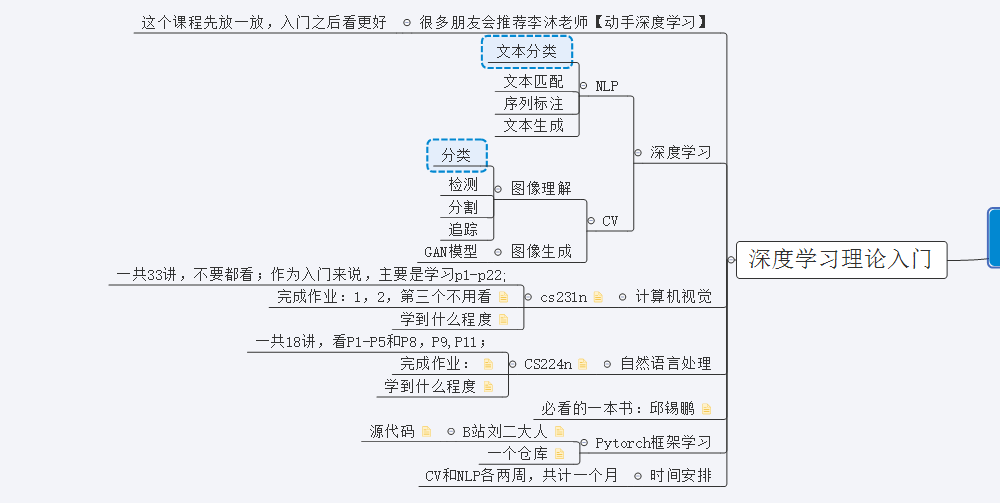
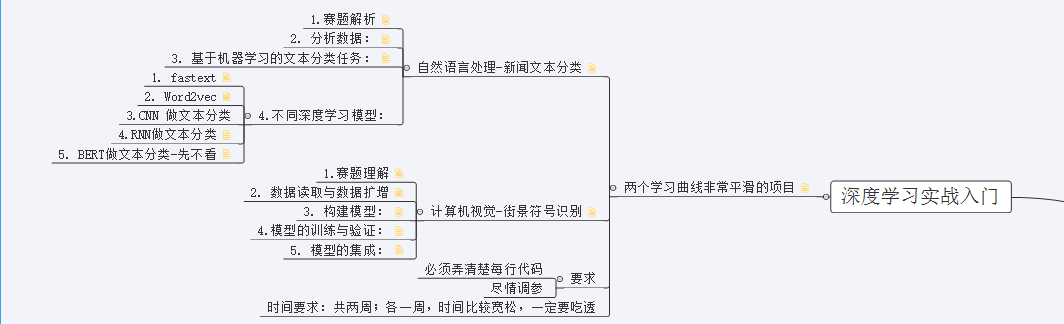
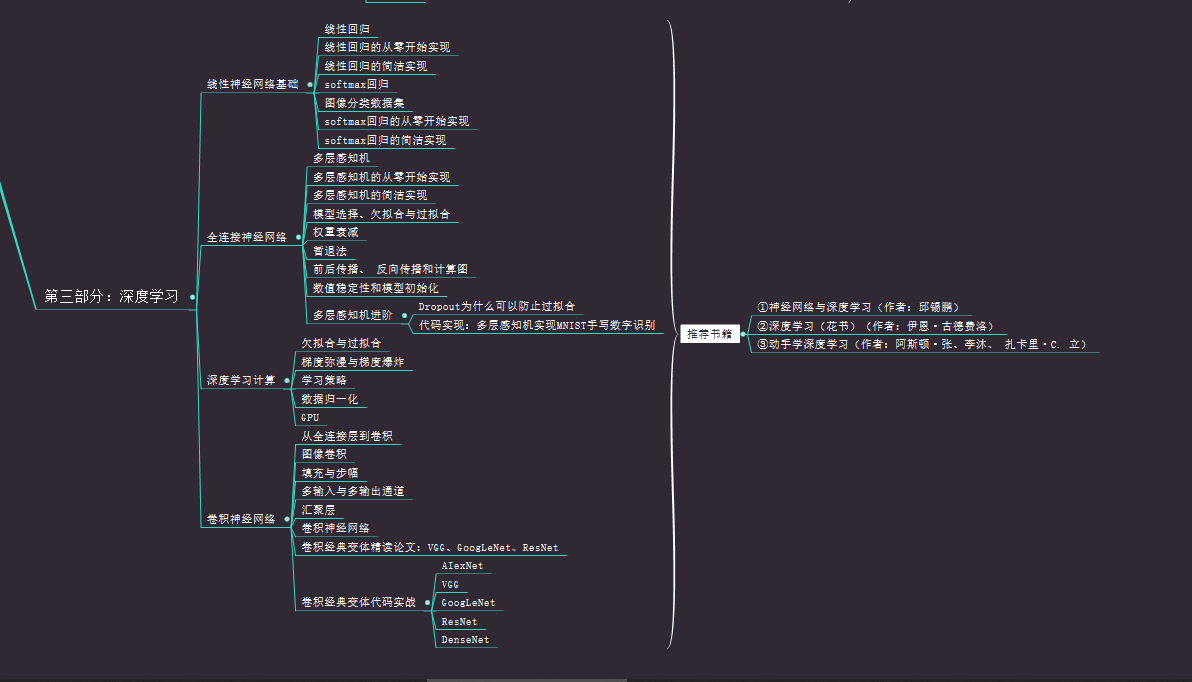
目标
1 | 寒假放学前必须给我把本科不会的算法思路和算法搞懂! |
递归
1 |
https://www.bilibili.com/video/BV1pt411h7aT/?spm_id_from=333.999.0.0

1 |
|
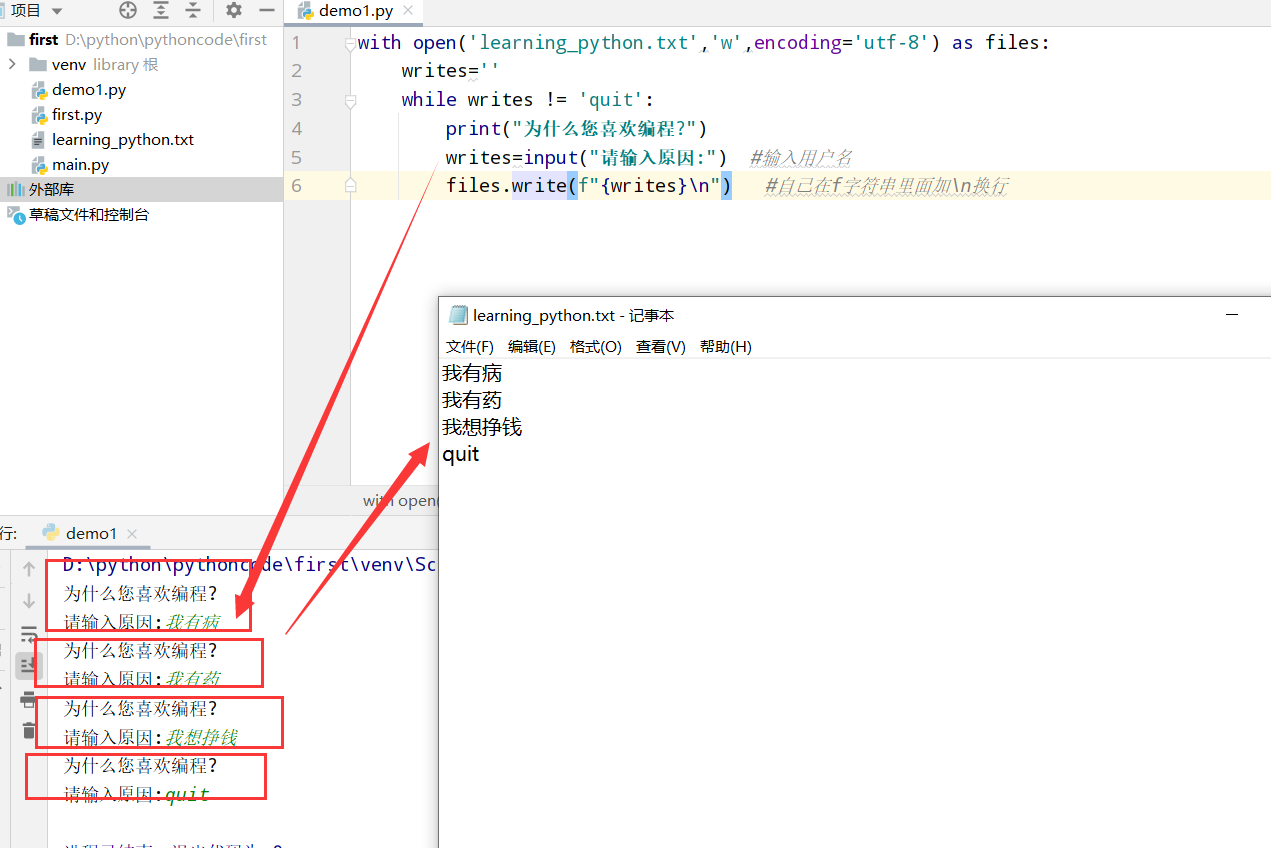
1 | 1.题目:垃圾分类的处理与数据分析 |
1 | 1.Kaggle:https://www.kaggle.com/account/login?phase=startRegisterTab&returnUrl=%2F |
1 | import torch |
1 | #1.使用models中的数据集 |
1 | #2.使用transforms包(Compose类) |
1 | #3.datasets包 -- 包中的类几乎都直接/间接继承自torch.utils.data.DataSet类 -- 借由datasets包得到的数据集都可以再传递给torch.utils.data.DataLoader(多线程并行加载样本数据) |

1 | #4.utils包(一些计算机视觉领域经常用到的操作) |
总体框架

人工神经元:
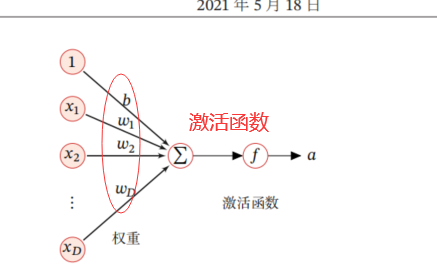
激活函数性质
1 | 1.连续并可导的非线性函数 |
sigmoid函数的公式

1 | 1.分为logistic函数和Tanh函数 |
sigmoid两种函数的图像:

ReLU函数公式

1 | 1.优点: |
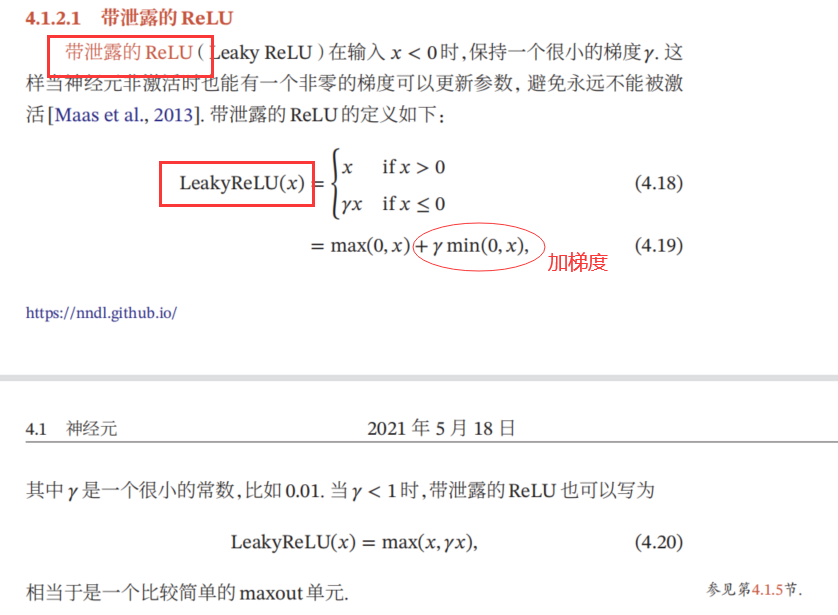



四种函数图对比:
1 | 1.自门控激活函数 |

1 | 1.高斯误差线性单元 --> 通过门控机制来调整其输出值的激活函数 |


三种网络结构:
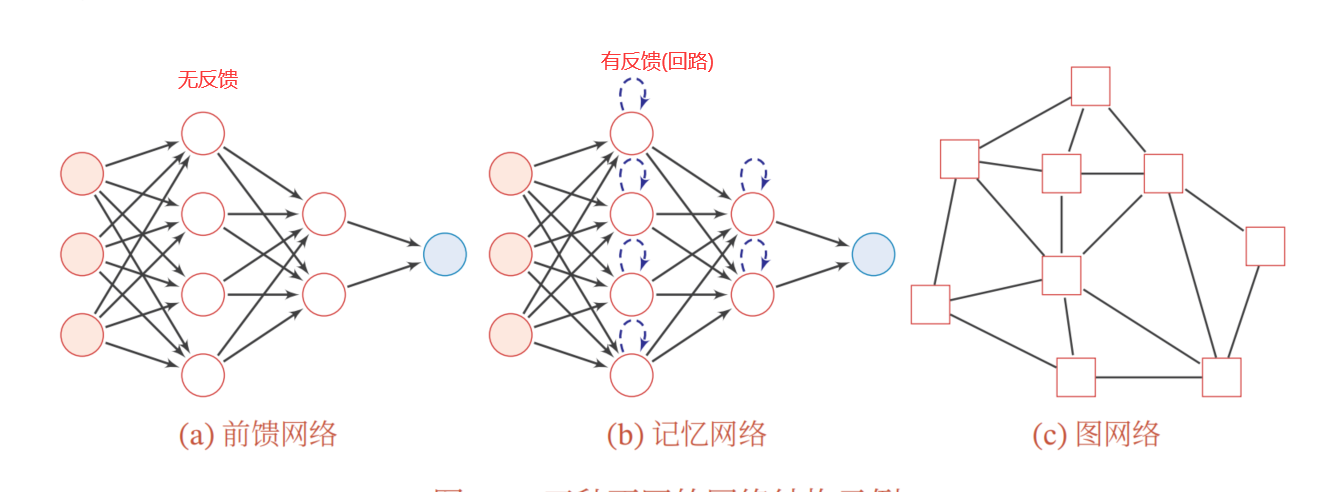
1 | 1.数据集: |
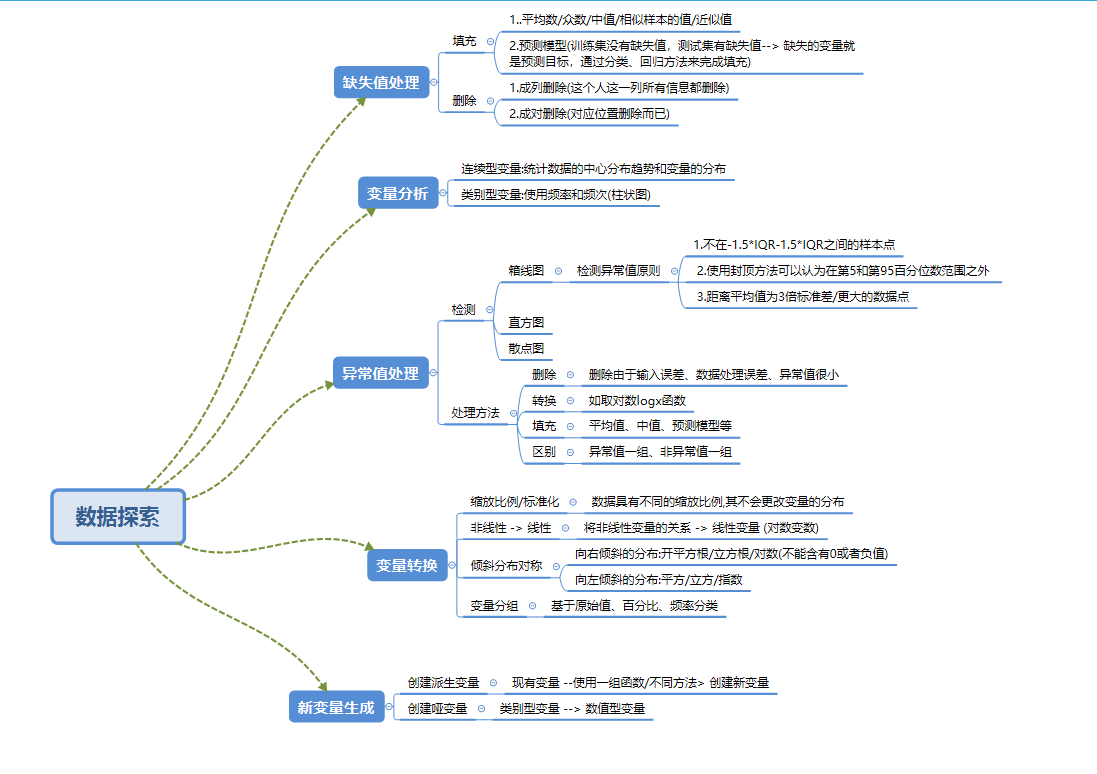
1 |
|
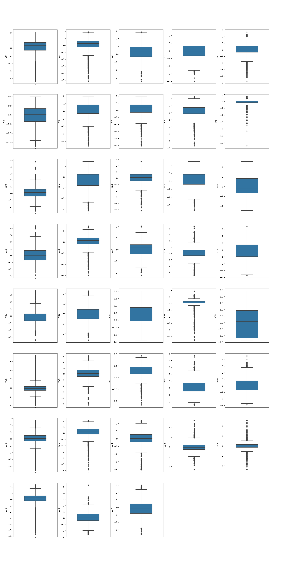
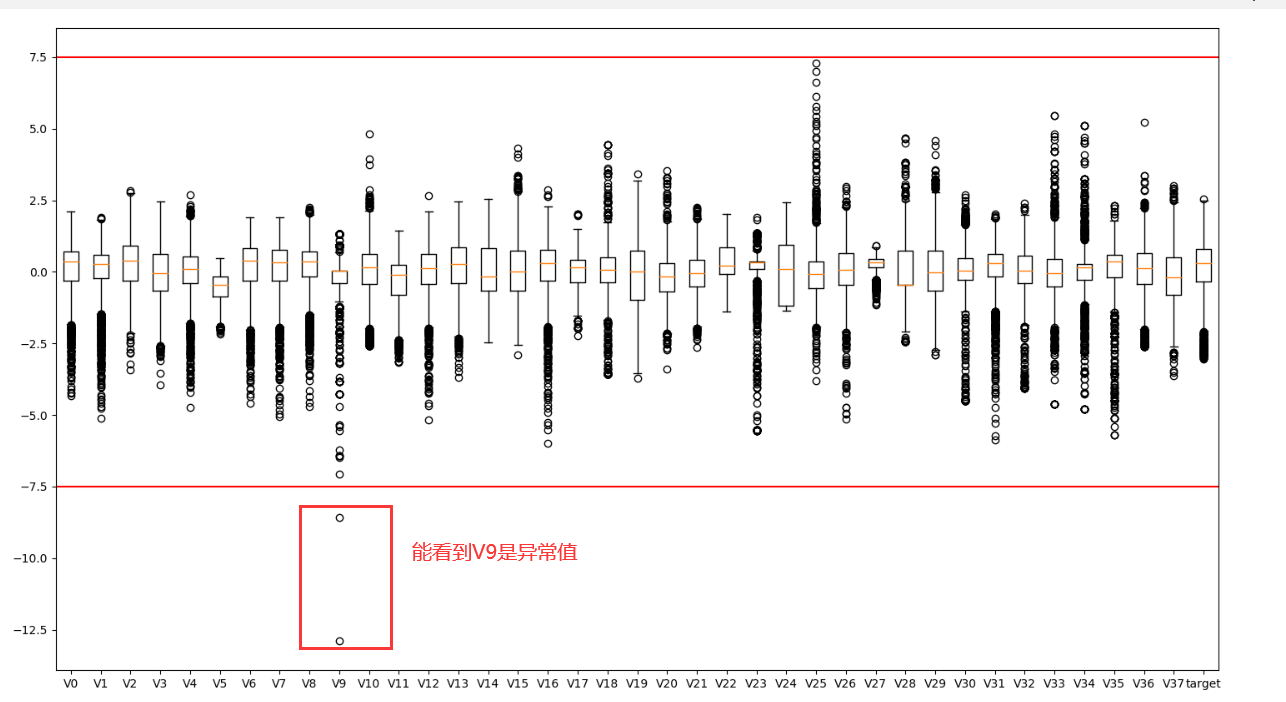
1 | ##2.1 箱型图boxplot(所有特征变量) |
整体的箱型图:
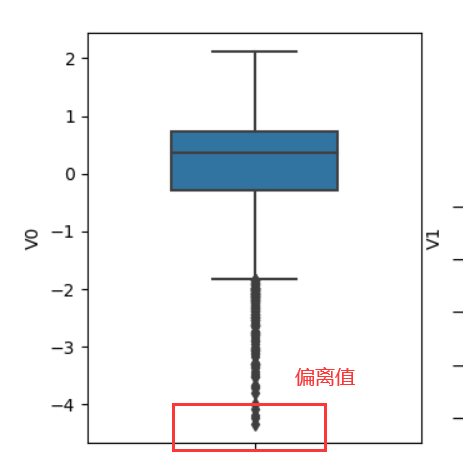
V0一个的箱型图:
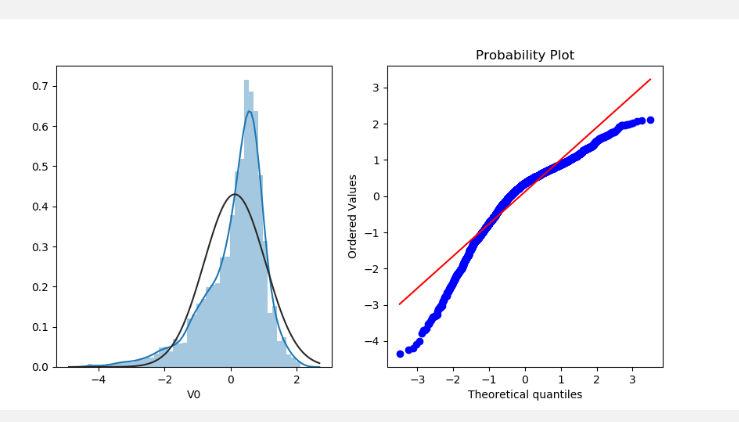
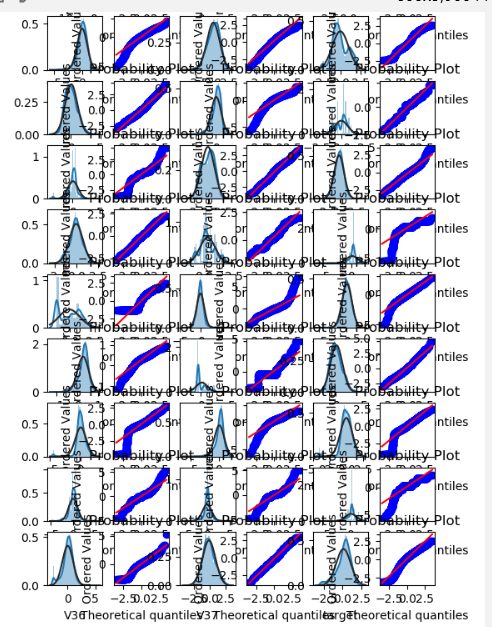
1 | ##2.3 直方图distplot和Q-Q图probplot(数据的分位数和正态分布的分位数对比参照) -- 如果数据符合正态分布 会在qq图内两条线重合 |
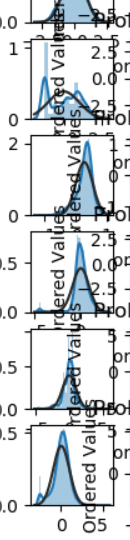
1 | ##2.4 KDE分布图kdeplot(核密度估计) --对直方图的加窗平滑(可以查看对比训练集和测试集中特征变量的分布情况) |
1 | ##2.5 线性回归关系图regplot(分析变量之间的线性回归关系) |
1 | #3.查看特征变量的相关性 |

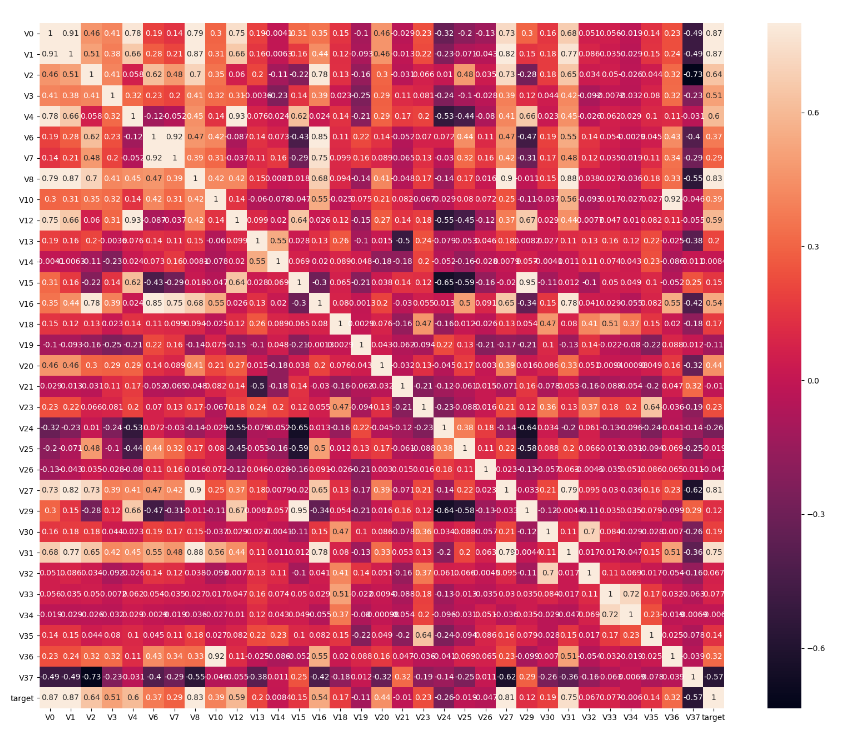
1 | ##3.2 热力图heatmap |
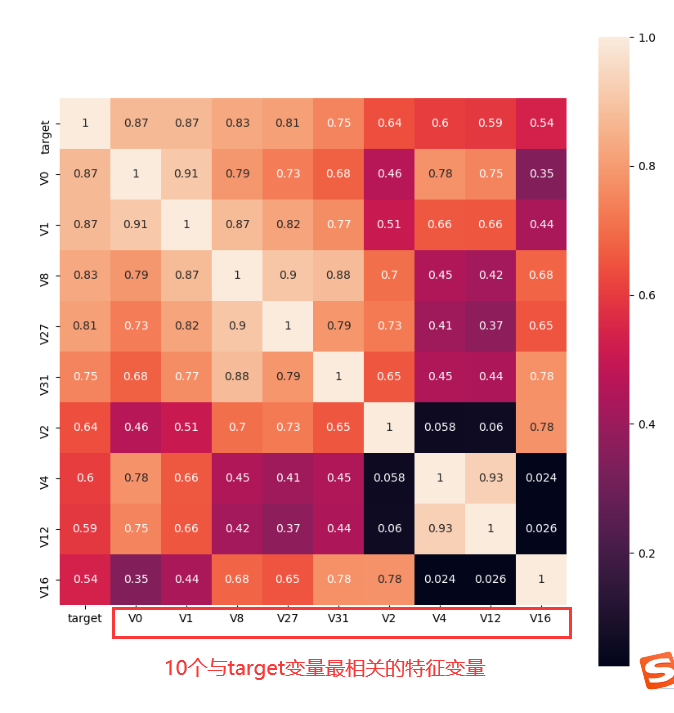
1 | ###3.3.1 寻找k个与target变量最相关的特征变量(K=10) |
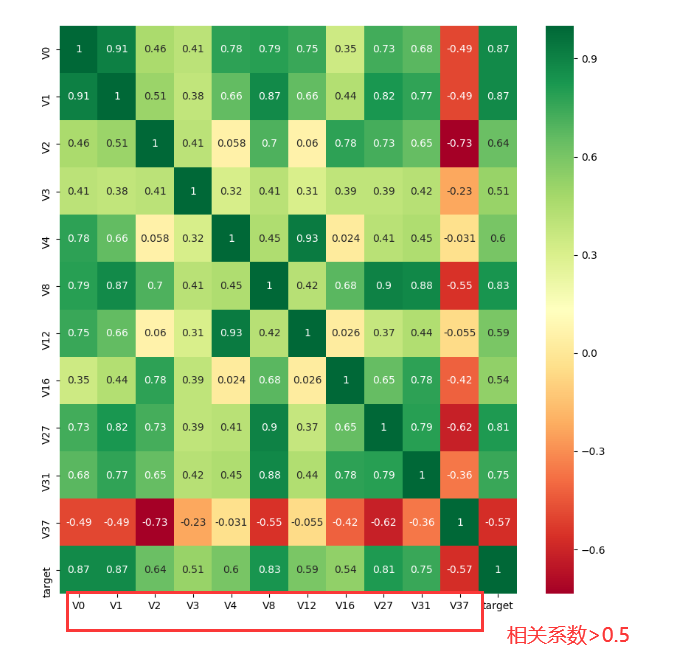
1 | ###3.3.2 找出与target变量的相关系数大于0.5的特征变量 |
1 | ###3.3.3 Box-Cox变换(线性回归基于正态分布 --> 统计分析将数据转换为符合正态分布) |
特征工程的重要性:
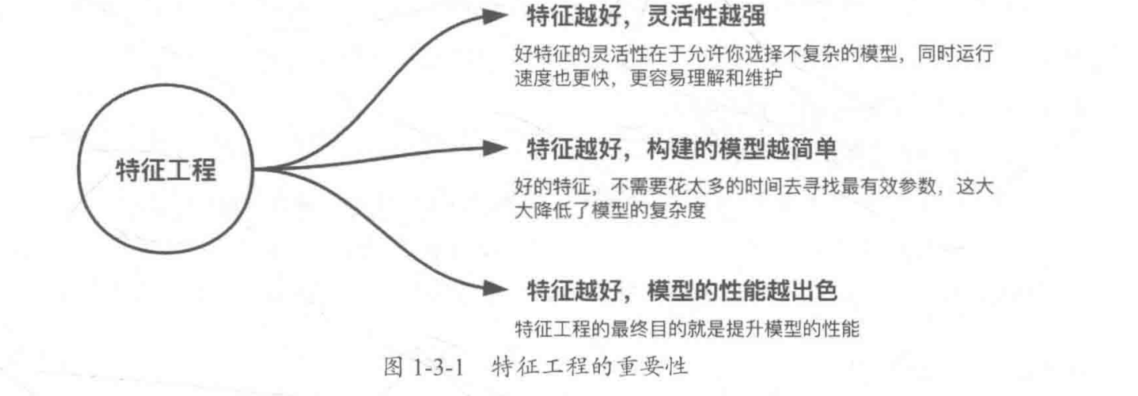
1 | 1.特征工程处理流程: |
1 | 1.数据采样的原因:经过采集和清洗之后正负样本是不均衡的 --> 数据采样 |
特征处理小结:


1 | 1.标准化: 依照特征矩阵的列去处理数据[通过求标准分数的方法将特征-->标准正态分布] |

1 | 1.区间缩放法: 利用两个最值(最大值和最小值)进行缩放 [归一化的一种] |
公式:

1 | 1.归一化: 样本的特征值-->同一量纲,数据-->[0,1]/[a,b]区间内 |
公式:

1 | 1. 定量特征二值化: 核心在于设定一个阈值(>阈值的赋值为1,≤阈值的赋值为0) |
1 | 1.哑变量/虚拟变量(Dummy Variable):通常是认为虚设的变量(0/1),用来反映某个变量的不同属性。 |
1 | 1.用Pandas读取后特征均为NaN(数据缺失) |
1 | 1.基于多项式的多项式转换(PolynomialFeatures类):参数degree为度(默认值为2) |
特征选择三类方法:
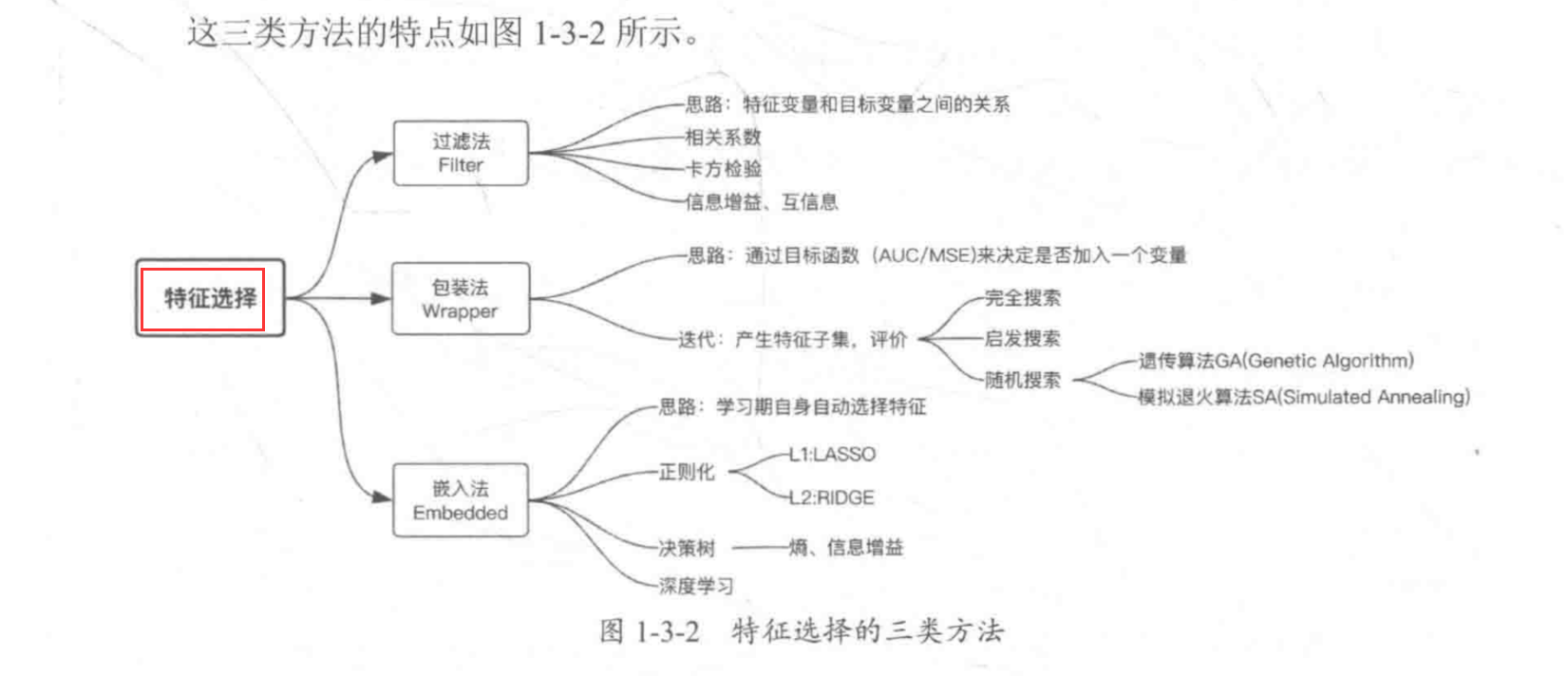
1 | 1.特征选择概念:比较简单粗暴,就是映射函数直接将不重要的特征(×),不过会造成特征信息的丢失,不利用模型精度 |
1 | ##箱型图 |
1 | ##归一化(最大值和最小值) --放缩到(0,1区间) |
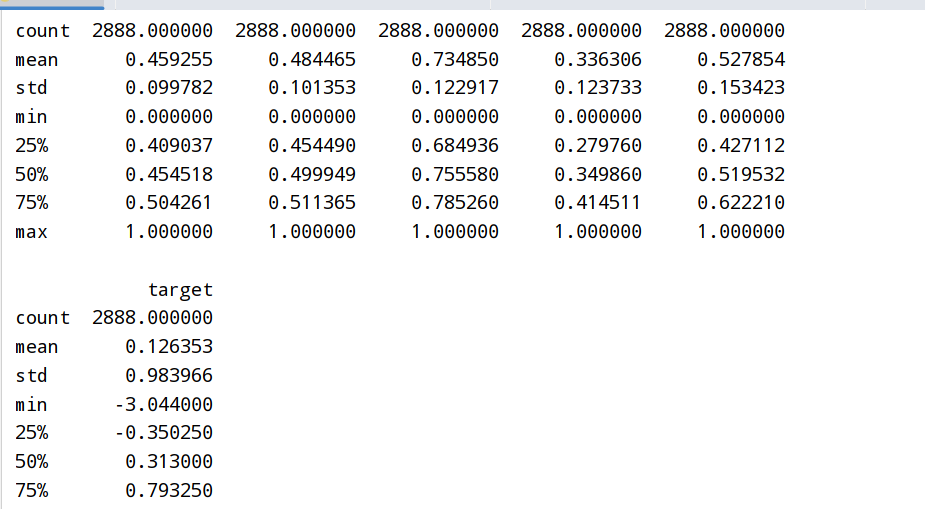
1 | ##查看数据分布 --通过KDE分布对比了特征变量在两个数据集中的分布情况(V5/V9/V11/V17/V22/V28在训练集和测试集分布差异较大,会影响模型的泛化能力,故删除这些特征) |
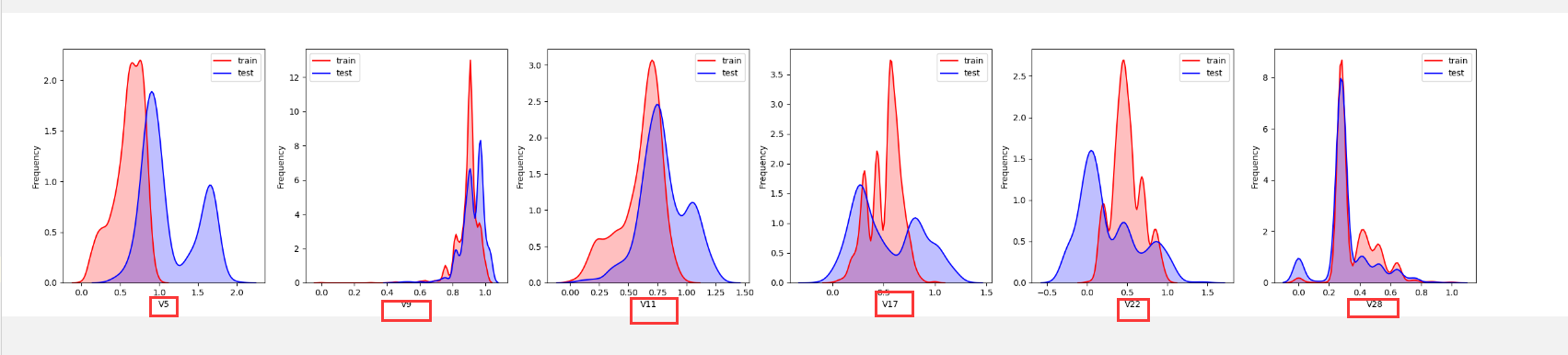
1 | ##特征相关性(热力图可视化显示) |
1 | ##特征降维(特征相关性的初筛--计算相关性系数并筛选>0.1的特征变量) |

1 | ##多重共线性分析(特征组之间的相关性系数较大) -- 每个特征变量与其他特征变量之间的相关性系数较大所以存在较大的共线性影响 --> 使用PCA进行处理(去除多重共线性) |
1 | ##PCA处理 |
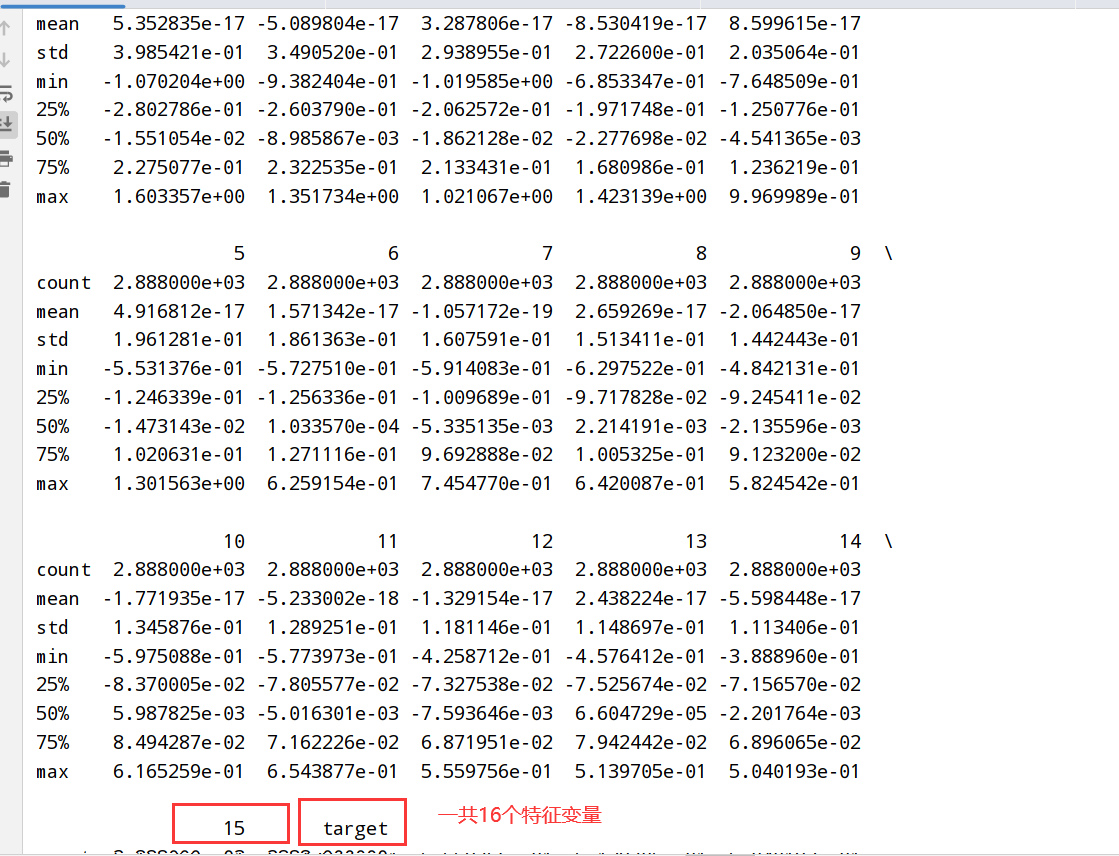
1 | import numpy as np |
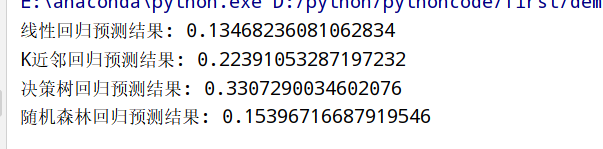
1 | import numpy as np |
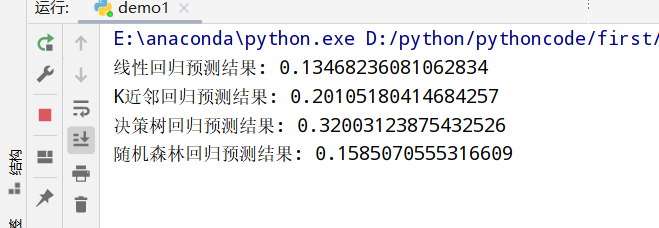
1 | import numpy as np |
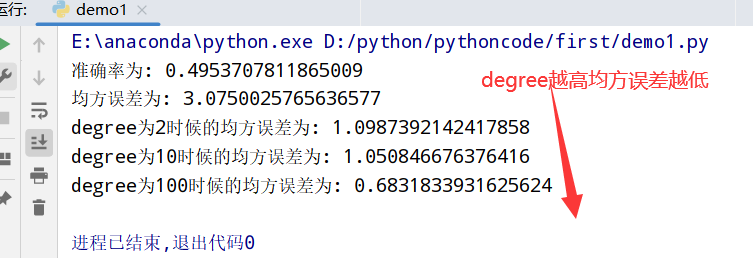

