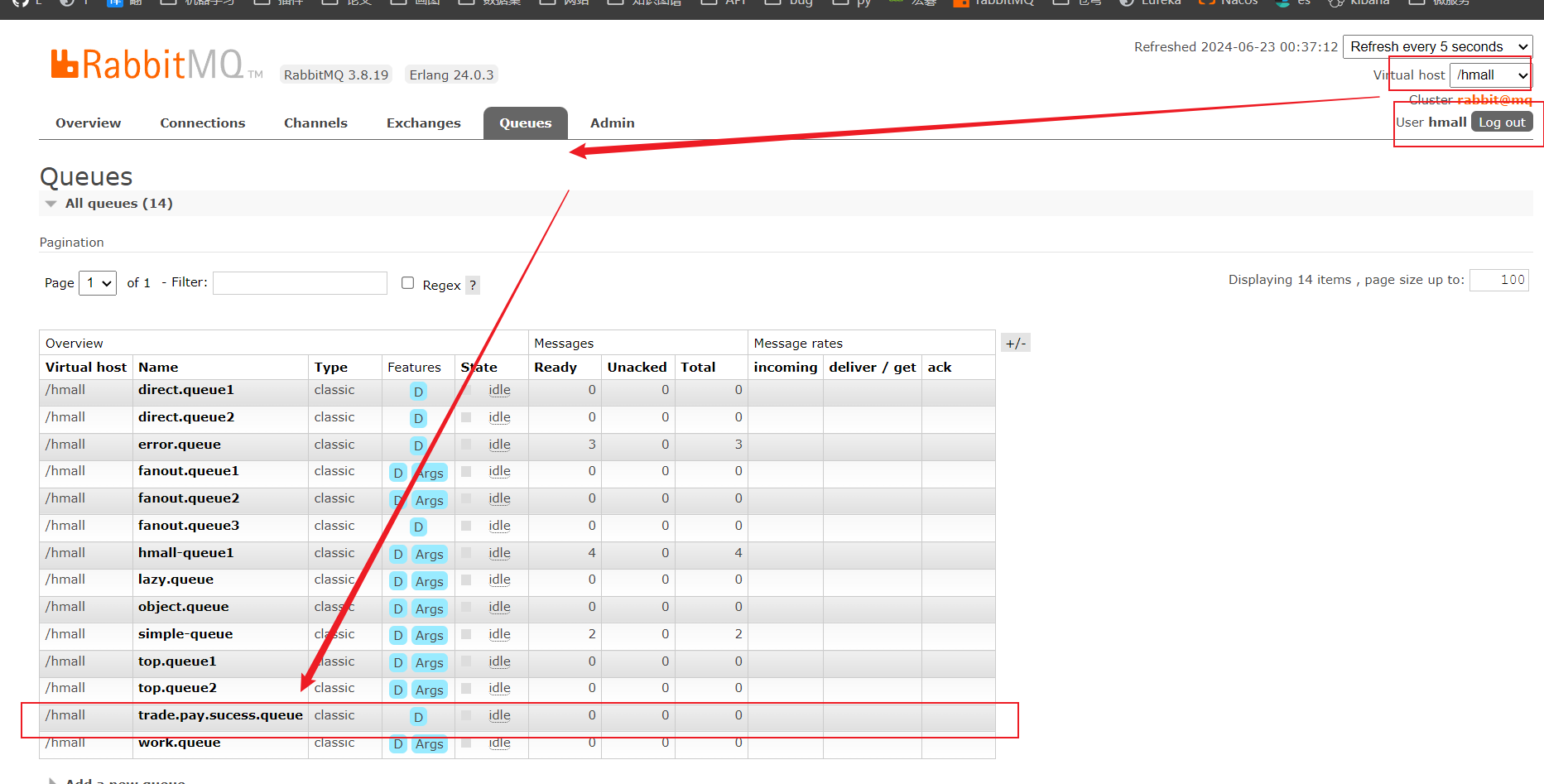
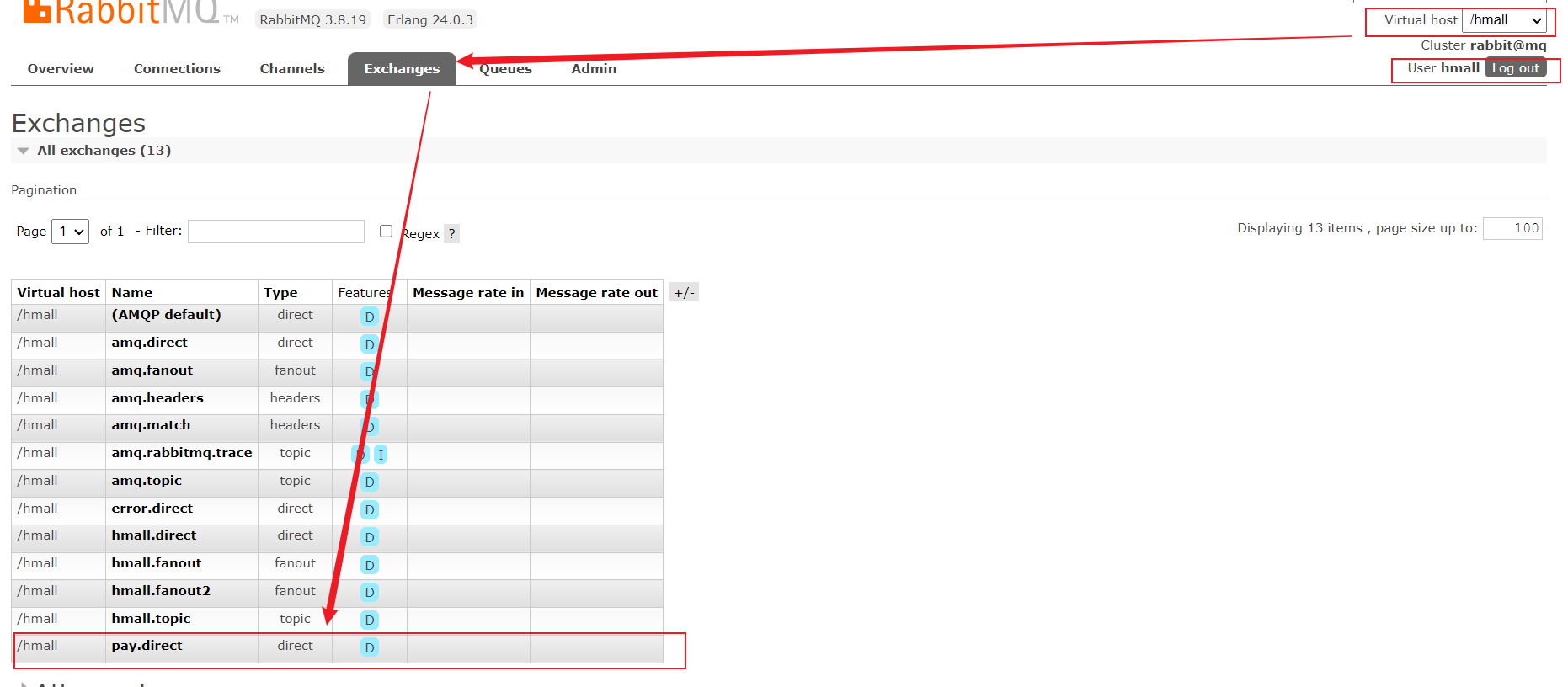
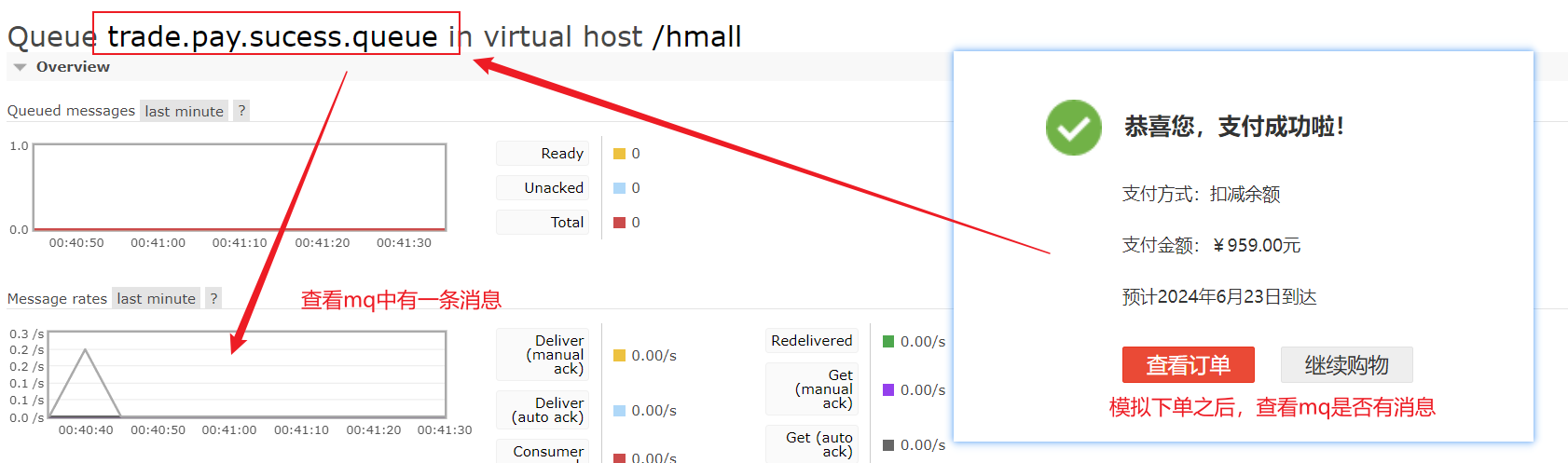
