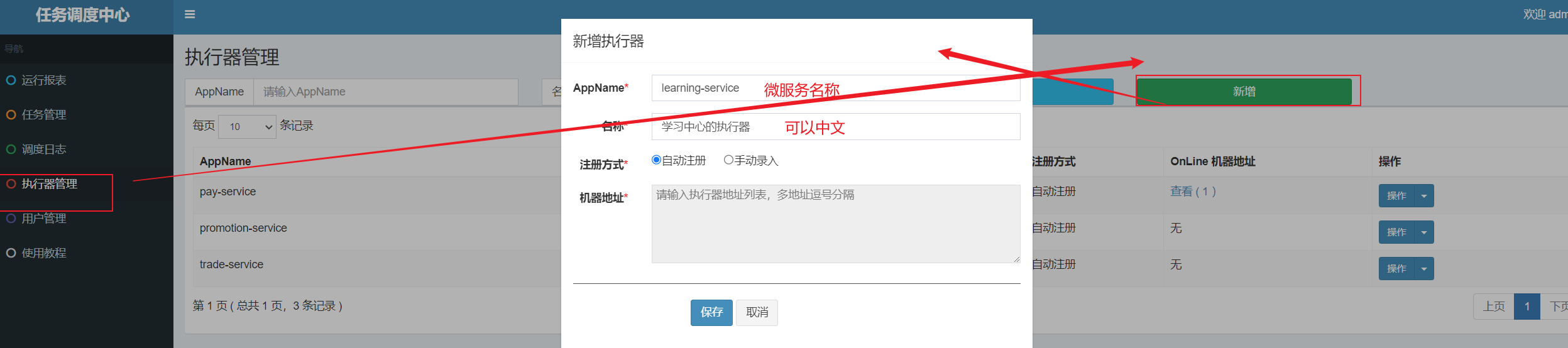
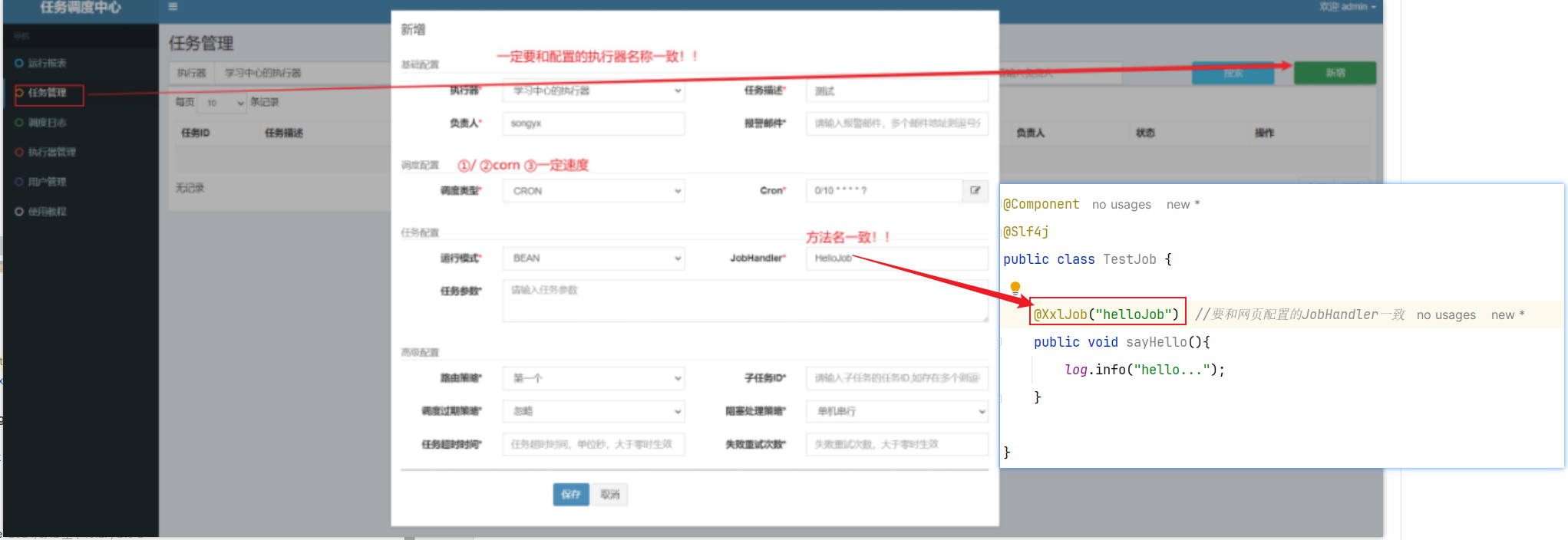
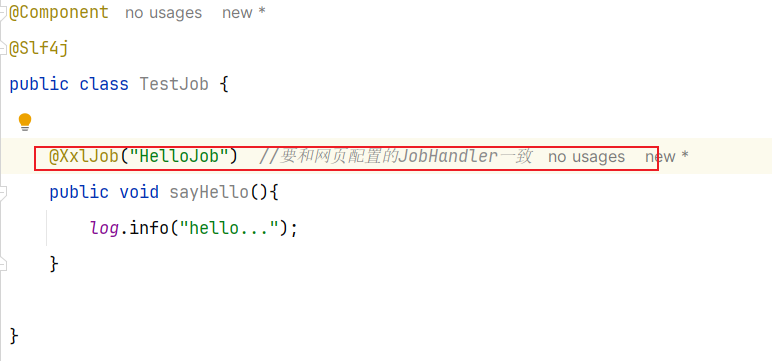
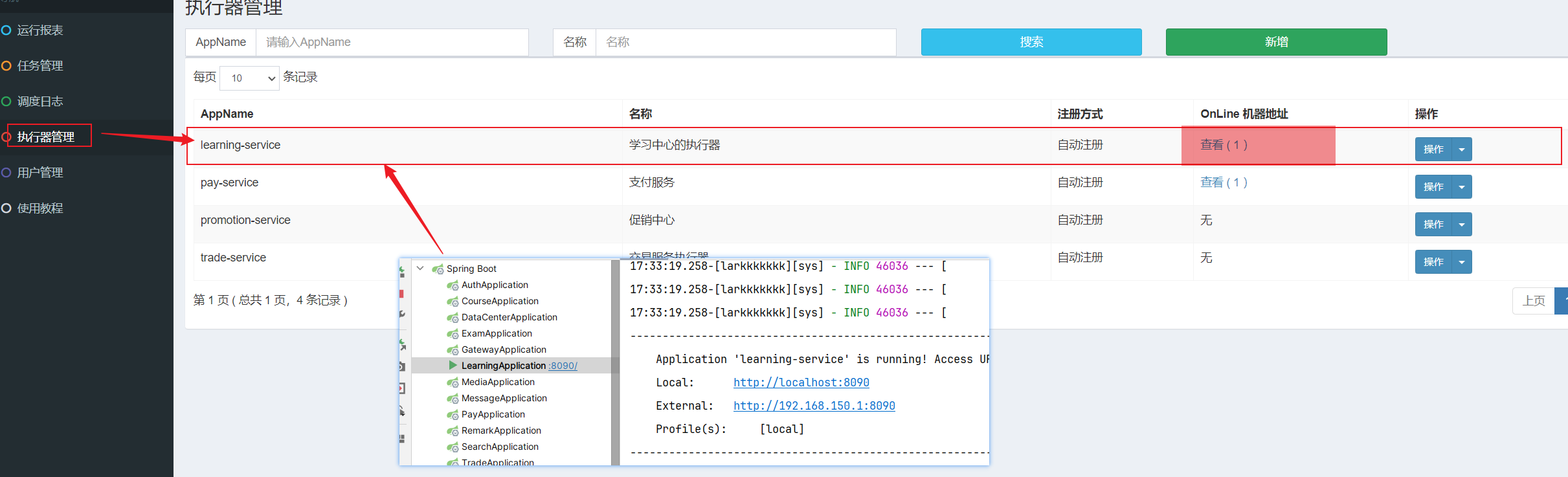
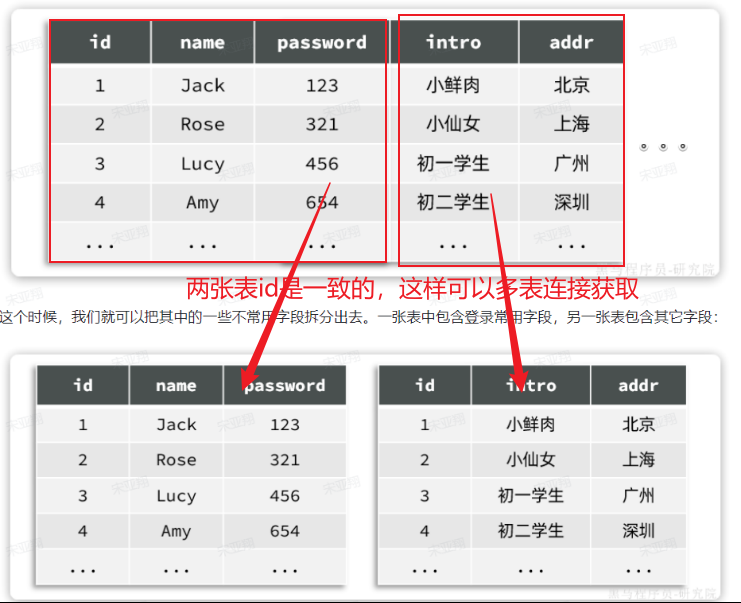
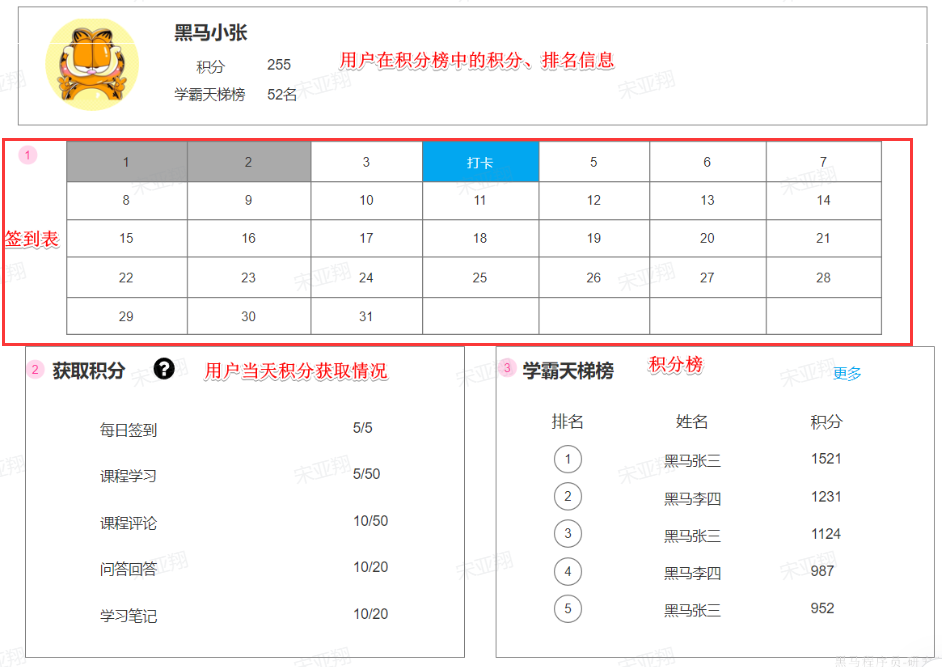
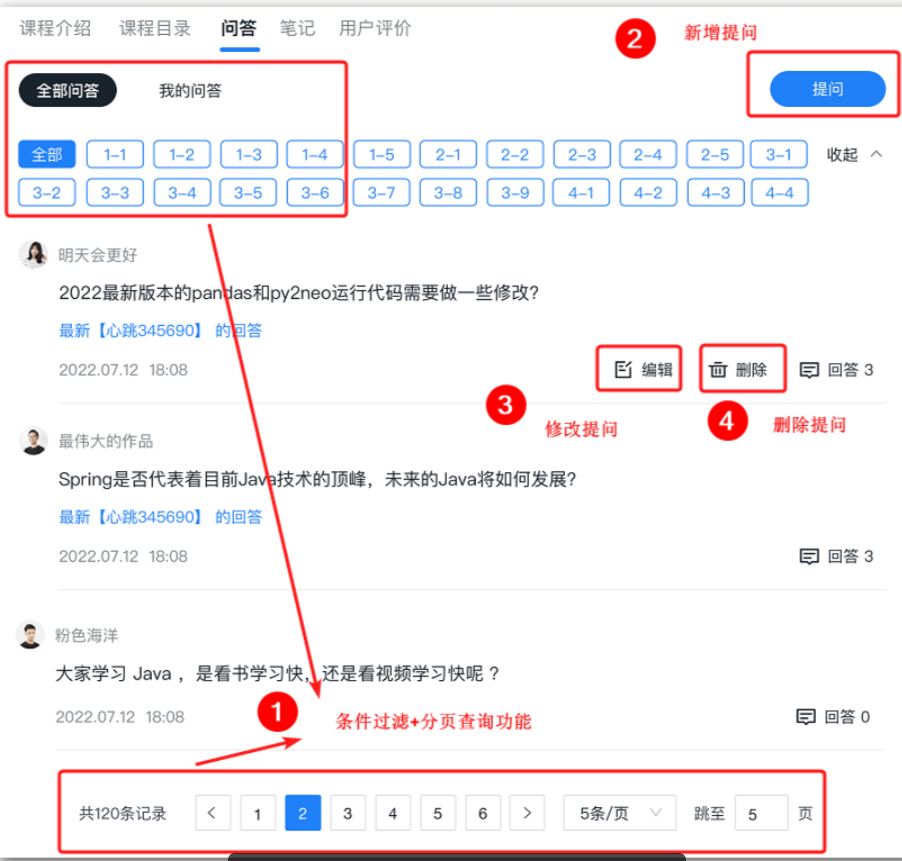
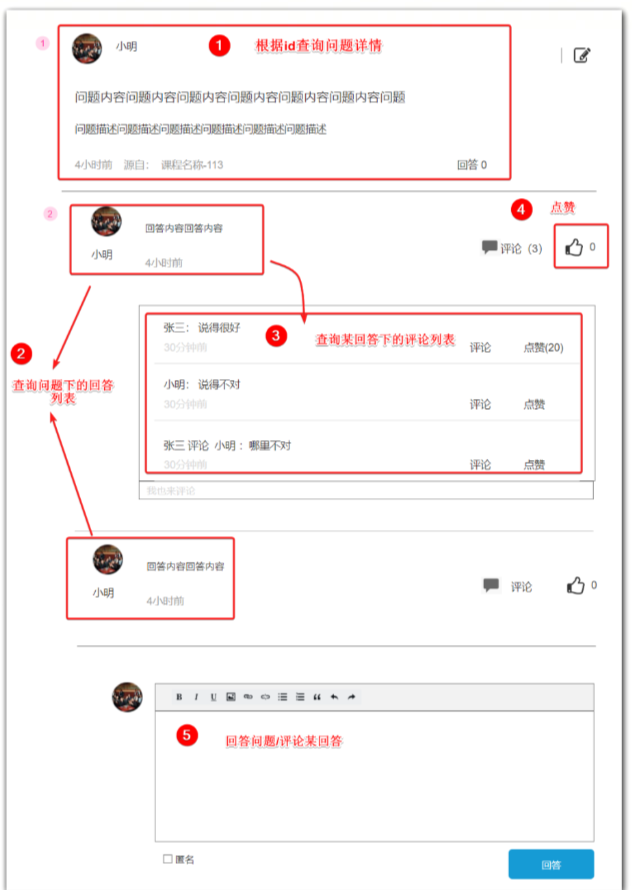
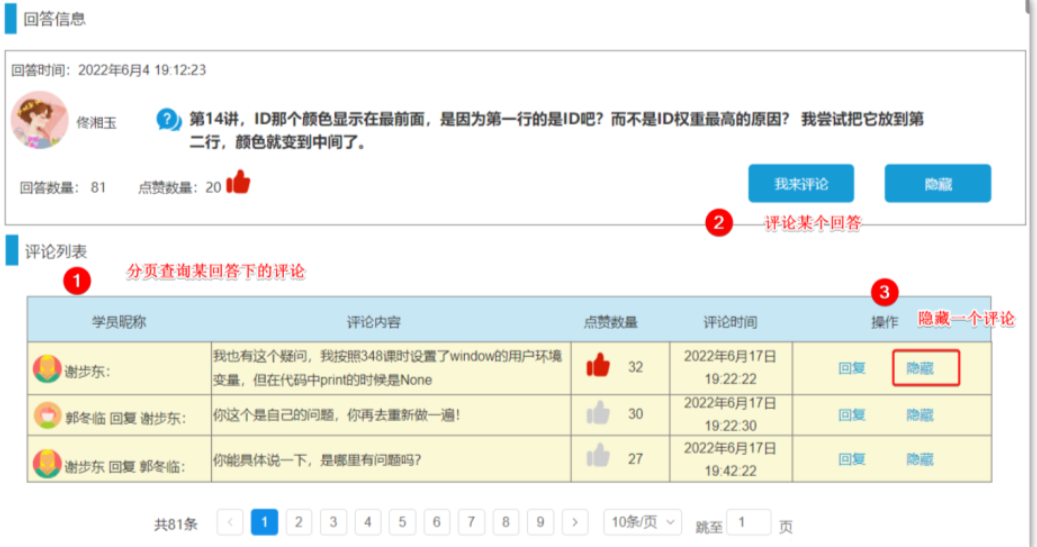
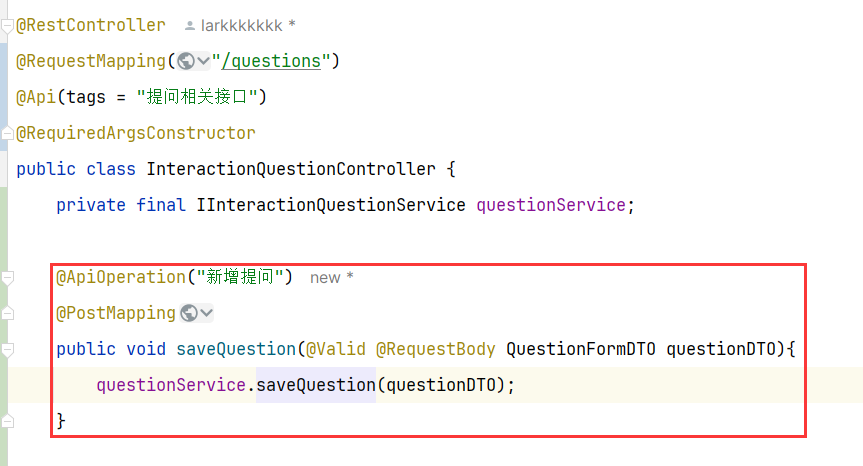
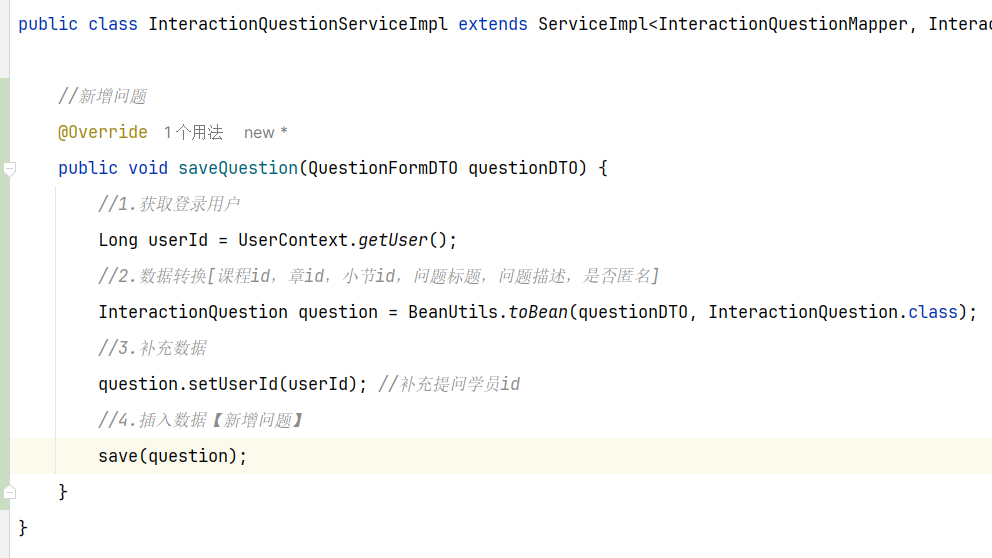
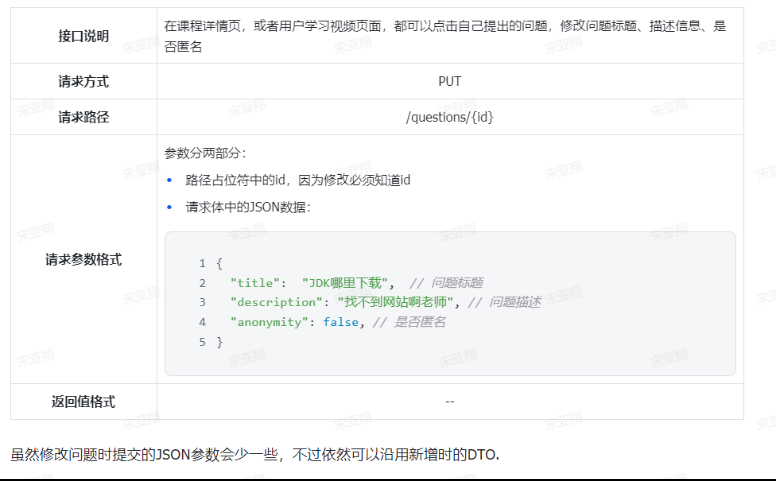
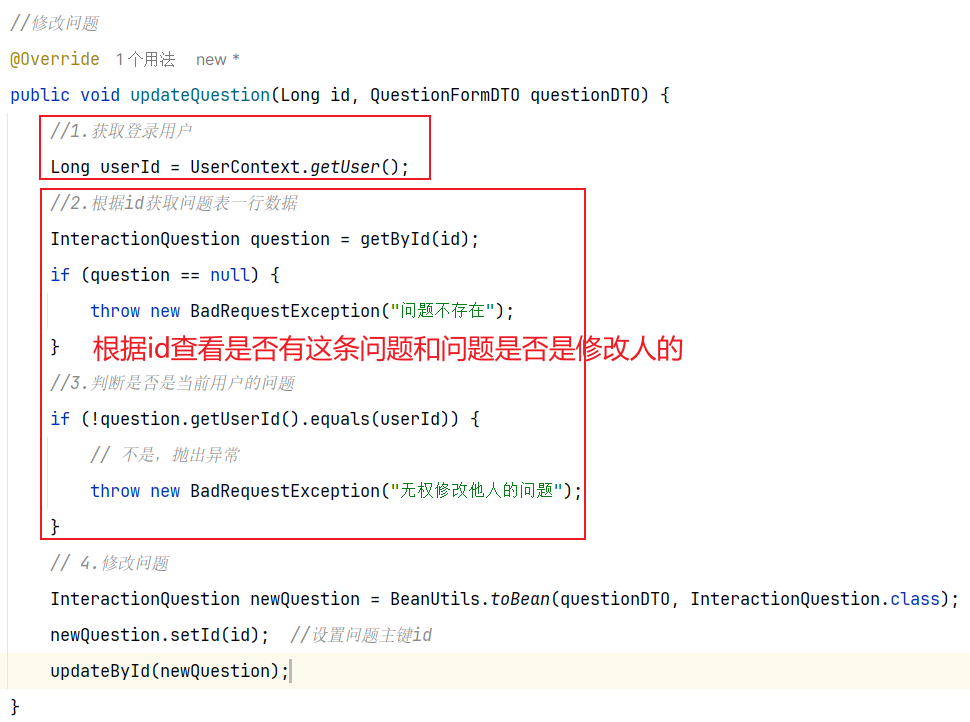
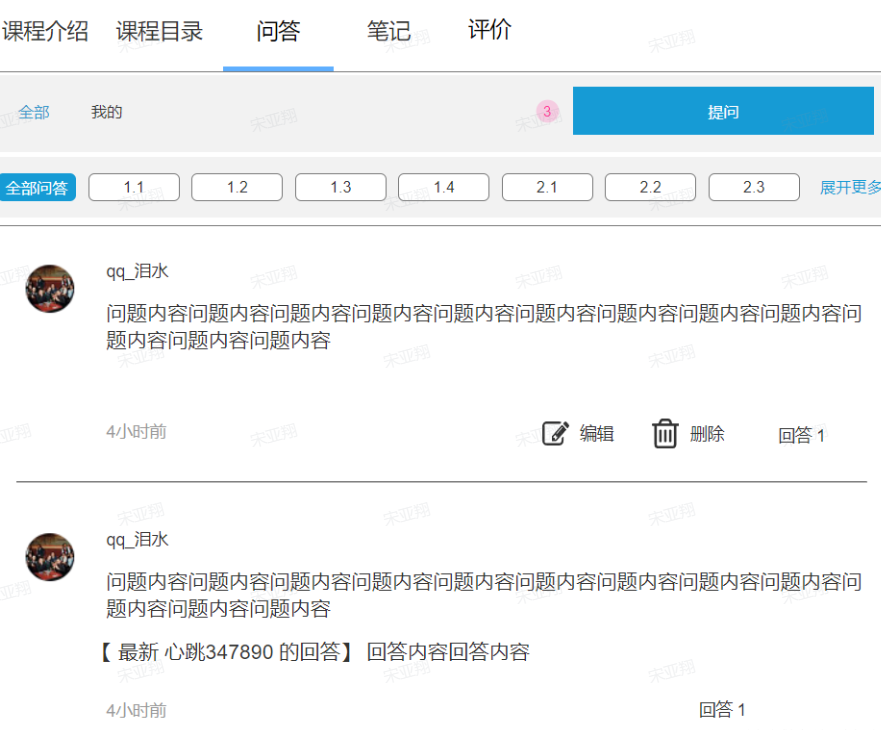
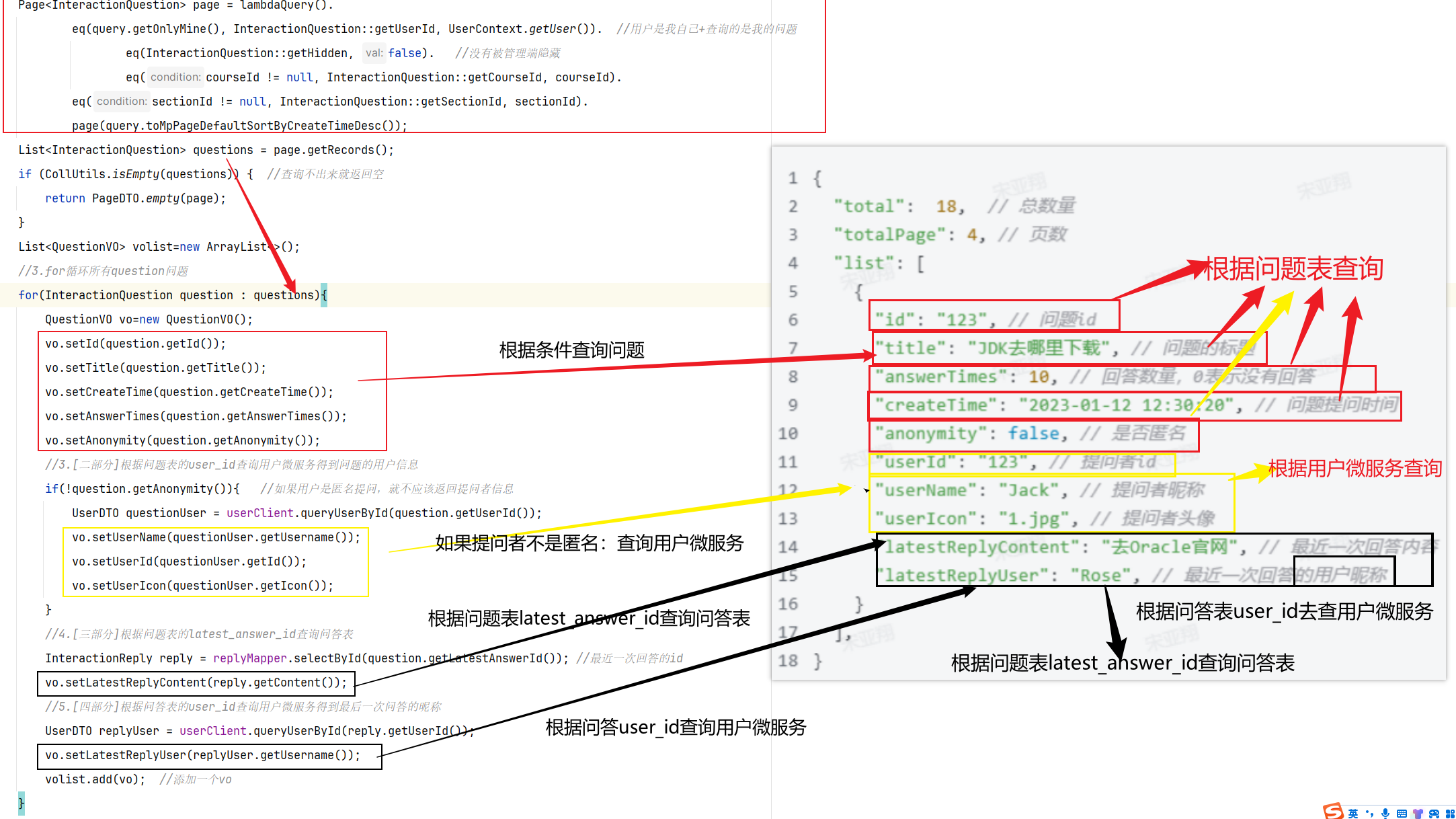
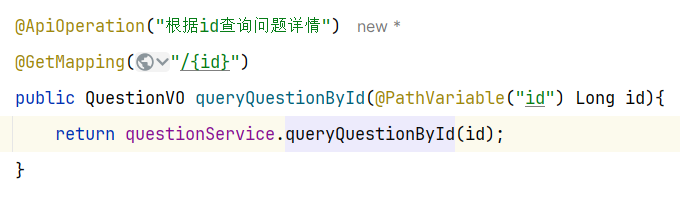
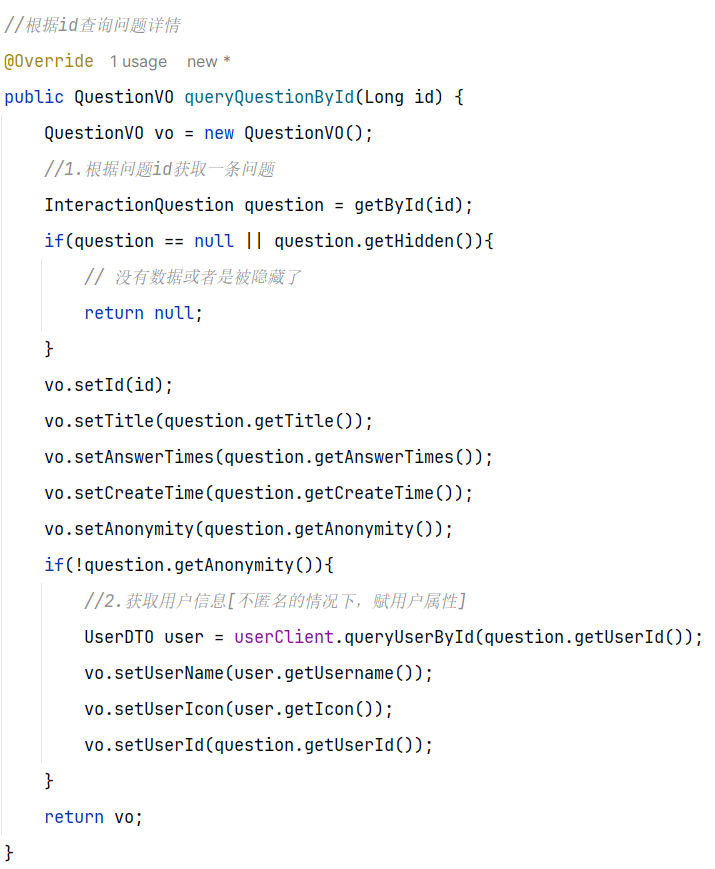
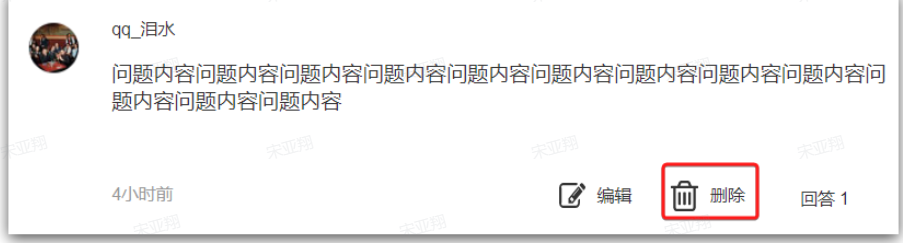
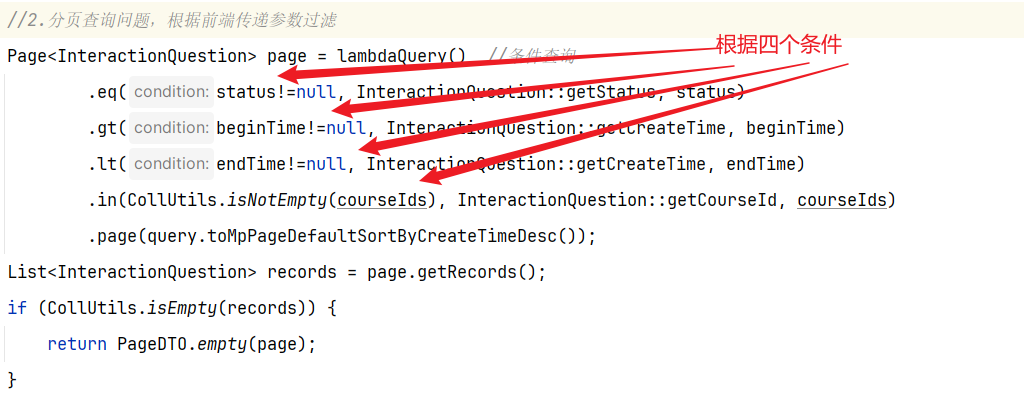
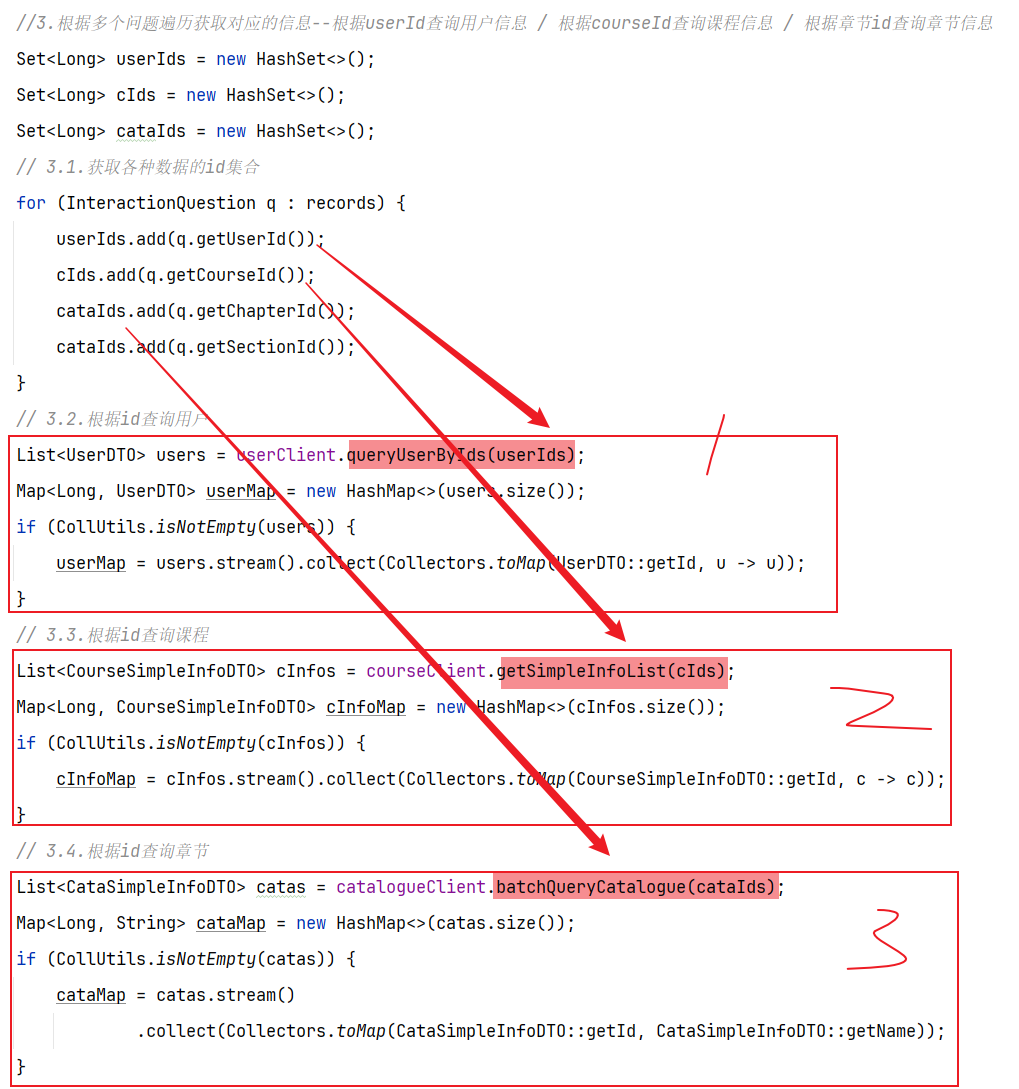
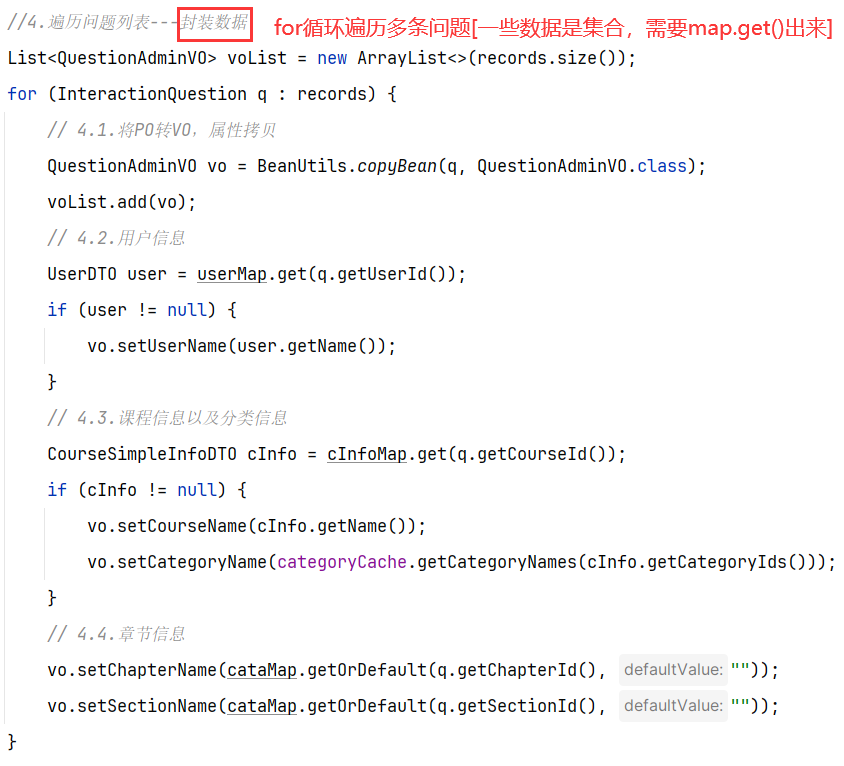
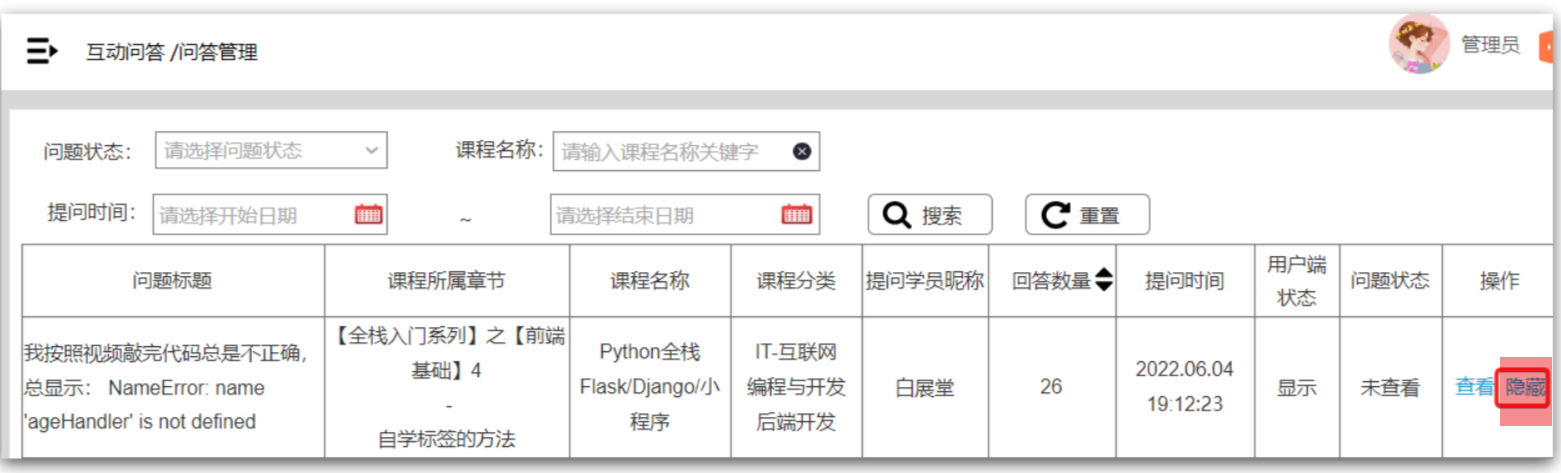
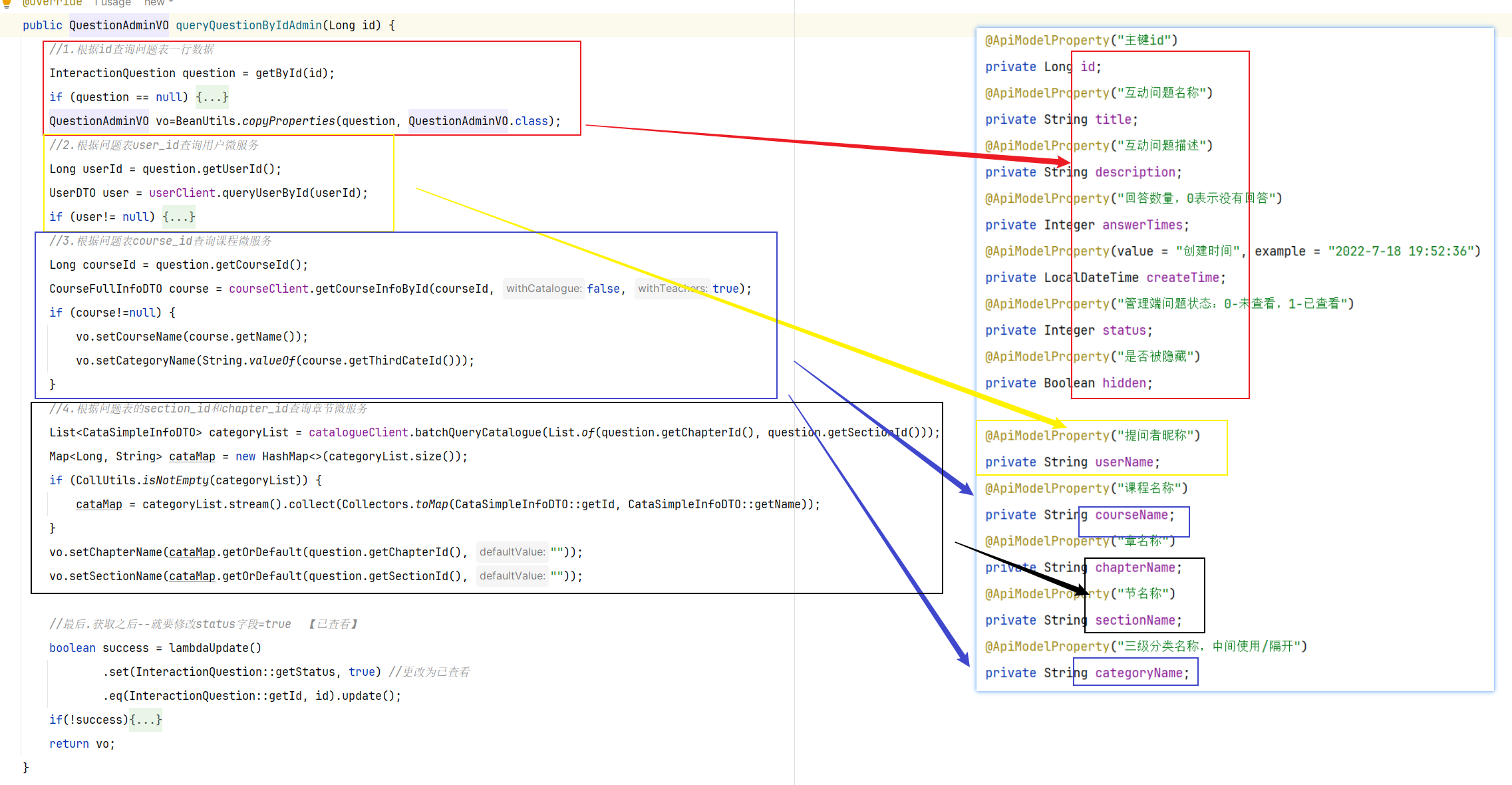
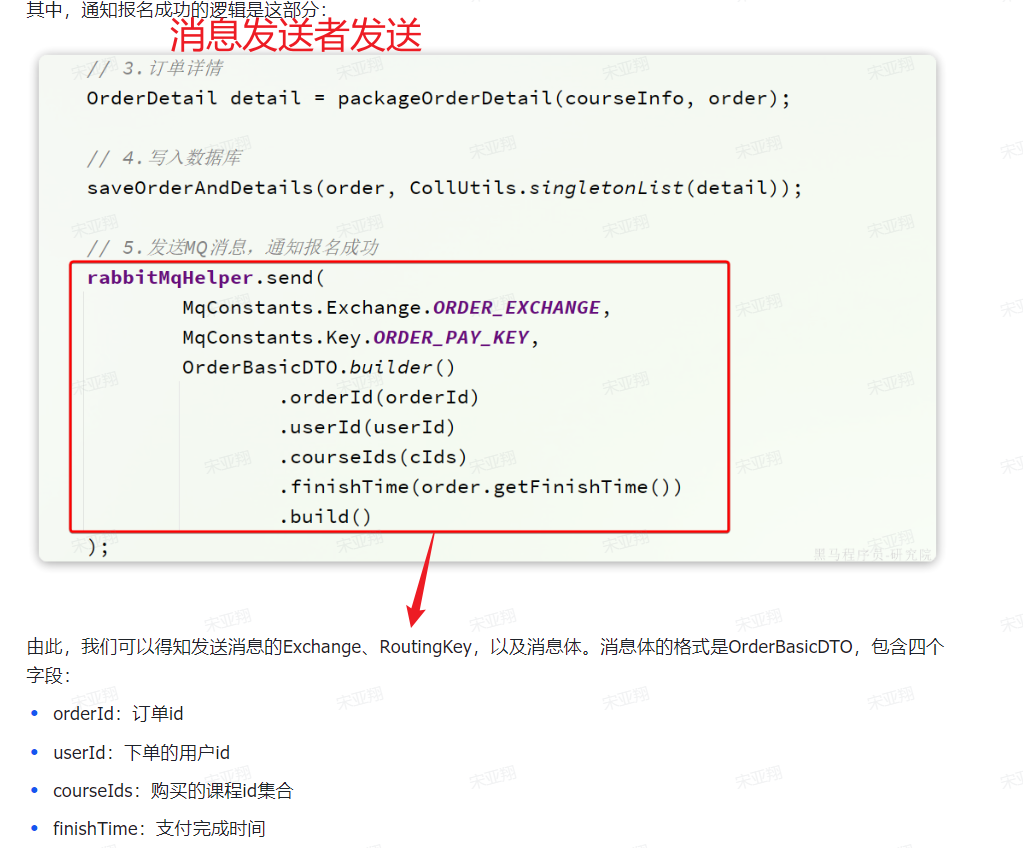
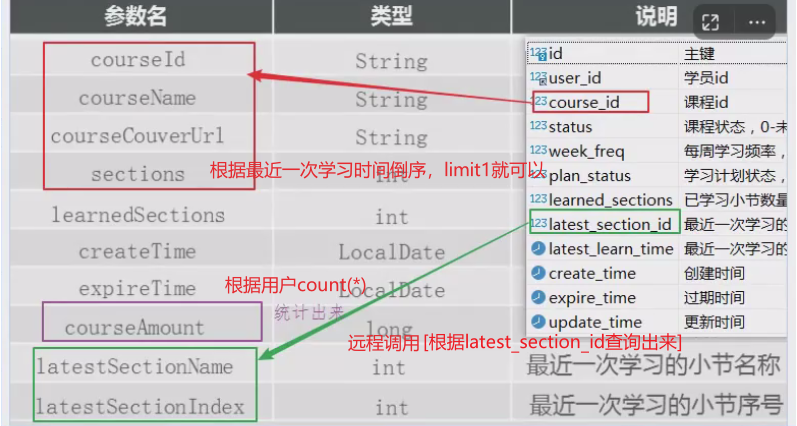
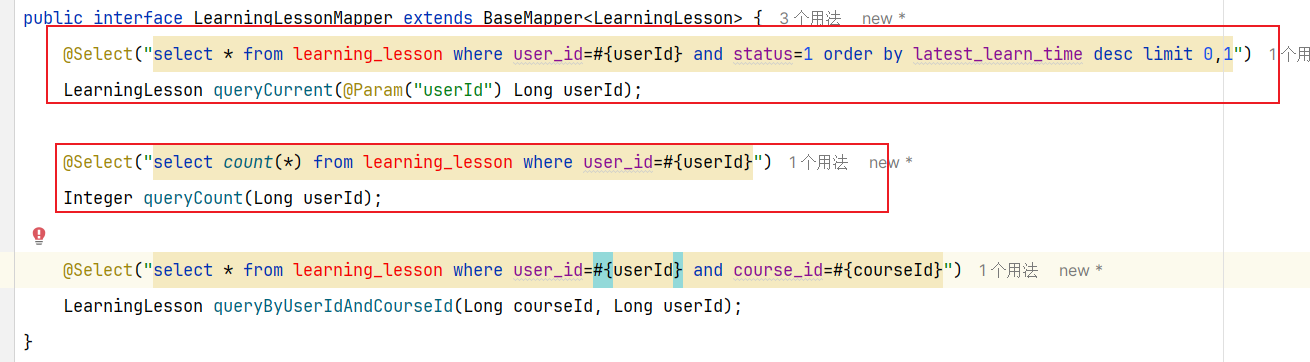
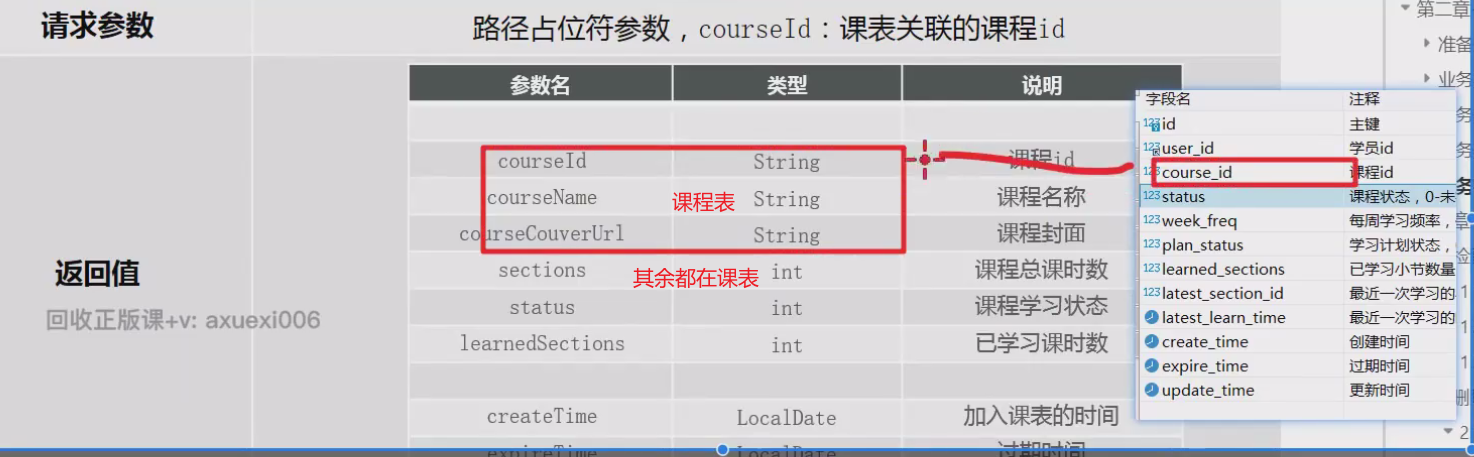
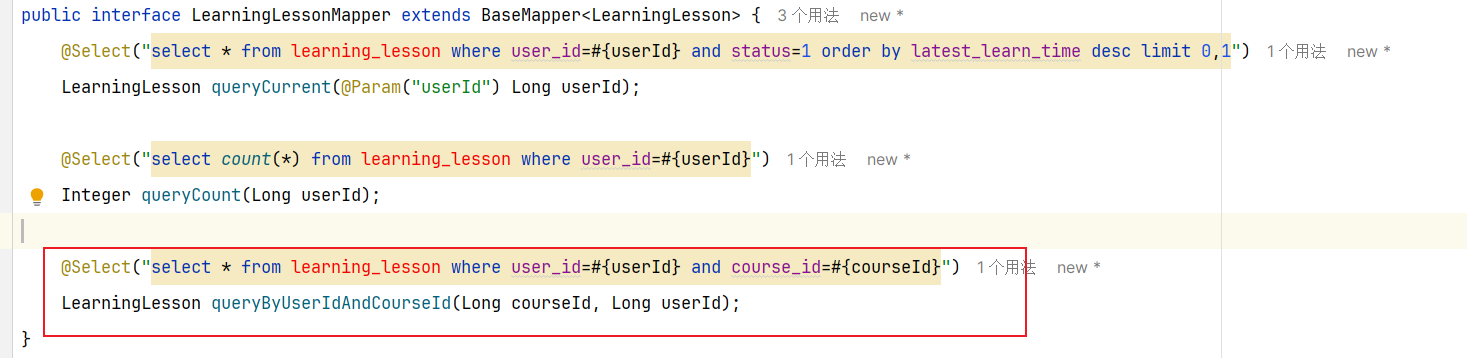
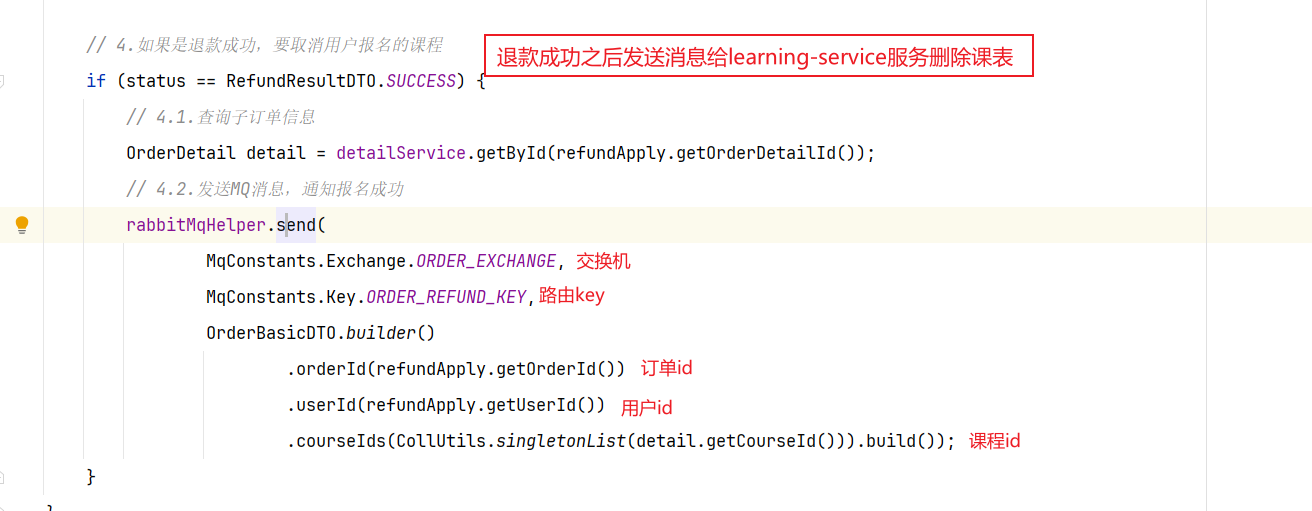
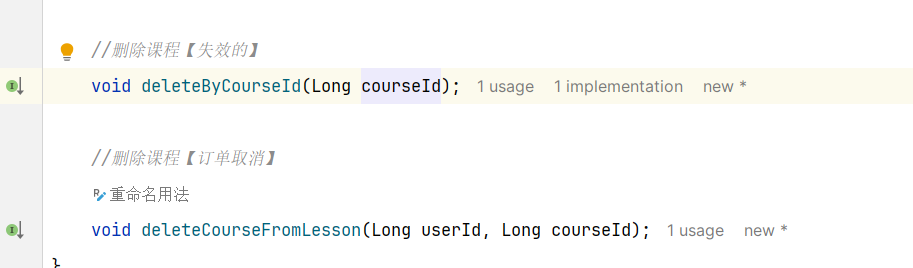
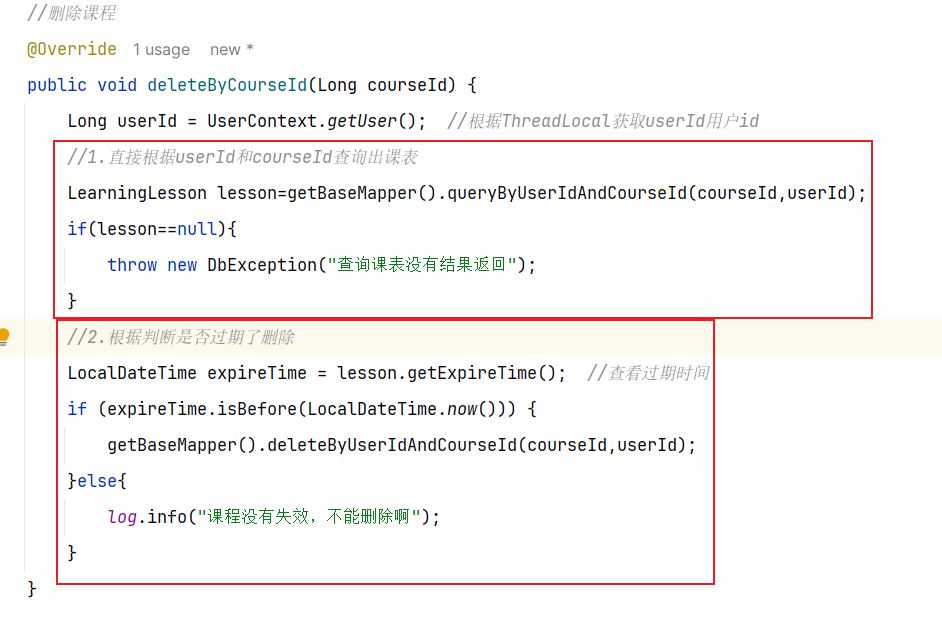
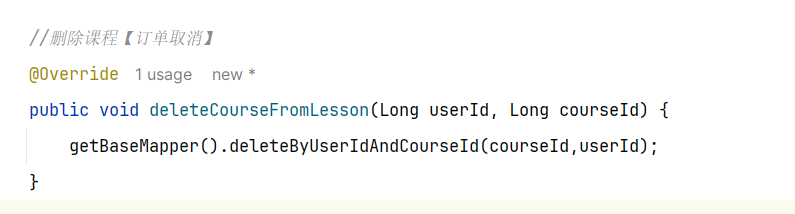
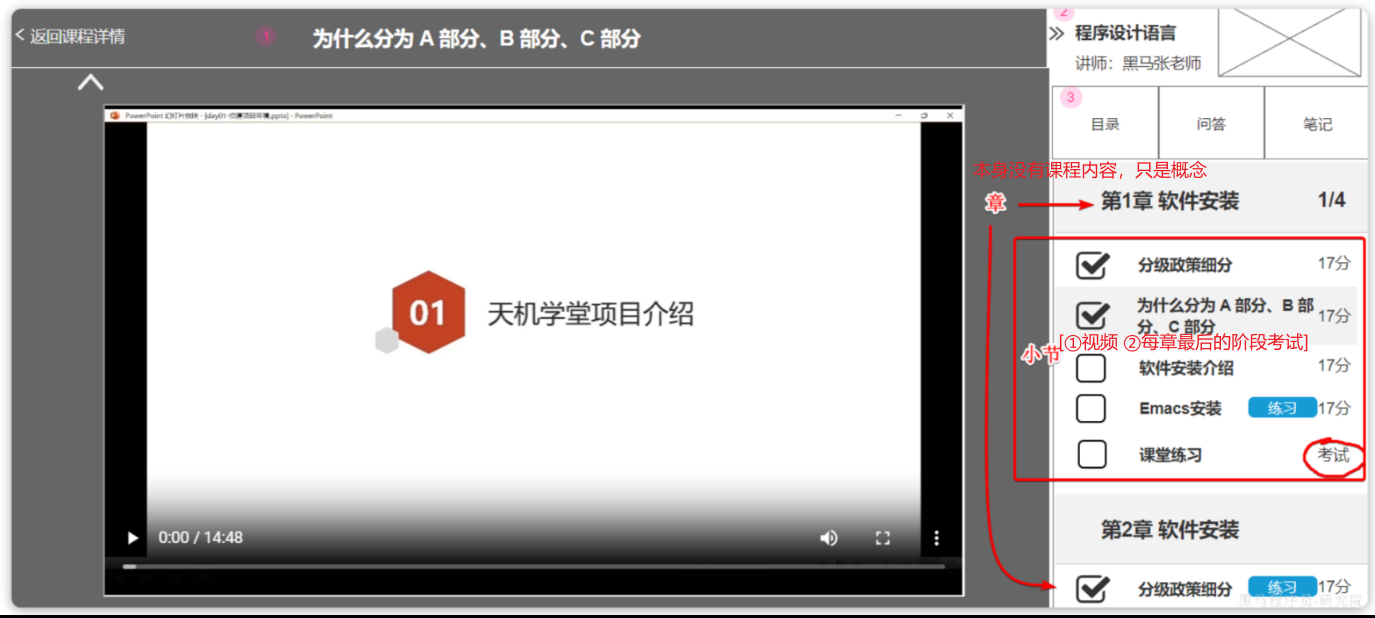
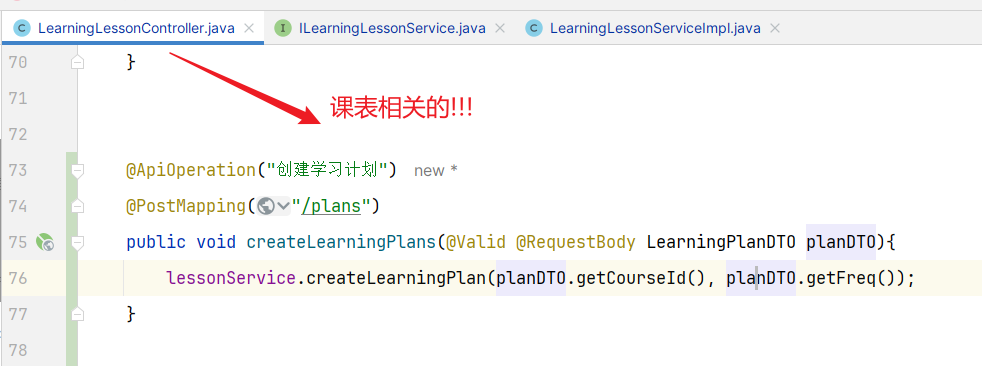
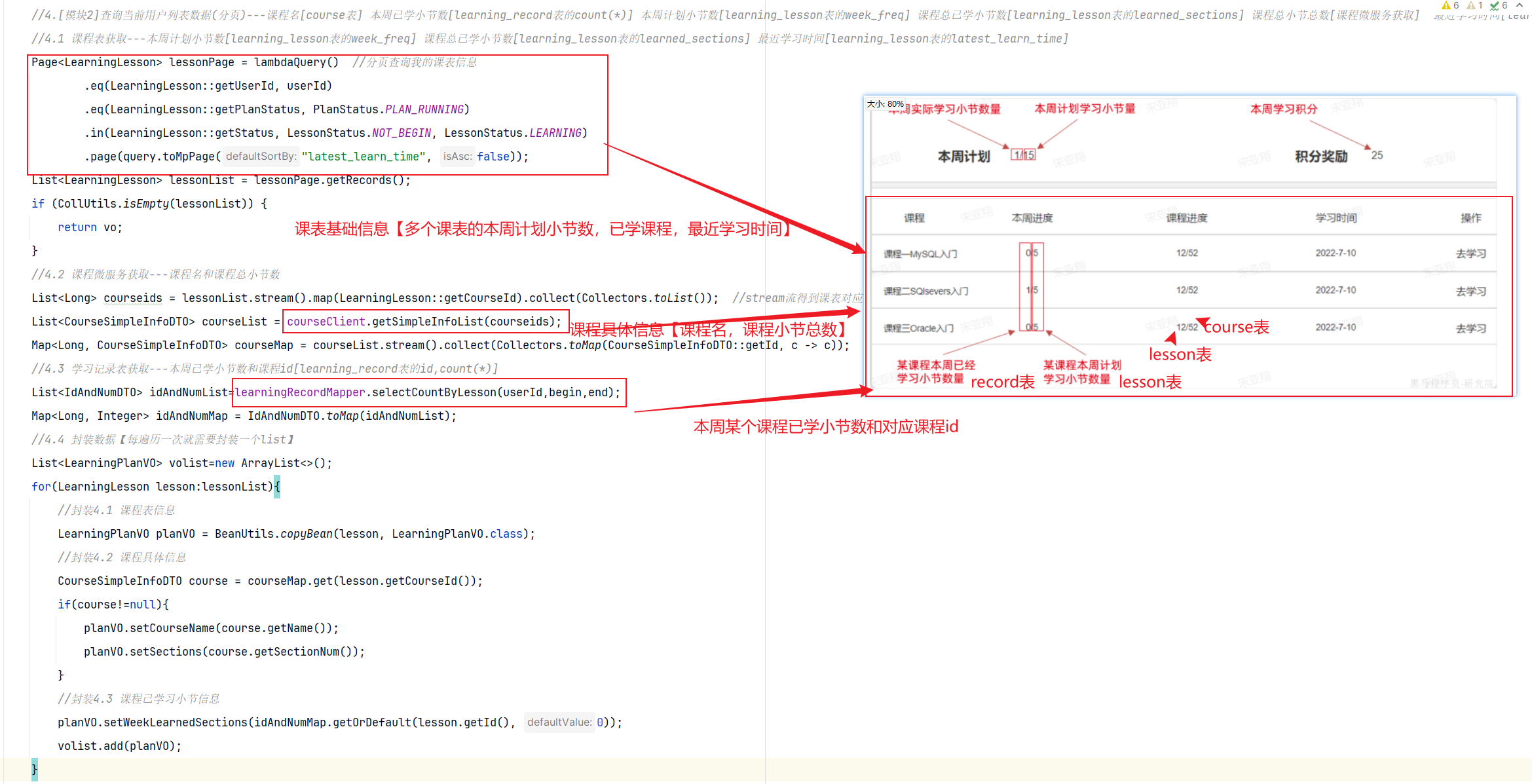
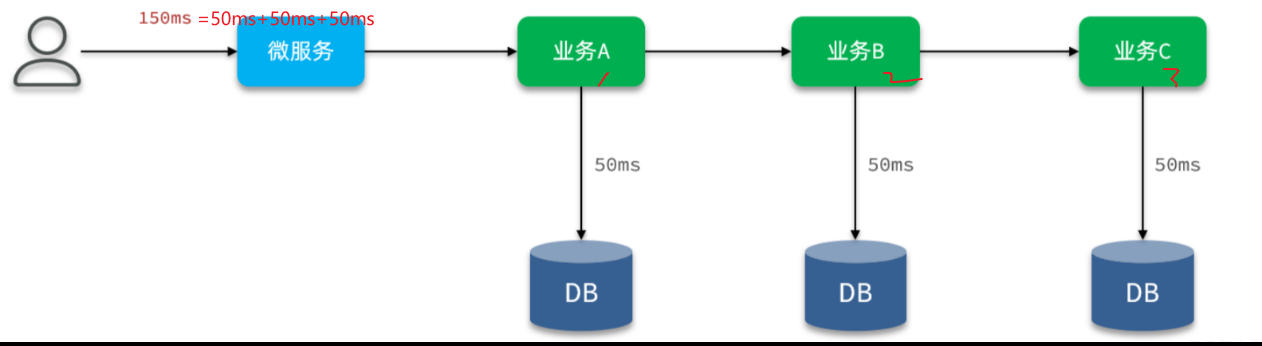
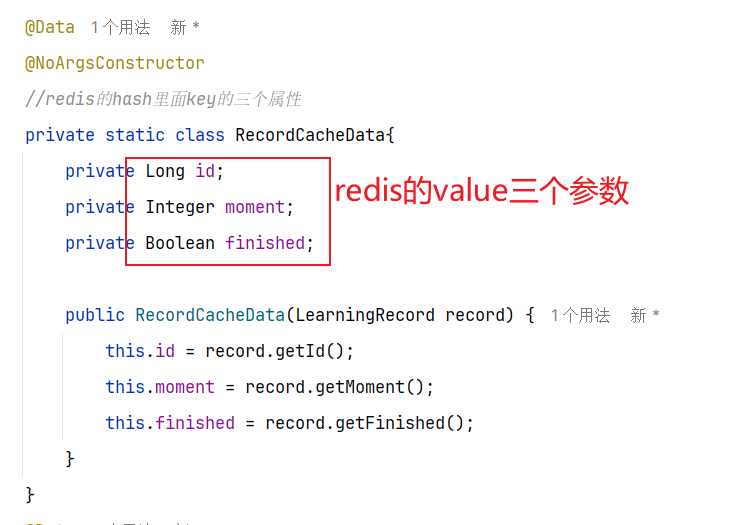
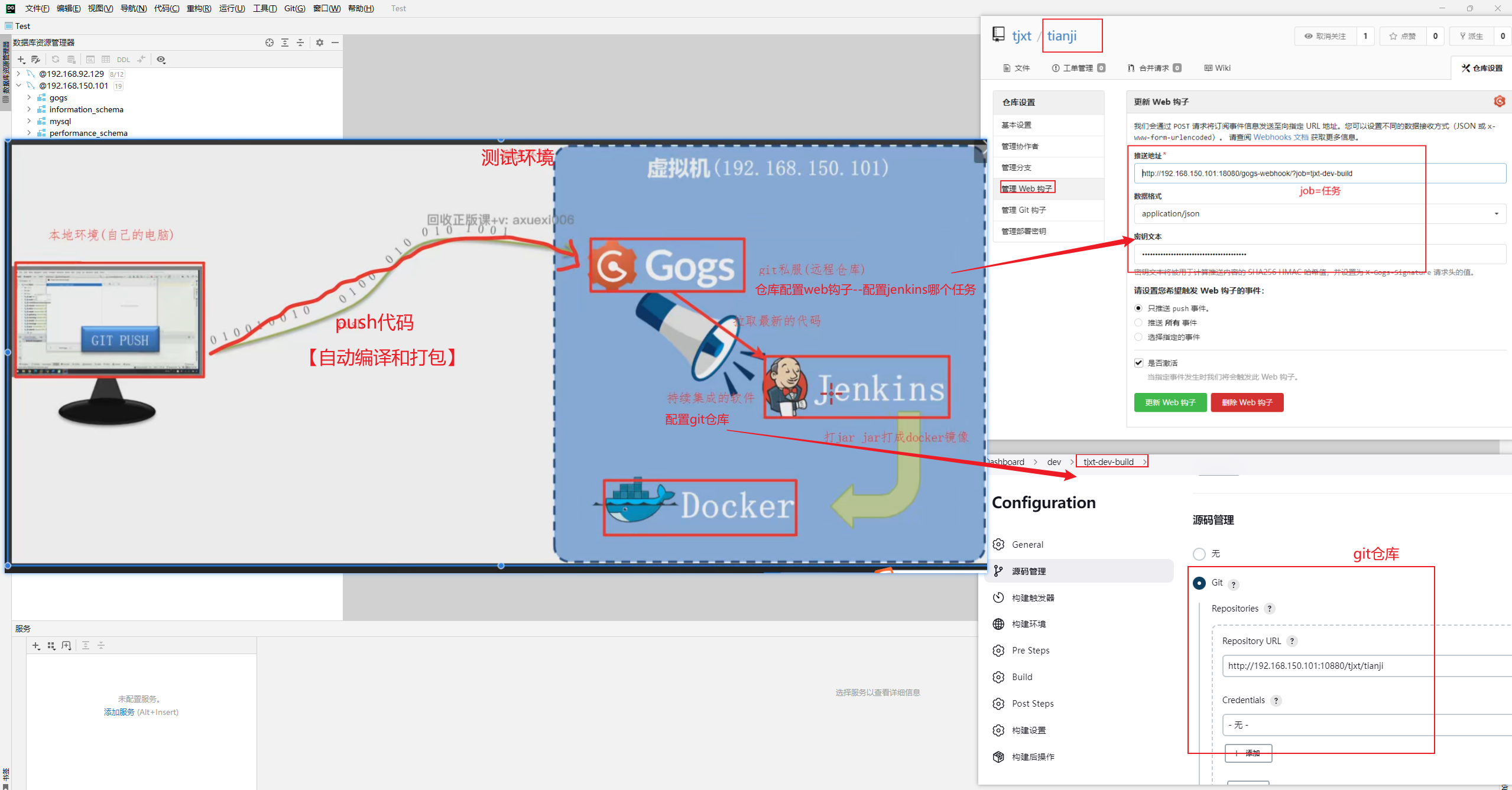
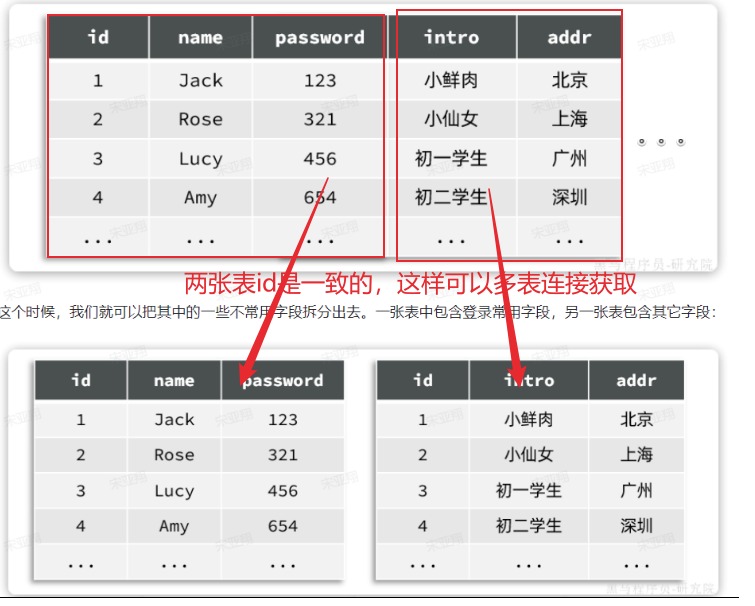
==—————-签到功能—————-== 为了激励东林学子学习,可以设定一个学习积分的排行榜。优秀的学子可以给予优惠券
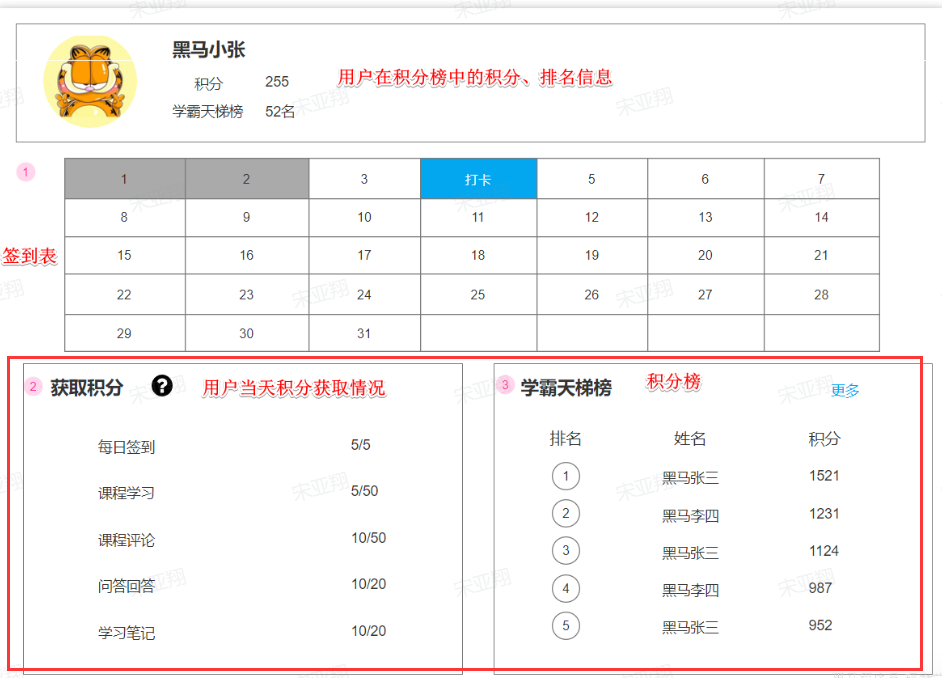
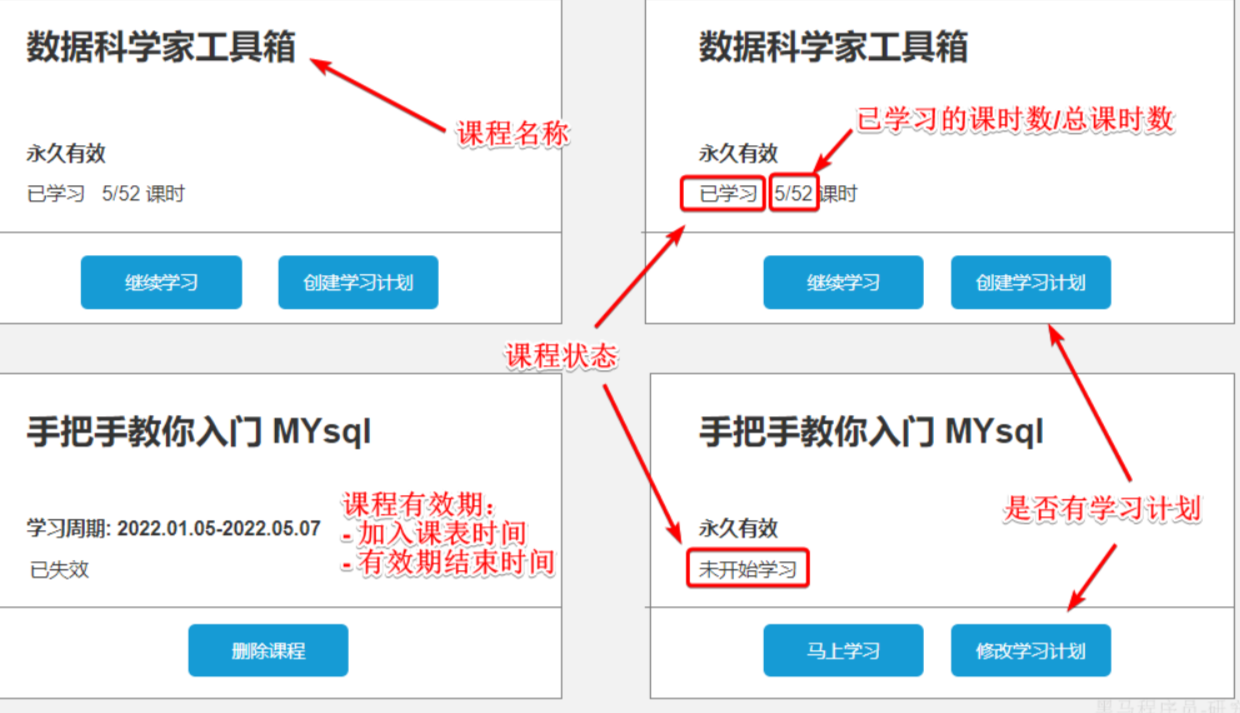
这个页面信息比较密集,从上往下来看分三部分:
顶部:当前用户在榜单中的信息
中部:签到表
下部:分为左右两侧
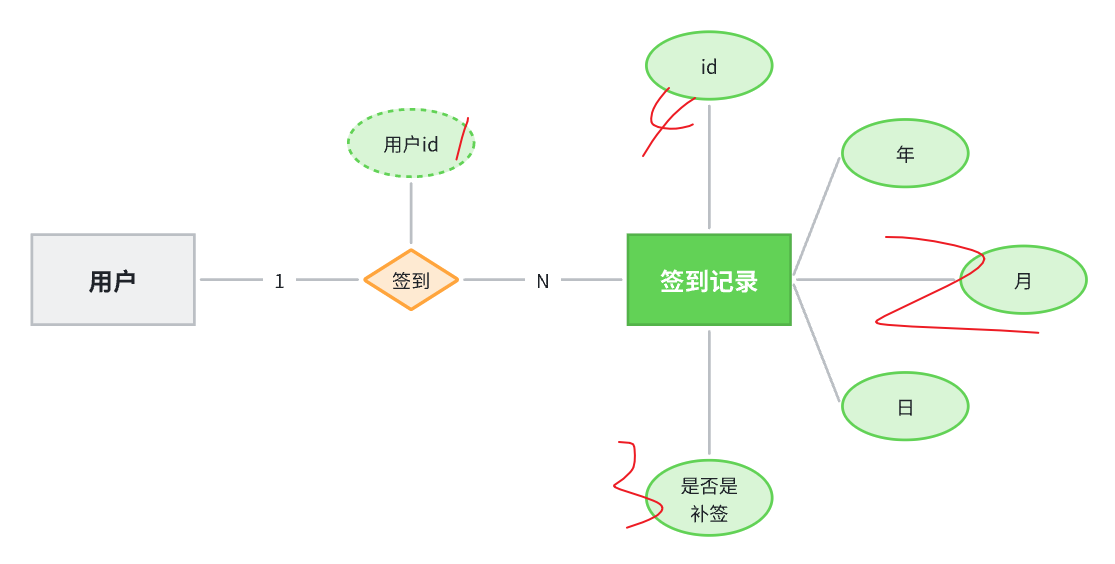
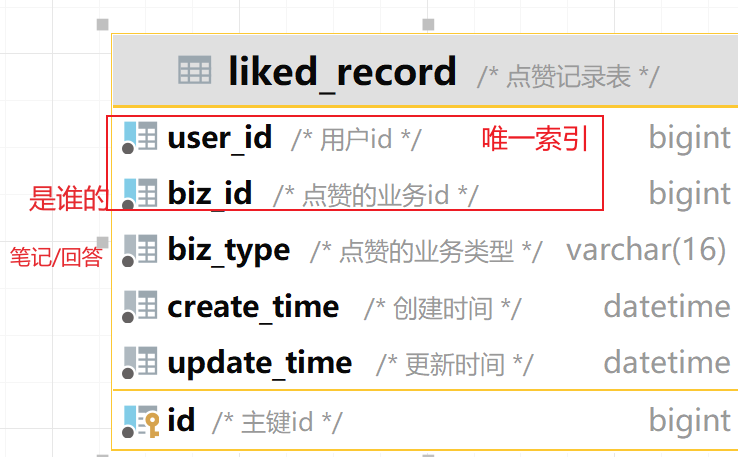
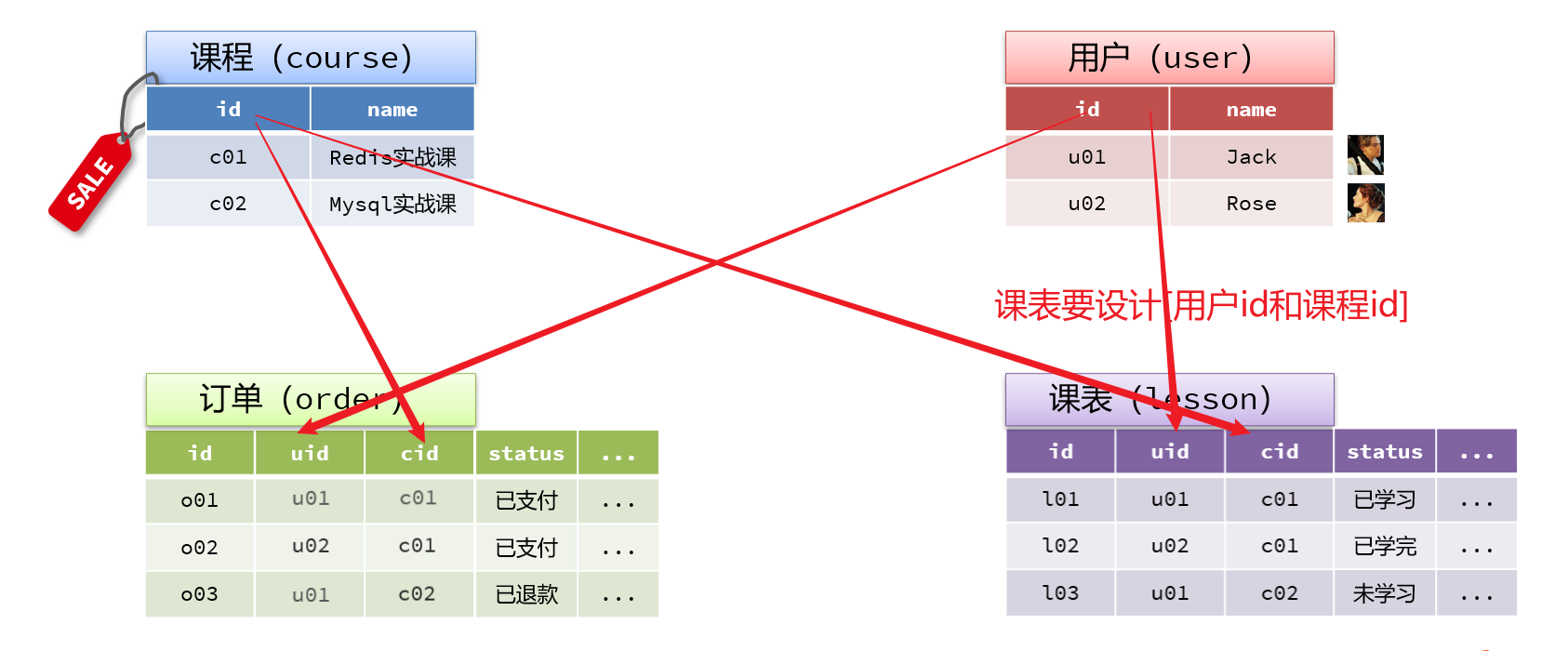
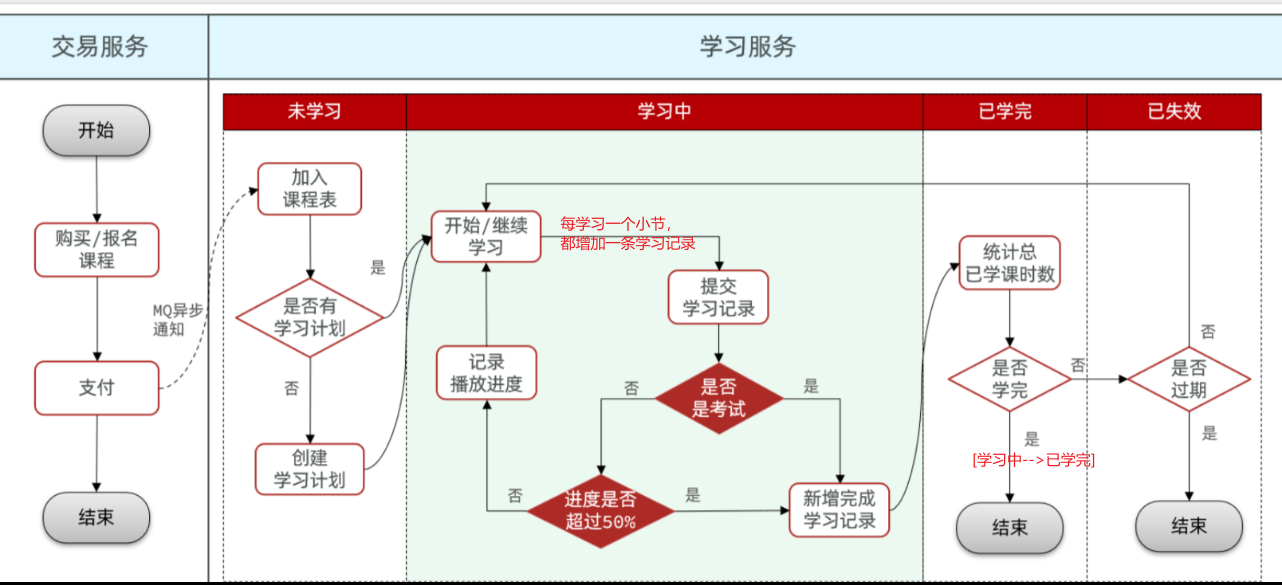