四种回归模型评估方法:
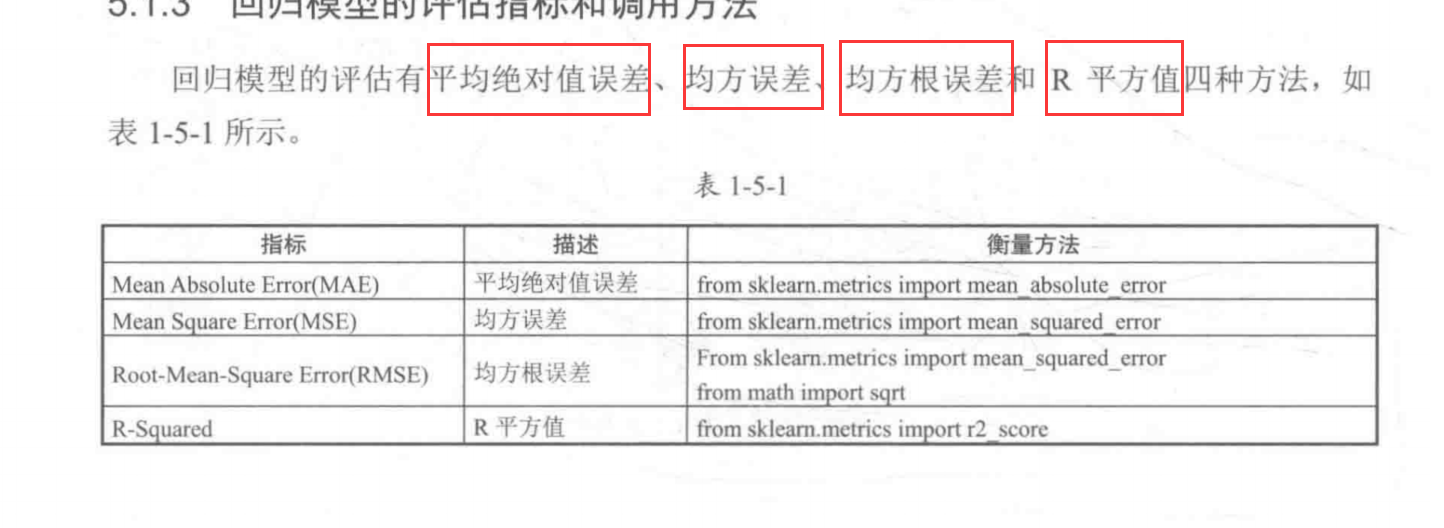
四种回归模型评估的公式:

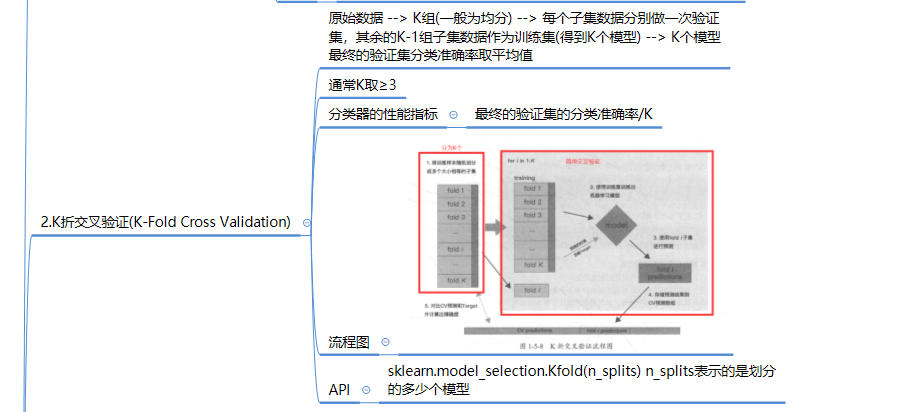
1.简单交叉验证
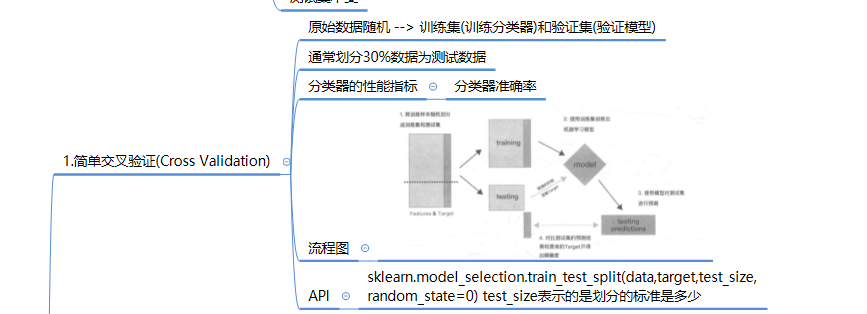
2.K折交叉验证
3.留一法交叉验证

4.留P法交叉验证

5.其他交叉验证

1 | 1.参数分类: |
参数对Random Forest的影响
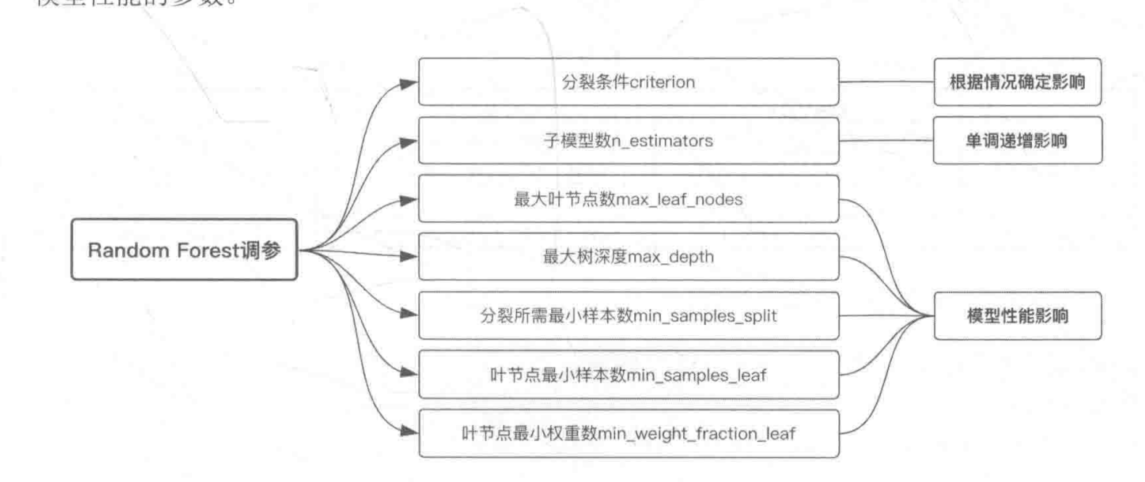
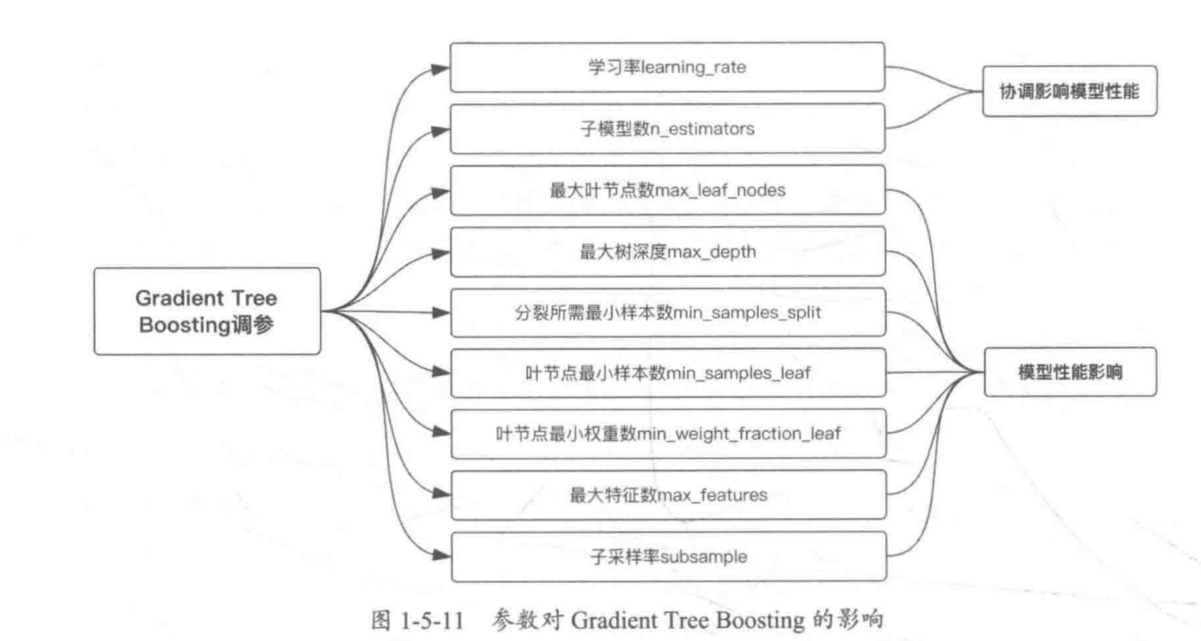
参数对Gradient Tree Boosting的影响

1 | import numpy as np |
1 | import numpy as np |
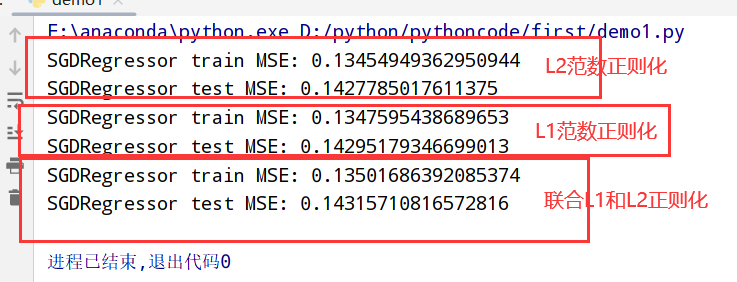
1 | import numpy as np |

1 | import numpy as np |

1 | import numpy as np |
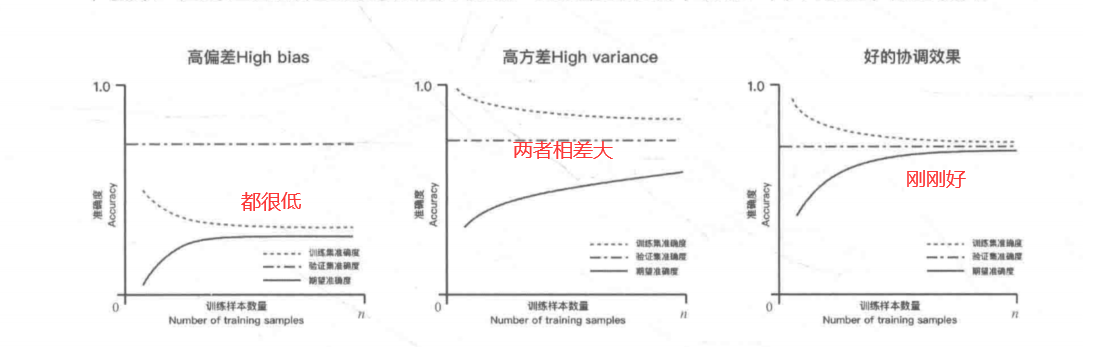
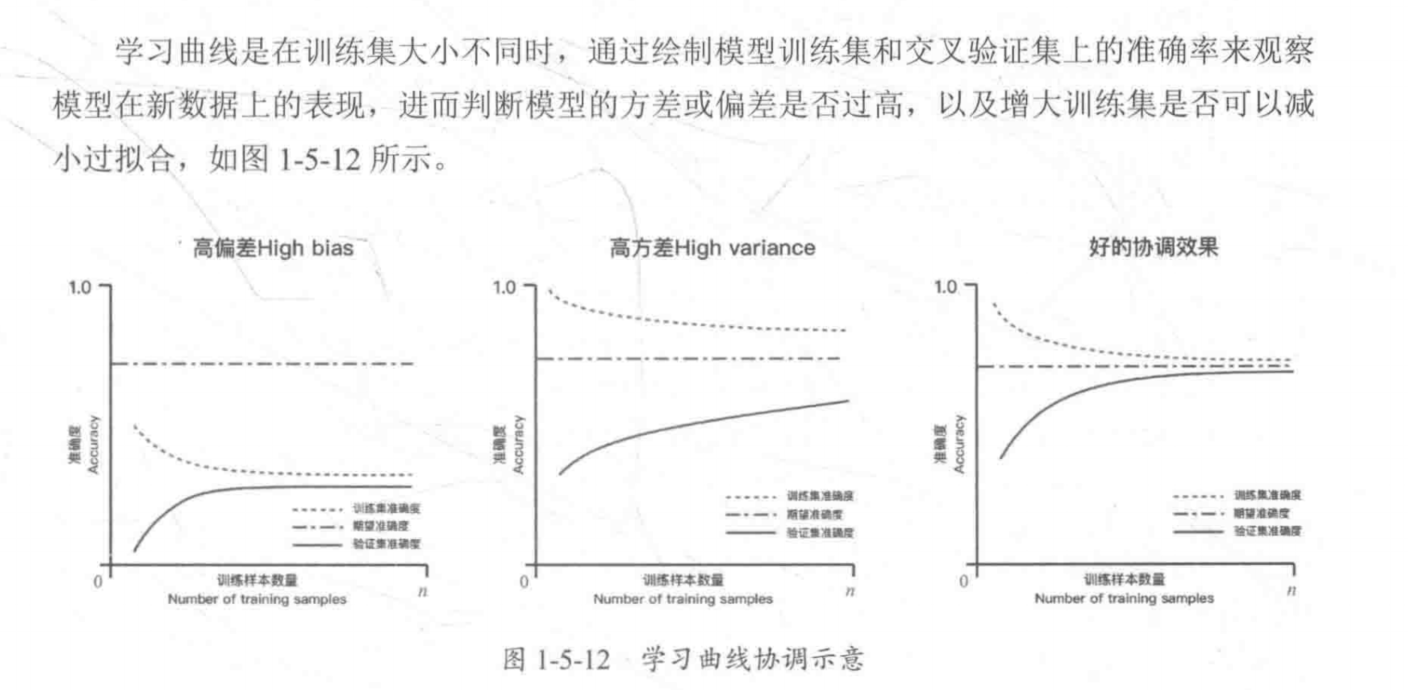
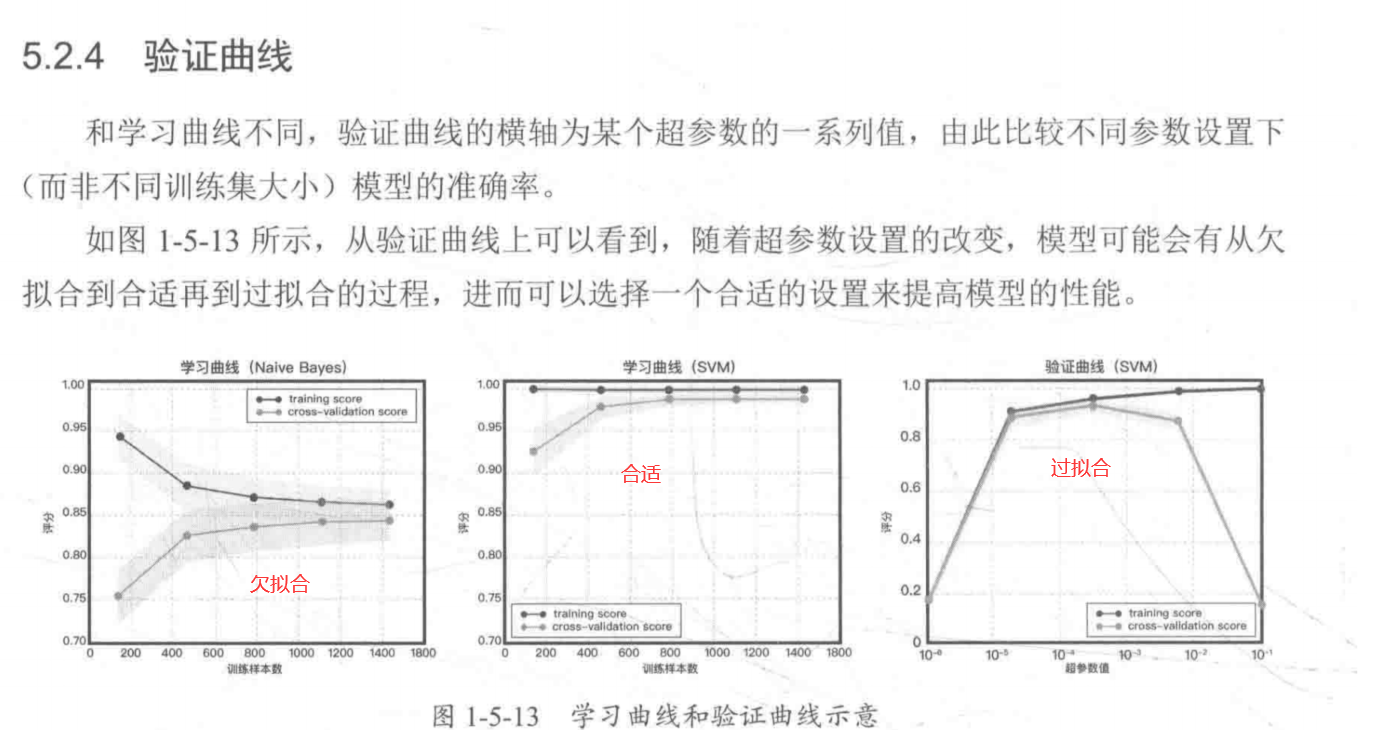
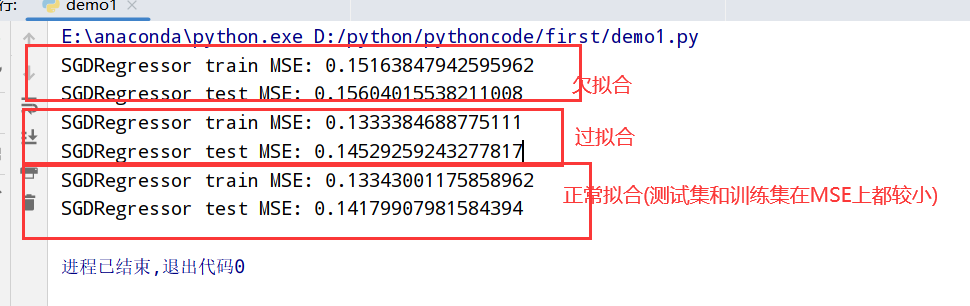
1 | 1.欠拟合(高偏差): 模型太简单(没能力学习到样本的底层规律) -- 训练集和测试集的准确率很低 |
1 | 1.概念:产生一组个体学习器 --根据某种策略 --> 结合个体学习器,加强模型效果 |
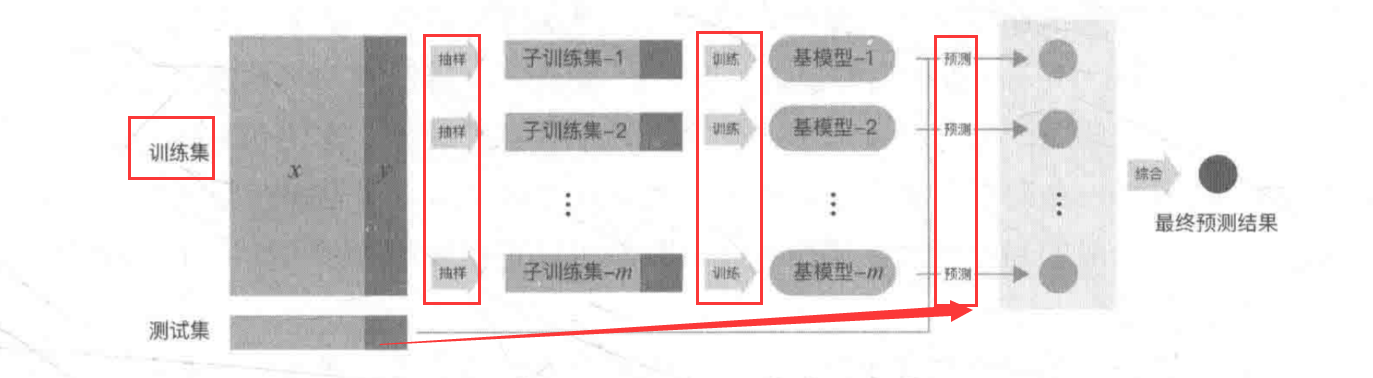
1 | 1.概念:从训练集中抽样得到每个基模型所需要的子训练集 --> 对所有基模型预测的结果进行综合,产生最终的预测结果 |
1 | 1.概念:(对Bagging方法改进) |
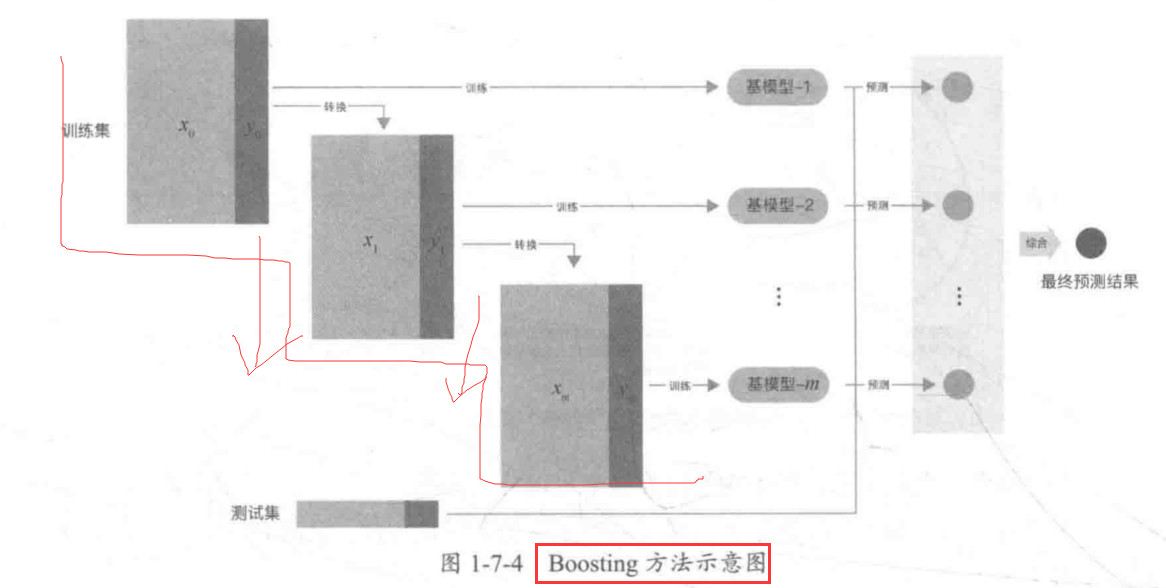
1 | 1.概念:(阶梯状)基模型按照次序一一进行训练 |
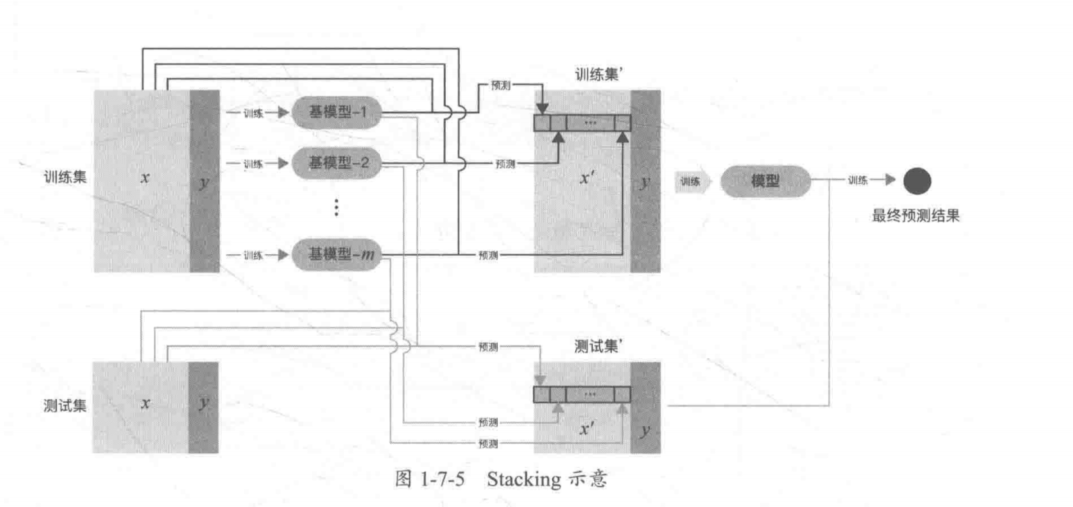
Stacking示意:
1 | 1.Voting(投票机制): 采用少数服从多数的原则 |
1 |
|
参考的路线:
1 | 1.统计学习:关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科 |
1 | 1.输入/输出空间: 输入与输出所有可能取值的集合 |
1 |
1 |
1 |
numpy功能
1 | 1.高性能科学计算和数据分析的基础包 |
1 | 1.ndarray是一个通用的同构数据多维容器(所有元素必须是同类型的) |
函数总结

1 | import numpy as np |
执行结果
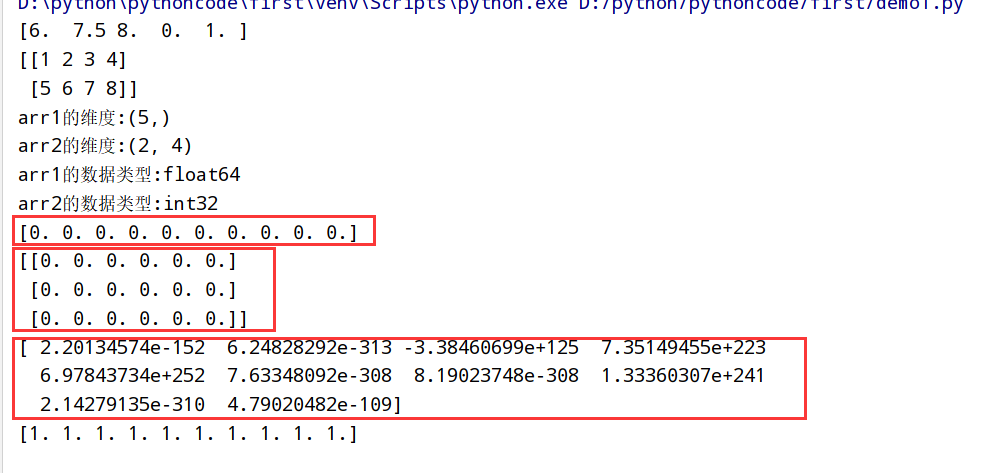
数据类型总结
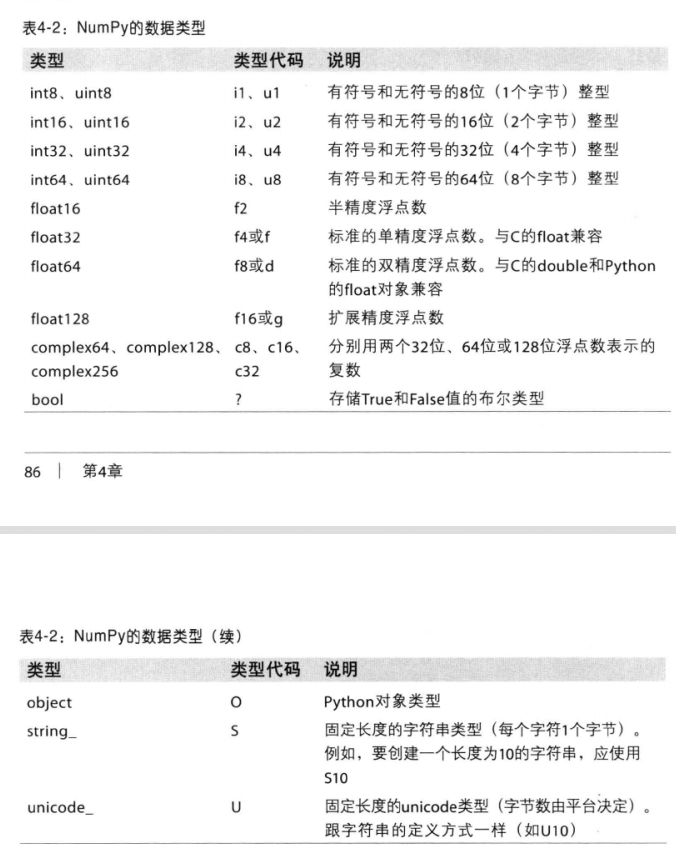
1 | import numpy as np |
执行结果
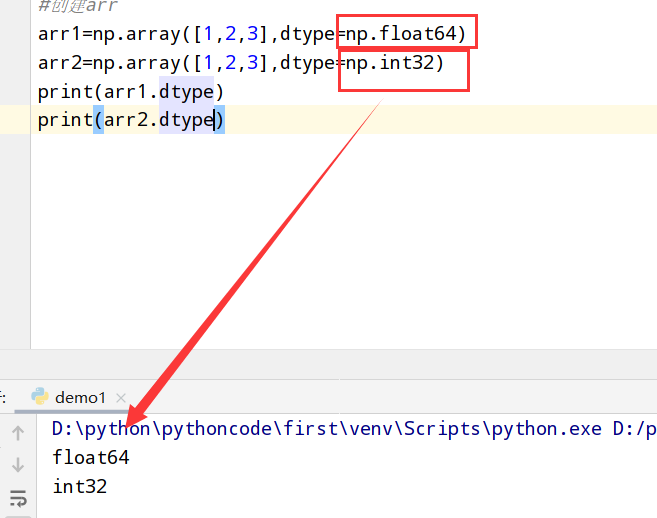
1 | import numpy as np |
执行结果

1 | import numpy as np |
执行结果
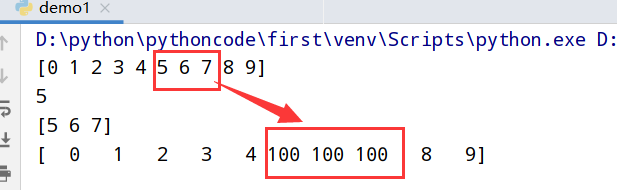
1 | import numpy as np |
执行结果
索引列表
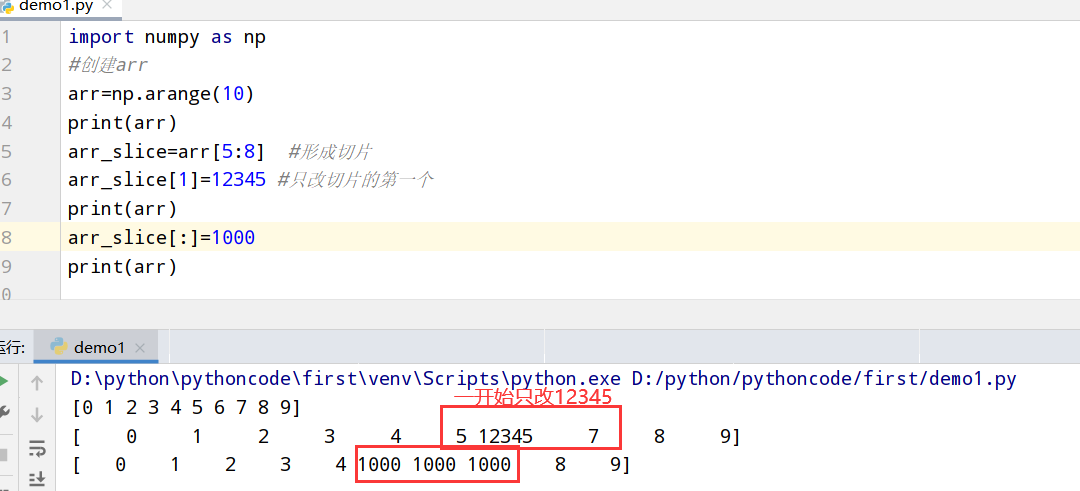
1 | import numpy as np |
执行结果
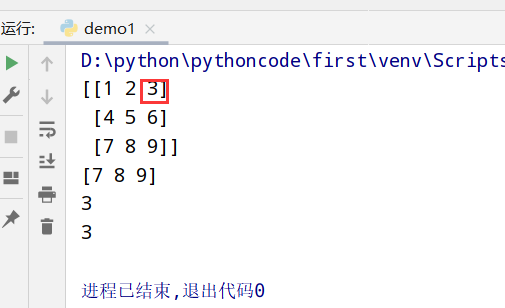
1 | import numpy as np |
执行结果
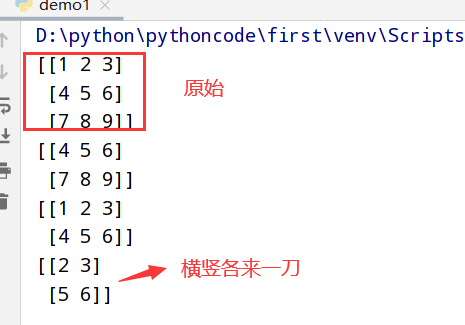
1 | import numpy as np |
执行结果
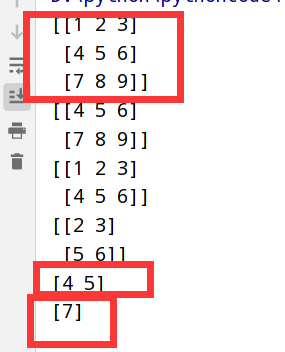
1 | import numpy as np |
执行结果

1 | import numpy as np |
执行结果
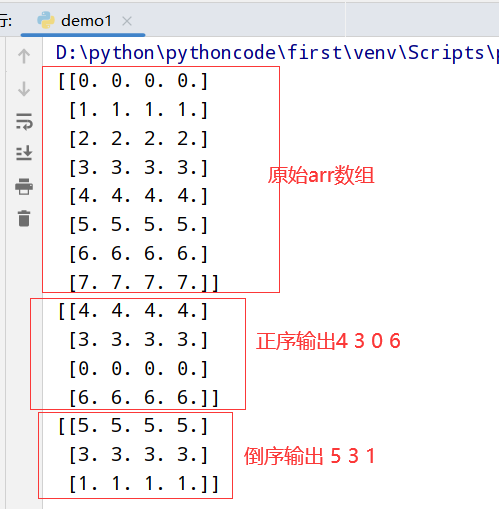
1 | import numpy as np |
执行结果
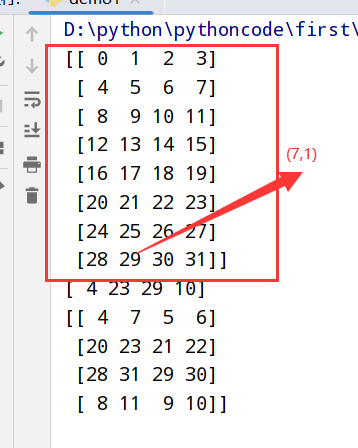
1 | import numpy as np |
执行结果
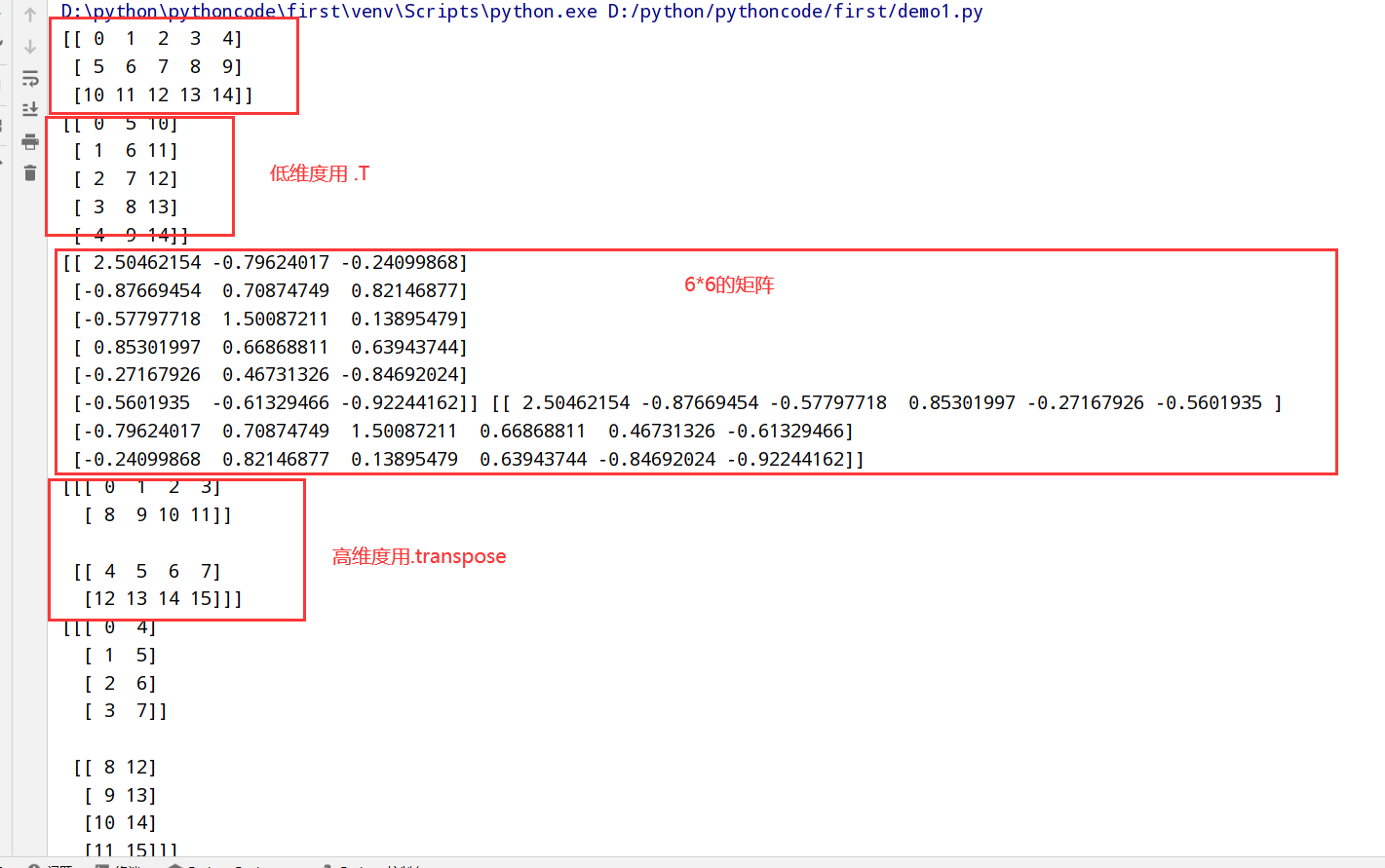
1 | 1.通用函数(ufunc):一种对ndarray中的数据执行元素级运算的函数 |
一元通用函数
二元通用函数
1 | #假设我们想要在一组值(网格型)上计算函数sqrt(x^2+y^2) |
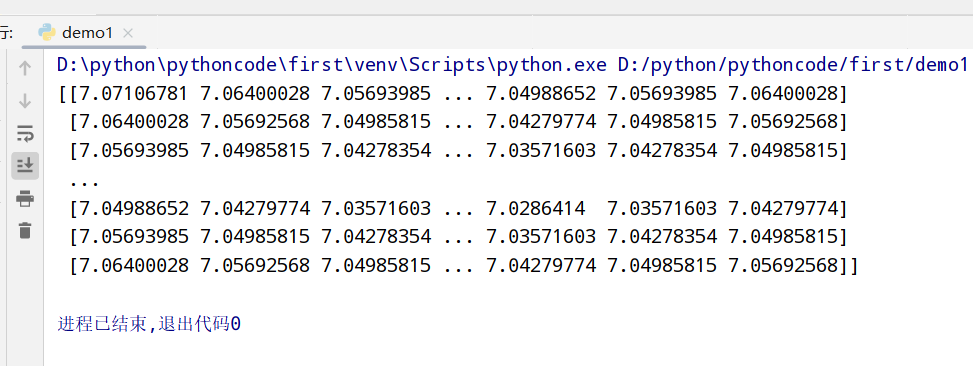
1 | import numpy as np |
基本数组统计方法

