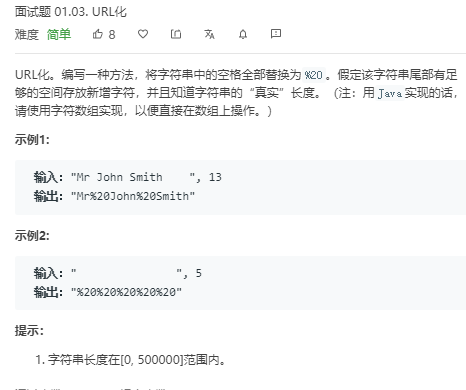
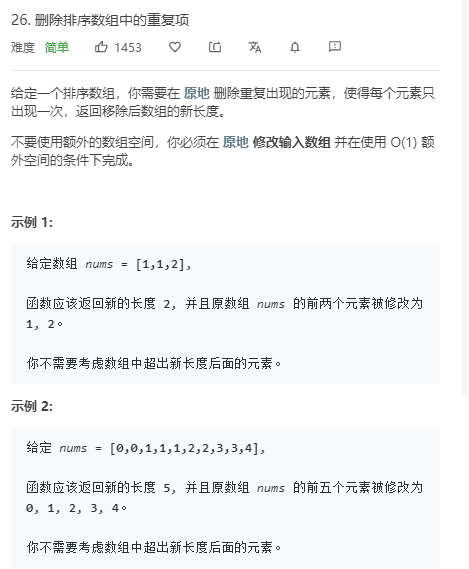
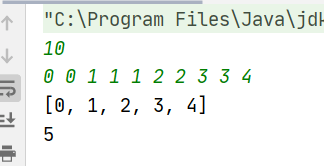
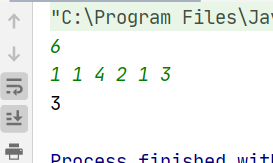
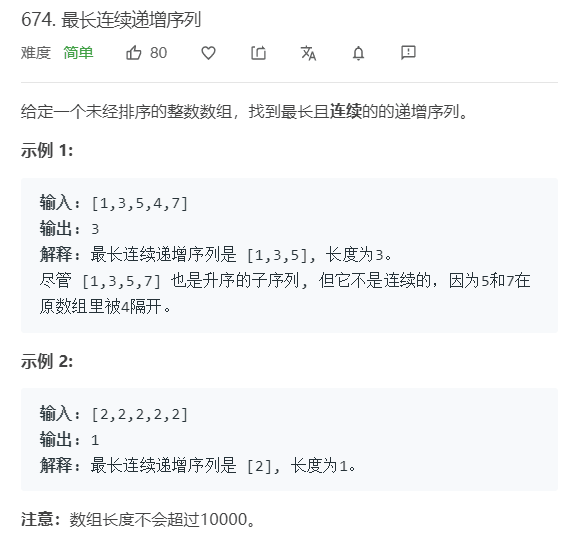
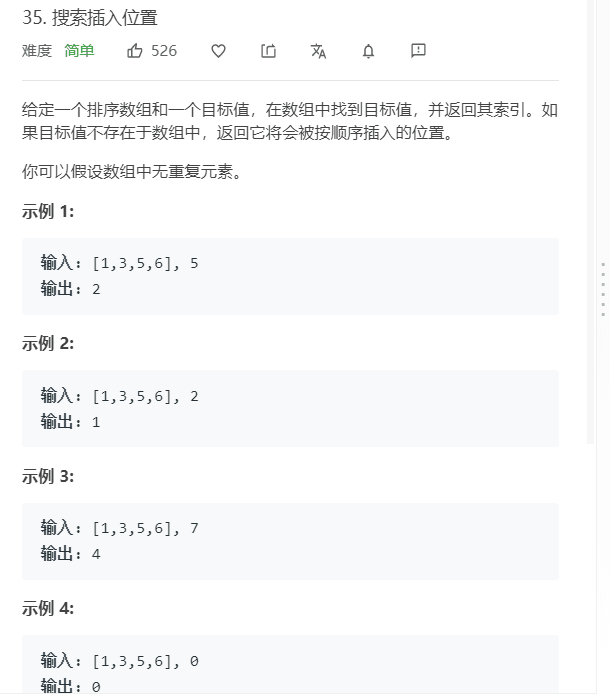
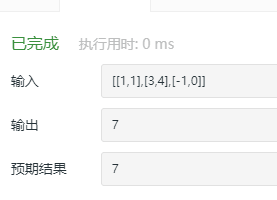
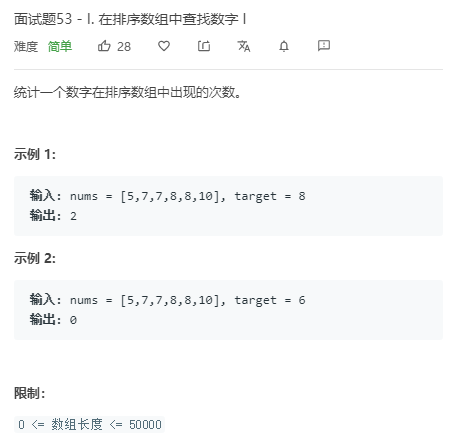
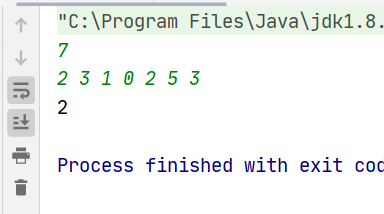
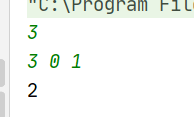
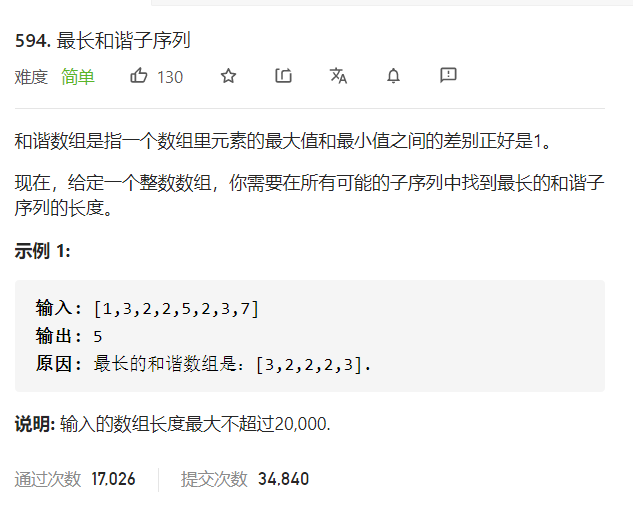
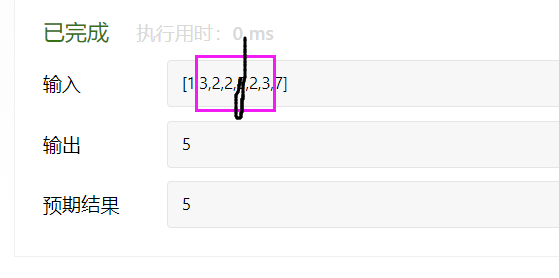
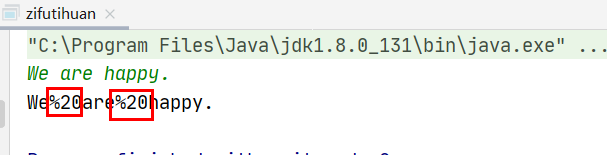
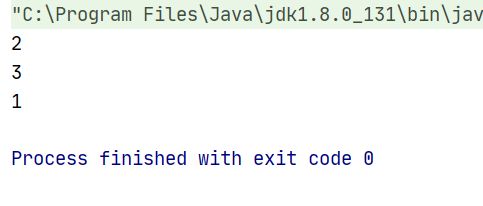
public class URLhua { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.nextLine(); int length=input.nextInt(); System.out.println(replaceSpaces(s,length)); }
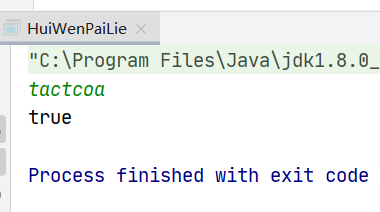
public class HuiWenPaiLie { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.next(); System.out.println(canPermutePalindrome(s)); }
public static boolean canPermutePalindrome(String s) { Set<Character> set = new HashSet<>(); for(char c:s.toCharArray()) { if (!set.add(c)) { //如果c字符不能添加就说明是重复出现 set.remove(c); //移除第一次添加的c字符 } } return set.size()<=1; //看最后是不是只有那个奇数的一个/全是偶数的被移除了 }
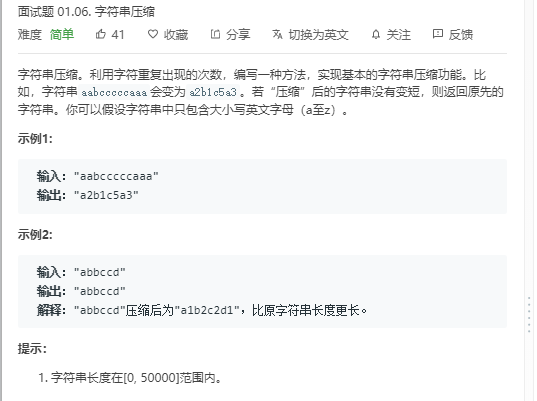
public class StringYaSuo { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.nextLine(); System.out.println(compressString(s));
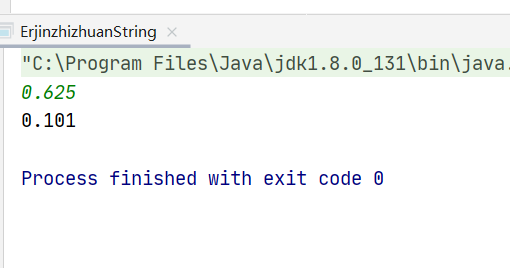
public class ErjinzhizhuanString { public static void main(String[] args) { Scanner input = new Scanner(System.in); Double num=input.nextDouble(); System.out.println(printBin(num)); }
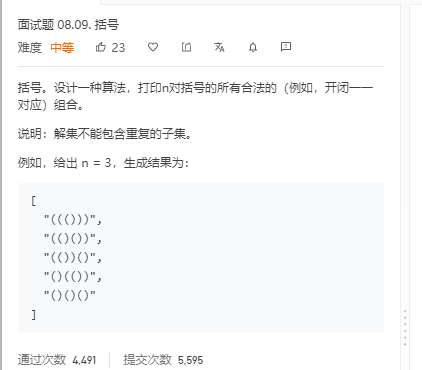
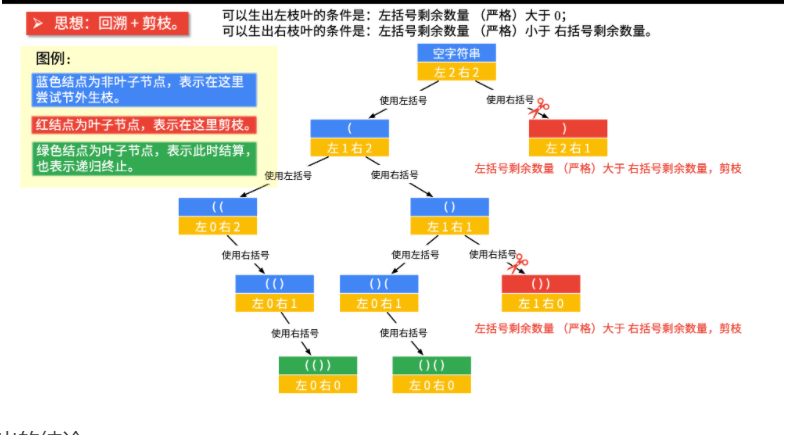
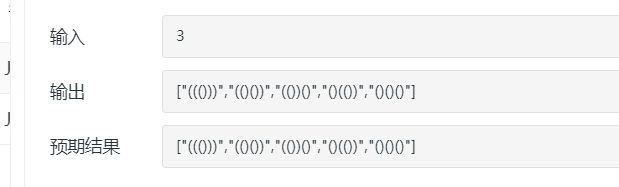
public class KuoHao { public static void main(String[] args) { Scanner input = new Scanner(System.in); int n=input.nextInt(); System.out.println(generateParenthesis(n)); //调用方法 }
public static List<String> generateParenthesis(int n) { List<String> res=new ArrayList(); //特定判断 if (n == 0) { return res; } //执行深度优先遍历 dfs("",n,n,res);