准备阶段—分析业务流程 准备阶段—字段分析 签到最核心的包含两个要素:
同时要考虑一些功能要素,比如:
补签功能,所以要有补签标示
按照年、月统计的功能:所以签到日期可以按照年、月、日分离保存
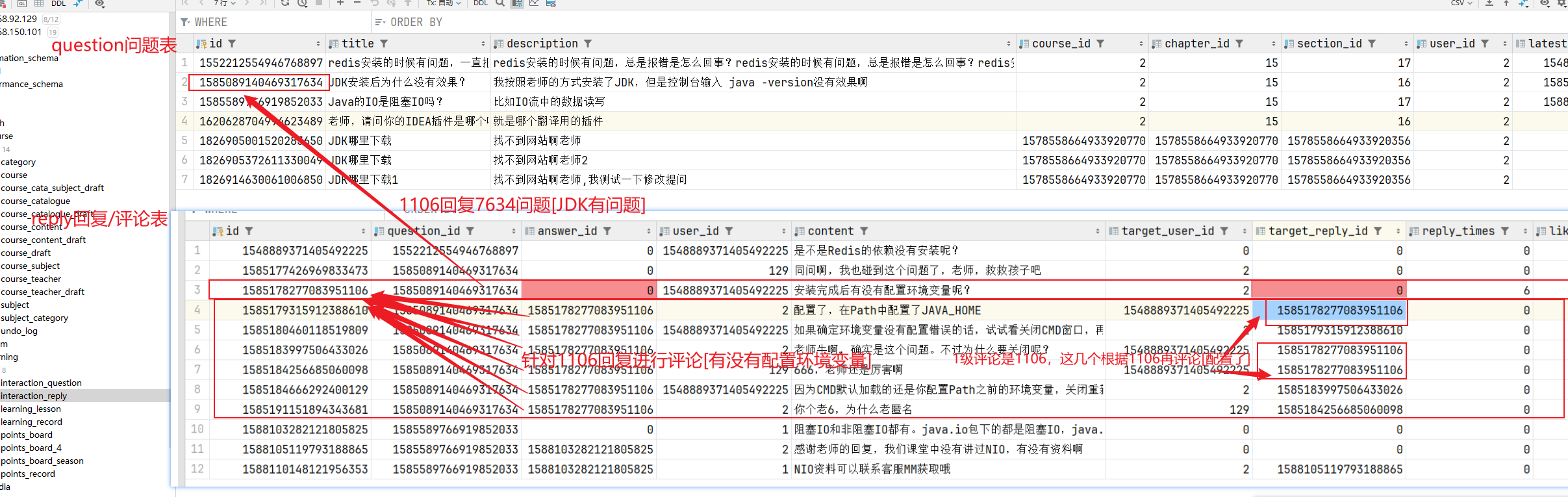
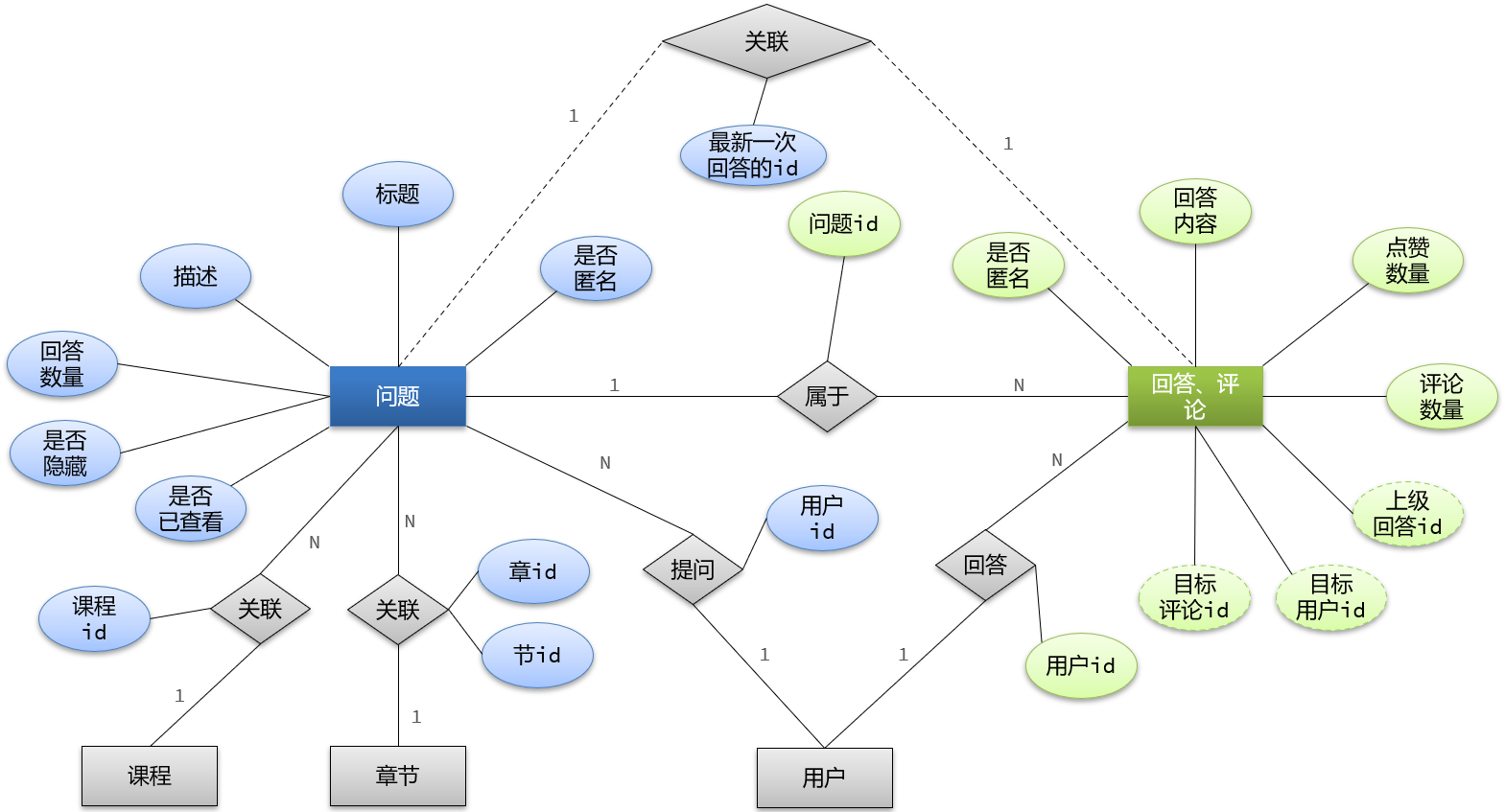
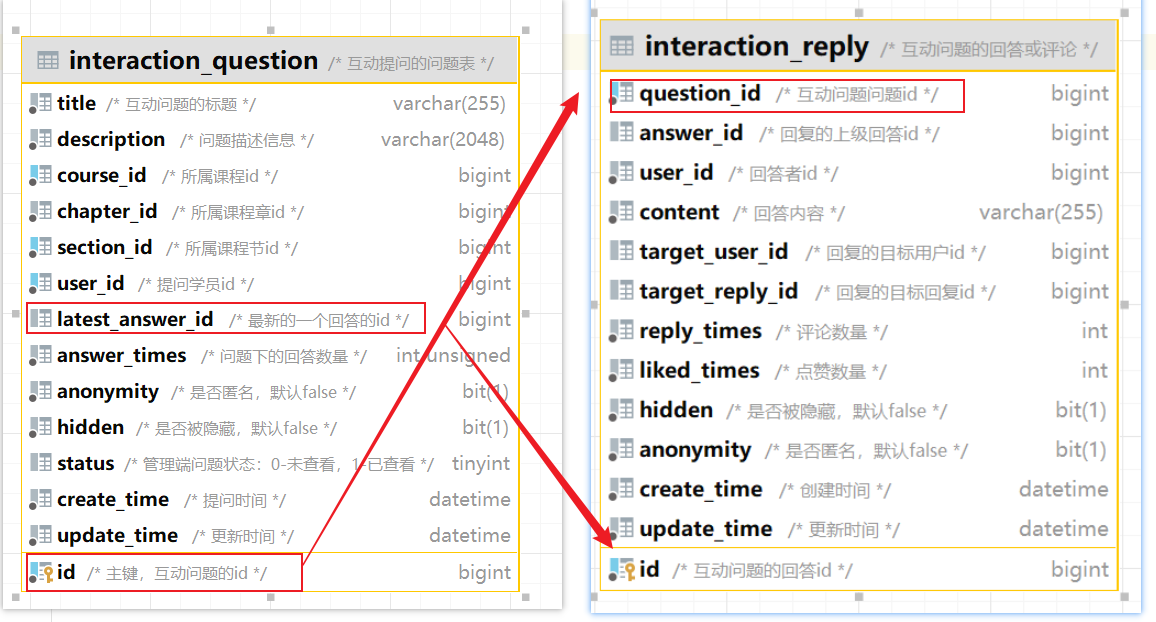
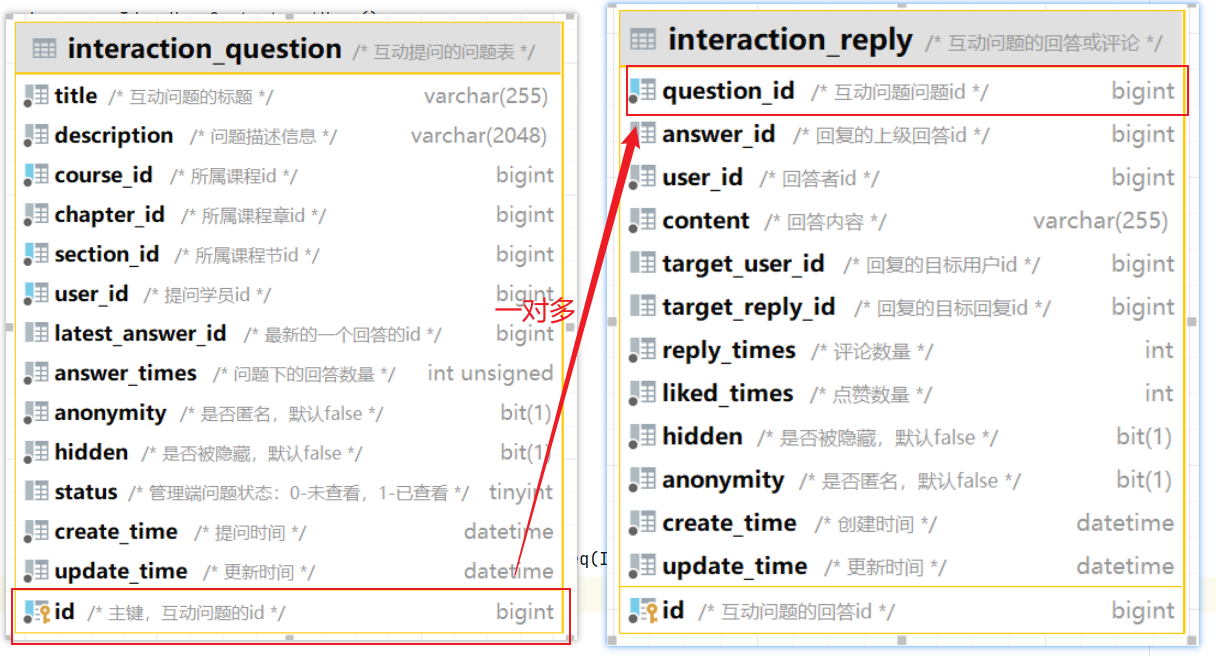
准备阶段—ER图
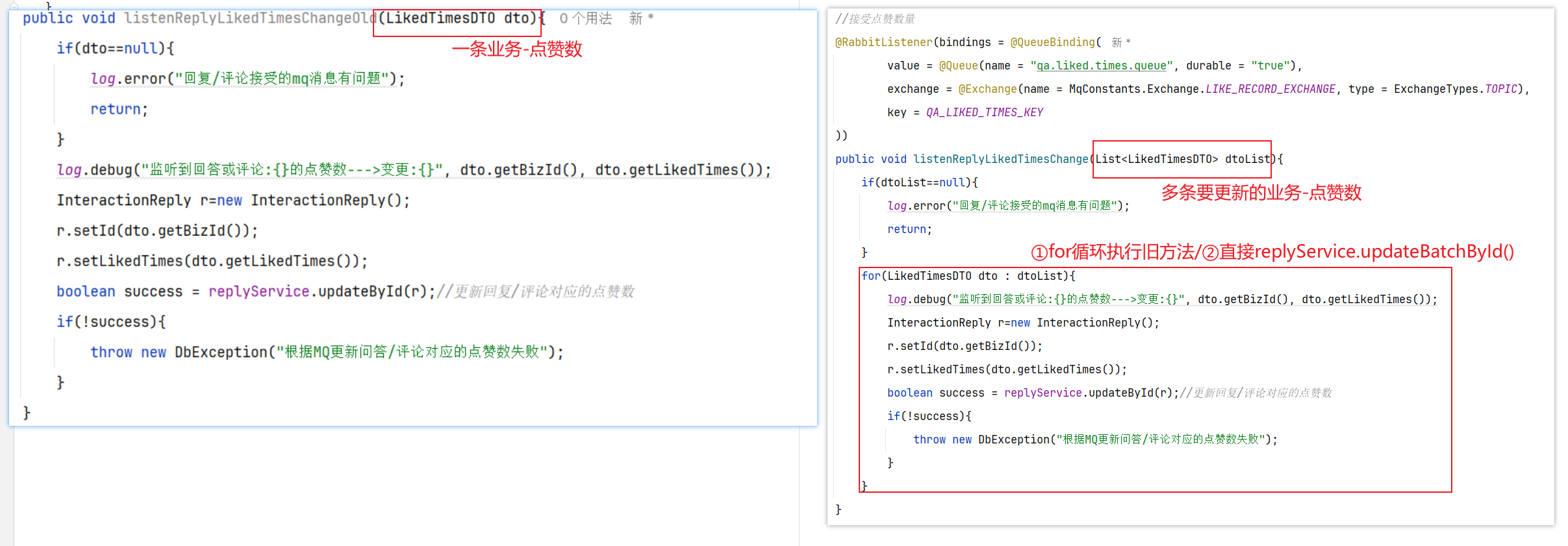
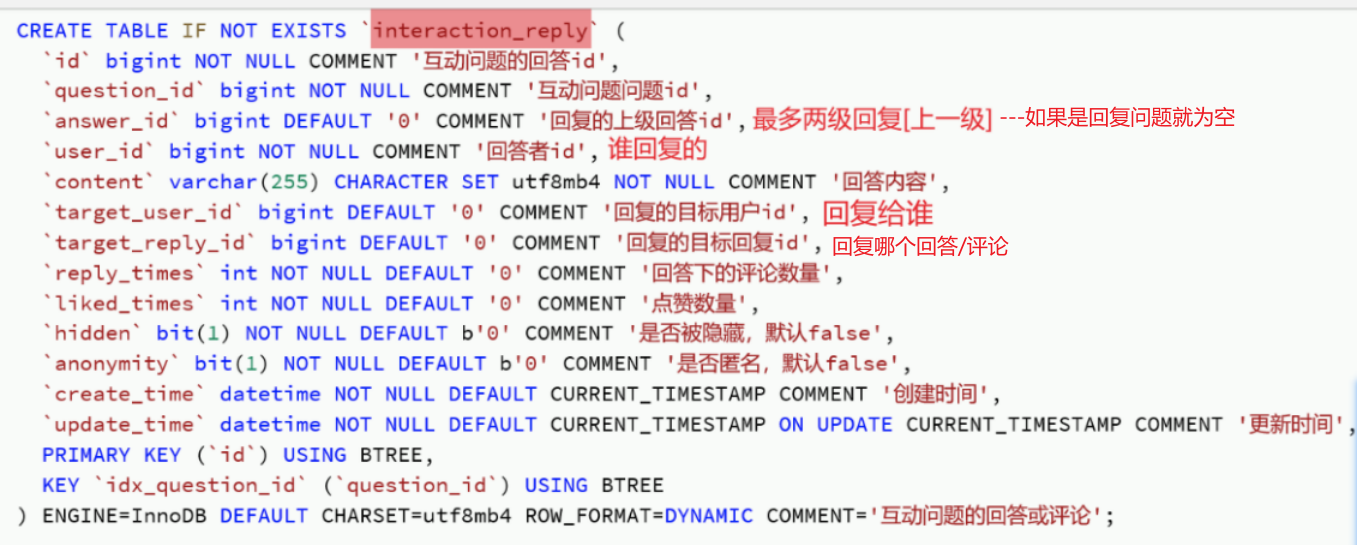
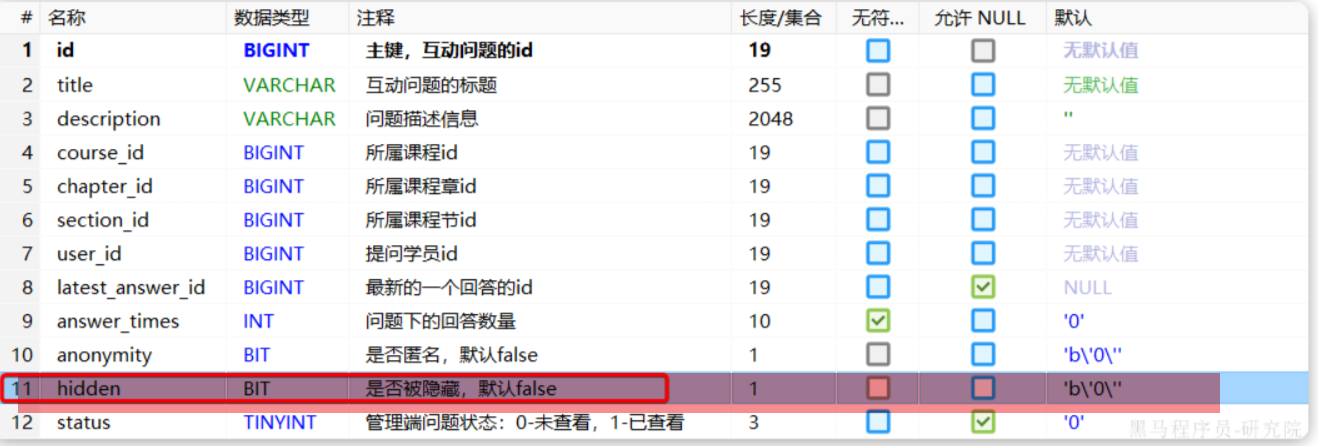
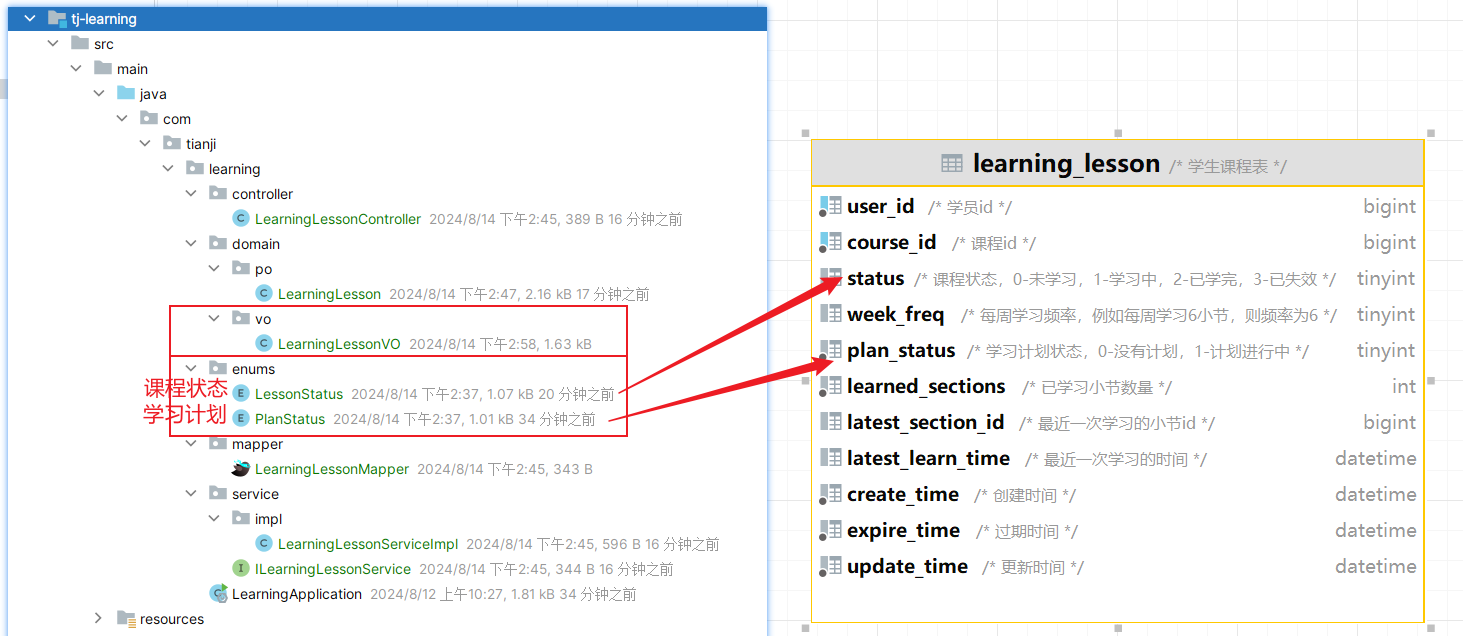
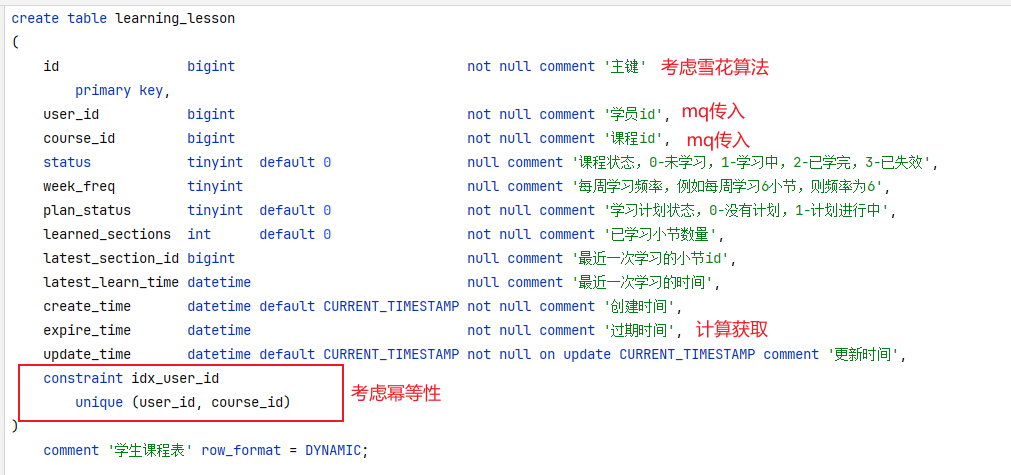
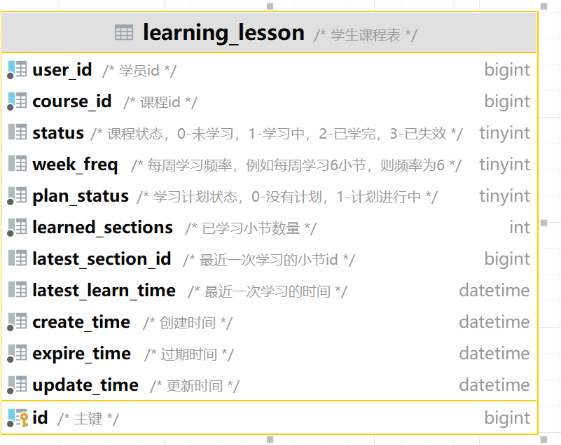
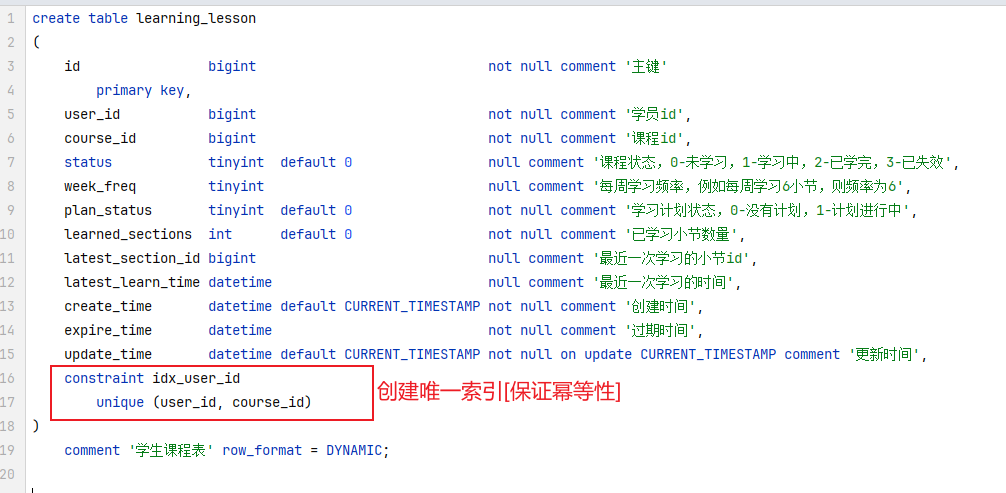
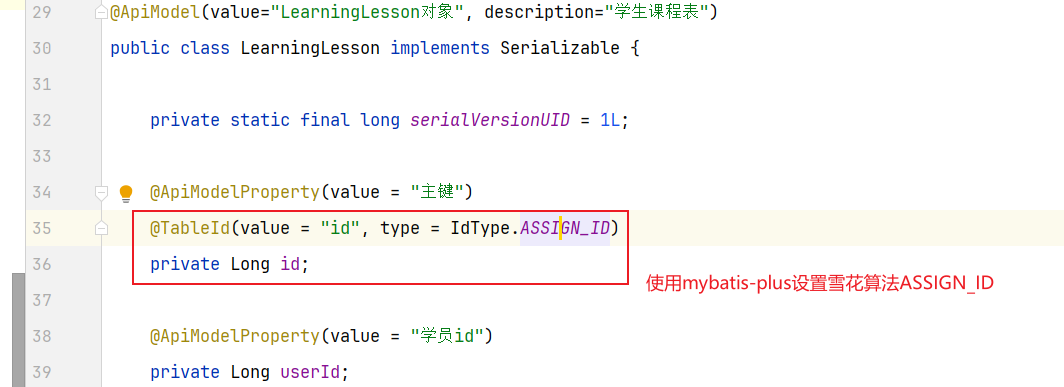
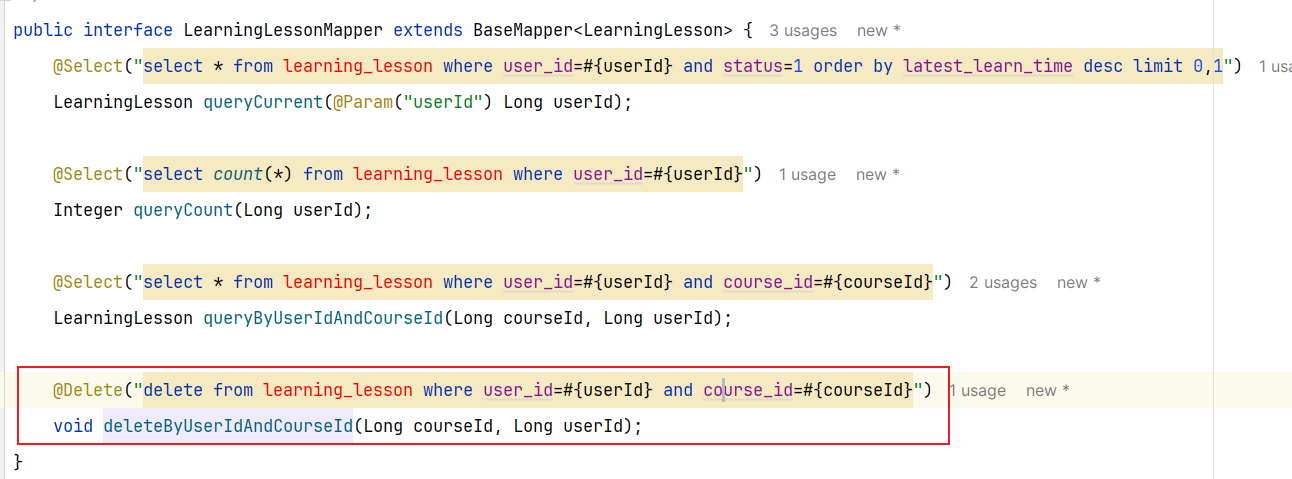
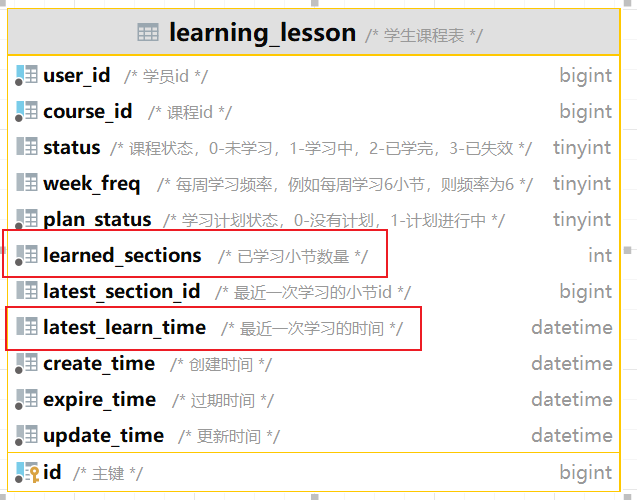
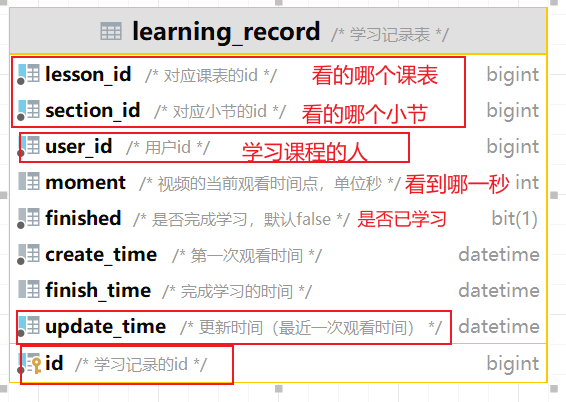
准备阶段—表结构 1 2 3 4 5 6 7 8 9 CREATE TABLE `sign_record` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键' , `user_id` bigint NOT NULL COMMENT '用户id' , `year` year NOT NULL COMMENT '签到年份' , `month` tinyint NOT NULL COMMENT '签到月份' , `date` date NOT NULL COMMENT '签到日期' , `is_backup` bit (1 ) NOT NULL COMMENT '是否补签' , PRIMARY KEY (`id` ), ) ENGINE =InnoDB DEFAULT CHARSET =utf8mb4 COMMENT ='签到记录表' ;
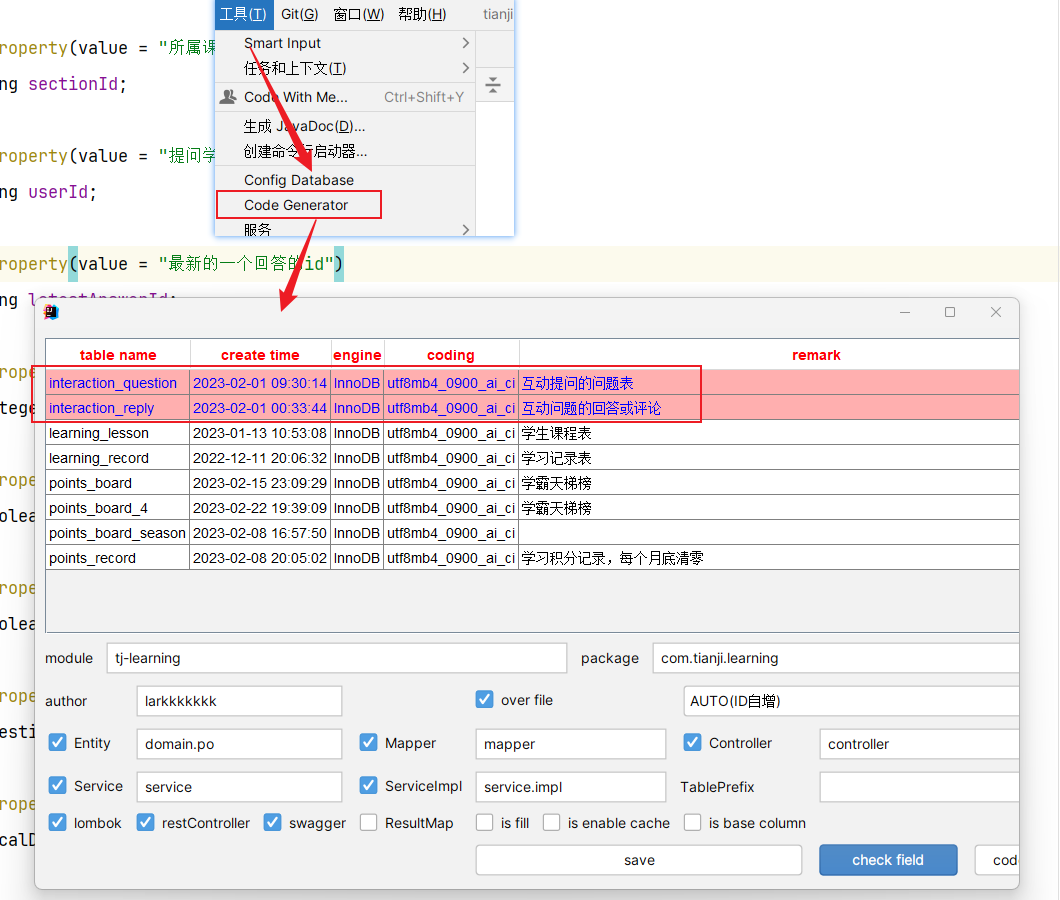
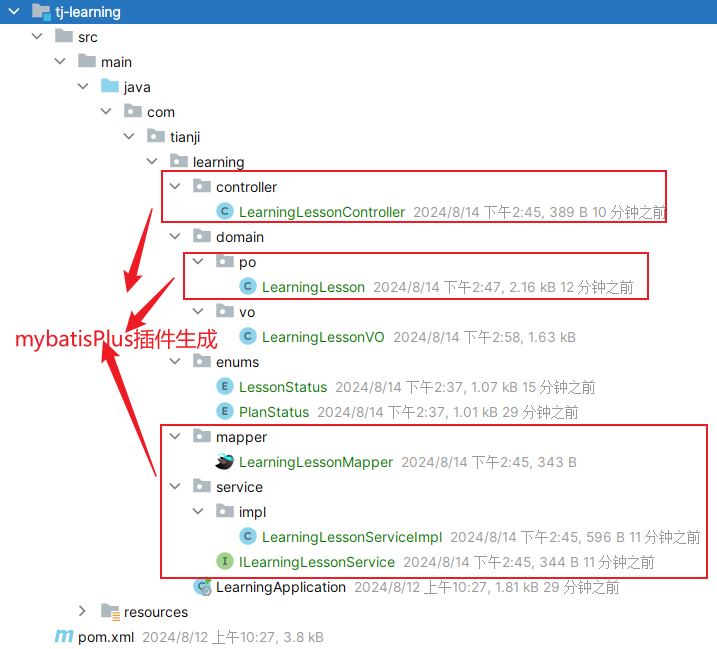
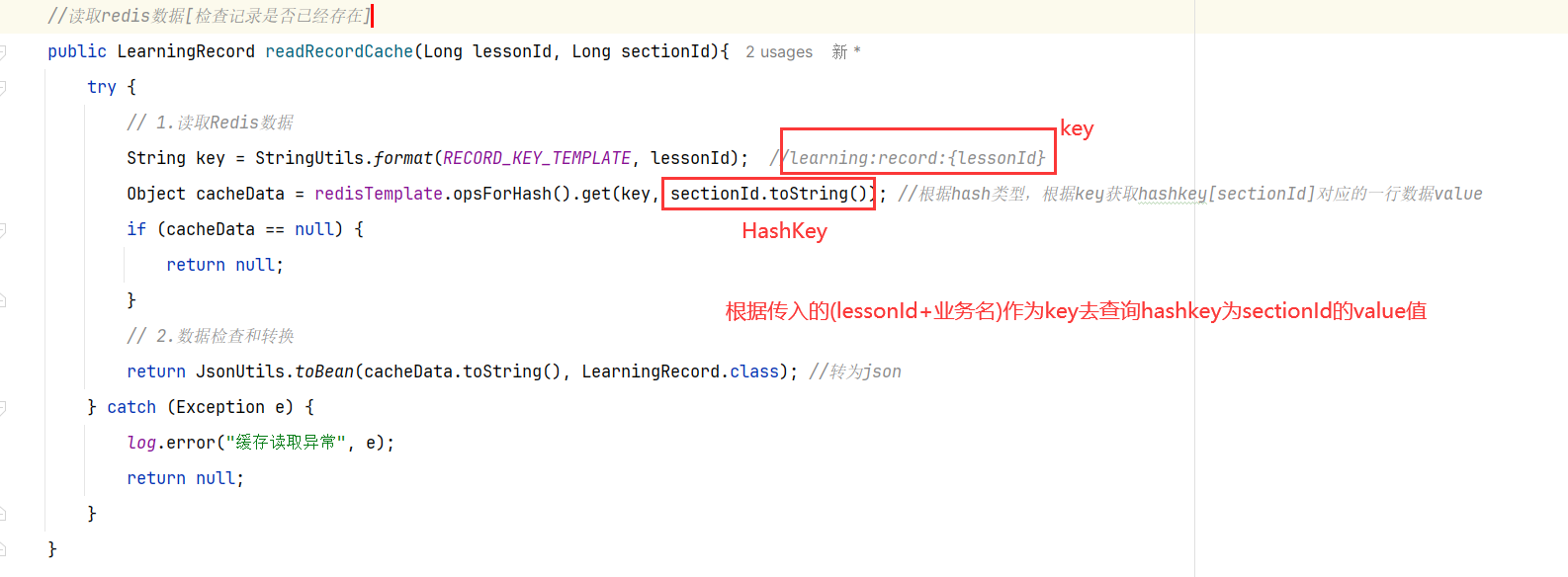
准备阶段—Mybatis-Plus代码生成 无【基于redis做的,没有mysql数据库表】
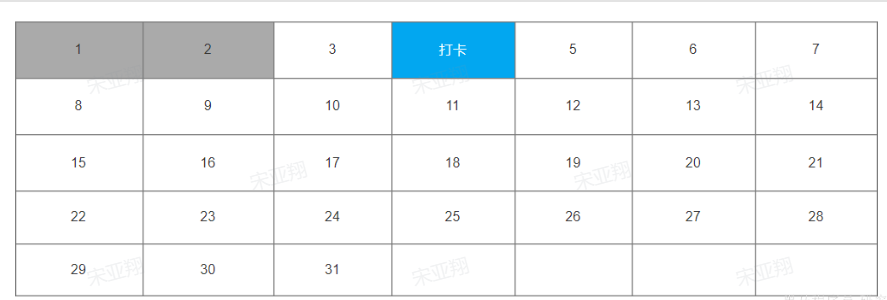
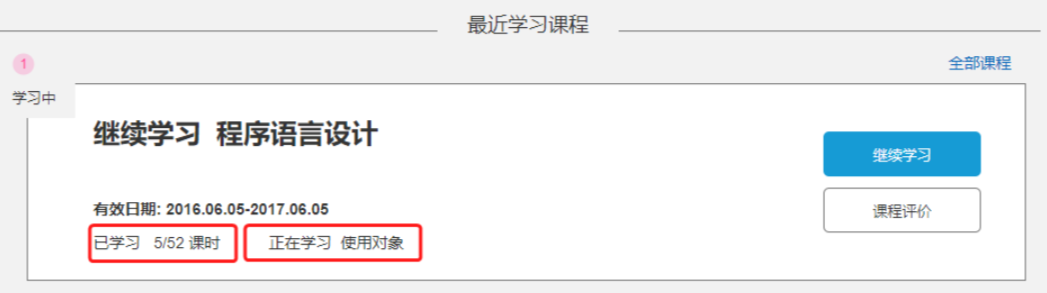
准备阶段–类型枚举 准备阶段–接口统计 回到个人积分页面,在页面中部有一个签到表:
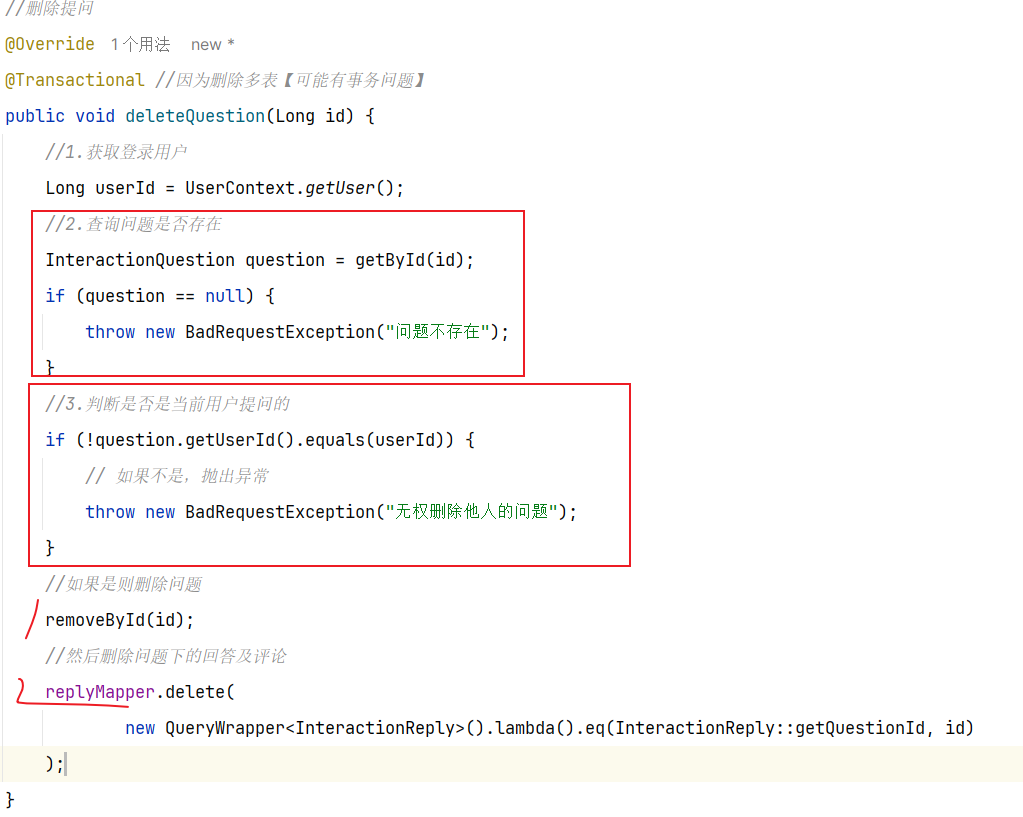
可以看到这就是一个日历,对应了每一天的签到情况。日历中当天的日期会高亮显示为《打卡》状态,点击即可完成当日打卡,服务端自然要记录打卡情况。
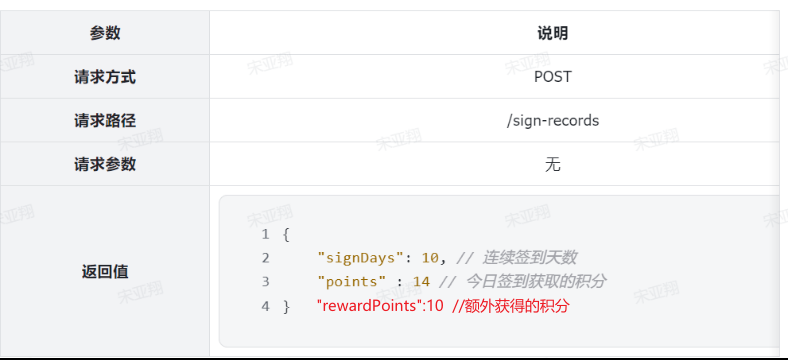
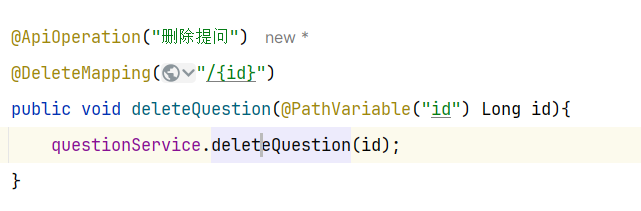
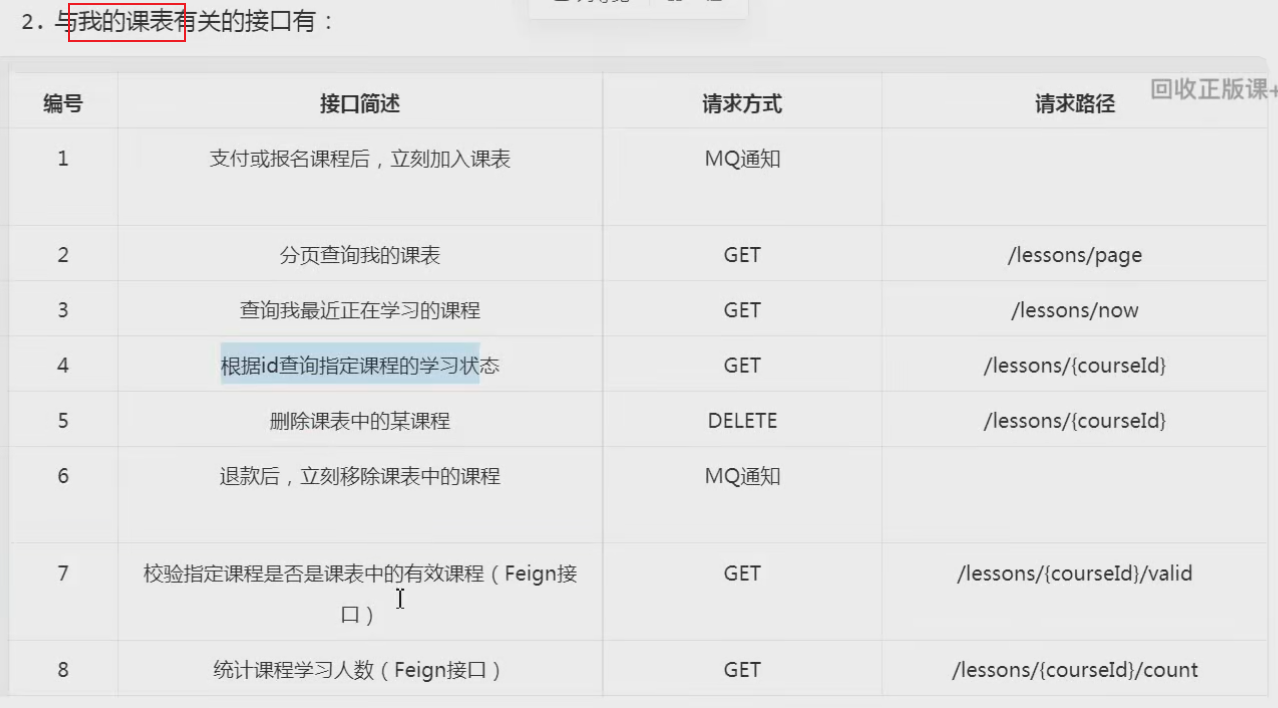
因此这里就有一个接口需要实现:①签到接口
除此以外,可以看到本月第一天到今天为止的所有打卡日期也都高亮显示标记出来了。也就是说页面还需要知道本月到今天为止每一天的打卡情况。这样对于了一个接口:②查询本月签到记录
准备阶段–redis的bitMap 1.基础知识 Redis 的 Bitmap(位图)是一种特殊的字符串数据类型 ,它利用字符串类型键(key)来存储一系列连续的二进制位(bits),每个位可以独立地表示一个布尔值(0 或 1)。这种数据结构非常适合用于存储和操作大量二值状态的数据,尤其在需要高效空间利用率和特定位操作场景中表现出色。
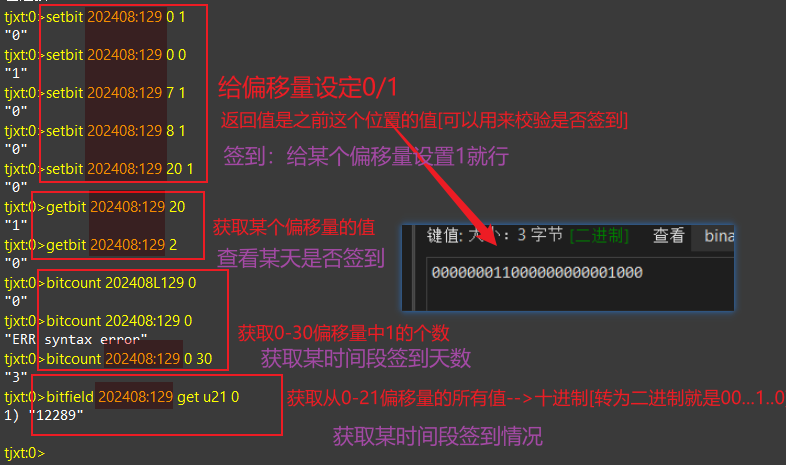