1 | import numpy as np |
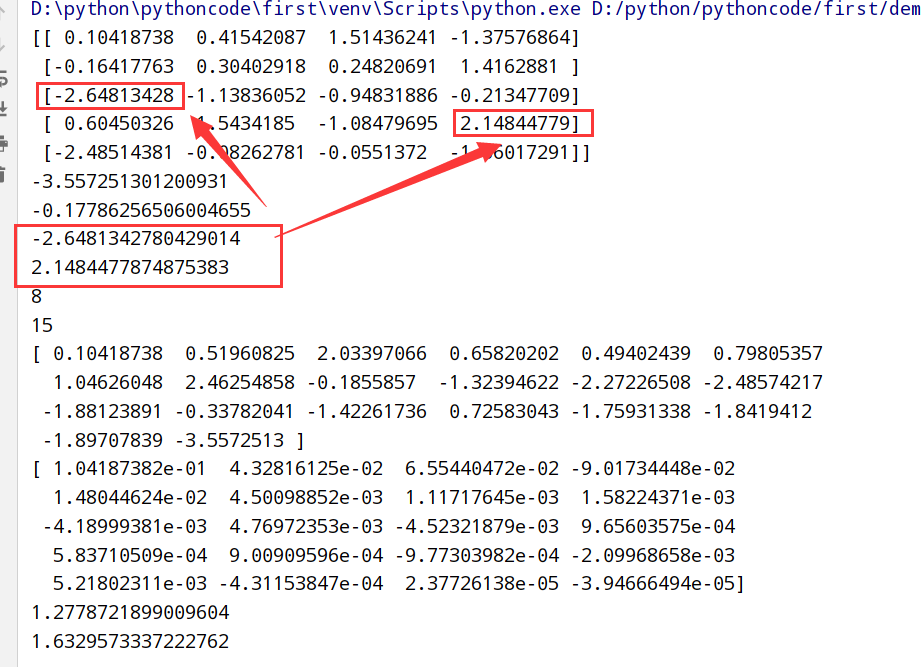
1 | import numpy as np |
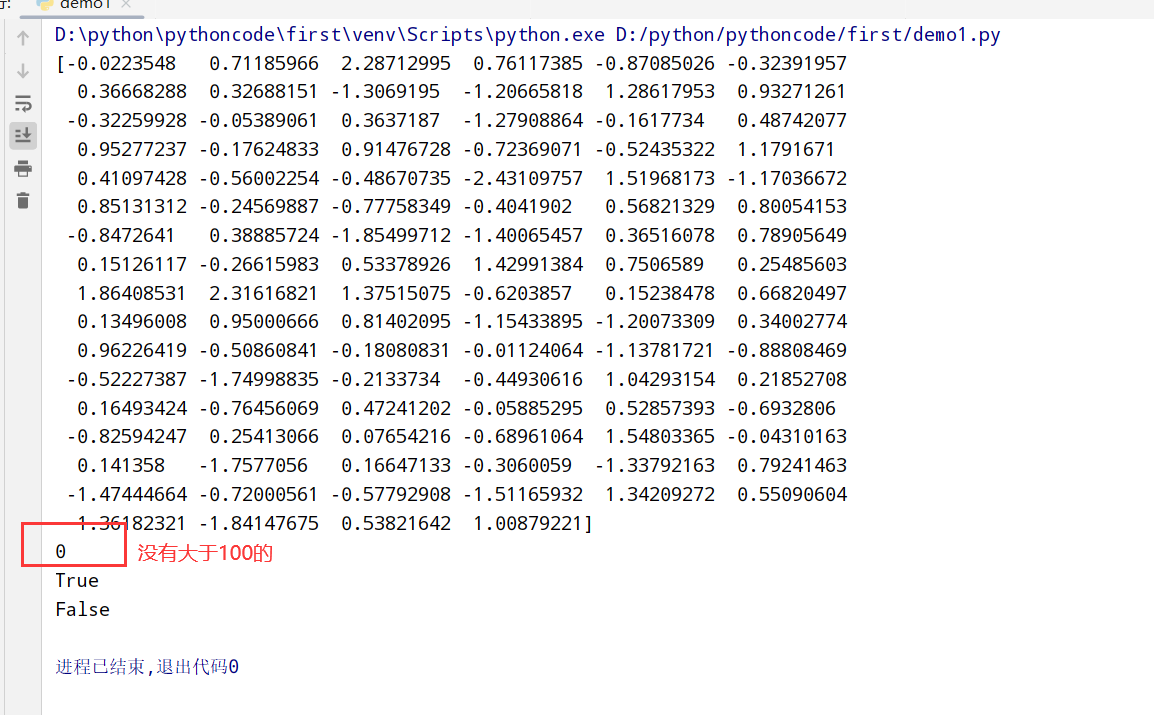
1 | import numpy as np |
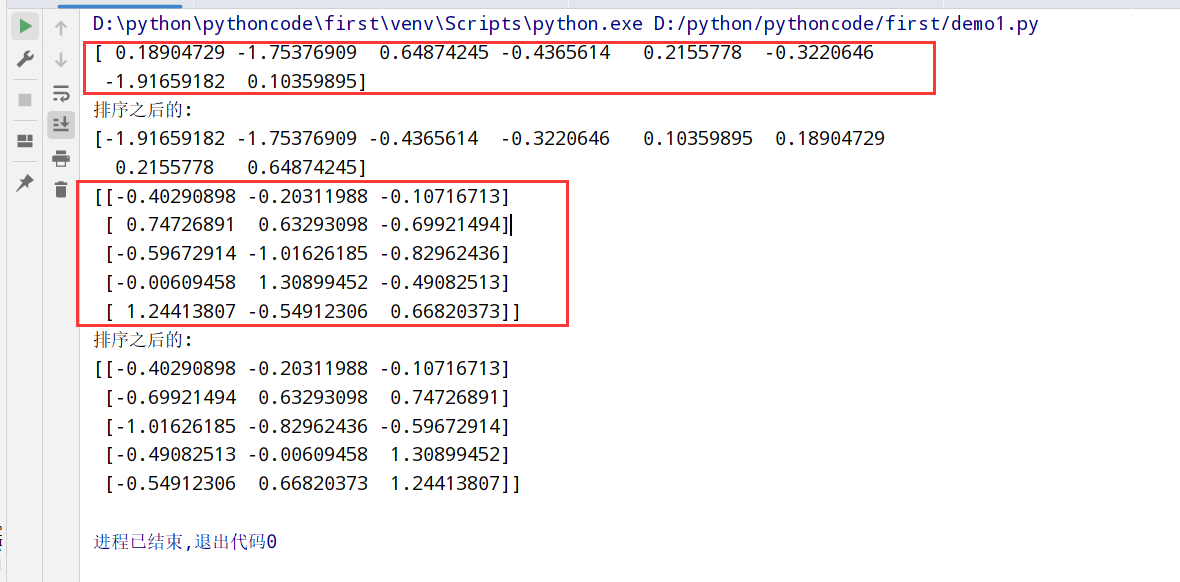

1 | import numpy as np |
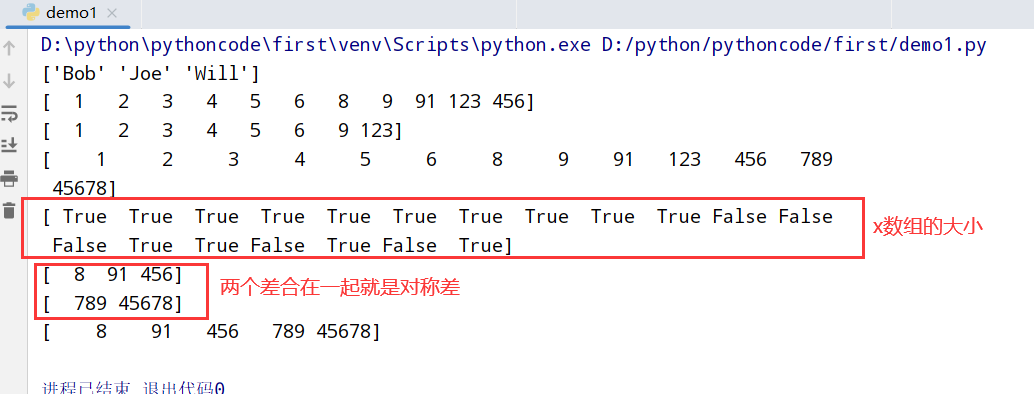
1 | import numpy as np |
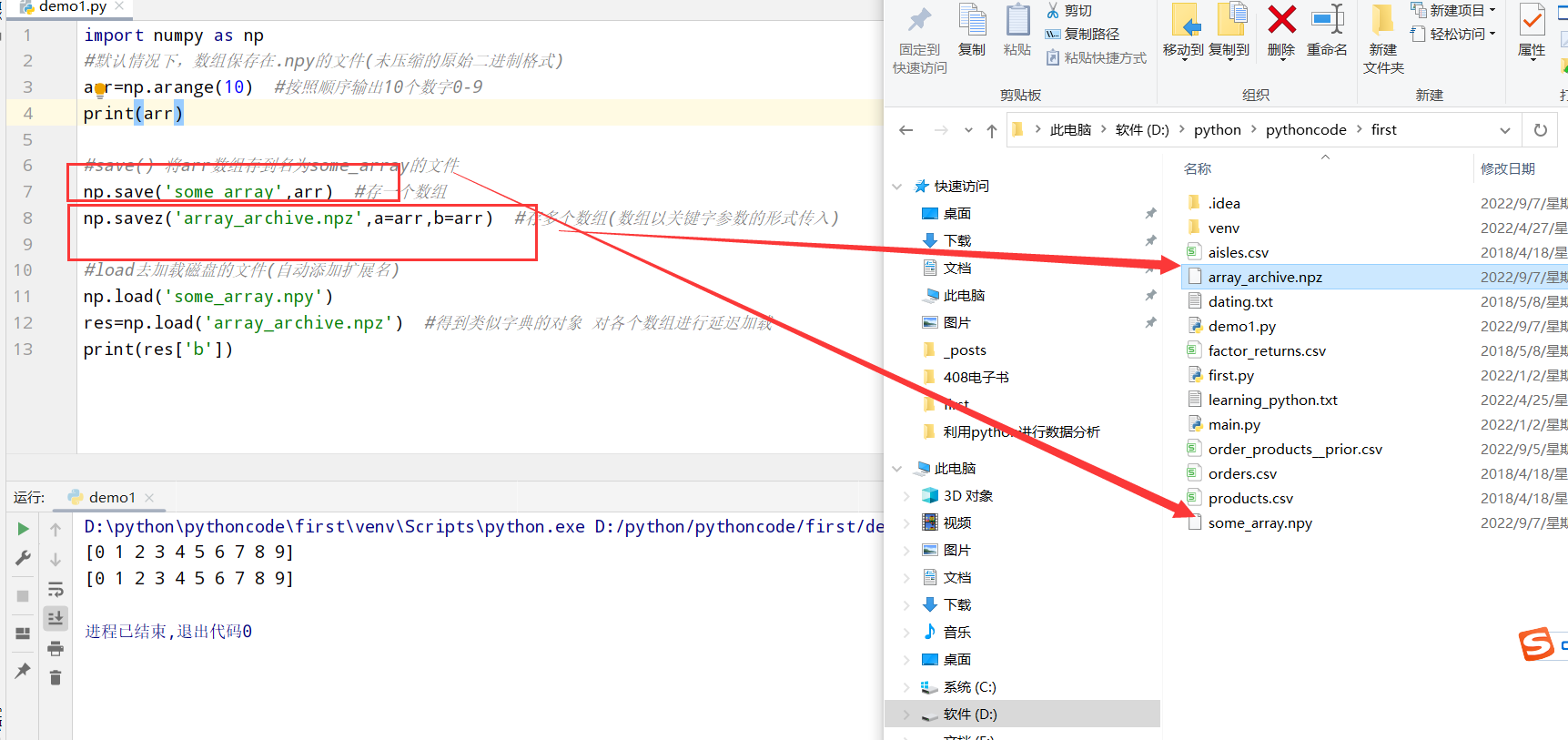
1 | #1.python中的文件读写函数 |
常用的numpy.linalg函数

1 | import numpy as np |
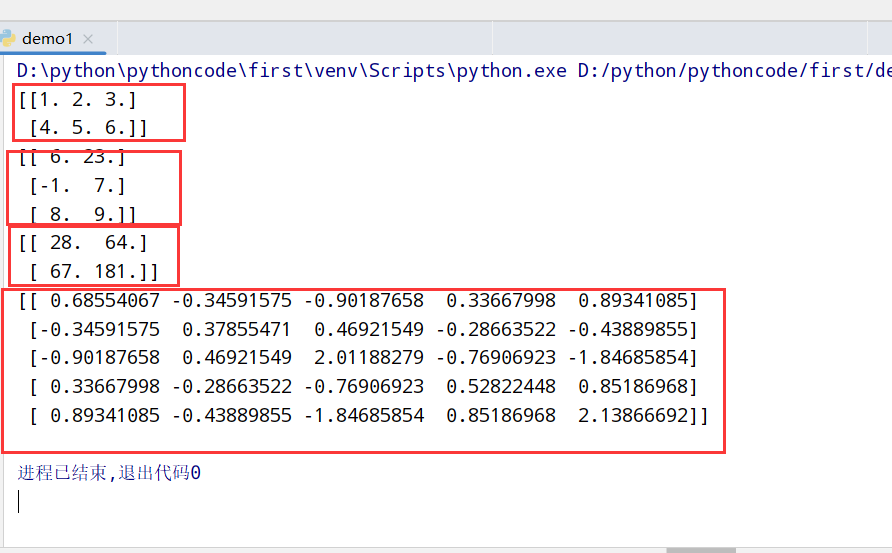
random函数

1 |
|
1 |
|
1 | import numpy as np |


1 | import numpy as np |
第一种方式
第二种方式
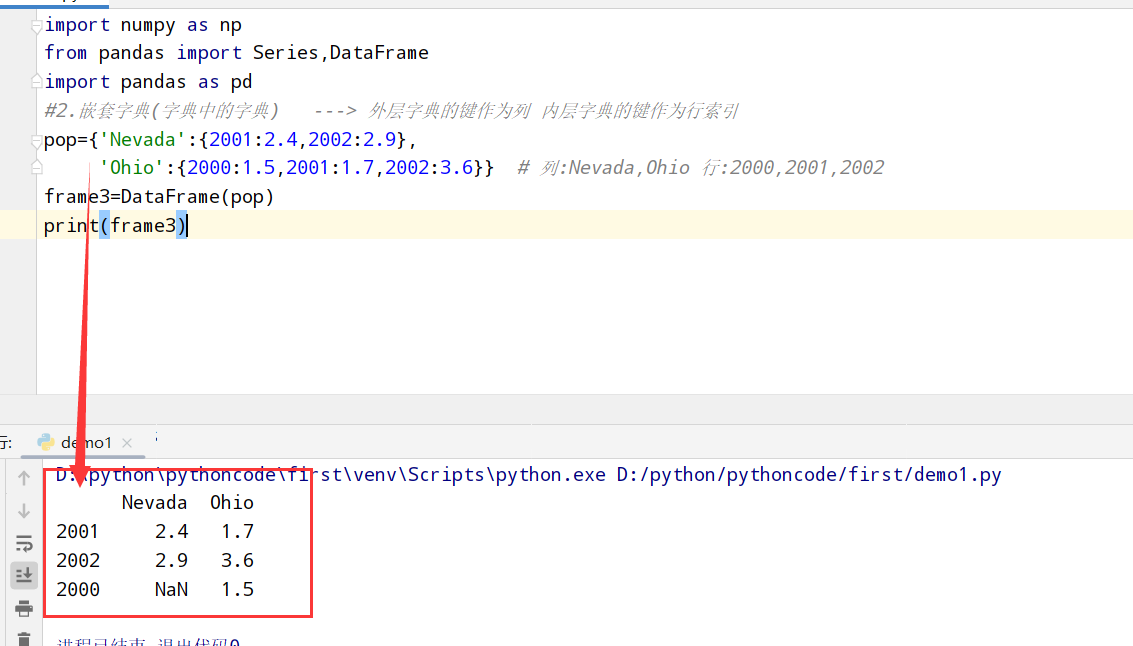
1 | import numpy as np |
Index对象

1 | import numpy as np |
Index的方法和属性

reindex函数的参数

method选项(前向/后向填充)

1 | import numpy as np |

1 | import numpy as np |
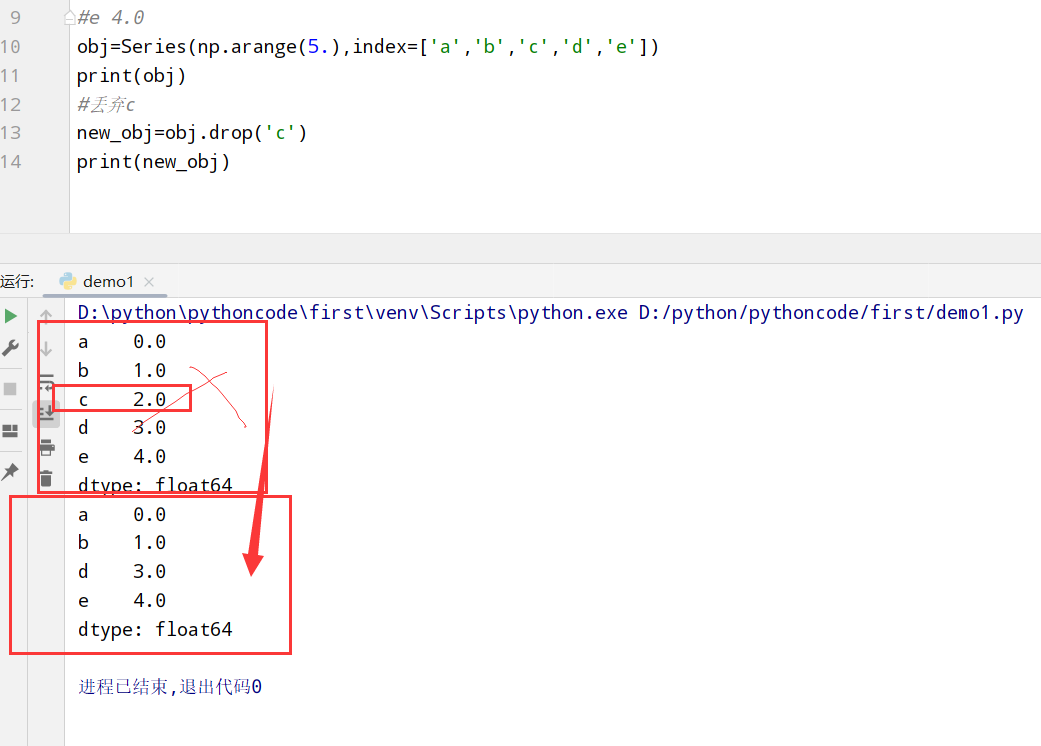
Series索引(啥都有)
1 | import numpy as np |
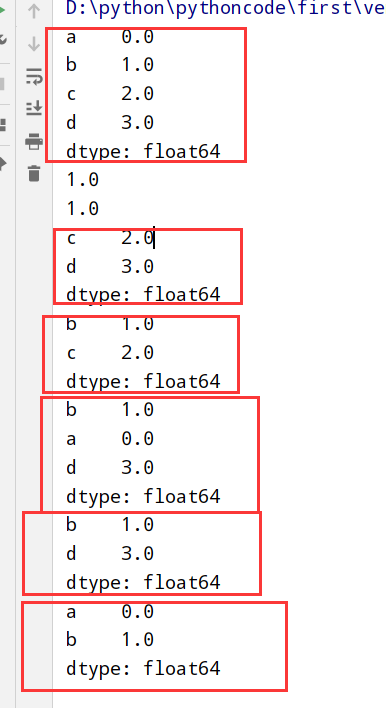
DataFrame索引(一个/多个列)
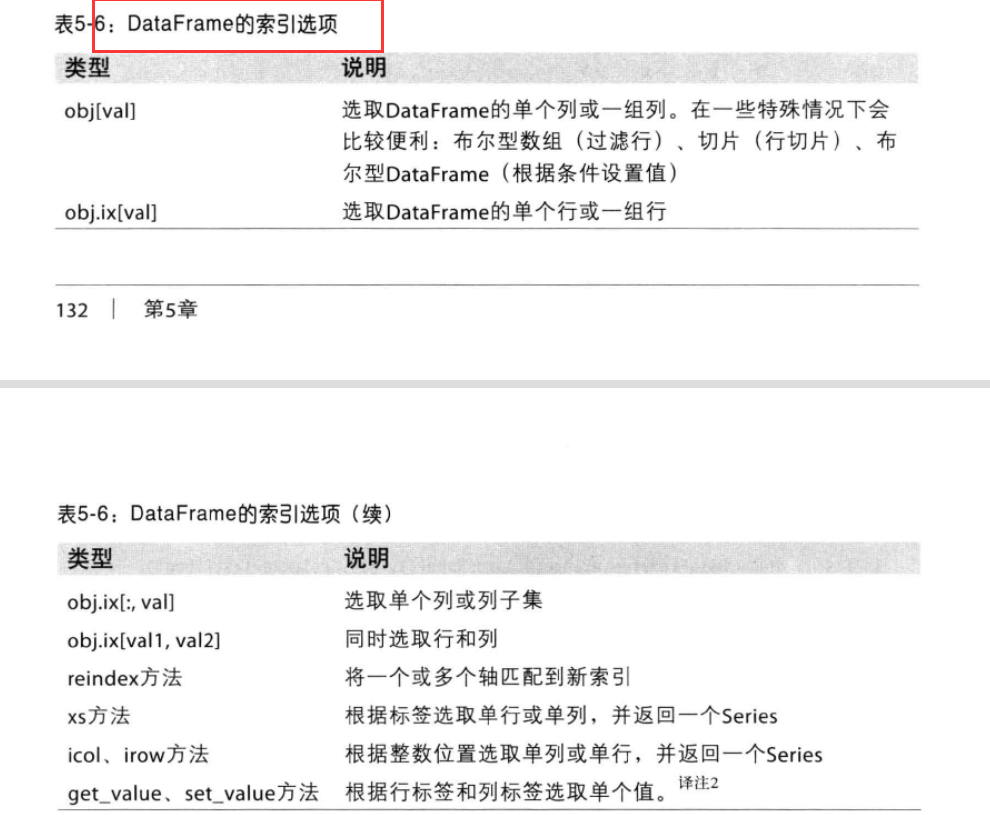
1 | import numpy as np |

算数方法

Series(不同就赋值NaN)
1 | import numpy as np |
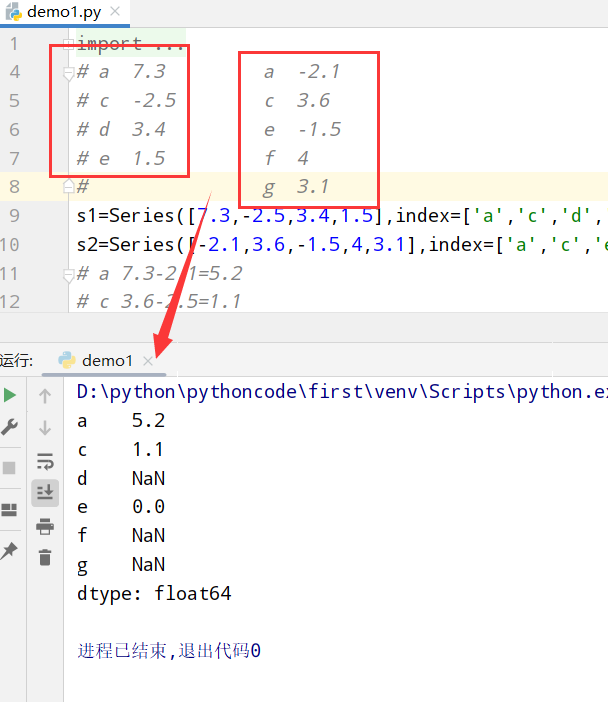
DataFrame(不同就赋值NaN)
1 | import numpy as np |
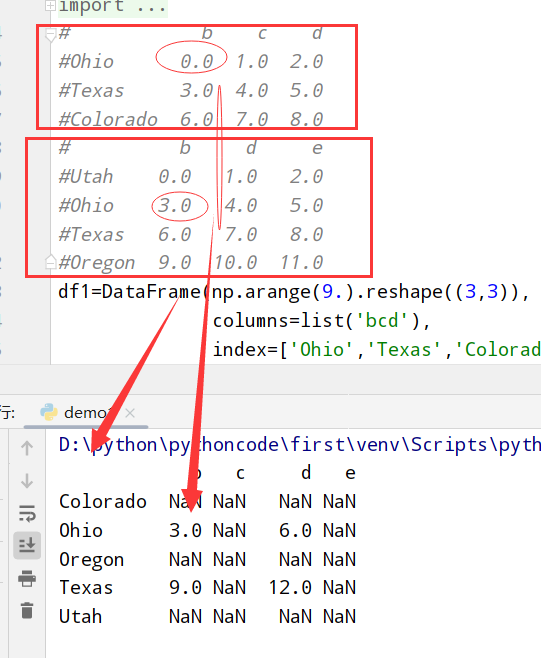
1 | import numpy as np |
Series(根据index排序)
1 | import numpy as np |

DataFrame(根据任意轴index排序)
1 | import numpy as np |

分析rank()怎么执行
https://blog.csdn.net/justinlonger/article/details/90646111
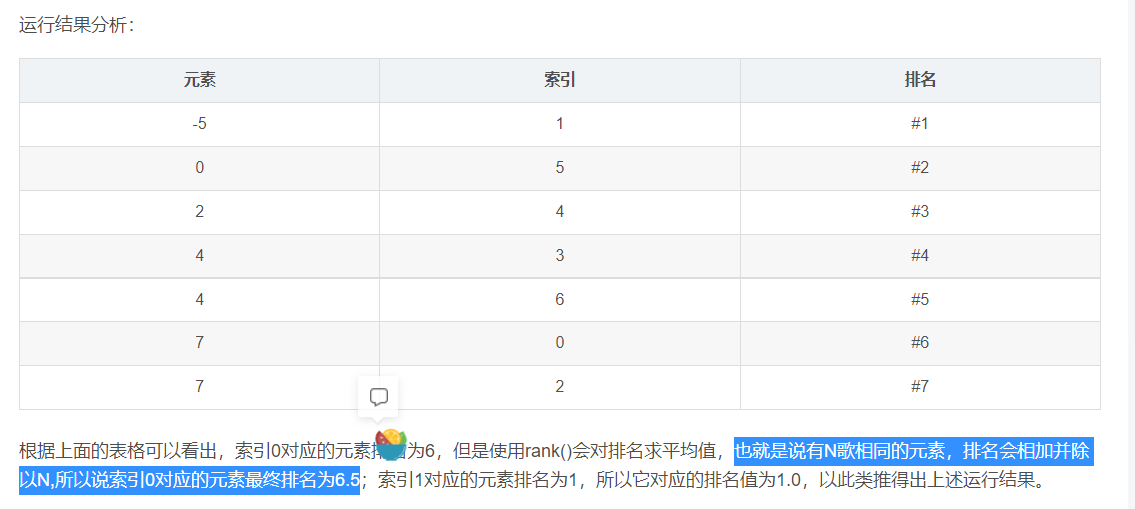
Series
1 | import numpy as np |
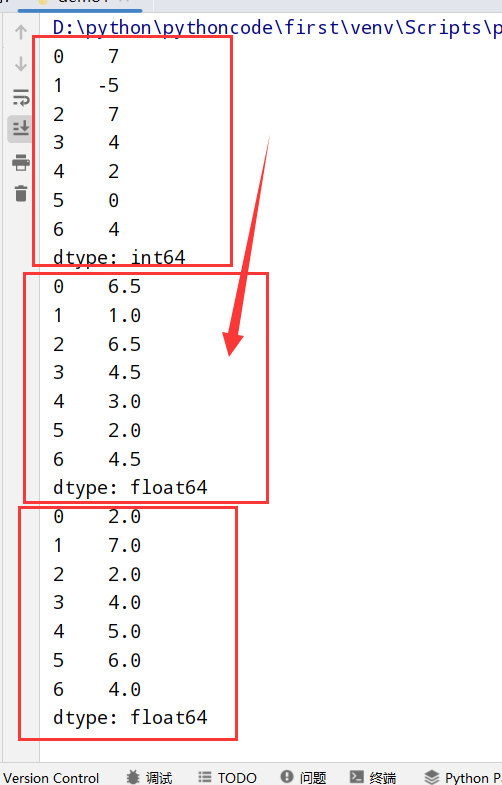
DataFrame
1 | import numpy as np |

Series
1 |
|
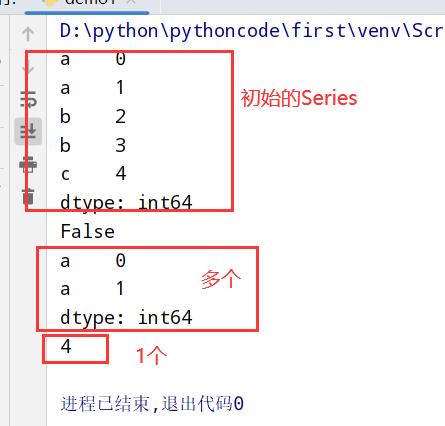
描述和汇总统计:

1 |
|
1 | 1.Series: |

1 | 1. obj.value_counts() |
NA处理方法

1 | 1.滤除: dropna() 默认丢弃任何含有Na的行 |

1 | import numpy as np |

1 | 1.swaplevel 根据两个级别的编号/名称 |
1 | 1.在统计和汇总(sum) --> sum(level='xxx') |
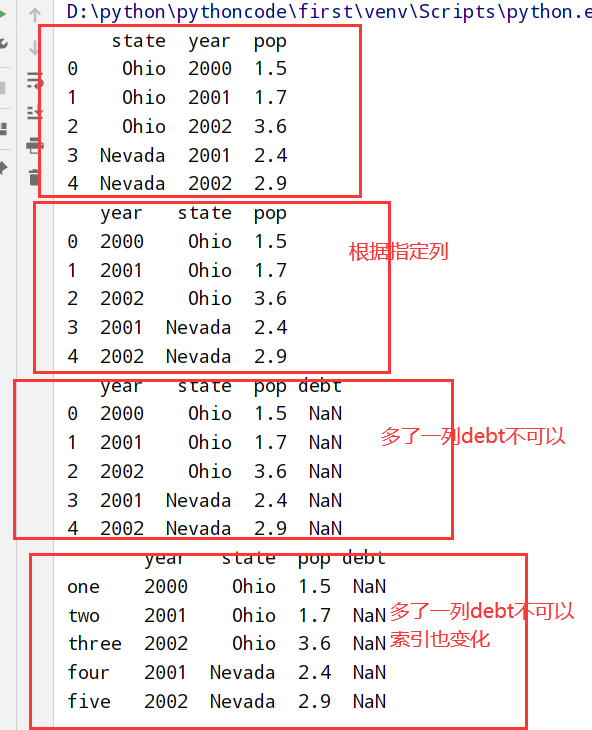
1 | 1.一个/多个列 --> 行索引 |
1 | 1.输入输出: |
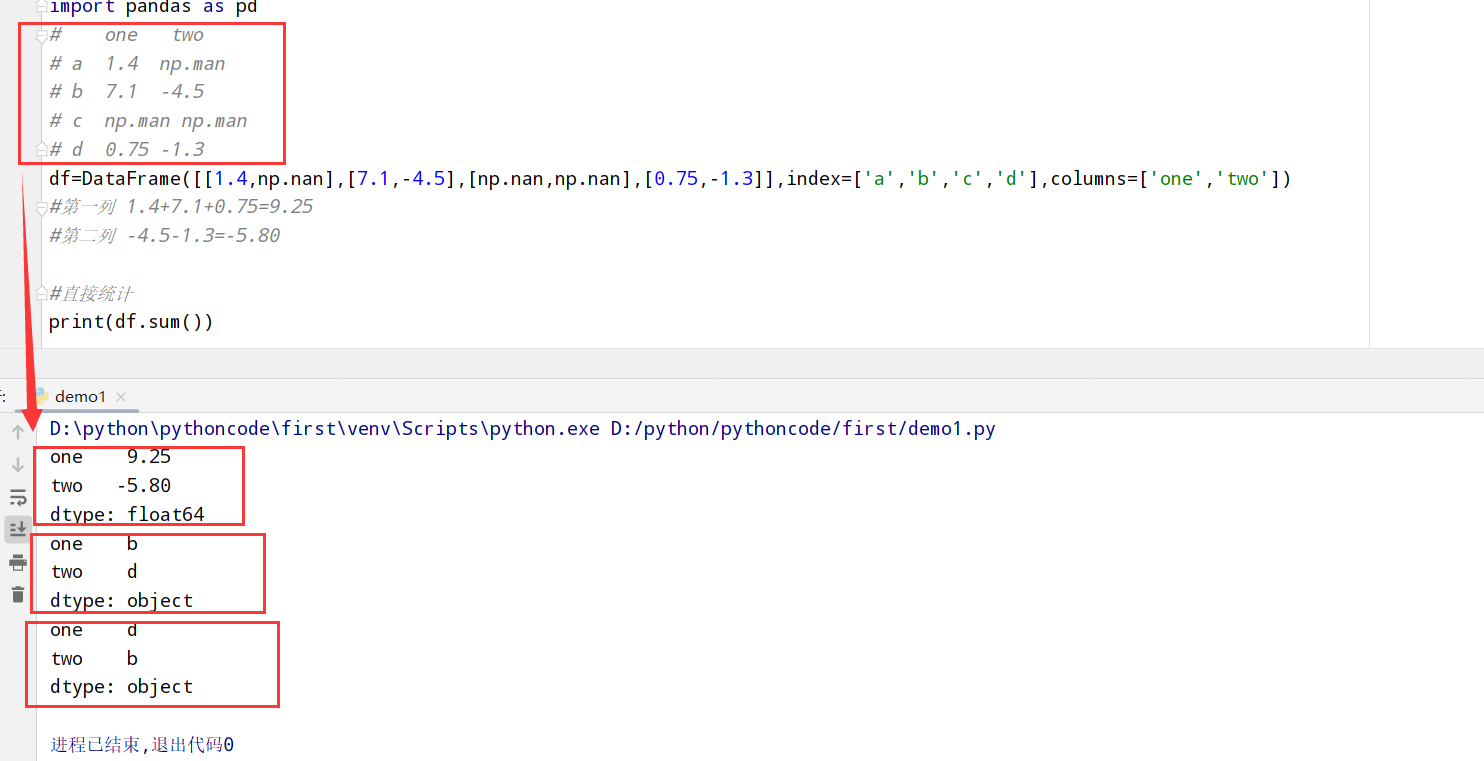
pandas解析函数
1 | 1. 表格型数据 --> DataFrame对象 |
read_csv/read_table函数的参数

1 | 1.pd.read_csv('xx.csv',nrows=xx) |
1 | 1.data.to_csv('xx.csv') # (默认) ,分隔符 |
Dialect属性:

1 |
|
1 |
|
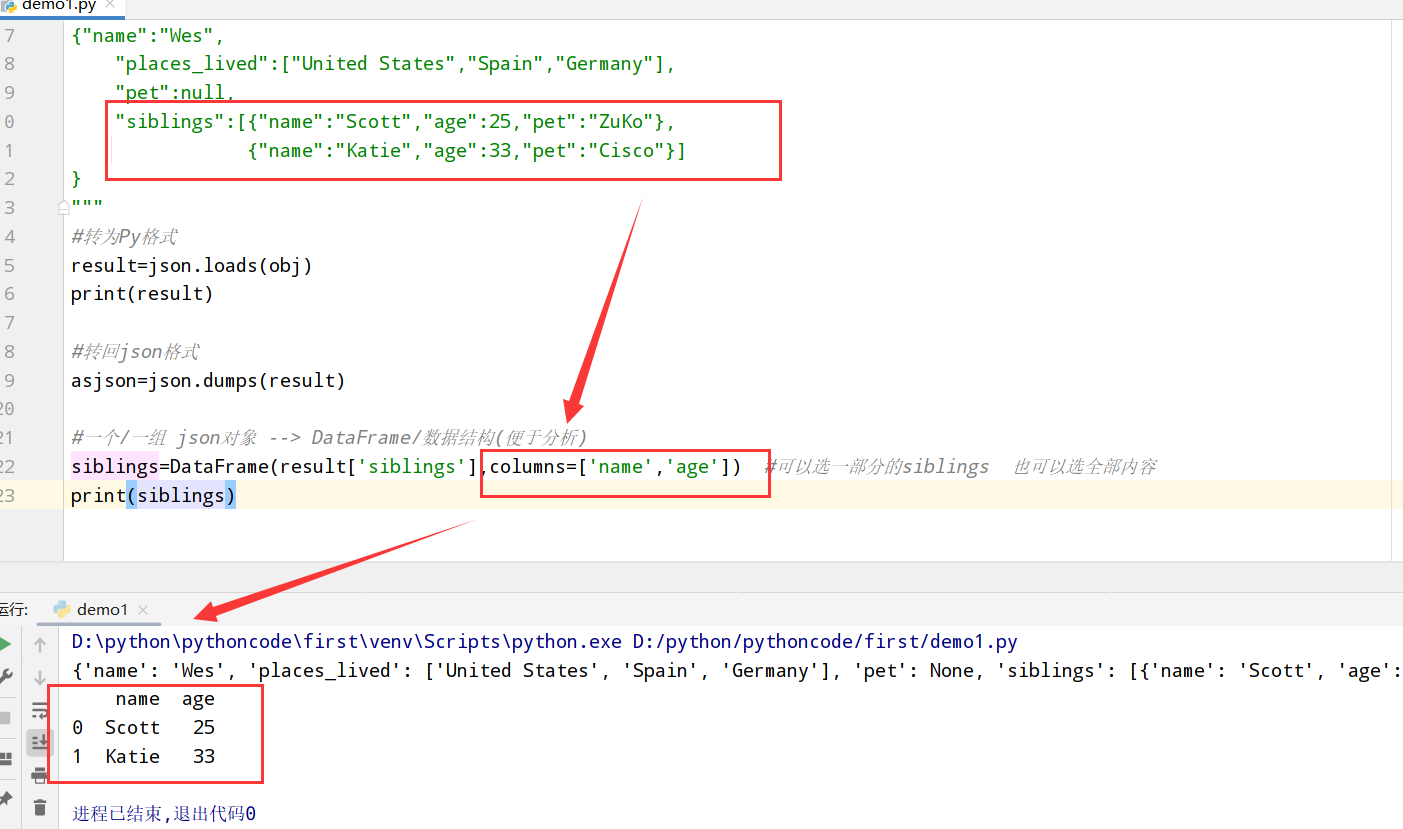
1 | 1.python有许多可以读写html和xml格式数据的库(比如:lxml) |
1 |
|
1 |
|
1 |
|
1 | #h5适合"一次写 多次读"的数据集 |
1 | #1.传入xls或xlsx文件 |
1 | import pandas as pd |
两种方式:
1 | 目前而言有两种方法: |
1 | import pandas as pd |

1 | import pandas as pd |
三种合并方法
1 | 1.pandas.merge 根据1个/多个键将不同的DataFrame中的行连接起来(像极了数据库连接操作 选几个行) |
merge函数参数

1 | import pandas as pd |

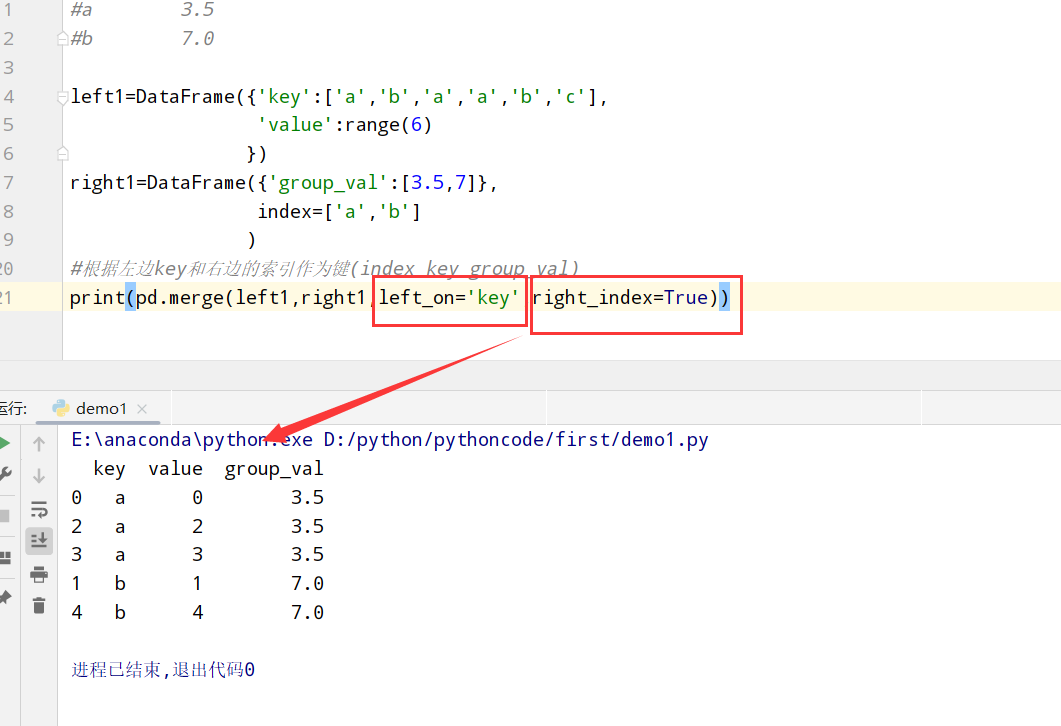
1 | 1.普通索引: 设置left_index或者right_index=True表明索引作为连接键 |
代码举例:
1 | import pandas as pd |
concat函数参数