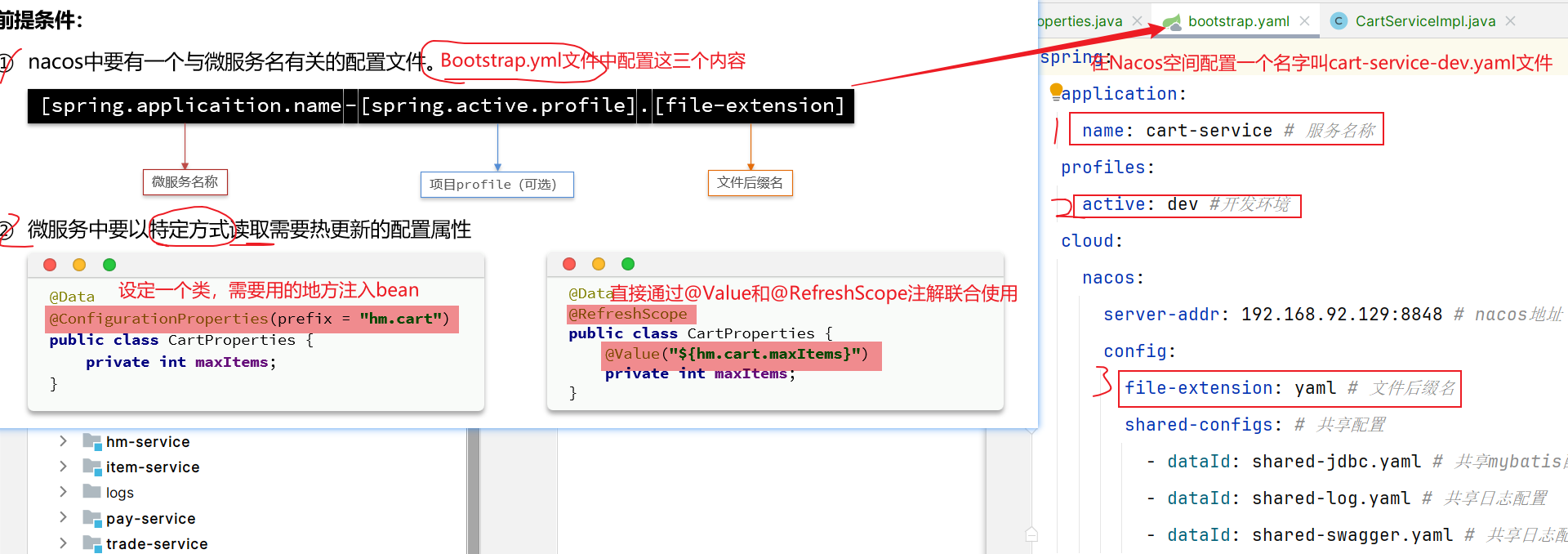
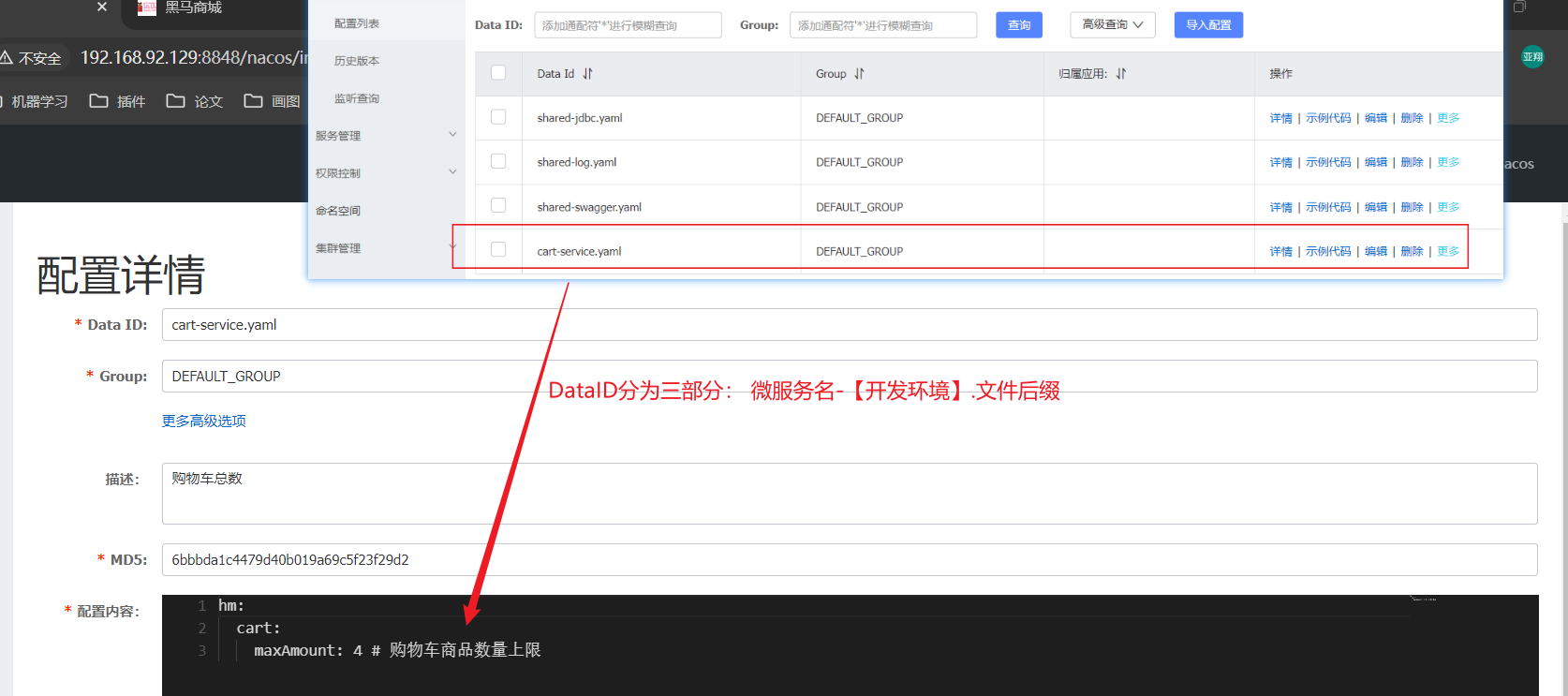
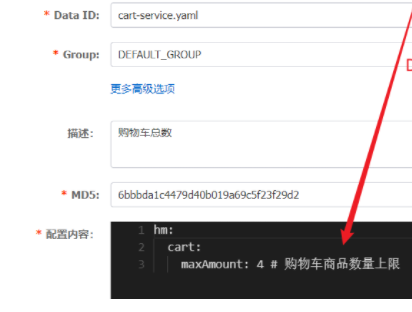