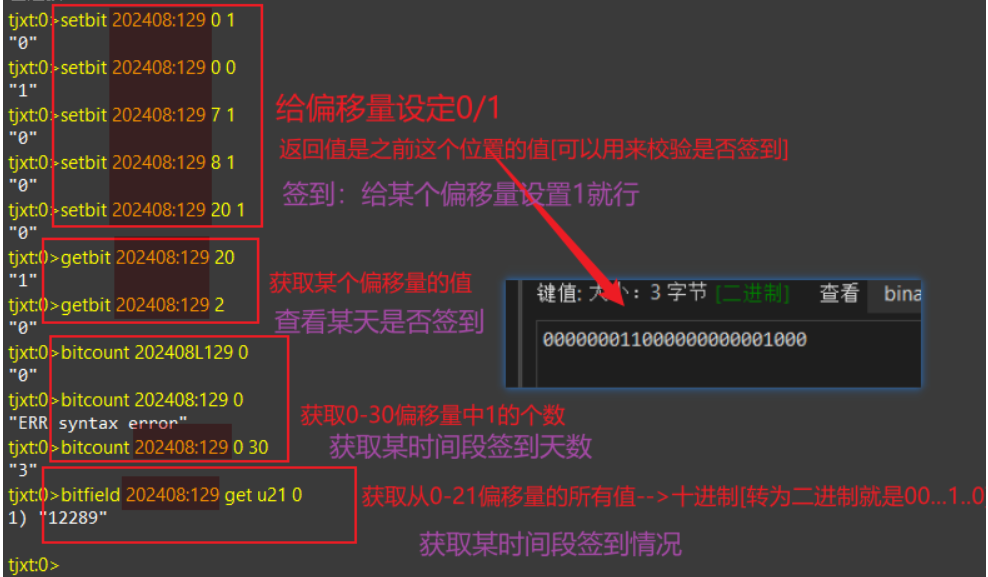
2.常用命令 我们可以使用setbit getbit bitcount bitfield四个指令:
1 2 3 4 5 6 7 8 # 签到/取消签到【给某人的某某年某某月为一个位图】 0就是偏移量【第一天】 1【1就是签到/0是不签到】 setbit YYYYMM:userId 0 1 # 获取某一天【0是第一天】的签到情况 getbit YYYYMM:userId 0 # 获取某时间段【第一天-第二十九天】内签到的总天数 ---是1的总数 bitcount YYYYMM:userId 0 30 # 获取某时间段【第一天-第二十天】签到的所有情况 u表示无符号/i表示有符号 ---得到的是一个十进制数 bitfield YYYYMM:userId get u21 0
3.bitMap扩展
基础类型:Redis最基础的数据类型只有5种:String、List、Set、SortedSet、Hash【其它特殊数据结构大多都是基于以上5这种数据类型】
BitMap基于String结构【String类型底层是SDS,会有一个字节数组用来保存数据。而Redis就提供了几个按位操作这个数组中数据的命令,实现了BitMap效果】
由于String类型的最大空间是512MB=2的31次幂个bit,因此可以存储的数据量级很大!!!【一个月才是31bit,四个字节】–> ==bitMap扩容是8个字节一组 ==
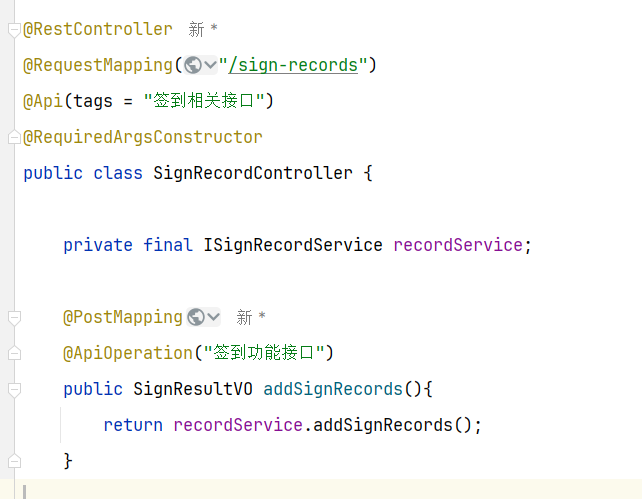
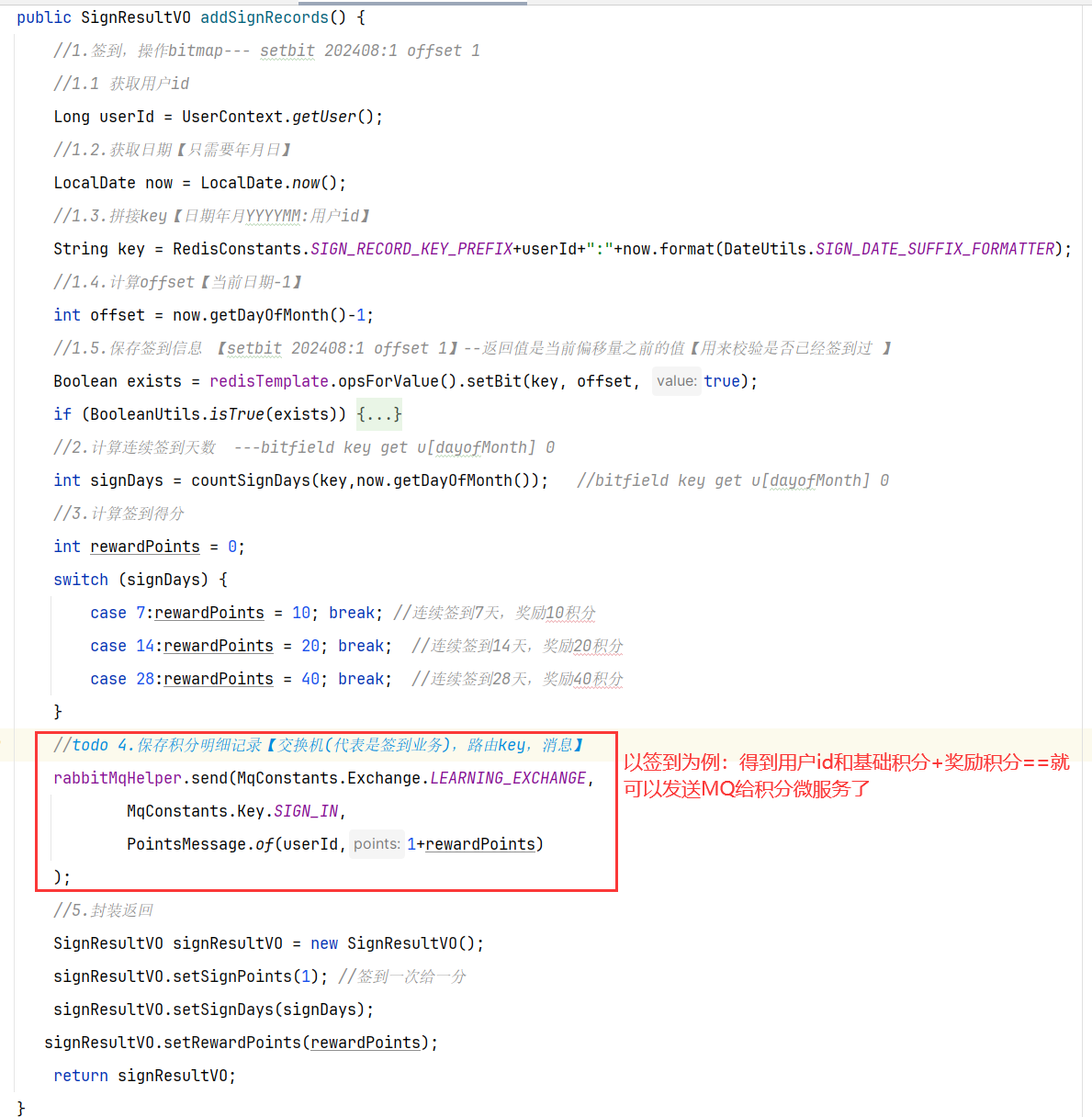
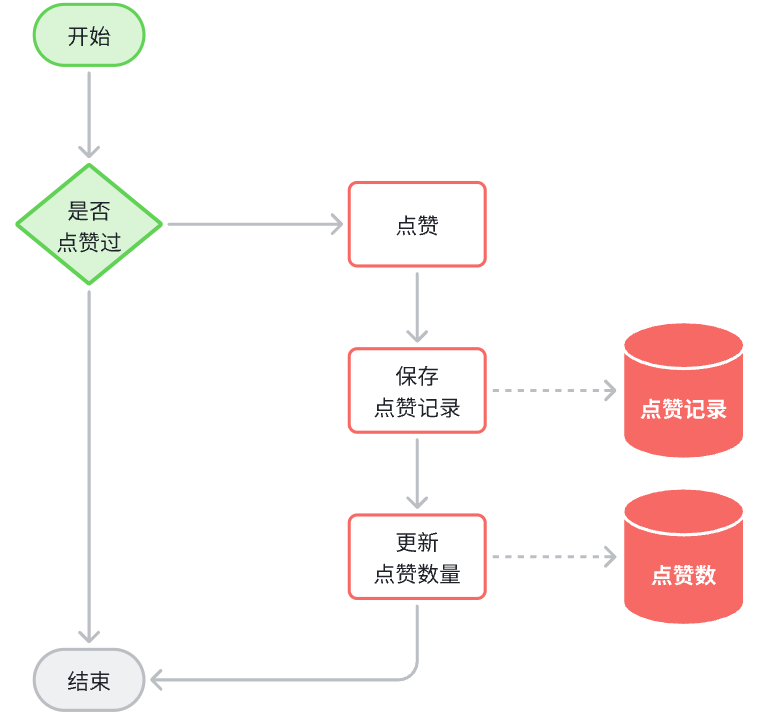
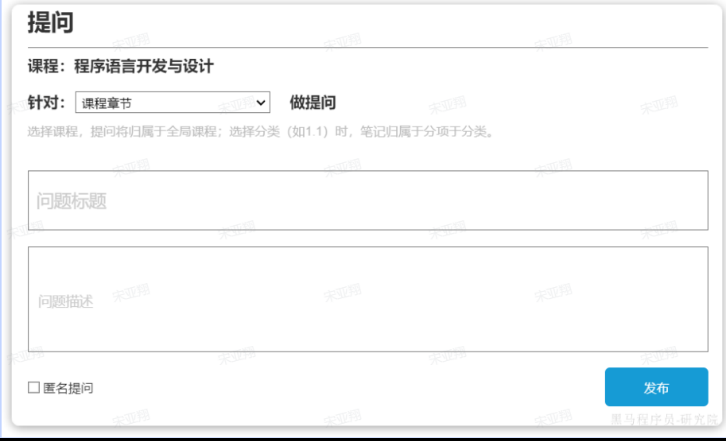
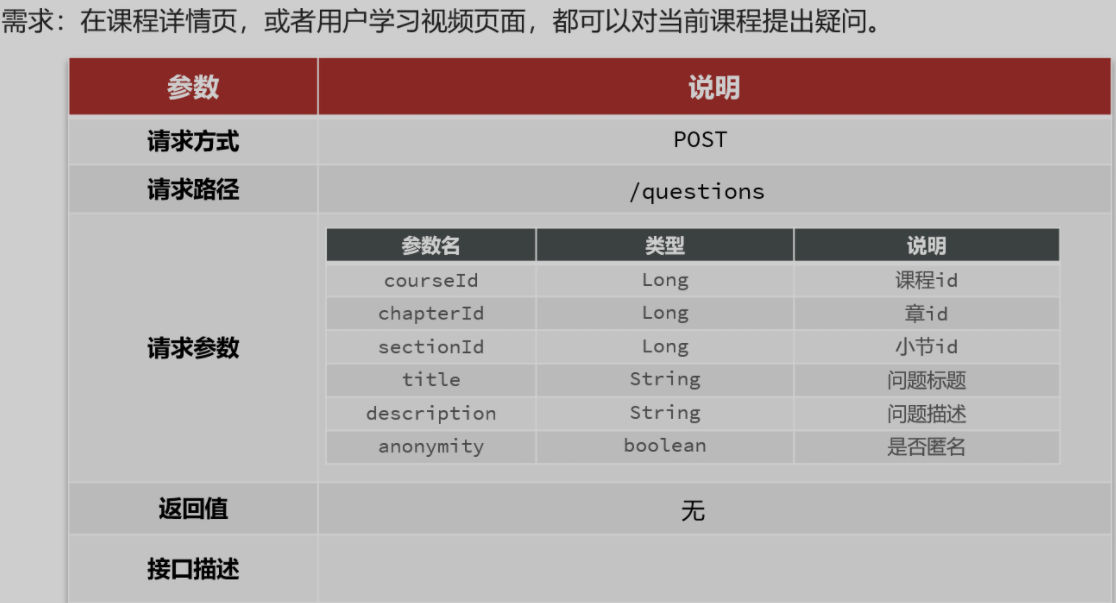
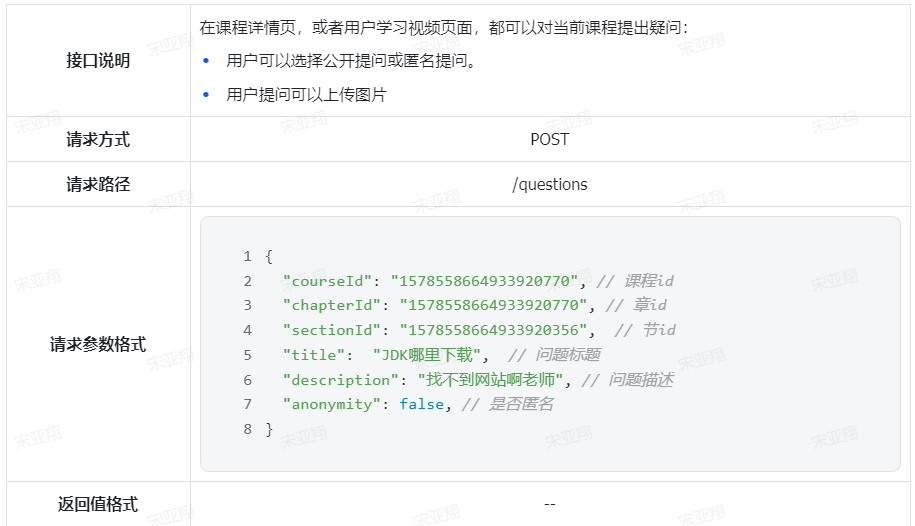
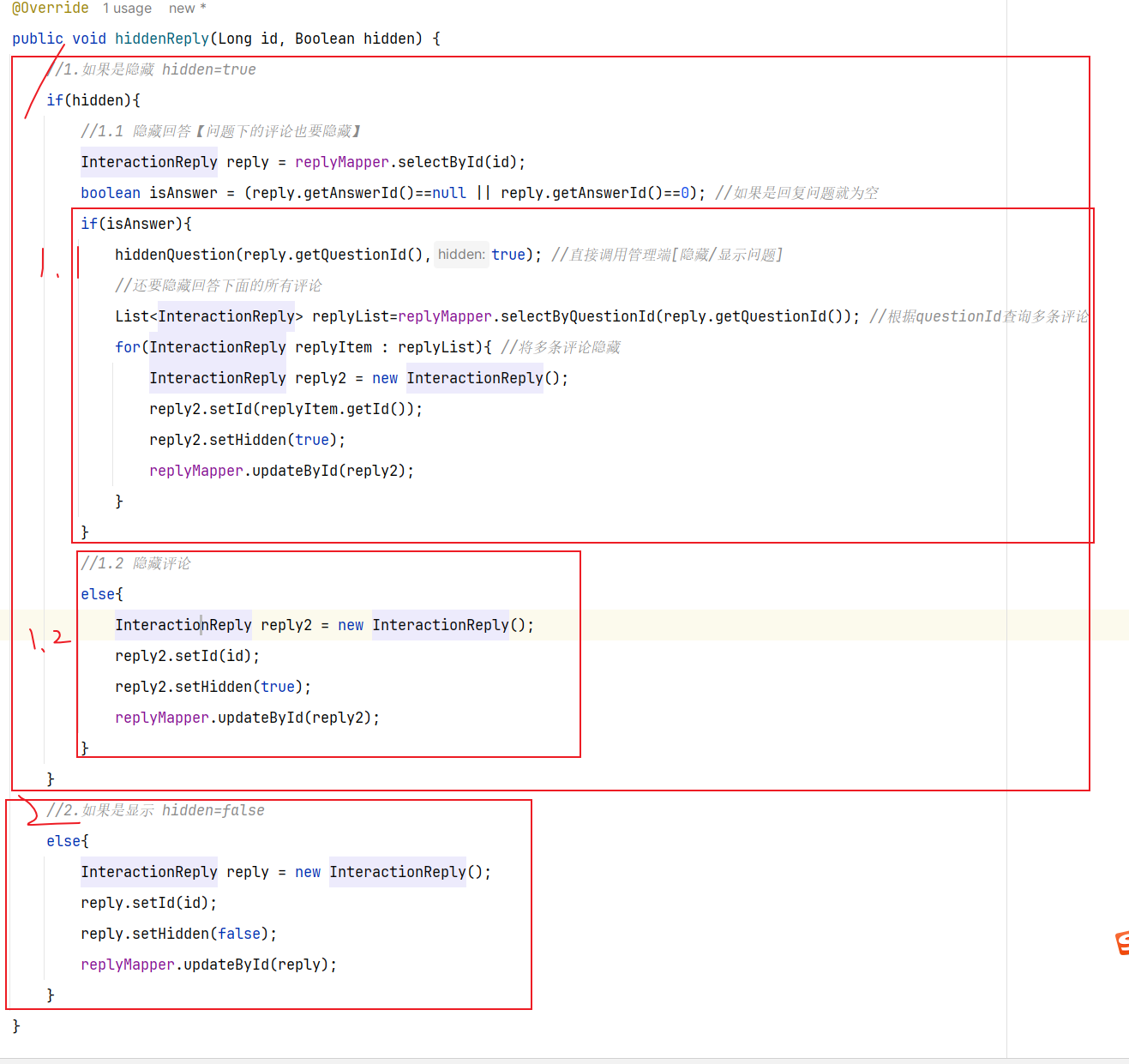
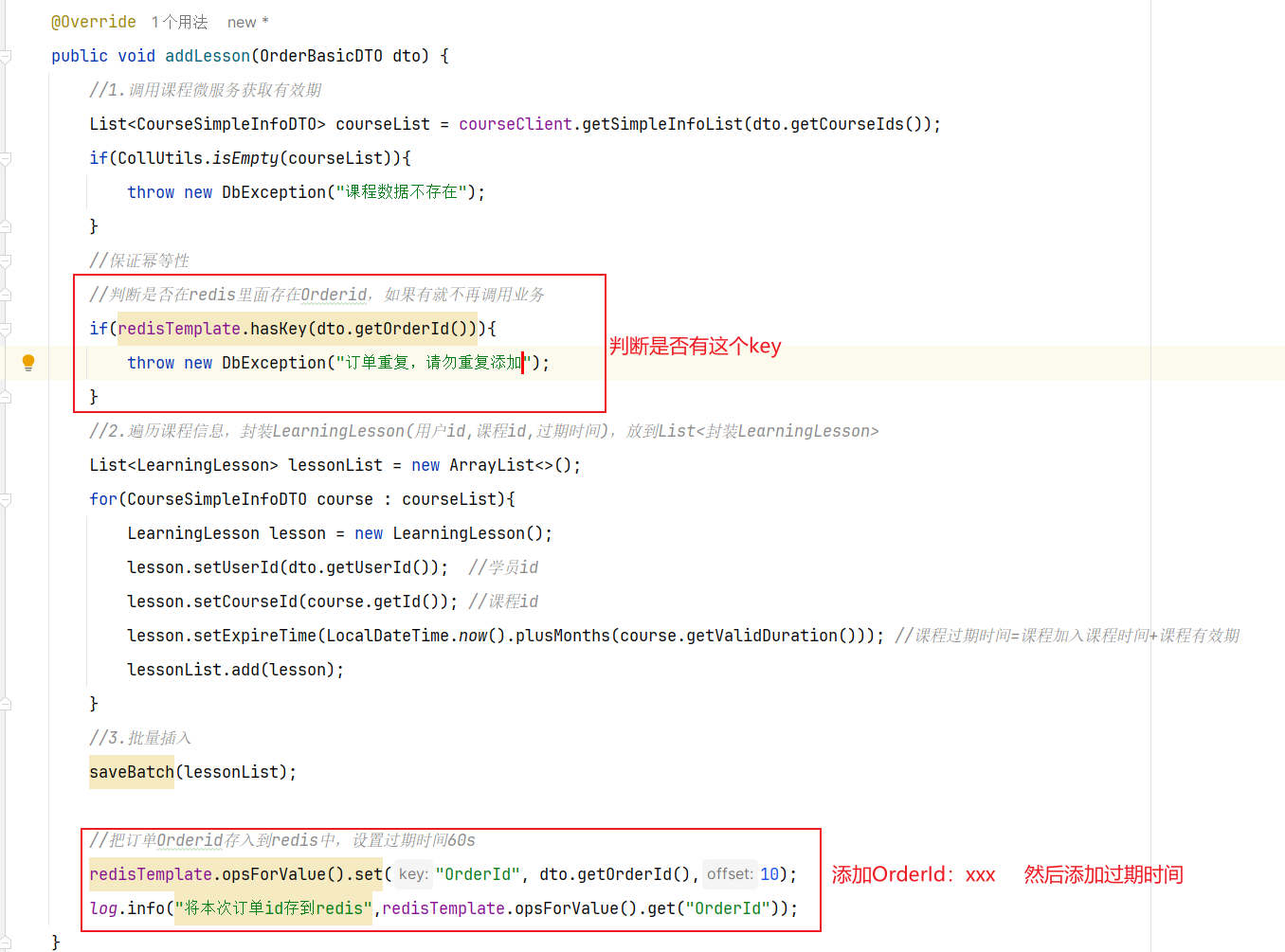
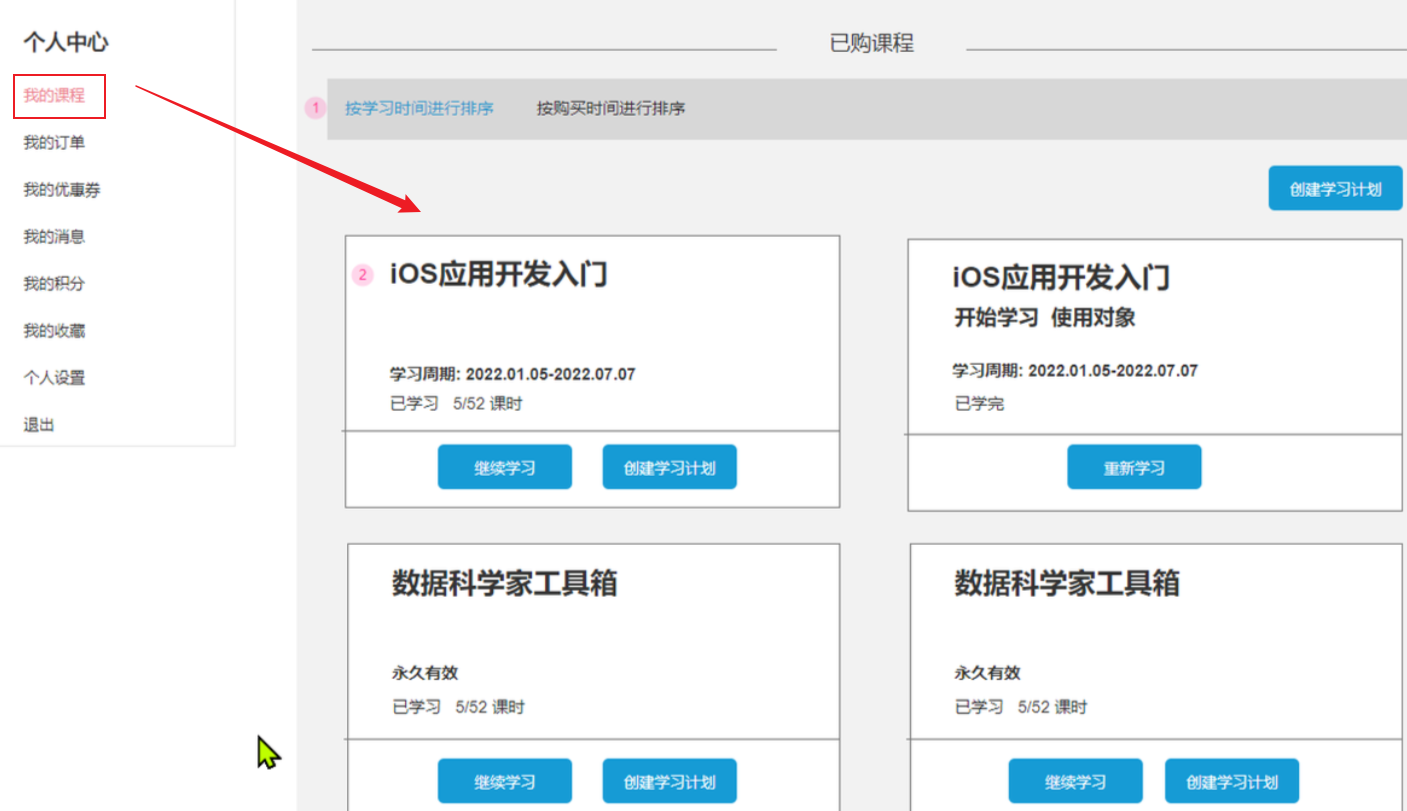
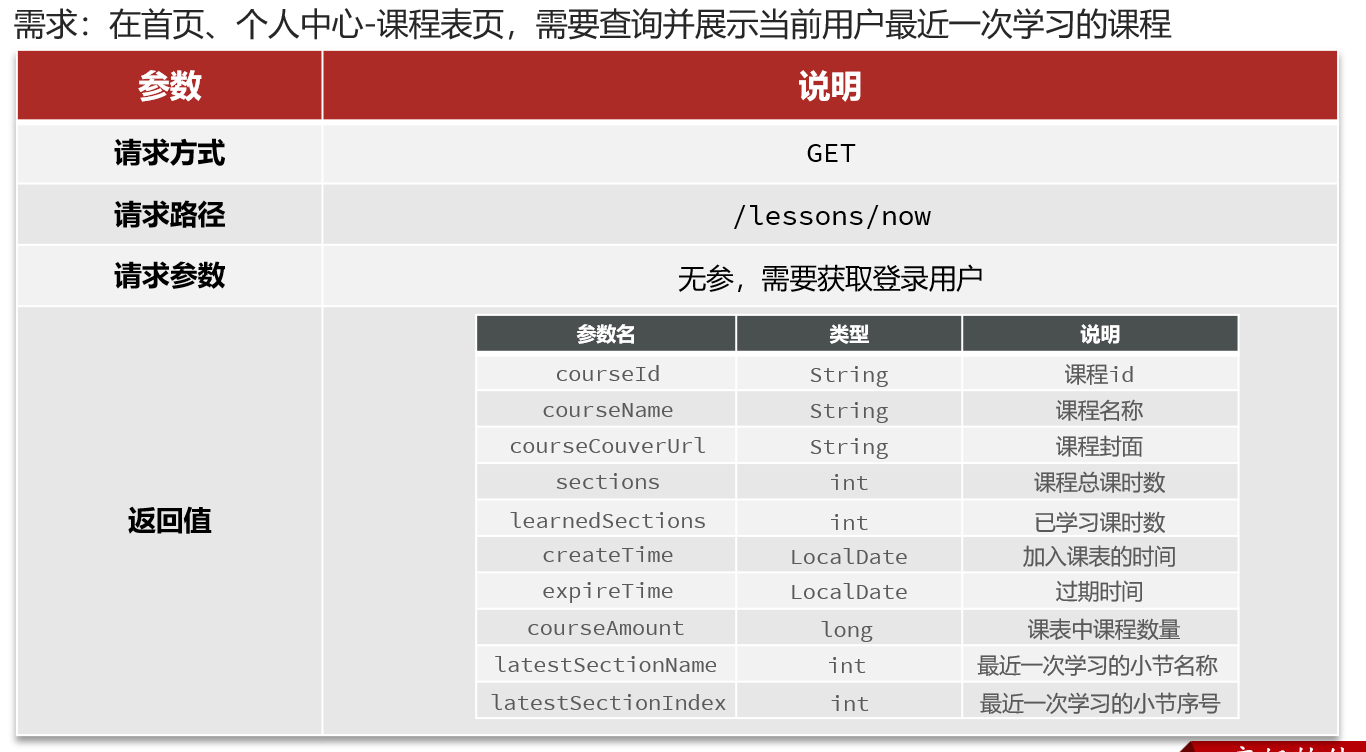
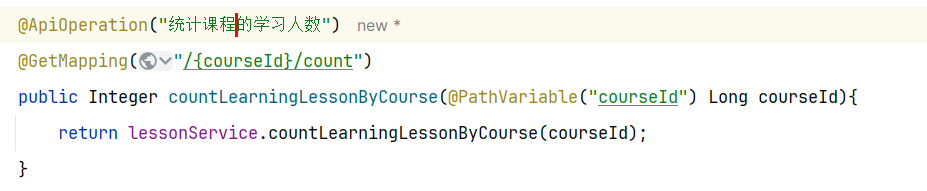
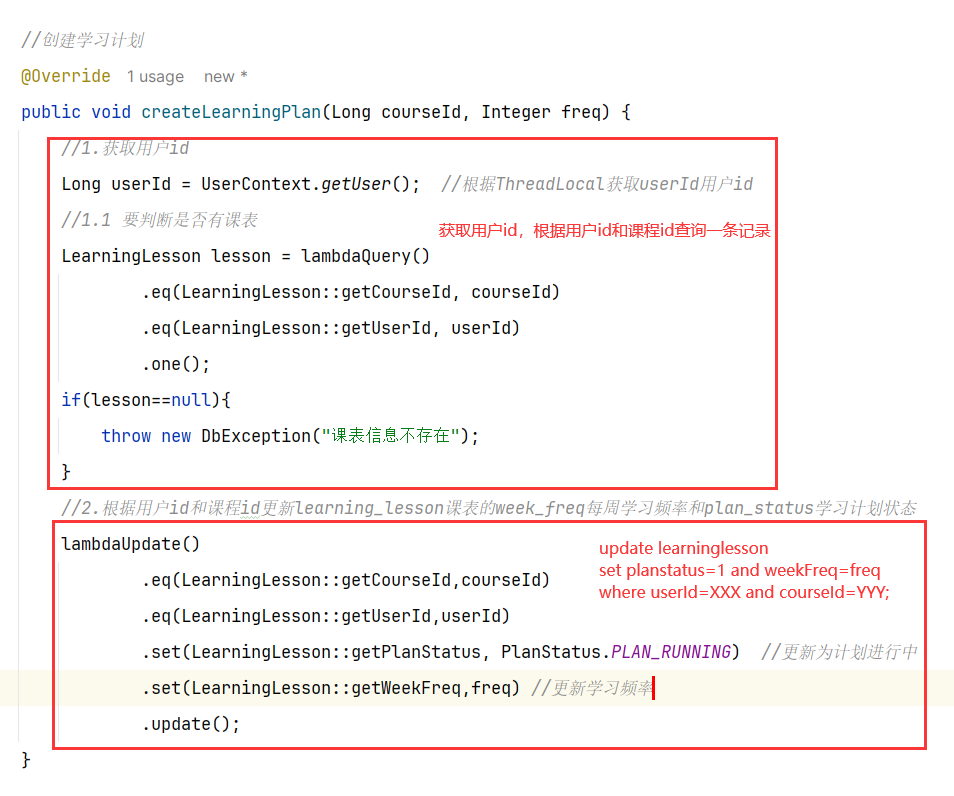
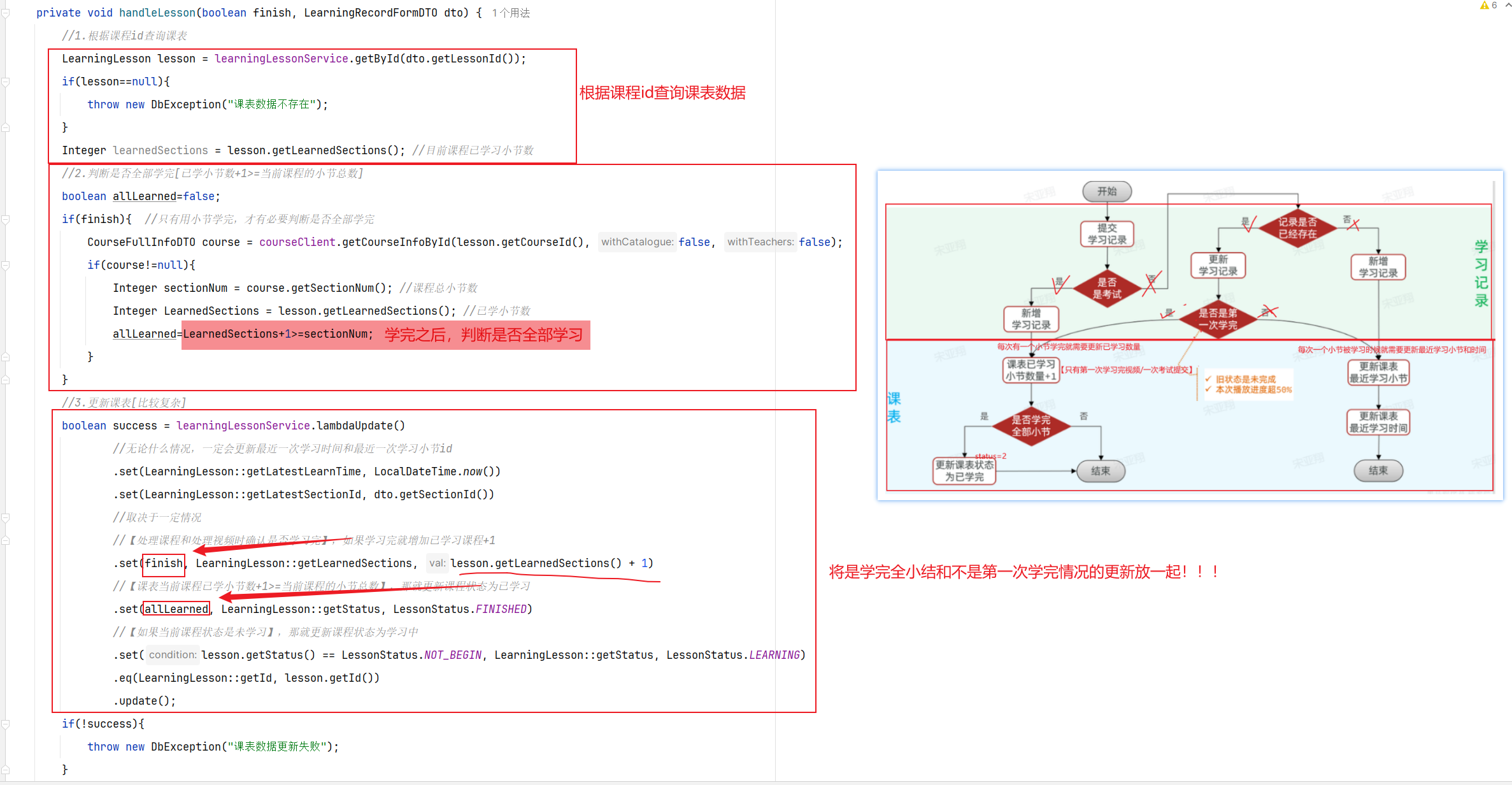
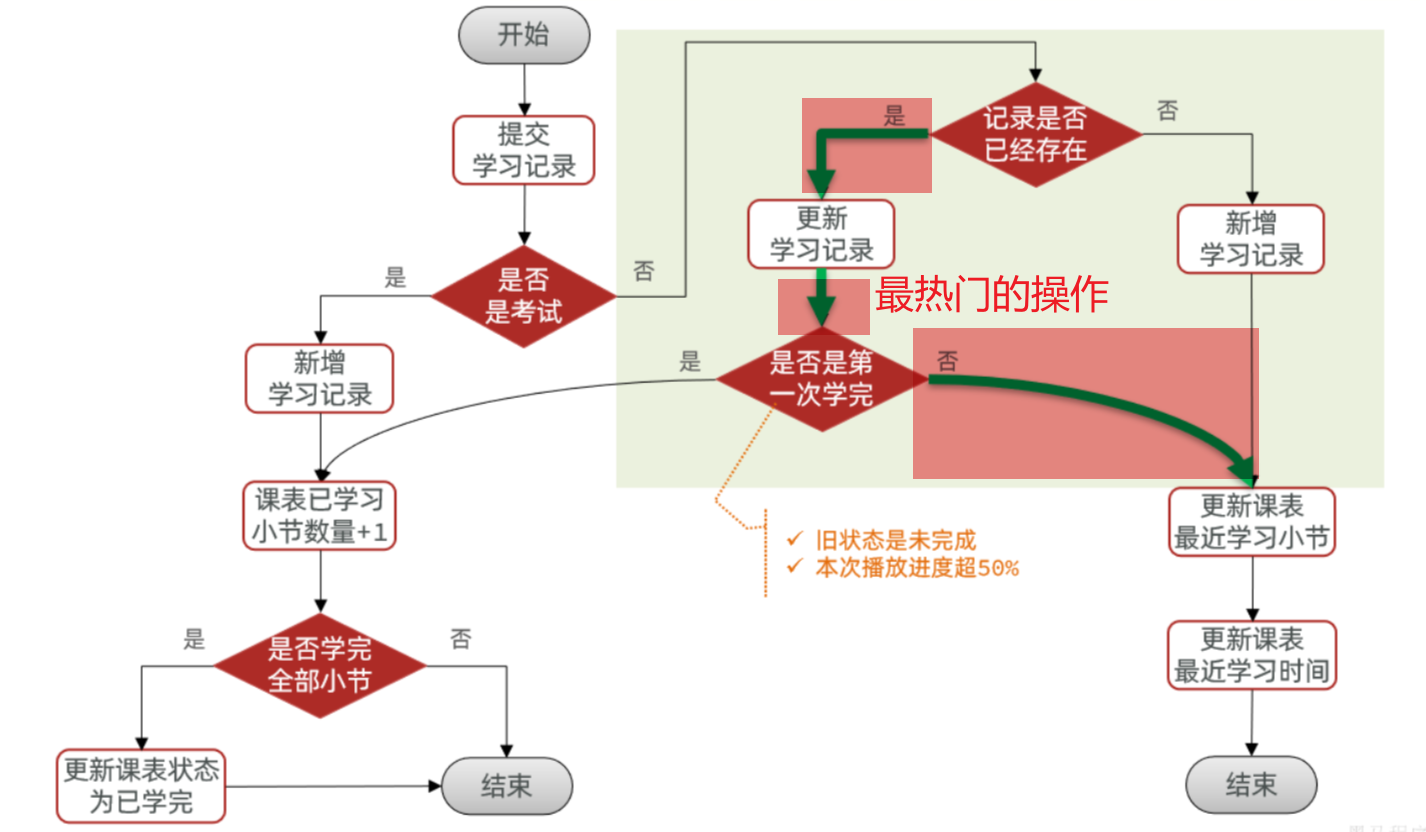
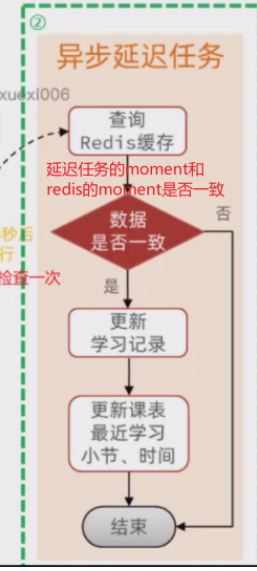
==——–具体实现——–== 1.签到 1.原型图 在个人中心的积分页面,用户每天都可以签到一次,连续签到则有积分奖励,请实现签到接口,记录用户每天签到信息,方便做签到统计。
在个人中心的积分页面,用户每天都可以签到一次:
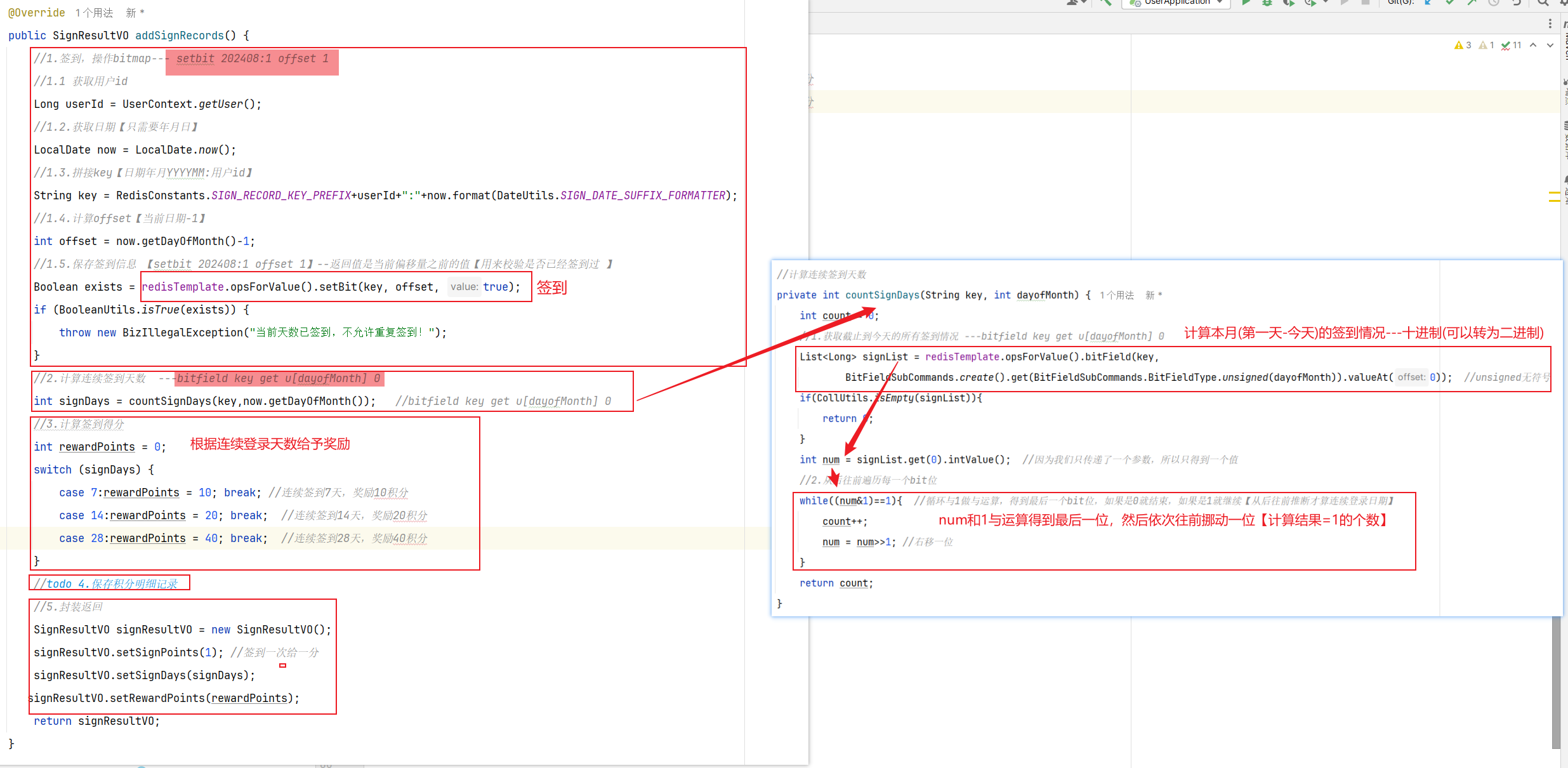
而在后台,要做的事情就是把BitMap中的与签到日期对应的bit位,设置为1
2.设计数据库 3.业务逻辑图
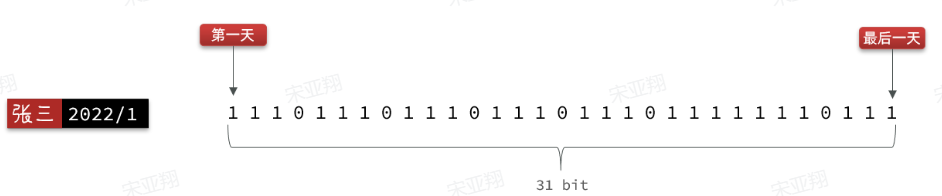
如果我们按月来统计用户签到信息,签到记为1,未签到记为0,就可以用一个长度为31位的二进制数来表示一个用户一个月的签到情况。最终效果如下:
我们知道二进制是计算机底层最基础的存储方式了,其中的每一位数字就是计算机信息量的最小单位了,称之为bit,一个月最多也就 31 天,因此一个月的签到记录最多也就使用 31 bit 就能保存了,还不到 4 个字节【mysql数据库就要使用数百字节】
4.接口分析
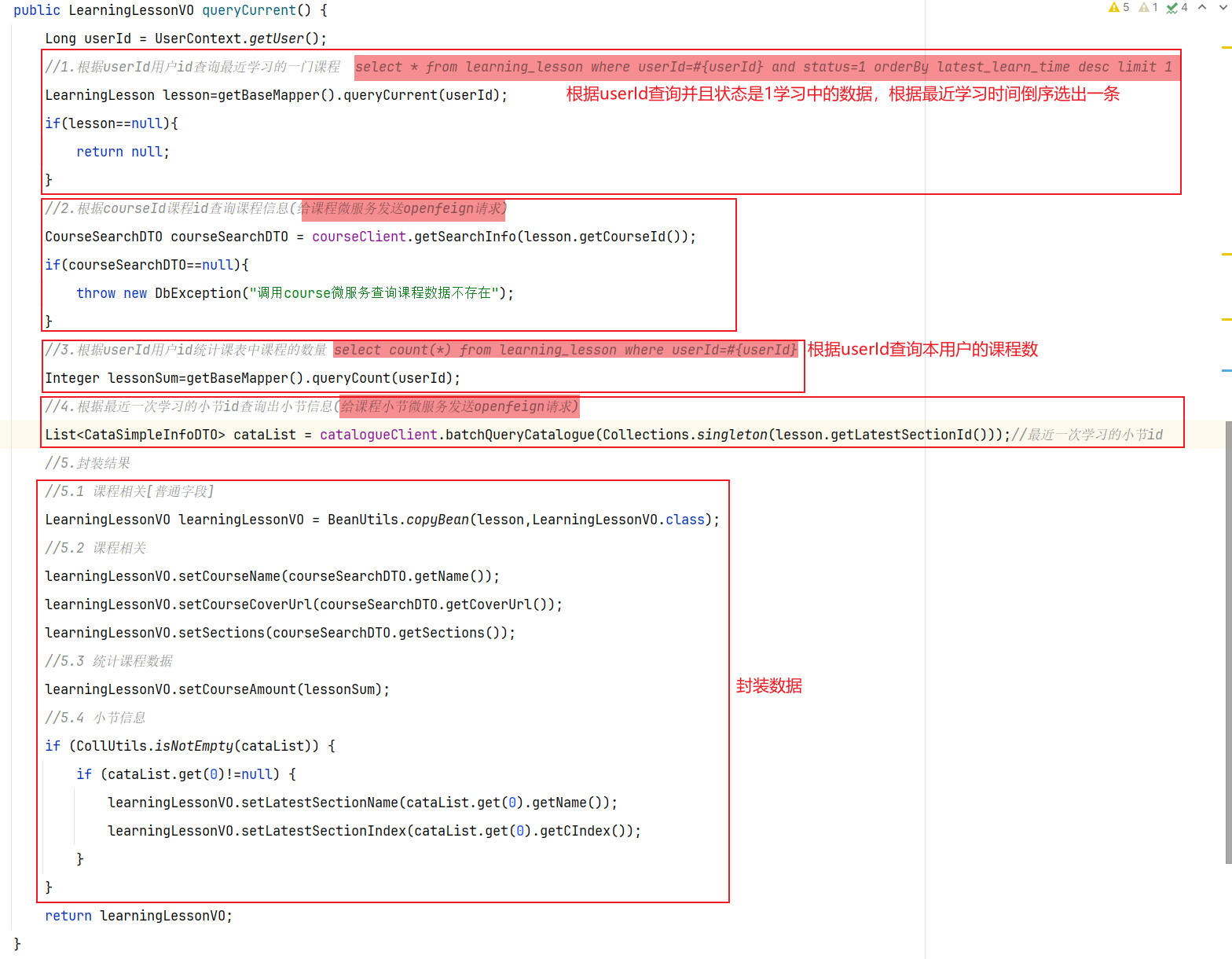
5.具体实现
无
6.具体难点和亮点
问题一:如何涉及签到的数据类型?为什么选redis的bitMap?怎么扩容的?一次扩充8位
考虑签到只需要1/0,那就使用bitMap;然后YYMM:Userid就是一个bitMap【代表某人某年某月的登录】,一共设计31个bit位就可以代表一个月的签到数据;扩容的话是8位一组,一般一个月就是4组32位(最后一位暂时没有用)
问题二:连续签到天数怎么计算?怎么从bitMap获取?怎么从后往前遍历?