1 |
|

方法总结
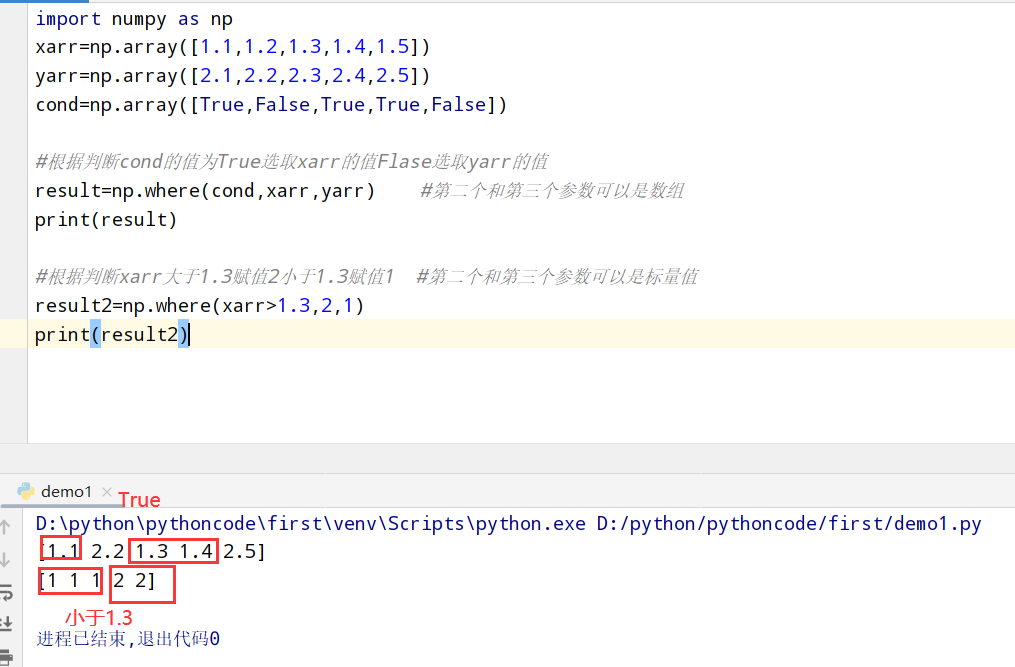
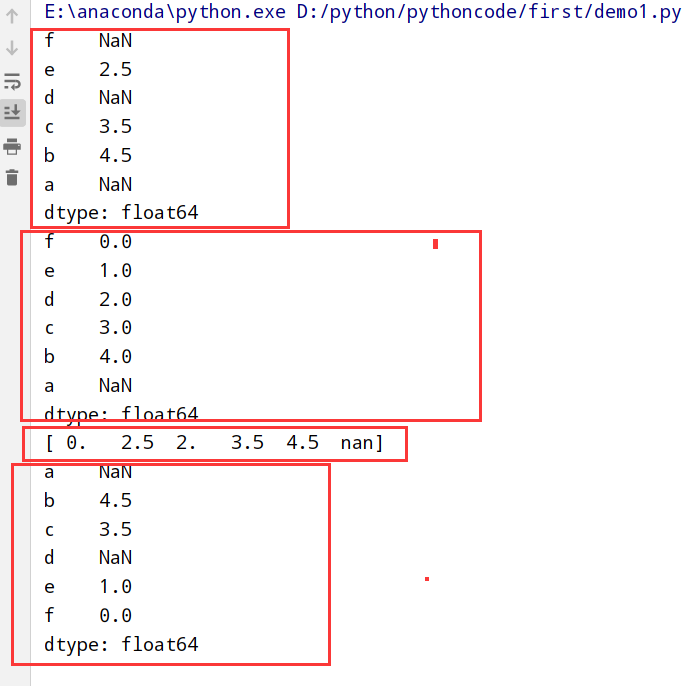
1 | 1. numpy中的where方法 |
1 | import pandas as pd |
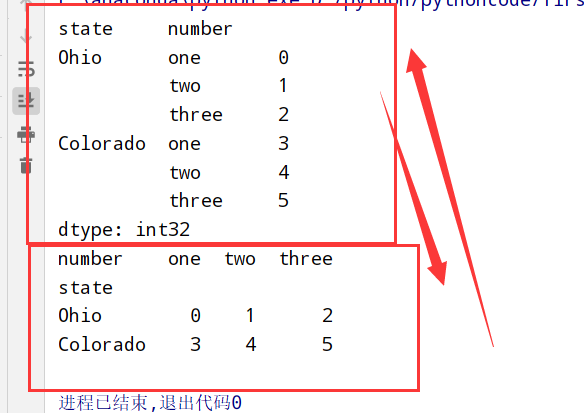
1 | 1.重塑 reshape方法 |
1 | 1.stack: 将数据的列"旋转"为行 【列-->行】 |
1 | import pandas as pd |
概述
1 | 1.时间序列数据[长格式(long)/堆叠格式(stacked)]存储在数据库和CSV |
1 |
|

1 | import pandas as pd |
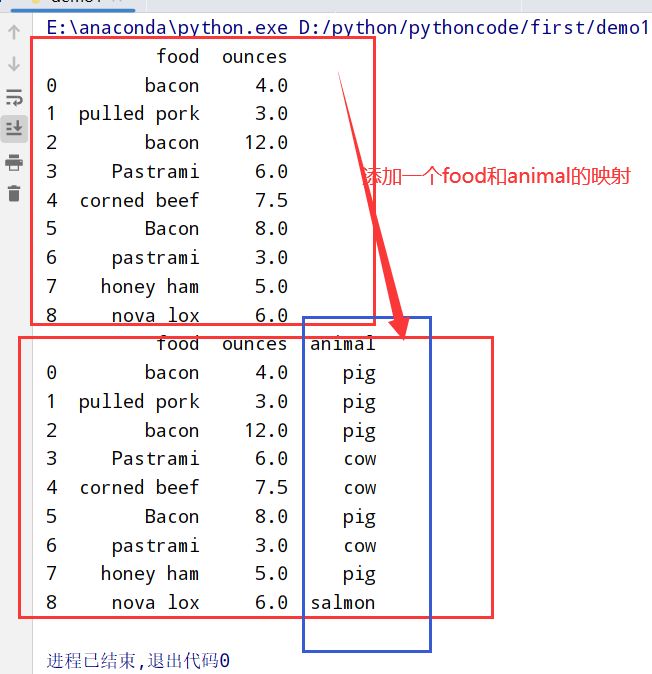
1 | import pandas as pd |
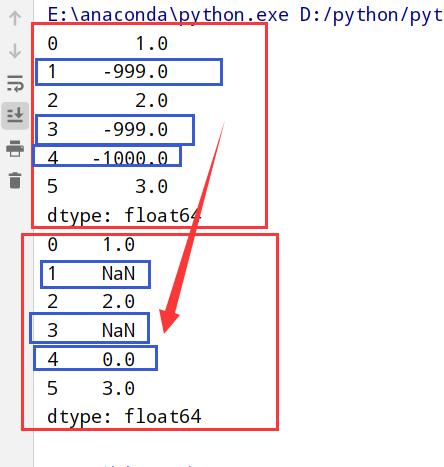
1 | import pandas as pd |
1 | import pandas as pd |
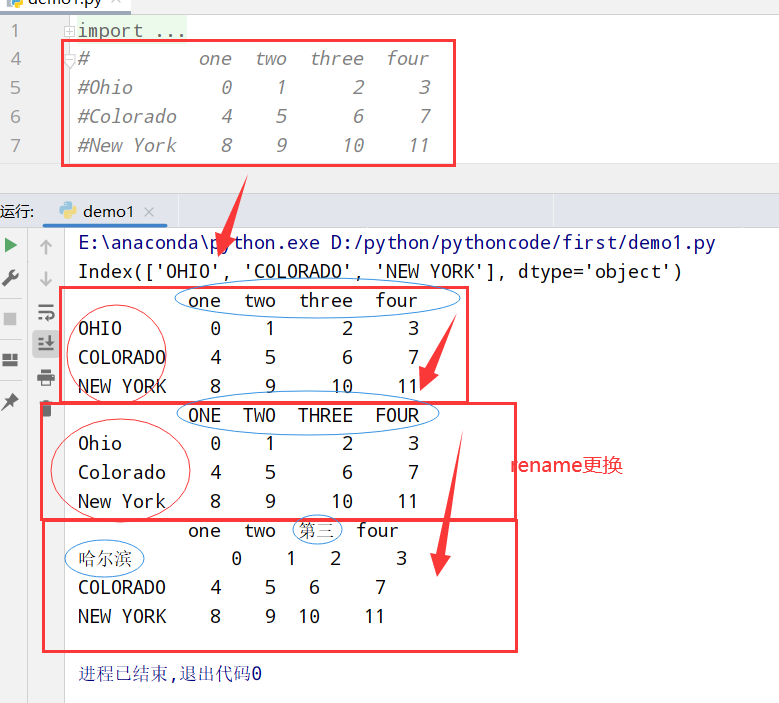
1 | import pandas as pd |
1 | import pandas as pd |
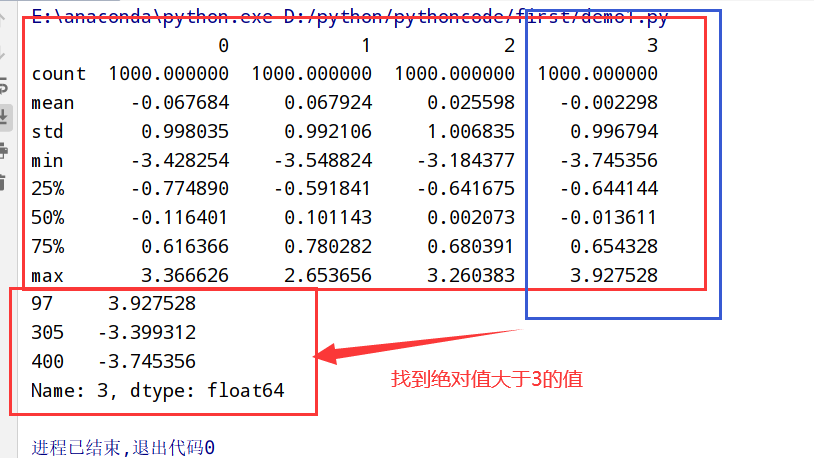
1 | import pandas as pd |

1 | 1.分类变量(categorical variable) --> 哑变量矩阵(dummy matrix)/指标矩阵(indicator matrix) |
1 | import pandas as pd |

py内置的字符串方法

1 | import pandas as pd |

1 | 1.py内置的re模块负责对字符串应用正则表达式 |


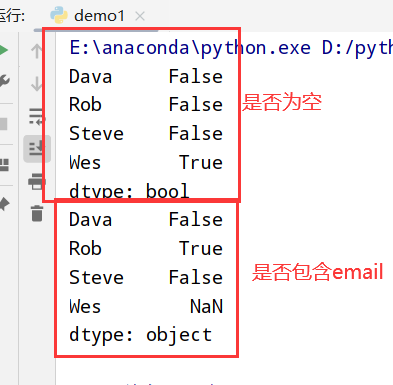
1 | import pandas as pd |
1 | 1.matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面) |
1 | import numpy as np |
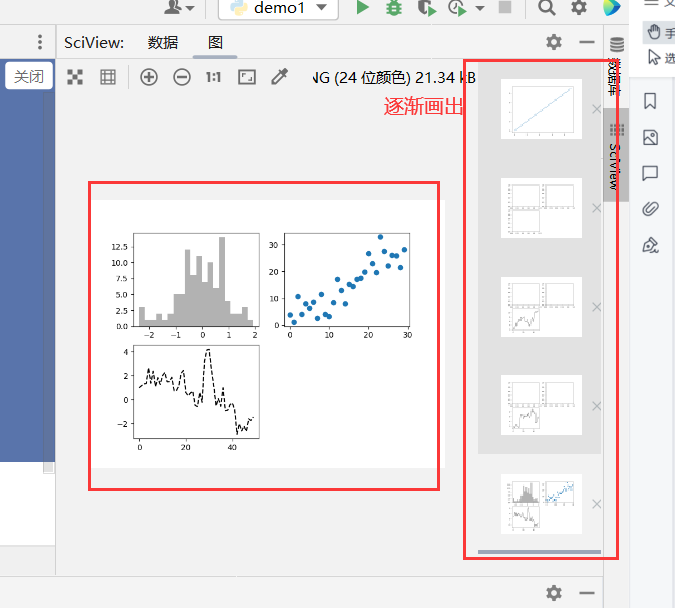

1 | import numpy as np |
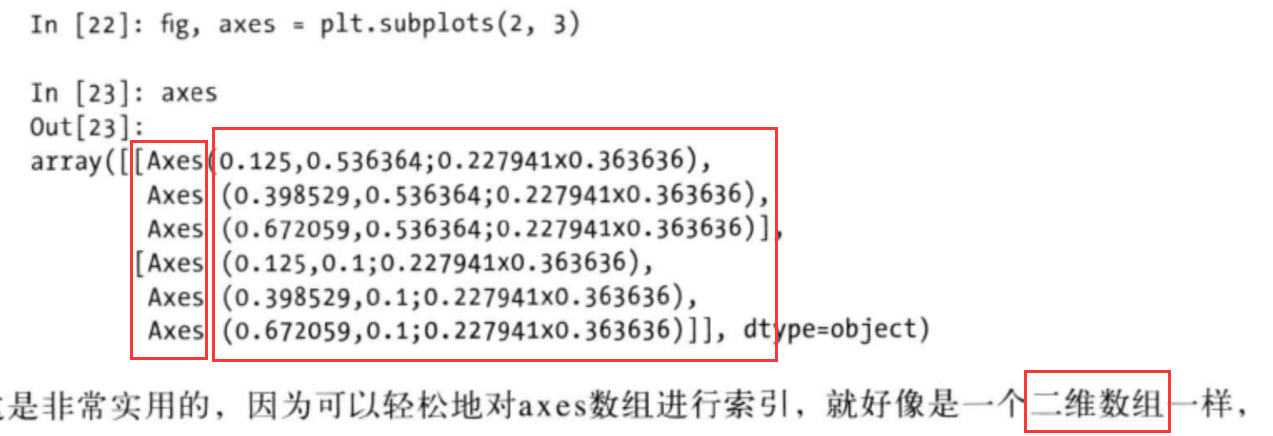
1 | # wspace和hspace用于控制宽度和高度的百分比(用作subplot之间的间距) |
1 | import numpy as np |
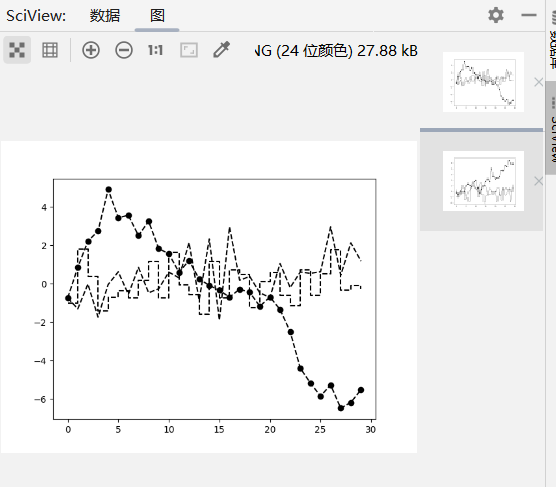
1 | 大多数的图表装饰项: |
1 | import numpy as np |
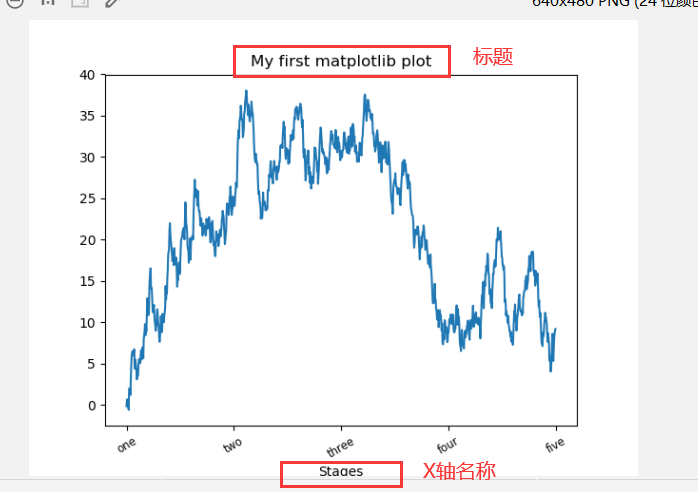
1 | import pandas as pd |
1 | 1.matplotlib有一些表示常见图形的对象(对象被称为块[patch]) |
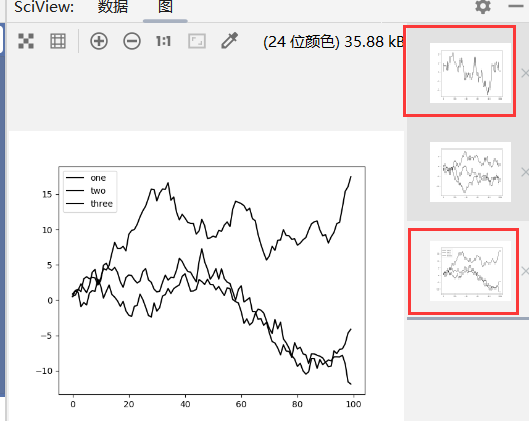
1 | import pandas as pd |
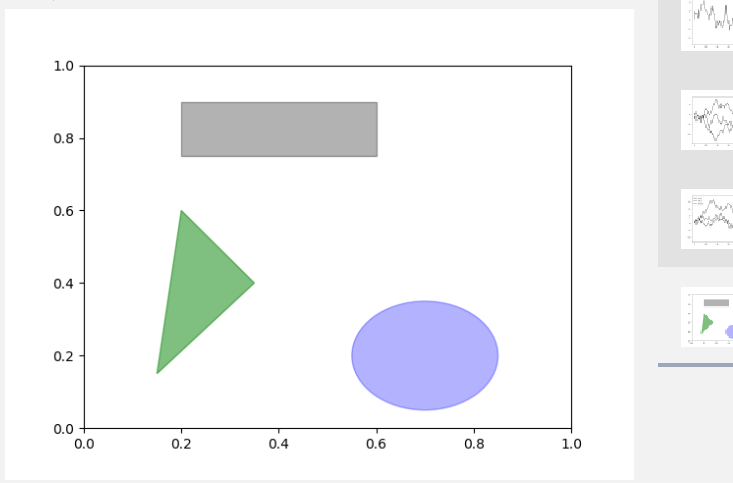
1 | import numpy as np |

1 | 操作matplotlib配置系统的方式 |
1 | 1.Series和DataFrame都有一个用于生成各类图表的plot方法(默认是线形图) |
Series的plot参数:

DataFrame的plot参数:
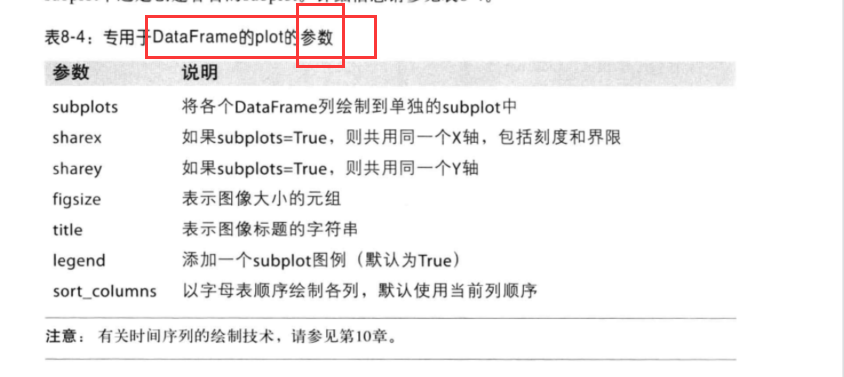
1 | import pandas as pd |
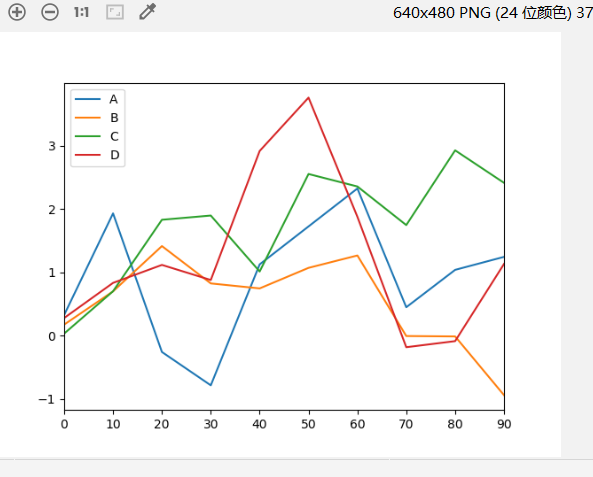
1 | 1.Series.plot( 设置kind='bar'(垂直柱状图) / kind='barh'(水平柱状图) ) |
1 | import numpy as np |
1 | 1.直方图(histogram):是一种可以对值频率进行离散化显示的柱状图[数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量] |
1 | tips['tip_pct']=tips[tip] / tips['total_bill'] |
1 | 1.散布图(scatter plot):是观察两个一维数据序列之间的关系 |
1 | 1.Chaco: 静态图+交互式图形 |
1 | 1.分组(split) : pandas对象(Series/DataFrame) --> 根据一个/多个键拆分(split)为多组 [对象特定轴上执行的,DataFrame可以在其行(axis=0)其列(axis=1)进行分组] |
流程:
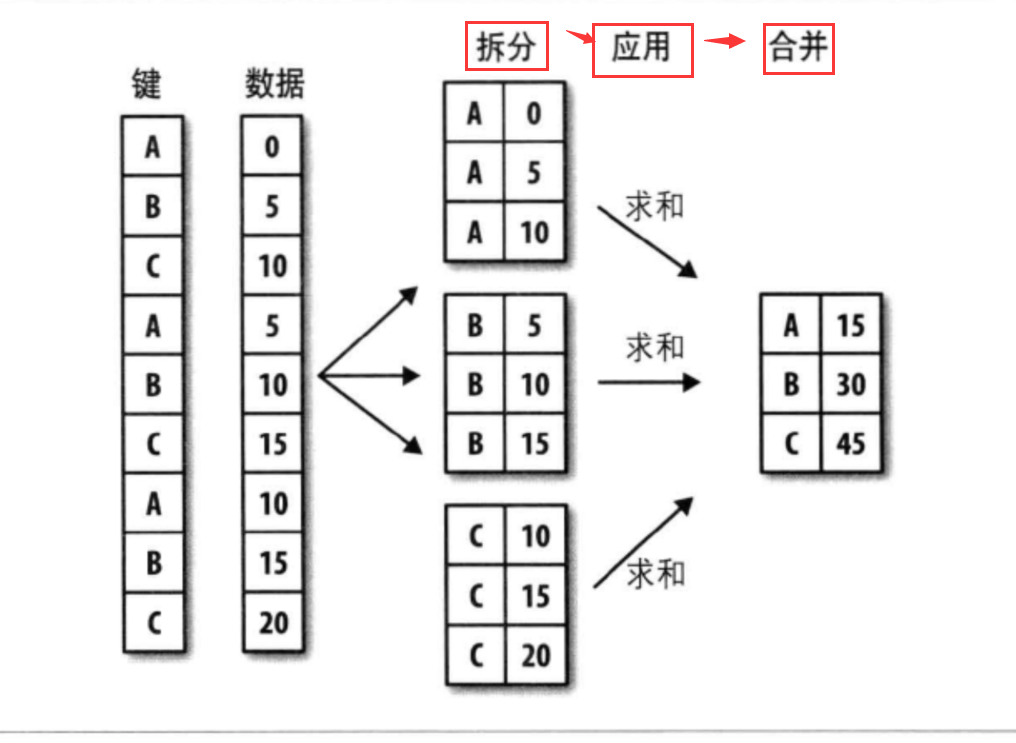
1 | import pandas as pd |
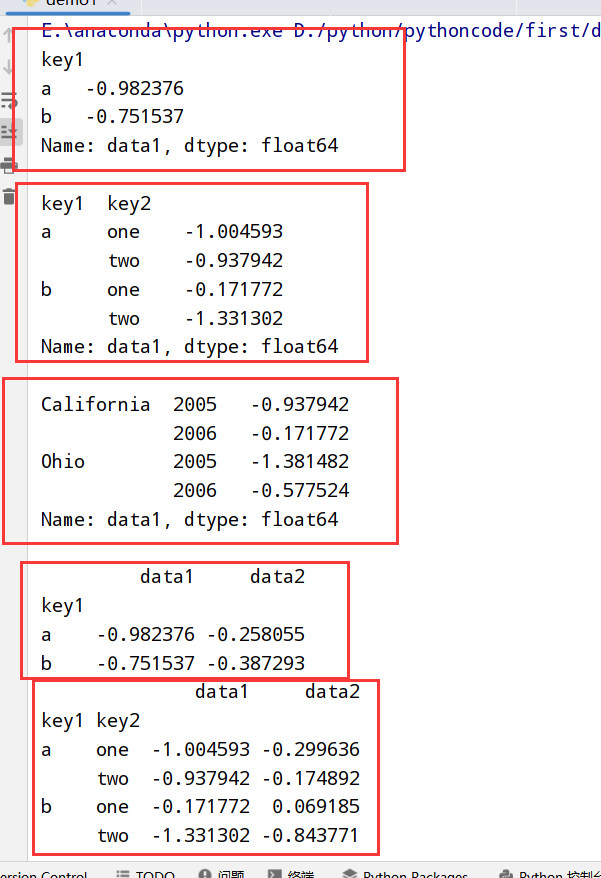
1 | 1.GroupBy对象支持迭代 --> 一组二元元组(分组名+数据块) |
执行结果:
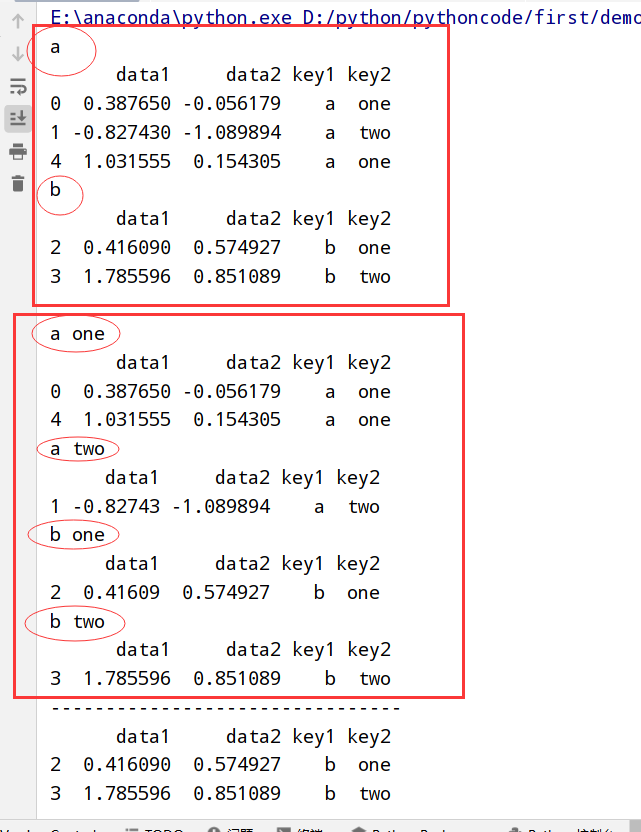

1 | #两种转换 |
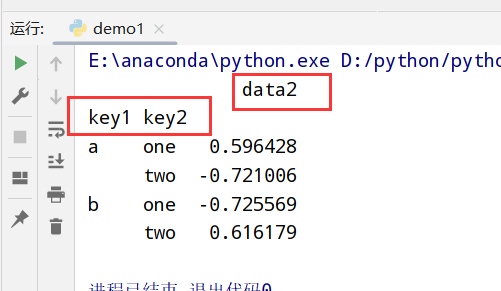
1 | import pandas as pd |
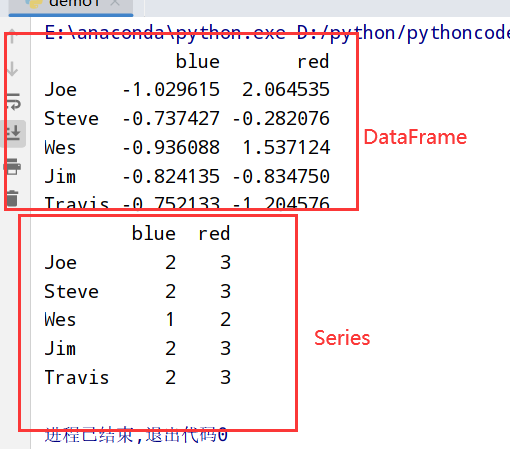
1 | import pandas as pd |
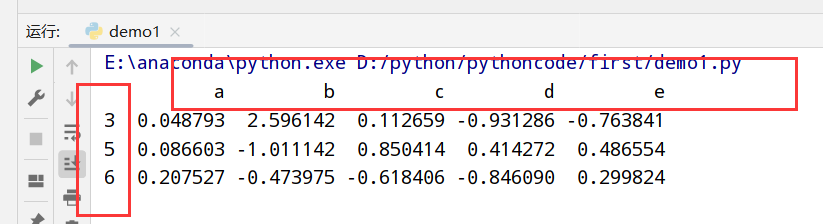
1 | import pandas as pd |
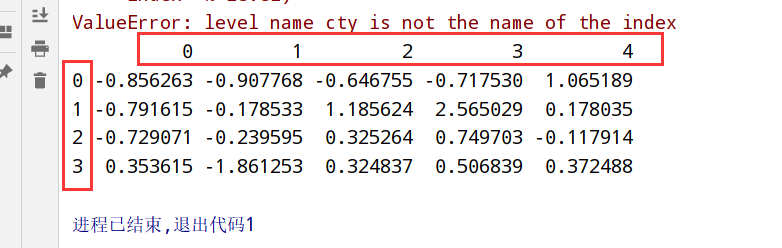
groupby聚合函数

1 | import pandas as pd |
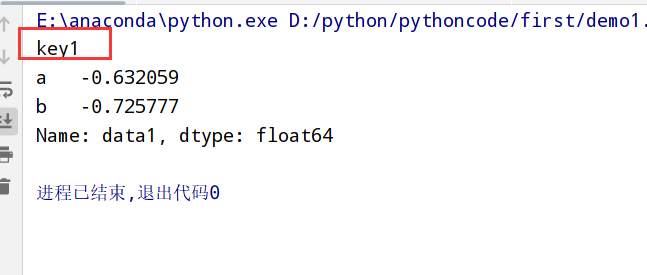
1 | import pandas as pd |
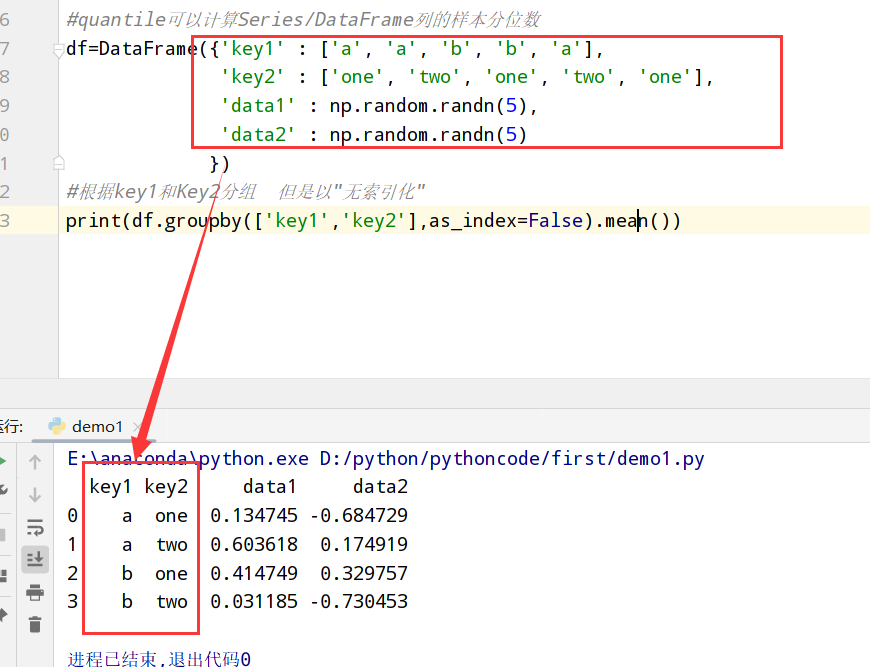
1 | import pandas as pd |
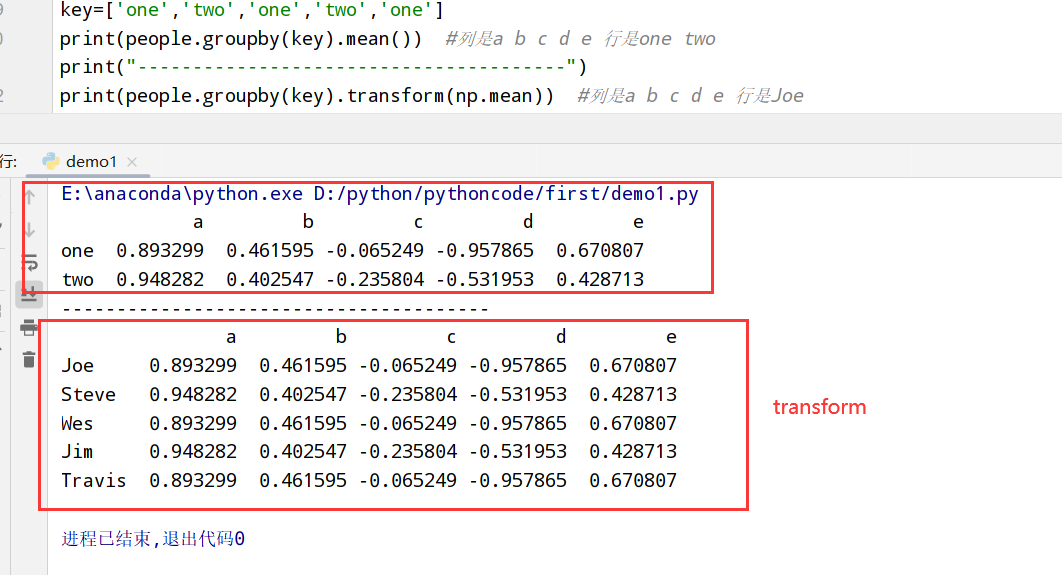
1 | data.groupby('key1',group_keys=False).apply(top) |
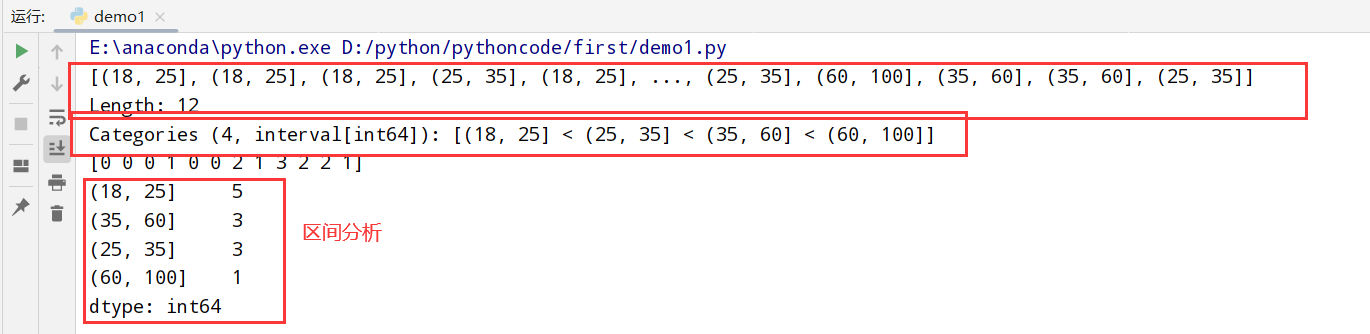
1 | 1.pandas有一些能根据指定面元/样本分位数-->数据拆分为多块的工具(cut和qcut) |
两种不同的分别方法(cut和qcut):
1 | import pandas as pd |
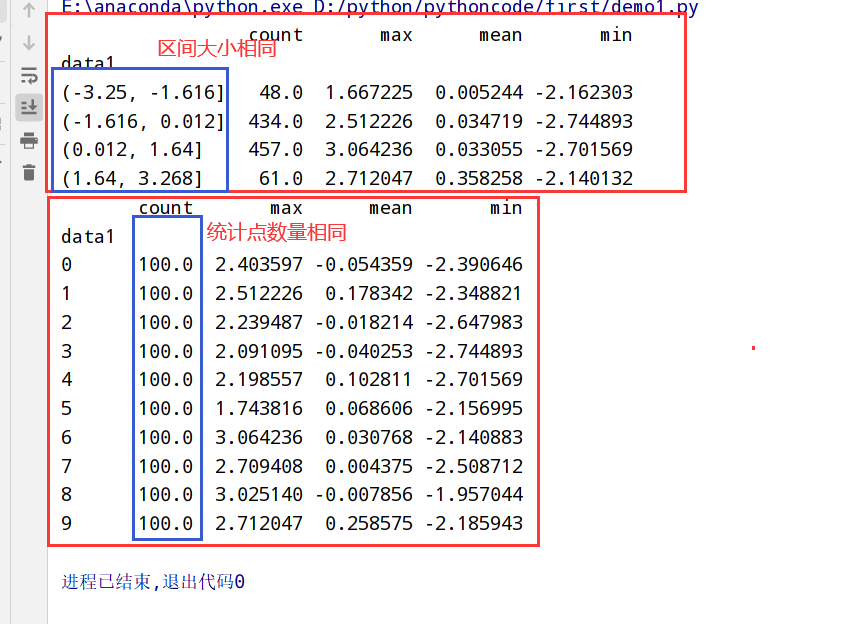
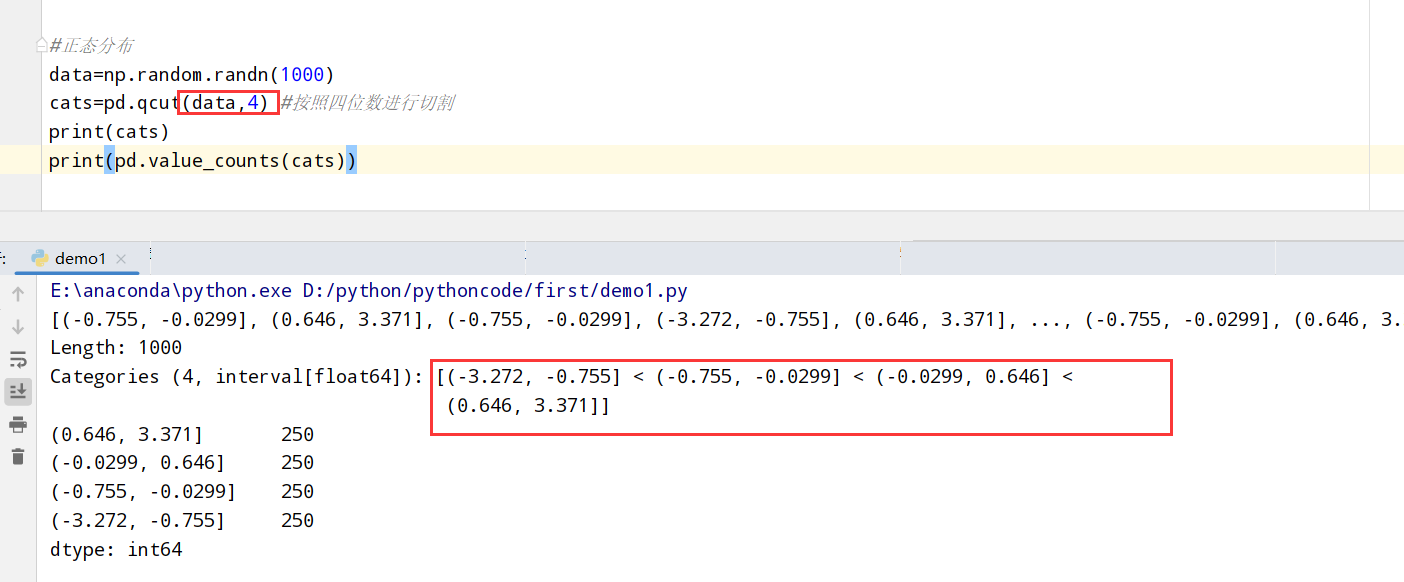
1 | import pandas as pd |

1 | import pandas as pd |
pivot_table参数:

1 | 透视表: |
1 | 具体应用场景: |
1 | 1.python标准库:日期(data)、时间(time)数据的数据类型、日历方面的功能 |
datetime模块中的数据类型

1 | import datetime |
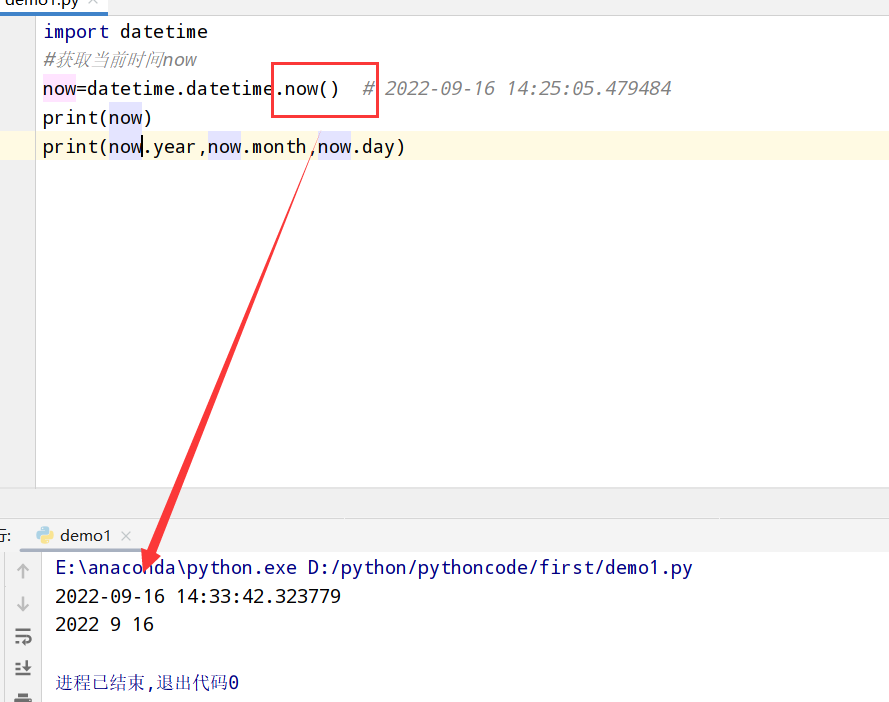
datetime格式定义:

1 | import datetime |
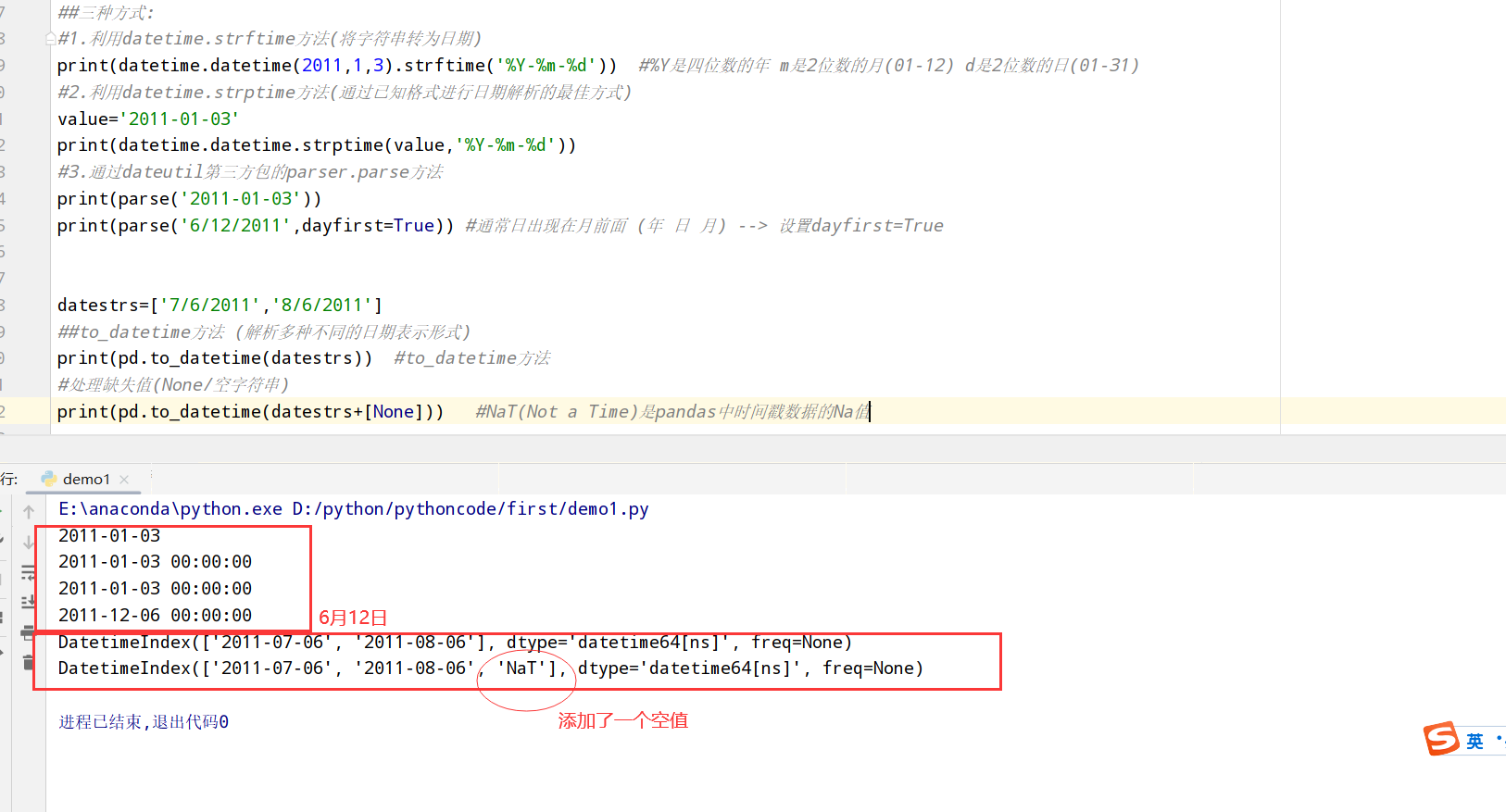
索引更换为datetime数据
1 | import datetime |
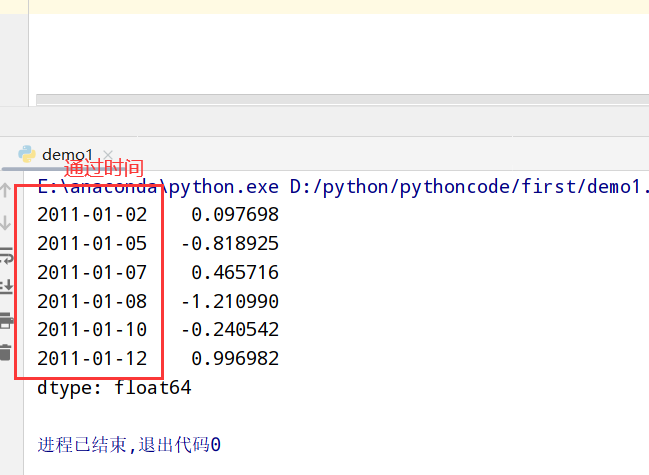
1 | import datetime |
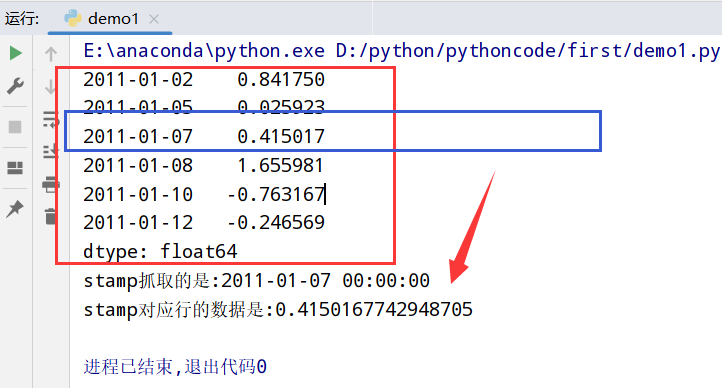
1 | import datetime |
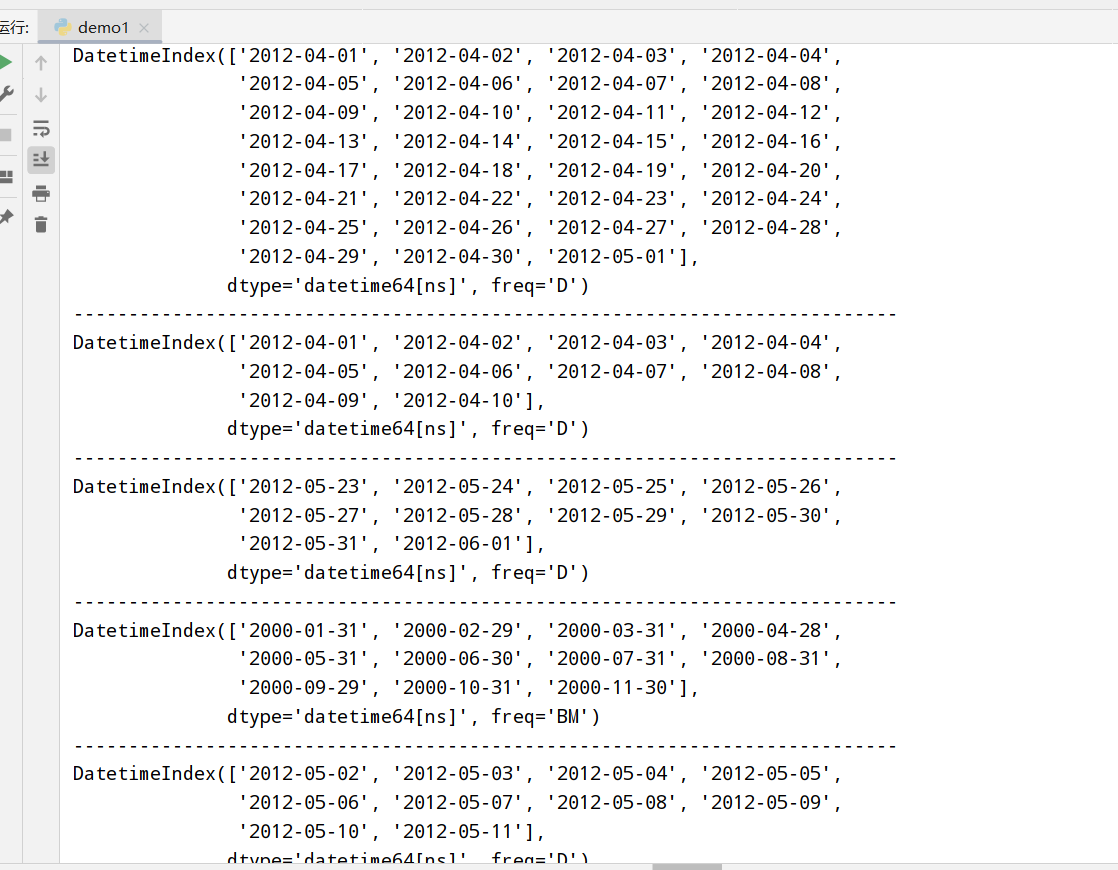
时间序列的基础频率

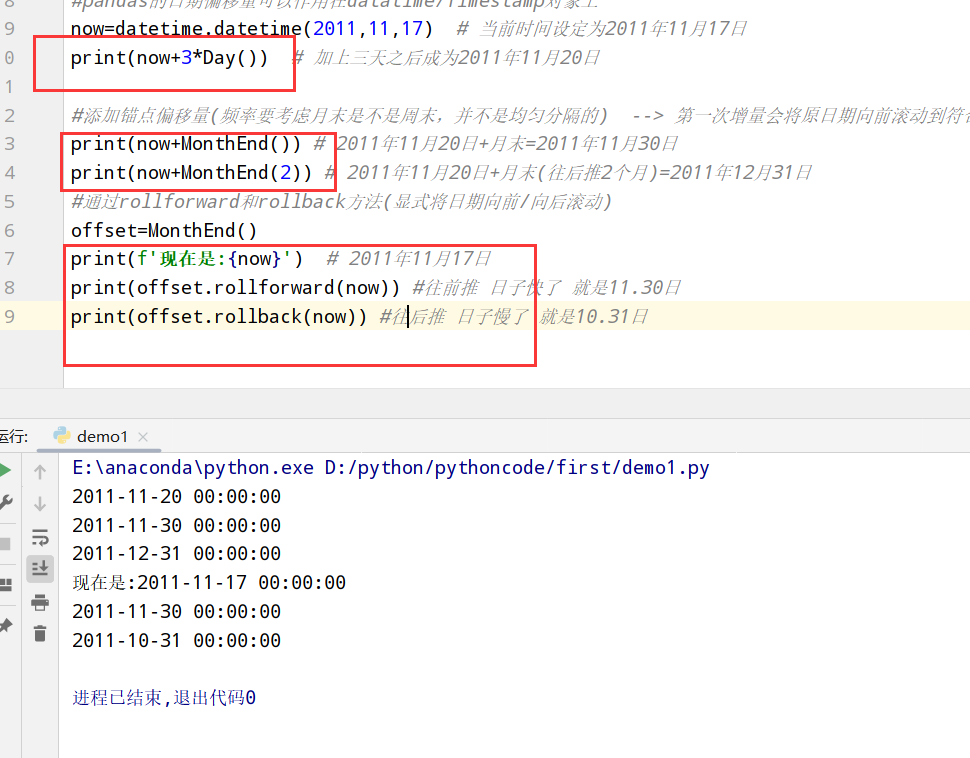
1 | import datetime |
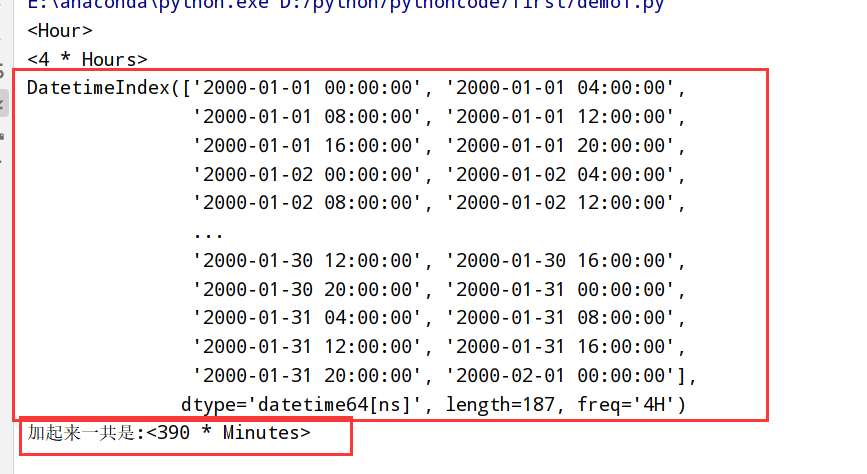
1 | import datetime |
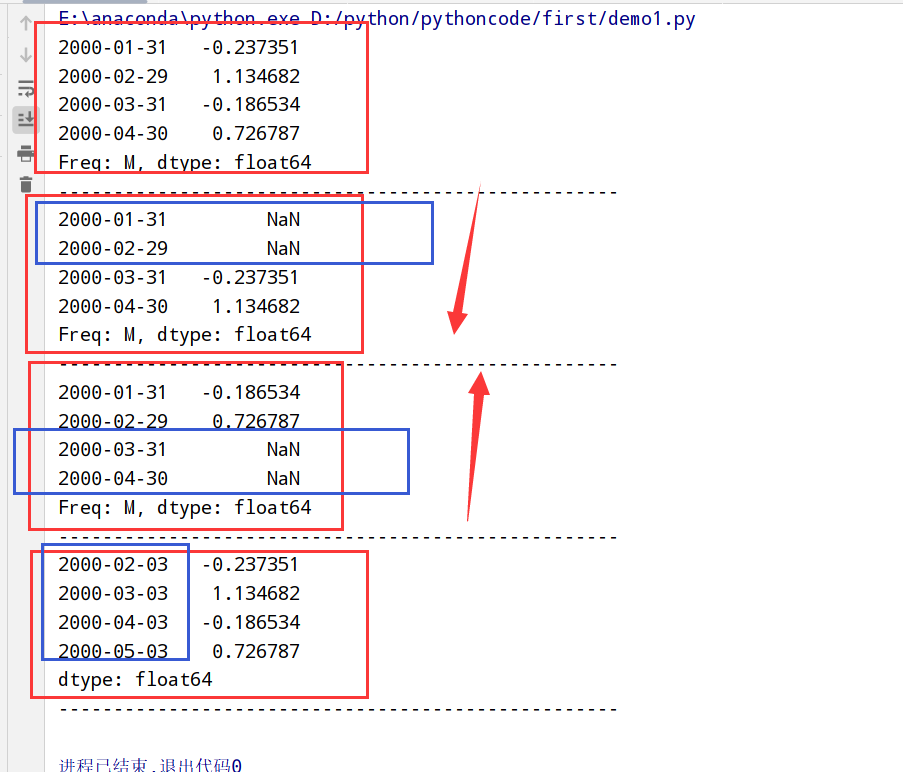
1 | import datetime |
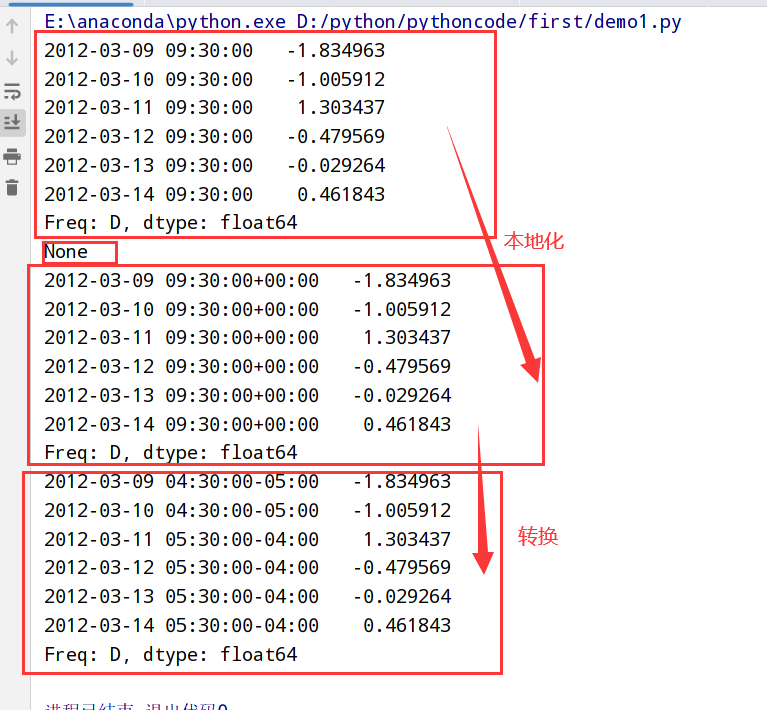
1 | 1.在Python中时区信息来自第三方库pytz --> 使得Python可以使用Olson数据库(汇编了世界时区信息) |
pandas中的方法可以接受时区名(建议)/对象
1 | import pytz |

1 | import datetime |
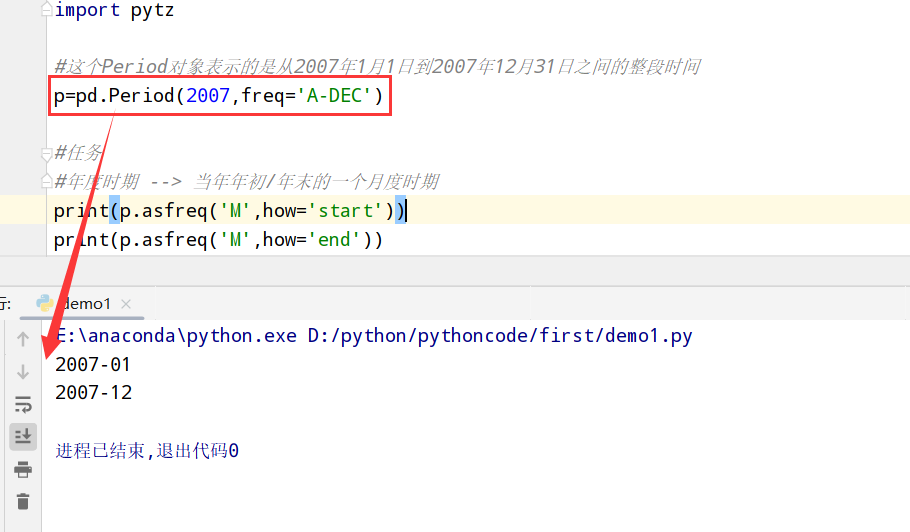
1 | 1.时期:时间区间(比如:数日,数月,数季,数年等) |
Period类
1 | import datetime |

1 | import datetime |
1 | index=pd.PeriodIndex(xxx,freq='Q-DEC') |
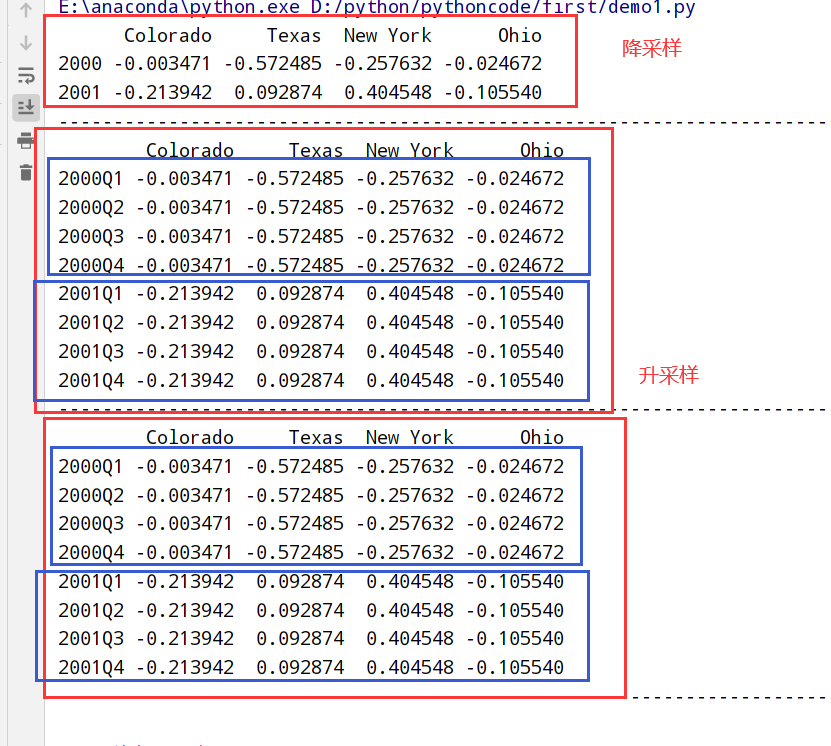
1 | 重采样(resampling):将时间序列从一个频率 --> 另一个频率的处理过程 |
resample方法的参数

1 | import datetime |
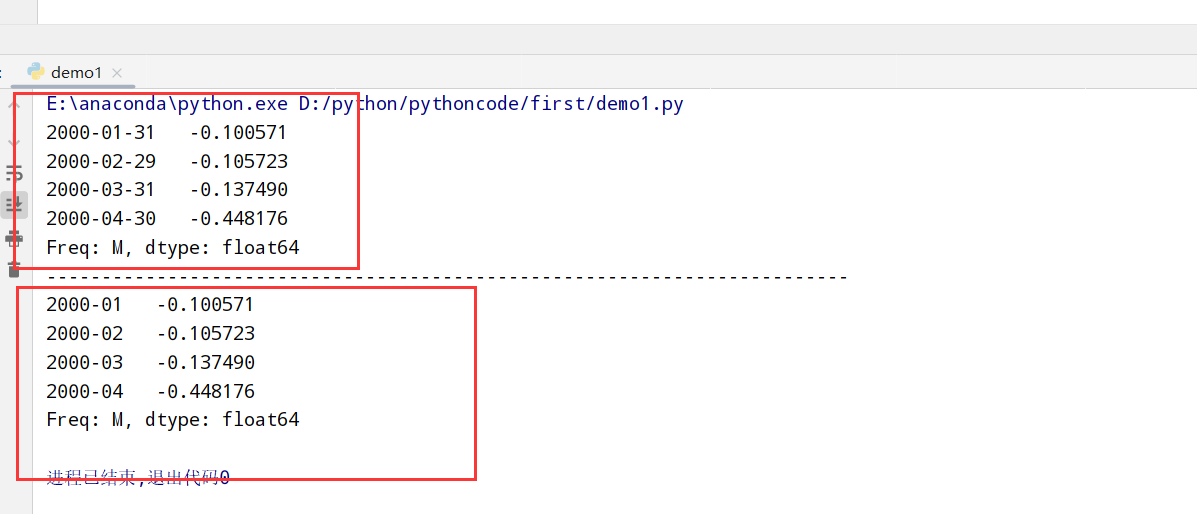
1 | import datetime |
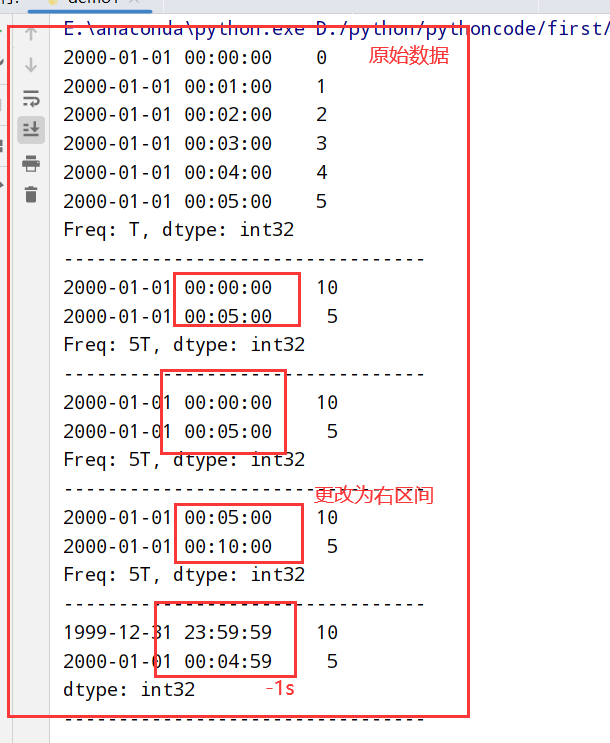
1 | import datetime |
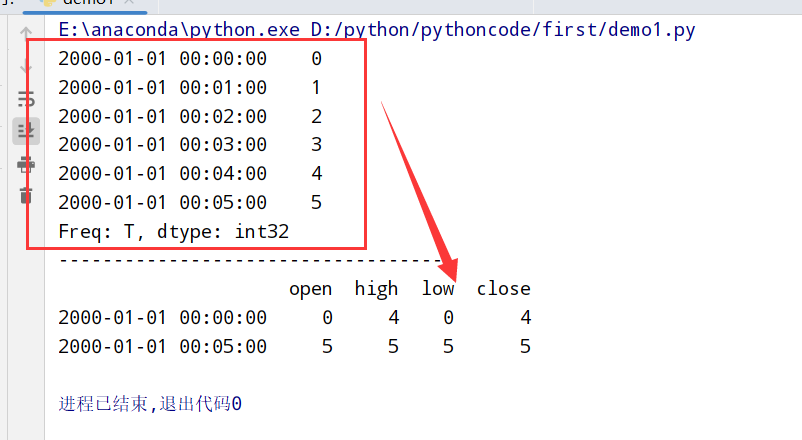
1 | import datetime |
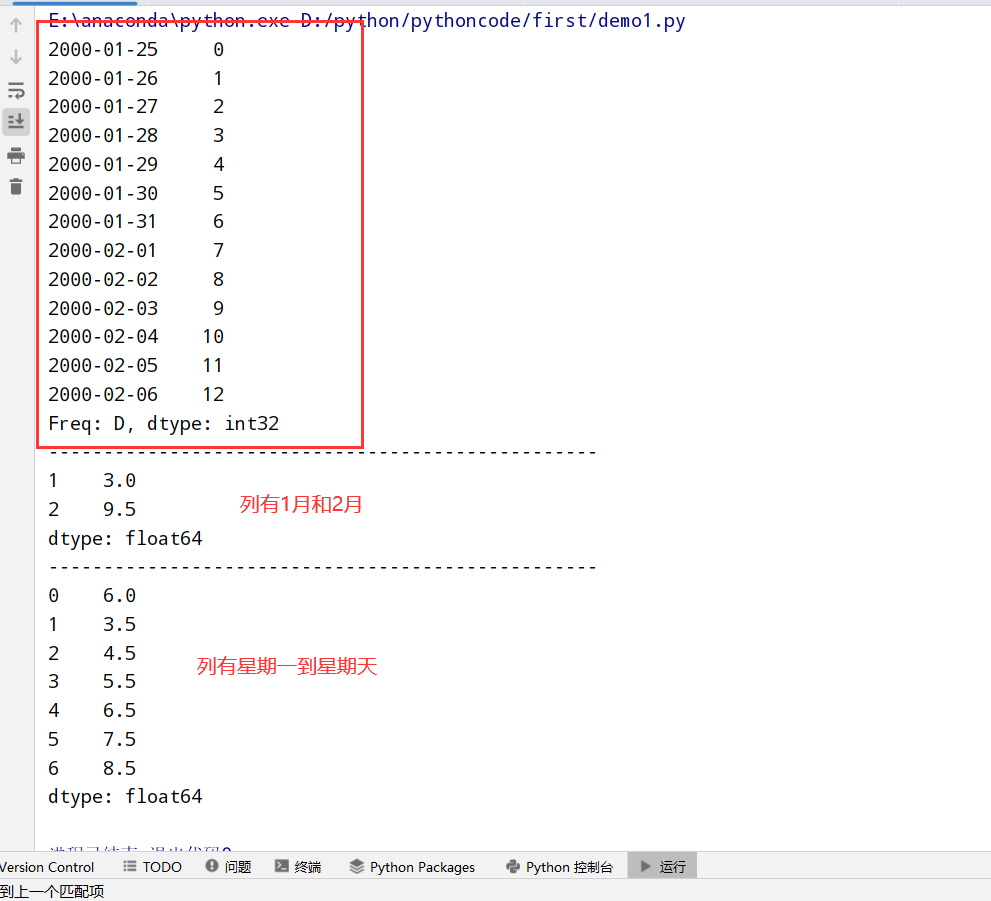
1 | import datetime |
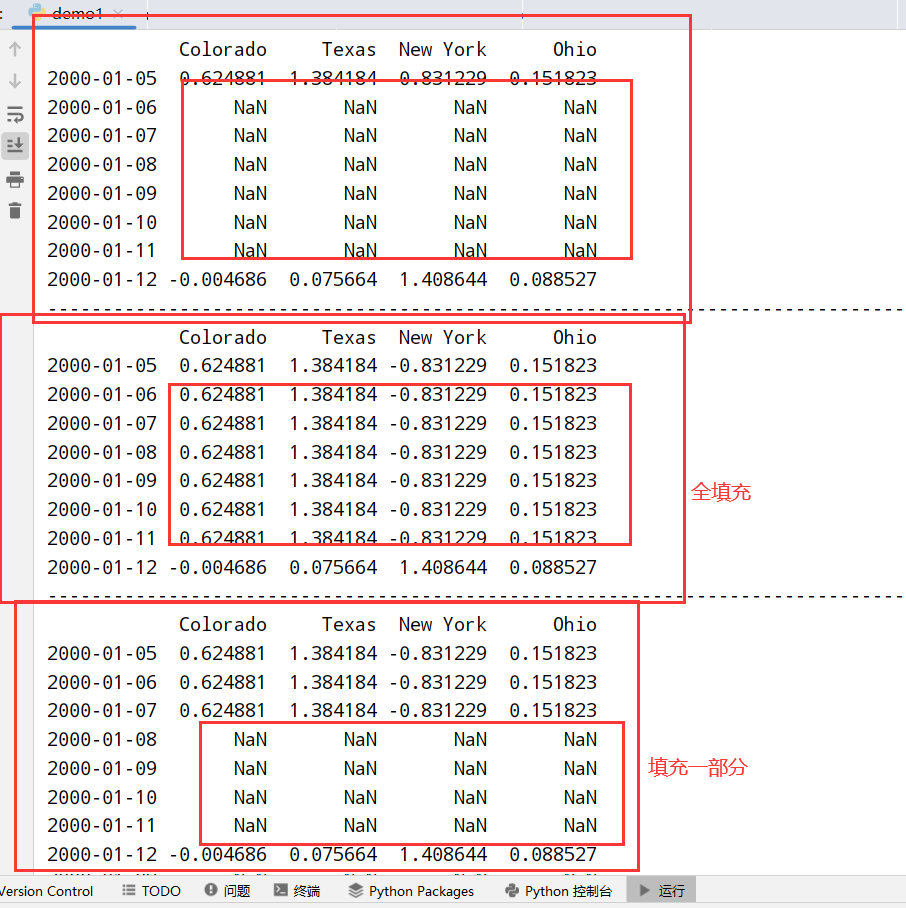
1 | import datetime |
移动窗口和指数加权函数:

具体代码
1 |
|
执行结果
具体代码
1 |
|
执行结果
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
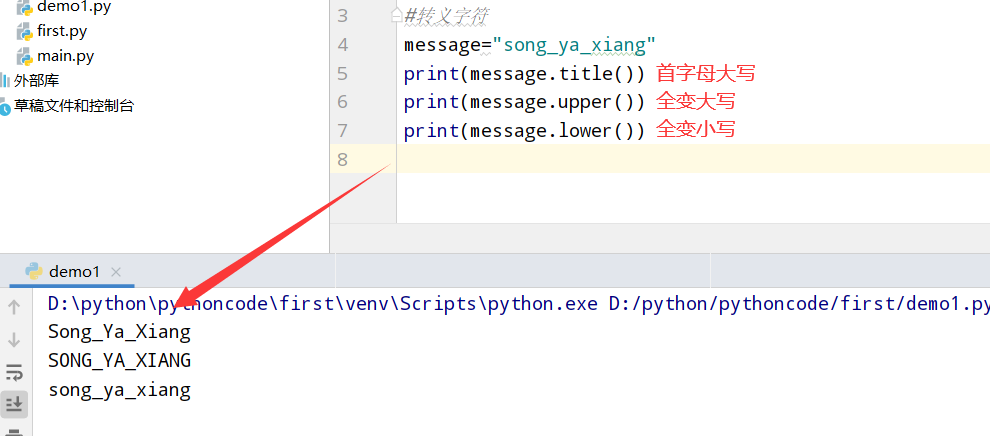
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
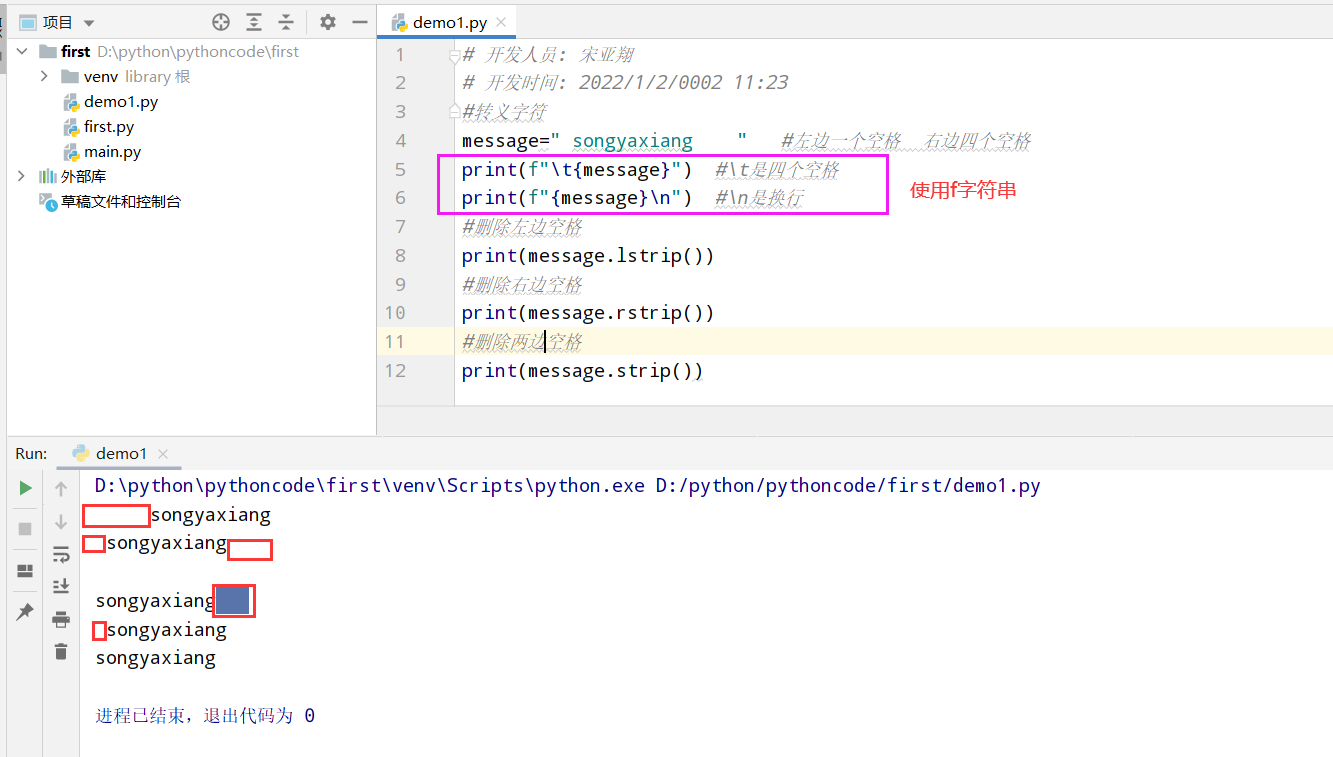
具体代码
1 |
|
执行结果
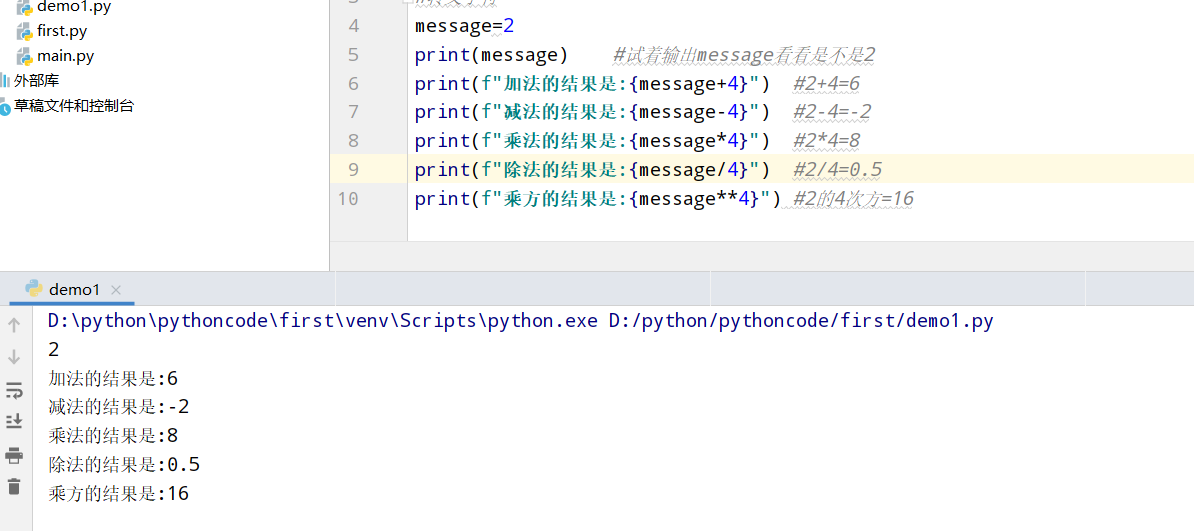
具体代码
1 |
|
执行结果
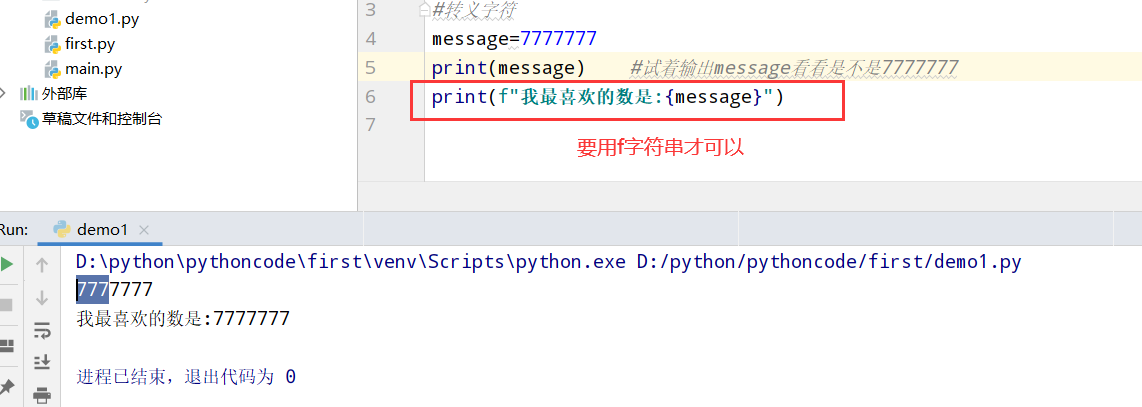
具体代码
1 |
|
执行结果
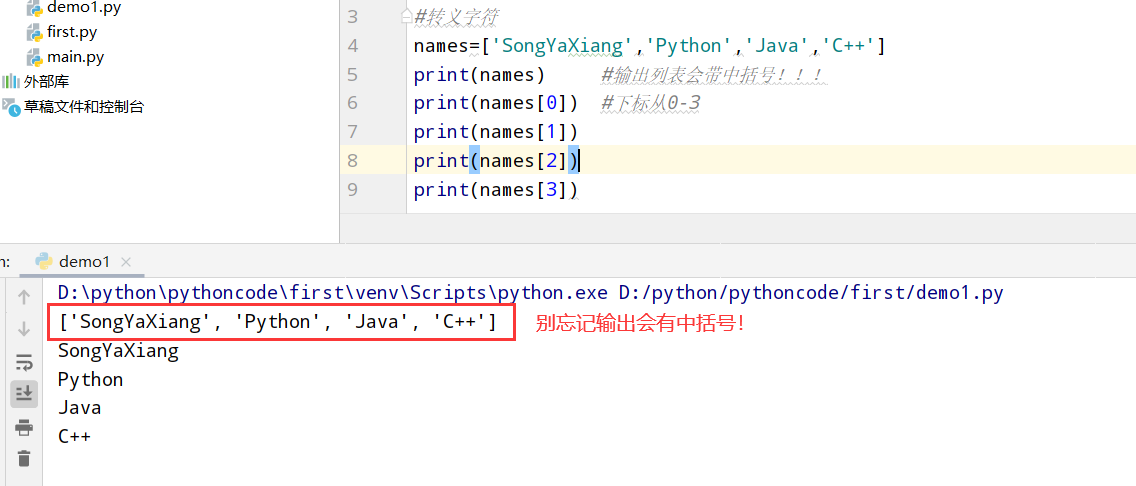
具体代码
1 |
|
执行结果
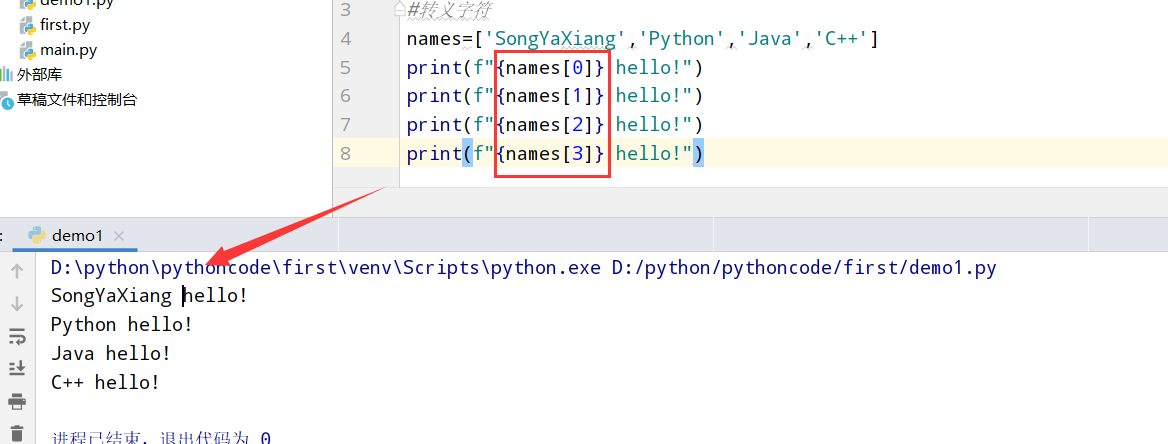
具体代码
1 |
|
执行结果
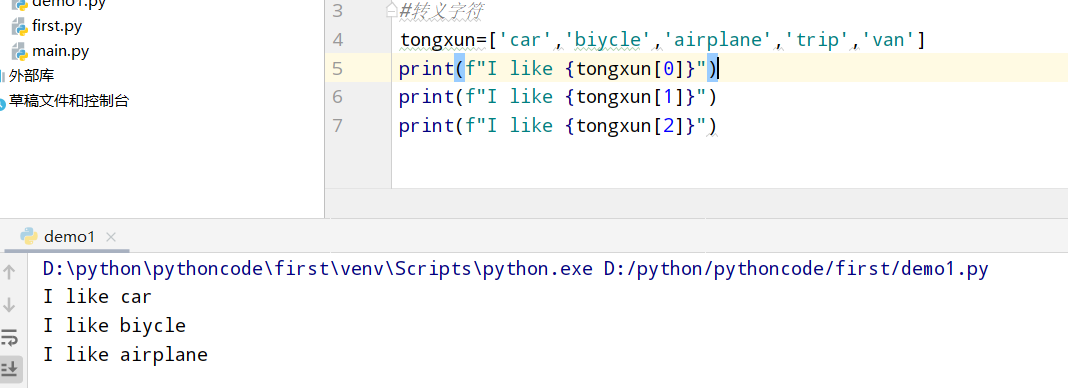
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
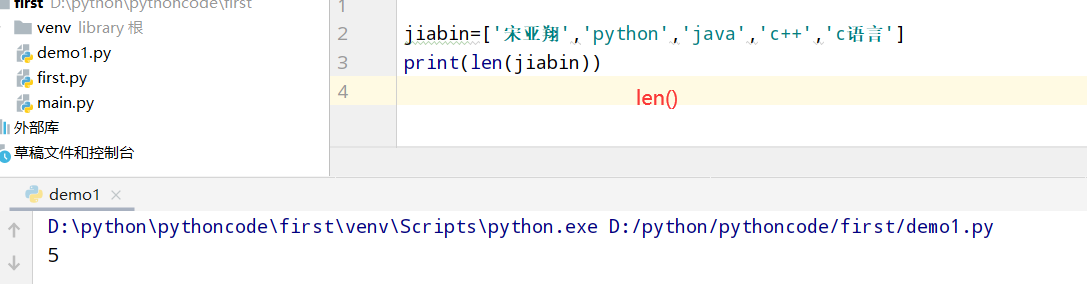
具体代码
1 |
|
执行结果
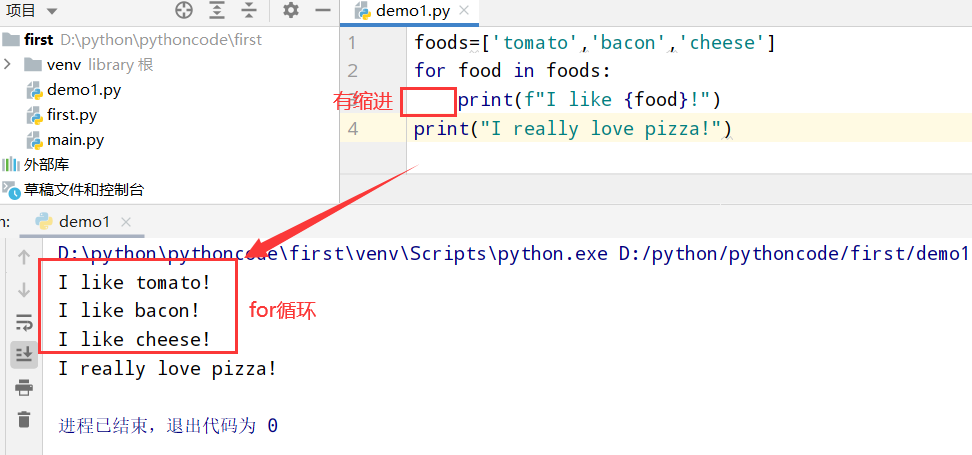
具体代码
1 |
|
执行结果
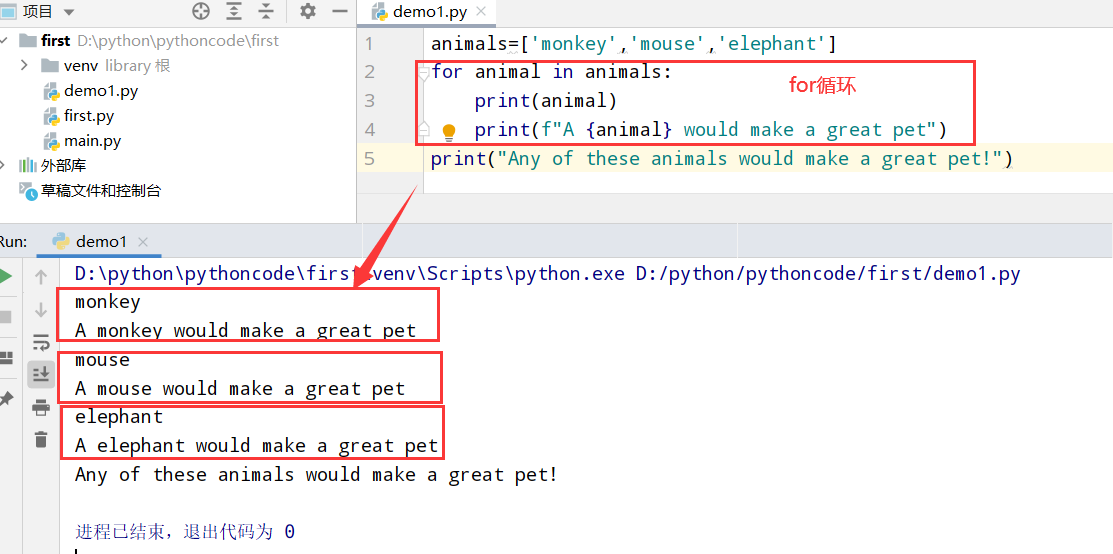
具体代码
1 |
|
执行结果
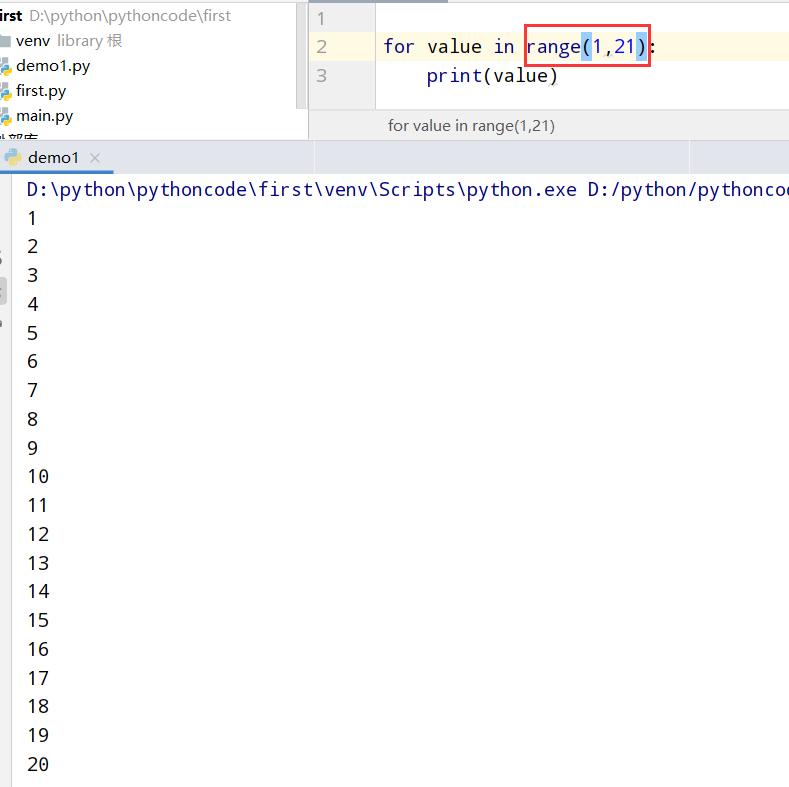
具体代码
1 |
|
执行结果
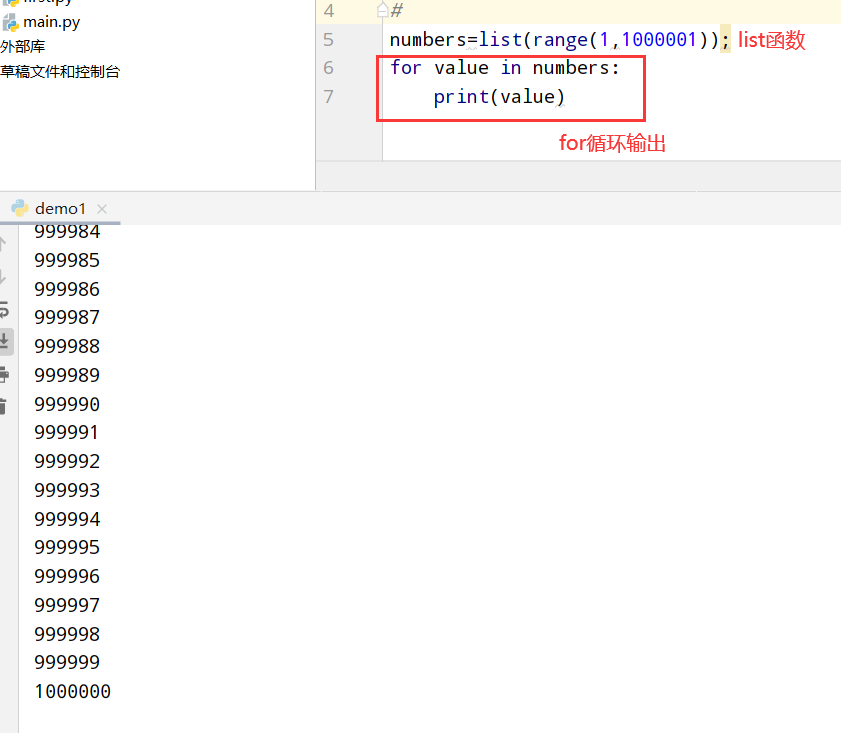
具体代码
1 |
|
执行结果
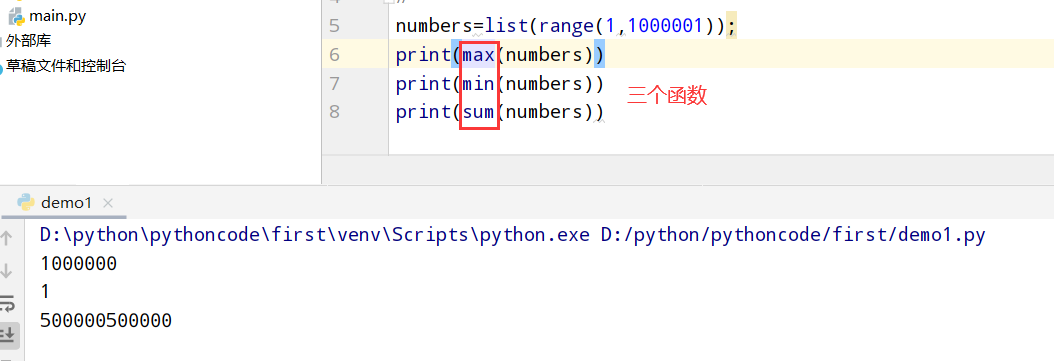
具体代码
1 |
|
执行结果
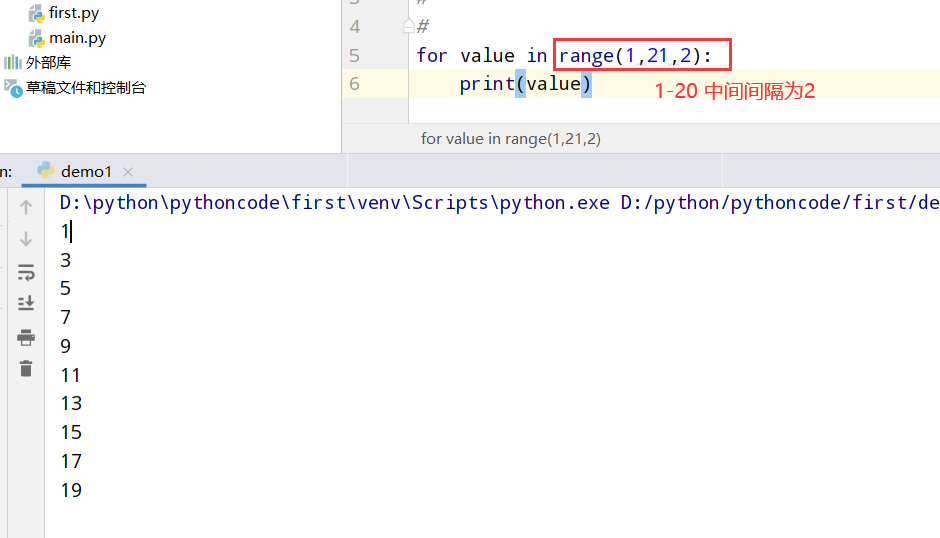
具体代码
1 |
|
执行结果
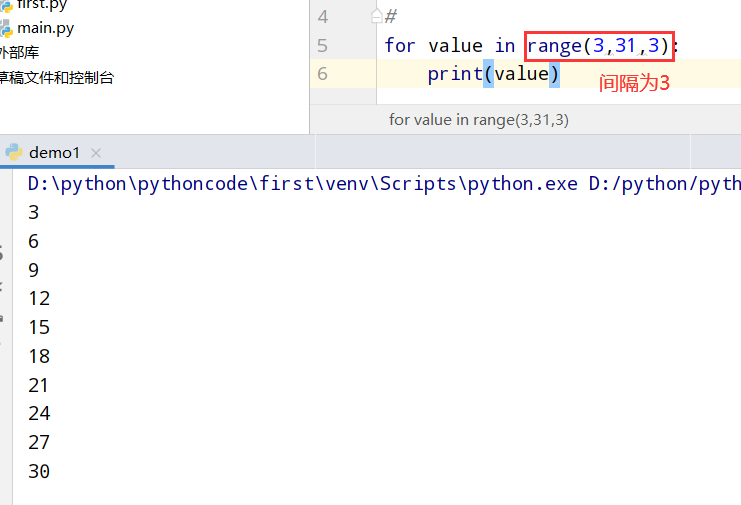
具体代码
1 |
|
执行结果
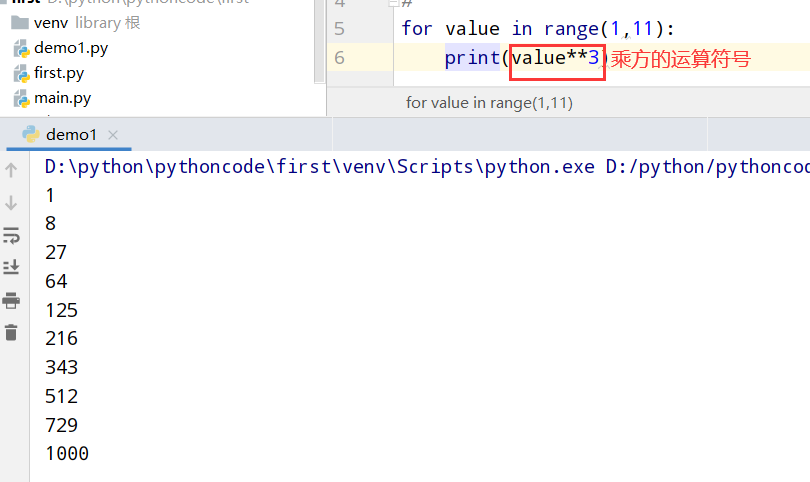
具体代码
1 |
|
执行结果
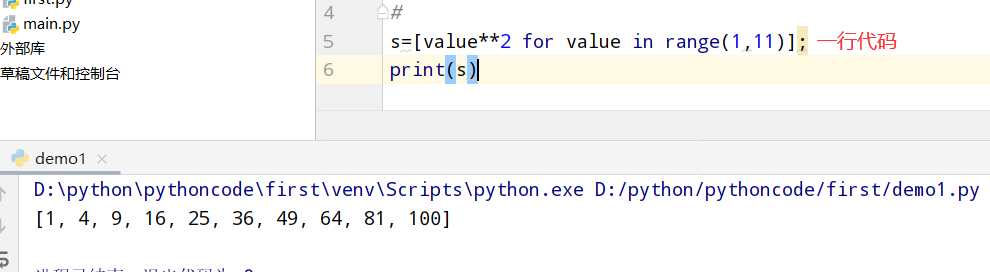
具体代码
1 |
|
执行结果
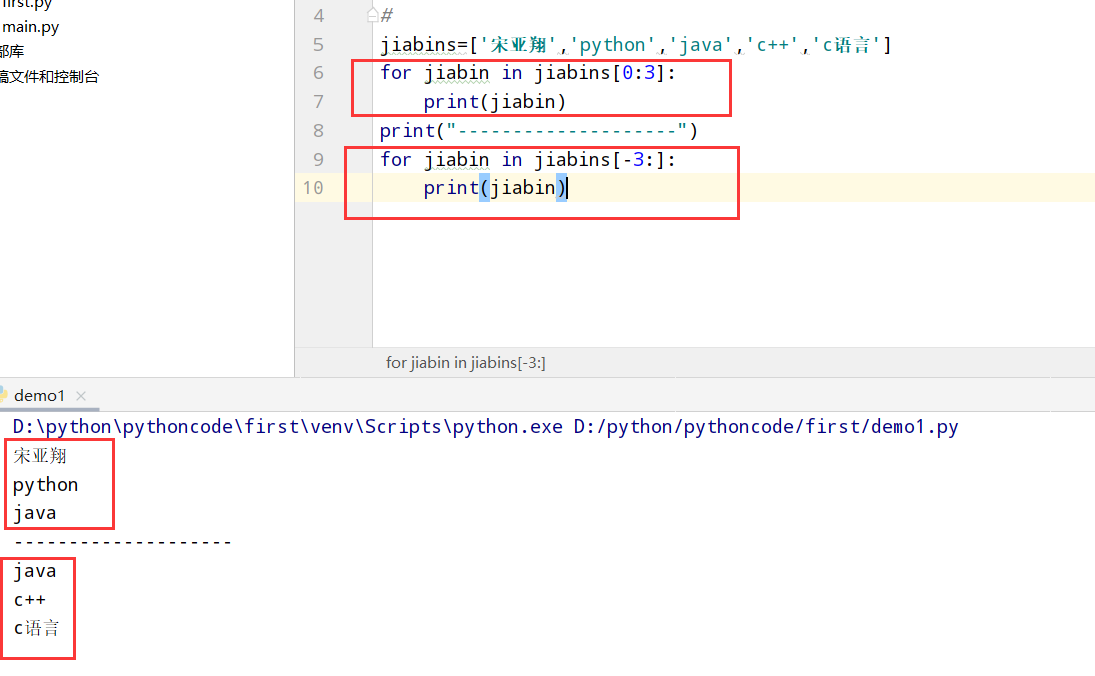
具体代码
1 |
|
执行结果
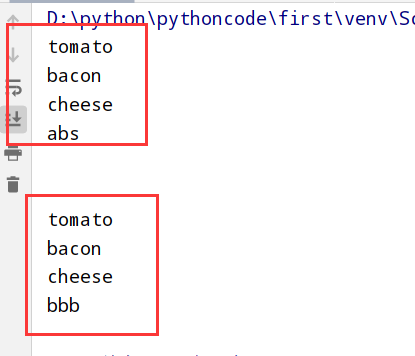
具体代码
1 |
|
执行结果
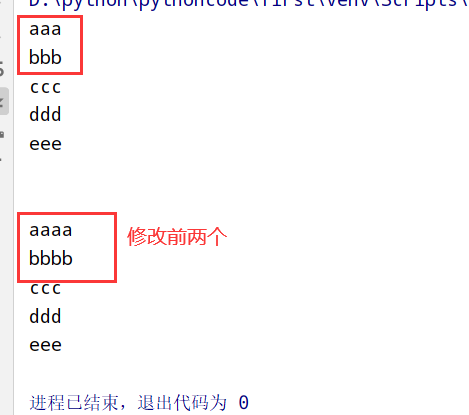
具体代码
1 |
|
执行结果
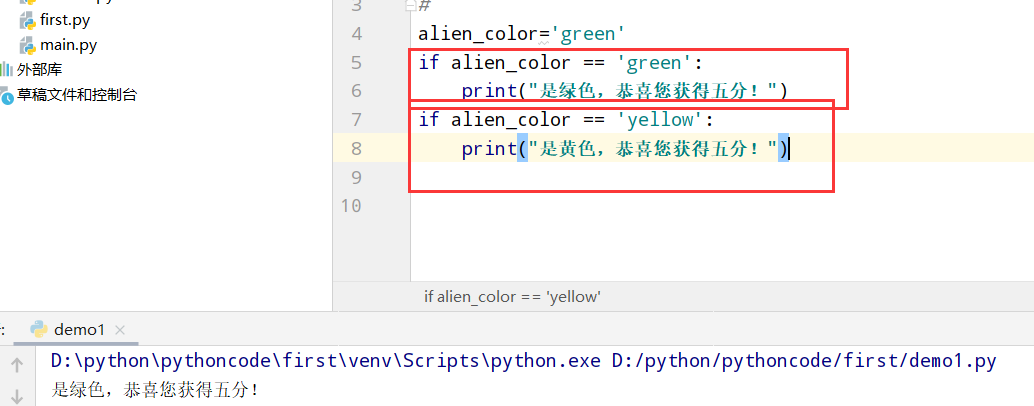
具体代码
1 |