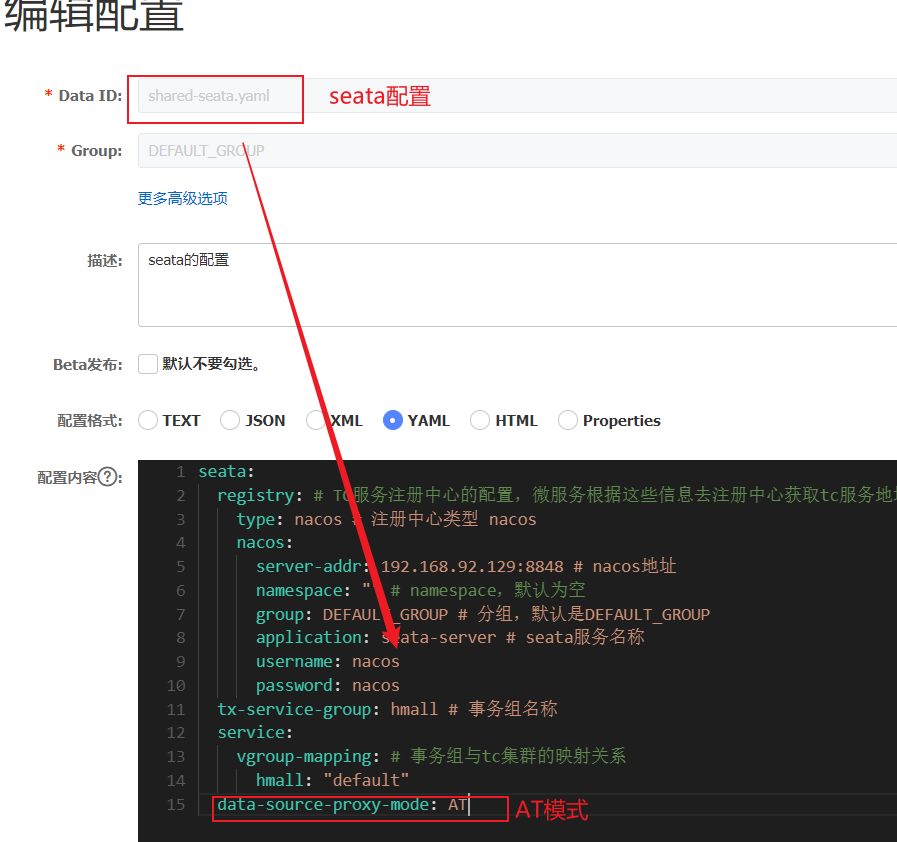
2.1 Nacos配置文件 首先,我们在nacos中添加一个配置文件,将购物车的上限数量添加到配置中:
注意文件的dataId格式:
1 [服务名]-[spring.active.profile].[后缀名]
文件名称由三部分组成:
服务名cart-servicespring.active.profilespring.active.profile,可以省略,则所有profile共享该配置后缀名
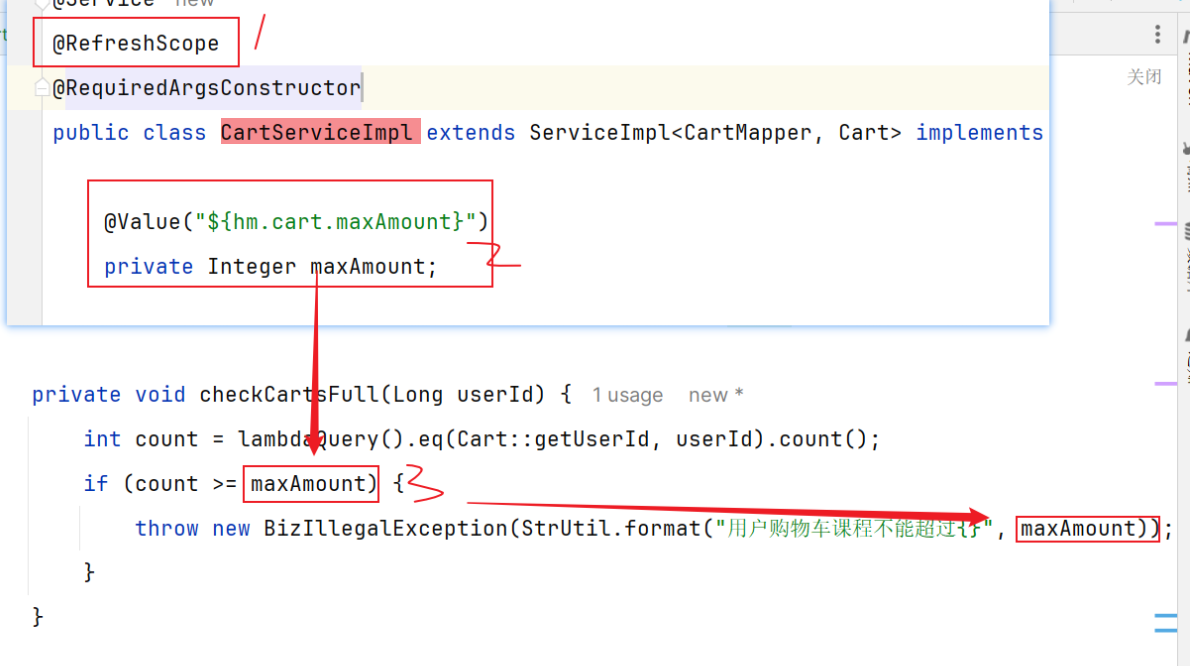
2.2 配置热更新 我们在微服务中读取配置,实现配置热更新。【一般我们使用第一种方式,第二种要用两个注解】