return res; }
/** * @param curStr 当前递归得到的结果 * @param left 左括号还有几个可以使用 * @param right 右括号还有几个可以使用 * @param res 结果集 */ private static void dfs(String curStr, int left, int right, List<String> res) { //因为每一次尝试,都使用新的字符串变量,所以无需回溯 if(left==0&&right==0){ res.add(curStr); // 在递归终止的时候,直接把它添加到结果集即可 return ; //void不需要返回 }
// 剪枝(左<右就符合左边用的多这样不需要剪枝) if (left > right) { return; //void不需要返回 }
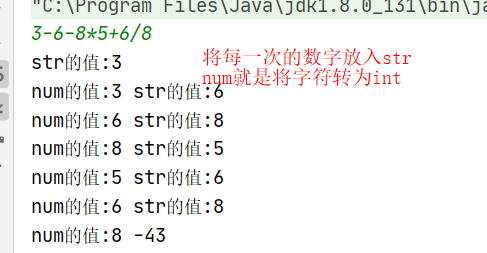
public class JiSuanQi { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.next(); System.out.println(calculate(s)); }
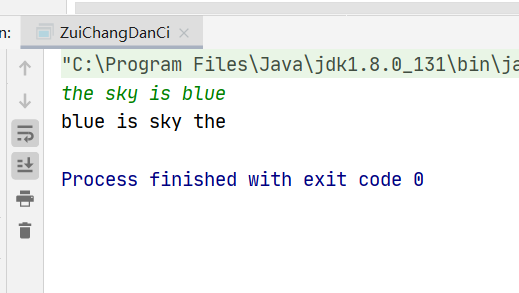
public class ZuiChangDanCi { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.nextLine(); System.out.println(reverseWords(s)); }
public static String reverseWords(String s) { String[] strs = s.trim().split(" "); // 删除首尾空格,分割字符串 StringBuilder res = new StringBuilder(); for(int i = strs.length - 1; i >= 0; i--) { // 倒序遍历单词列表 if(strs[i].equals("")){ continue; // 遇到空单词则跳过 } res.append(strs[i]+" "); // 将单词拼接至 StringBuilder } return res.toString().trim(); // 转化为字符串,删除尾部空格,并返回 }
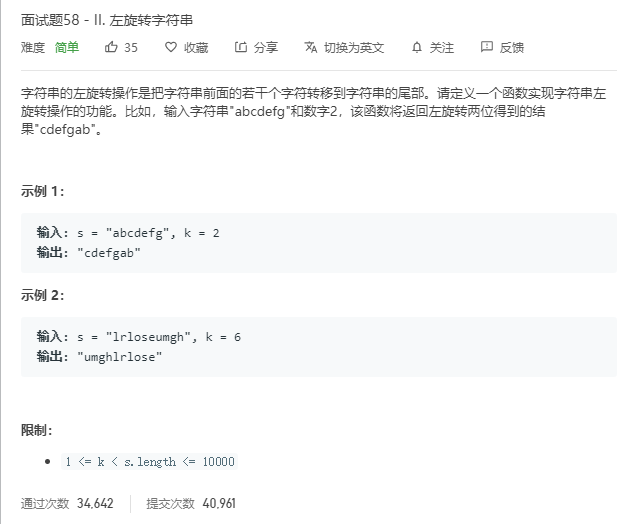
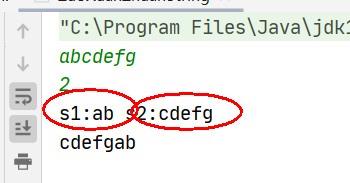
public class ZuoXuanZhuanString { public static void main(String[] args) { Scanner input = new Scanner(System.in); String s=input.nextLine(); int n=input.nextInt(); System.out.println(reverseLeftWords(s,n)); }
public class Main { public static void main(String[] args) { Scanner input=new Scanner(System.in); String s=input.next(); int n=input.nextInt(); System.out.println(convert(s,n)); }
public static String convert(String s, int numRows) { if(numRows<2){ //如果是0行或者1行 就直接输出s即可 return s; } //存储每一行的字符(要拼接所以要用StringBuilder类) List<StringBuilder> rows = new ArrayList<StringBuilder>(); //根据行数每行添加一个StringBuilder for(int i=0;i<numRows;i++){ rows.add(new StringBuilder()); //每一行都有一个 } int i=0; int flag=-1; for(char c:s.toCharArray()){ rows.get(i).append(c); //对应行添加进去字符 if(i==0||i==numRows-1){ flag=-flag; //到了拐角要变换flag } i=i+flag; //1的话就是往下加 -1的话就是往上加 } StringBuilder res = new StringBuilder(); //新建接住结果 for(StringBuilder row:rows) { res.append(row); //添加每一行的结果集合 } return res.toString();//最后记得转字符串 }