连续登录天数:从当前天从后往前算连续1的个数【一定是从后往前】;从后往前就用算出来的十进制数&1做与运算【只关心最后一位结果】,然后右移十进制得到前面的一位
1 2 3 4 5 int count = 0; // 定义一个计数器 for(/*从后向前遍历签到记录中的每一个bit位*/){ // 判断是否是1 // 如果是,则count++ }
问题三:怎么判断重复签到?
利用setbit返回值的特性
问题四:bitmap用哪些指令了?
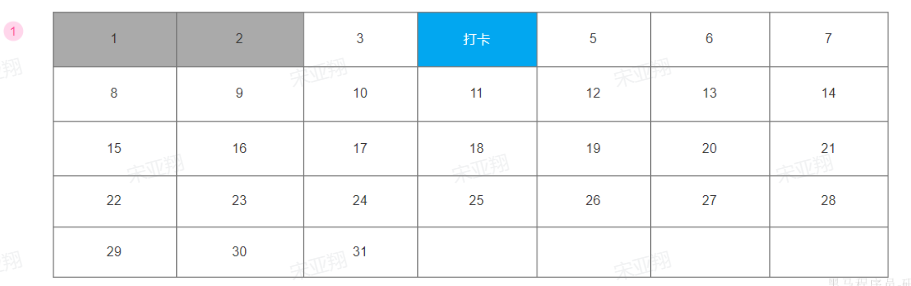
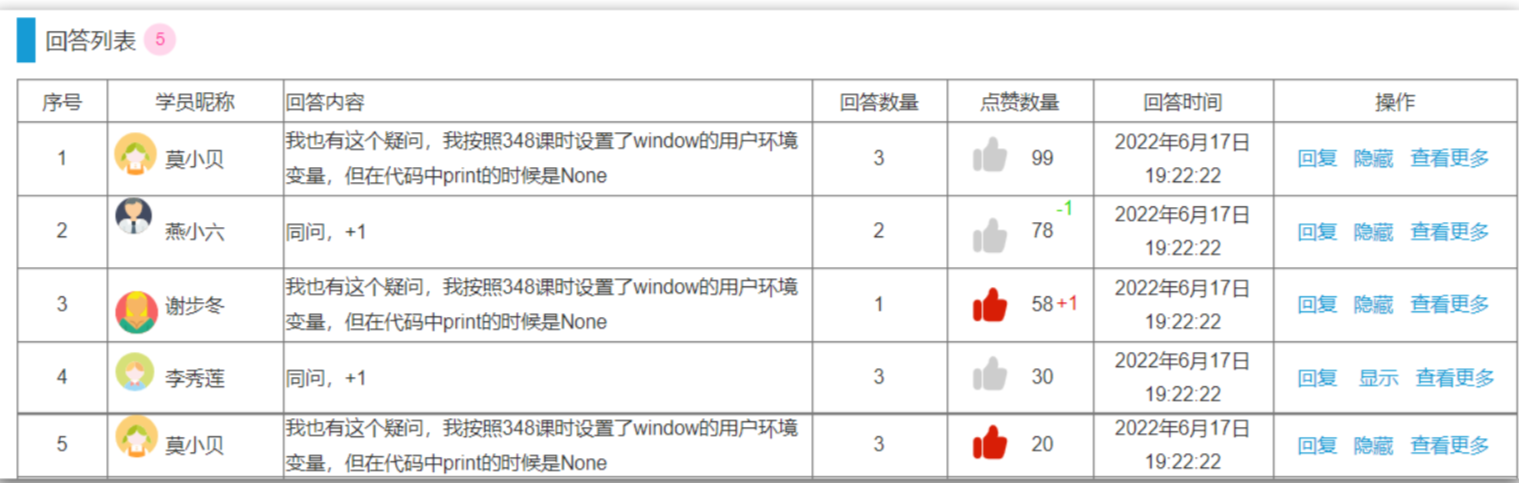
2.查询我的本月签到记录 1.原型图 在签到日历中,需要把本月(第一天-今天)的所有签到过的日期高亮显示。
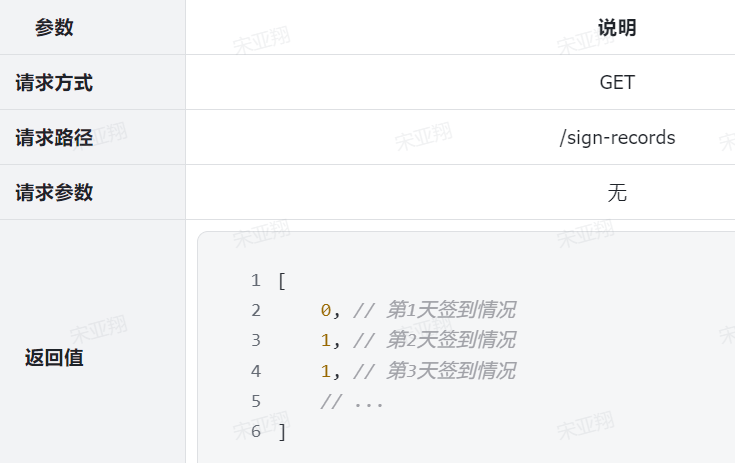
因此我们必须把签到记录返回,具体来说就是每一天是否签到的数据。是否签到,就是0或1,刚好在前端0和1代表false和true,也就是签到或没签到。
因此,每一天的签到结果就是一个0或1的数字,我们最终返回的结果是一个0或1组成的数组,对应从本月第1天到今天为止每一天的签到情况。
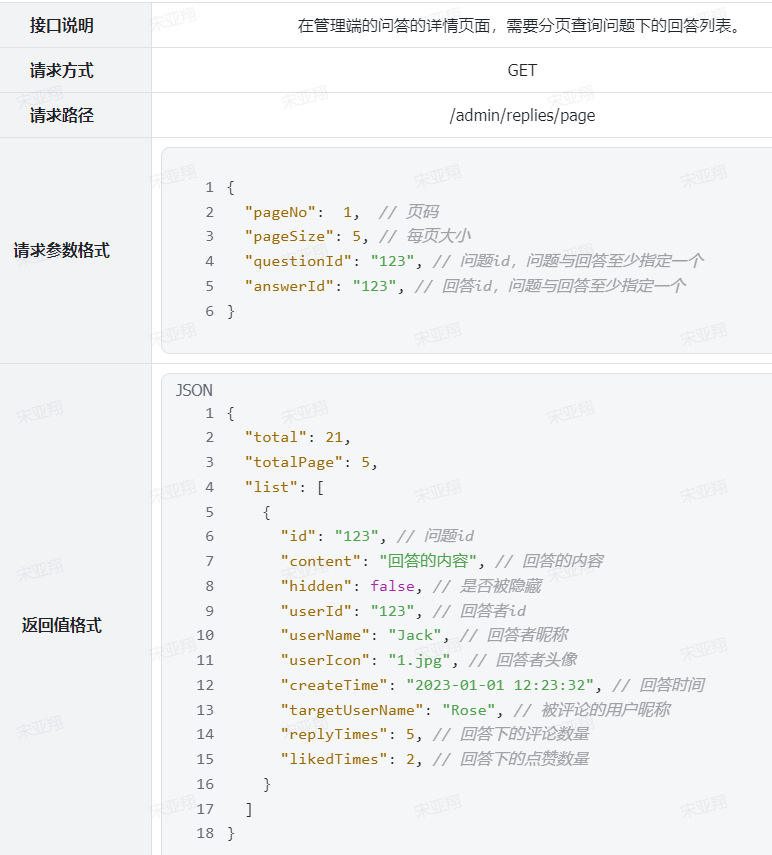
2.设计数据库 3.业务逻辑图 4.接口分析 综上,最终的接口如下:
5.具体实现
无
6.具体难点和亮点
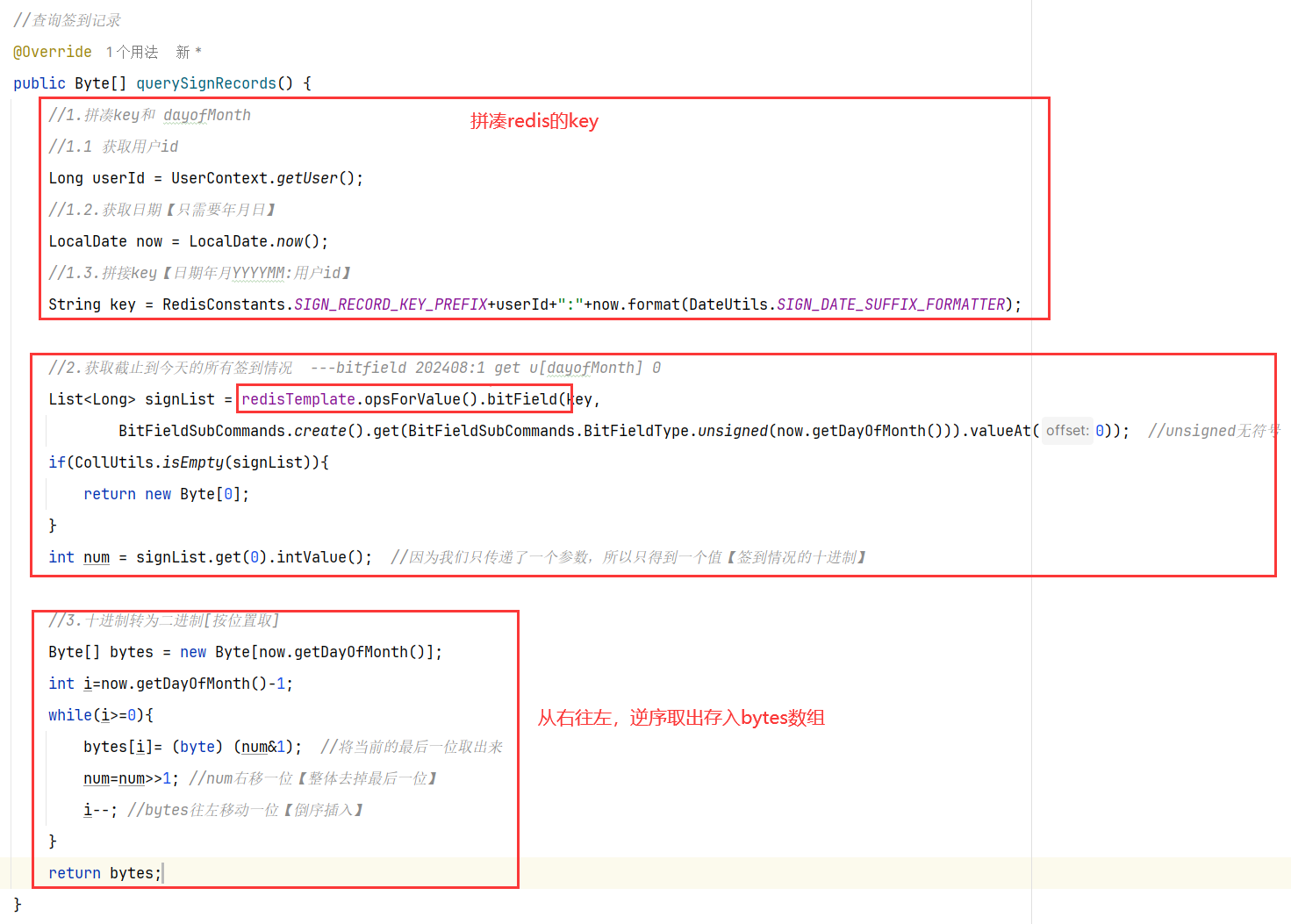
问题一:如何获取本月的登录记录?
根据bitfield指令可以获得本月等登录记录(0001…0111001)的十进制数字
问题二:如何转为二进制,并且统计转为byte数组?
第一种办法,十进制转为字符串二进制,然后二进制char的for循环遍历得到byte[①必须-‘0’才是数字1,不然是ascii码的48;②因为十进制不是32位,转出来也不是32位!!!]
第二种办法,按照统计连续天数的思路(10进制与1进行与运算,可以依次倒序取出所有的0/1,然后逆序一下就是结果)
==——————————————== ==—————-积分功能—————-==
积分:用户在天机学堂网站的各种交互行为都可以产生积分,积分值与行为类型有关
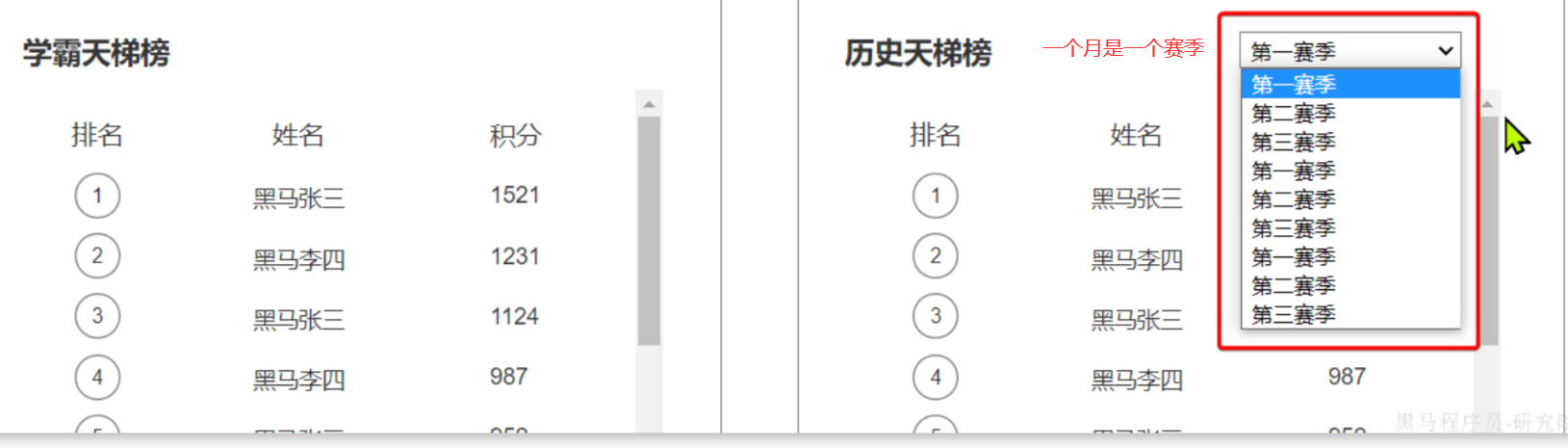
学霸天梯榜:按照每个学员的总积分排序得到的排行榜,称为学霸天梯榜。排名前三的有奖励。天梯榜每个自然月为一个赛季,月初清零
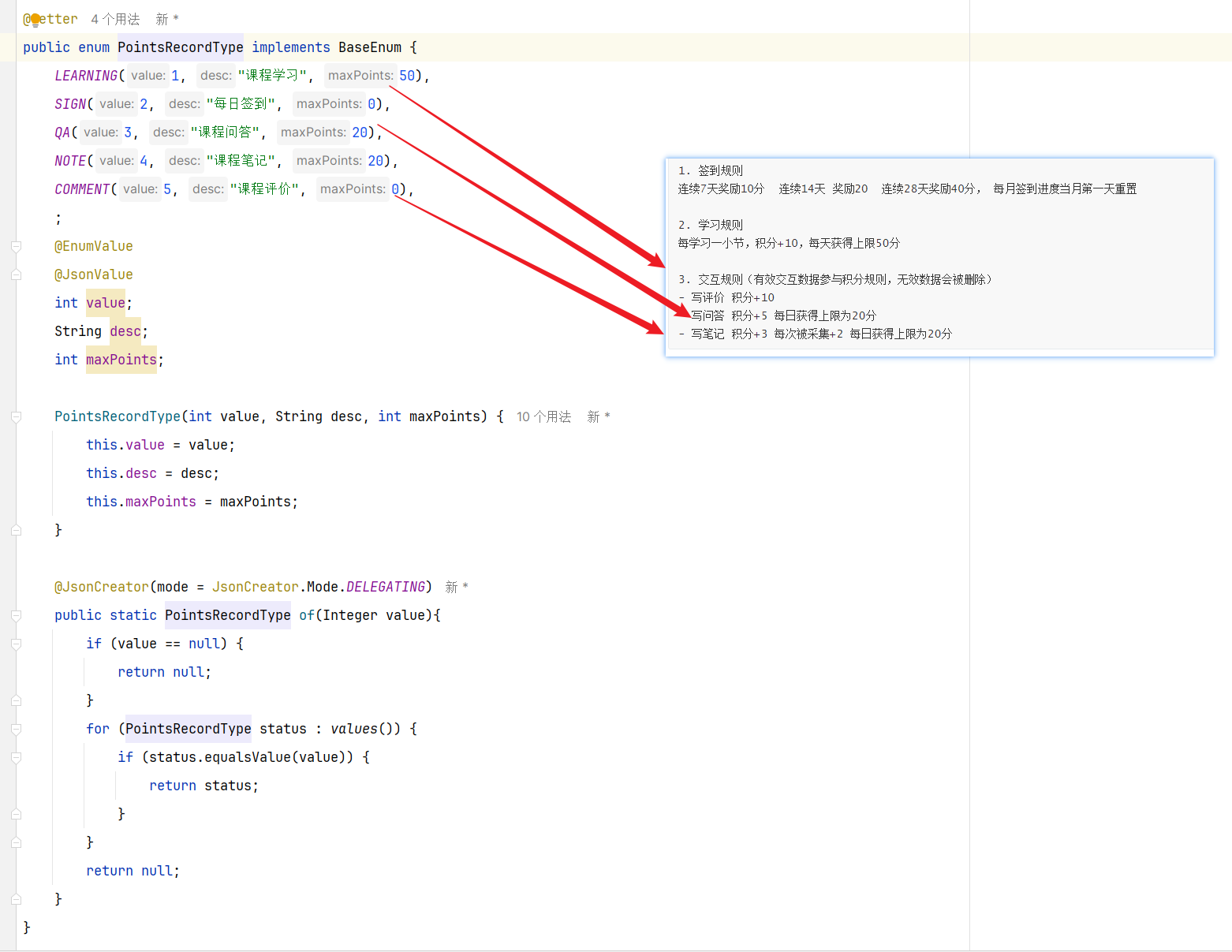
准备阶段—分析业务流程 具体的积分获取细则如下:
1 2 3 4 5 6 7 8 9 10 1. 签到规则 连续7天奖励10分 连续14天 奖励20 连续28天奖励40分, 每月签到进度当月第一天重置【本篇文章的签到!!!!!!!】 2. 学习规则 每学习一小节,积分+10,每天获得上限50分 3. 交互规则(有效交互数据参与积分规则,无效数据会被删除) - 写评价 积分+10 - 写问答 积分+5 每日获得上限为20分 - 写笔记 积分+3 每次被采集+2 每日获得上限为20分
用户获取积分的途径有5种:
签到:在个人积分页面可以每日签到,每次签到得1分,连续签到有额外积分奖励。
学习:也就是看视频
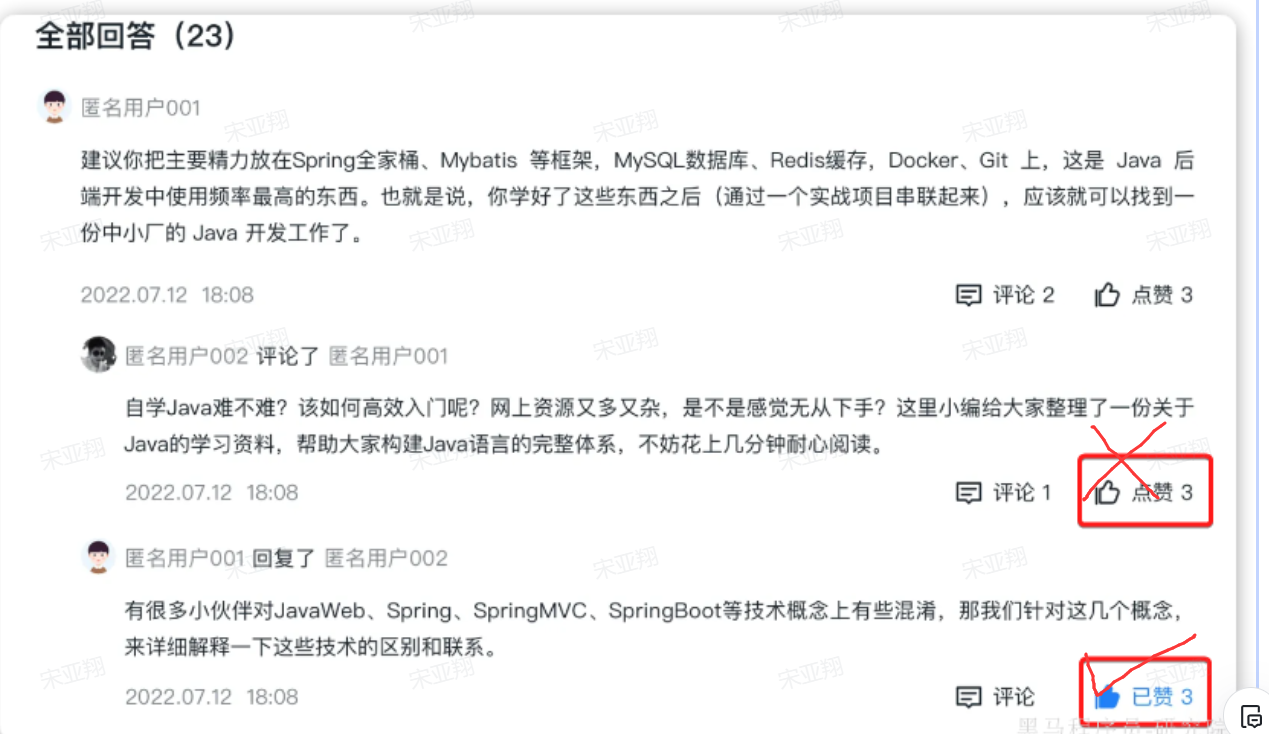
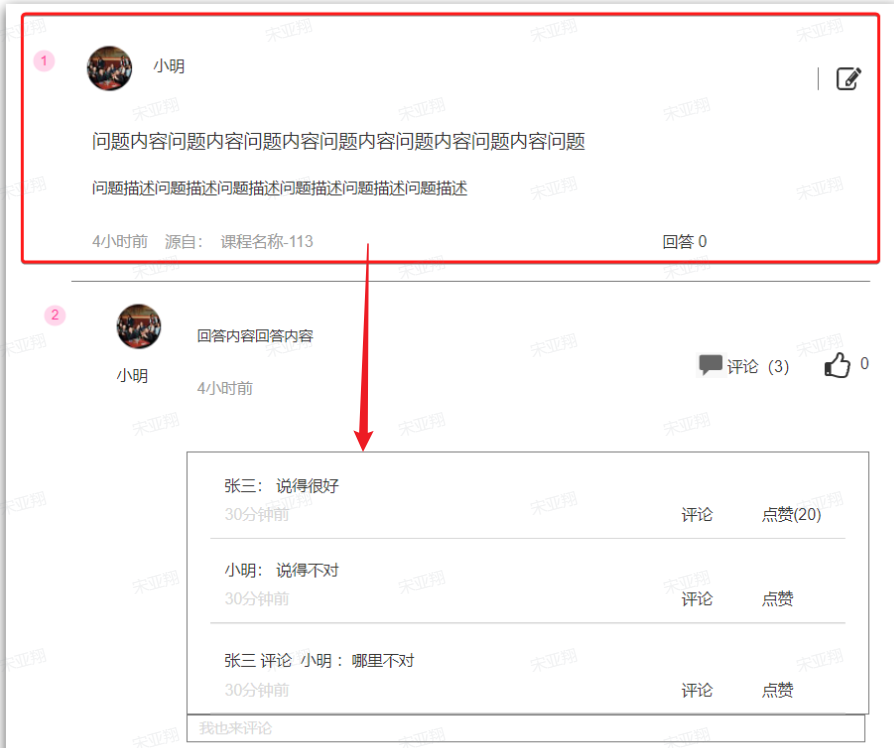
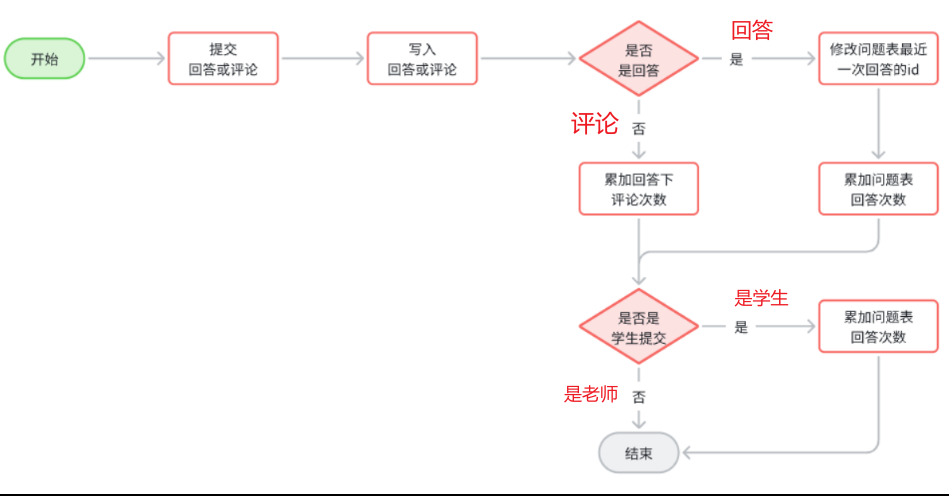
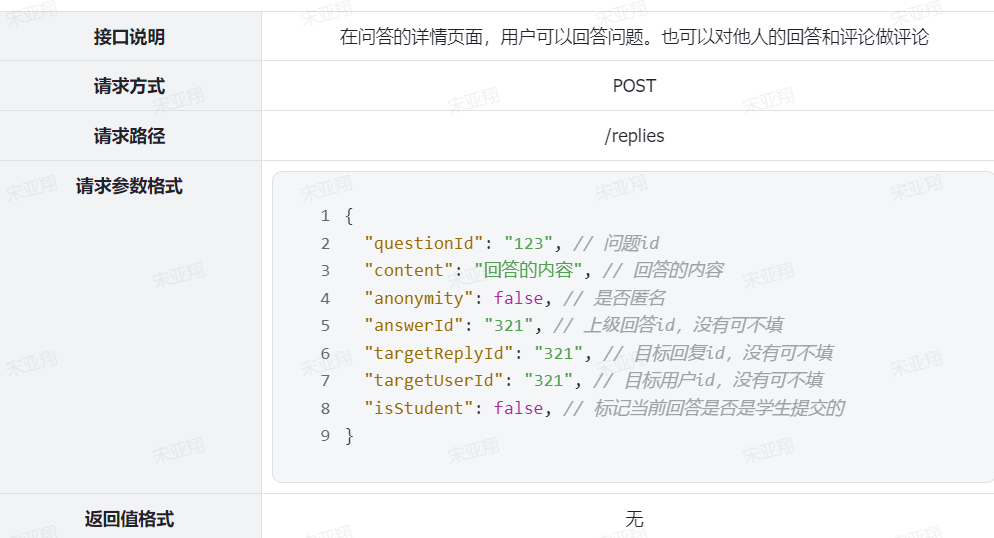
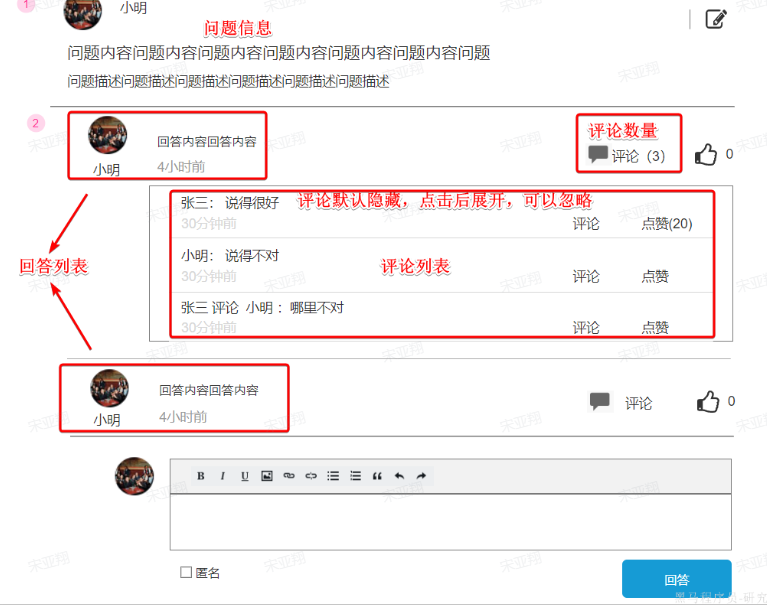
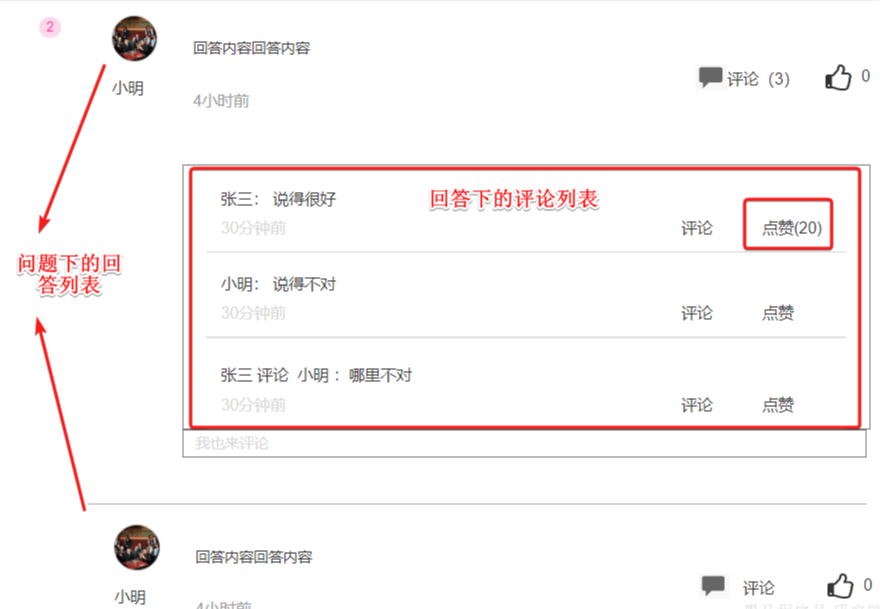
写回答:就是给其他学员提问的问题回答,给回答做评论是没有积分的。
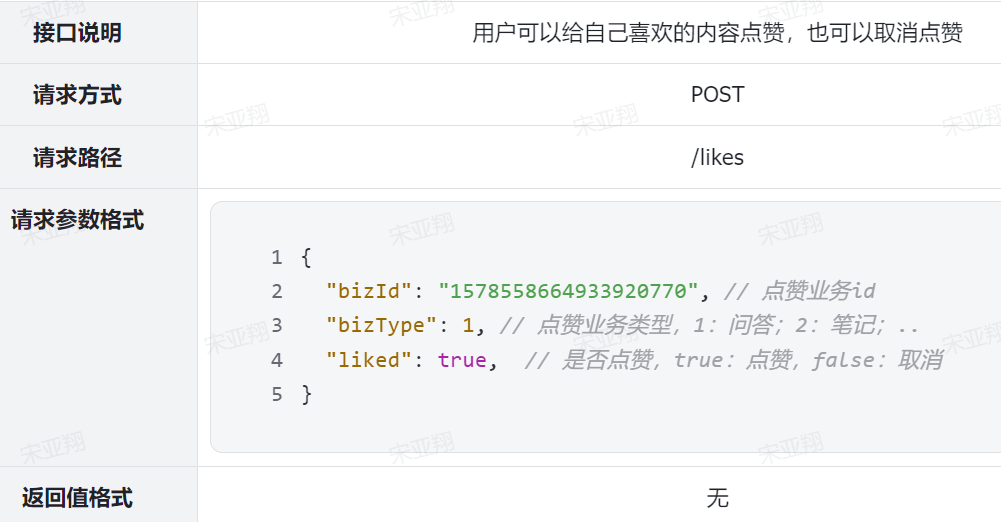
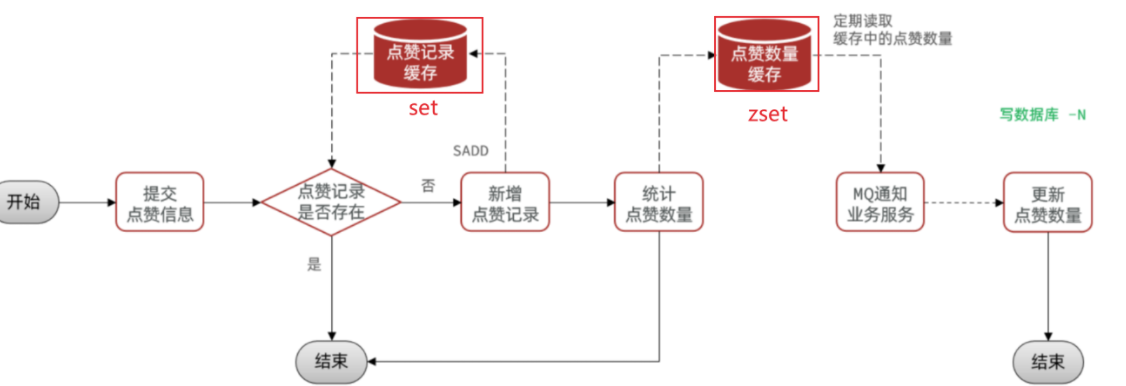
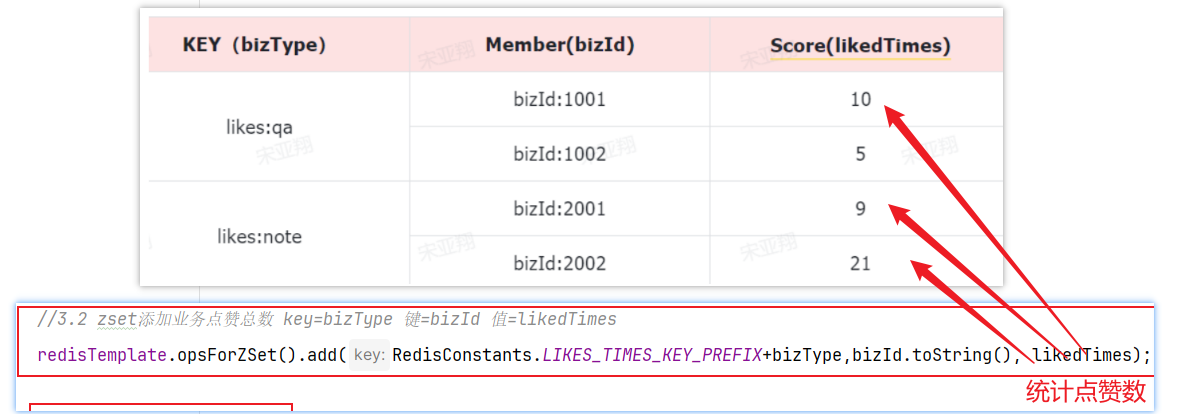
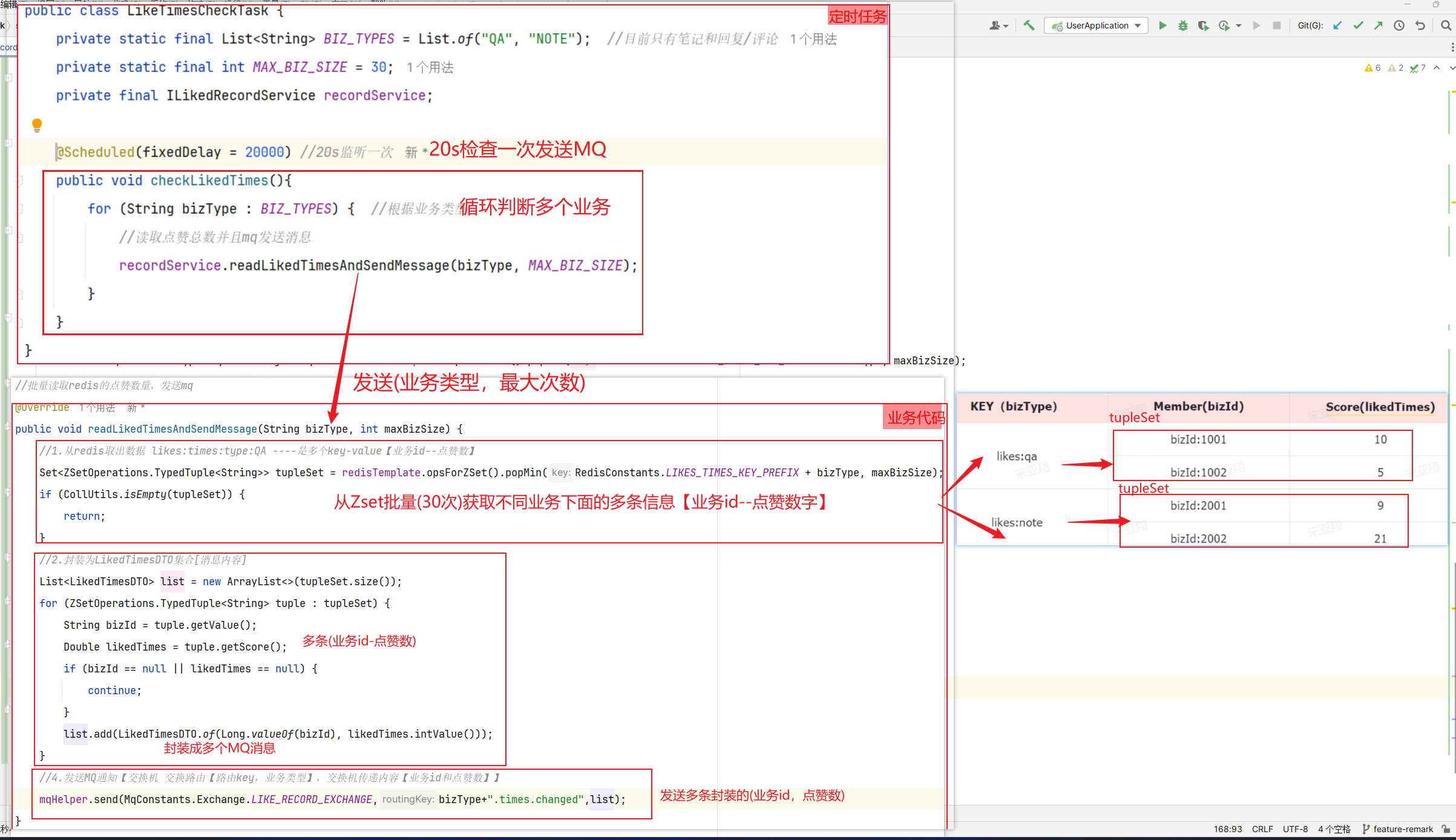
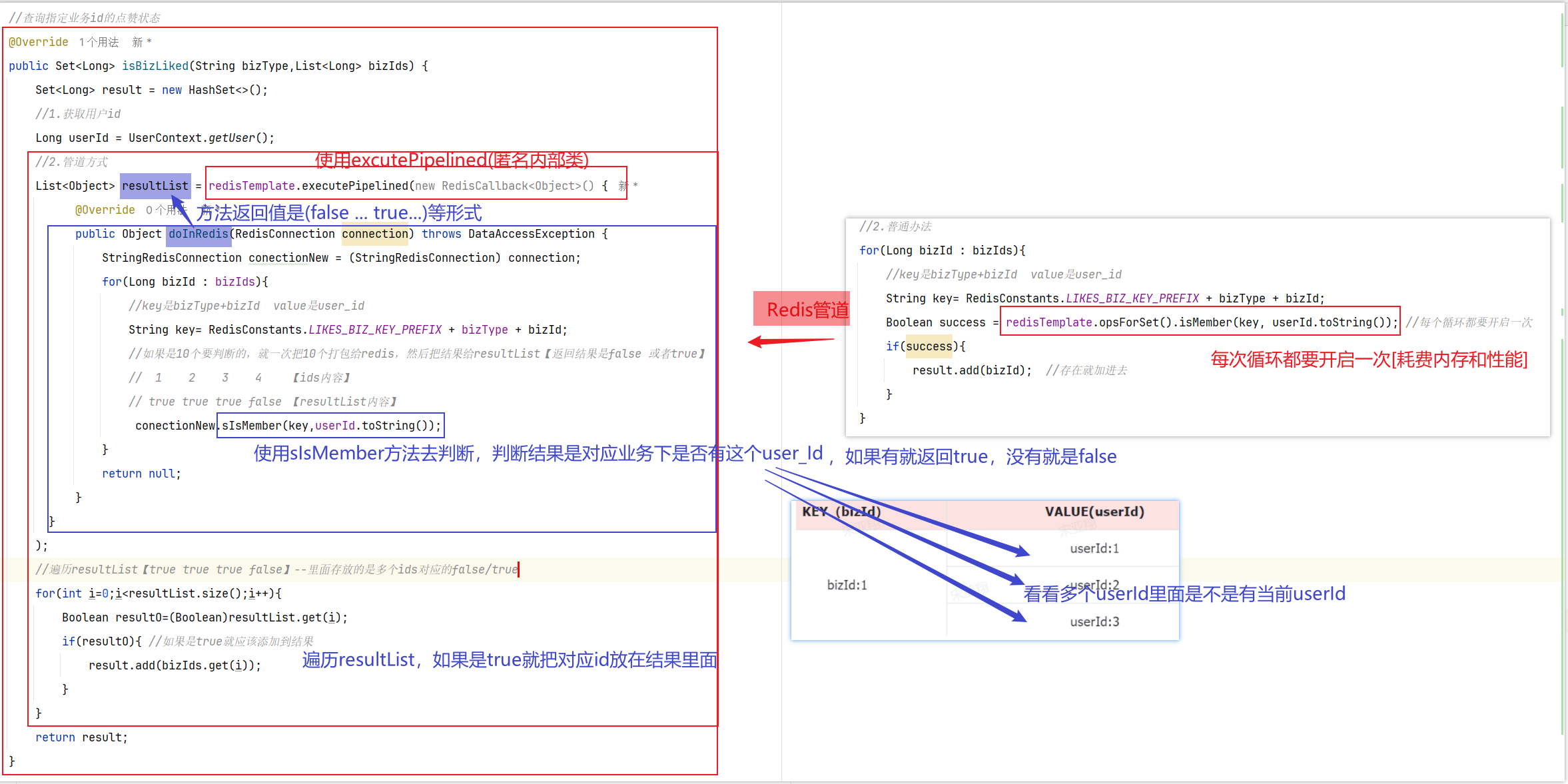
写笔记:就是学习的过程中记录公开的学习笔记,分享给所有人看。或者你的笔记被人点赞。
写评价:对你学习过的课程评价,可以获取积分。但课程只能评价一次。
这个页面信息比较密集,从上往下来看分三部分:
顶部:当前用户在榜单中的信息
中部:签到表
下部:分为左右两侧
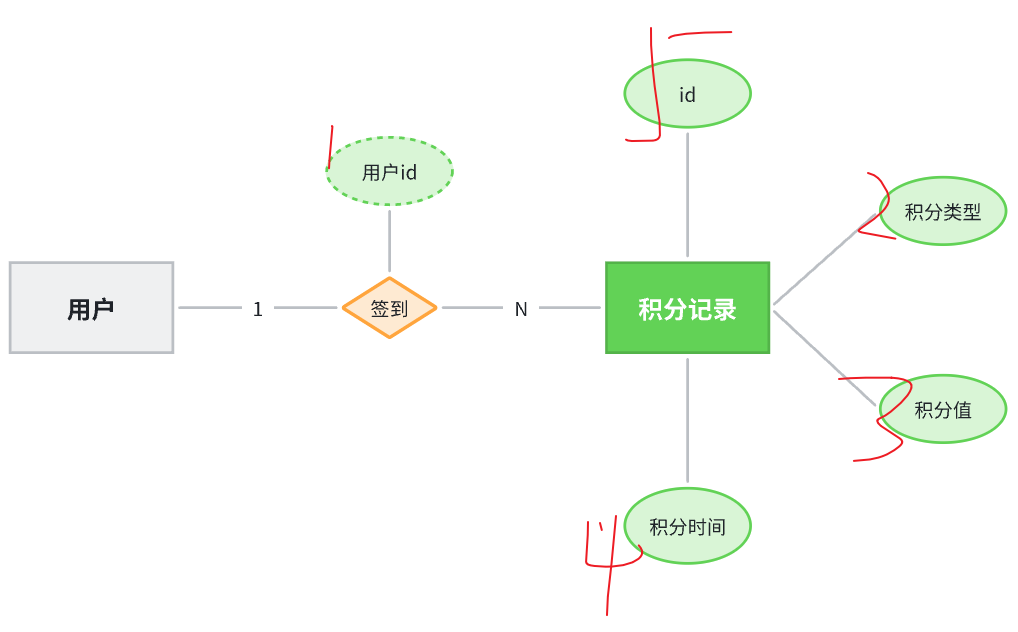
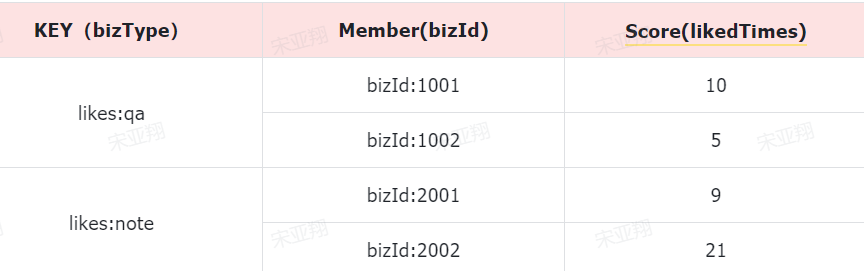
准备阶段—字段分析 积分记录的目的有两个:一个是统计用户当日某一种方式获取的积分是否达到上限;一个是统计积分排行榜。
要达成上述目的我们至少要记录下列信息:
本次得到积分值
积分方式
获取积分时间
获取积分的人
准备阶段—ER图
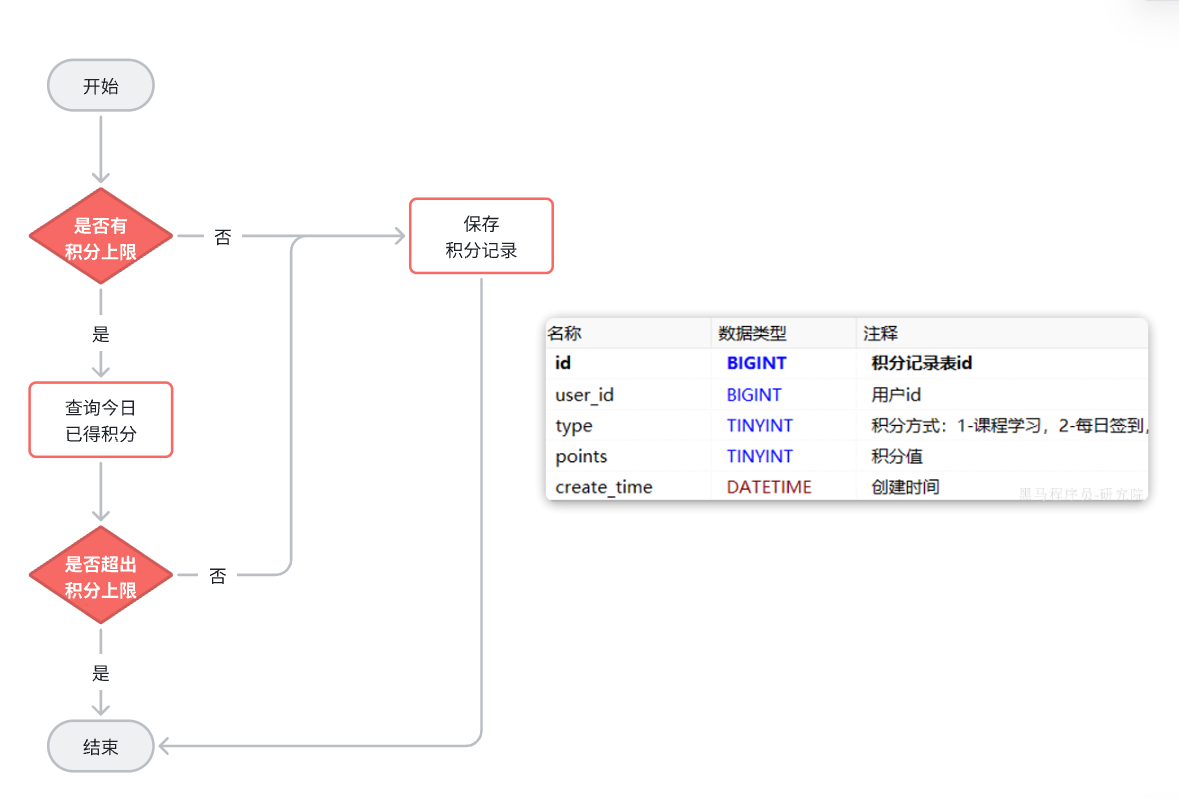