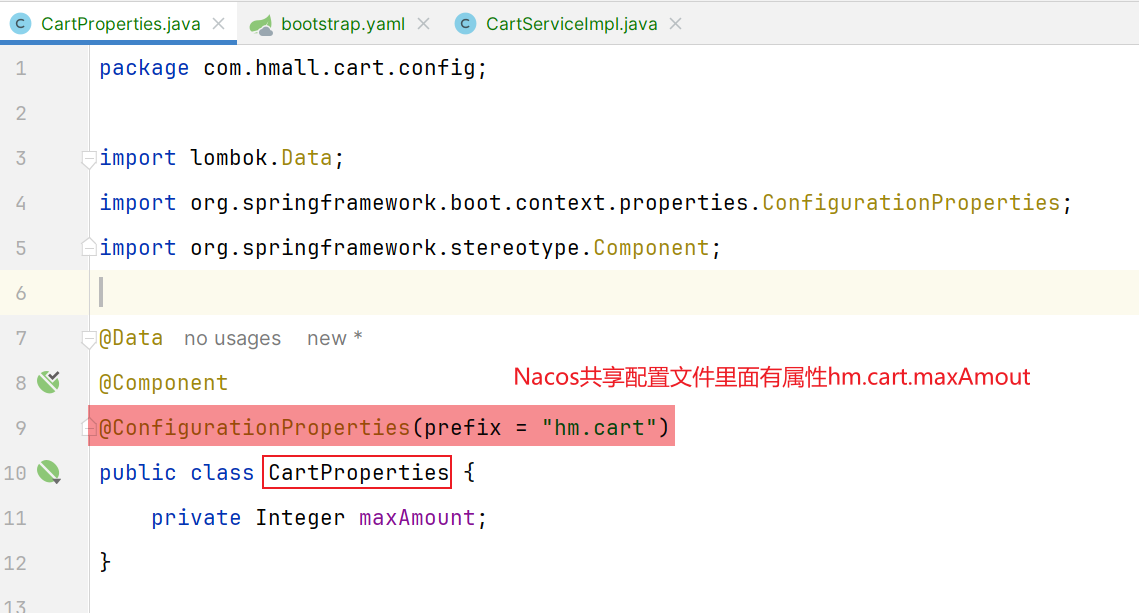
现在我们需要读取Nacos配置文件中的信息hm.cart.maxAmount属性:
2.2.1 方式一 在cart-service中新建一个属性读取类:
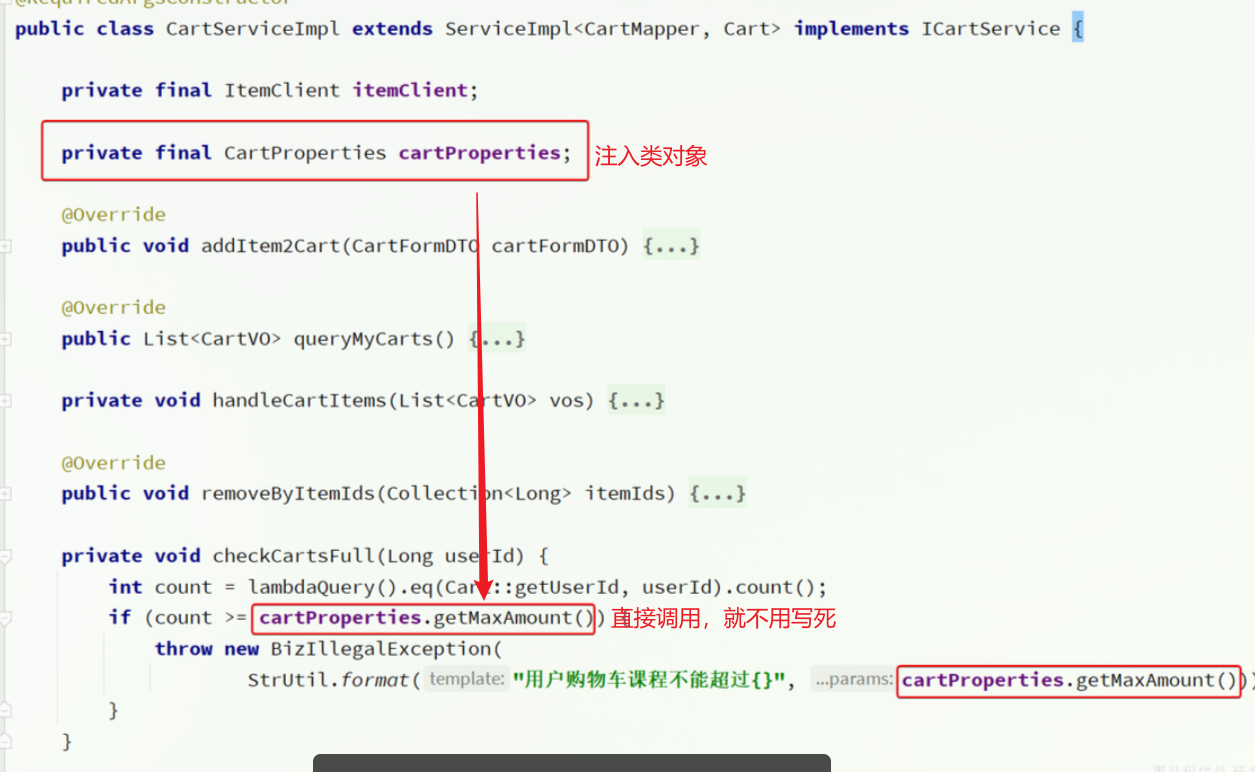
接着,在业务中使用该属性加载类:
2.2.2 方式二 直接搭配@RefreshScope注解和@Value注解获取