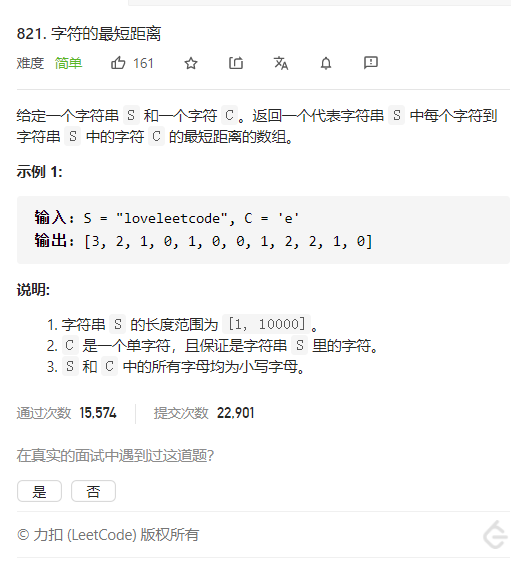
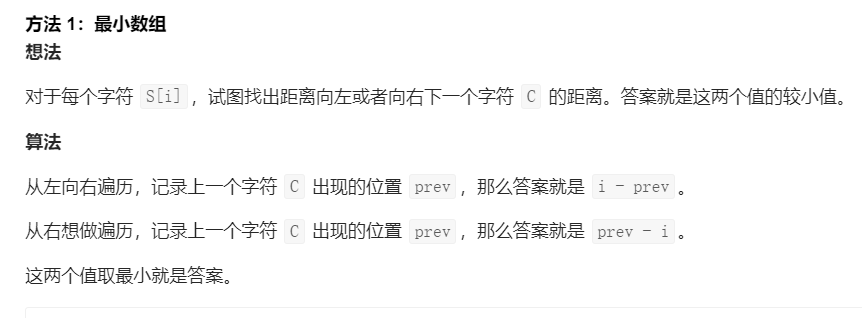
public class Main { public static void main(String[] args) { Scanner input = new Scanner(System.in); System.out.println(Arrays.toString(shortestToChar("loveleetcode",'e'))); }
public static int[] shortestToChar(String S, char C) { int N = S.length(); //获取字符串长度 int[] ans = new int[N]; //返回结果的ans数组
int prev=Integer.MIN_VALUE/2; //先取负数 //从左往右取结果 for (int i = 0; i < N; ++i) { //正序 if (S.charAt(i) == C) prev = i; ans[i] = i - prev; //找到相近的字符的距离 } //从右往左取结果 prev = Integer.MAX_VALUE / 2; //先取正数 for (int i = N-1; i >= 0; --i) { //倒序 if (S.charAt(i) == C) prev = i; ans[i] = Math.min(ans[i], prev - i); //找到相近的字符的距离 } return ans; //返回ans数组 }
}
结果
删除回文子序列(因为只有a和b字符)
题目
分析
代码
1 2 3 4 5 6 7 8 9 10
public int removePalindromeSub(String s) { if ("".equals(s)) { return 0; //空字符串 } if (s.equals(new StringBuilder(s).reverse().toString())){ return 1; //本身就是回文串 } return 2; //其他情况就是一次性删除所有a 然后删除b }
结果
字符串的最大公因子(辗转相除法)
题目
分析
使用辗转相除法得到最大公因子!!!
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
public String gcdOfStrings(String str1, String str2) { // 假设str1是N个x,str2是M个x,那么str1+str2肯定是等于str2+str1的。 if (!(str1 + str2).equals(str2 + str1)) { return ""; } int l1=str1.length(); int l2=str2.length(); // 辗转相除法求gcd。 return str1.substring(0, gcd(l1, l2)); //截取str1的部分字符串 }
public static int gcd(int a, int b) { return b == 0? a: gcd(b, a % b); //b是0就返回a b不是0就返回a%b }
public String reverseOnlyLetters(String S) { Stack<Character> letters = new Stack(); for (char c: S.toCharArray()) if (Character.isLetter(c)) letters.push(c); //所有数字反序压栈
StringBuilder ans = new StringBuilder();
//第二次再次遍历 for (char c: S.toCharArray()) { if (Character.isLetter(c)) ans.append(letters.pop()); //如果当前位是字母 就出栈 刚好是反序 else ans.append(c); //特殊位置继续放入当前位置 }