准备阶段—表结构 1 2 3 4 5 6 7 8 9 10 CREATE TABLE IF NOT EXISTS `points_record` ( `id` bigint NOT NULL AUTO_INCREMENT COMMENT '积分记录表id', `user_id` bigint NOT NULL COMMENT '用户id', `type` tinyint NOT NULL COMMENT '积分方式:1-课程学习,2-每日签到,3-课程问答, 4-课程笔记,5-课程评价', `points` tinyint NOT NULL COMMENT '积分值', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`) USING BTREE, KEY `idx_user_id` (`user_id`,`type`) USING BTREE, KEY `idx_create_time` (`create_time`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=41 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='学习积分记录,每个月底清零';
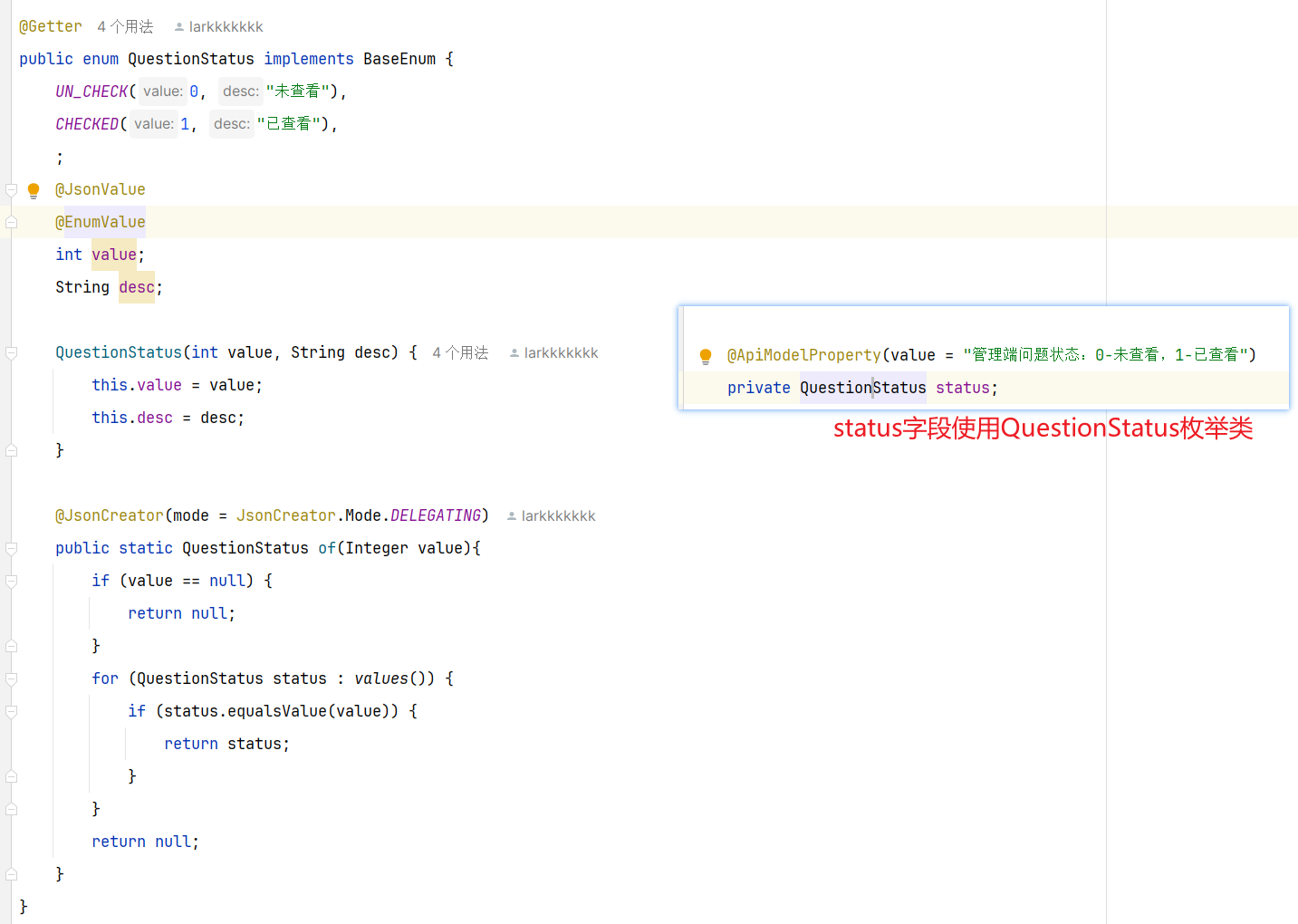
准备阶段—Mybatis-Plus代码生成 准备阶段–类型枚举 针对数据库的积分类型字段:设计成枚举类型
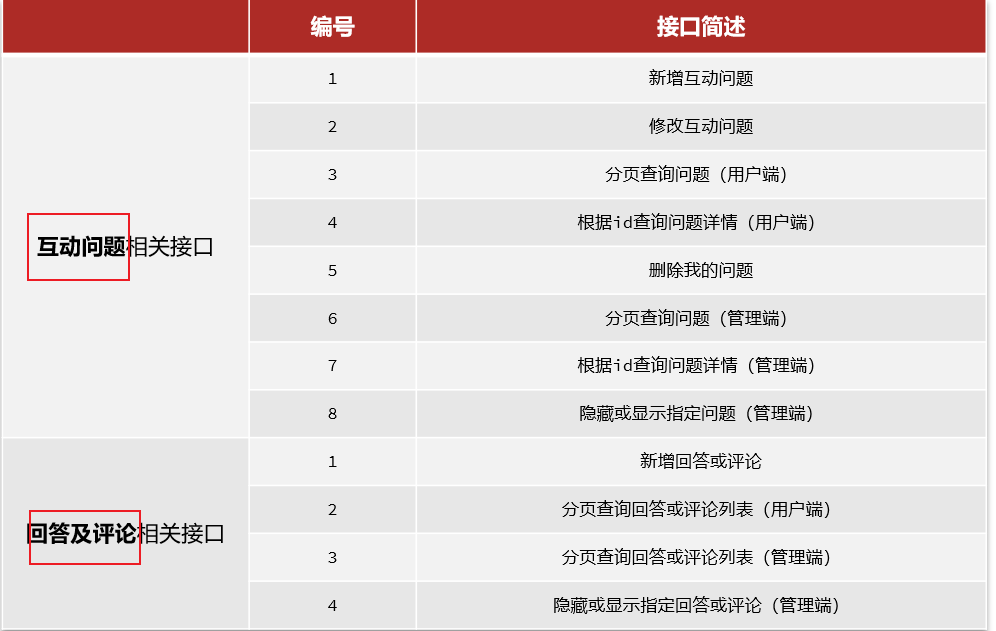
准备阶段–接口统计
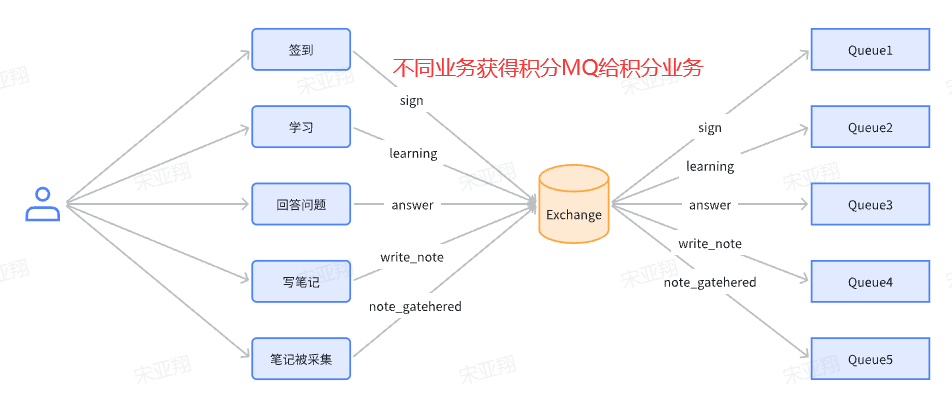
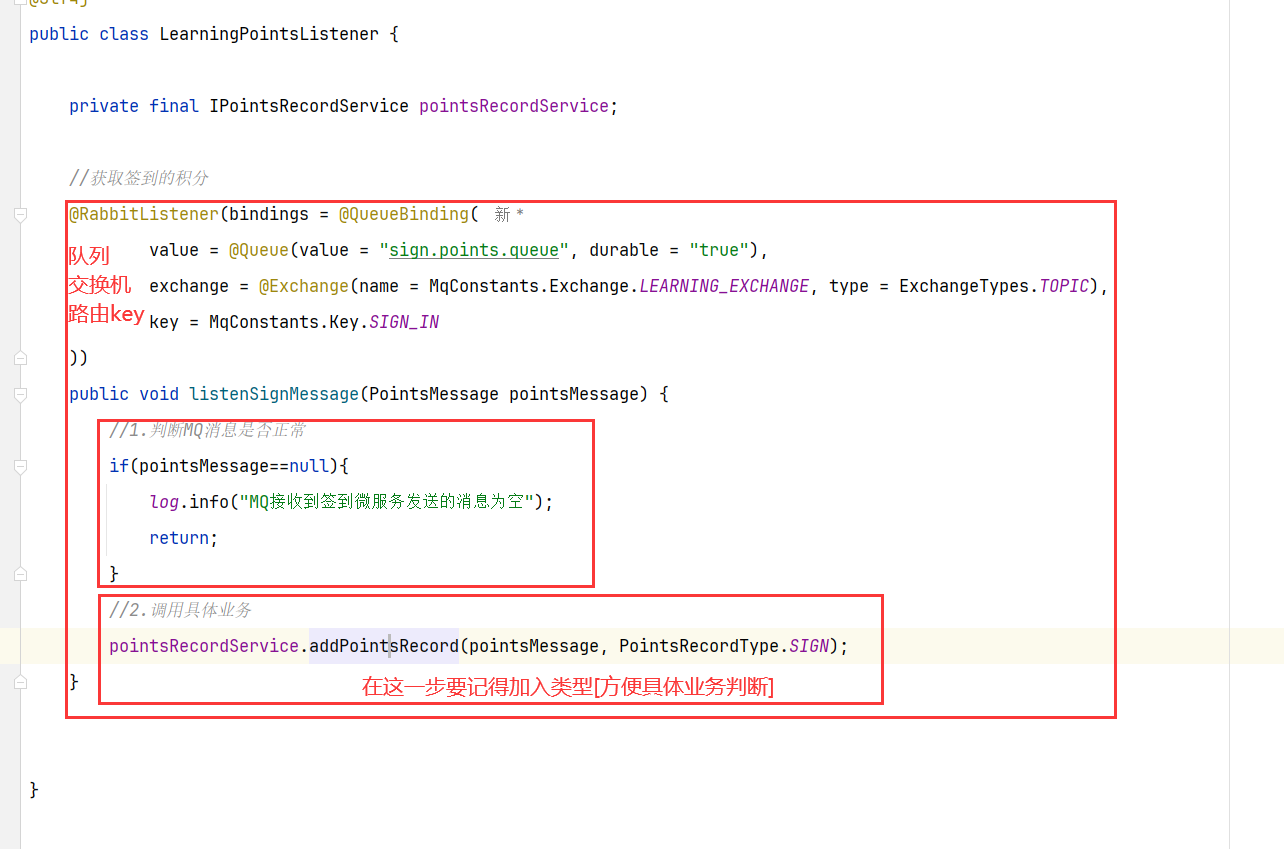
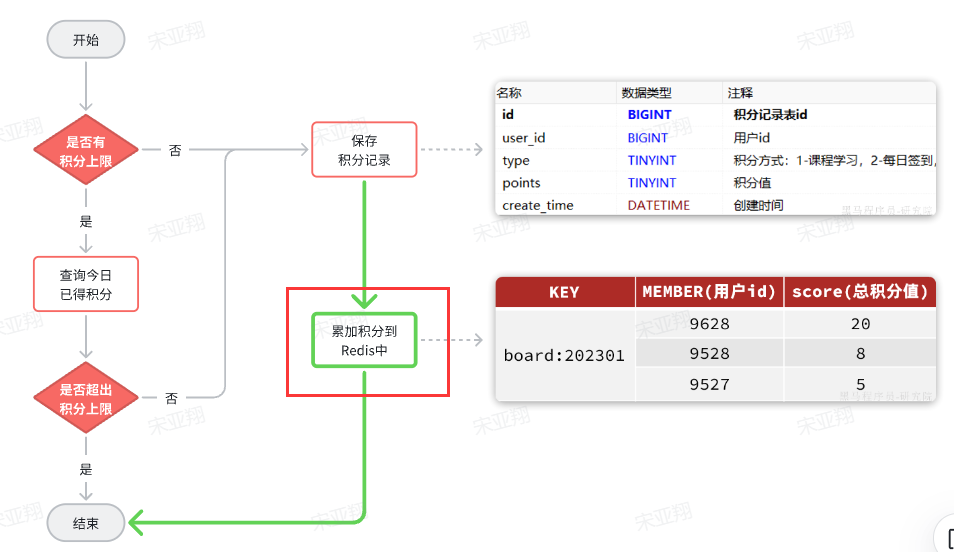
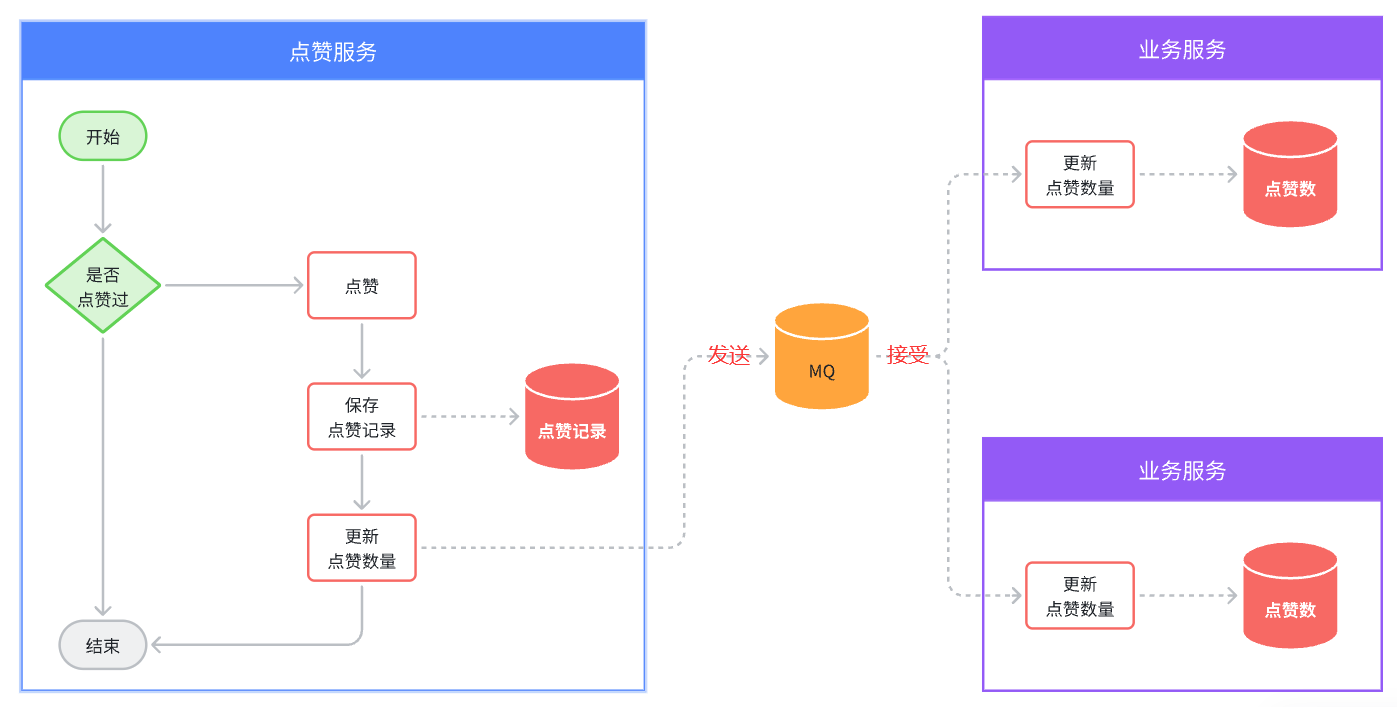
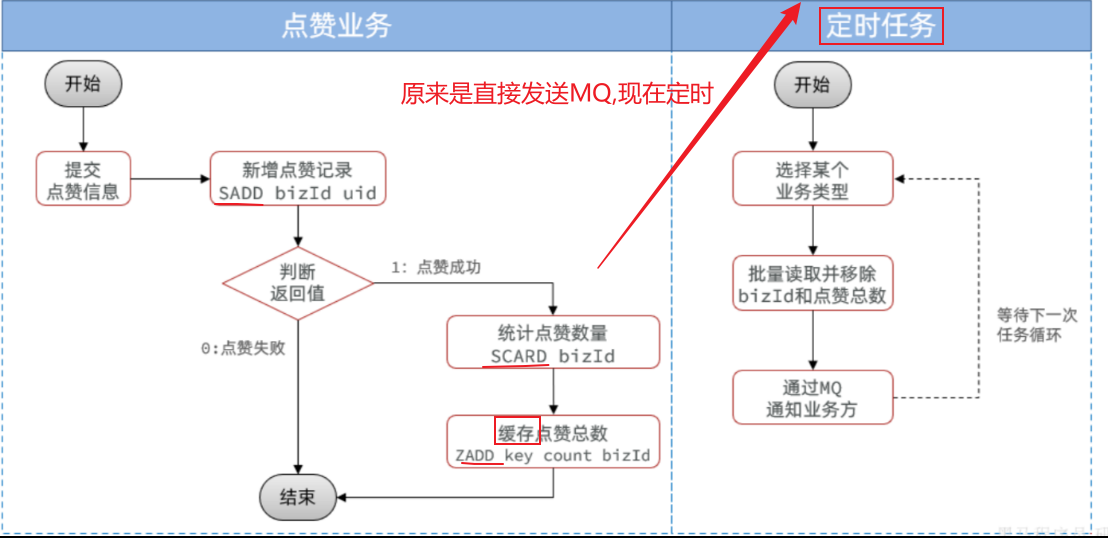
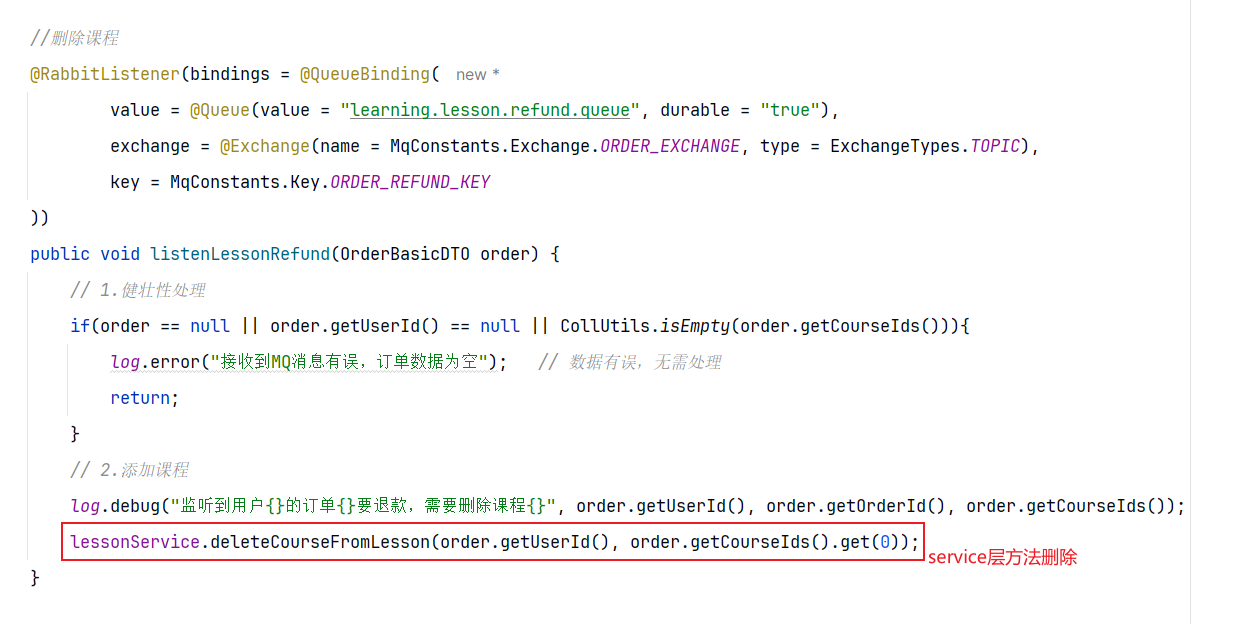
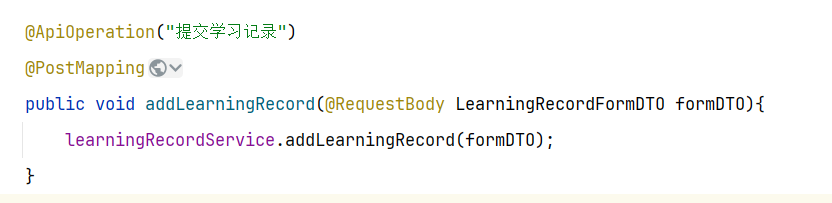
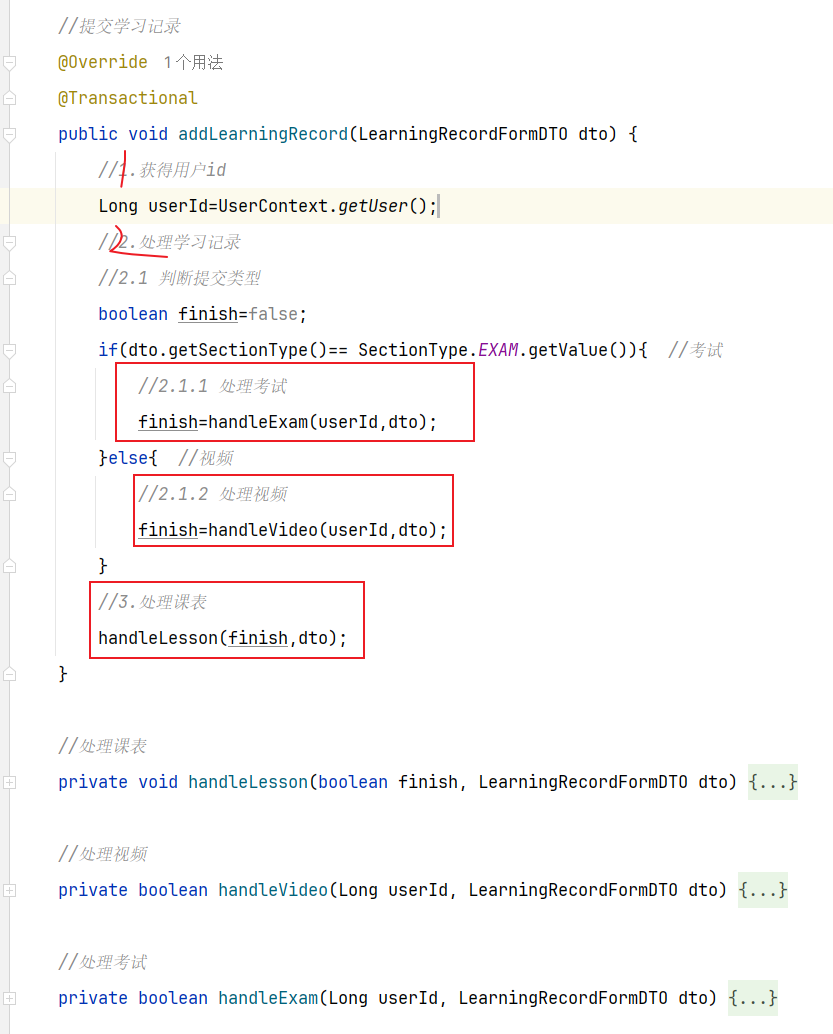
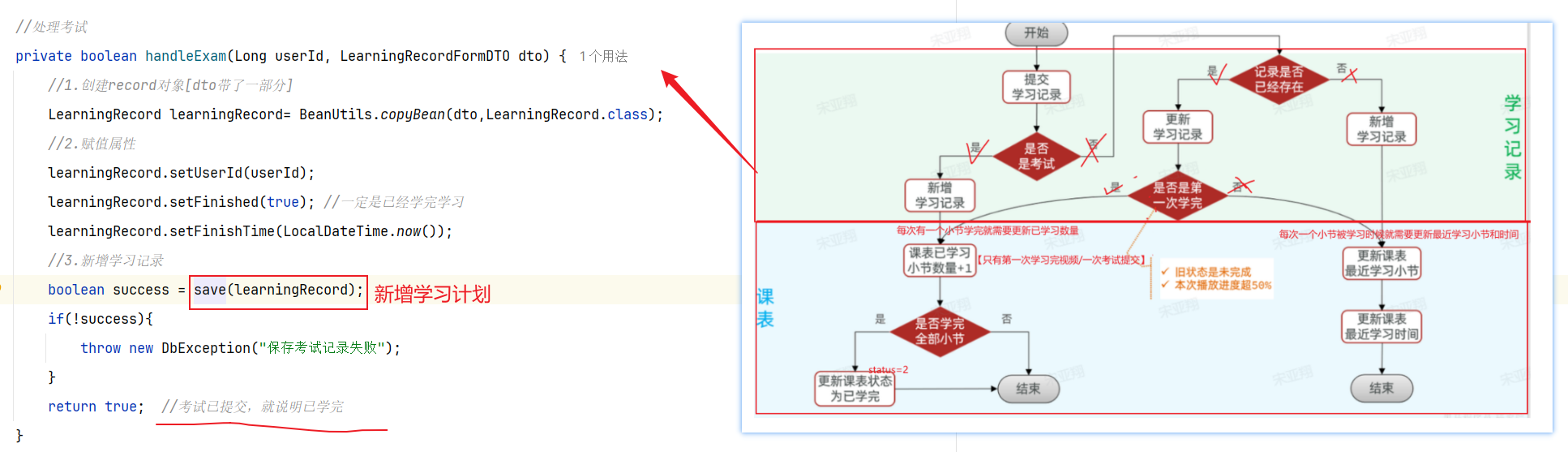
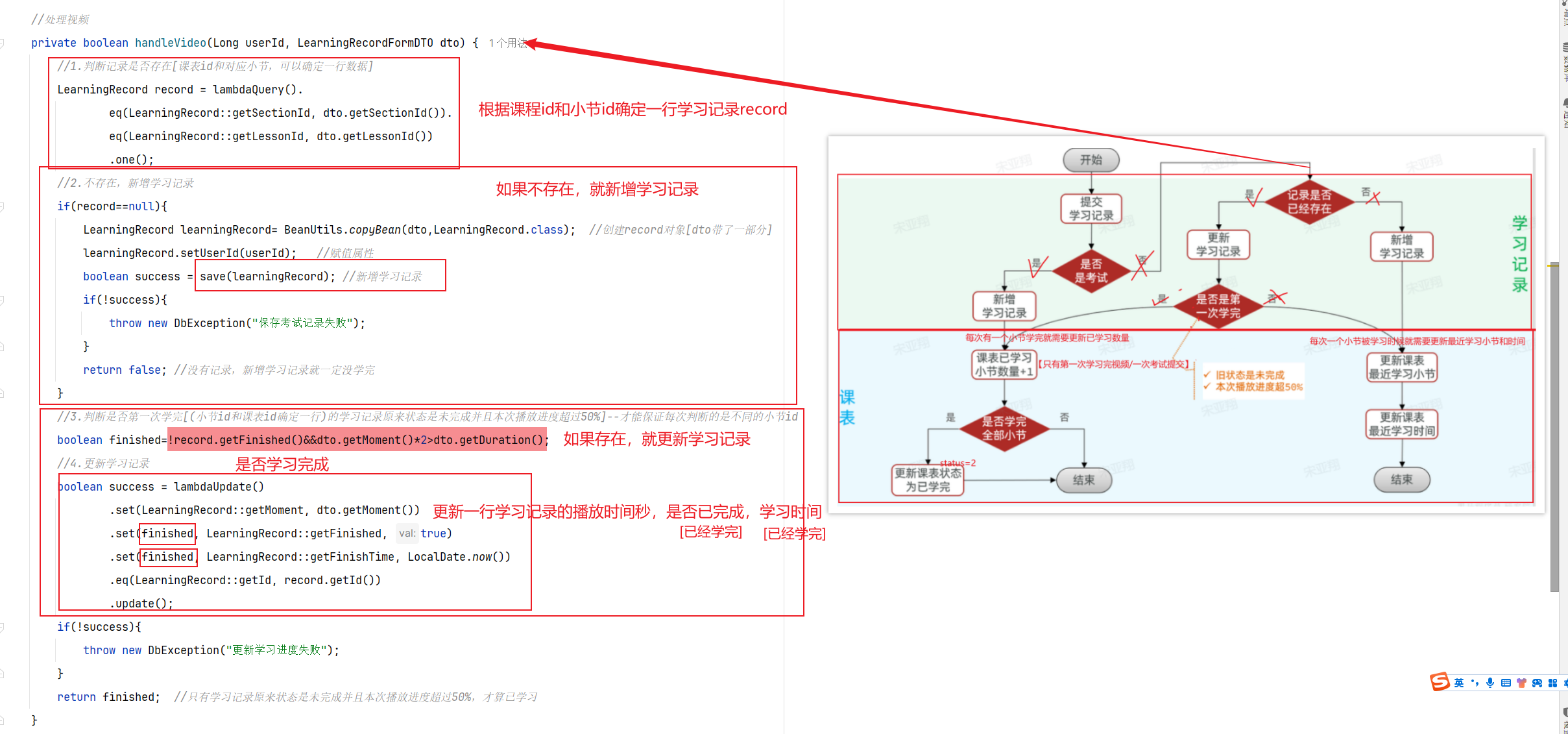
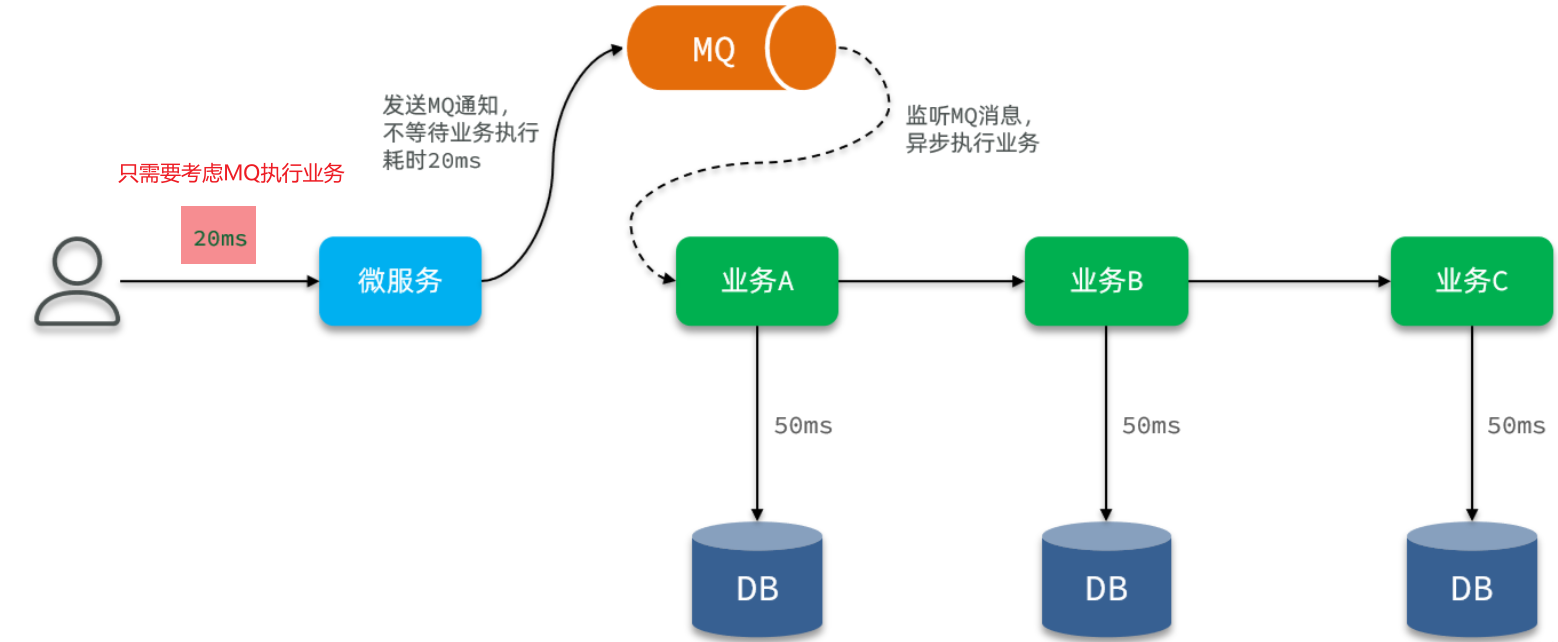
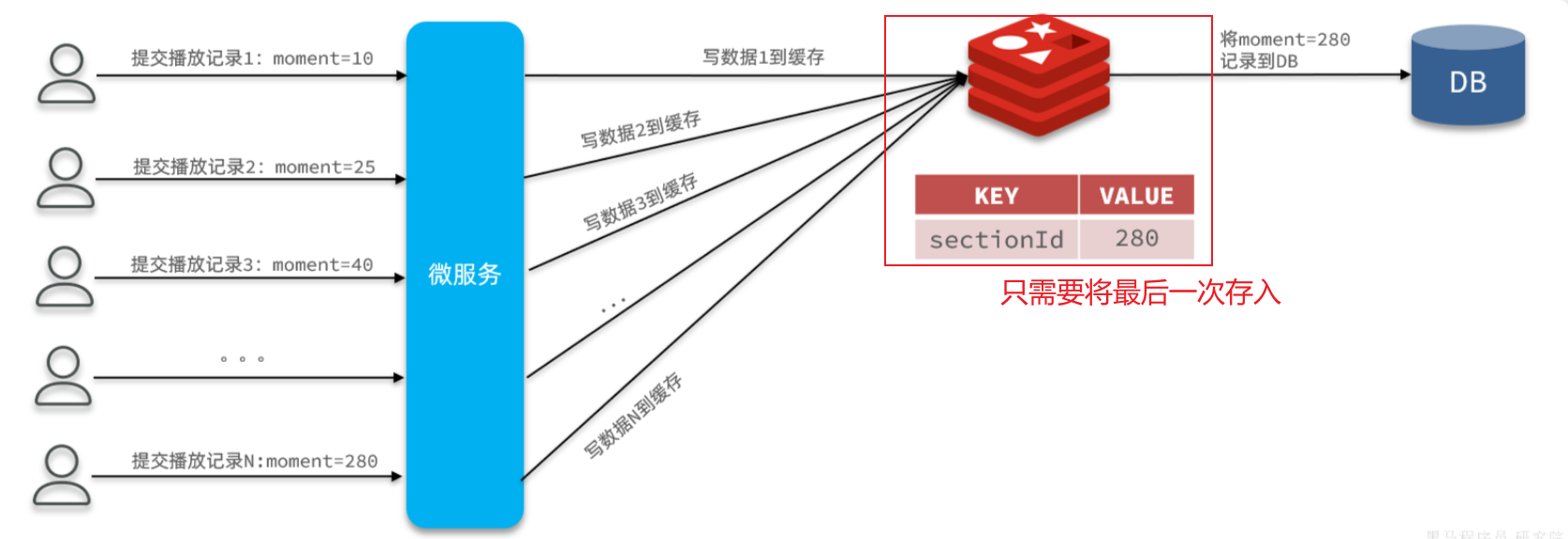
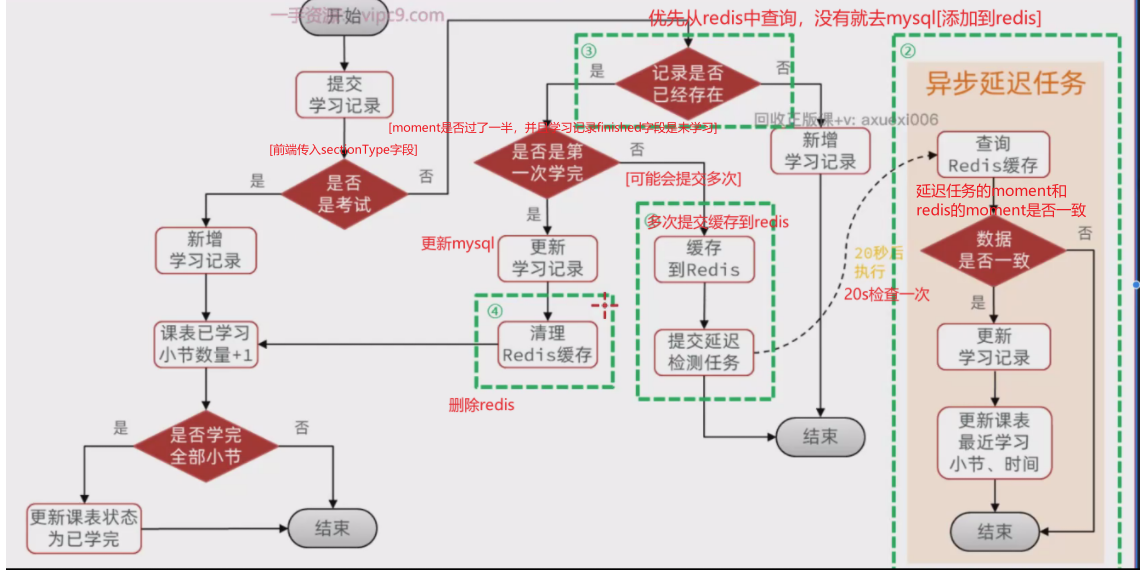
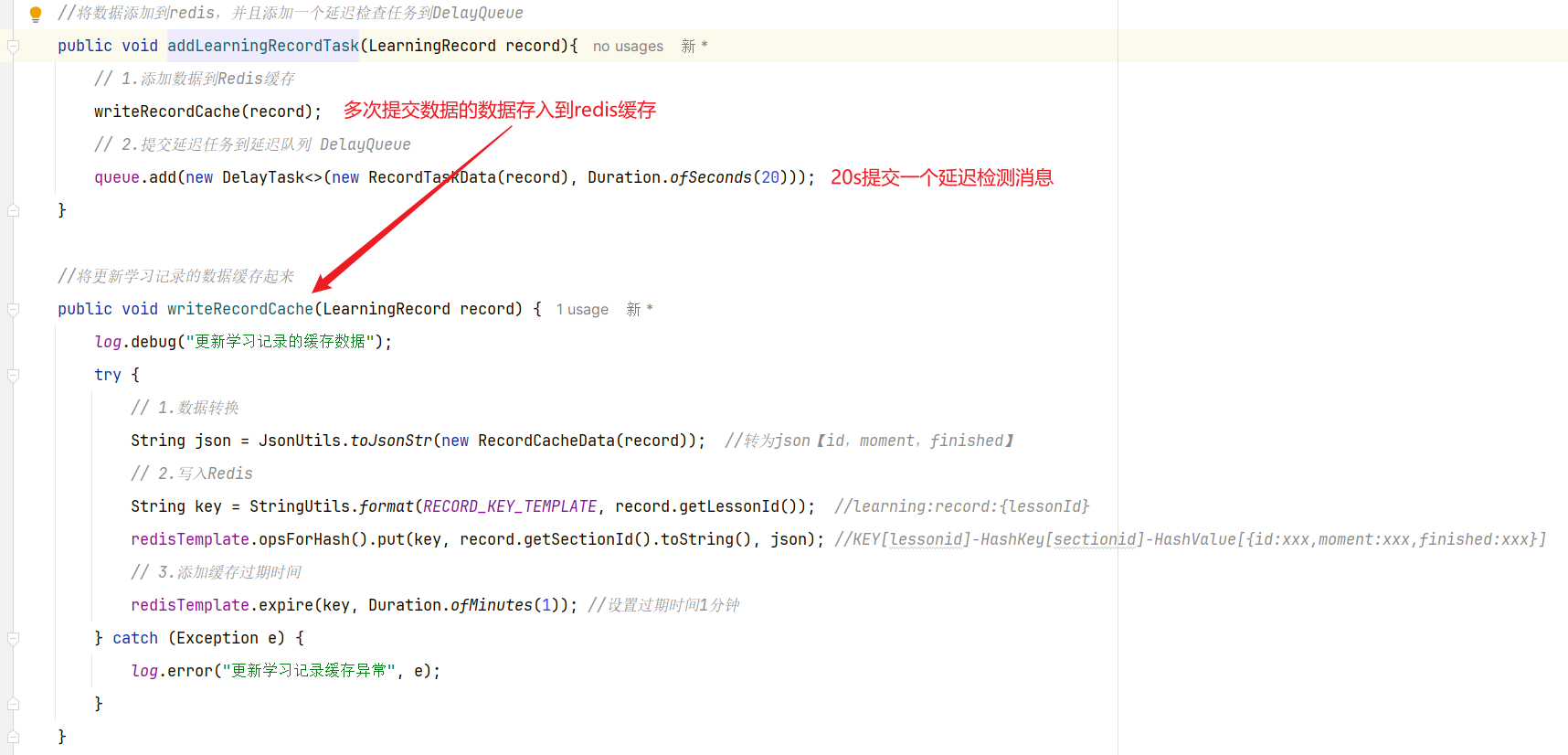
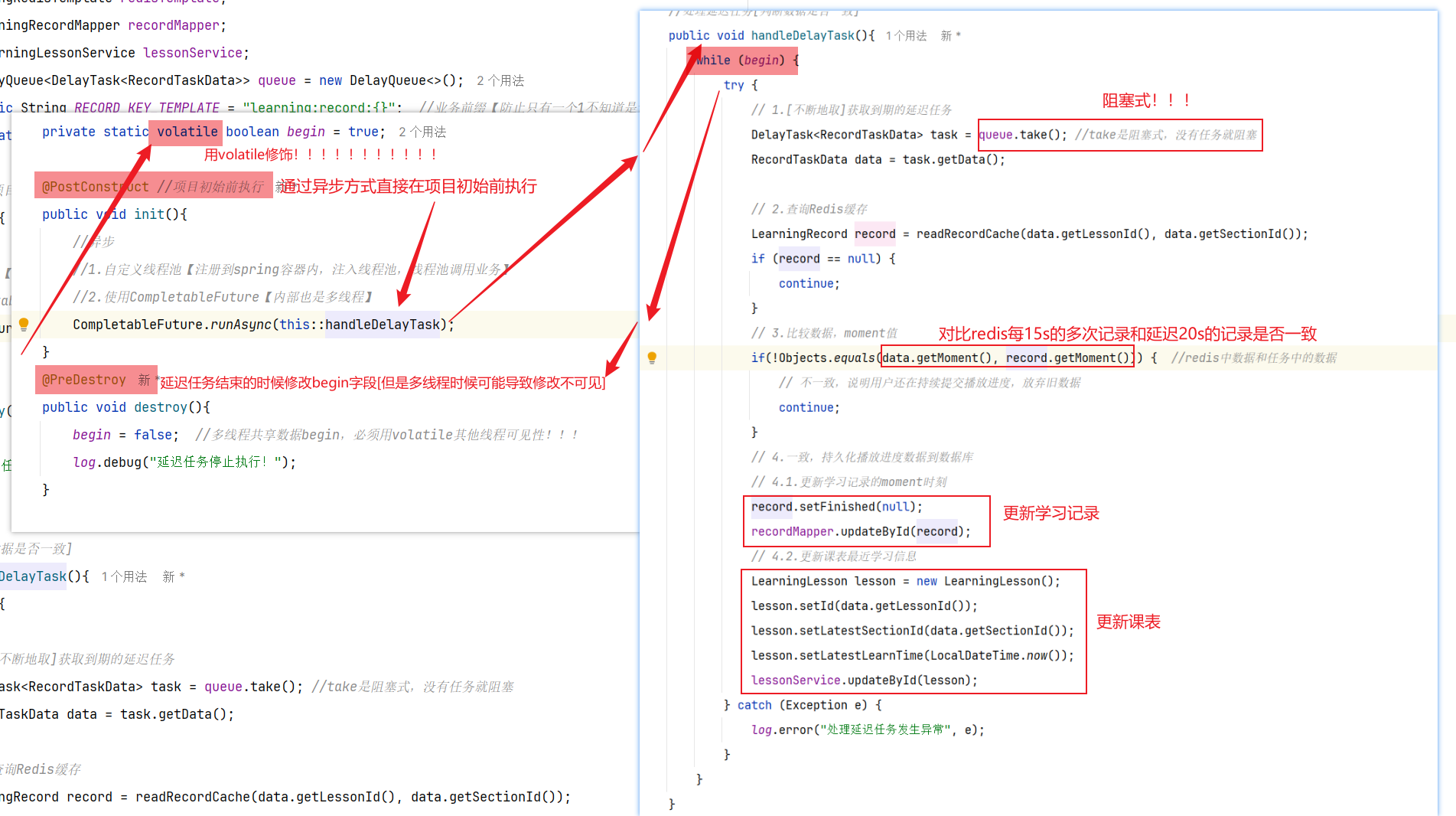
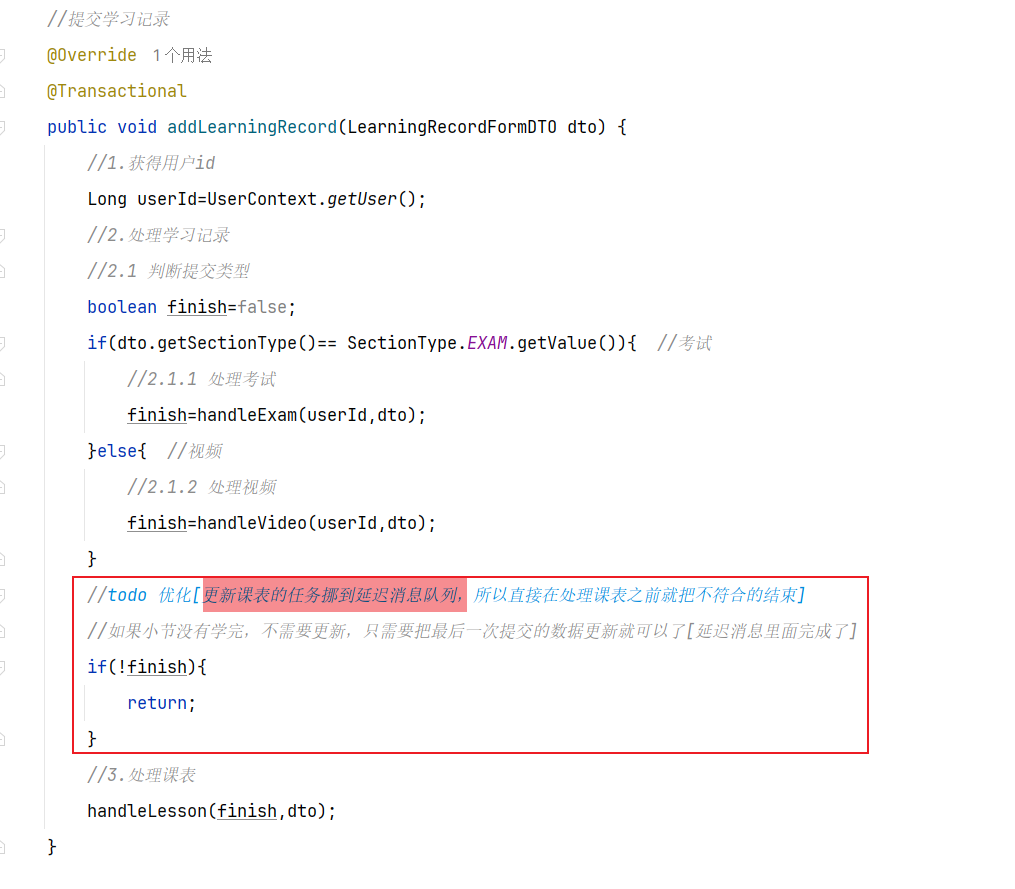
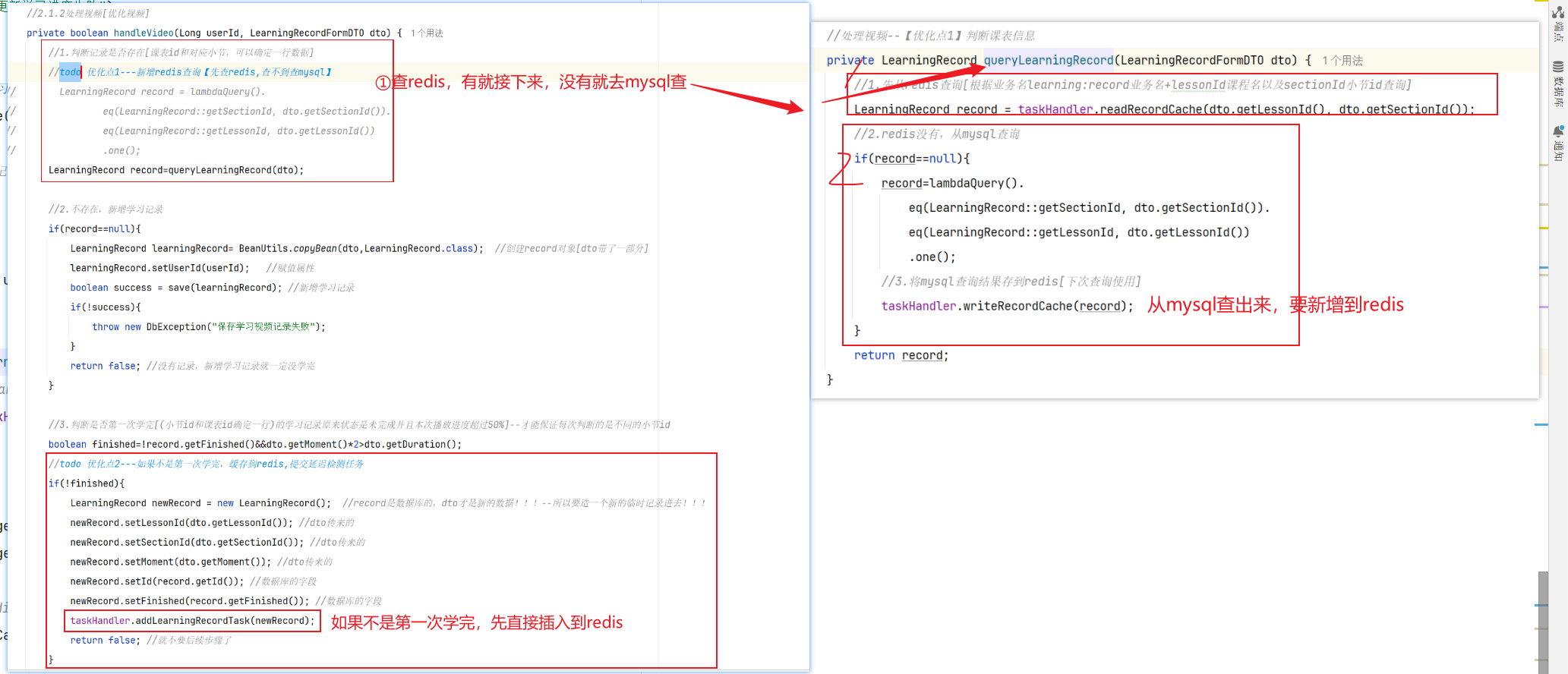
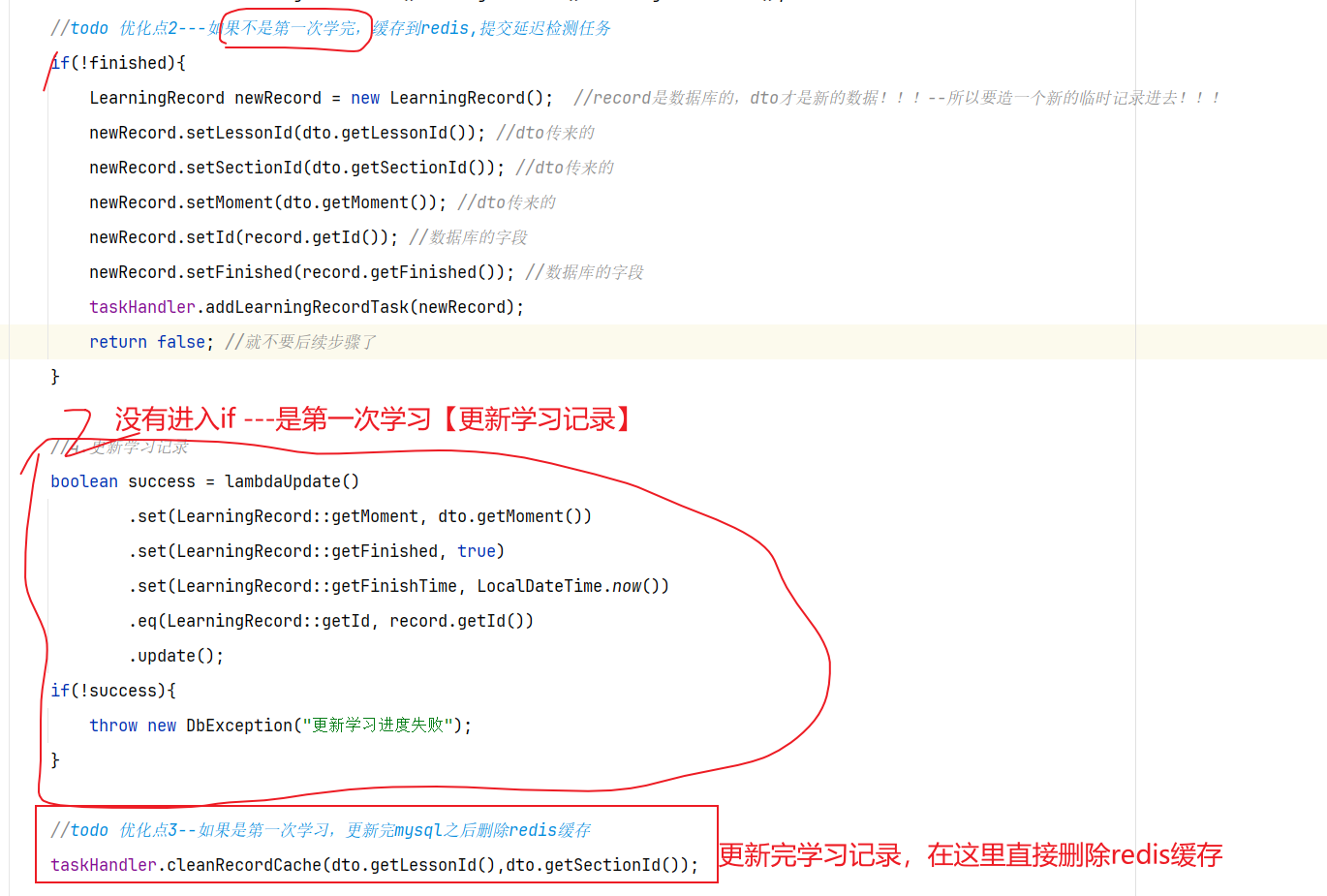
==——–具体实现——–== 1.保存积分[MQ消费者] 1.原型图 由积分规则可知,获取积分的行为多种多样,而且每一种行为都有自己的独立业务。而这些行为产生的时候需要保存一条积分明细到数据库。
我们显然不能要求其它业务的开发者在开发时帮我们新增一条积分记录,这样会导致原有业务与积分业务耦合。因此必须采用异步方式,将原有业务与积分业务解耦。如果有必要,甚至可以将积分业务抽离,作为独立微服务。
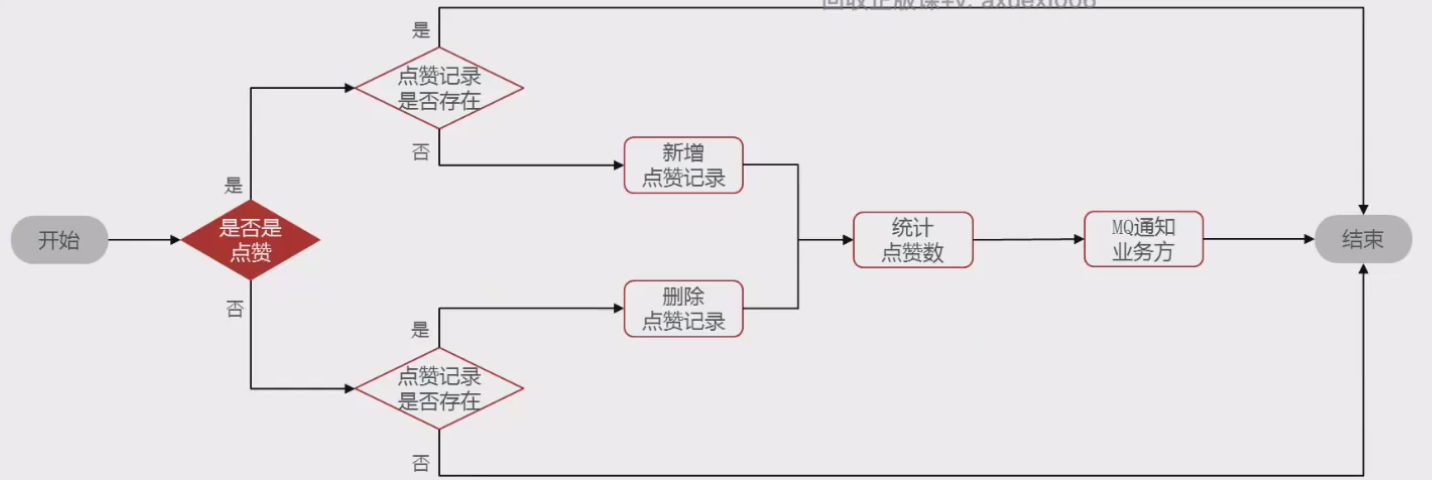
2.设计数据库 3.业务逻辑图
具体可以加分的业务发送MQ【用户id,获得的积分】
积分微服务通过MQ获取,具体业务处理
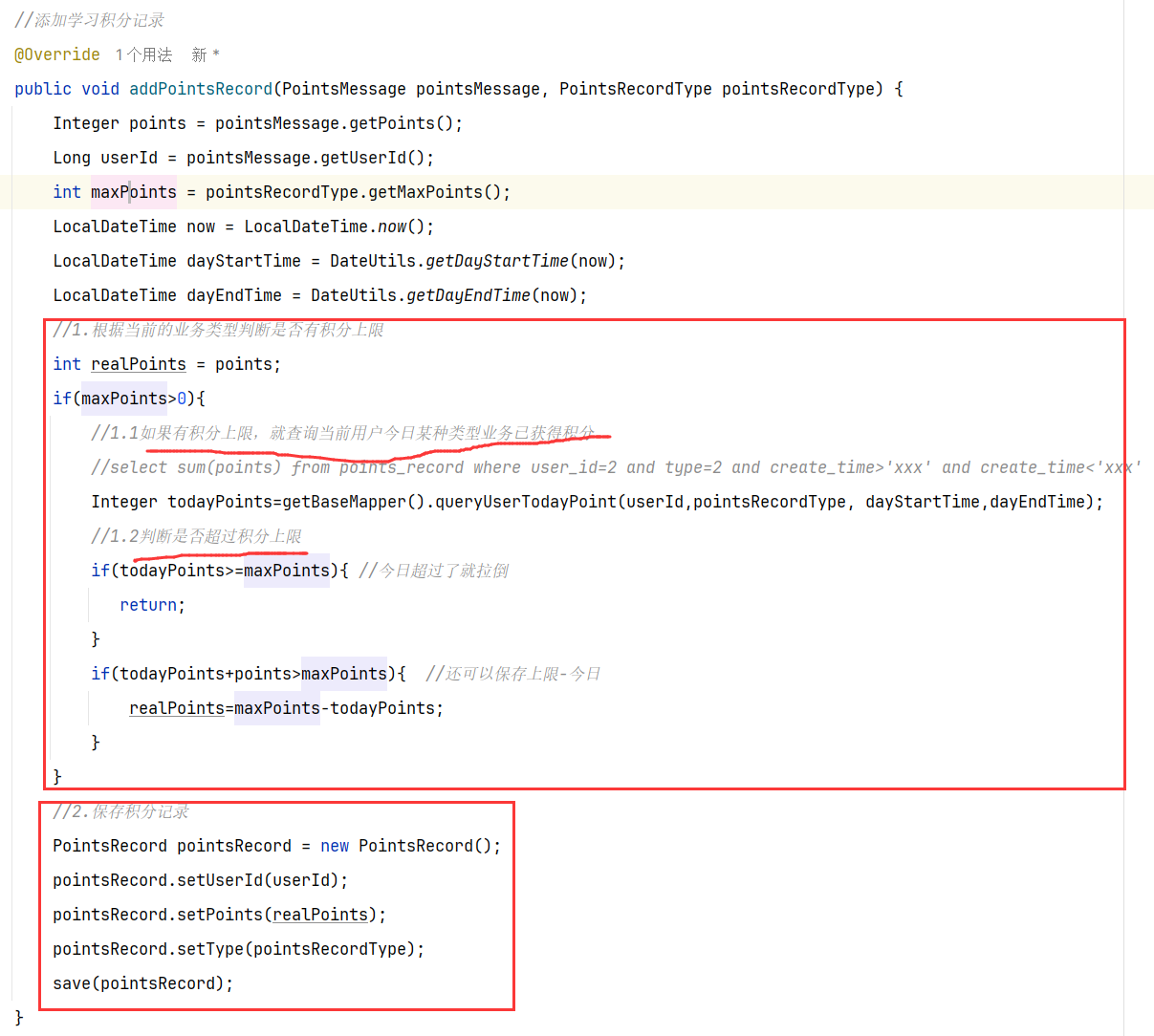
具体业务
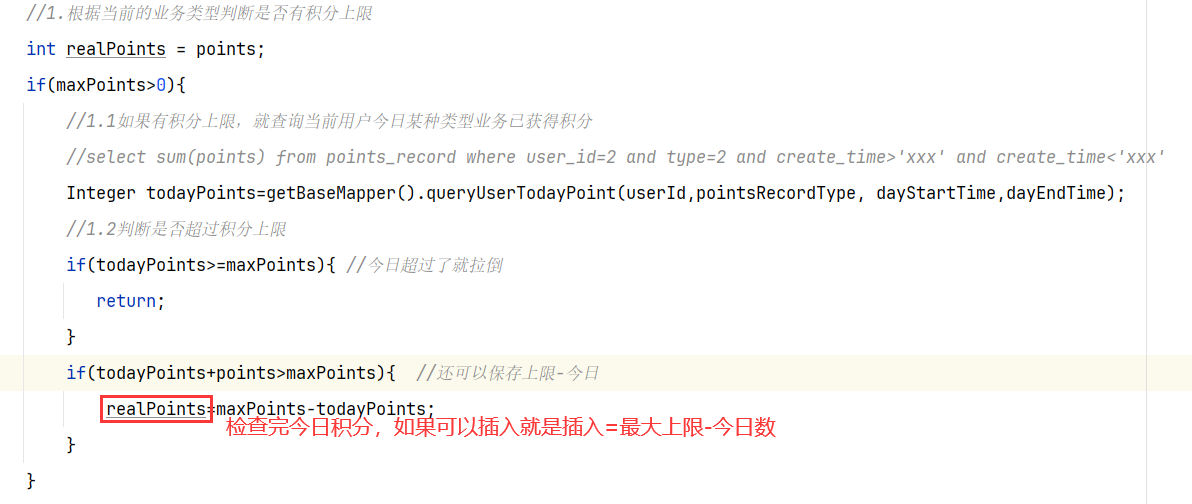
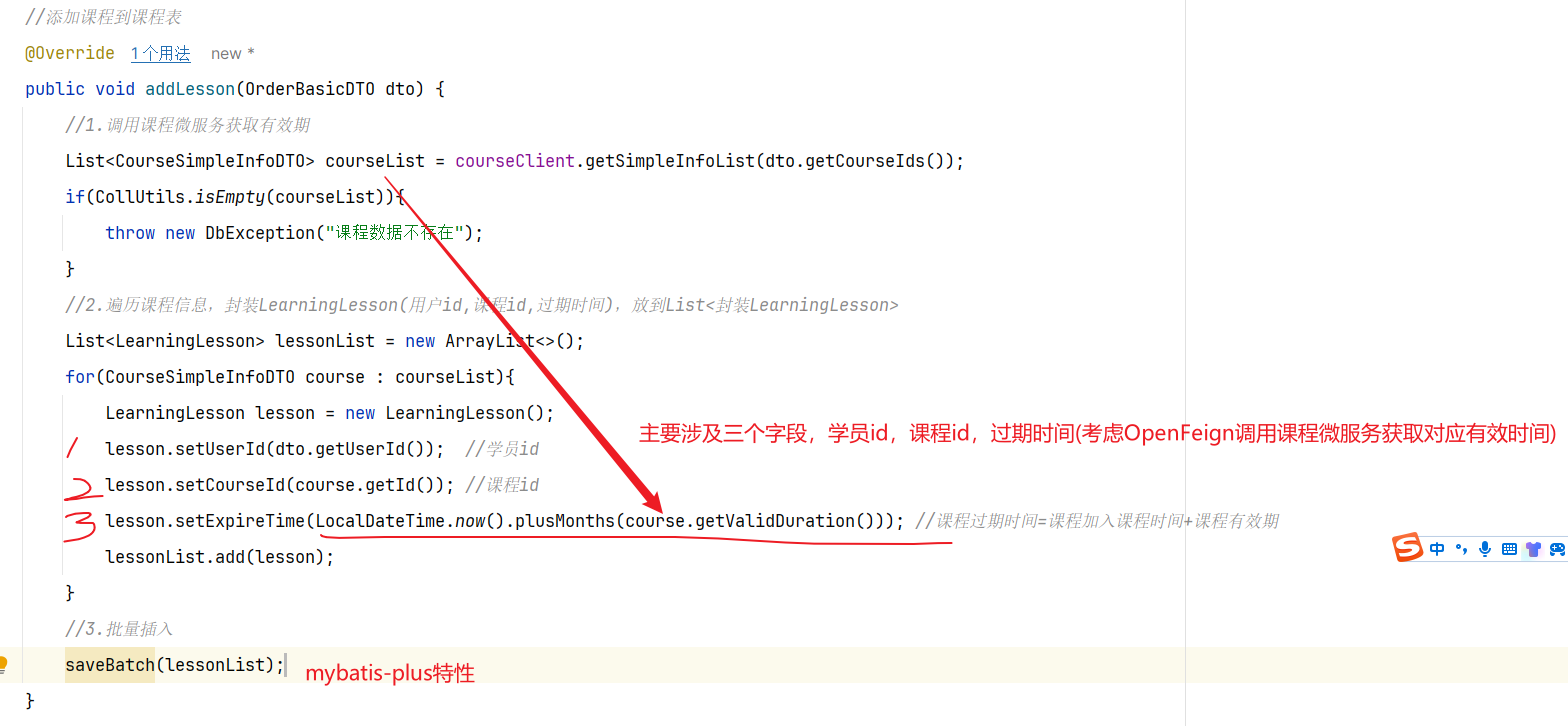
1.查看是哪个业务,是不是有积分上限
2.如果有积分上限,要看看今日获得积分情况:如果满了拉倒,如果没有计算出还可以加多少积分
3.加入积分
4.接口分析
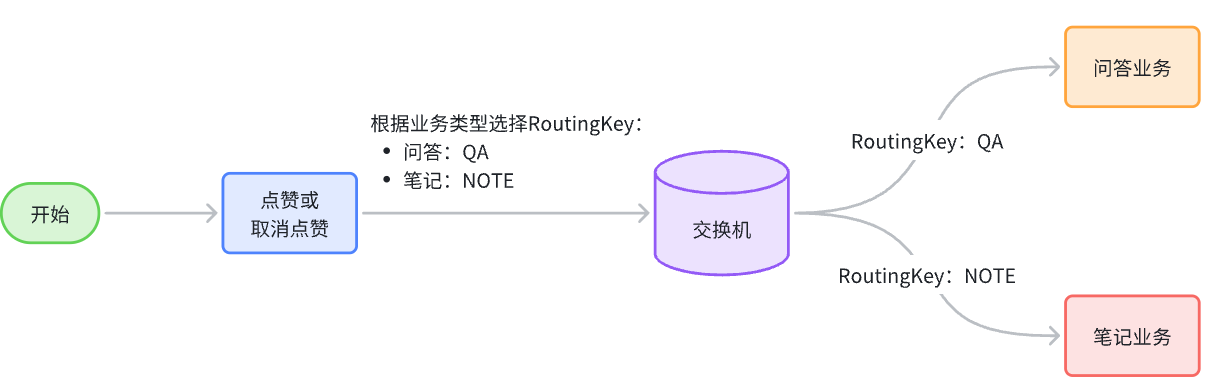
因此,我们需要为每一种积分行为定义一个不同的RoutingKey【用来分辨不同的业务,从而进行不同的业务处理】
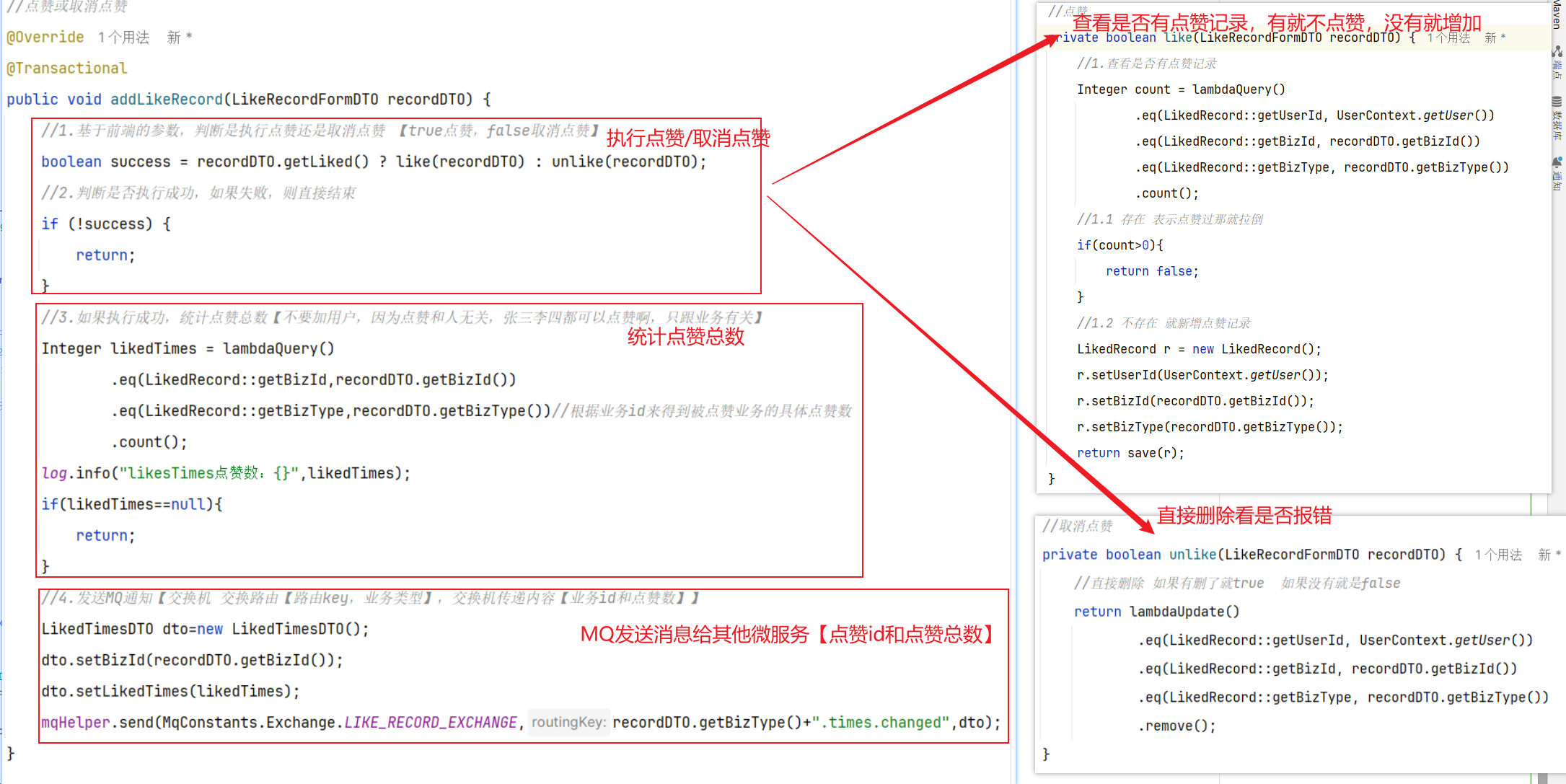
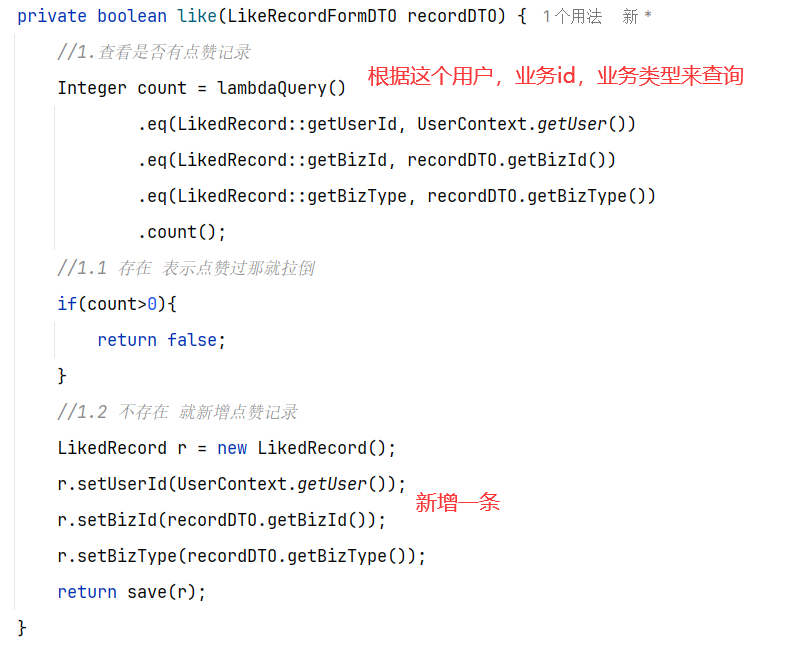
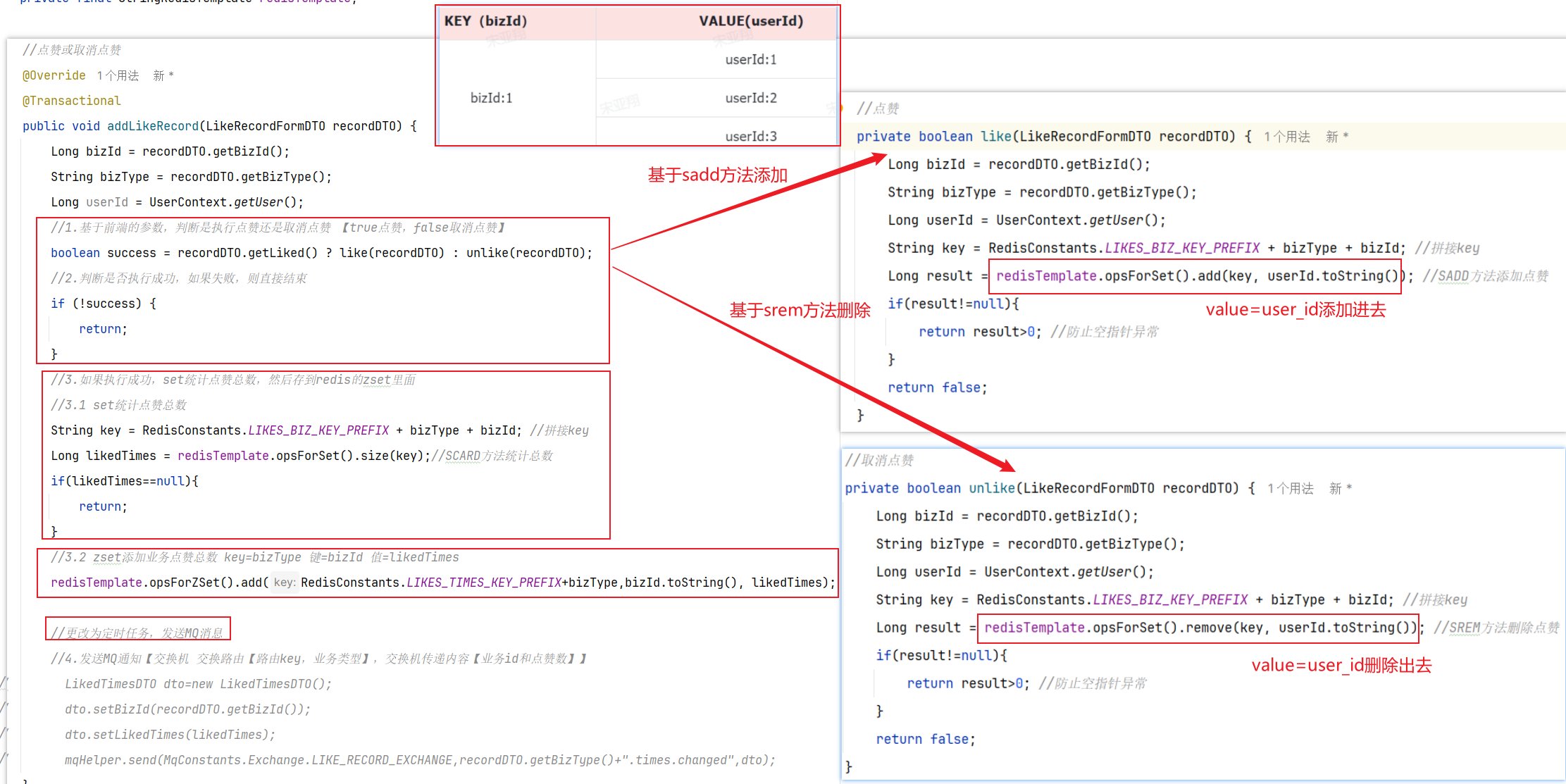
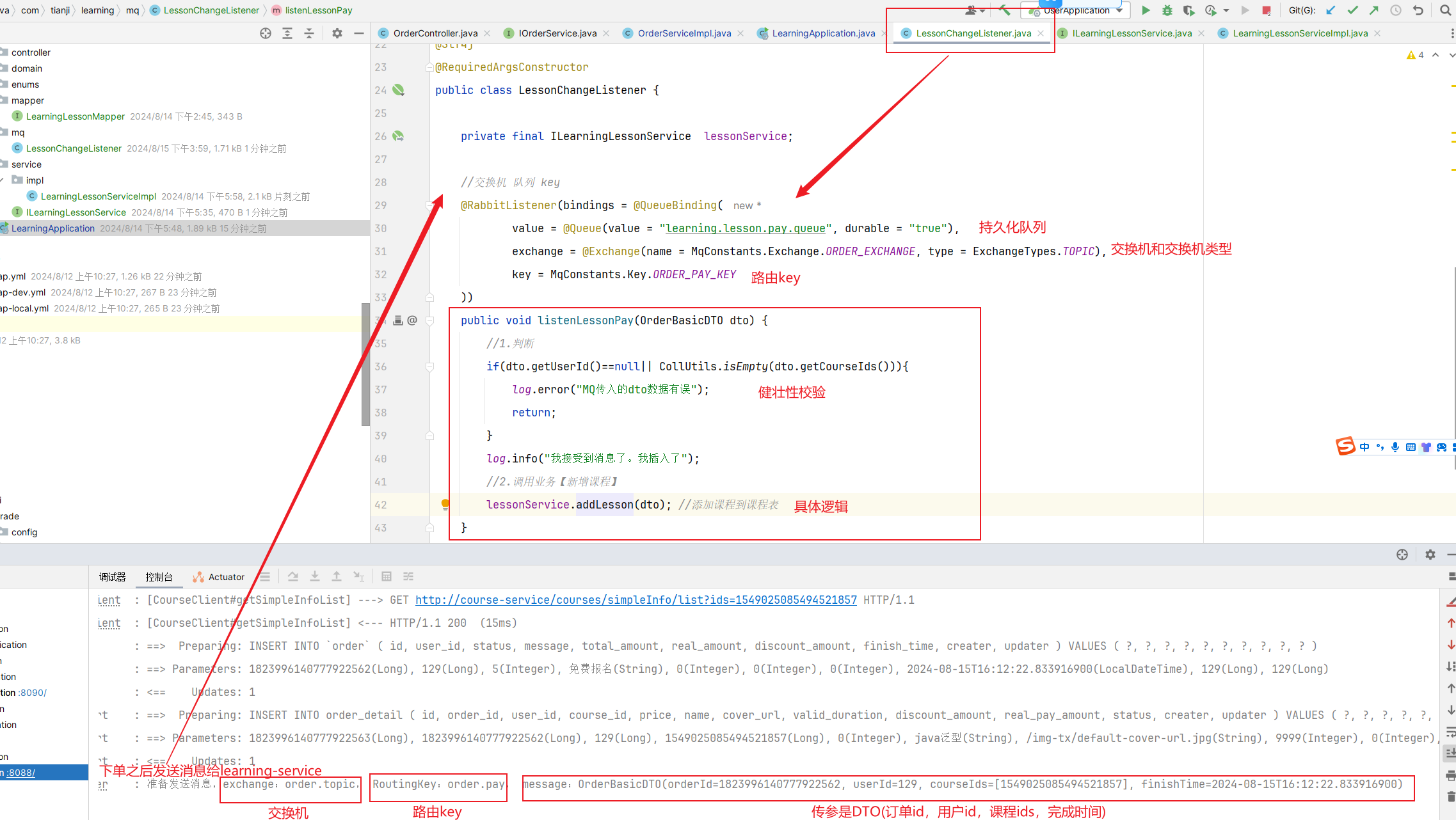
5.具体实现 5.1 MQ发送者[获得积分的微服务] ==获取到积分,发送MQ给积分微服务就行【加不加积分微服务自己负责】==
5.2 MQ消费者[获取积分然后判断是否满足条件加入] ==其他微服务学习获得积分(用户id,学习到的积分)—》积分微服务【内部判断是否上限,未上限的情况下加入到积分表】==
MQ接受消息
积分微服务处理业务
6.具体难点和亮点
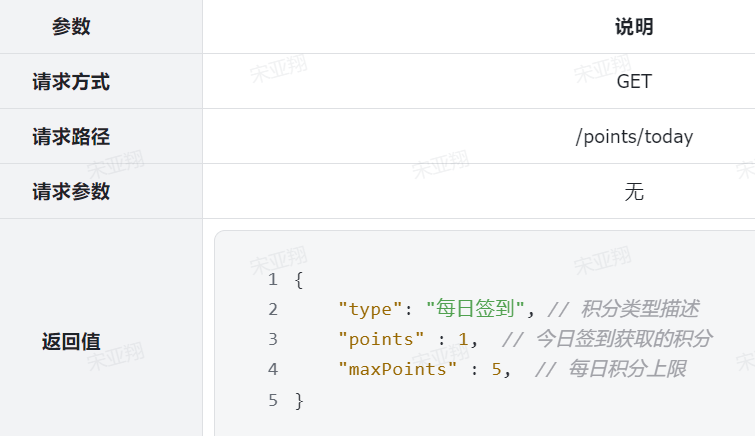
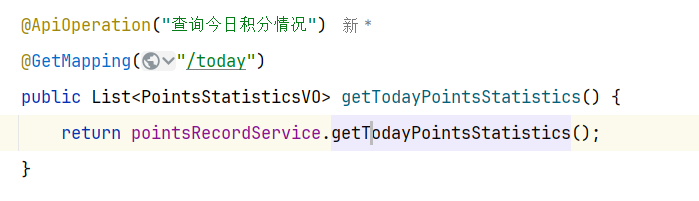
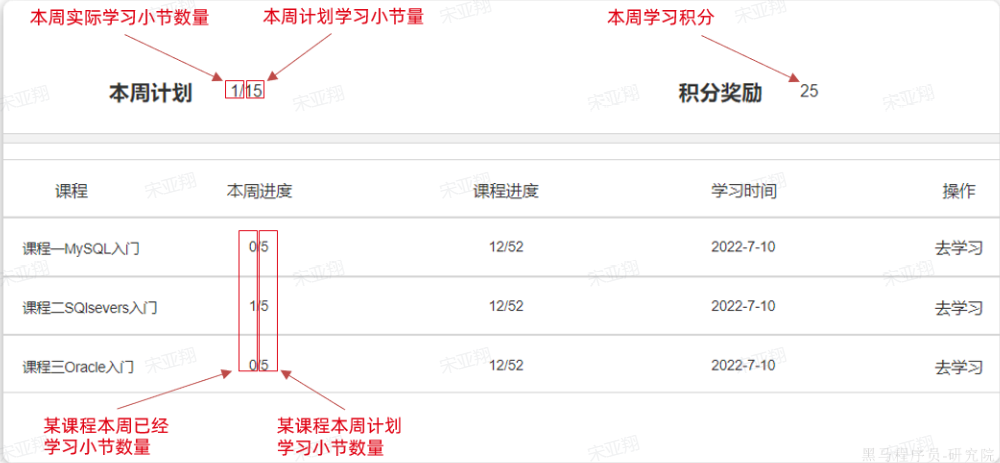
2.查询今日积分情况 1.原型图 在个人中心,用户可以查看当天各种不同类型的已获得的积分和积分上限:
可以看到,页面需要的数据:
而且积分类型不止一个,所以结果应该是集合。
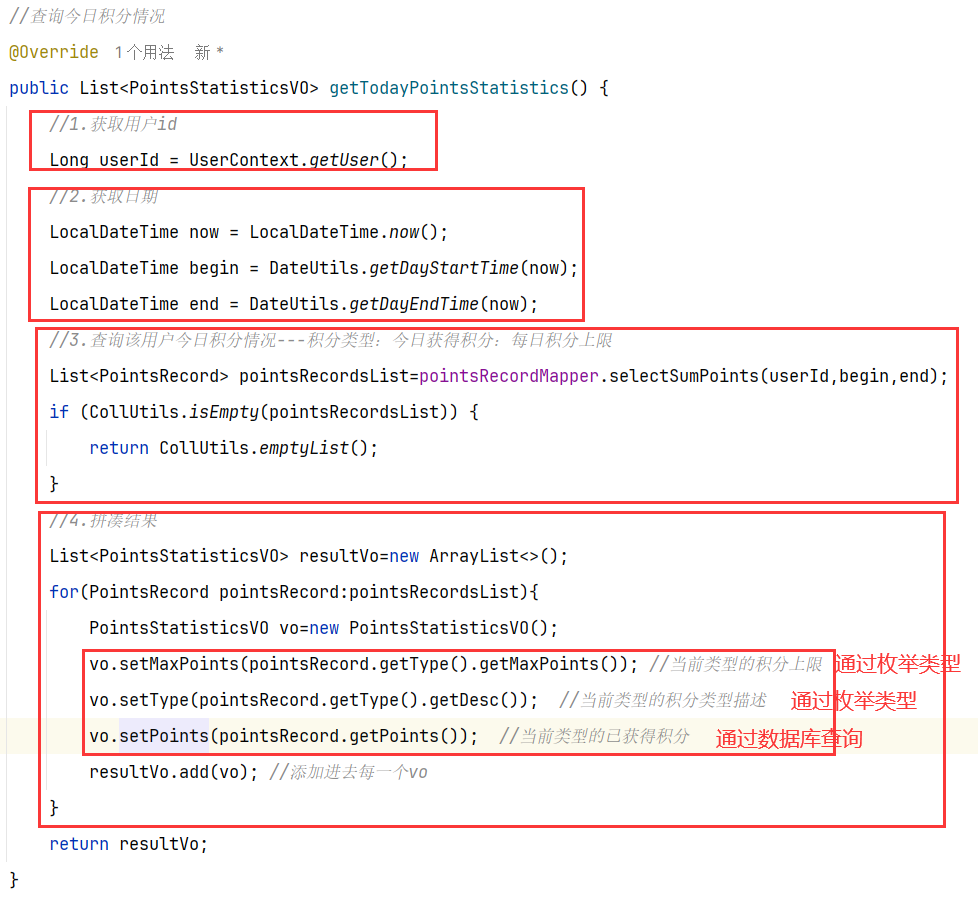
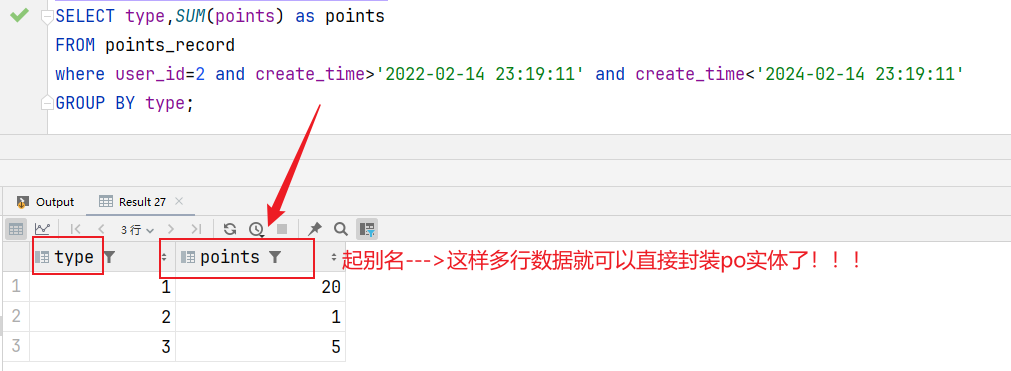
2.设计数据库 3.业务逻辑图 就是根据数据group by type分别取出类型和对应的sum(points)
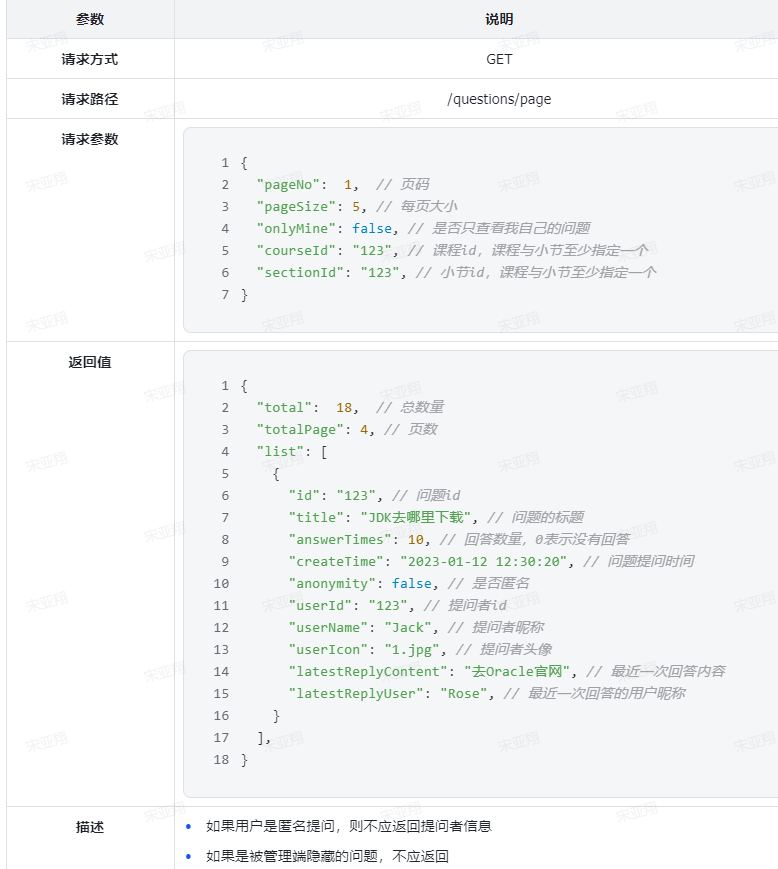