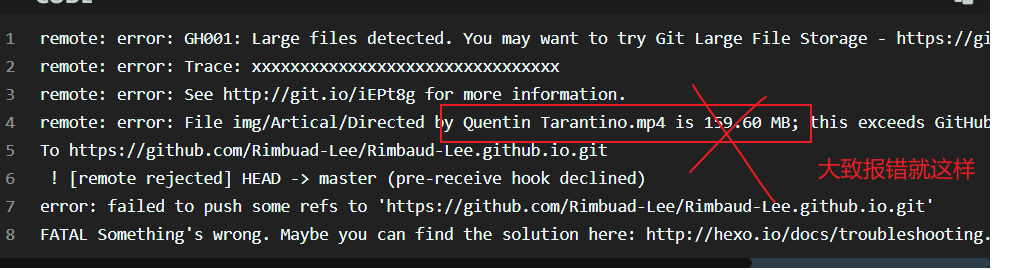
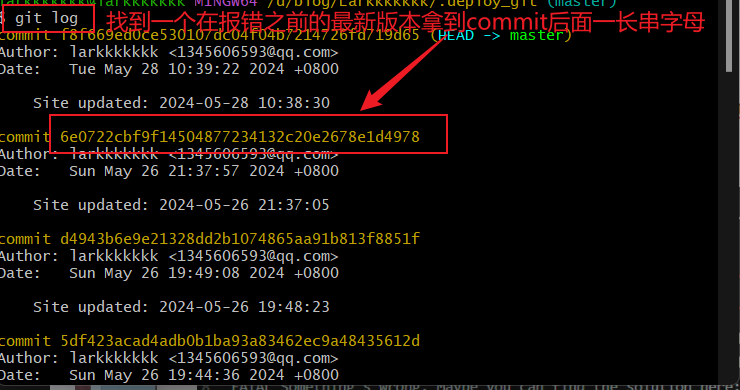
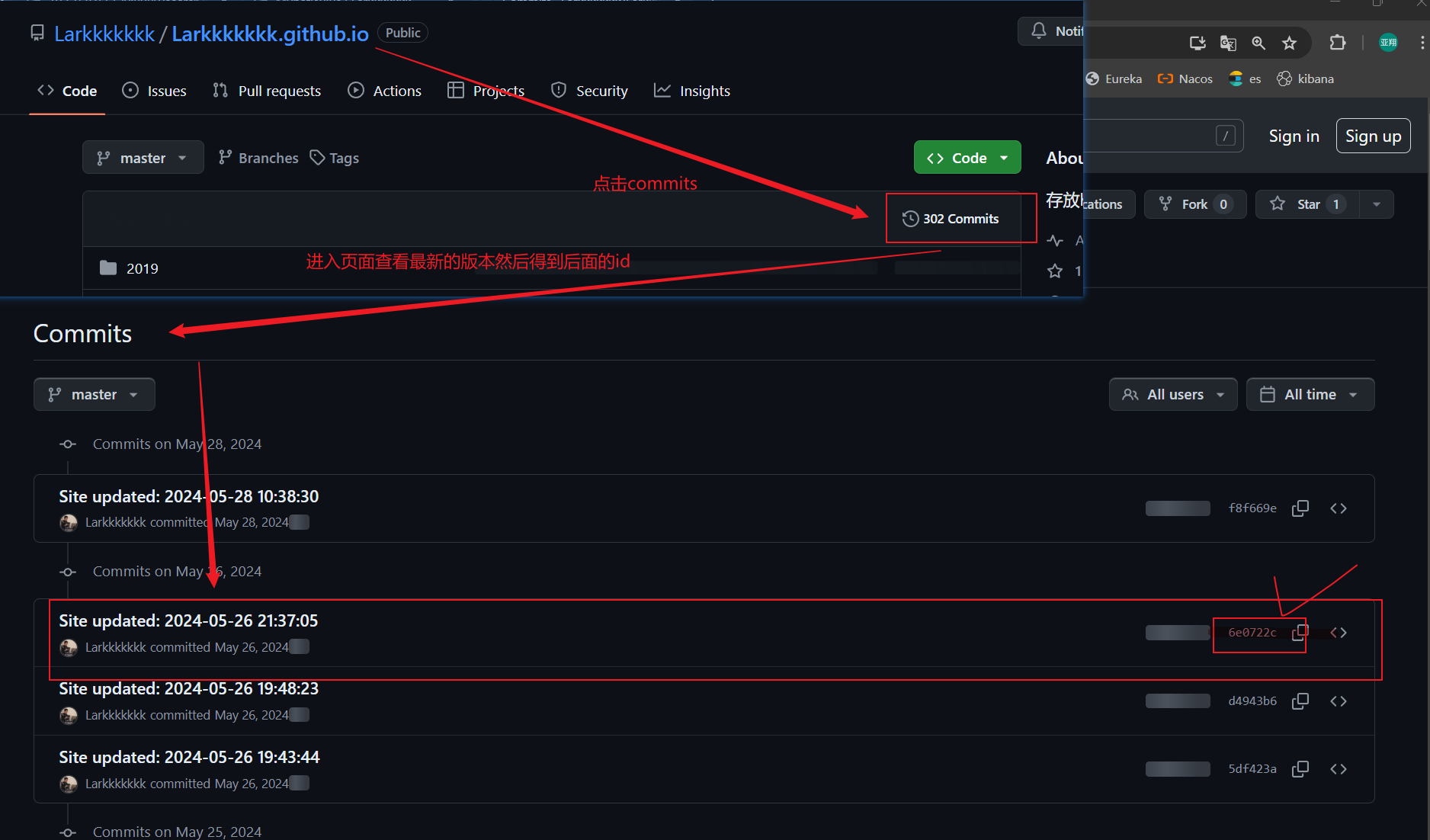
3.动态路由 用到了在学