public class LiangShuHe { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); int[] a=new int[n]; for(int i=0;i<n;i++){ a[i]=input.nextInt(); } int m=input.nextInt(); int[] c=twoSum(a,m); //接结果数组 for(int i=0;i<2;i++){ System.out.print(c[i]+" "); }
}
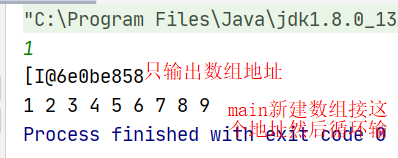
public static int[] twoSum(int[] numbers, int target) { if(numbers==null){ return null; } int left=0; //左指针 int right=numbers.length-1; //右指针 while(left<right){ int sum=numbers[left]+numbers[right]; //两个指针所在数组的值 if(sum==target){ return new int[]{left+1,right+1}; //直接返回一个新建数组 值就是两个下标 }else if(sum<target){ //左边的太小 左指针右移 left++; } else{ //右边的太大 右指针左移 right--; } } return null; }
}
结果
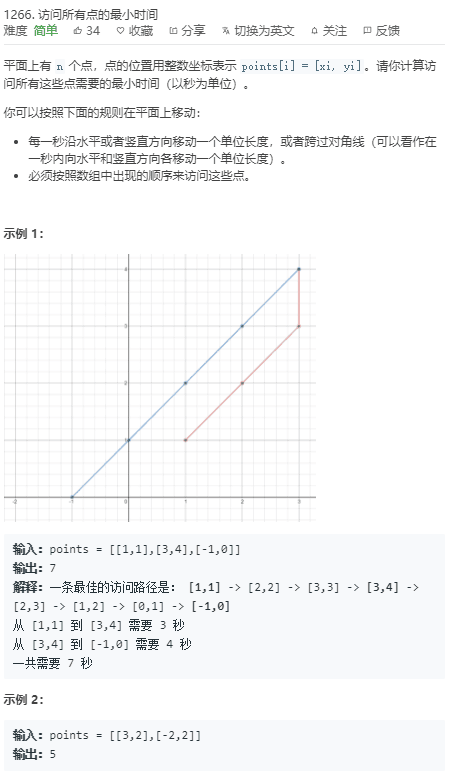
1266.访问所有点的最小时间(切比雪夫距离)
题目
分析
其实就是dx和dy的最大值之和
代码
1 2 3 4 5 6 7 8 9
public int minTimeToVisitAllPoints(int[][] points) { int res=0; //最后的距离 for(int i=1;i<points.length;++i){ int xMinus=Math.abs(points[i][0]-points[i-1][0]); int yMinus=Math.abs(points[i][1]-points[i-1][1]); res+=(xMinus>yMinus?xMinus:yMinus); //加两坐标差最大值 } return res; }
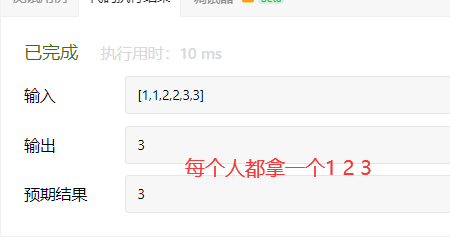
public class ChaZhaoShuZi { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); int[] a=new int[n]; for(int i=0;i<n;i++){ a[i]=input.nextInt(); } int m=input.nextInt(); System.out.println(search(a,m)); }
public static int search(int[] nums, int target) { int left=0; int right=nums.length-1; //1. 找右边界 while(left<=right){ int middle=(left+right)/2; if (nums[middle]<=target){ //一直找最右边的数字!!!!!! left=middle+1; //在右边 }else{ right=middle-1; //在左边 } } int righter=left;
//初始化左右指针 left=0; right=nums.length-1;
//2. 找左边界 while(left<=right){ int middle=(left+right)/2; if (nums[middle]>=target){ //一直找最左边的数字!!!!!!! right=middle-1; //在右边 }else{ left=middle+1; //在左边 } } int lefter=right; return righter-lefter-1; //返回出现区间的大小 }
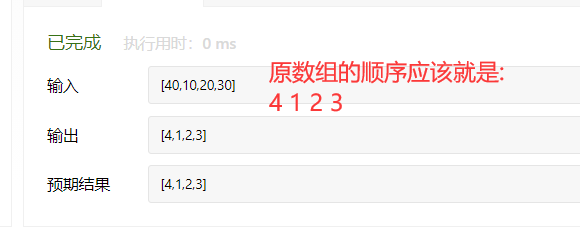
public class MoShuSuoYin { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); int[] a=new int[n]; for(int i=0;i<n;i++){ a[i]=input.nextInt(); } System.out.println(findMagicIndex(a)); }