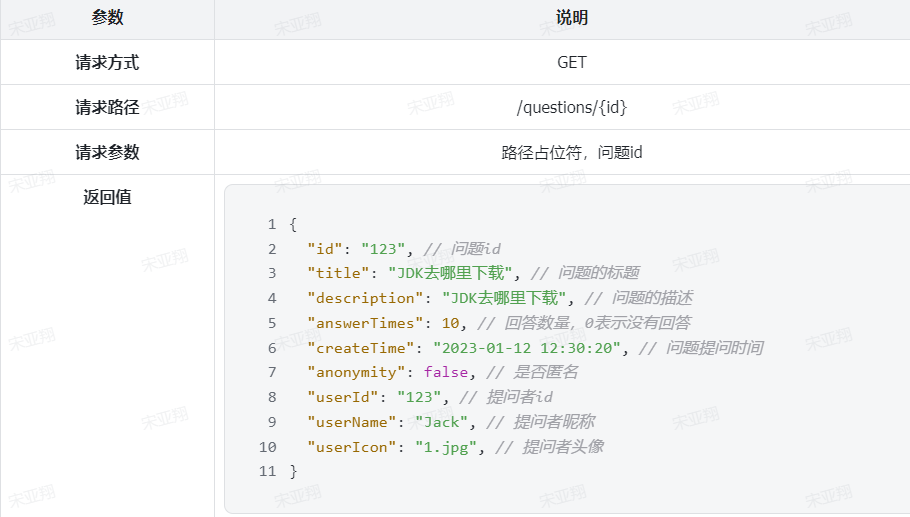
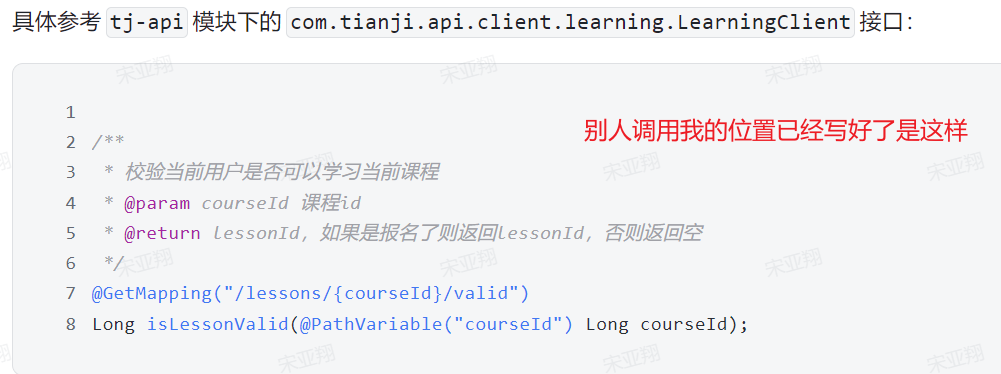
4.接口分析 另外,这个请求是查询当前用户的积分信息,所以只需要知道当前用户即可, 无需传参。
综上,接口信息如下:
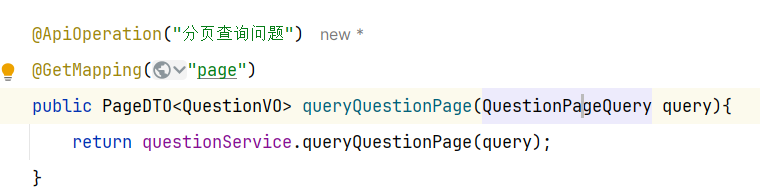
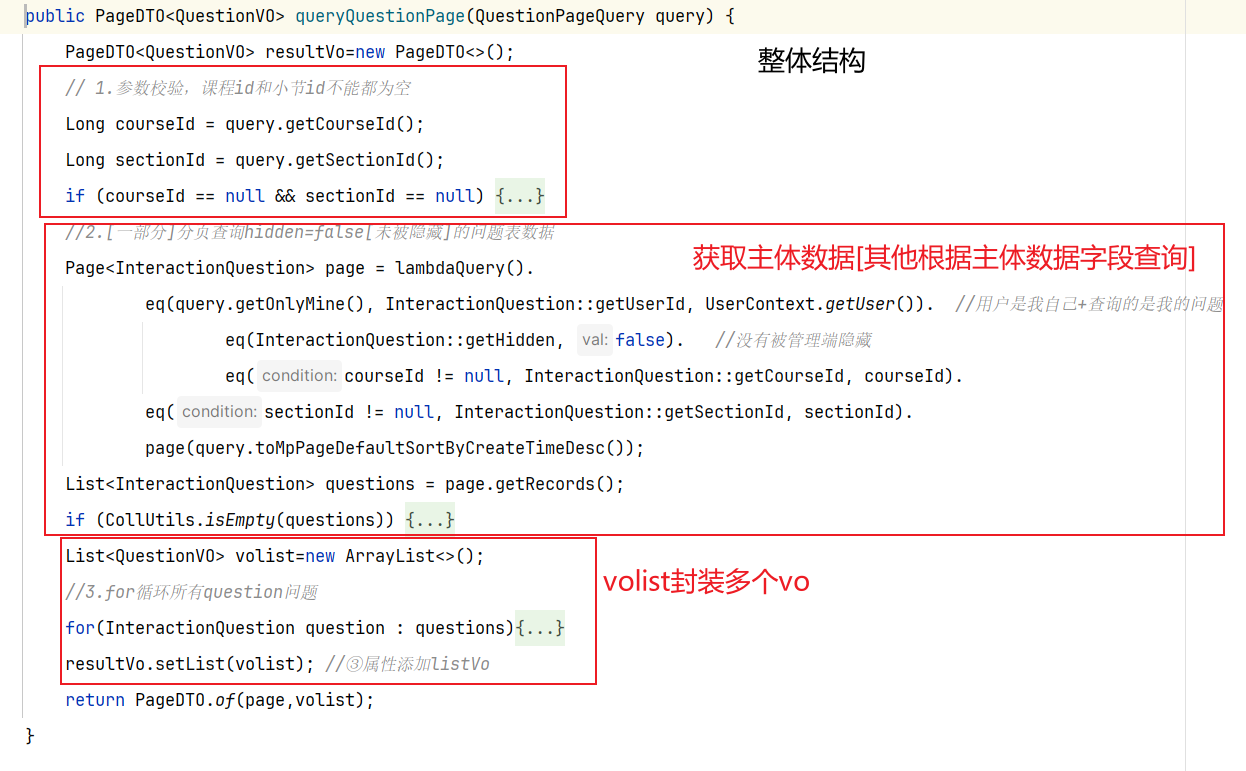
5.具体实现
6.具体难点和亮点
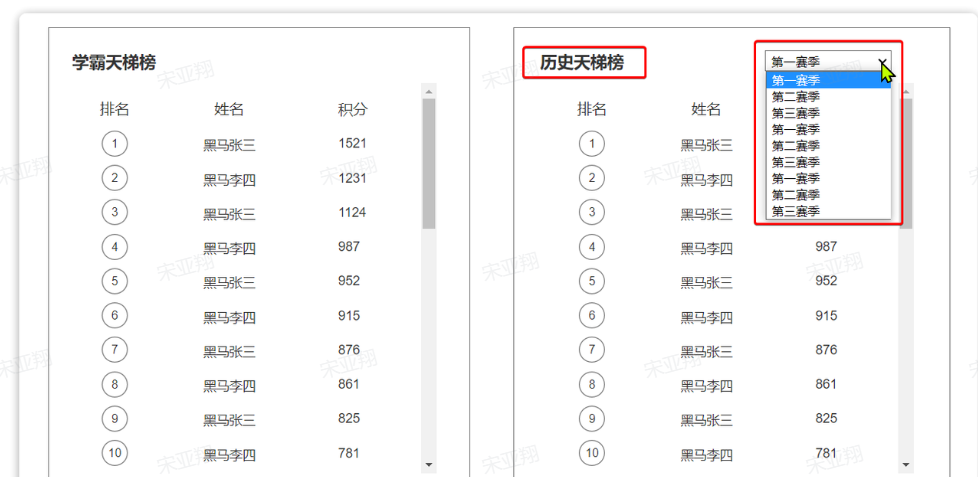
==——————————————== ==—————排行榜功能—————== 准备阶段—分析业务流程 顶部展示的当前用户在榜单中的信息,其实也属于排行榜信息的一部分。因为排行榜查出来了,当前用户是第几名,积了多少分也就知道了。
当我们点击更多时,会进入历史榜单页面:
准备阶段—字段分析 排行榜是分赛季的,而且页面也需要查询到历史赛季的列表。因此赛季也是一个实体,用来记录每一个赛季的信息。当然赛季信息非常简单:
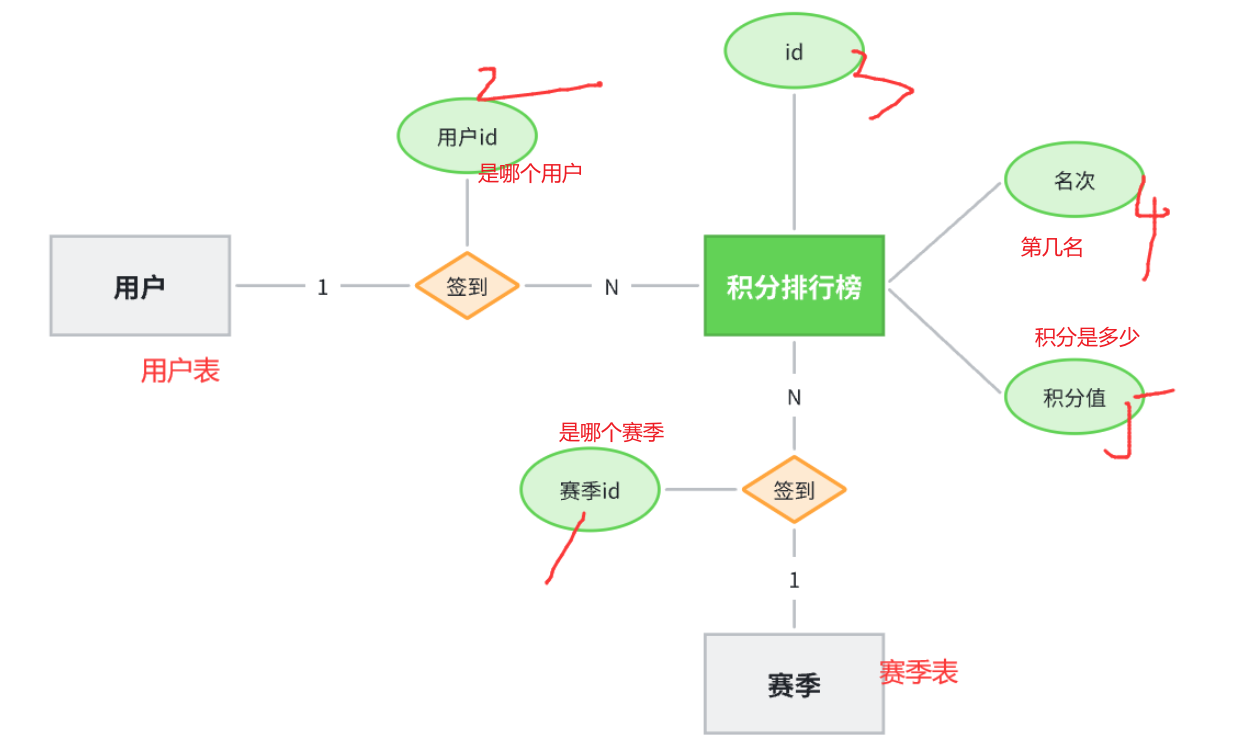
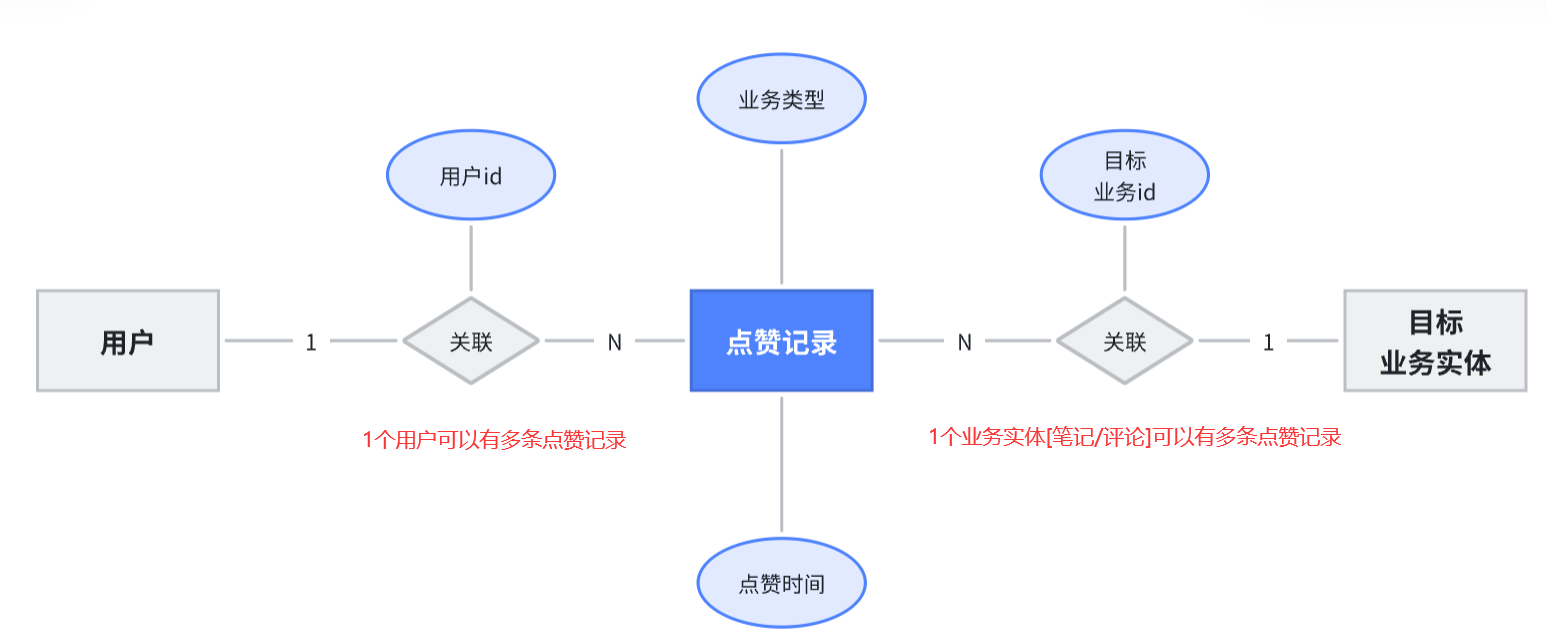
排行榜也不复杂,核心要素包括:
当然,由于要区分赛季,还应该关联赛季信息:
准备阶段—ER图
准备阶段—表结构
1 2 3 4 5 6 7 CREATE TABLE IF NOT EXISTS `points_board_season` ( `id` int NOT NULL AUTO_INCREMENT COMMENT '自增长id,season标示', `name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '赛季名称,例如:第1赛季', `begin_time` date NOT NULL COMMENT '赛季开始时间', `end_time` date NOT NULL COMMENT '赛季结束时间', PRIMARY KEY (`id`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC;
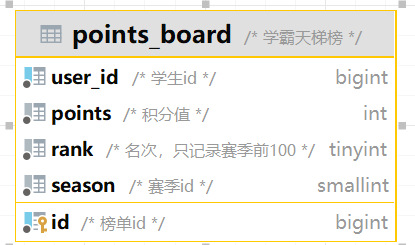
1 2 3 4 5 6 7 8 9 CREATE TABLE IF NOT EXISTS `points_board` ( `id` bigint NOT NULL COMMENT '榜单id', `user_id` bigint NOT NULL COMMENT '学生id', `points` int NOT NULL COMMENT '积分值', `rank` tinyint NOT NULL COMMENT '名次,只记录赛季前100', `season` smallint NOT NULL COMMENT '赛季,例如 1,就是第一赛季,2-就是第二赛季', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `idx_season_user` (`season`,`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC COMMENT='学霸天梯榜';
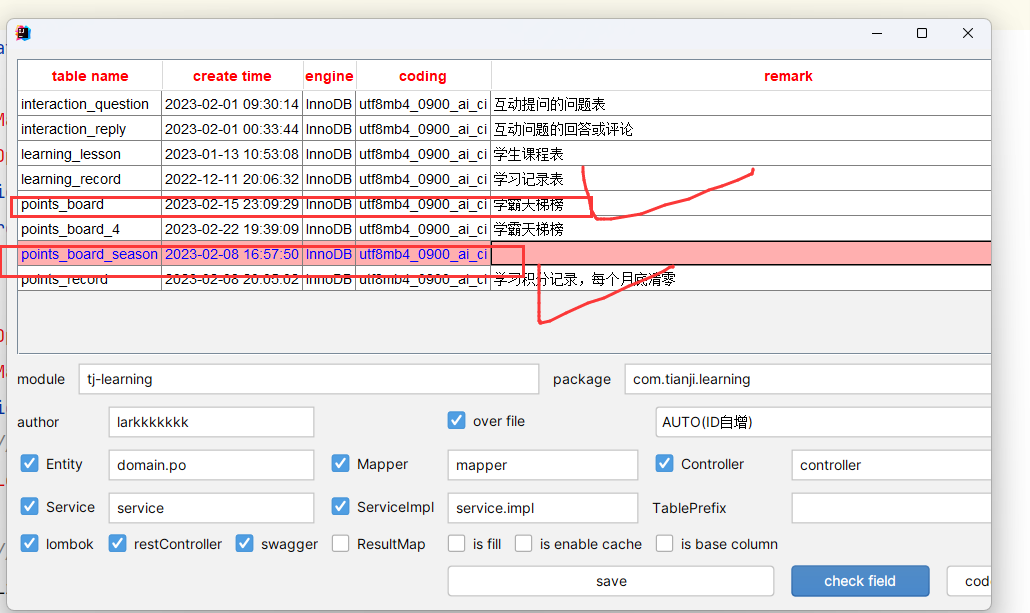
准备阶段—Mybatis-Plus代码生成 准备阶段–类型枚举 准备阶段–接口统计
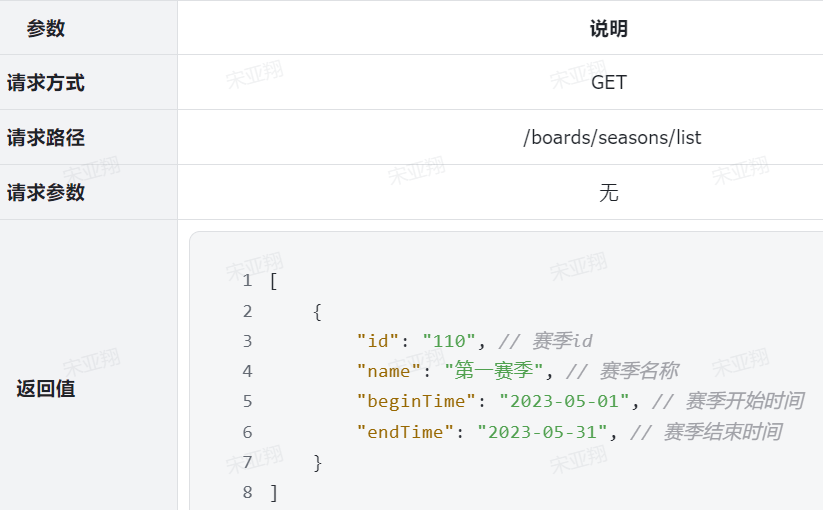
1.查询赛季列表功能 1.原型图 在历史赛季榜单中,有一个下拉选框,可以选择历史赛季信息:
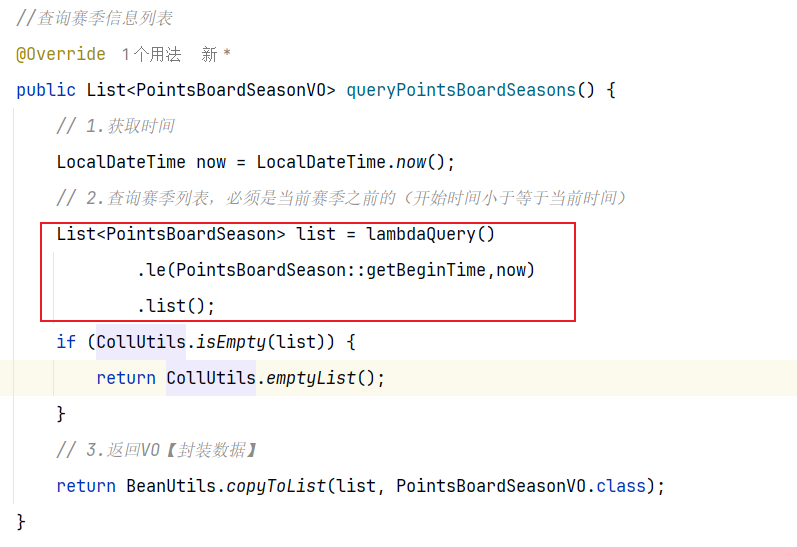
2.设计数据库 3.业务逻辑图 其实就是获取赛季表的信息【多条信息】
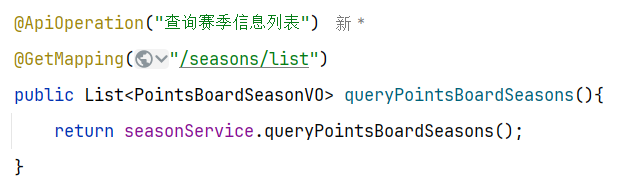
4.接口分析 因此,我们需要实现一个接口,把历史赛季全部查询出来
5.具体实现
无
6.具体难点和亮点
查询赛季列表—>必须是当前赛季【开始时间小于等于当前时间】
==实时数据[Zset数据类型]== 0.业务分析
Mysql:要不停计算,不停添加数据【很繁琐】
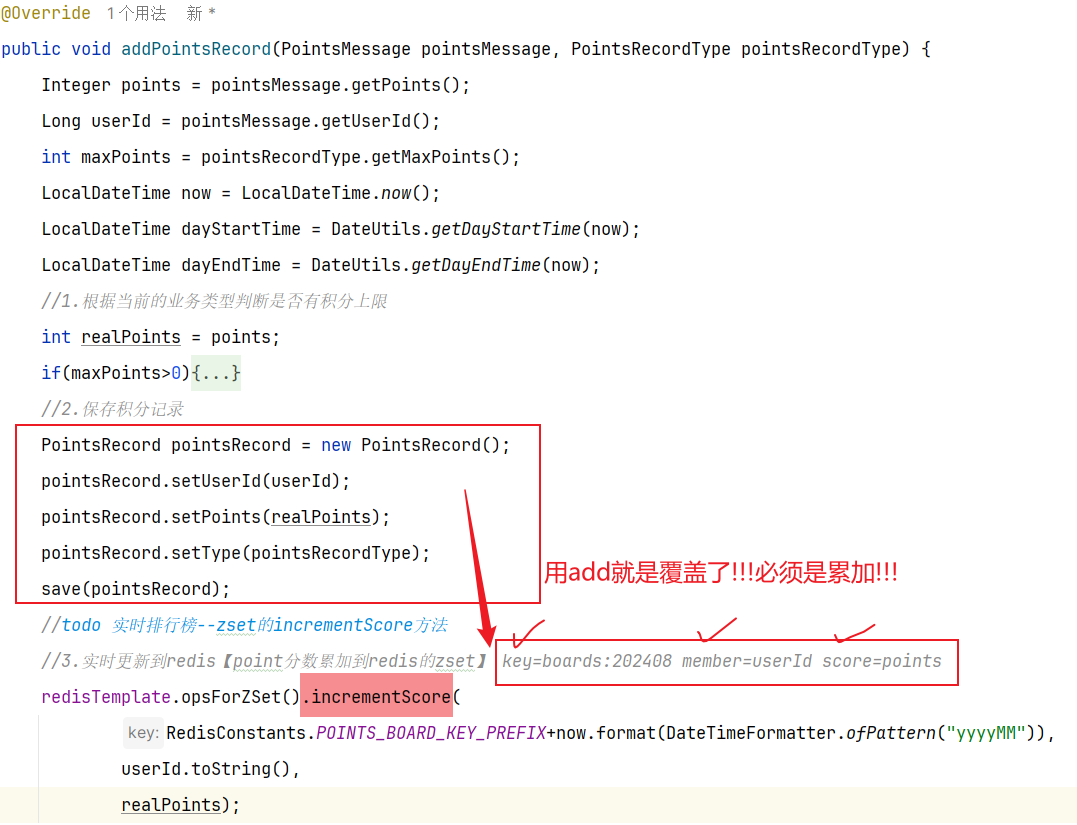
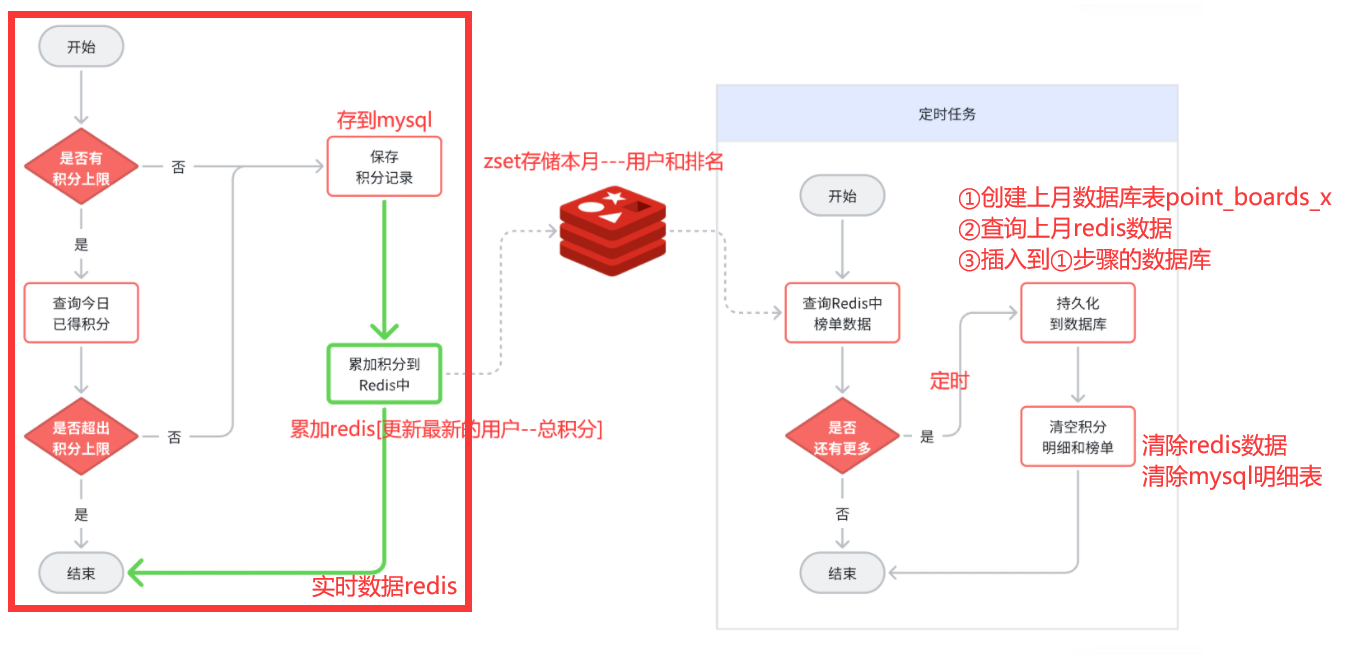
Redis:既然考虑积分排名,就是用redis的Zset数据结构【key=赛季日期,member=用户id,score=积分和】—如果有用户新增积分,那就累加 到对应score上,zset就可以实时更新
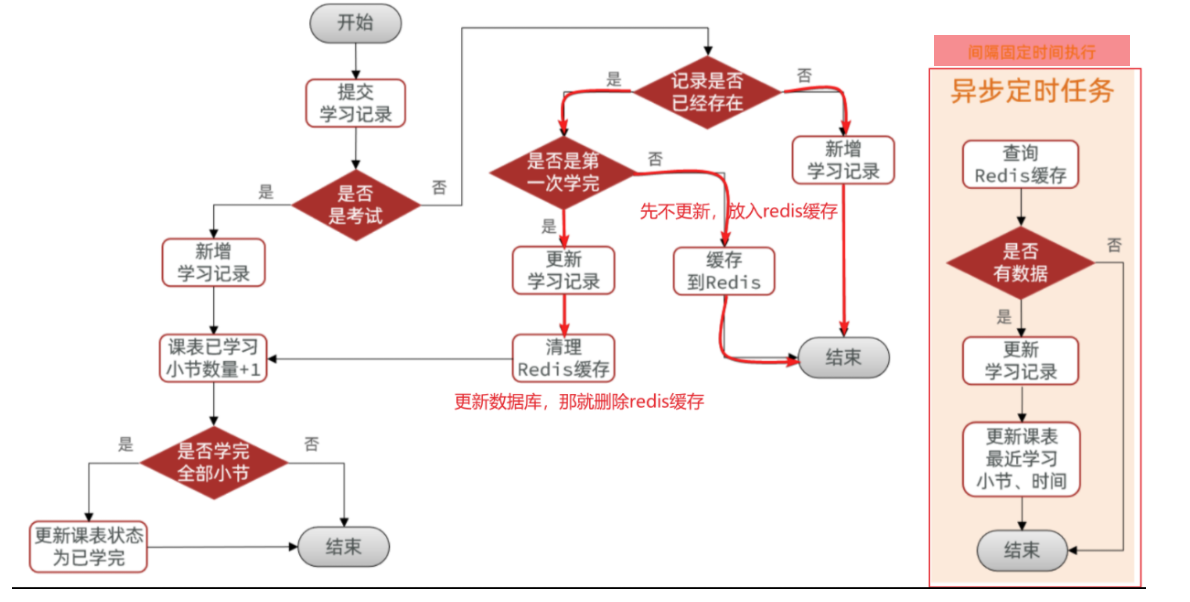
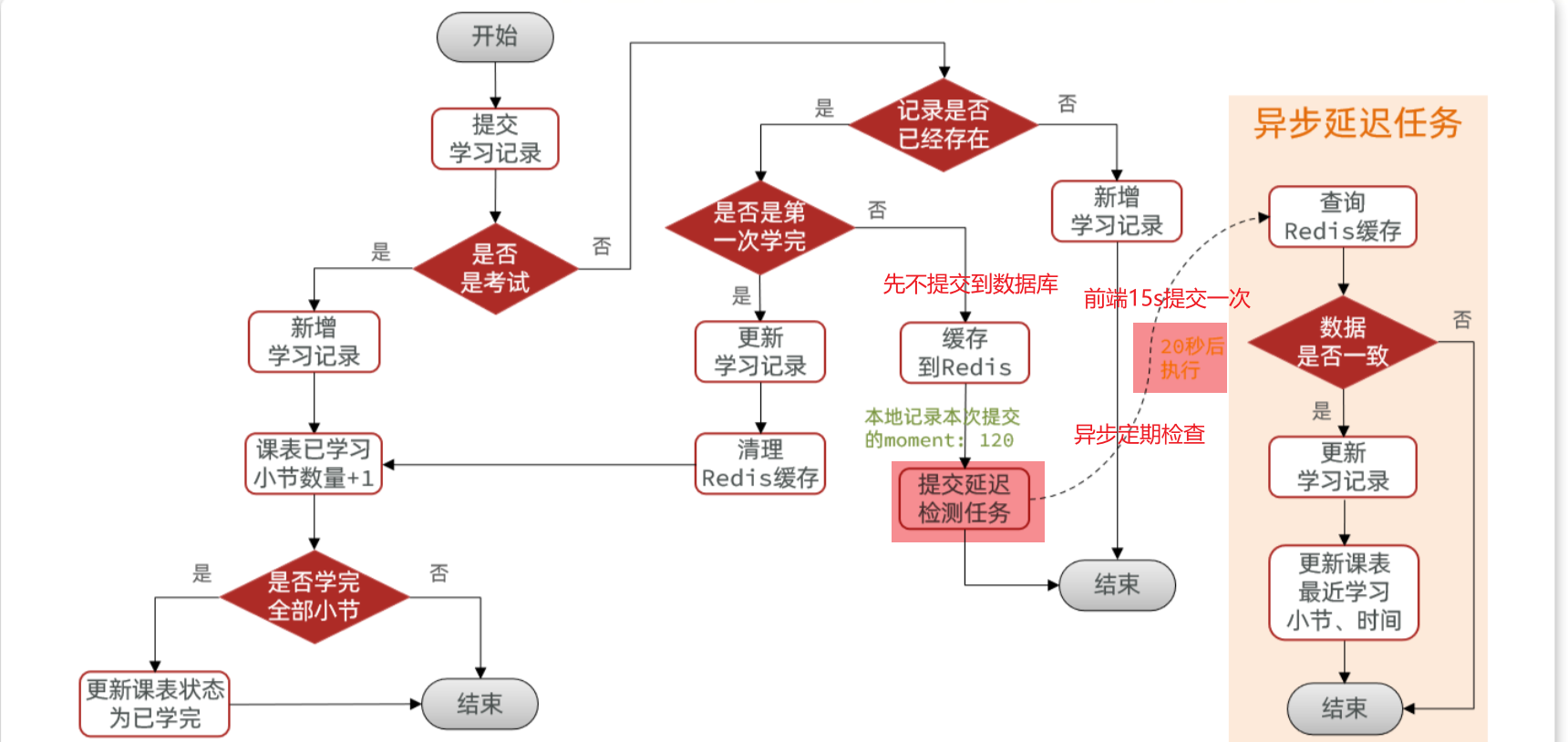
既然要使用Redis的SortedSet来实现排行榜,就需要在用户每次积分变更时,累加积分到Redis的SortedSet中 。因此,我们要对之前的新增积分功能做简单改造,如图中绿色部分:
在Redis中,使用SortedSet结构,以赛季的日期为key,以用户id为member,以积分和为score. 每当用户新增积分,就累加到score中 ,SortedSet排名就会实时更新。这样一个实时的当前赛季榜单就出现了
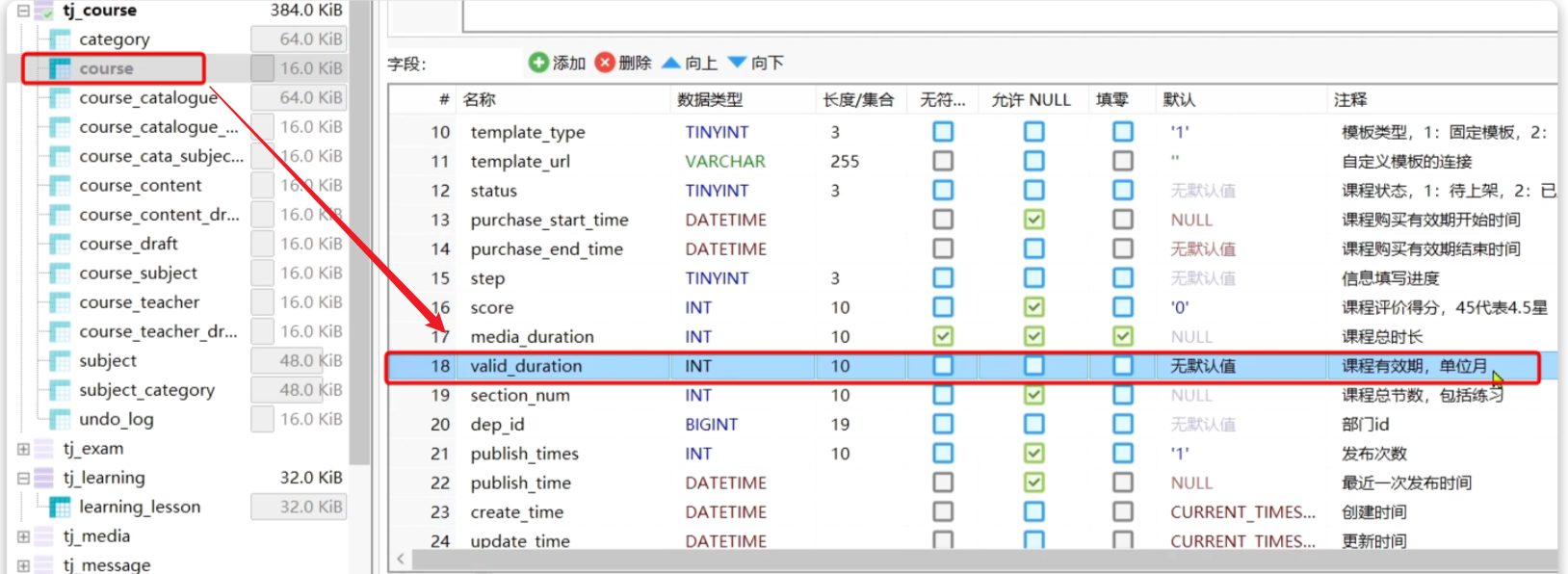
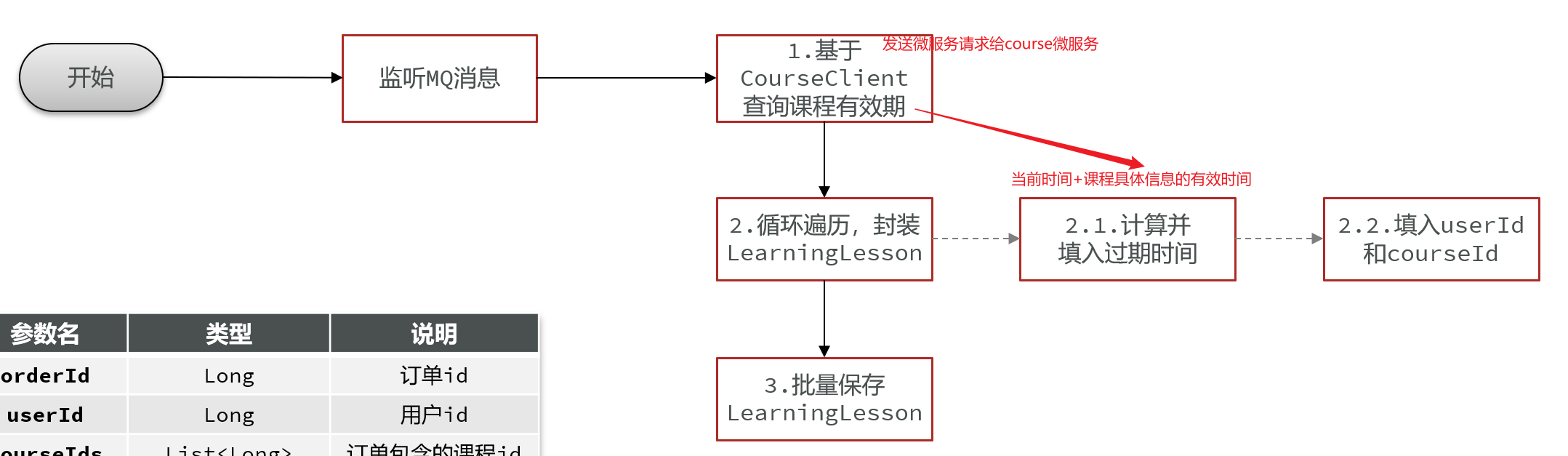
==——–具体实现——–== 1.生成本赛季榜单(实时数据) 1.原型图 2.设计数据库 3.业务逻辑图 4.接口分析 一旦积分微服务获取到积分,然后将积分新增到积分明细表之后,我就可以发送积分【累加】到redis!!!!