|
执行结果
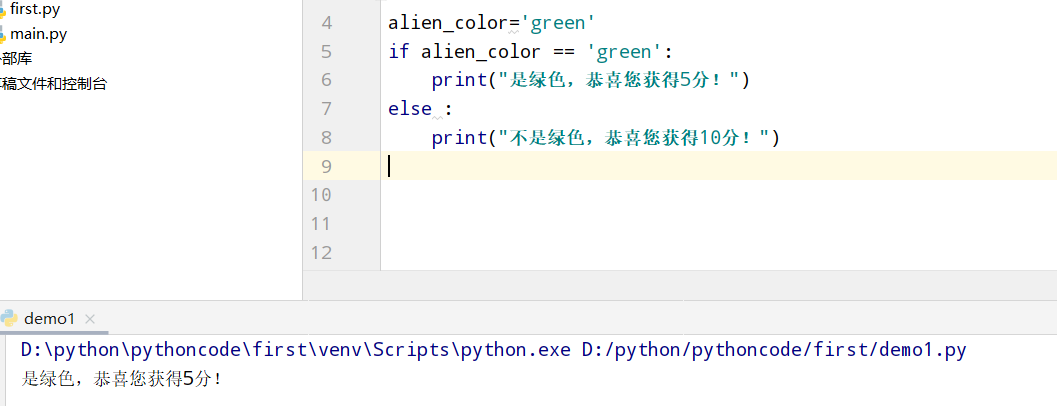
具体代码
1 |
|
执行结果
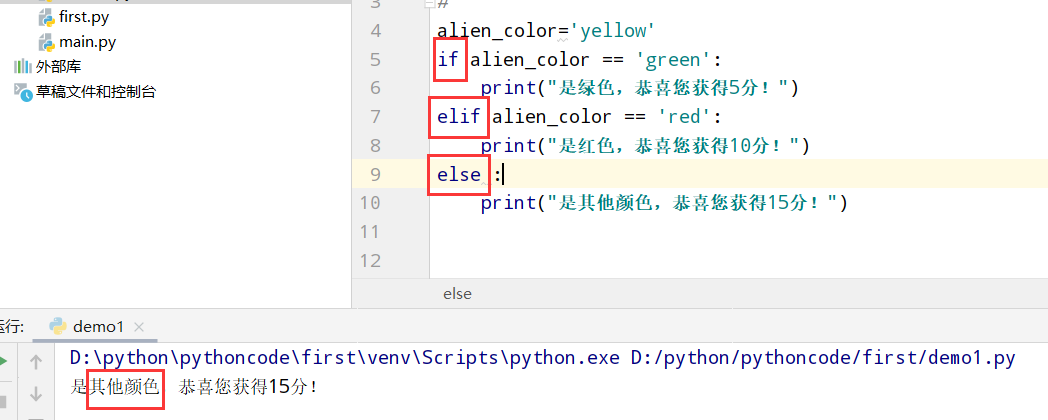
具体代码
1 |
|
执行结果
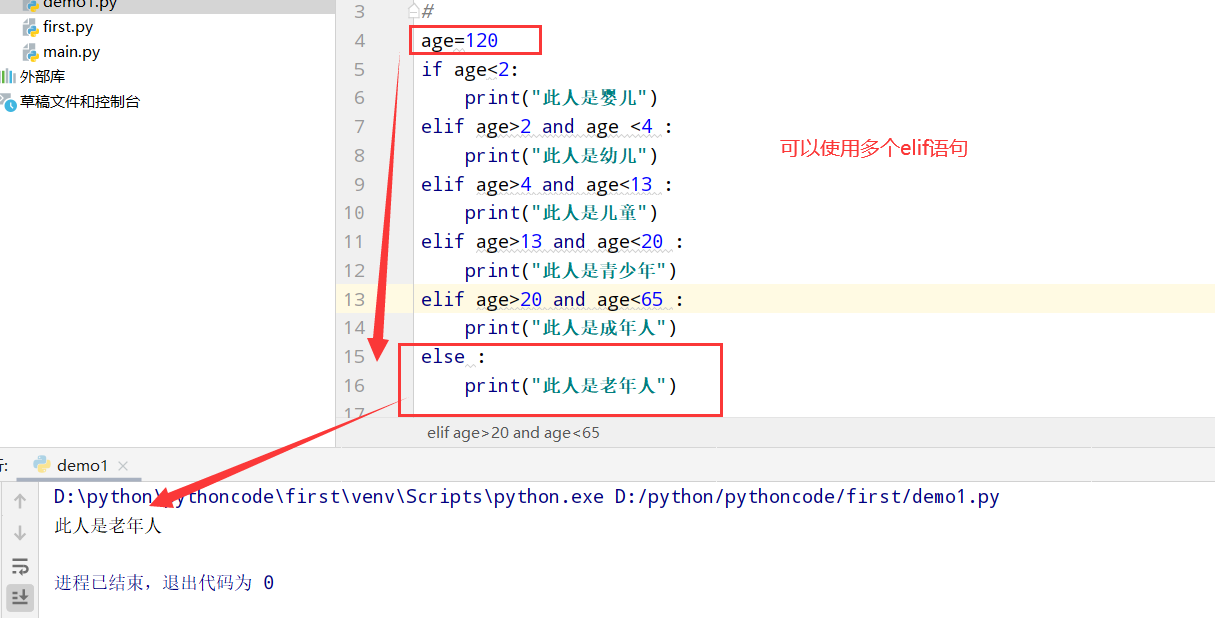
具体代码
1 |
|
执行结果
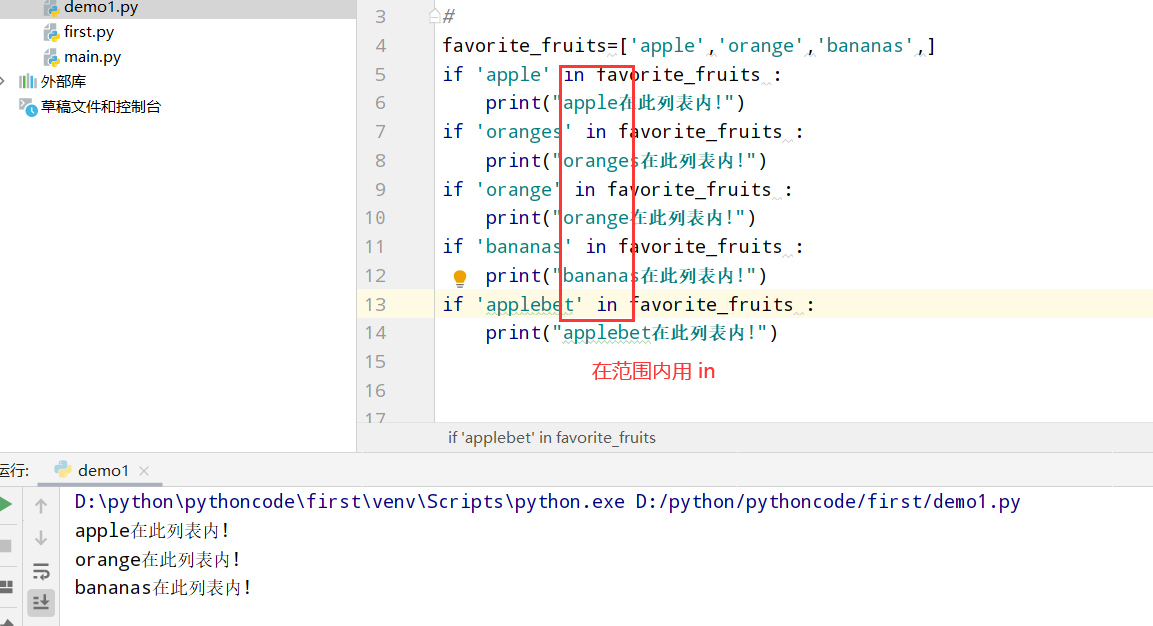
具体代码
1 |
|
执行结果
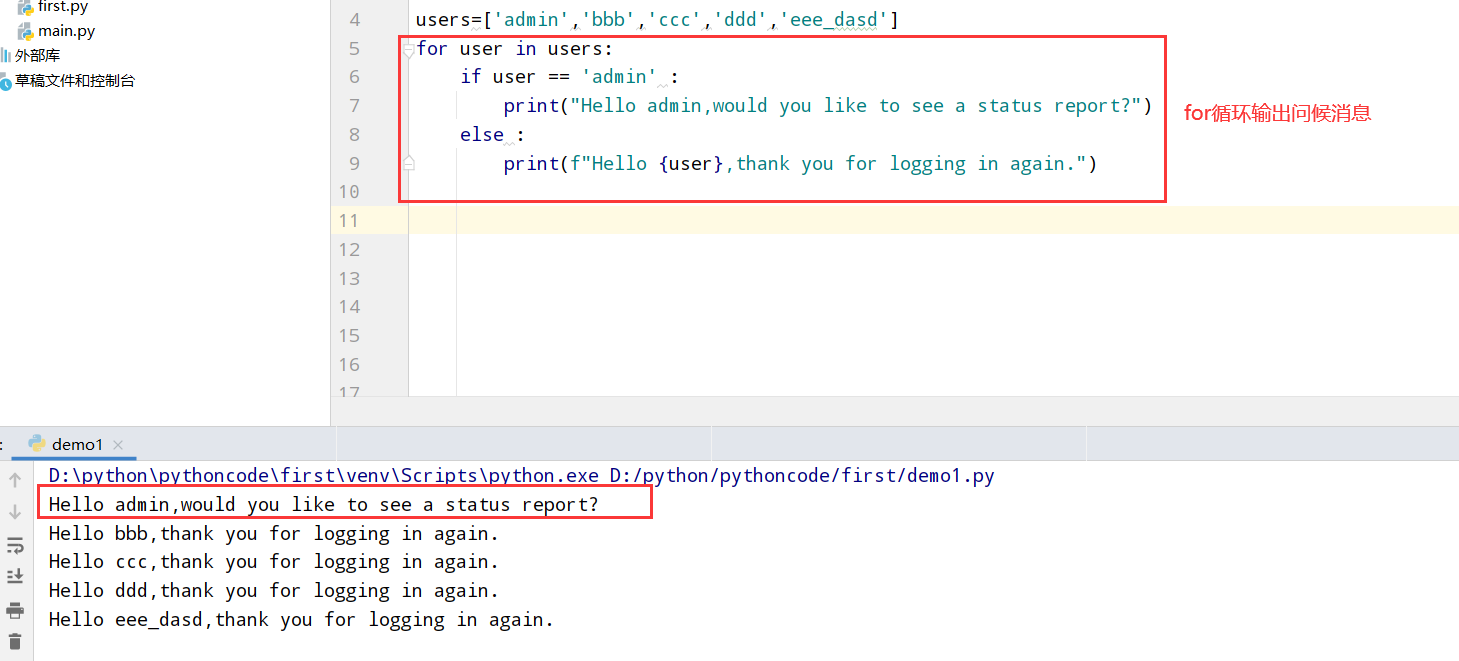
具体代码
1 |
|
执行结果
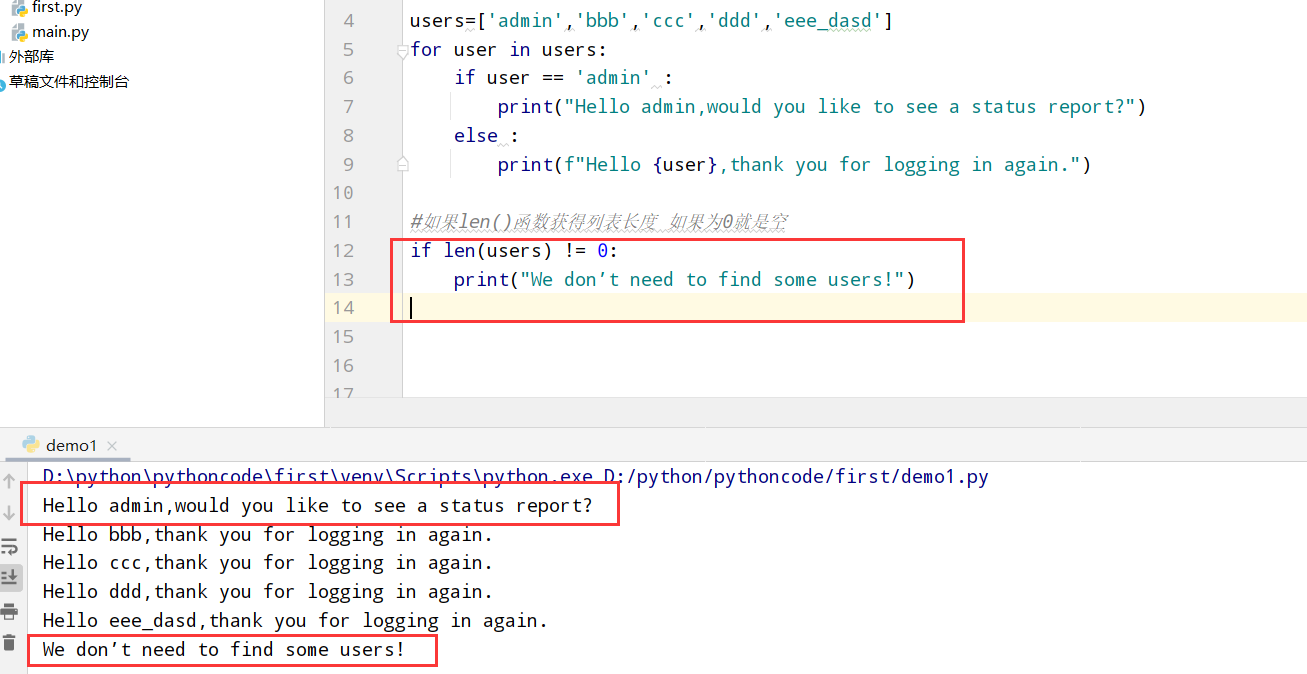
具体代码
1 |
|
执行结果
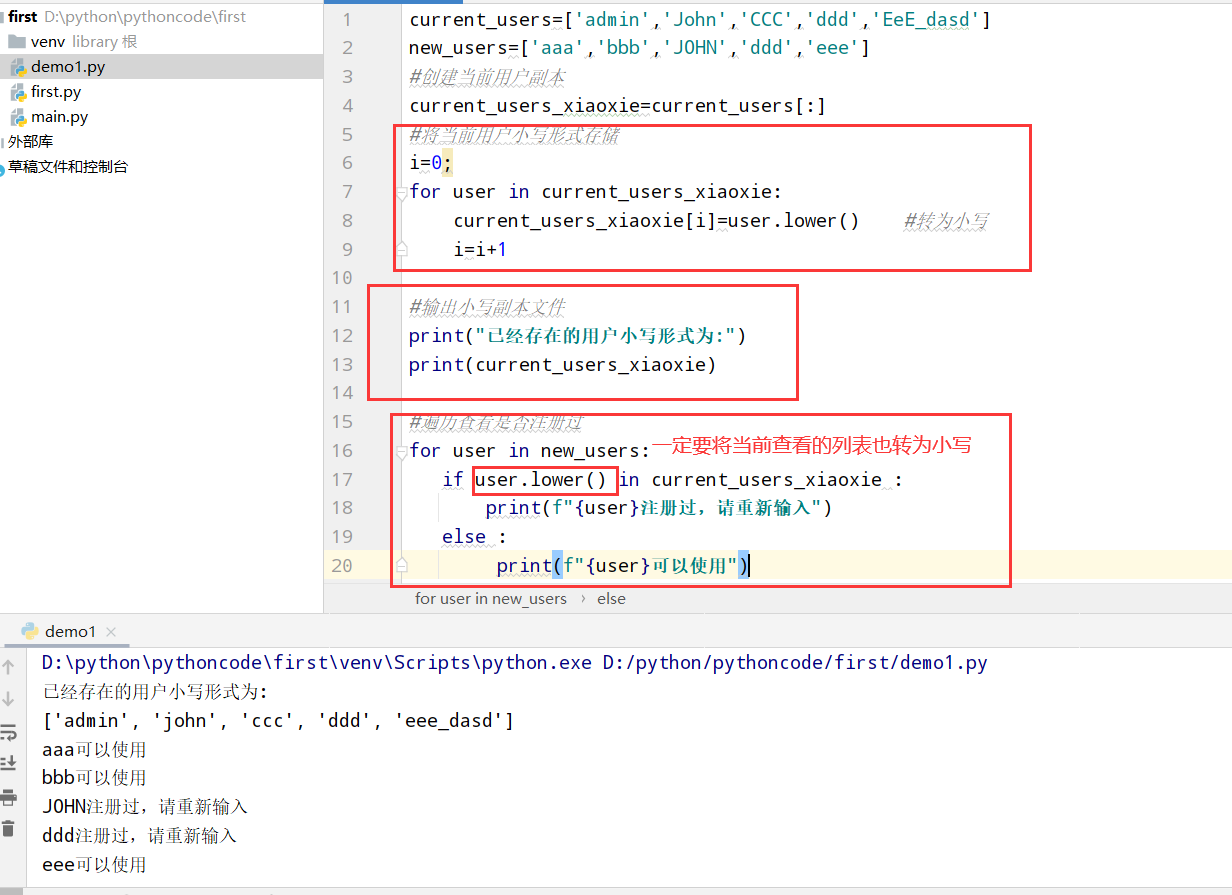
具体代码
1 |
|
执行结果
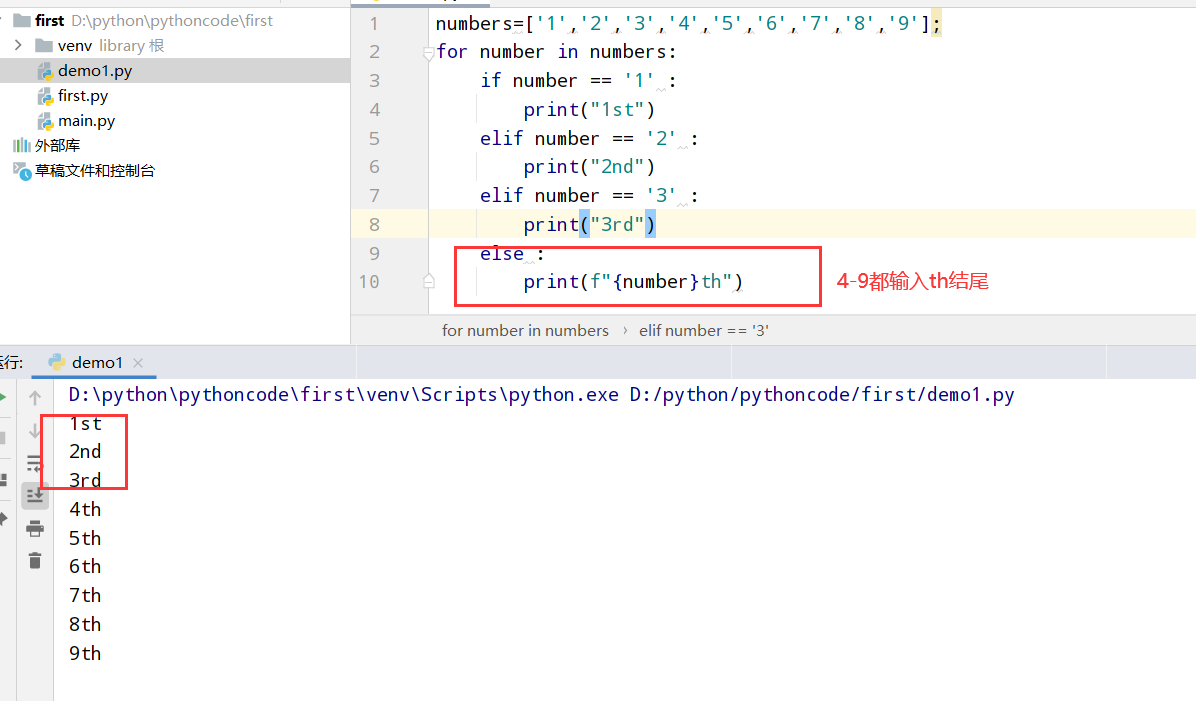
具体代码
1 |
|
执行结果
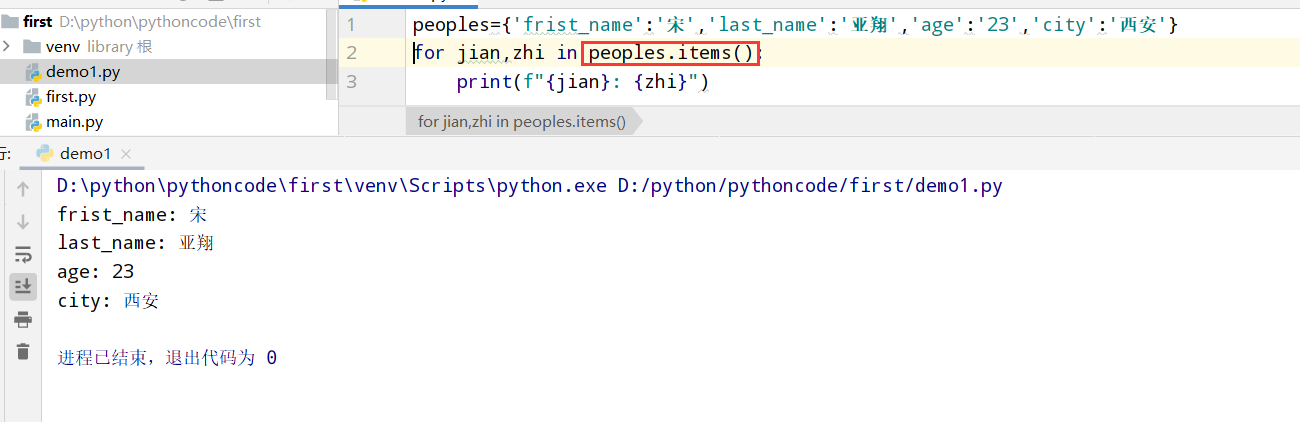
具体代码
1 |
|
执行结果
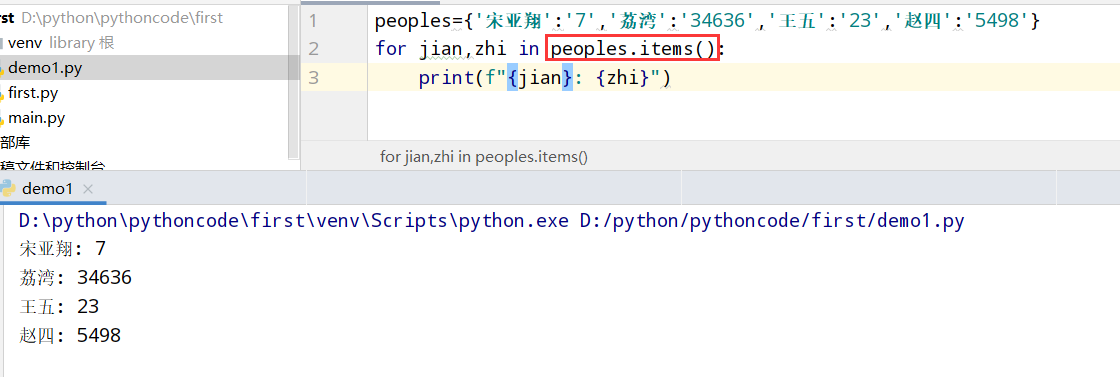
具体代码
1 |
|
执行结果
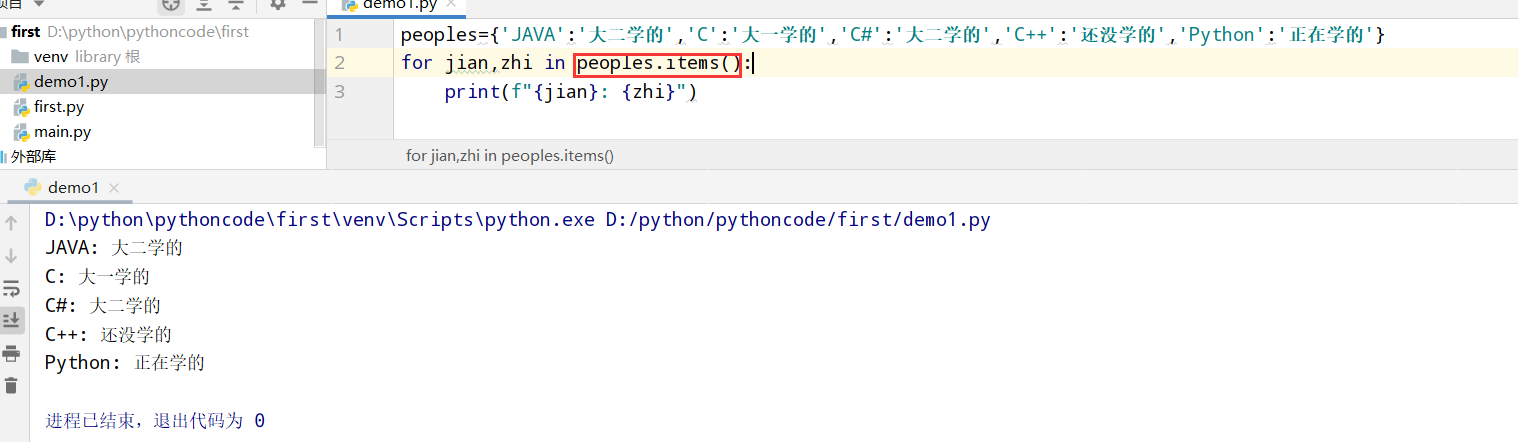
具体代码
1 |
|
执行结果
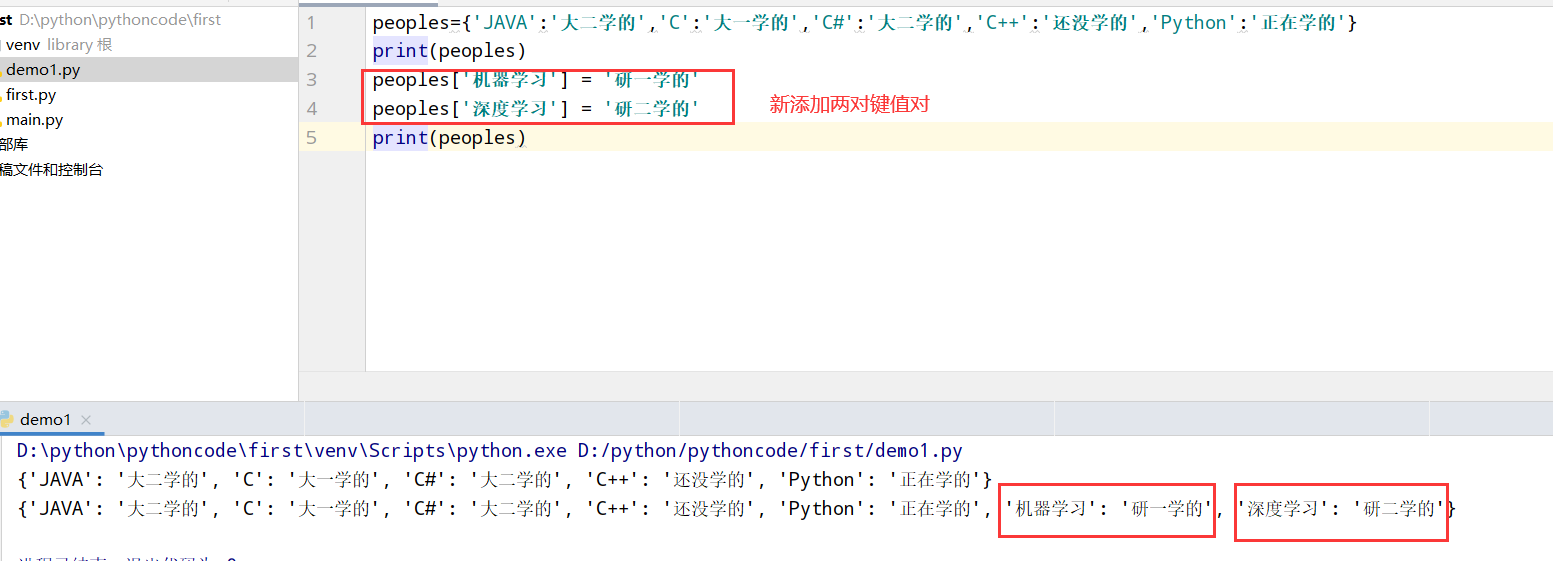
具体代码
1 |
|
执行结果
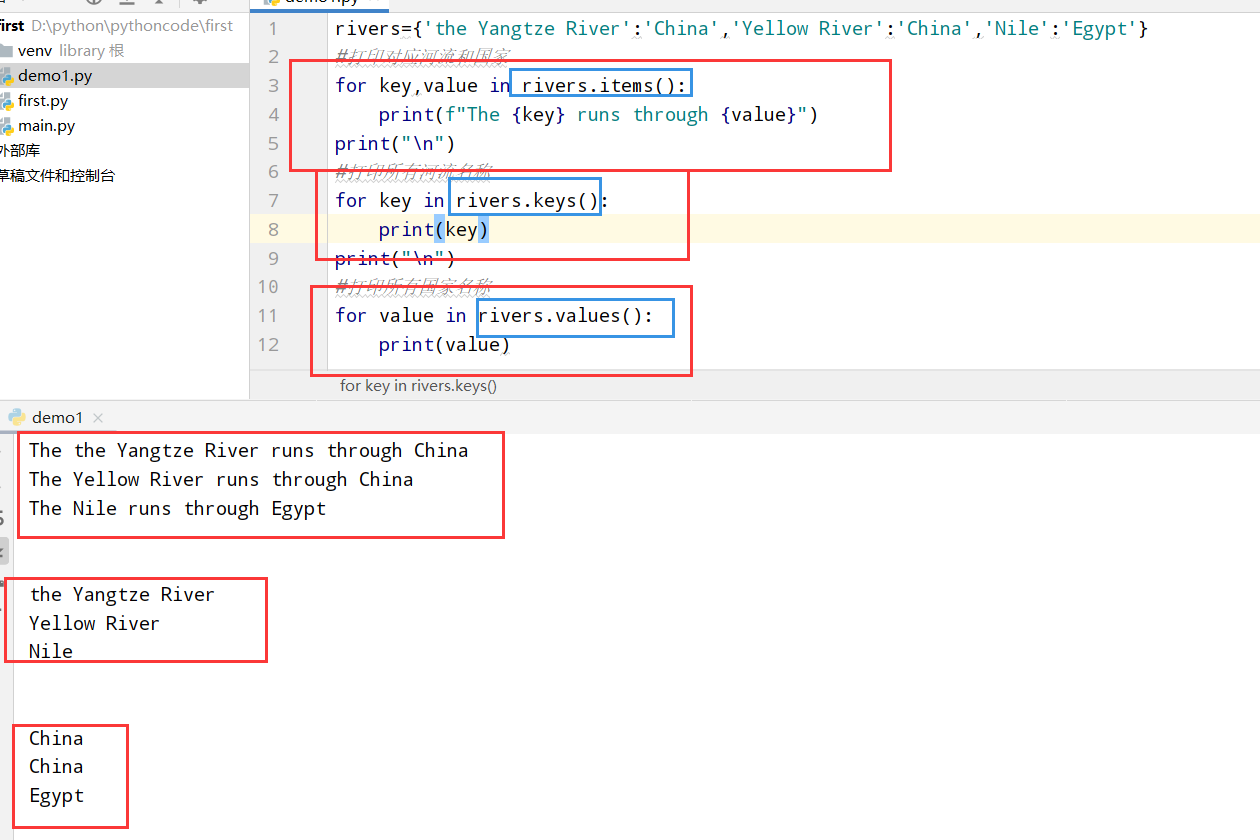
具体代码
1 |
|
执行结果
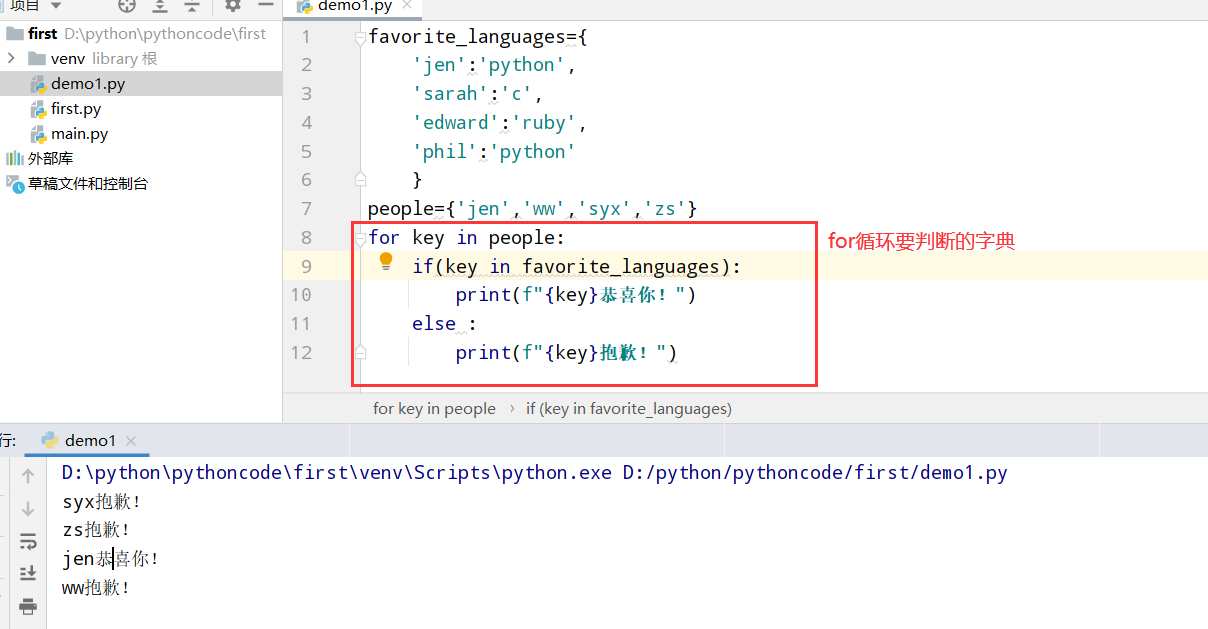
具体代码
1 |
|
执行结果
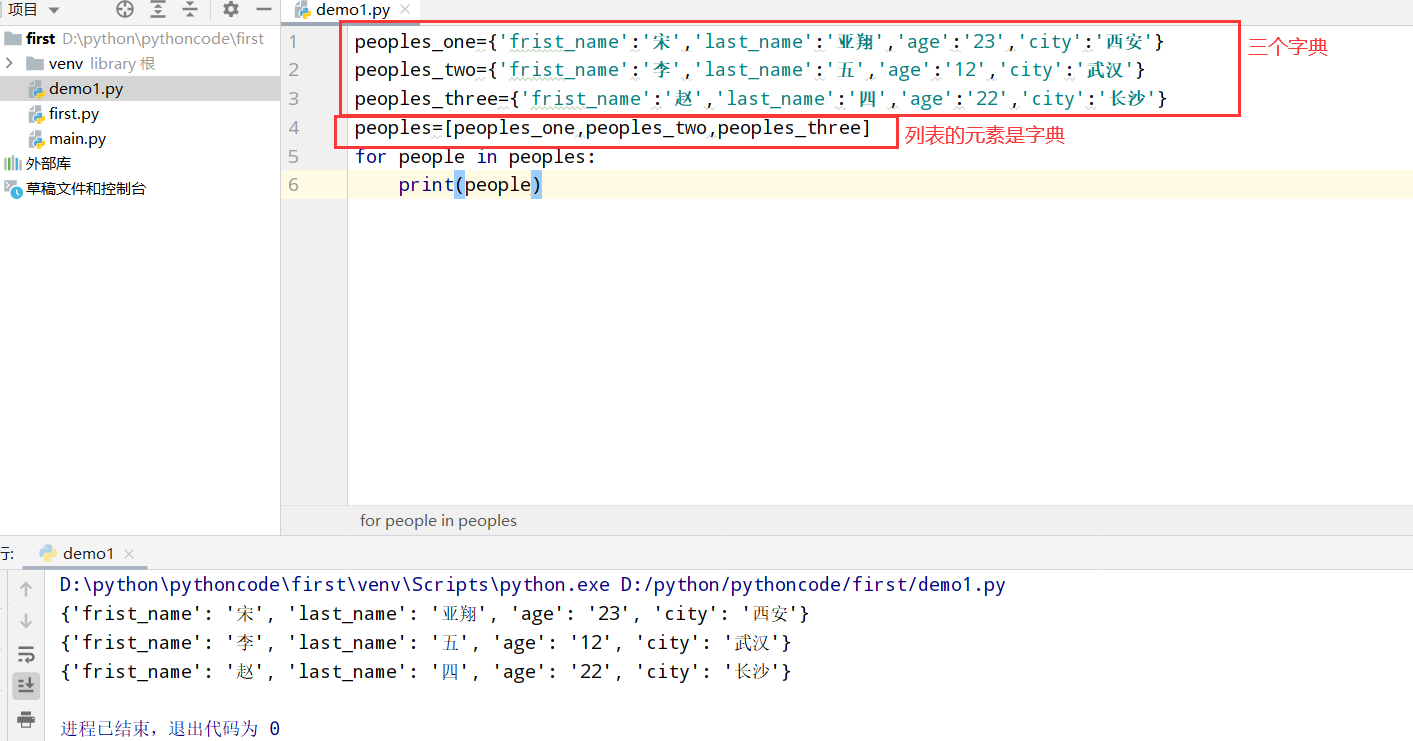
具体代码
1 |
|
执行结果
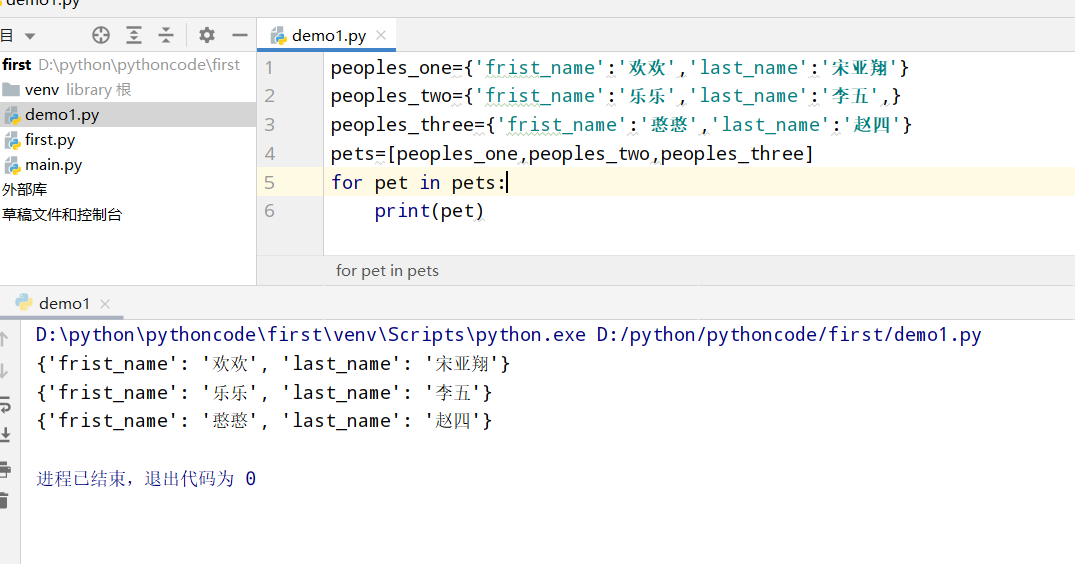
具体代码
1 |
|
执行结果
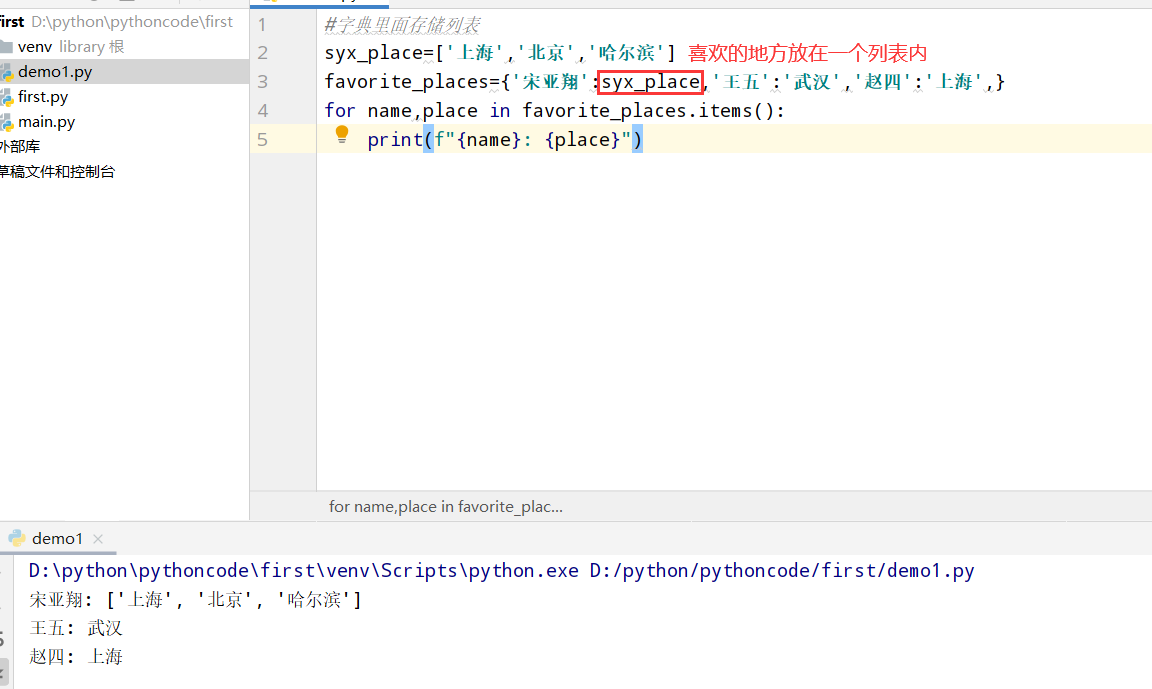
具体代码
1 |
|
执行结果
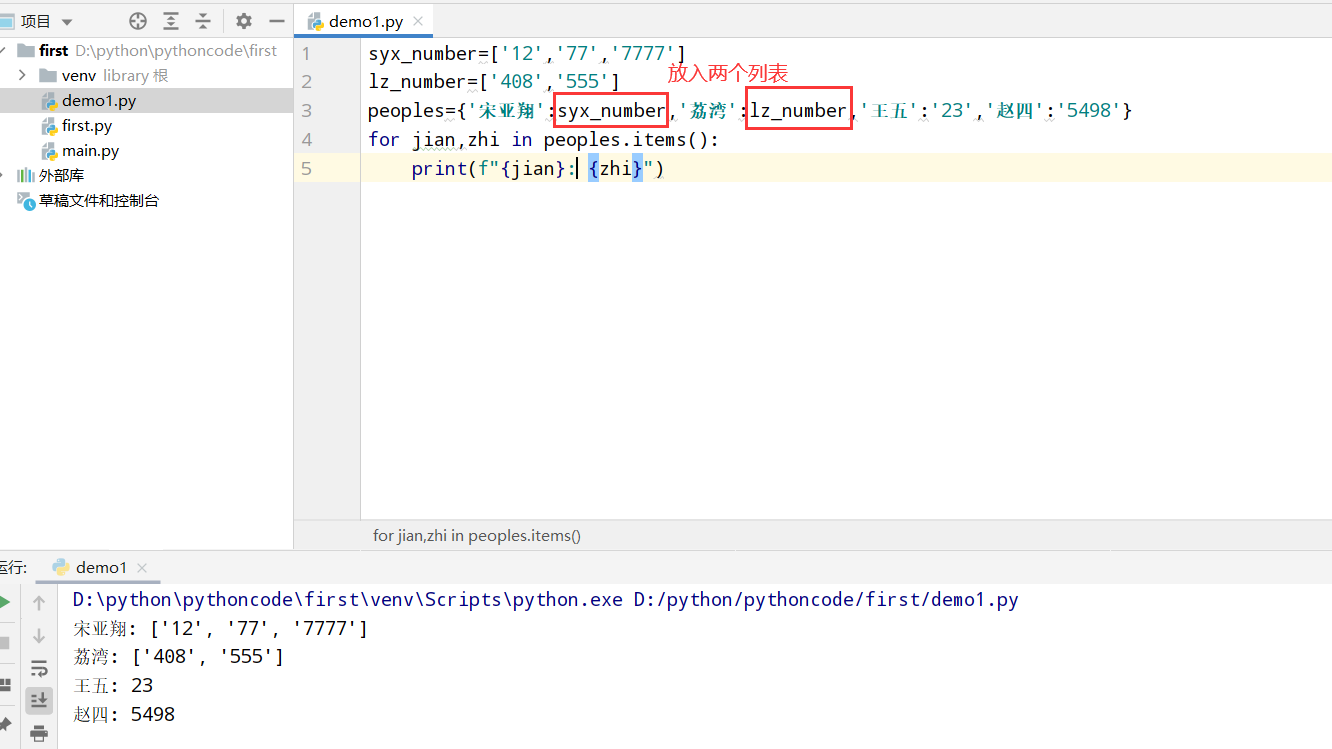
具体代码
1 |
|
执行结果
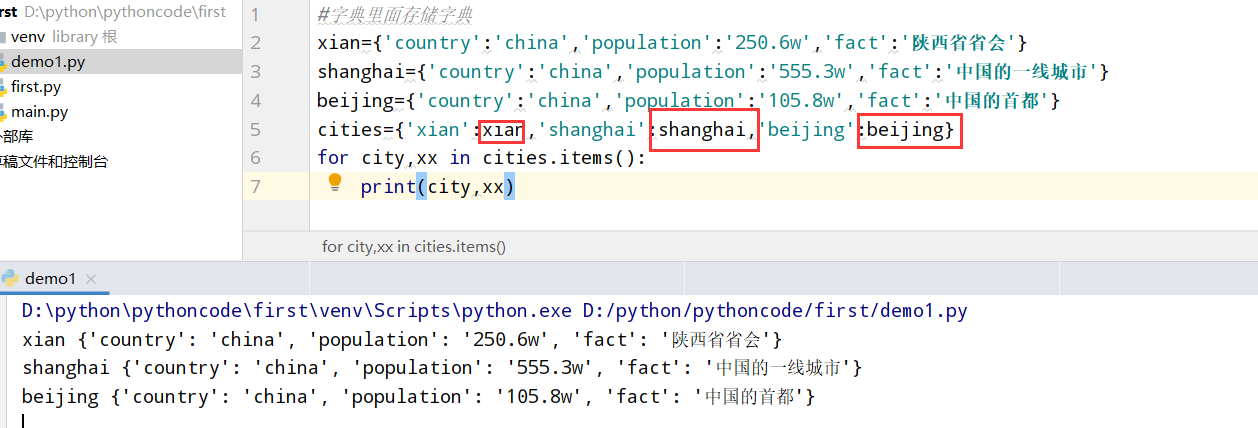
具体代码
1 |
|
执行结果
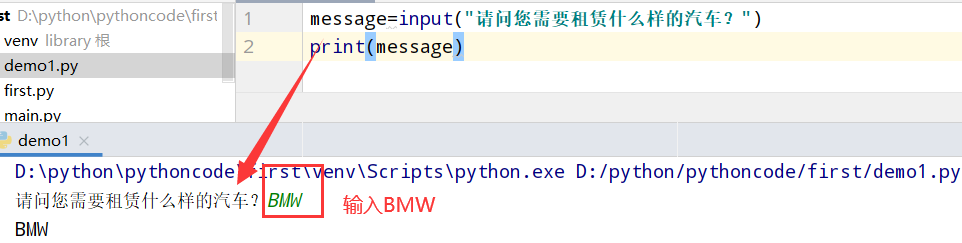
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
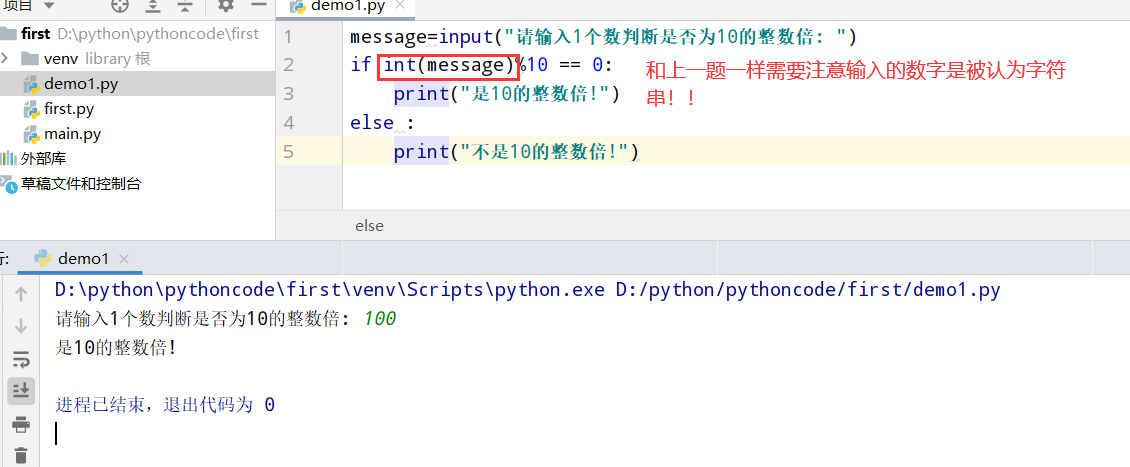
具体代码
1 |
|
执行结果
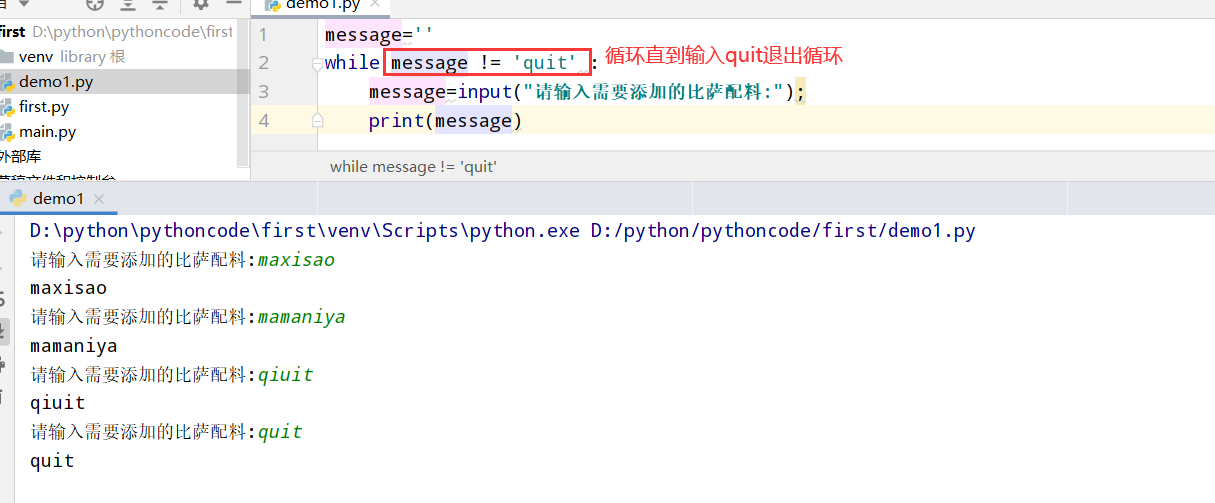
具体代码
1 |
|
执行结果
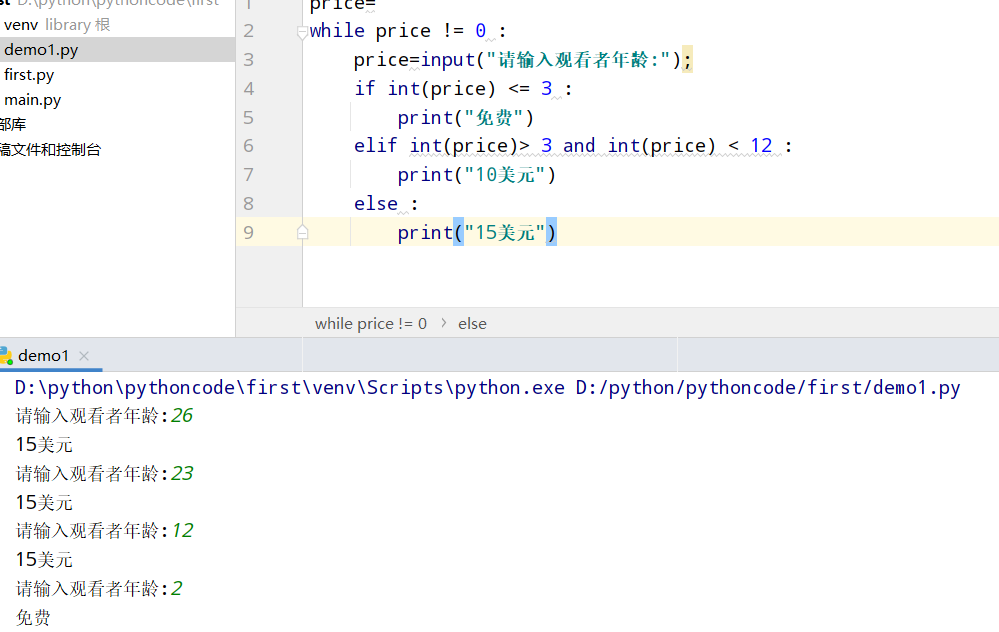
具体代码
1 |
|