public static int findMagicIndex(int[] nums) { int left = 0, right = nums.length; //左右指针 while (left < right) { int mid = left + (right - left) / 2; if (nums[mid] != mid) //左边有缺少的数字 { if (nums[mid] >= 0) { right = mid; } else { left = mid + 1; //在右边 } } else { left = mid + 1; //右边有缺少的数字 } } return left -1; }
public class LingJuZheng { public static void main(String[] args) { Scanner input = new Scanner(System.in); int m = input.nextInt(); int n = input.nextInt(); int[][] a = new int[m][n]; for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++){ a[i][j] = input.nextInt(); } } setZeroes(a); //调用方法进行清0 for (int i = 0; i < m; i++) { for (int j = 0; j < n; j++){ System.out.print(a[i][j]+" "); //输出数组 } System.out.println(); }
}
public static void setZeroes(int[][] matrix) { boolean[] line = new boolean[matrix.length]; //设置两个存放行和列的布尔数组 boolean[] column = new boolean[matrix[0].length]; //1.找出要清零的行列 for (int i = 0; i < matrix.length; i++) { for (int j = 0; j < matrix[0].length; j++) { if (matrix[i][j] == 0) { line[i] = true; //存放要清0的行 column[j] = true; //存放要清0的列 } } }
//2.开始对行清零 for (int i = 0; i < matrix.length; i++) { if (line[i]) { //行存在 for (int j = 0; j < matrix[0].length; j++) { matrix[i][j] = 0; //所在列清0 } } }
//3.开始对列清零 for (int i = 0; i < matrix[0].length; i++) { if (column[i]) { //列存在 for (int j = 0; j < matrix.length; j++) { matrix[j][i] = 0; //所在行清0 } } }
}
}
结果
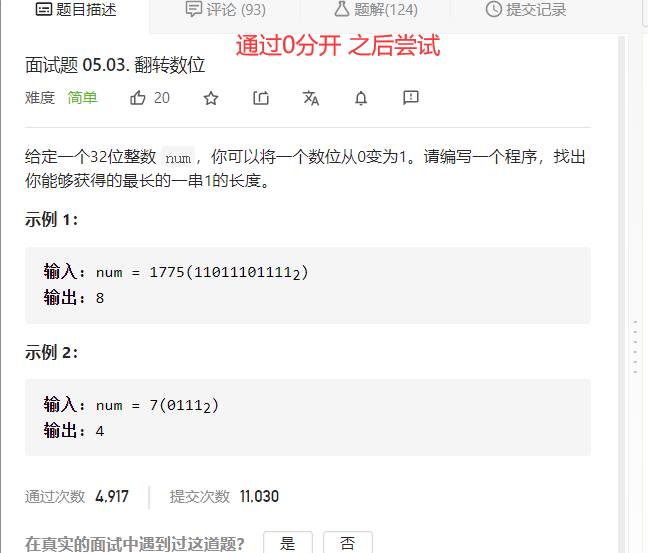
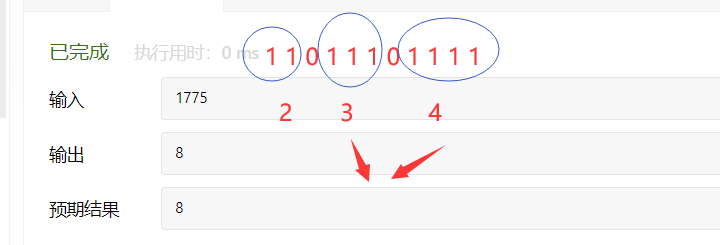
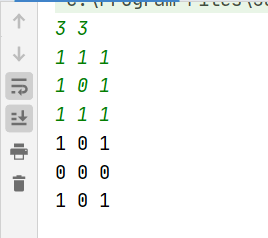
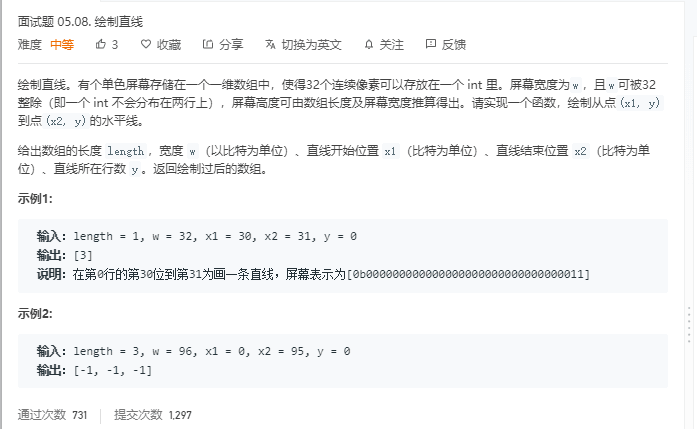
面试05.08绘制直线(位运算)
题目
分析
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14
class Solution { public int[] drawLine(int length, int w, int x1, int x2, int y) { int[] ans=new int[length]; int low=(y*w+x1)/32; int high=(y*w+x2)/32; for(int i=low;i<=high;i++){ ans[i]=-1; } ans[low]=ans[low]>>>x1%32; ans[high]=ans[high]&Integer.MIN_VALUE>> x2 % 32; return ans;
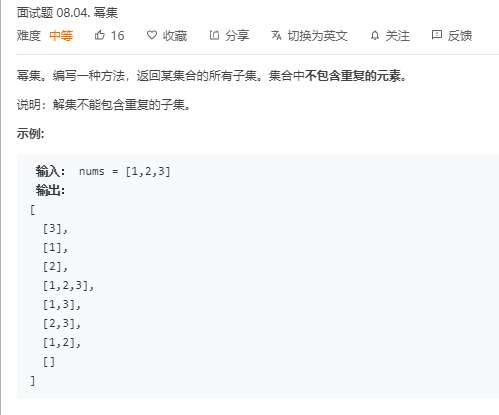
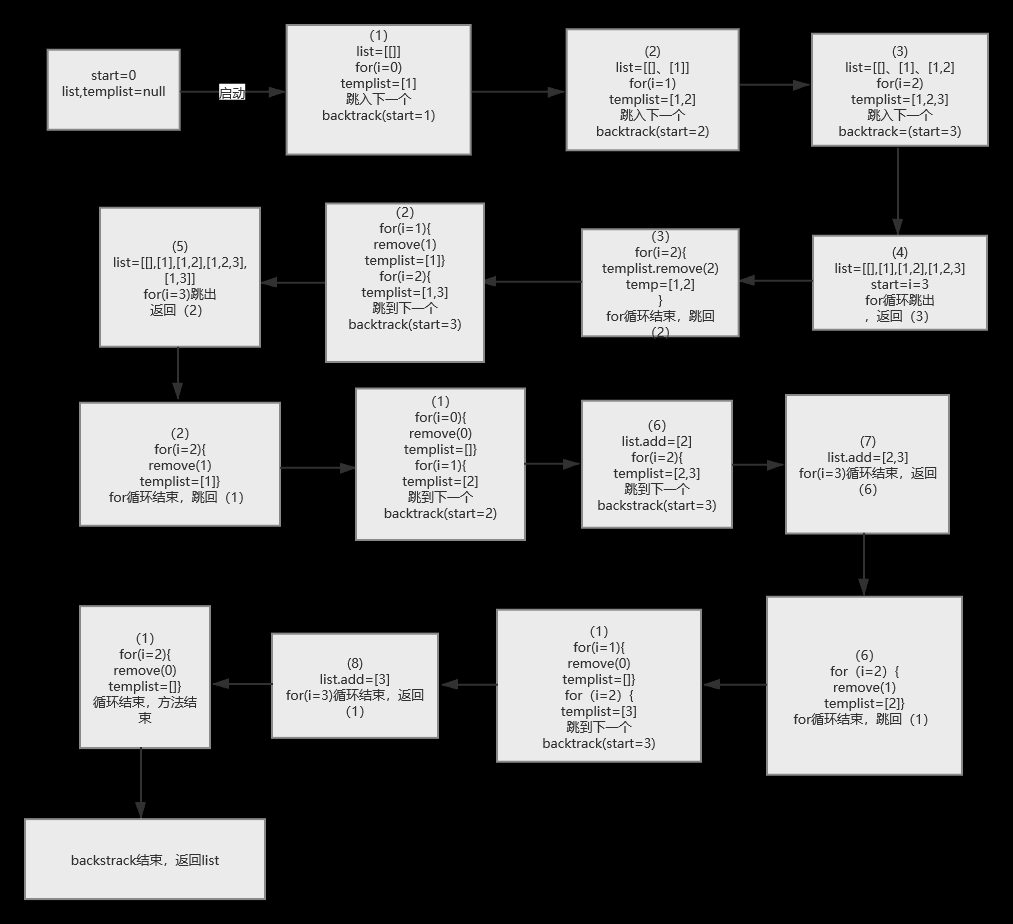
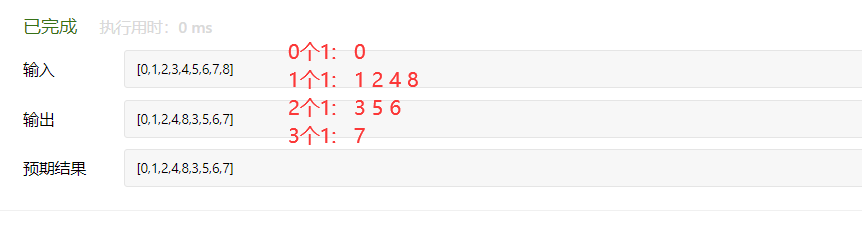