5.具体实现
6.具体难点和亮点
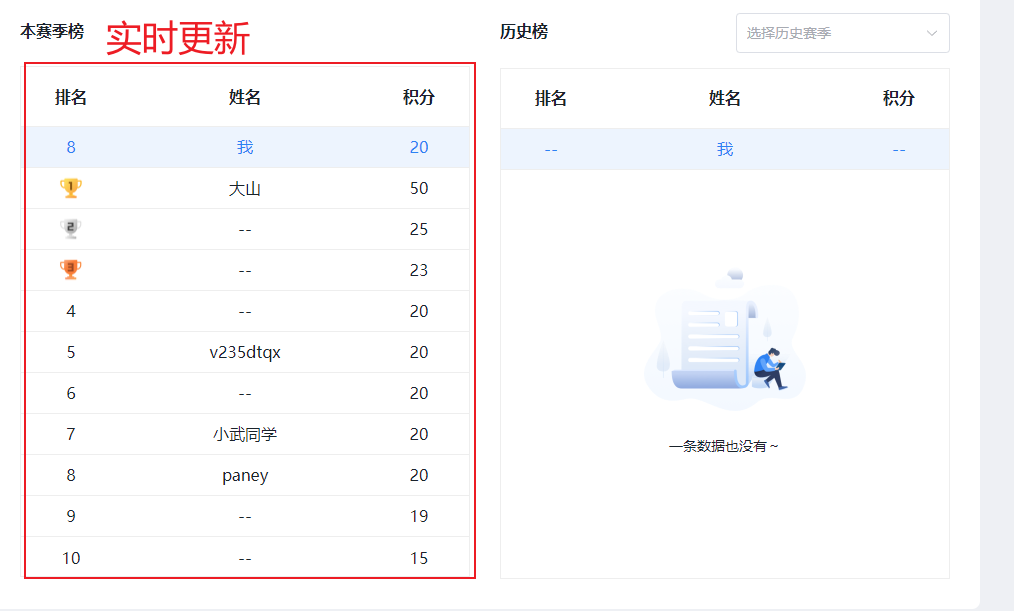
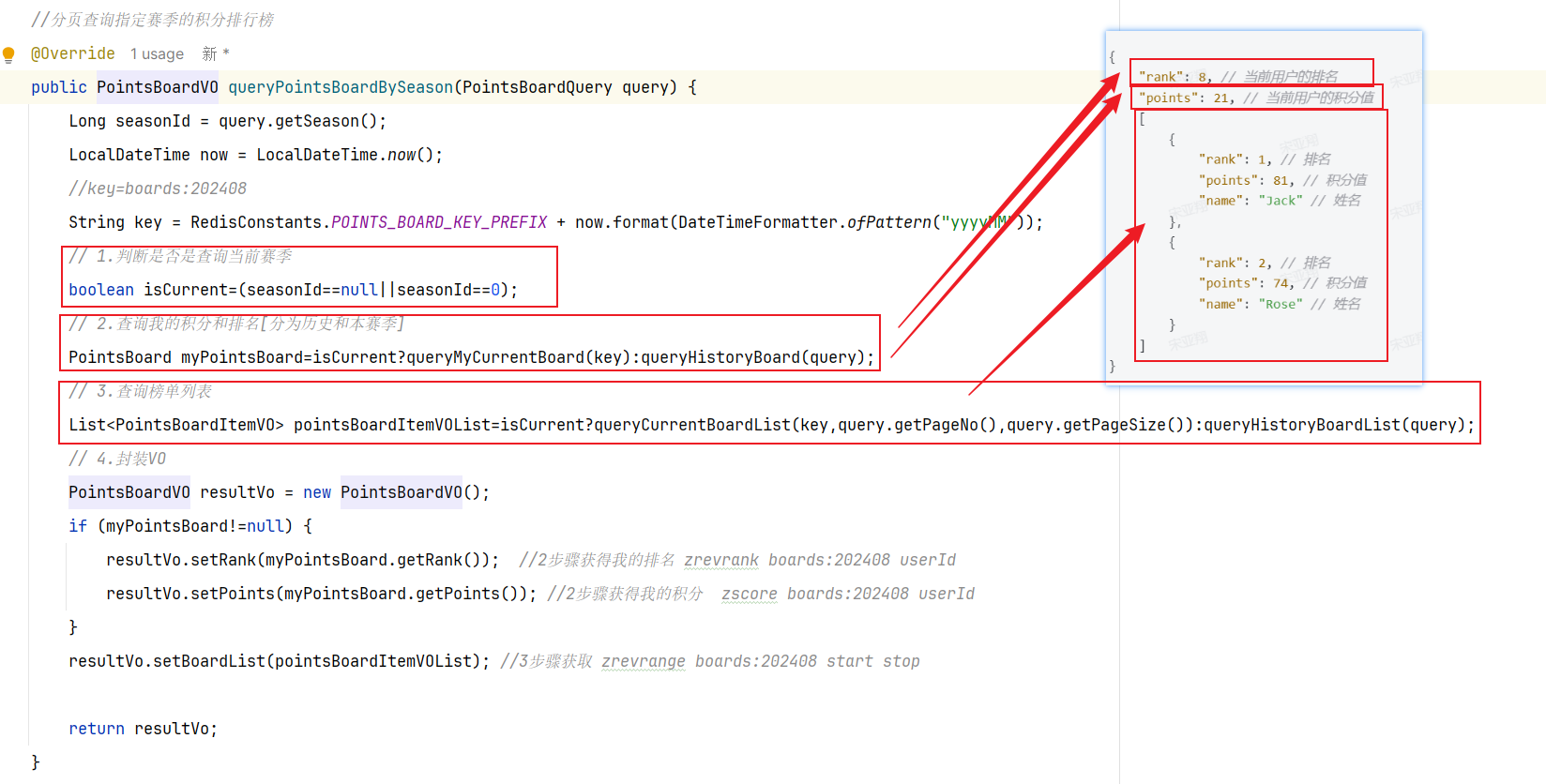
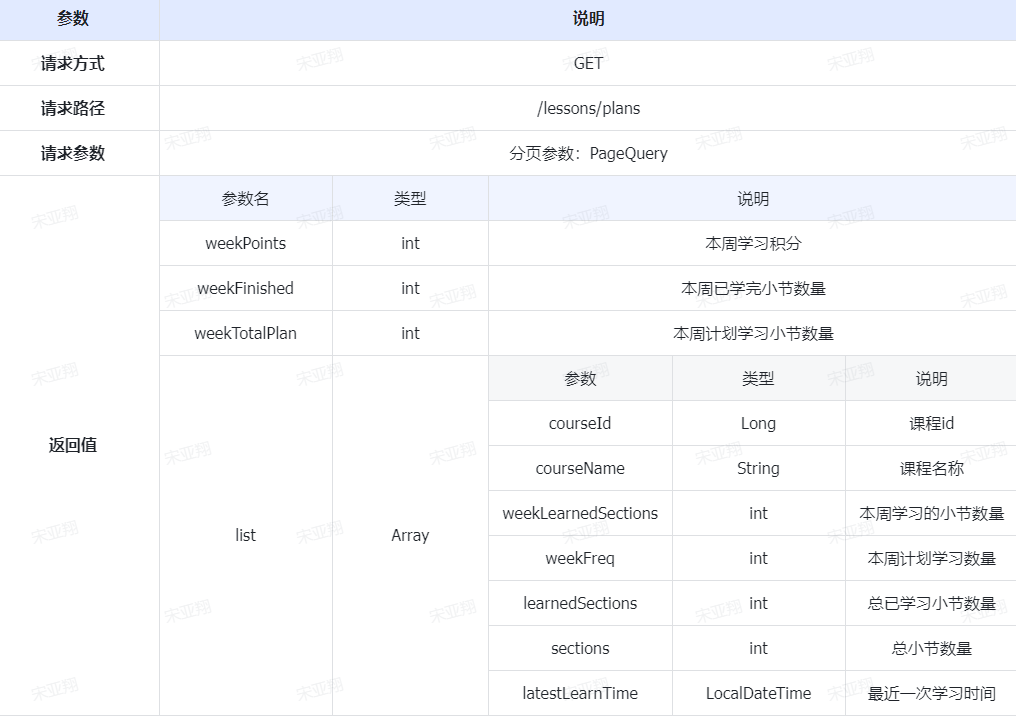
2.查询积分榜(实时数据) 1.原型图 在个人中心,学生可以查看指定赛季积分排行榜(只显示前100 ),还可以查看自己总积分和排名。而且排行榜分为本赛季榜单和历史赛季榜单。
我们可以在一个接口中同时实现这两类榜单的查询
首先,我们来看一下页面原型(这里我给出的是原型对应的设计稿,也就是最终前端设计的页面效果):
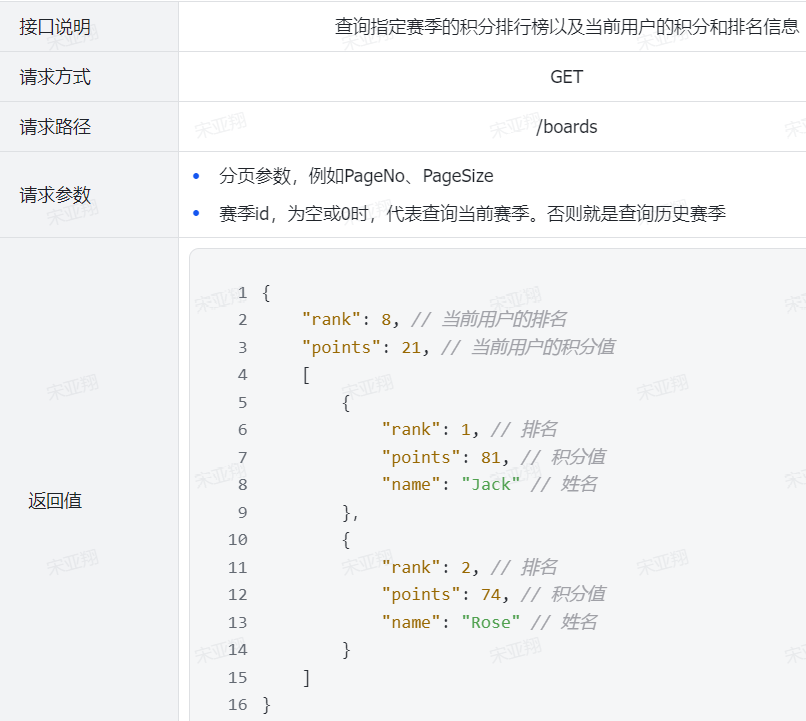
2.设计数据库 3.业务逻辑图 首先我们分析一下请求参数:
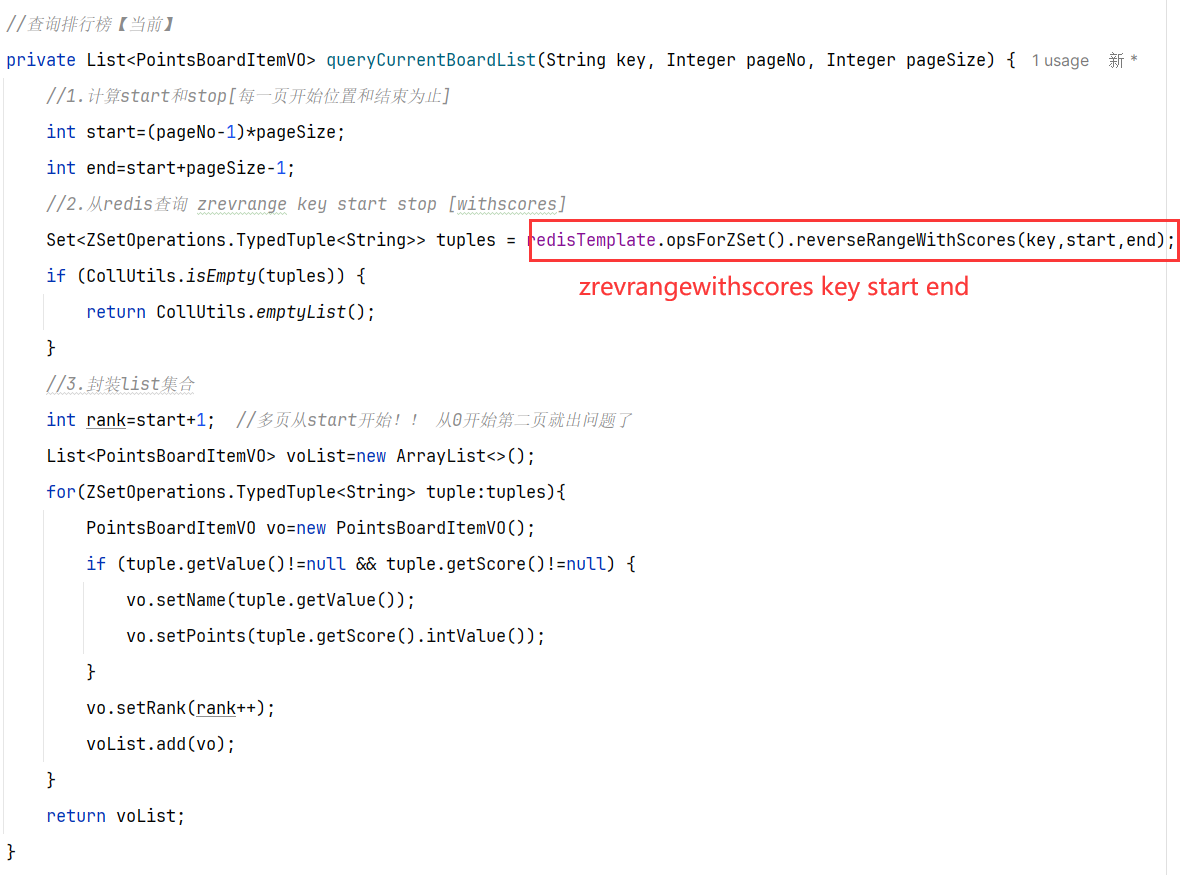
榜单数据非常多,不可能一次性查询出来,因此这里一定是分页查询(滚动分页),需要分页参数。
由于要查询历史榜单需要知道赛季,因此参数中需要指定赛季id。【当赛季id为空,我们认定是查询当前赛季。这样就可以把两个接口合二为一】
然后是返回值,无论是历史榜单还是当前榜单,结构都一样。分为两部分:
当前用户的积分和排名。【当前用户不一定上榜,因此需要单独查询】
榜单数据。就是N个用户的积分、排名形成的集合。
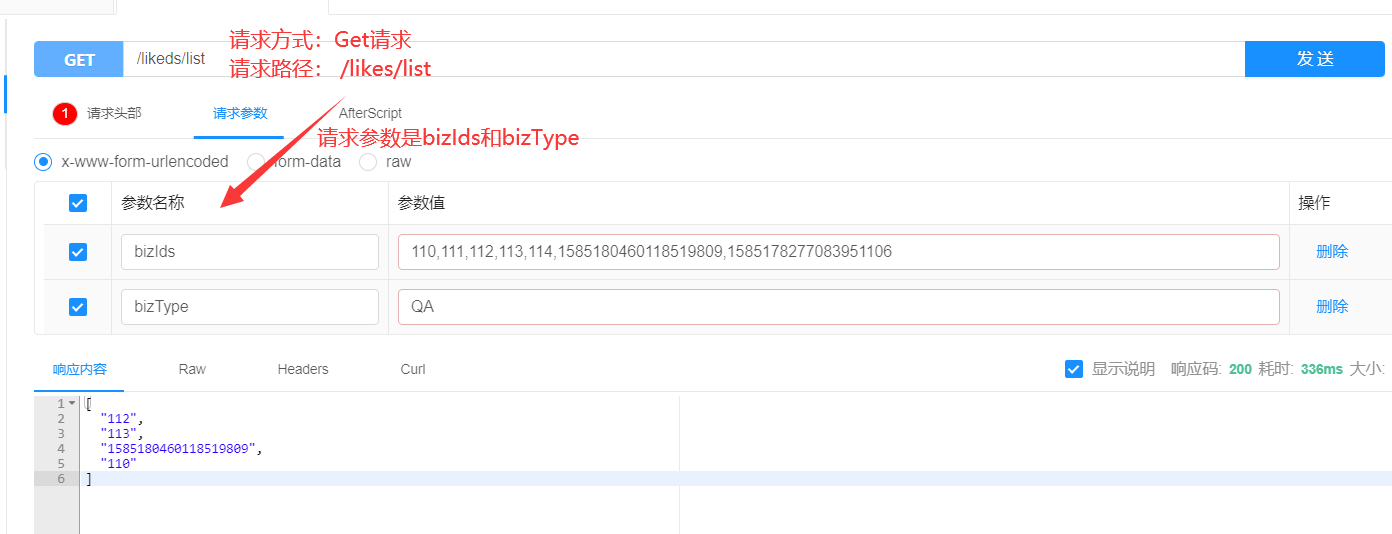
4.接口分析 综上,接口信息如下:
5.具体实现
分为整体:
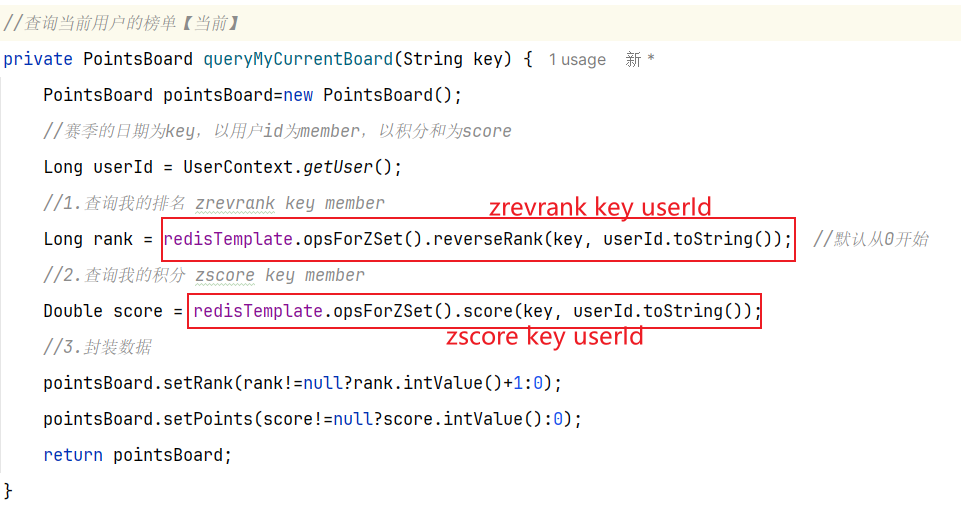
其中查询我的积分和排名:
其中查询榜单列表:
无
6.具体难点和亮点
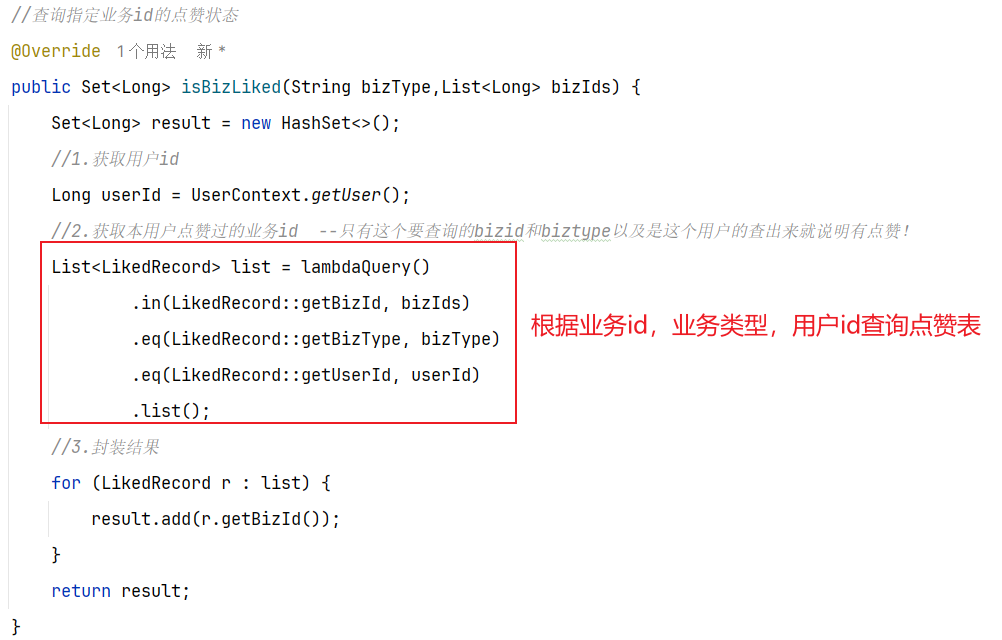
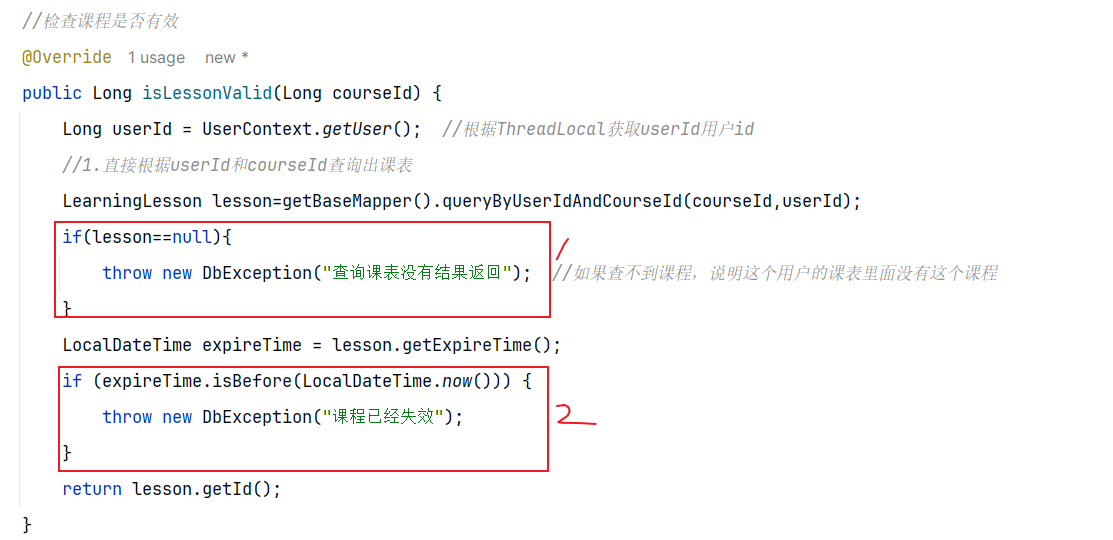
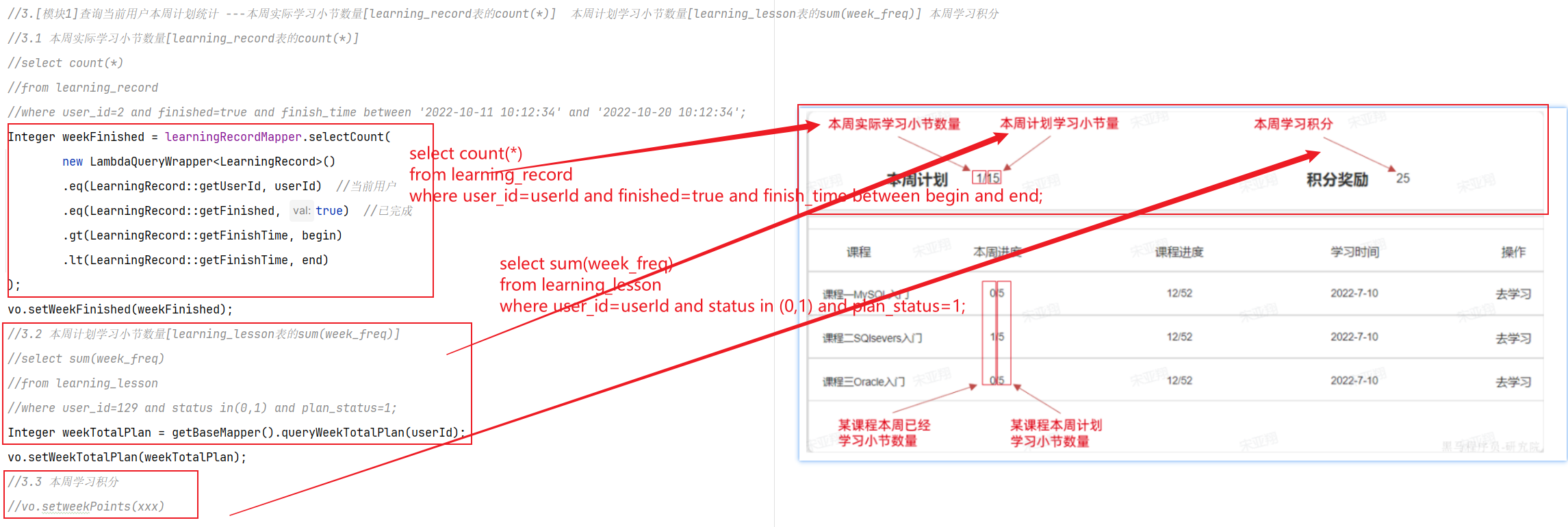
问题一:如何获取用户(User_id)我的排名和积分?
获得我的积分 zscore boards:202408 userId
获得我的排名 zrevrank boards:202408 userId
==——————————————== ==历史数据[Redis和Mysql数据持久化]== 0.业务分析 积分排行榜是分赛季的,每一个月是一个赛季。因此每到每个月的月初,就会进入一个新的赛季。所有用户的积分应该清零,重新累积。
如果直接删除Redis数据,那就丢失了一个赛季 —-==持久化 ==—-> Mysql
假如有数百万用户,每个赛季榜单都有数百万数据。随着时间推移,历史赛季越来越多,如果全部保存到一张表中,数据量会非常恐怖!–>==海量数据存储策略==
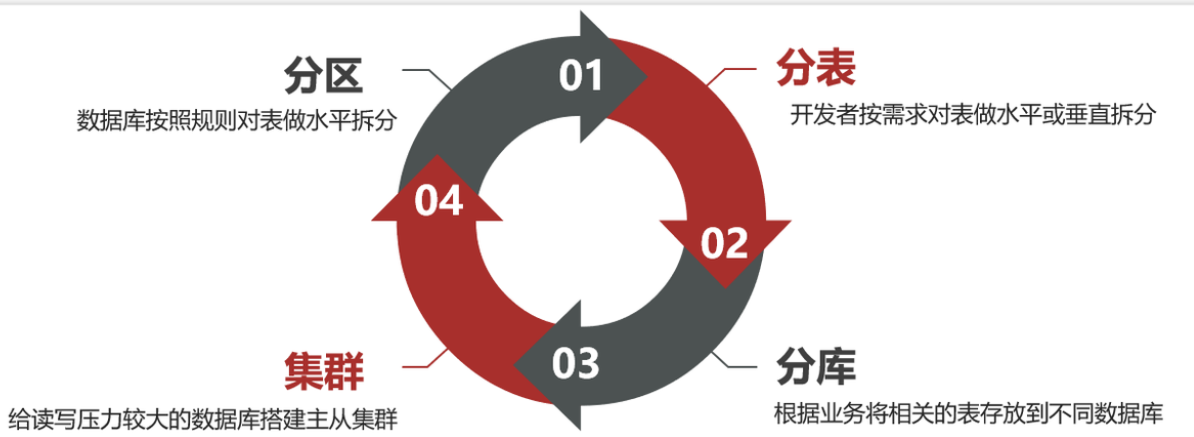
1.海量数据存储策略[四种策略]
1.1 分区 表分区(Partition) 是一种数据存储方案,可以解决单表数据较多的问题【MySQL5.1开始支持表分区功能】
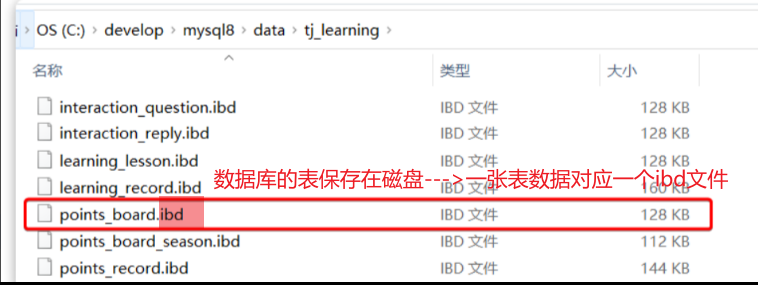
如果表数据过多 —> 文件体积非常大 —> 文件跨越多个磁盘分区 —> 数据检索时的速度就会非常慢 —>【Mysql5.1引入表分区 】按照某种规则,把表数据对应的ibd文件拆分成多个文件来存储。
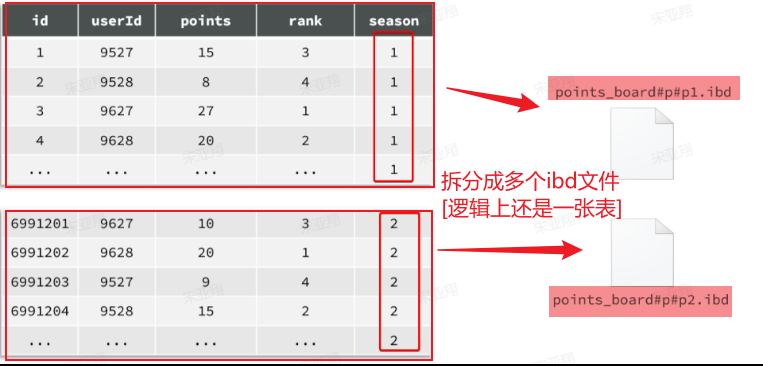
例如,我们的历史榜单数据,可以按照赛季切分:
此时,赛季榜单表的磁盘文件就被分成了两个文件,但逻辑上还是一张表。CRUD不会变化,只是底层MySQL处理上会有变更,检索时可以只检索某个文件就可以
表分区的好处:
1.可以存储更多的数据,突破单表上限。甚至可以存储到不同磁盘,突破磁盘上限
2.查询时可以根据规则只检索某一个文件,提高查询效率
3.数据统计时,可以多文件并行统计,最后汇总结果,提高统计效率【分而治之,各自统计】
4.对于一些历史数据,如果不需要时,可以直接删除分区文件,提高删除效率
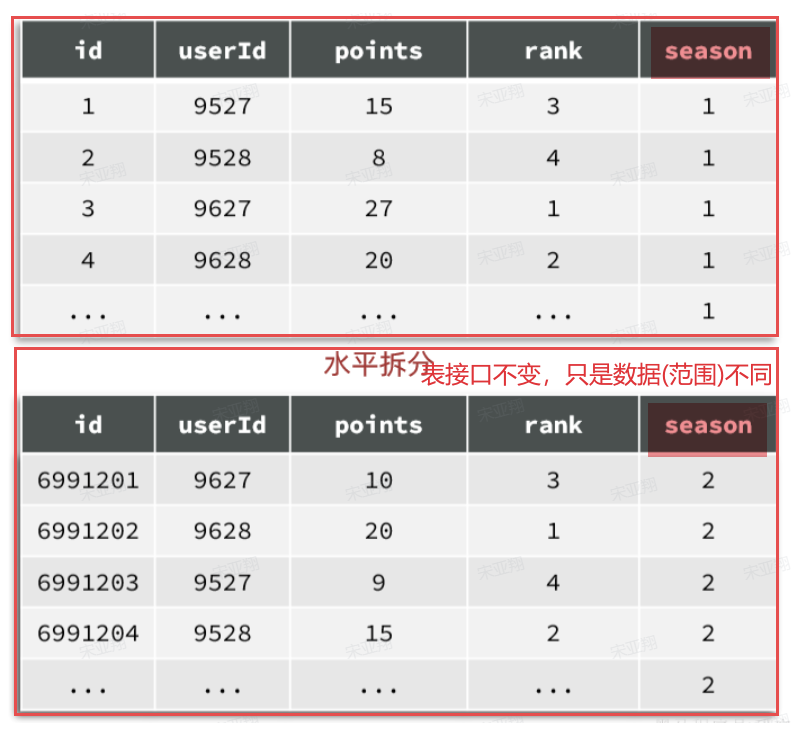
表分区的方式:【对数据做水平拆分 】
Range分区:按照指定字段的取值范围分区 –保单表,根据1-10,11-20这样10个为一组区分
List分区:按照指定字段的枚举值分区【必须提前制定所有分区值,否则会因为找不到报错】–保单表,根据保单是车险财/非车进行区分
Hash分区:按照字段做hash运算后分区【字段一般是对数值类型】 –保单表,根据保单表%hash运算进行区分
Key分区:按照指定字段的值做运算结果分区【不限定字段类型】 –保单表,根据保单号%9进行区分
1.2 分表 开发者自己对表的处理,与数据库无关
在开发中我们很多情况下业务需求复杂,更看重分表的灵活性。因此,我们大多数情况下都会选择分表方案。
分表的好处:
分表的坏处:
1.CRUD需要自己判断访问哪张表
2.垂直拆分还会导致事务问题及数据关联问题:【原本一张表的操作,变为多张表操作,要考虑长事务情况】
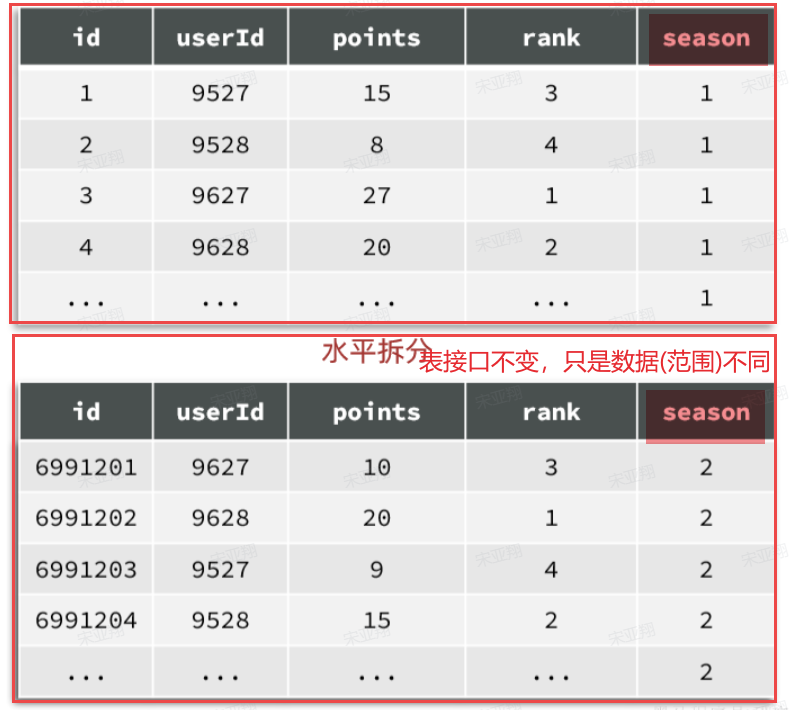
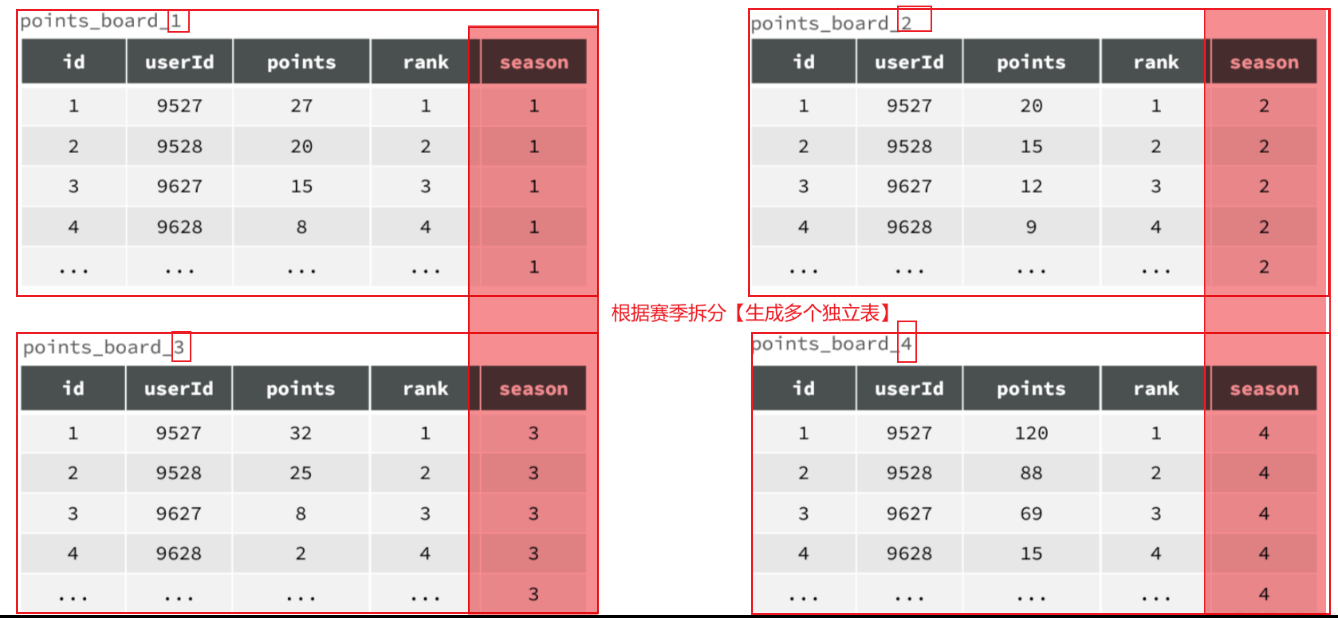
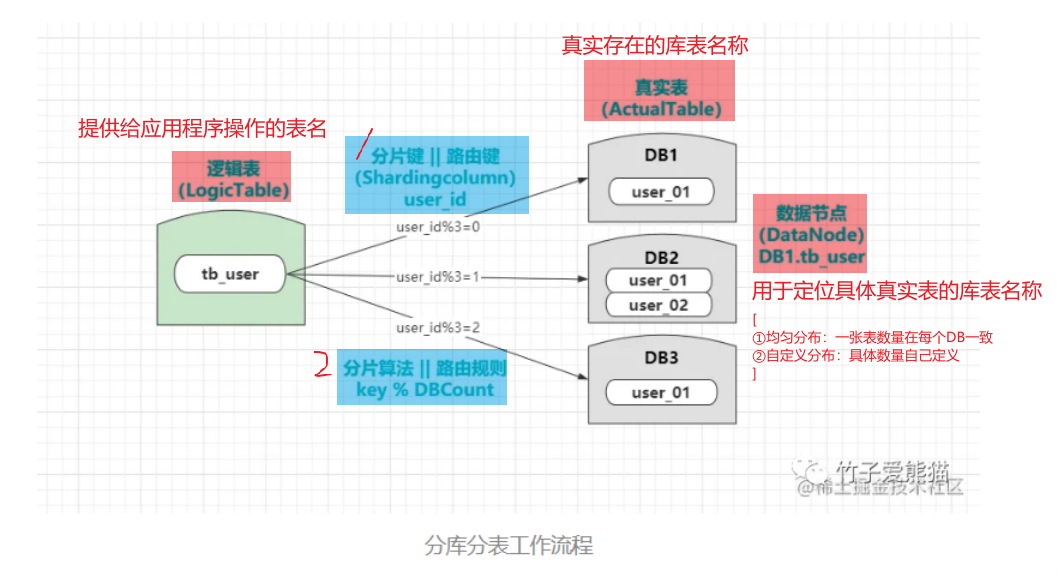
1.2.1 水平分表 例如,对于赛季榜单,我们可以按照赛季拆分为多张表,每一个赛季一张新的表 。如图:
这种方式就是水平分表,表结构不变 ,仅仅是每张表数据不同 。查询赛季1,就找第一张表。查询赛季2,就找第二张表。
1.2.2 垂直分表 如果一张表的字段非常多(比如达到30个以上,这样的表我们称为宽表 )。宽表由于字段太多,单行数据体积就会非常大,虽然数据不多,但可能表体积也会非常大!从而影响查询效率。
例如一个用户信息表,除了用户基本信息,还包含很多其它功能信息:
1.3 分库[垂直分库] 无论是分区,还是分表,我们刚才的分析都是建立在单个数据库 的基础上。但是单个数据库也存在一些问题:
单点故障问题:数据库发生故障,整个系统就会瘫痪【鸡蛋都在一个篮子里】
单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈【性能有限制】
单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢【存储有限制】
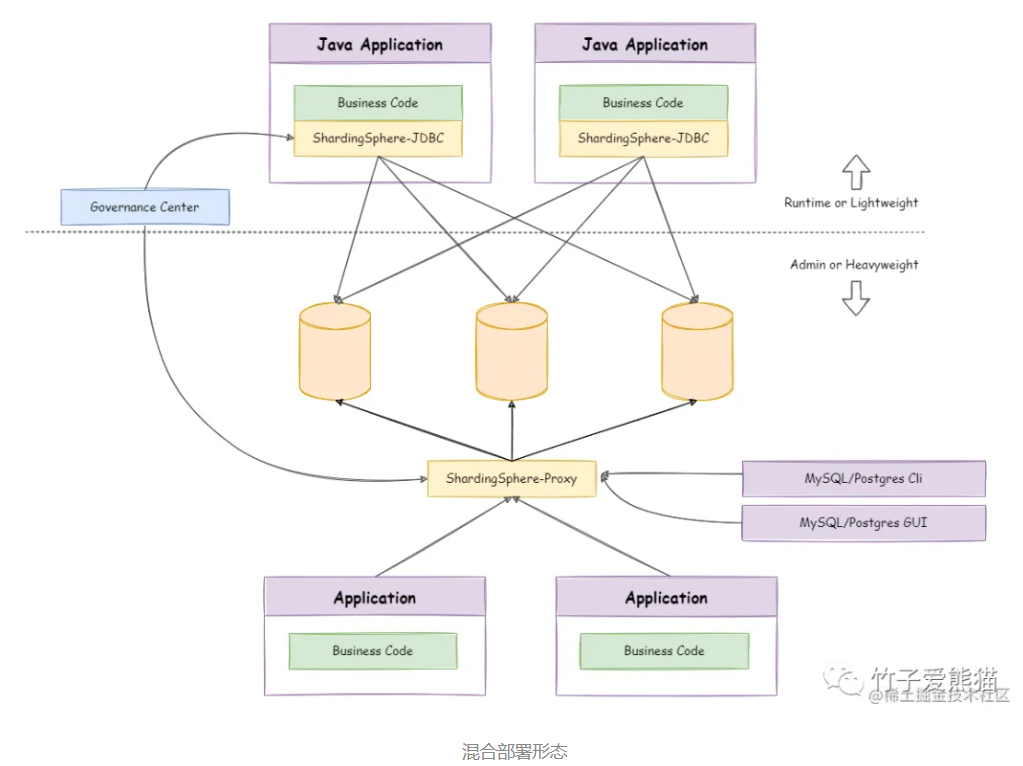
综上,在大型系统中,我们除了要做①分表、还需要对数据做②分库—>建立综合集群。
优点:【解决了单个数据库的三大问题】
1.解决了海量数据存储问题,突破了单机存储瓶颈
2.提高了并发能力,突破了单机性能瓶颈
3.避免了单点故障
缺点:
1.成本非常高【要多个服务器,多个数据库】
2.数据聚合统计比较麻烦【因为牵扯多个数据库,有些语句会很麻烦】
3.主从同步的一致性问题【主数据库往从数据库更新,会有不可取消的延误时间,只能通过提高主从数据库网络带宽,机器性能等操作(↓)延误时间】
4.分布式事务问题【因为涉及多个数据库多个表,使用seata分布式事务可以解决】
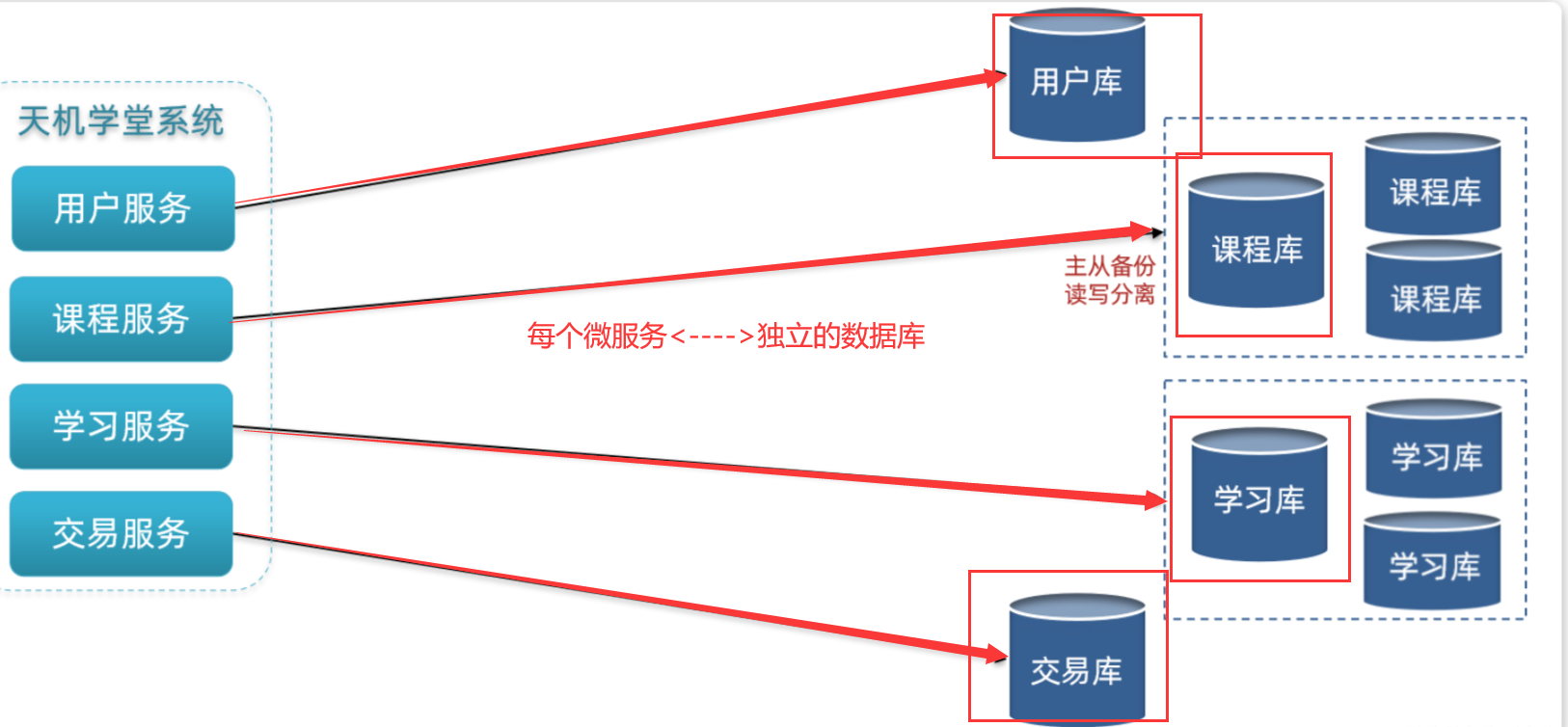
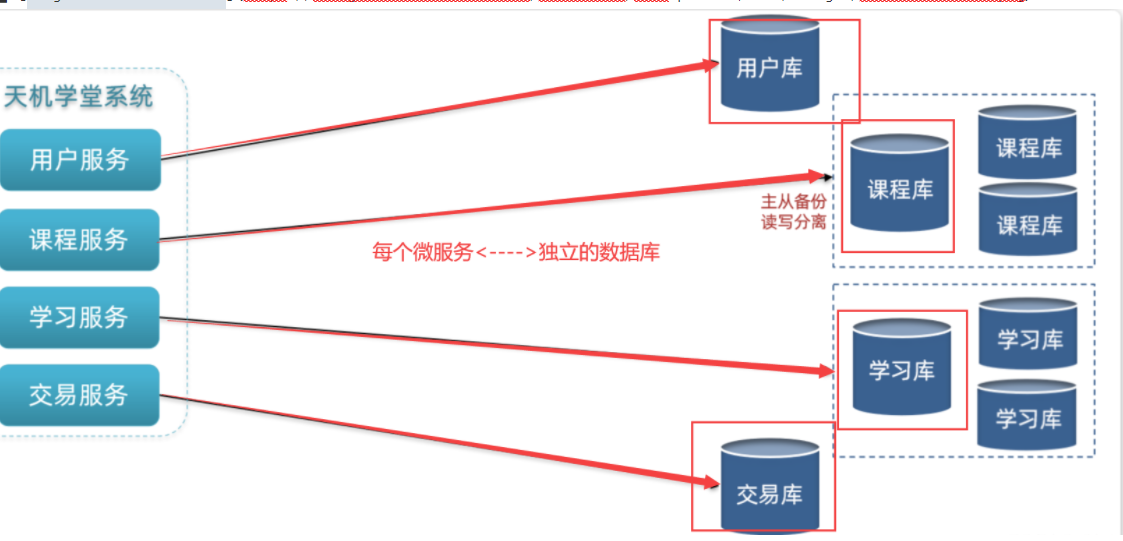
微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的
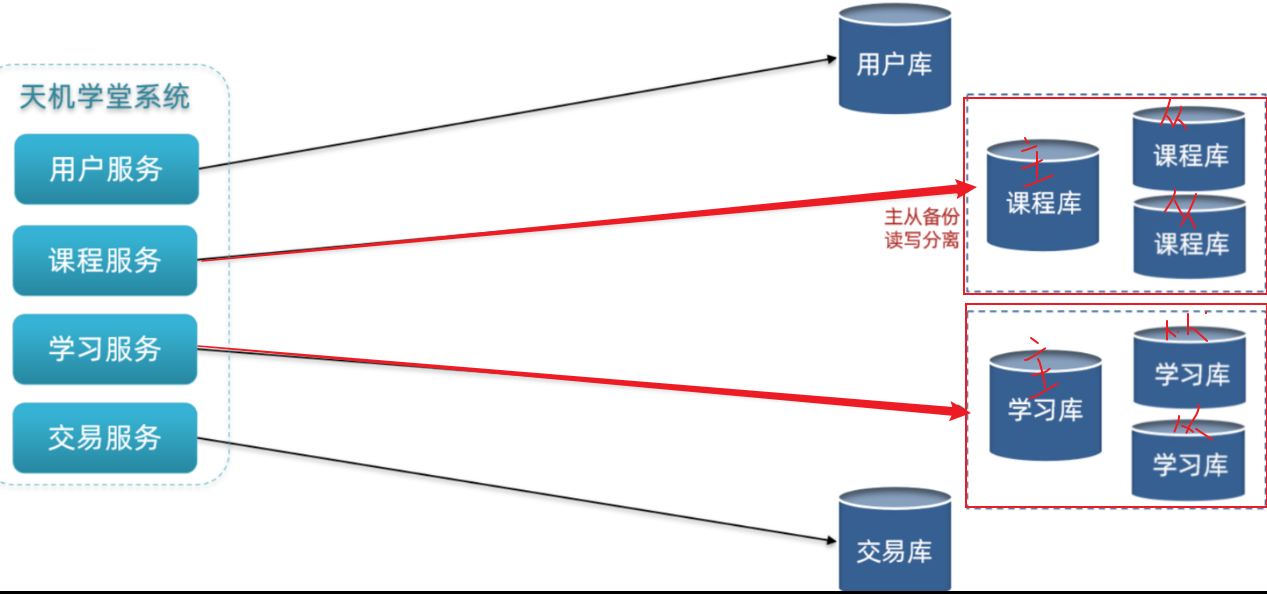
1.4 集群[主写从读] [保证单节点的高可用性]给数据库建立主从集群,主节点向从节点同步数据,两者结构一样
2.[历史榜单]存储策略—水平分表 东林微课堂是一个教育类项目,用户规模并不会很高,一般在十多万到百万级别。因此最终的数据规模也并不会非常庞大。综合之前的分析,结合天机学堂的项目情况,我们可以对榜单数据做分表,但是暂时不需要做分库和集群。
由于我们要解决的是数据过多问题,因此分表的方式选择水平分表 。具体来说,就是按照赛季拆分,每一个赛季是一个独立的表,如图:
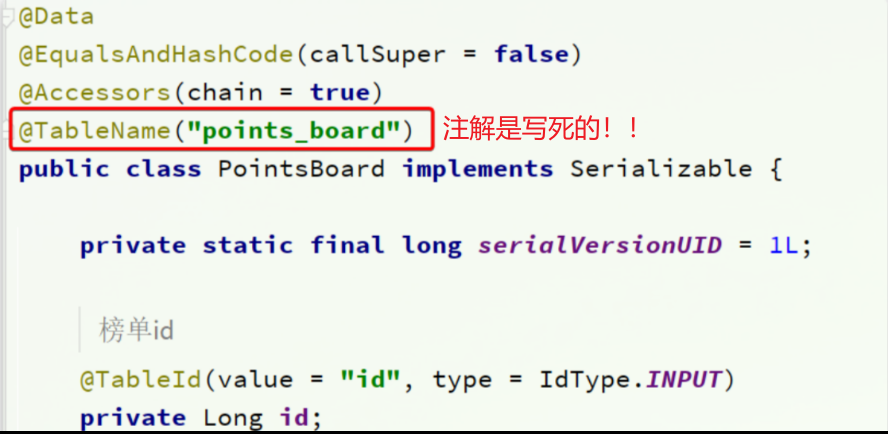
但是,考虑我们只需要排名,积分,用户id即可—>可以删除掉season,rank两个字段【也可以减少单表存储】
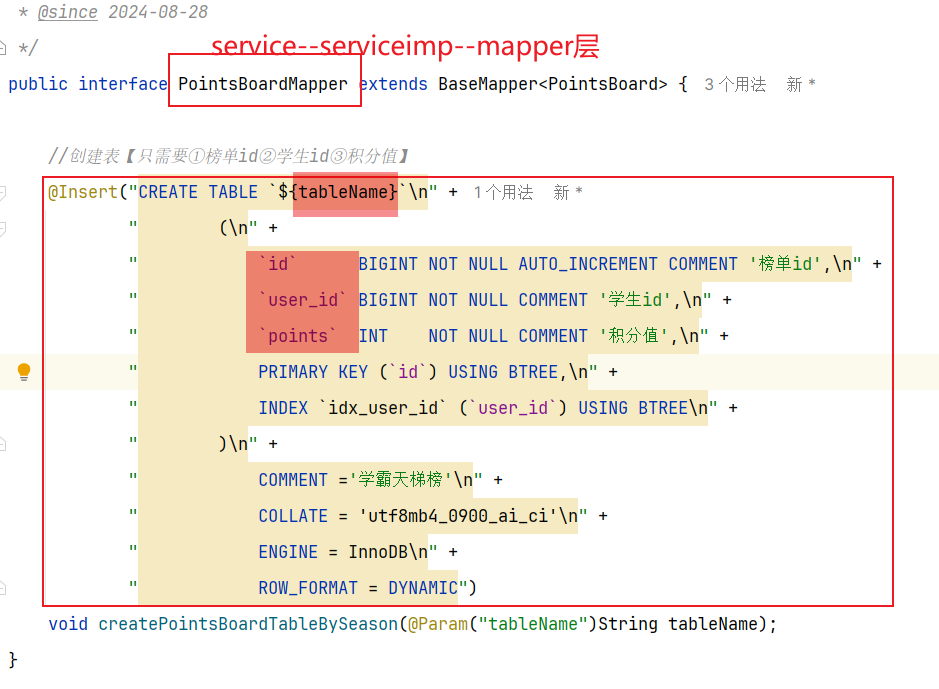
1 2 3 4 5 6 7 8 CREATE TABLE IF NOT EXISTS `points_board_X` ( `id` BIGINT NOT NULL AUTO_INCREMENT COMMENT '榜单id', `user_id` BIGINT NOT NULL COMMENT '学生id', `points` INT NOT NULL COMMENT '积分值', PRIMARY KEY (`id`) USING BTREE, INDEX `idx_user_id` (`user_id`) USING BTREE )COMMENT ='学霸天梯榜' COLLATE = 'utf8mb4_0900_ai_ci' ENGINE = InnoDB ROW_FORMAT = DYNAMIC;