public class MiDeng { public static void main(String[] args) { Scanner input = new Scanner(System.in); int n = input.nextInt(); int[] a=new int[n]; for(int i=0;i<n;i++){ a[i]=input.nextInt(); } System.out.println(subsets(a)); }
public static List<List<Integer>> subsets(int[] nums) { //结果集合 List<List<Integer>> list = new ArrayList(); //回溯方法 backtrack(list,new ArrayList<>(),nums,0); //返回list集合 return list; }
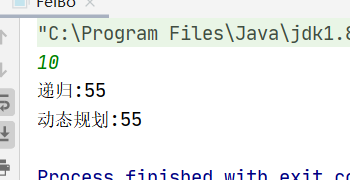
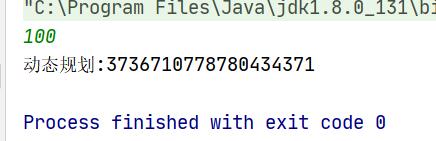
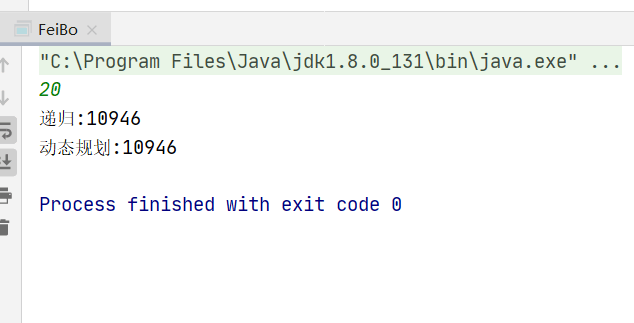
public class FeiBo { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); //System.out.println("递归:"+digui(n)); //递归 System.out.println("动态规划:"+dongtai(n)); //动态代理 }
//递归 public static int digui(int n){ if(n<=0){ return 0; } if(n==1){ return 1; } return digui(n-1)+digui(n-2); //从第二项开始依次递增 }
//动态规划 public static long dongtai(int n){ if(n<=0){ return 0; } if(n<=2){ return 1; } long a=1; long b=1; long c=2; for(int i=2;i<n;i++){ //依次往后挪动 c=a+b; //第三个数 a=b; //原来的b成为下一轮的a b=c; //原来的c成为下一轮的b } return c; }
public class QingWa { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); System.out.println("递归:"+tiao(n)); //递归 System.out.println("动态规划:"+tiaoer(n)); //动态规划 }
//递归实现 public static int tiao(int n) { if(n<=1){ return 1; // f(n)=1 } return 2*tiao(n-1); // f(n)=2*f(n-1) }
//动态规划 public static int tiaoer(int n) { if(n<=0){ return 0; // f(0)=0 } if(n==1){ return 1; // f(1)=1 } int a=1; int b=1; for(int i=1;i<n;i++){ b=a*2; //当前的值是上一个的二倍 a=b; //计算出来的值当做下一轮的数 } return b; }
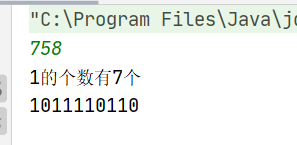
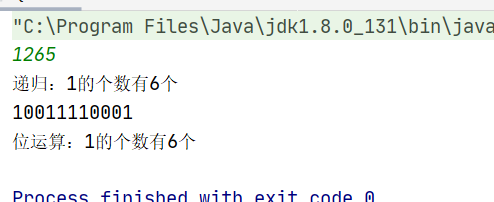
public class QiuYi { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); System.out.println("一共有:"+qiu(n)); //1的个数 System.out.println(qiuer(n)); //每一位的值 }
//求出有多少个1 private static long qiu(int n) { long sum=0; //计数器 int m=1; //每一位的值 while(n!=0){ m=n%2; if(m==1){ sum++; //如果是1就计数器加1 } n=n/2; } return sum; }
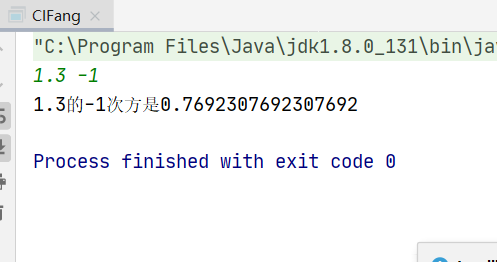
public class CIFang { public static void main(String[] args) { Scanner input=new Scanner(System.in); double n=input.nextDouble(); int m=input.nextInt(); System.out.println(n+"的"+m+"次方是"+cifang(n,m)); }
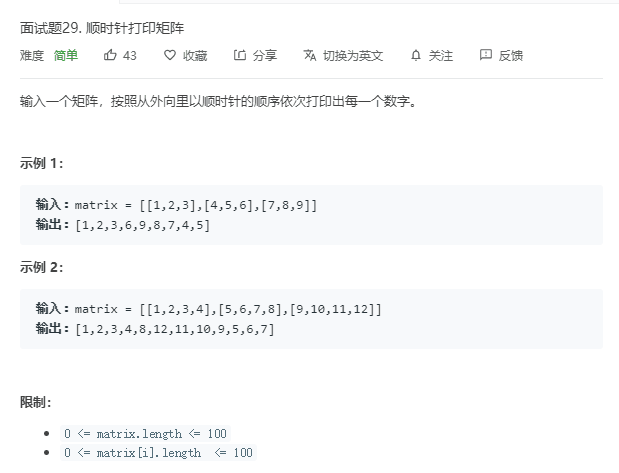
public class ShunXu { public static void main(String[] args) { Scanner input=new Scanner(System.in); int n=input.nextInt(); //输入二维数组的行和列 int m=input.nextInt(); int[][] a=new int[n][m]; for(int i=0;i<n;i++){ for(int j=0;j<m;j++){ a[i][j]=input.nextInt(); //输入要判断的数组元素 } }
}
public static ArrayList<Integer> printMatrix(int [][] matrix) { ArrayList<Integer> list=new ArrayList<Integer>(); //定义arraylist集合 底层是数组 int row=matrix.length; //行 int col=matrix[0].length; //列 int left=0; int right=col-1; int top=0; int bottom=row-1; return list; }
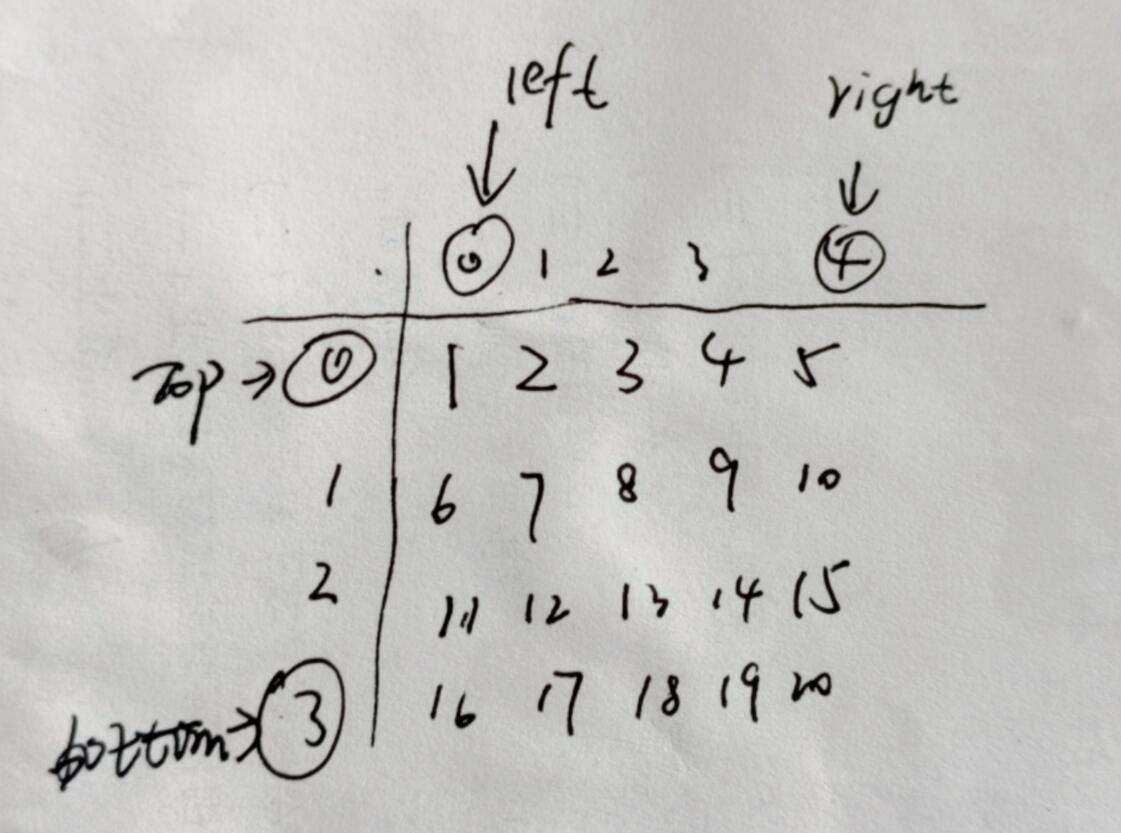
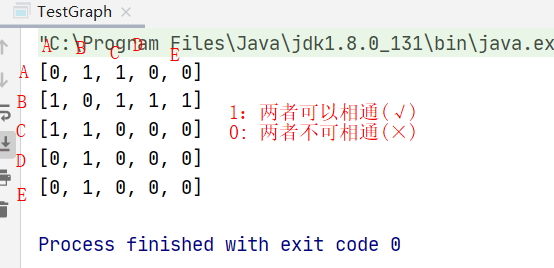
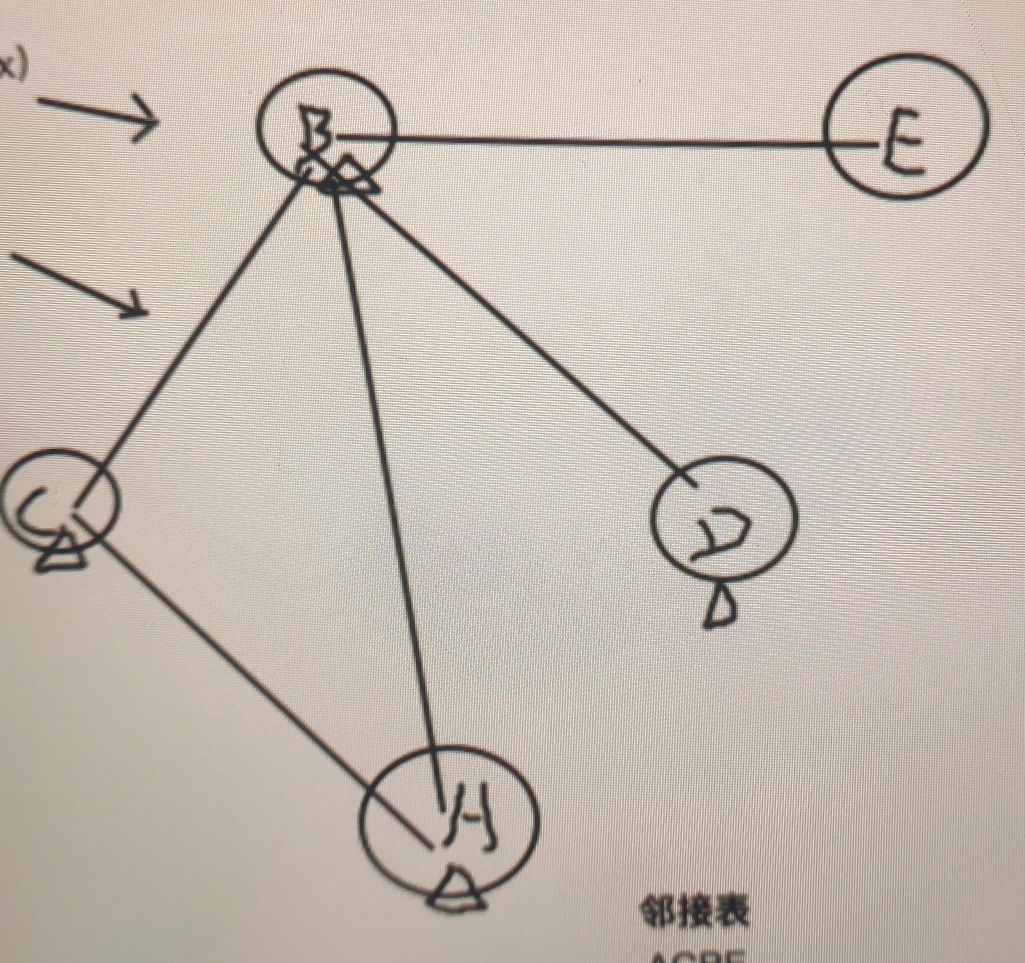
1. 栈先放入A顶点 (栈内:A)
2. 搜索邻接矩阵中第一行A顶点可以到达哪个顶点
3. 栈再放入B顶点 (栈内:B A)
4. 搜索邻接矩阵中第二行B顶点可以到达哪个顶点
5. 栈再放入C顶点 (栈内:C B A)
6. 搜索邻接矩阵中第三行C顶点可以到达哪个顶点
7. 没有可以到达的顶点因此C顶点从栈弹出 (栈内:B A) --已经搜索到的C弹出(C)
8. 返回到栈顶B顶点查看还可以到达哪个顶点
9. 栈再放入D顶点 (栈内: D B A)
10. 搜索邻接矩阵中第四行D顶点可以到达哪个顶点
11. 没有可以到达的顶点因此D顶点从栈弹出 (栈内:B A) --已经搜索到的D弹出(C D)
12. 返回到栈顶B顶点查看还可以到达哪个顶点
13. 栈再放入E顶点 (栈内:E B A)
14. 搜索邻接矩阵中第五行E顶点可以到达哪个顶点
15. 没有可以到达的顶点因此E顶点从栈弹出 (栈内:B A) --已经搜索到的E弹出(C D E)
16. 五个顶点都被遍历过后弹出栈内元素(先出B后出A)
17. 最终遍历顺序是: A B E D C
广度优先搜索算法(BFS)
从当前顶点一条路走到死,走死顶点就出队。让屁股后面的顶点继续走到死
1. 队列先放入A顶点 (队列内:A)
2. 搜索邻接矩阵中第一行A顶点可以到达哪个顶点
3. 队列再放入B顶点 (队列内:B A)
4. 搜索邻接矩阵中第一行A顶点还可以到达哪个顶点
5. 队列再放入C顶点 (队列内:C B A)
6. 现在A没有可以到达的顶点因此A顶点出队(队列内:C B) --已经搜索到的A出队(A)
7. 现在搜索B还可以到达哪些顶点
8. 队列再放入D顶点 (队列内:D C B)
9. 在搜索B还可以到达哪些顶点
10. 队列再放入E顶点 (队列内:E D C B)
11. 五个顶点都被遍历过后弹出栈顶元素(先出B后出C然后D最后E)
12. 最终遍历顺序是: A B C D E
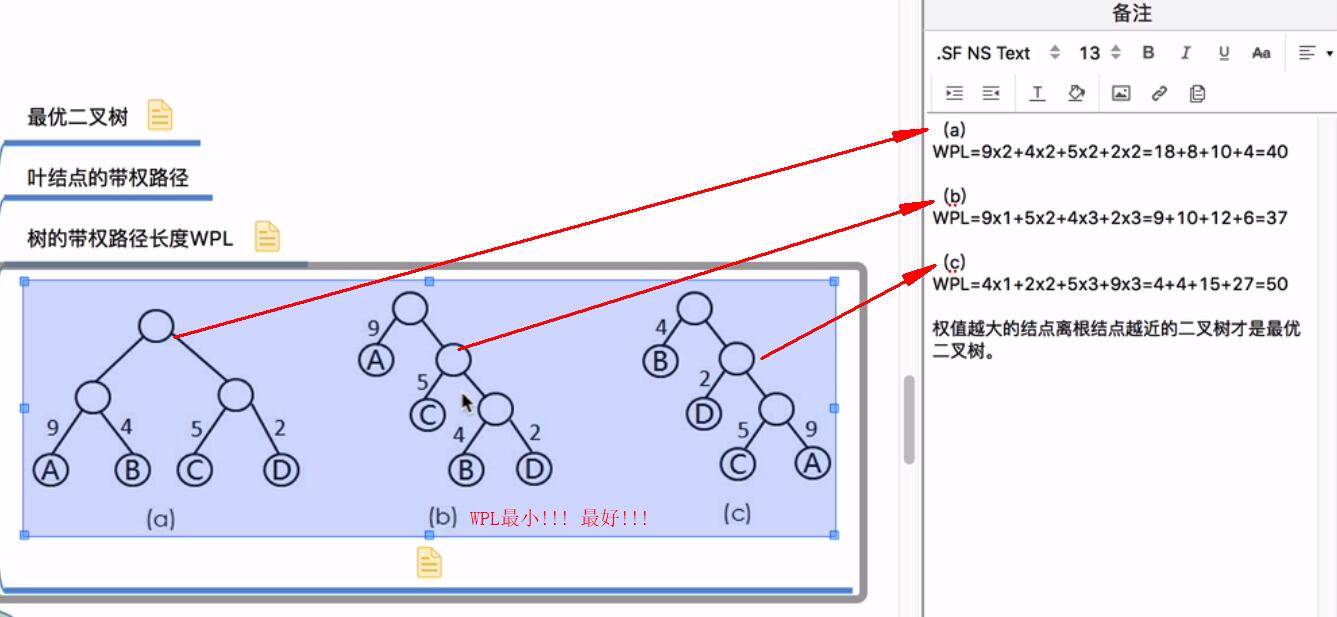
public class Test { public static void main(String[] args) { int[] arr=new int[]{3,7,8,29,5,11,23,14}; System.out.println("原来的数组: "+Arrays.toString(arr)); //输出原来的数组 Node node=createHuffmanTree(arr); //调用方法 }