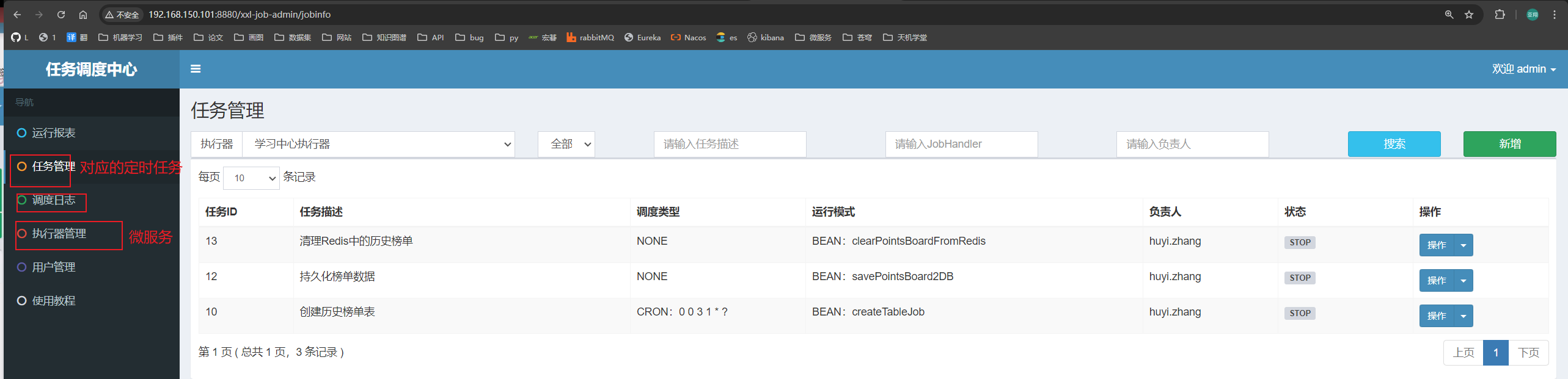
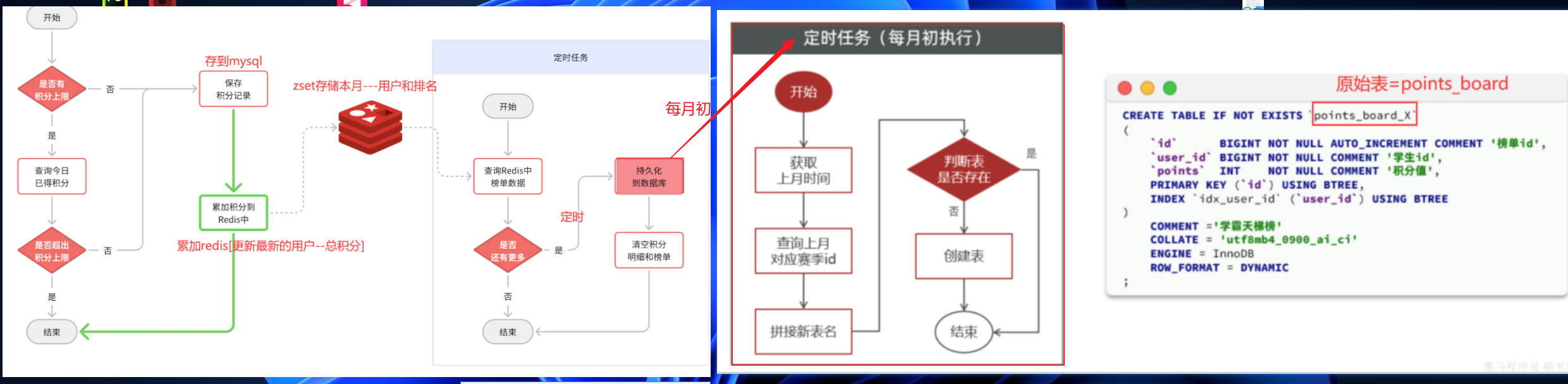
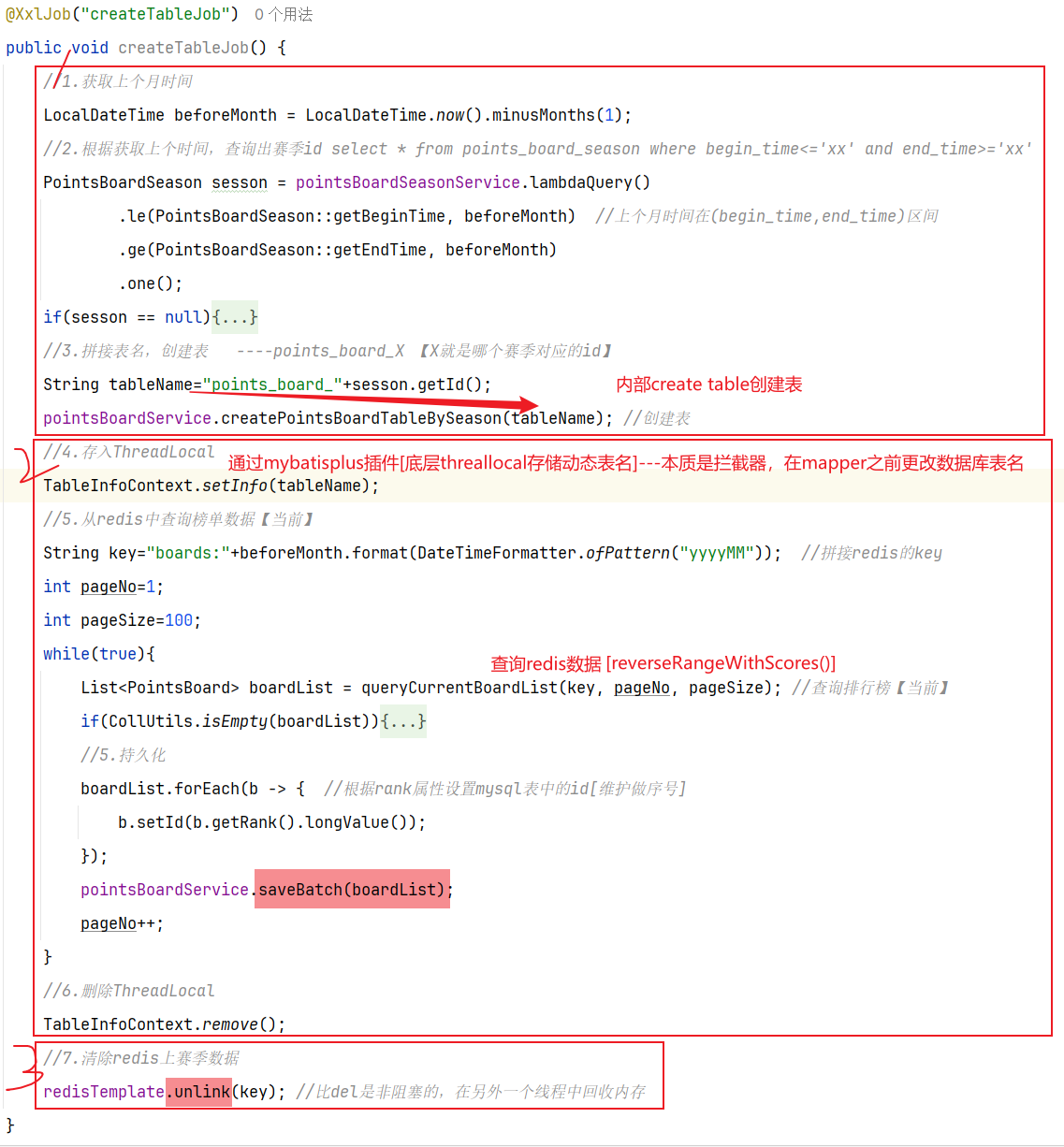
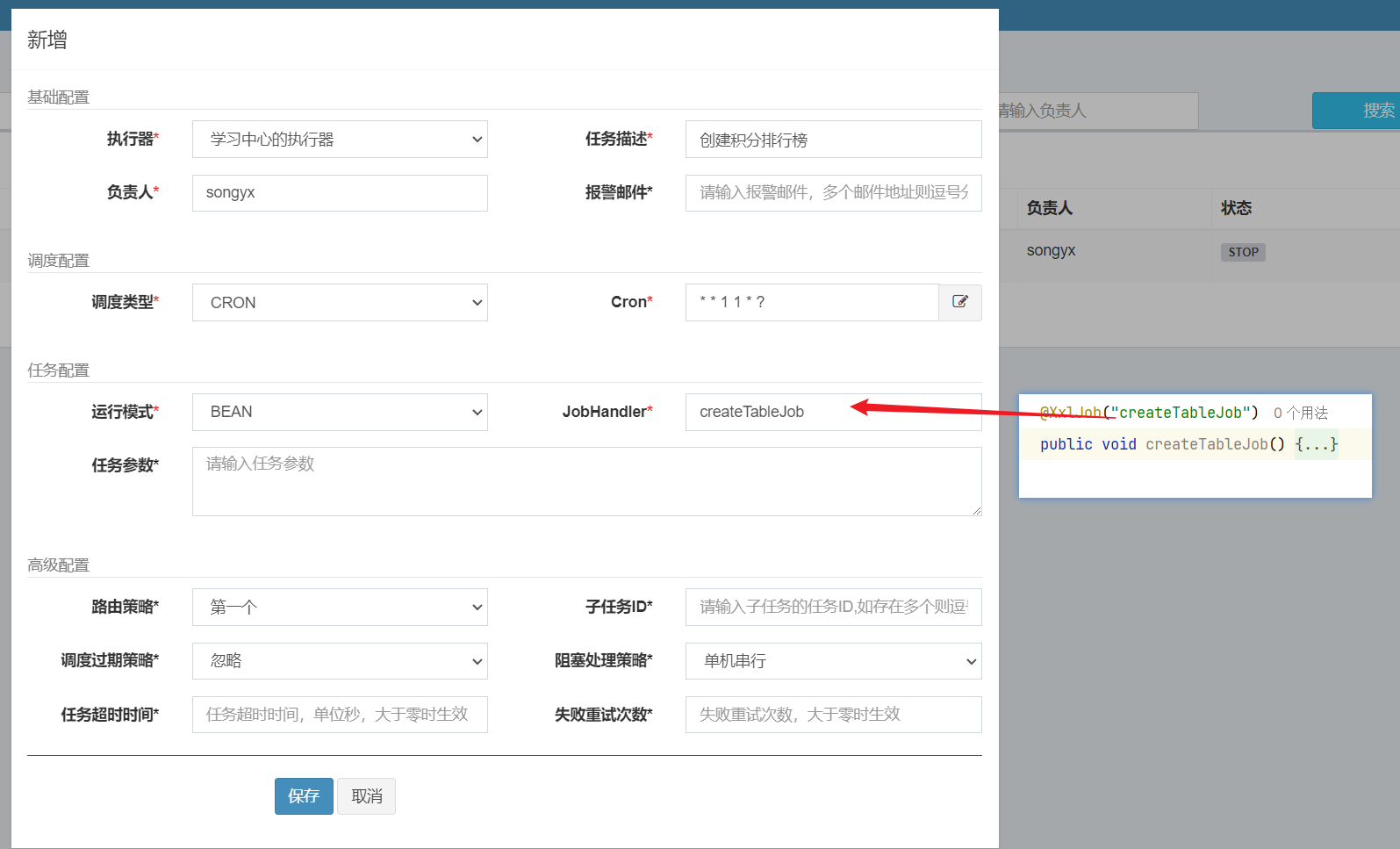
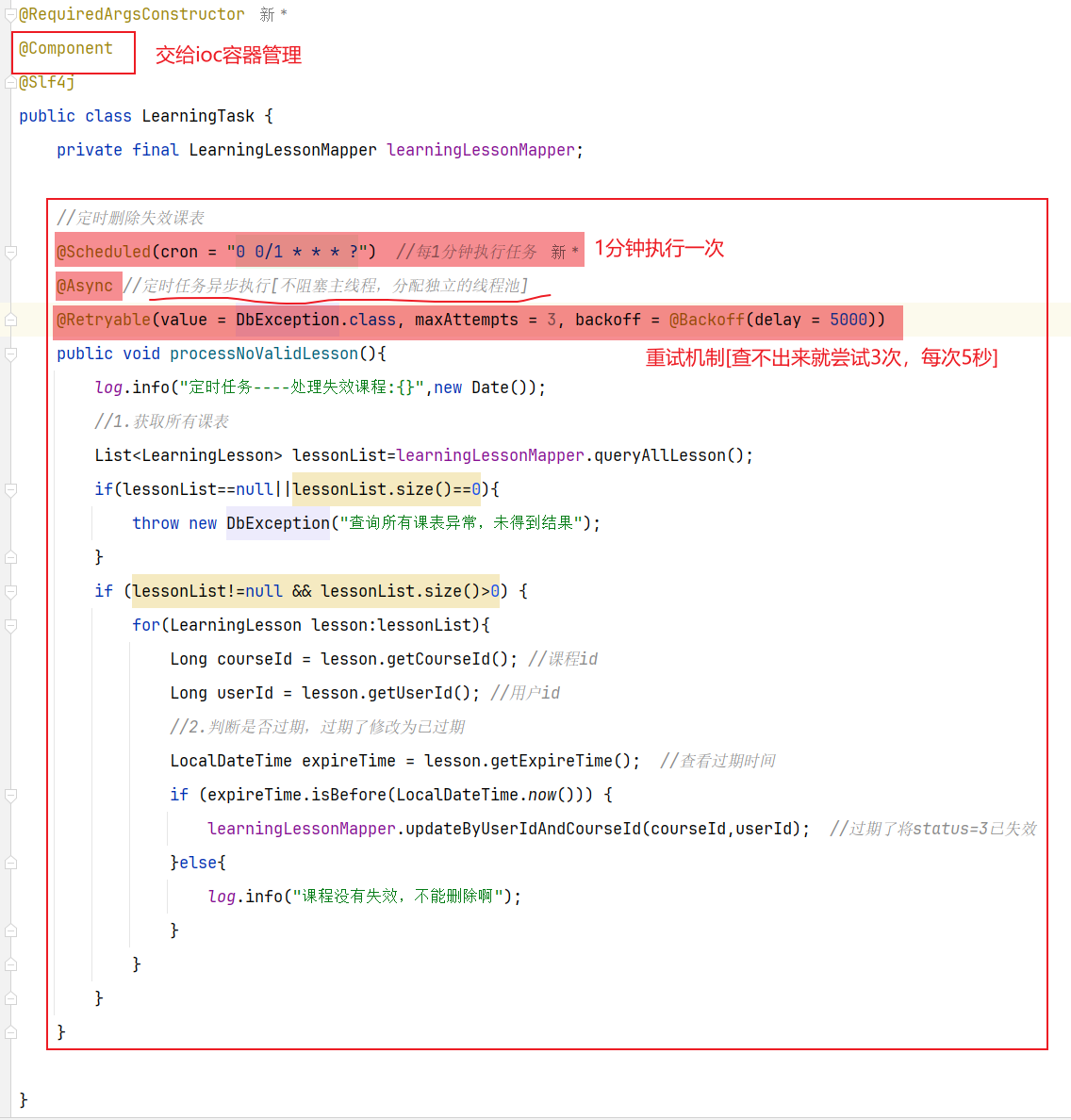
==——–具体实现——–== 1.[定时]生成历史榜单表 1.1 业务设计 每个赛季刚开始的时候(月初)来创建新的赛季榜单表。每个月的月初执行一个创建表的任务,我们可以利用定时任务 来实现。
【由于表的名称中包含赛季id,因此在定时任务中我们还要先查询赛季信息,获取赛季id,拼接得到表名,最后创建表】
大概流程如图:
1.2 实现思路
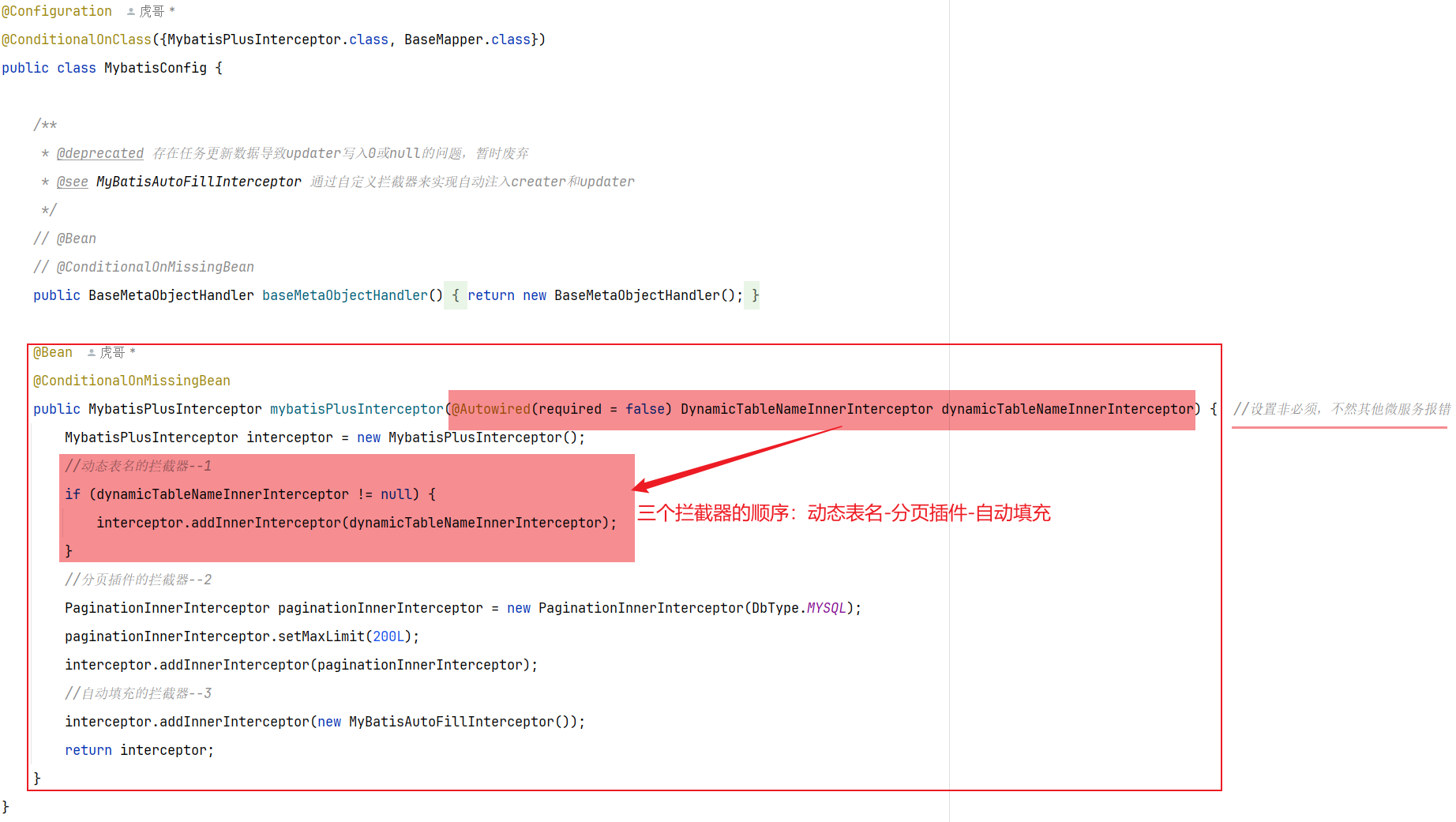
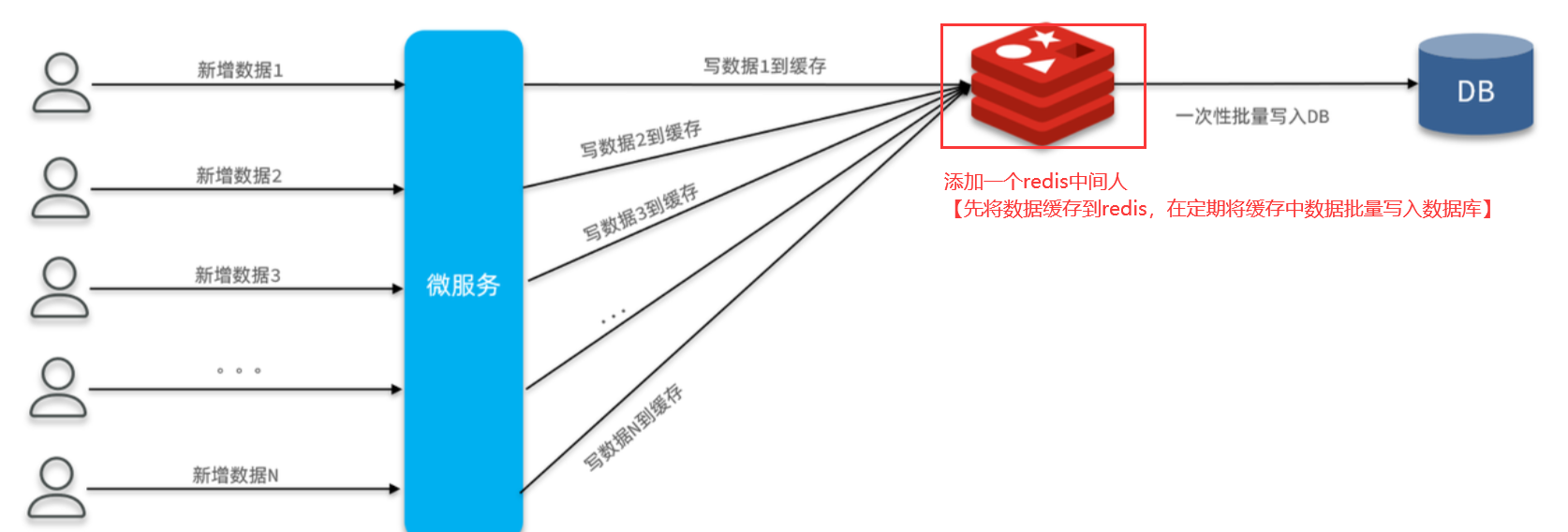
根据(key,pageNo,pageSize)分页查询redis数据[id(改为input自己输入,按照rank属性设置),user_id,points],然后通过saveBatch分批插入新建的数据库内[数据库名根据mybatisplus动态插件底层通过threadlocal存储表名,本质是一个拦截器,在数据到mapper和数据库打交道的时候更改数据库名],插入结束记得remove删除
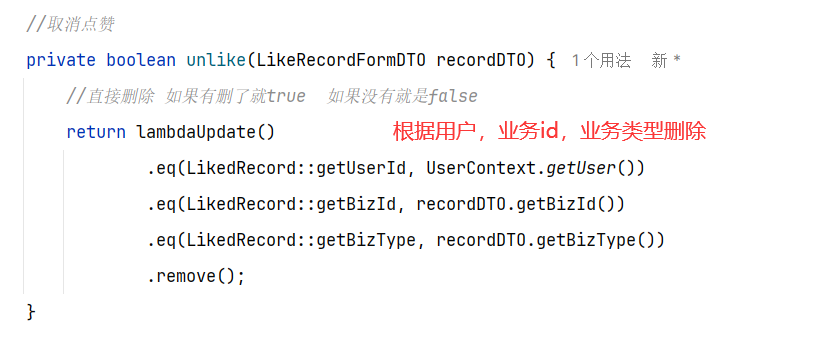
③清除redis数据:unlike命令会在另外一个线程中回收内存,非阻塞【del会阻塞】
使用unlike指令删除【非阻塞式】
1.3 具体实现
1.4 具体难点和亮点
根据(key,pageNo,pageSize)分页查询redis数据[id(改为input自己输入,按照rank属性设置),user_id,points],然后通过saveBatch分批插入新建的数据库内[数据库名根据mybatisplus动态插件底层通过threadlocal存储表名,本质是一个拦截器,在数据到mapper和数据库打交道的时候更改数据库名],插入结束记得remove删除
③清除redis数据:unlike命令会在另外一个线程中回收内存,非阻塞【del会阻塞】
使用unlike指令删除【非阻塞式】
2.MybatisPlus动态表名插件 2.1 原始情况
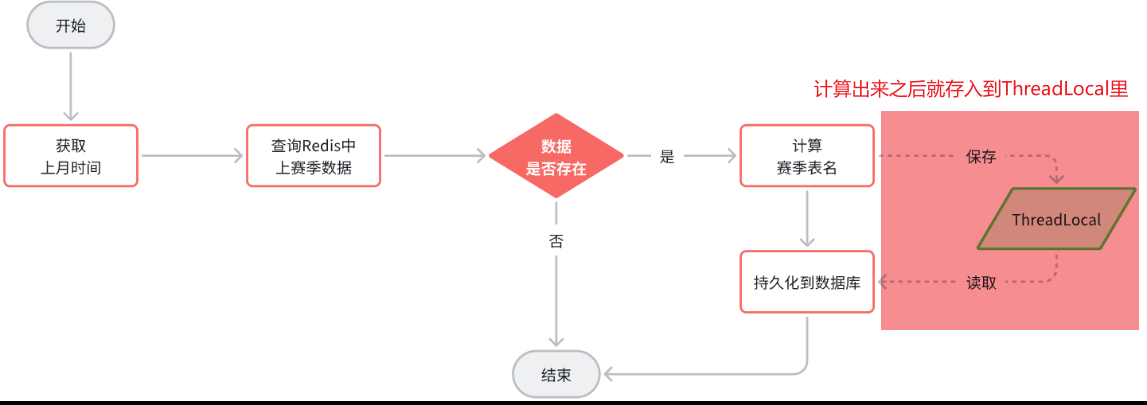
2.2 实现思路 流程中,我们会先计算表名,然后去执行持久化,而动态表名插件就会生效,去替换表名。
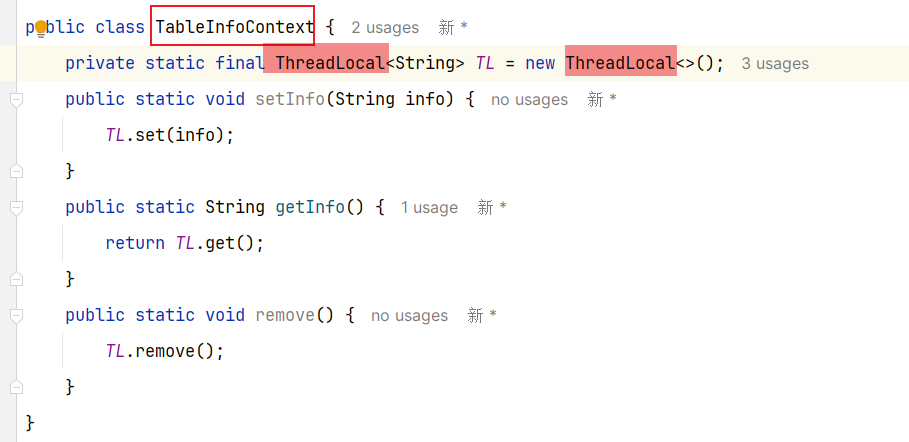
因此,一旦我们计算完表名,以某种方式传递给插件中的TableNameHandler,那么就无需重复计算表名了。都是MybatisPlus内部调用的,我们无法传递参数。—> 但是可以在一个线程中实现数据共享
2.3 具体实现
3.XxlJob分片 3.1 原理 刚才定义的定时持久化任务,通过while死循环,不停的查询数据,直到把所有数据都持久化为止。这样如果数据量达到数百万,交给一个任务执行器来处理会耗费非常多时间—->实例多个部署 ,这样就会有多个执行器并行执行(但是多个执行器执行相同代码,都从第一页开始也会重复处理)—->任务分片
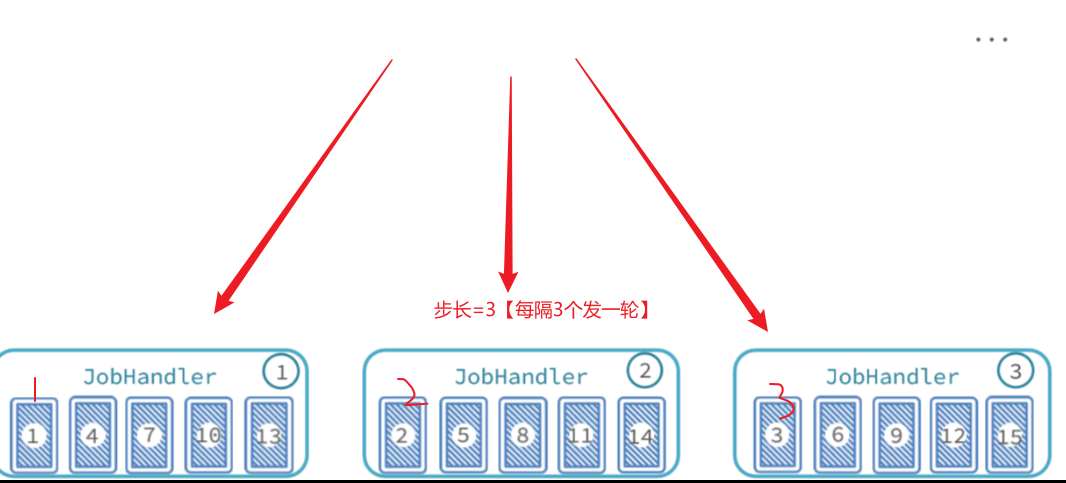
举例[类似于发牌 ]:
最终,每个执行器处理的数据页情况:
执行器1:处理第1、4、7、10、13、…页数据
执行器2:处理第2、5、8、11、14、…页数据
执行器3:处理第3、6、9、12、15、…页数据
要想知道每一个执行器执行哪些页数据,只要弄清楚两个关键参数即可:
起始页码:pageNo【执行器编号是多少,起始页码就是多少】
下一页的跨度:step【执行器有几个,跨度就是多少。也就是说你要跳过别人读取过的页码,类似于分布式ID的步长】
因此,现在的关键就是获取两个数据:
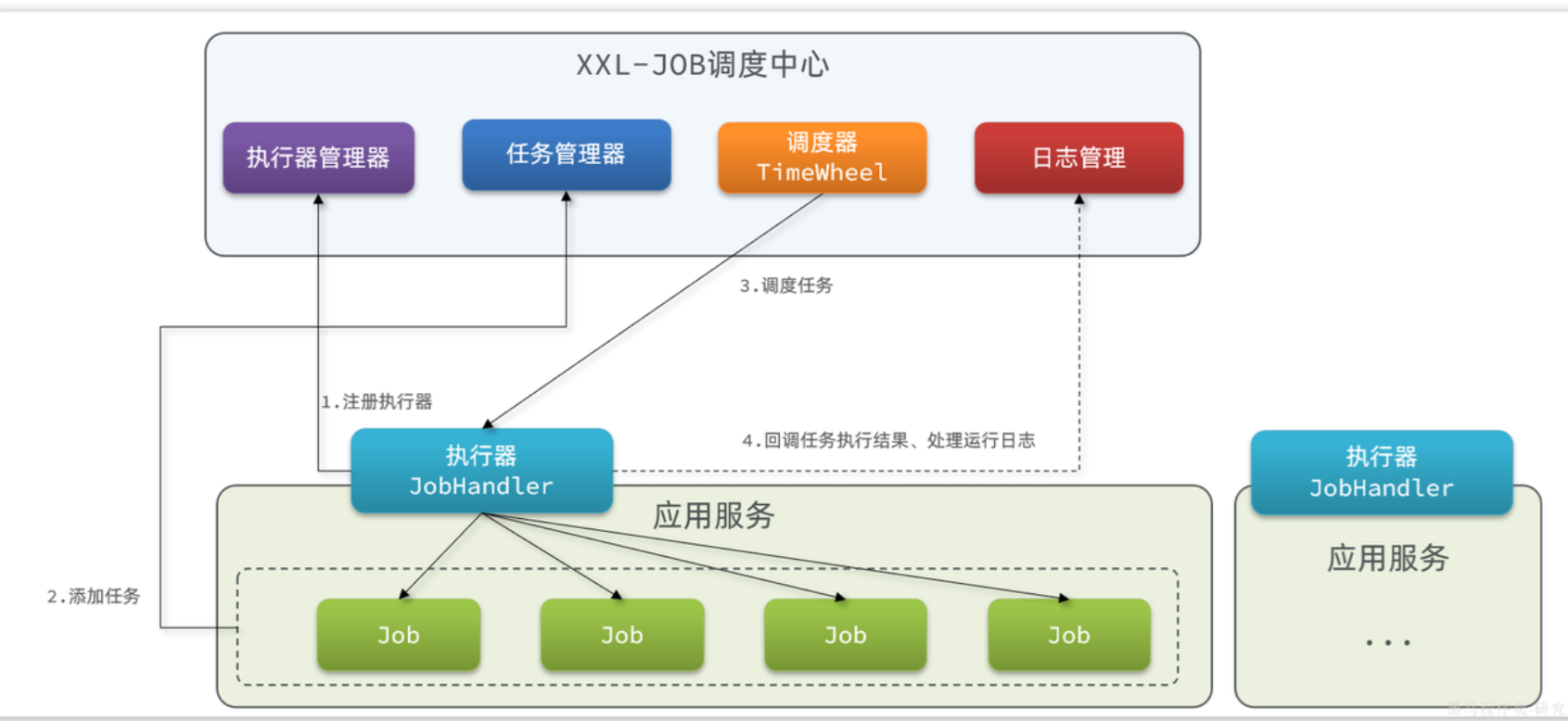
这两个参数XXL-JOB作为任务调度中心,肯定是知道的,而且也提供了API帮助我们获取:
这里的分片序号其实就是执行器序号,不过是从0开始,那我们只要对序号+1,就可以作为起始页码了
3.2 业务优化
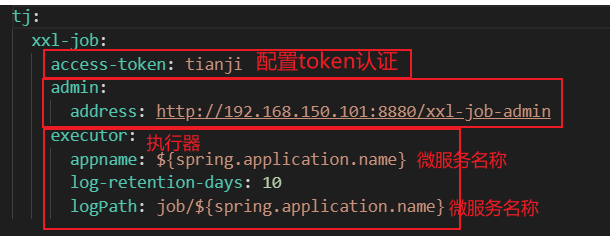
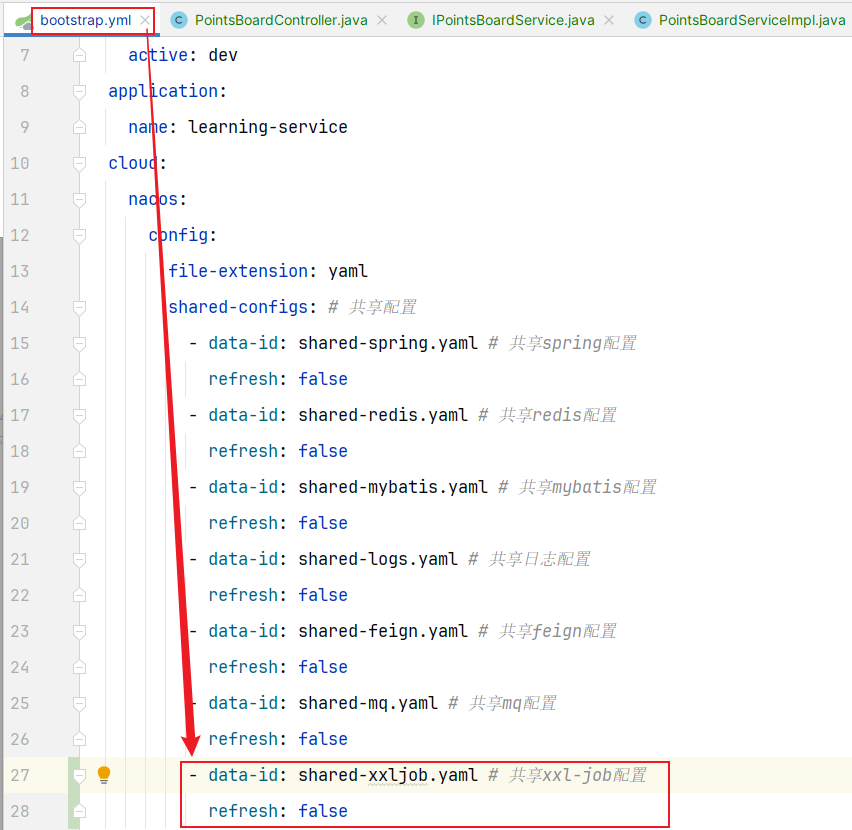
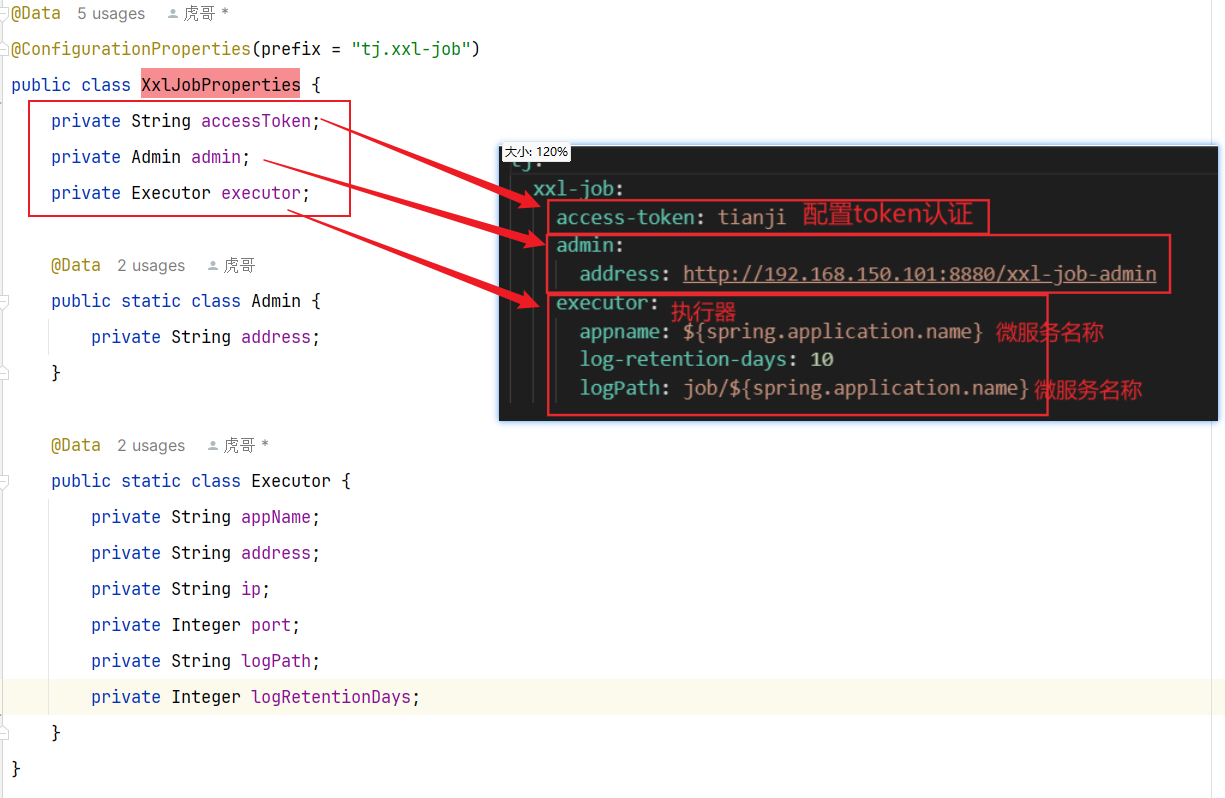
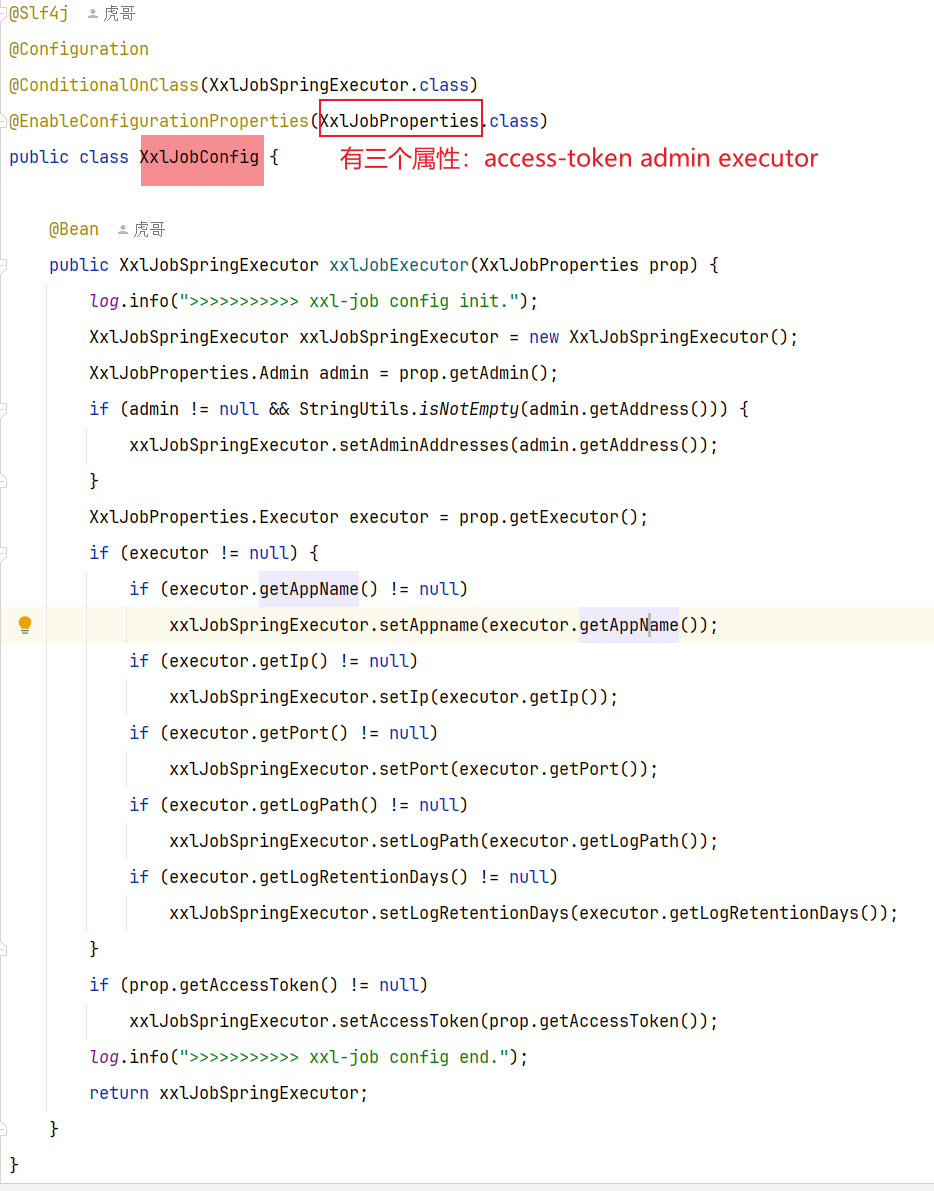
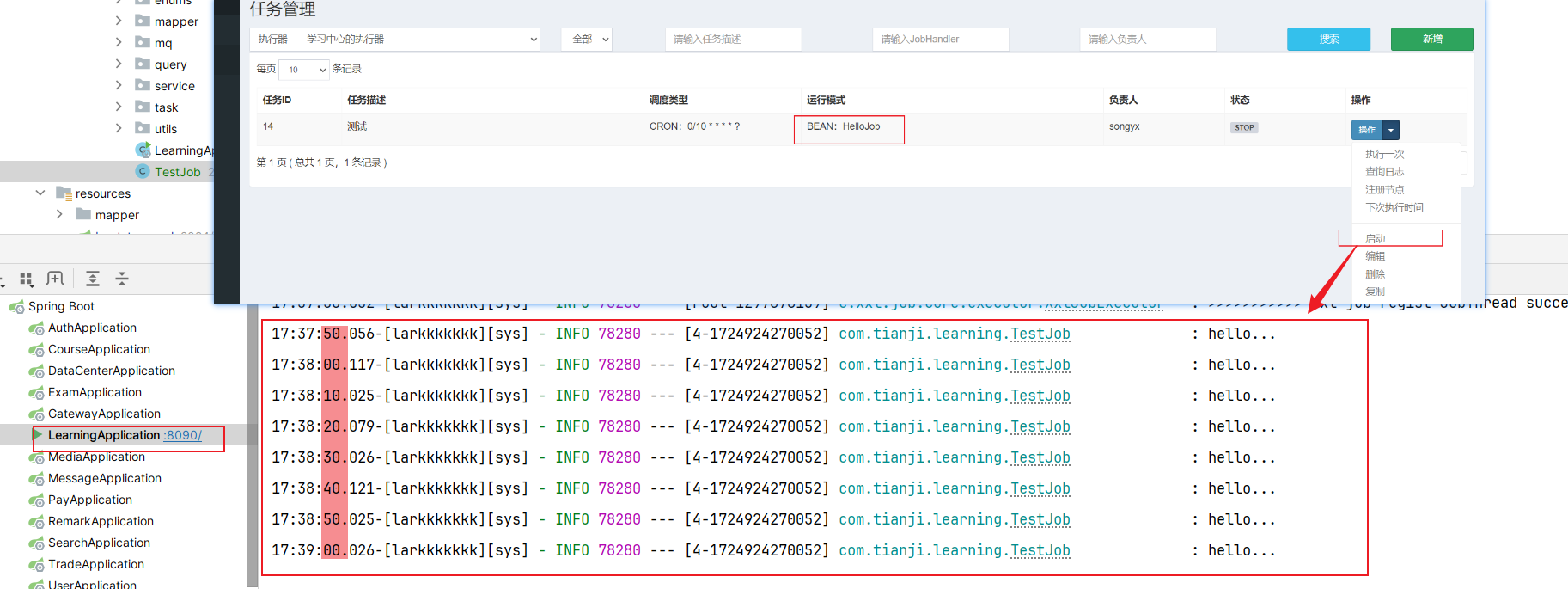
3.3 引发问题解决方案 使用xxl-job定时每月初进行持久化:
①根据计算上个月时间创建上赛季mysql表
②根据查询出来上赛季redis数据,数据库新表名通过mp动态表名插件(本质是一个拦截器,在与mapper数据库接触过程中通过threadlocal更改数据库名)】然后查询数据
面试题 面试官:你在项目中负责积分排行榜功能,说说看你们排行榜怎么设计实现的?
答:我们的排行榜功能分为两部分:一个是当前赛季排行榜,一个是历史排行榜。
因为我们的产品设计是每个月为一个赛季,月初清零积分记录,这样学员就有持续的动力去学习。这就有了赛季的概念,因此也就有了当前赛季榜单和历史榜单的区分,其实现思路也不一样。
首先说当前赛季榜单,我们采用了Redis的SortedSet来实现。member是用户id,score就是当月积分总值。每当用户产生积分行为的时候,获取积分时,就会更新score值。这样Redis就会自动形成榜单了。非常方便且高效。
然后再说历史榜单,历史榜单肯定是保存到数据库了。不过由于数据过多,所以需要对数据做水平拆分,我们目前的思路是按照赛季来拆分,也就是每一个赛季的榜单单独一张表。这样做有几个好处:
拆分数据时比较自然,无需做额外处理
查询数据时往往都是按照赛季来查询,这样一次只需要查一张表,不存在跨表查询问题
因此我们就不需要用到分库分表的插件了,直接在业务层利用MybatisPlus就可以实现动态表名,动态插入了。简单高效。
我们会利用一个定时任务在每月初生成上赛季的榜单表,然后再用一个定时任务读取Redis中的上赛季榜单数据,持久化到数据库中。最后再有一个定时任务清理Redis中的历史数据。
这里要说明一下,这里三个任务是有关联的,之所以让任务分开定义,是为了避免任务耦合。这样在部分任务失败时,可以单独重试,无需所有任务从头重试。
当然,最终我们肯定要确保这三个任务的执行顺序,一定是依次执行的[通过xxlJob分布式调度完成,弥补单体的springTask框架不能顺序执行的毛病]
面试官追问:你们使用Redis的SortedSet来保存榜单数据,如果用户量非常多怎么办?
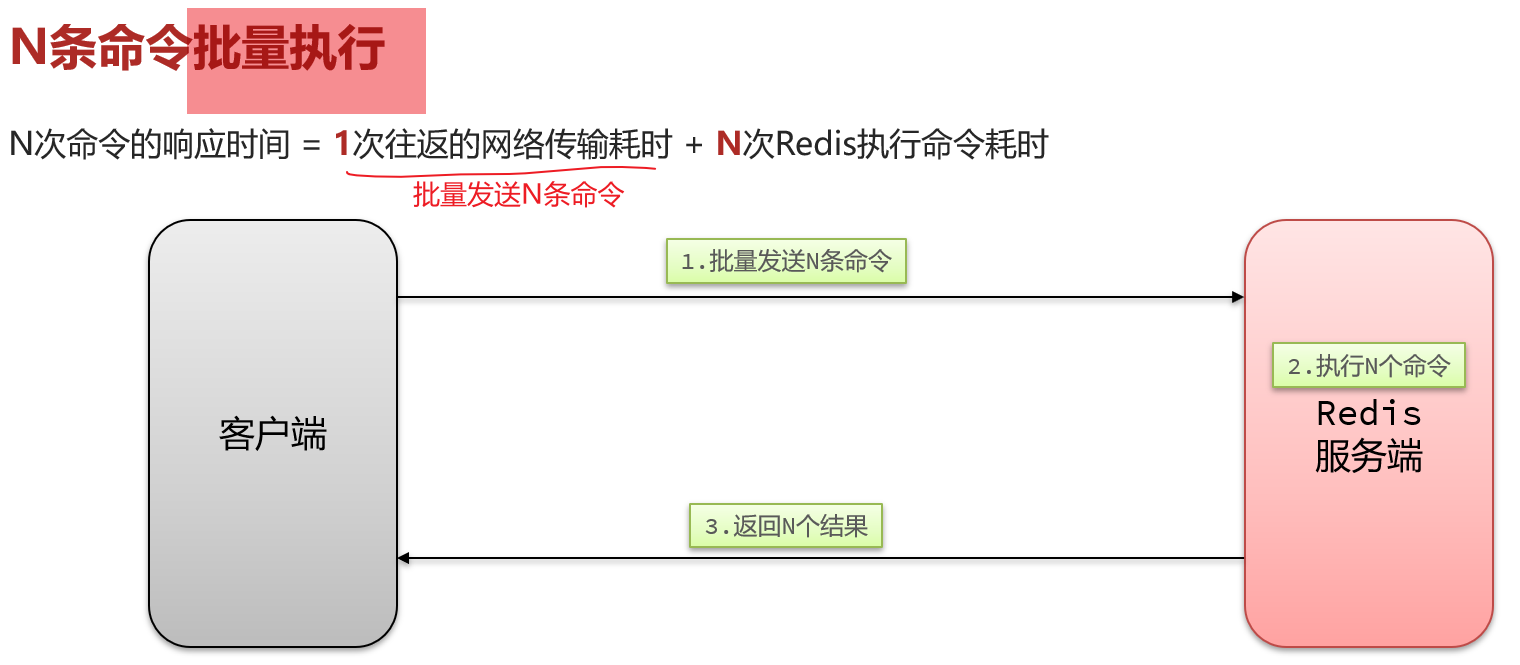
首先Redis的SortedSet底层利用了跳表机制,性能还是非常不错的。即便有百万级别的用户量,利用SortedSet也没什么问题,性能上也能得到保证。在我们的项目用户量下,完全足够。
当系统用户量规模达到数千万,乃至数亿时,我们可以采用分治的思想,将用户数据按照积分范围划分为多个桶。
然后为每个桶创建一个SortedSet类型的key,这样就可以将数据分散,减少单个KEY的数据规模了。
而要计算排名时,只需要按照范围查询出用户积分所在的桶,再累加分值范围比他高的桶的用户数量即可。依然非常简单、高效。
面试官追问:你们使用历史榜单采用的定时任务框架是哪个?处理数百万的榜单数据时任务是如何分片的?你们是如何确保多个任务依次执行的呢?
答:我们采用的是XXL-JOB框架。
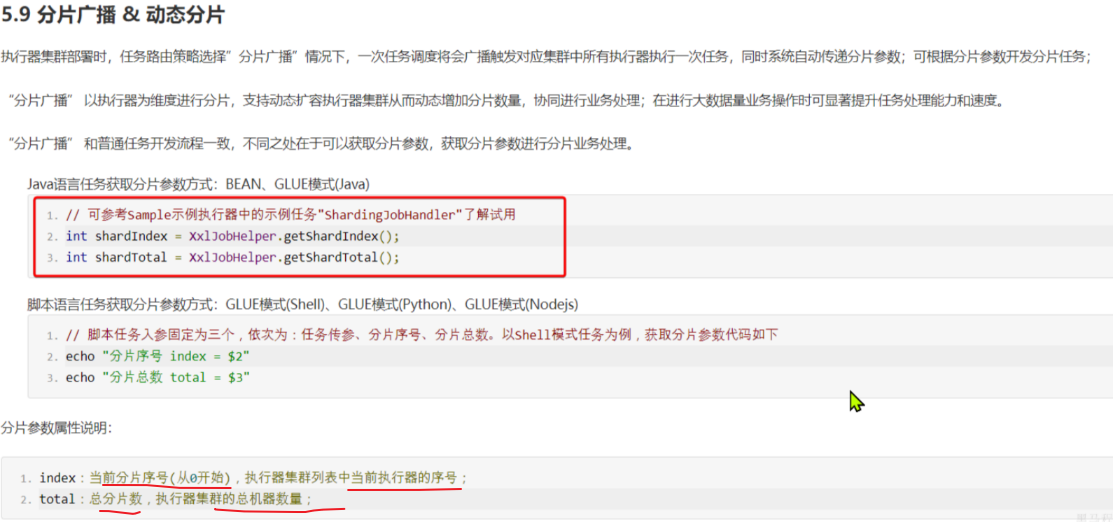
XXL-JOB自带任务分片广播机制,每一个任务执行器都能通过API得到自己的分片编号、总分片数量。在做榜单数据批处理时,我们是按照分页查询的方式:
每个执行器的读取的起始页都是自己的分片编号+1,例如第一个执行器,其起始页就是1,第二个执行器,其起始页就是2,以此类推
然后不是逐页查询,而是有一个页的跨度,跨度值就是分片总数量。例如分了3片,那么跨度就是3
此时,第一个分片处理的数据就是第1、4、7、10、13等几页数据,第二个分片处理的就是第2、5、8、11、14等页的数据,第三个分片处理的就是第3、6、9、12、15等页的数据。
这样就能确保所有数据都会被处理,而且每一个执行器都执行的是不同的数据了。
最后,要确保多个任务的执行顺序,可以利用XXL-JOB中的子任务功能。比如有任务A、B、C,要按照字母顺序依次执行,我们就可以将C设置为B的子任务,再将B设置为A的子任务。然后给A设置一个触发器。
这样,当A触发时,就会依次执行这三个任务了。