public static void main(String[] args) { //输入一个叫msg的字符串 让他使用哈夫曼编码 String msg="can you can a can as a can canner can a can."; byte[] bytes=msg.getBytes(); //进行哈夫曼编码压缩 byte[] b=huffmanZip(bytes); System.out.println("压缩前"+bytes.length); System.out.println("压缩后"+b.length); }
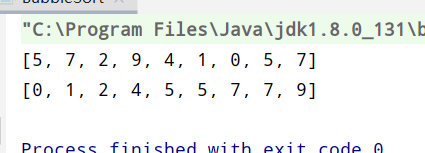
public class BubbleSort { public static void main(String[] args){ int []arr=new int[]{5,7,2,9,4,1,0,5,7}; System.out.println(Arrays.toString(arr)); //先输出之前的数组 maopao(arr) ; System.out.println(Arrays.toString(arr)); //输出排序之后的数组 }
public class QuickSort { public static void main(String[] args) { int []arr=new int[]{5,7,2,9,4,1,0,5,7}; System.out.println(Arrays.toString(arr)); //输出之前的数组 kuaisu(arr,0,arr.length-1); //开头和结尾相当于指针 System.out.println(Arrays.toString(arr)); //输出排序之后的数组 }
public static void kuaisu(int[] arr,int start,int end){ //传入数组和前后两个参数 if(start<end){ //如果左边和右边冲突就是快速排序的结束条件 //将第一个数作为标准数 int biao=arr[start]; //需要排序的下标 int low=start; int high=end;
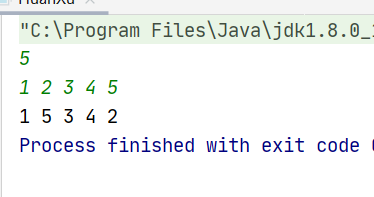
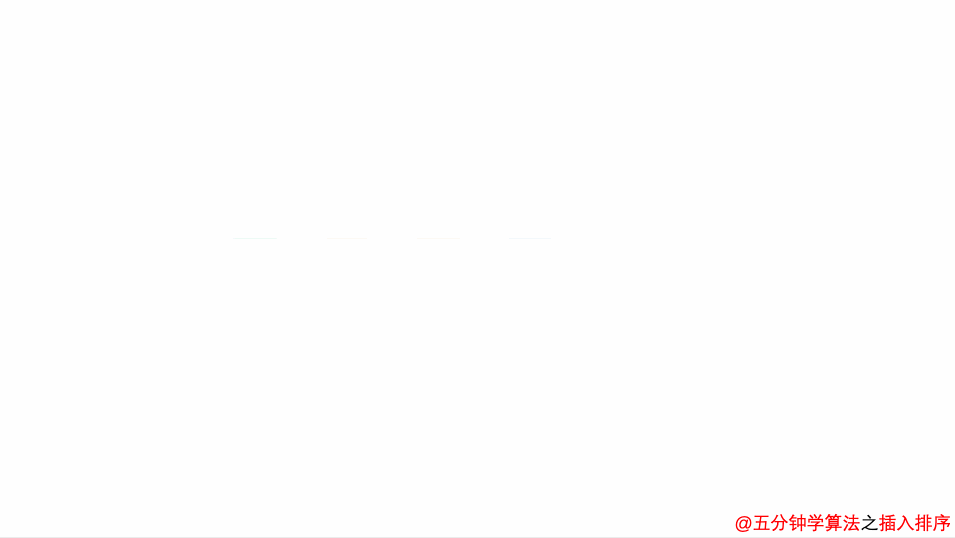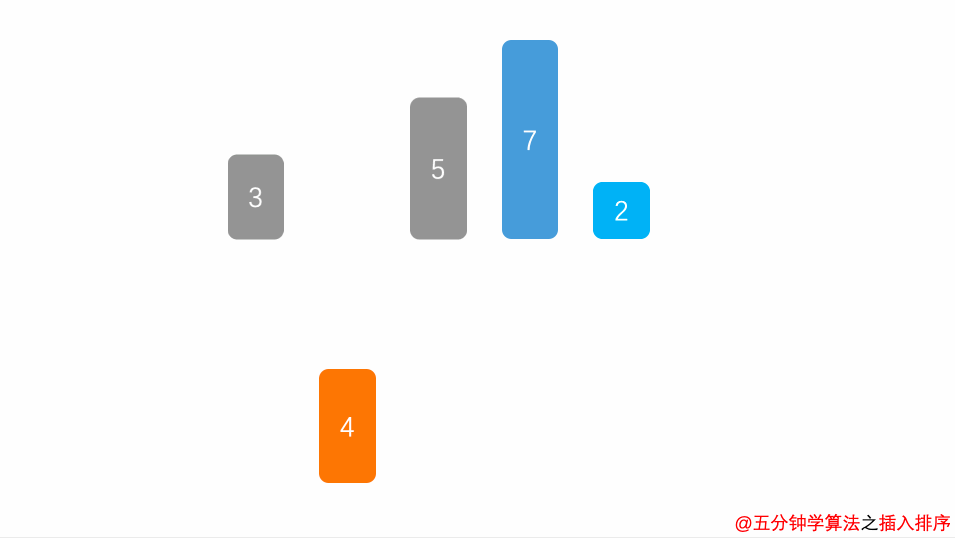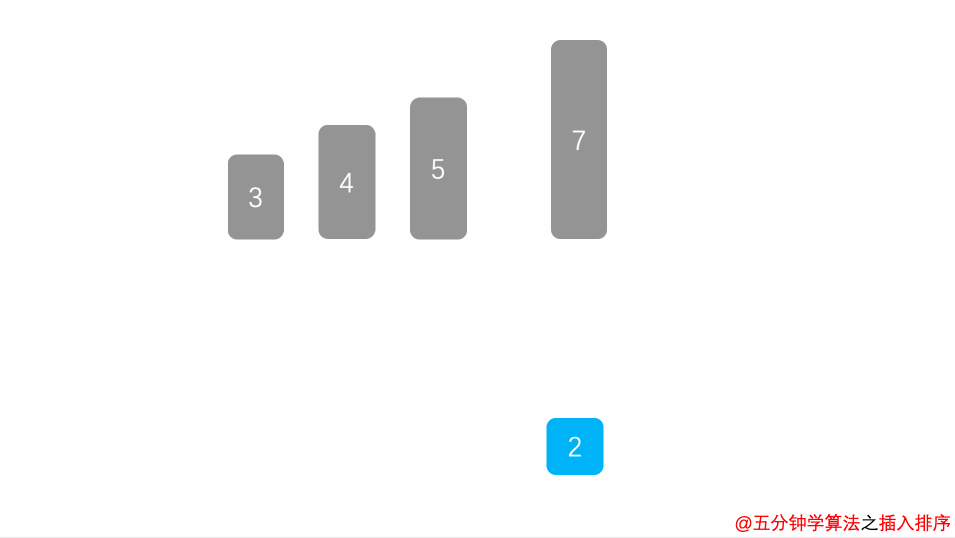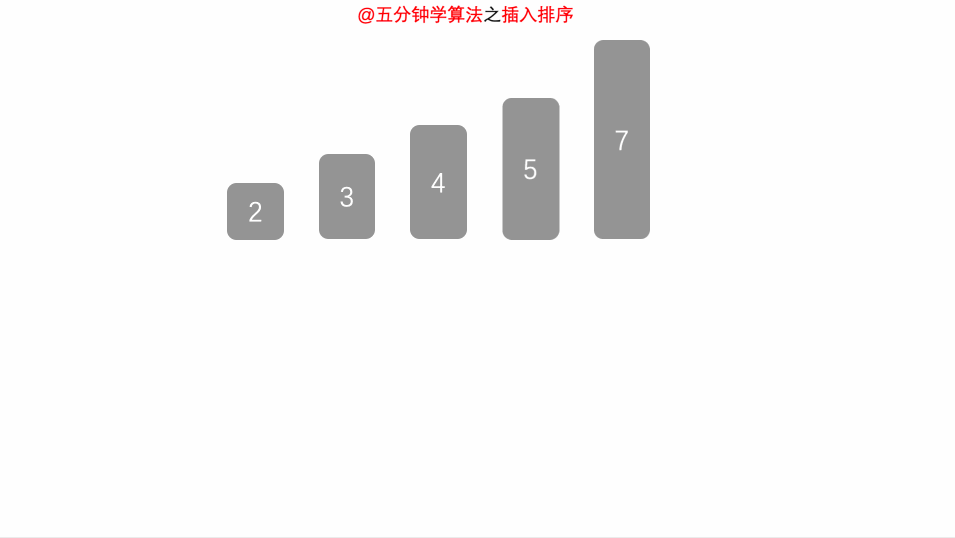
public class Main { public static void main(String[] args) { Scanner input = new Scanner(System.in); //int n=input.nextInt(); int[] a=new int[]{1,5,3,6,9,4,11,87,23}; find(a); //调用方法返回结果 System.out.println(Arrays.toString(a)); }
public static void find(int[] a){ for(int i=1;i<a.length;i++){ //从第二位开始遍历 int temp=a[i]; //将要插入的数字存放到temp里面 int flag; //定义flag下标 因为for循环外面还要用 for(flag=i-1;flag>=0&&a[flag]>temp;flag--){ //找0到i-1位置遍历 a[flag+1]=a[flag]; //只有满足前面比要插入的数字大 才让他往后挪动 } a[flag+1]=temp; //最后flag通过for会给一个值 然后将要插入的数字插入位置 } }
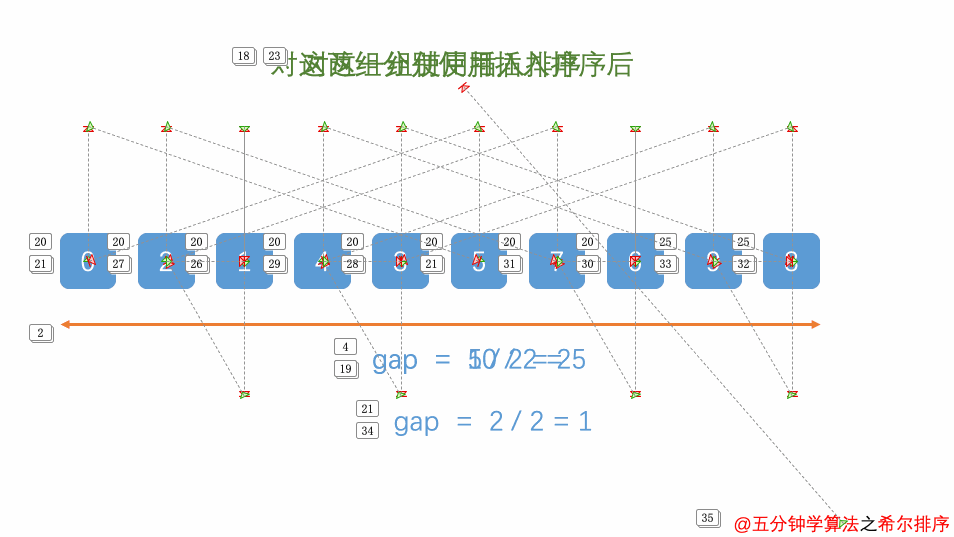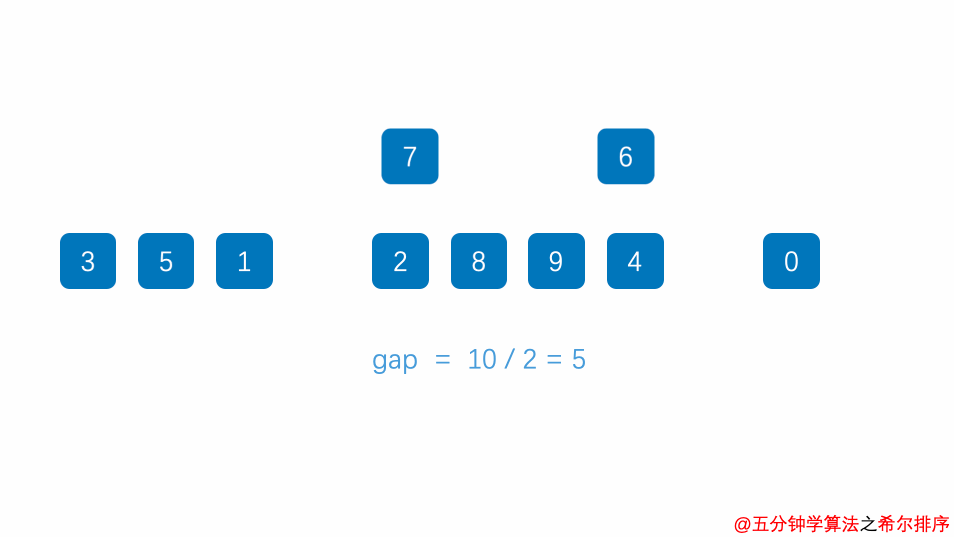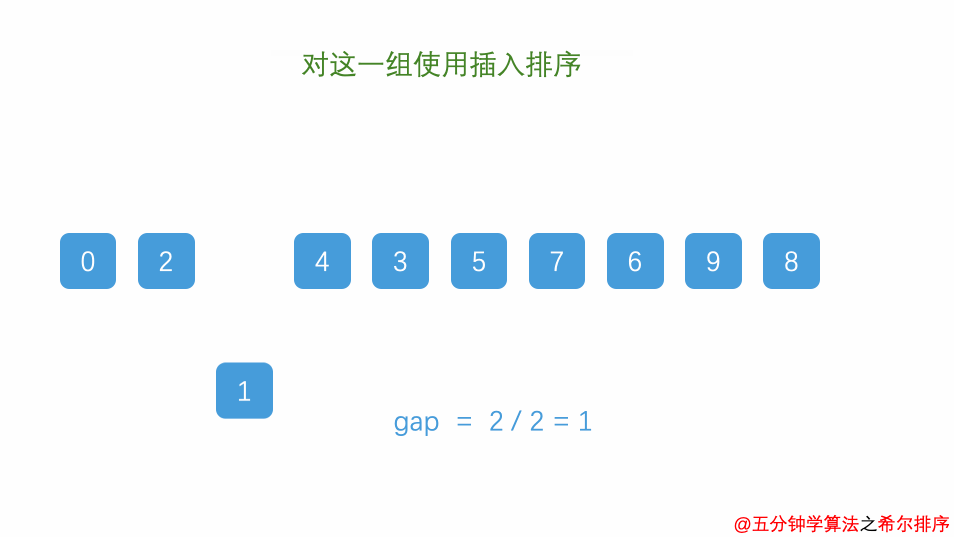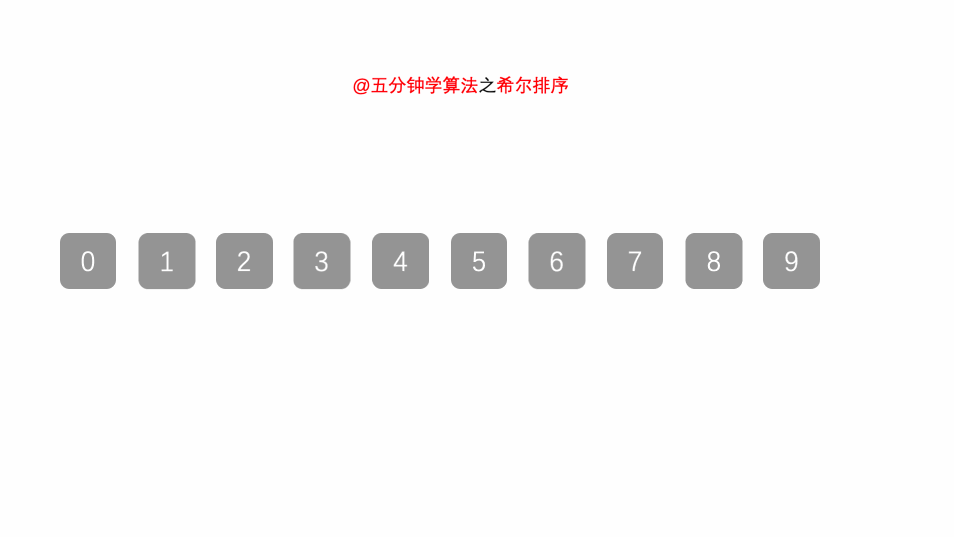
public class ShellSort { public static void main(String[] args) { int []arr=new int[]{5,7,2,9,4,1,0,5,7}; System.out.println(Arrays.toString(arr)); shellSort(arr); System.out.println(Arrays.toString(arr)); }