执行结果
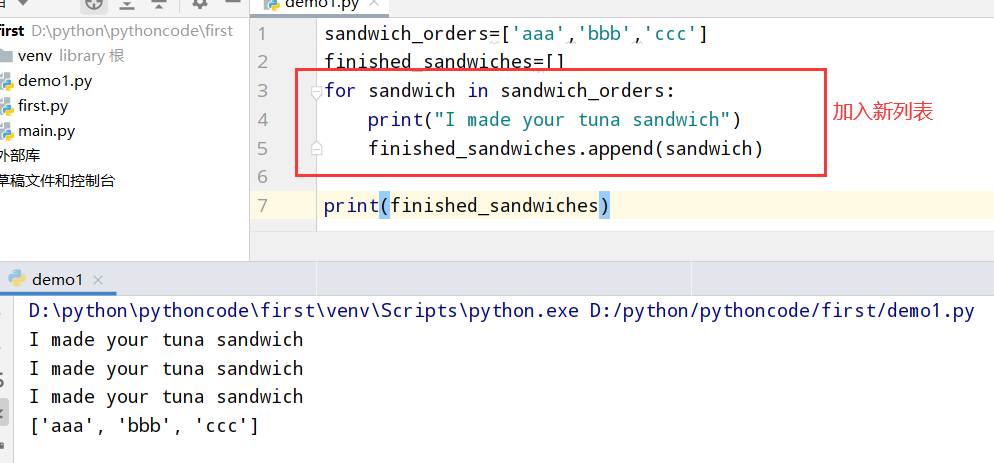
具体代码
1 |
|
执行结果
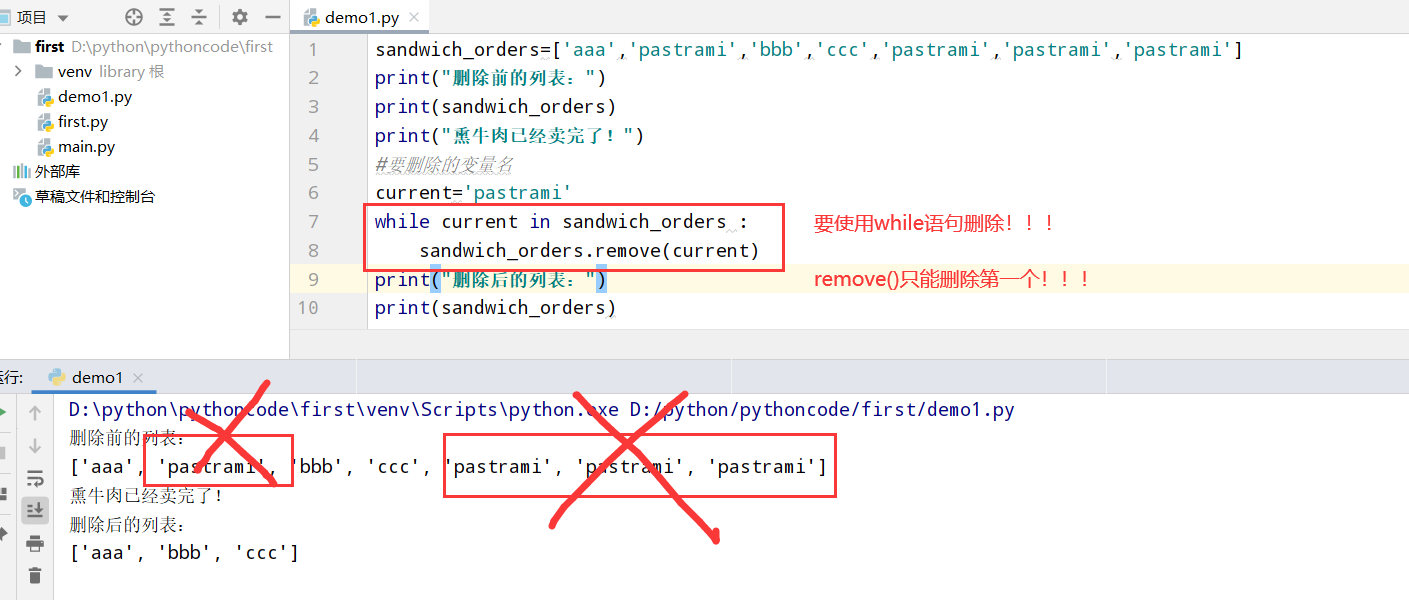
具体代码
1 |
|
执行结果
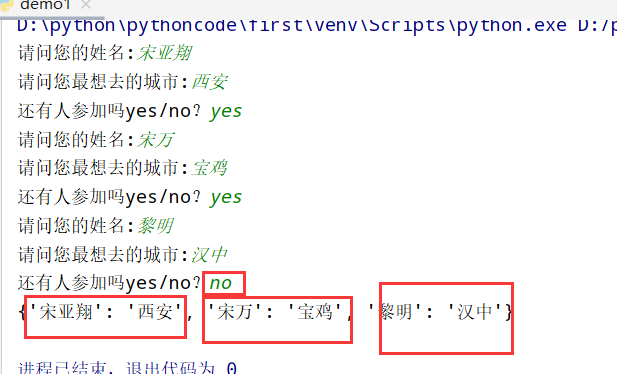
具体代码
1 |
|
执行结果
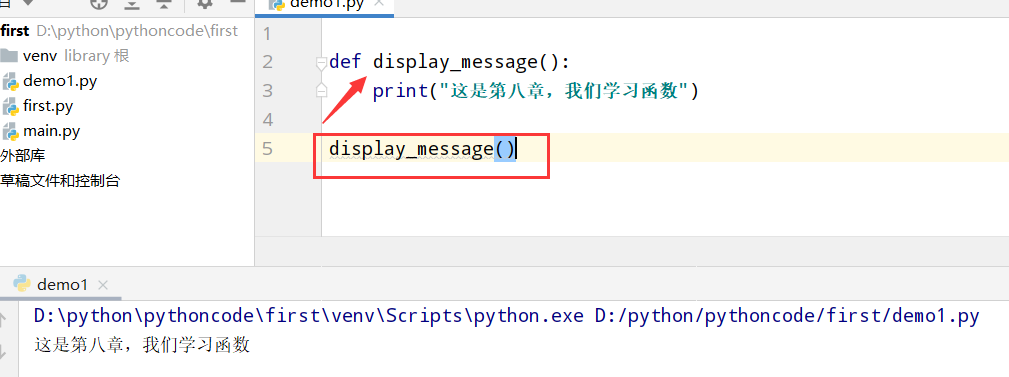
具体代码
1 |
|
执行结果
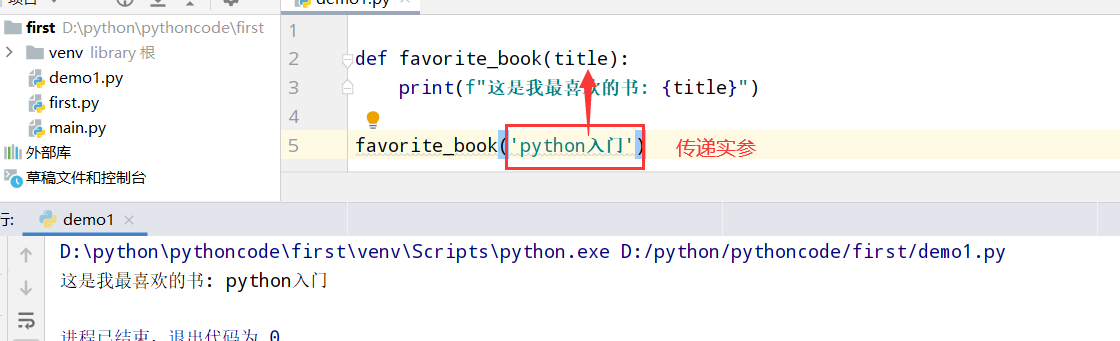
具体代码
1 |
|
执行结果
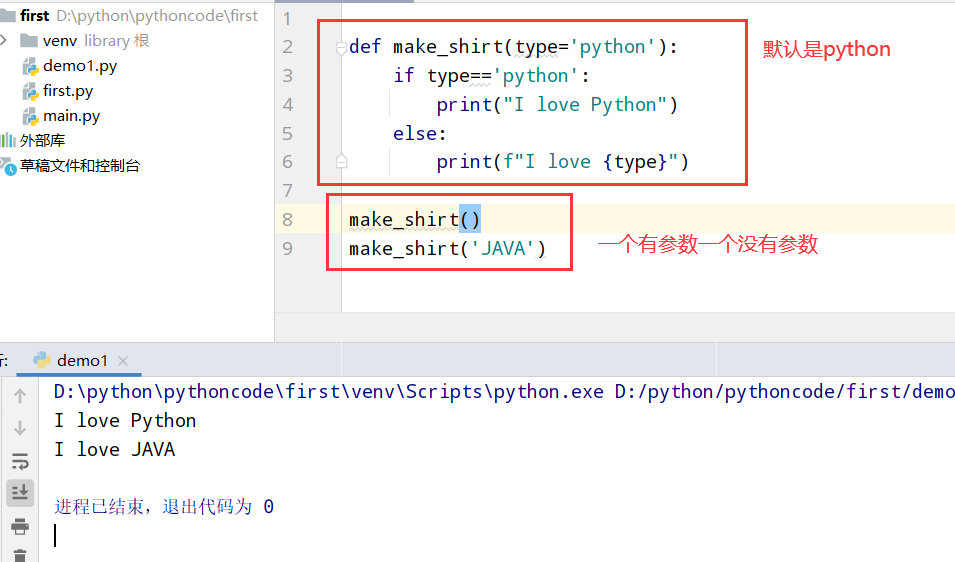
具体代码
1 |
|
执行结果
具体代码
1 |
|
执行结果
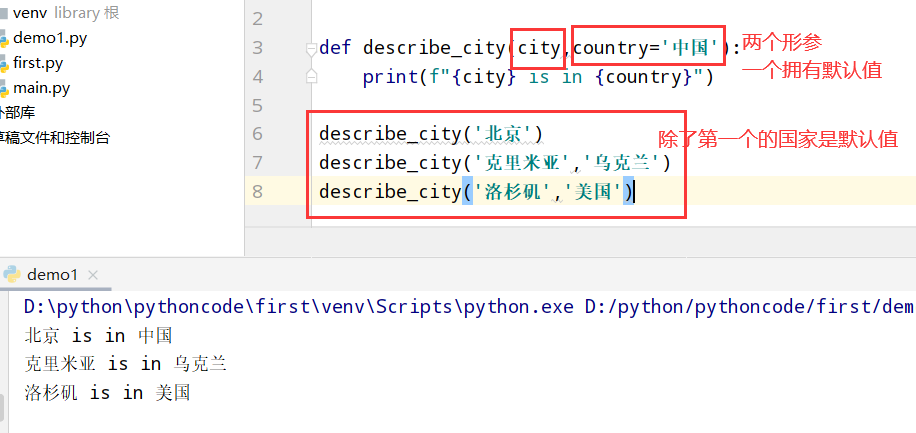
具体代码
1 |
|
执行结果
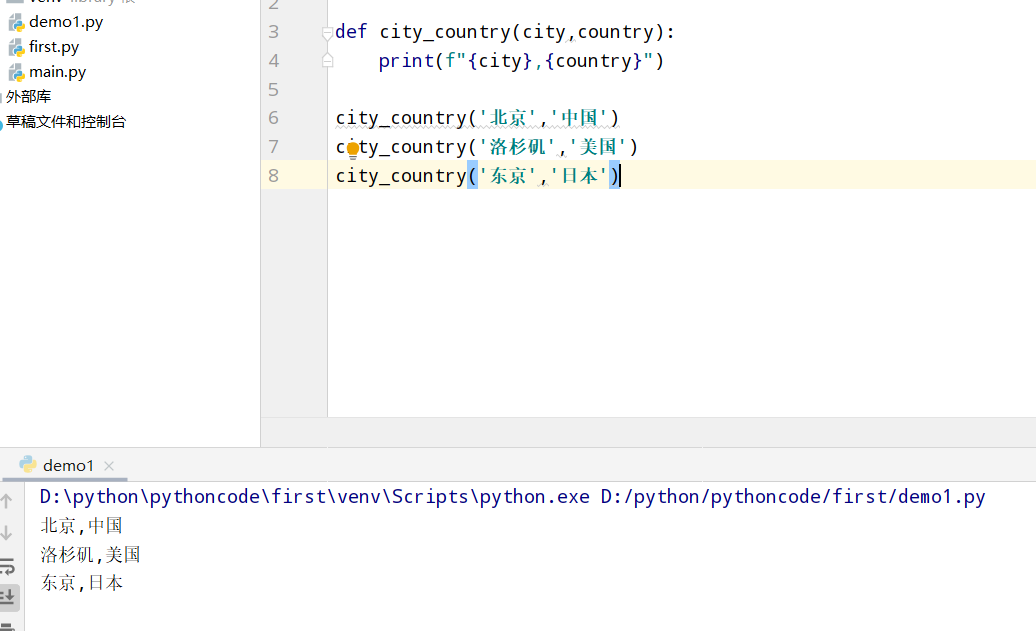
具体代码
1 |
|
执行结果
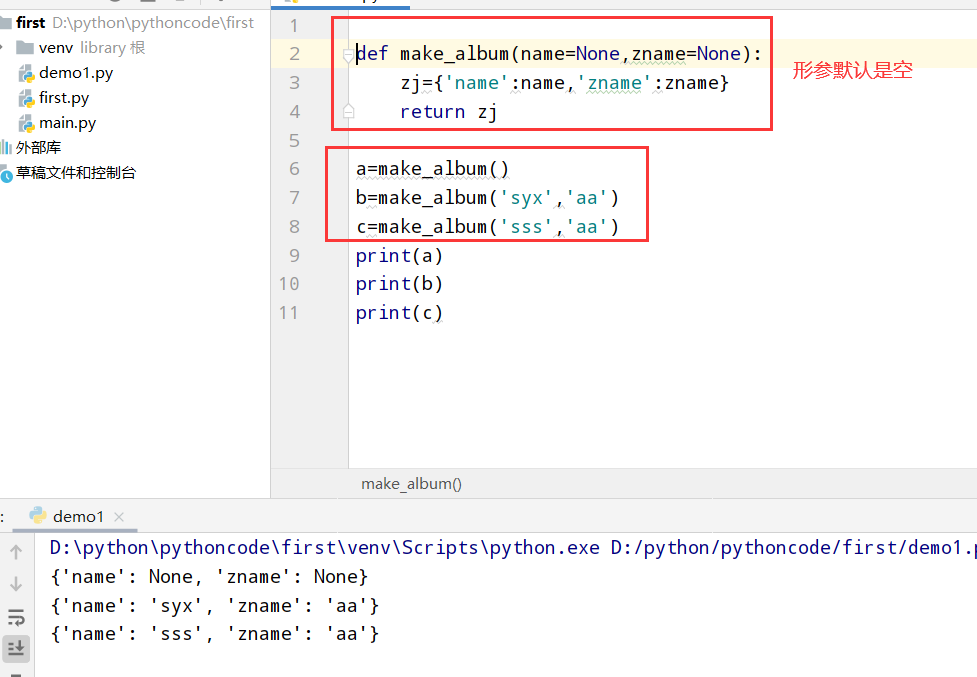
具体代码
1 |
|
执行结果
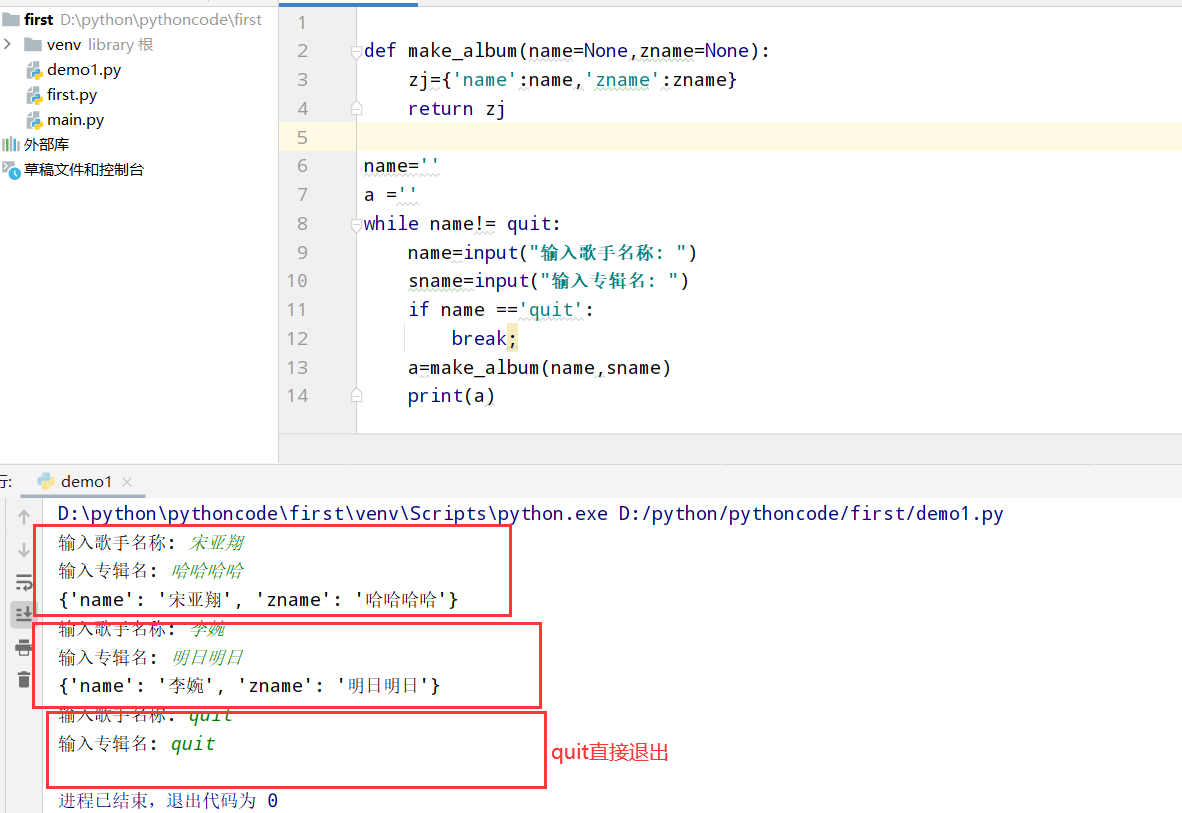
具体代码
1 |
|
执行结果
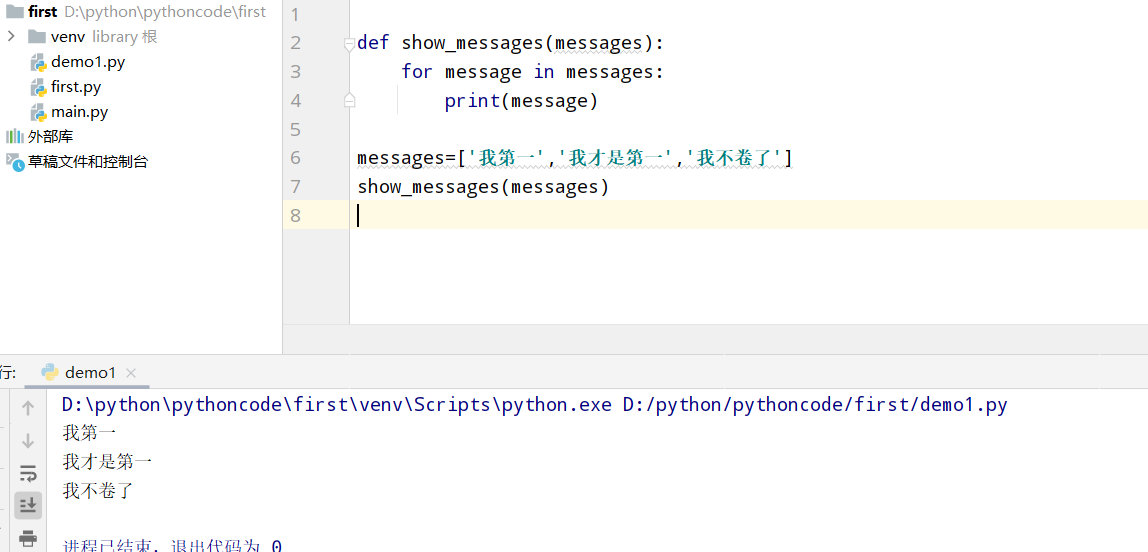
具体代码
1 |
|
执行结果
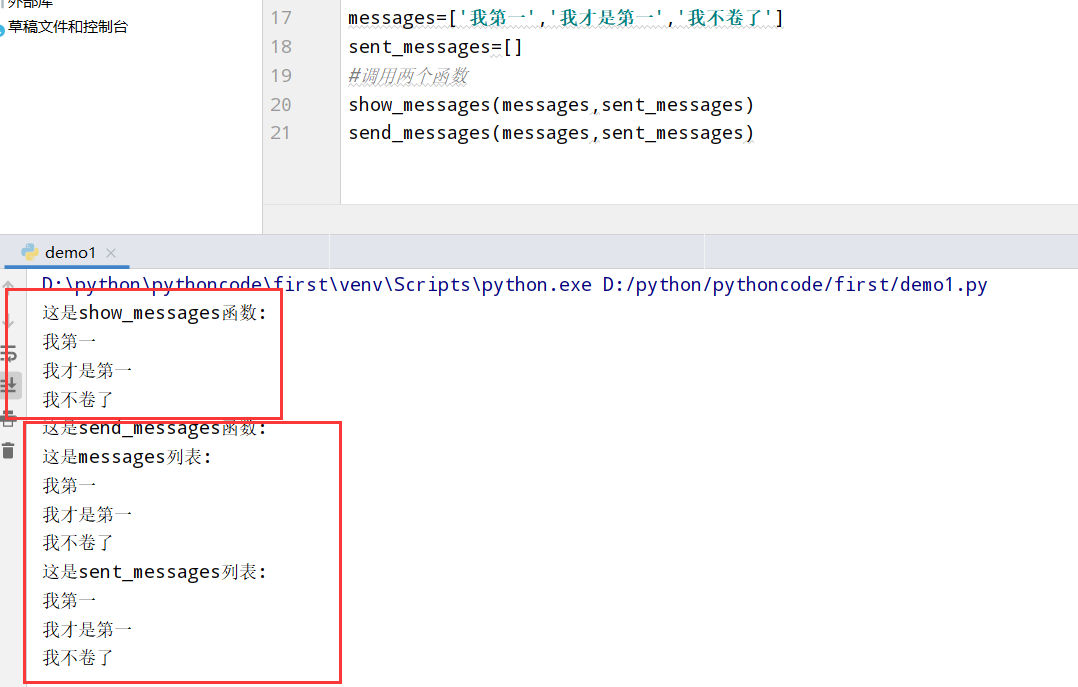
具体代码
1 |
|
执行结果
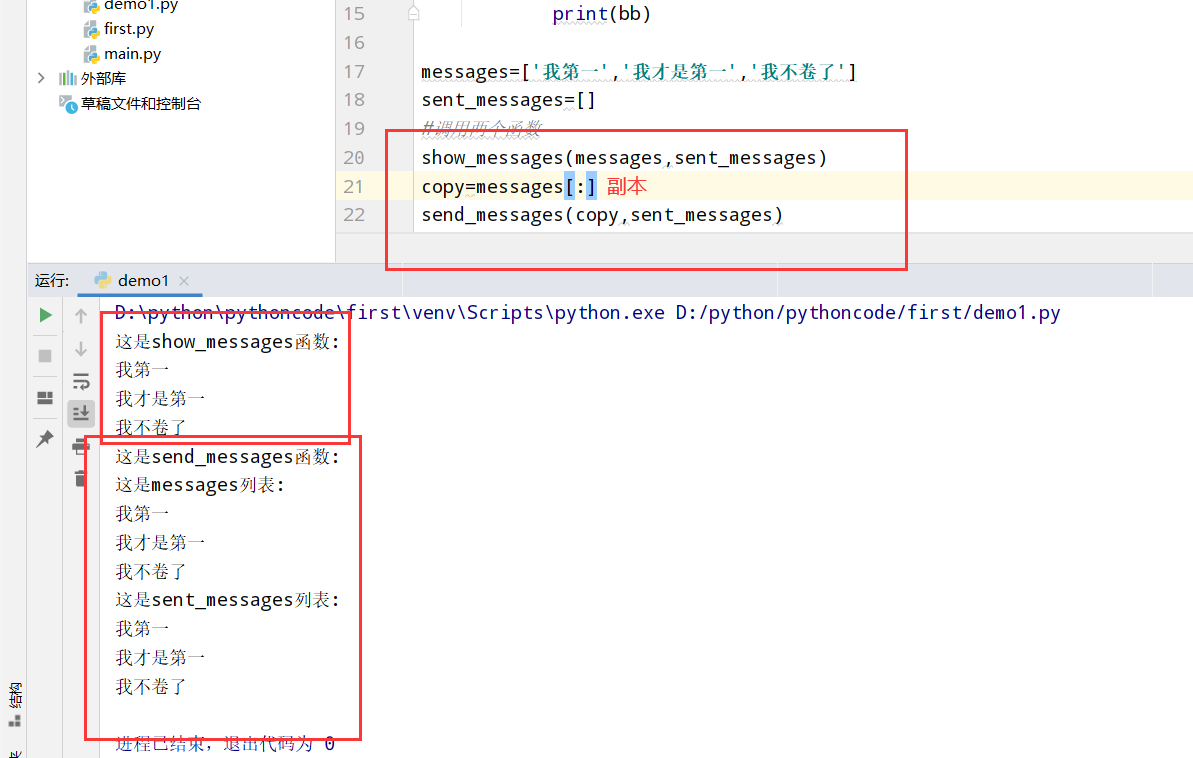
具体代码
1 |
|
执行结果
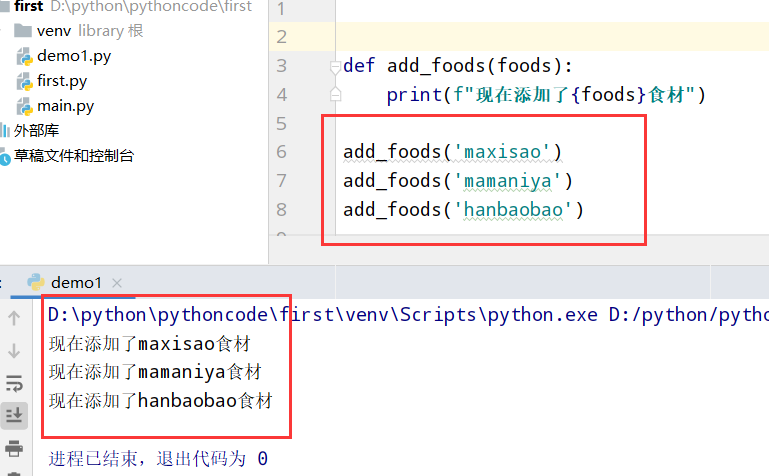
具体代码
1 |
|
执行结果
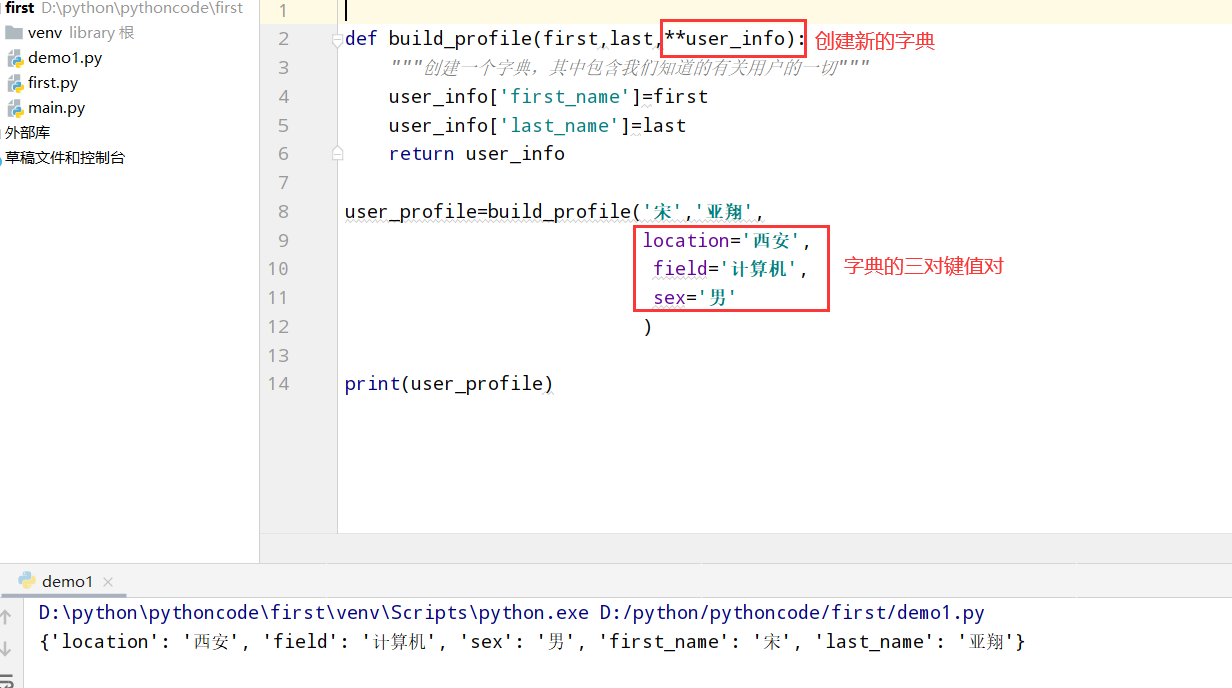
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
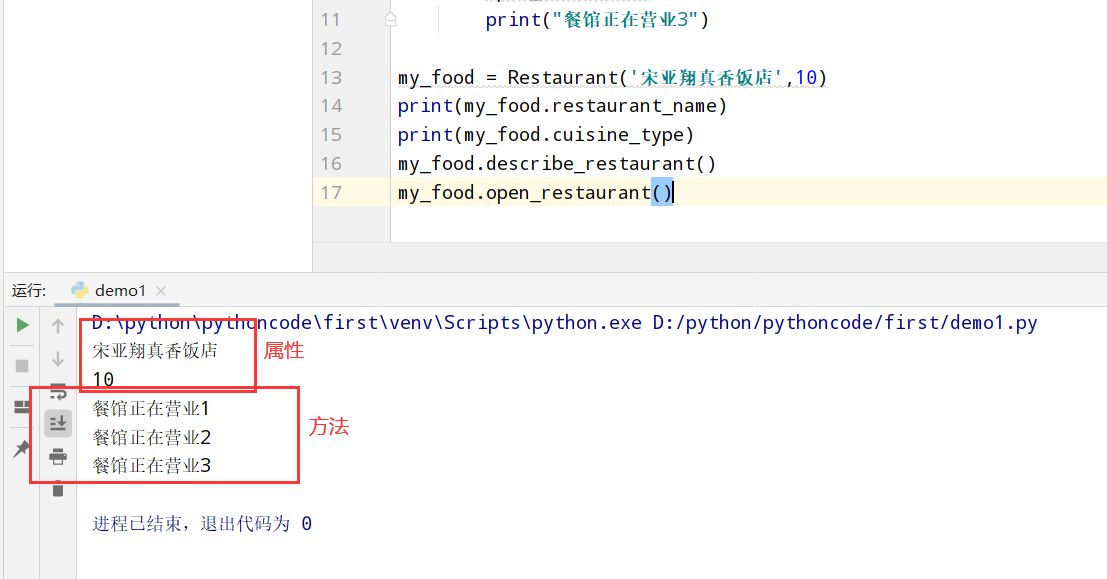
具体代码
1 |
|
执行结果
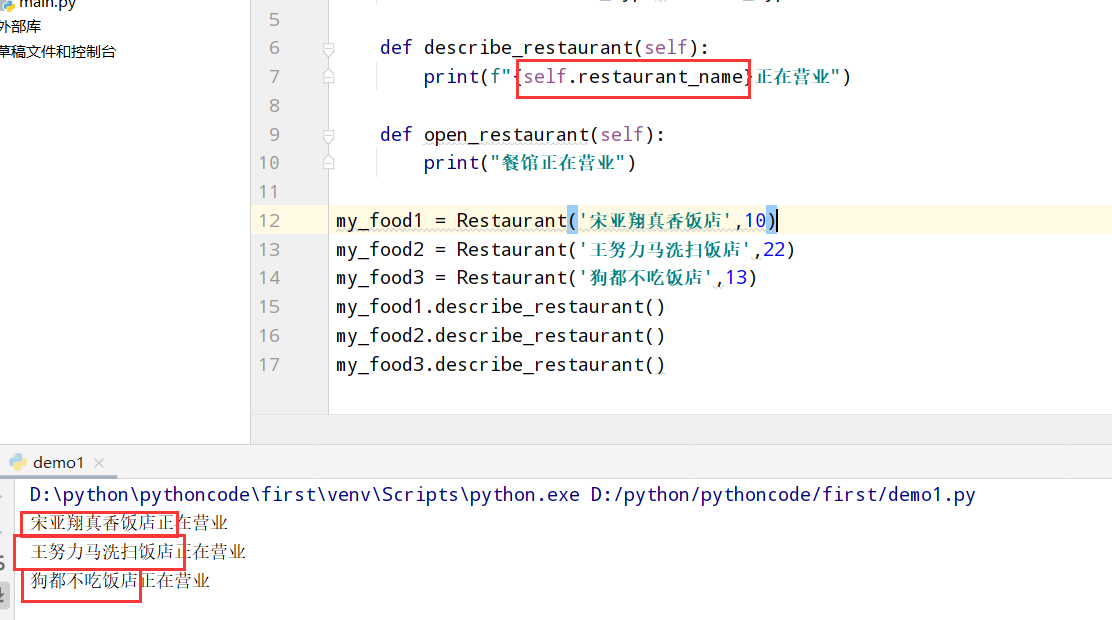
具体代码
1 |
|
执行结果
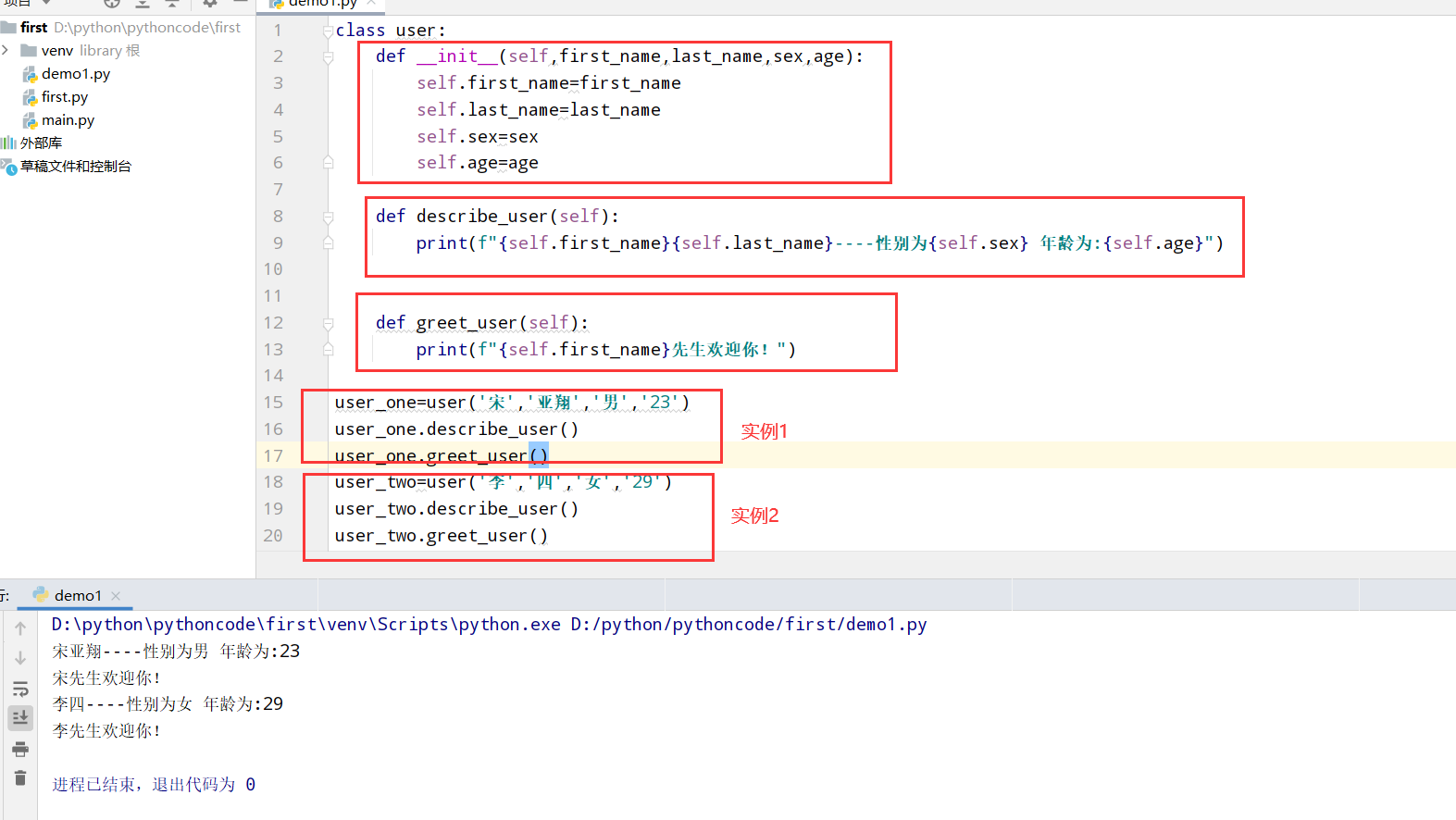
具体代码
1 |
|
执行结果
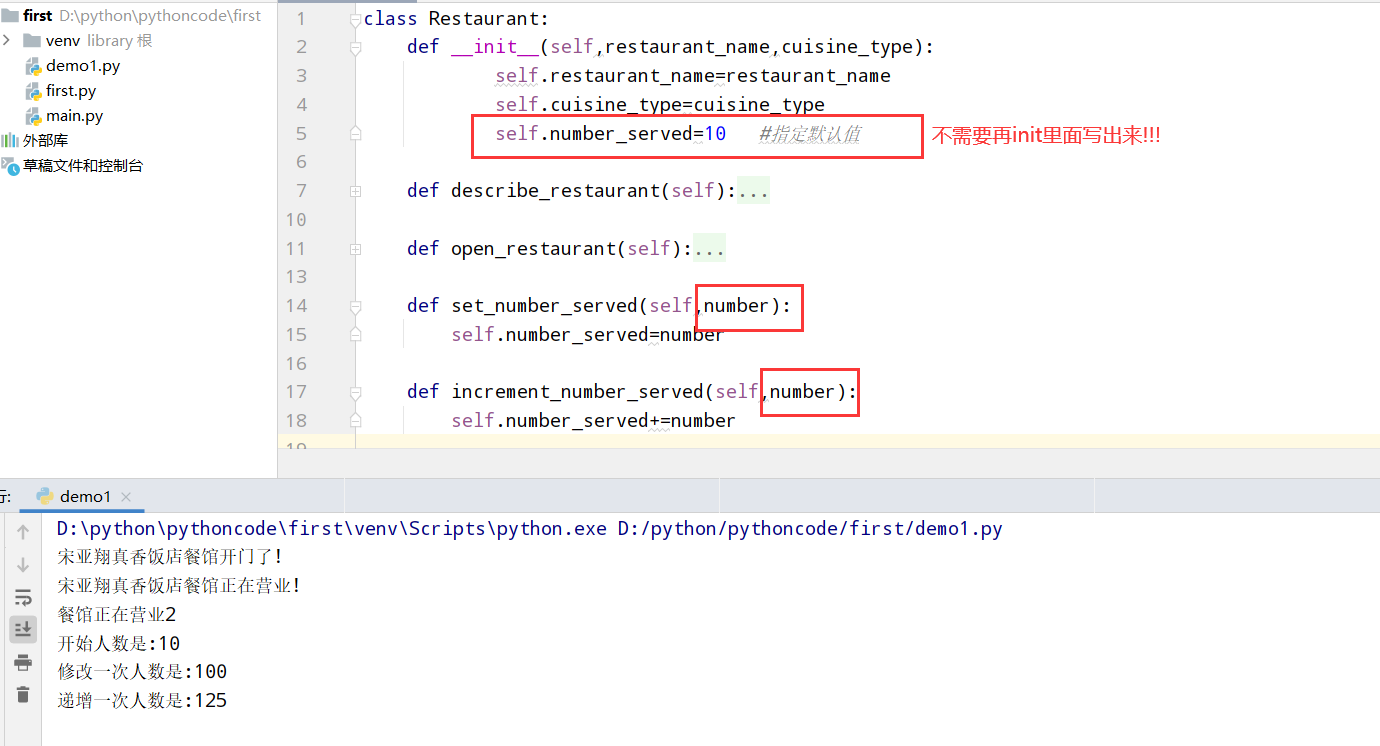
具体代码
1 |
|
执行结果
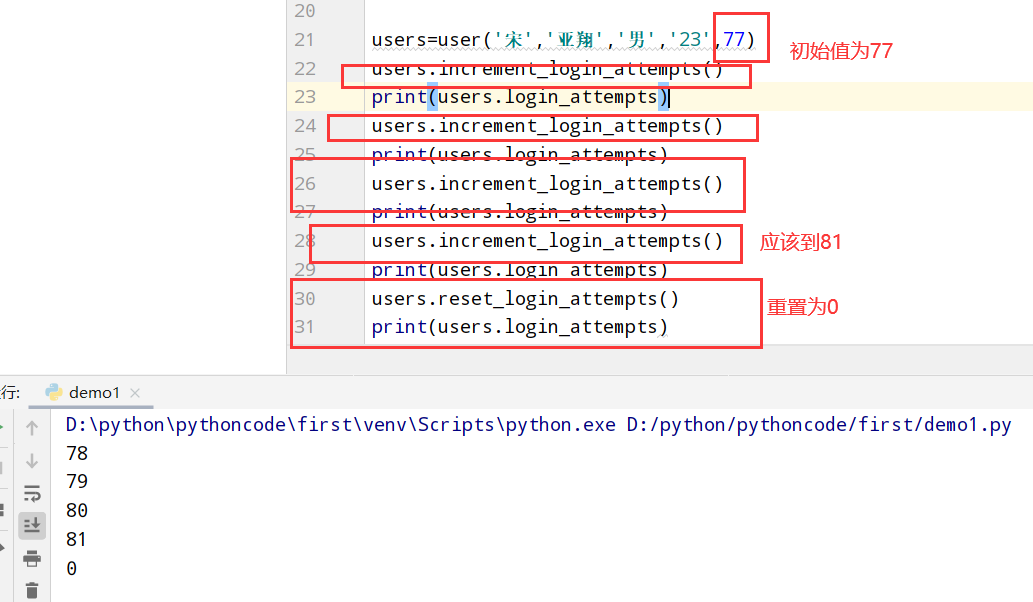
具体代码
1 |
|
执行结果
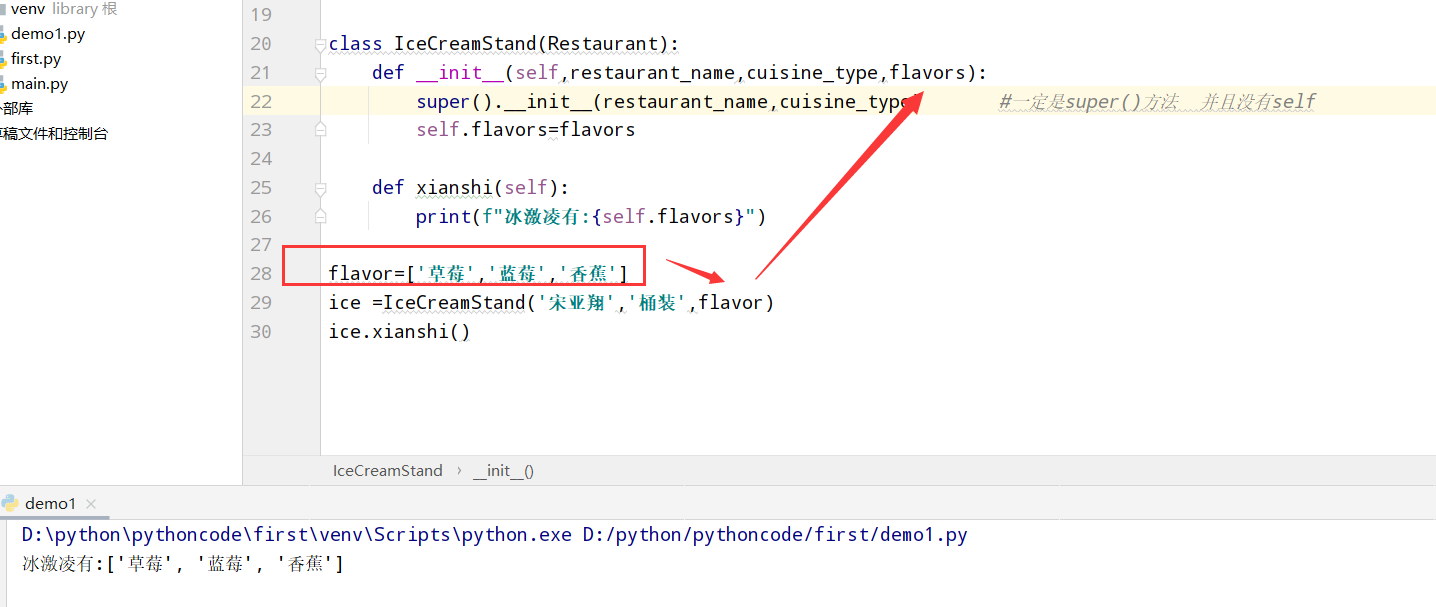
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
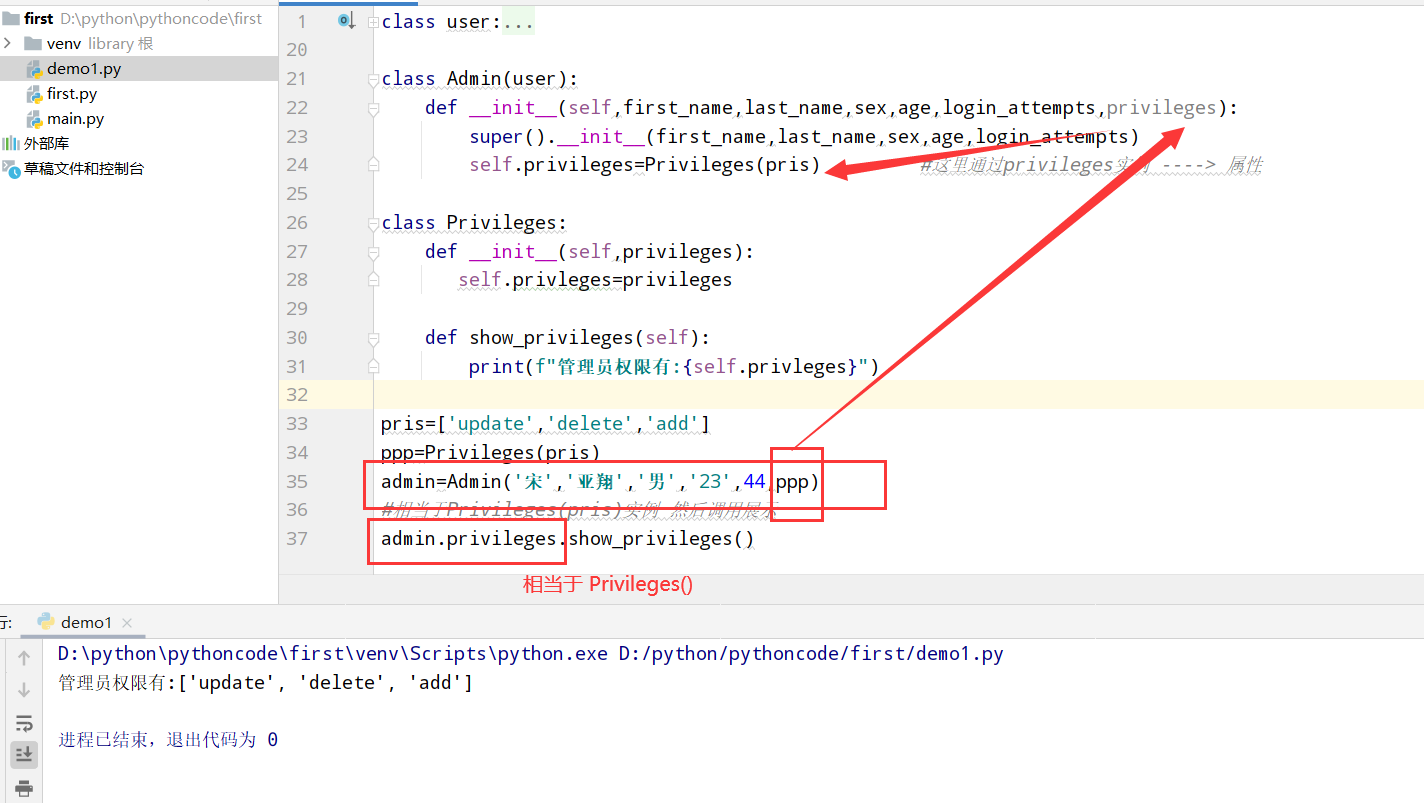
具体代码
1 |
|
执行结果
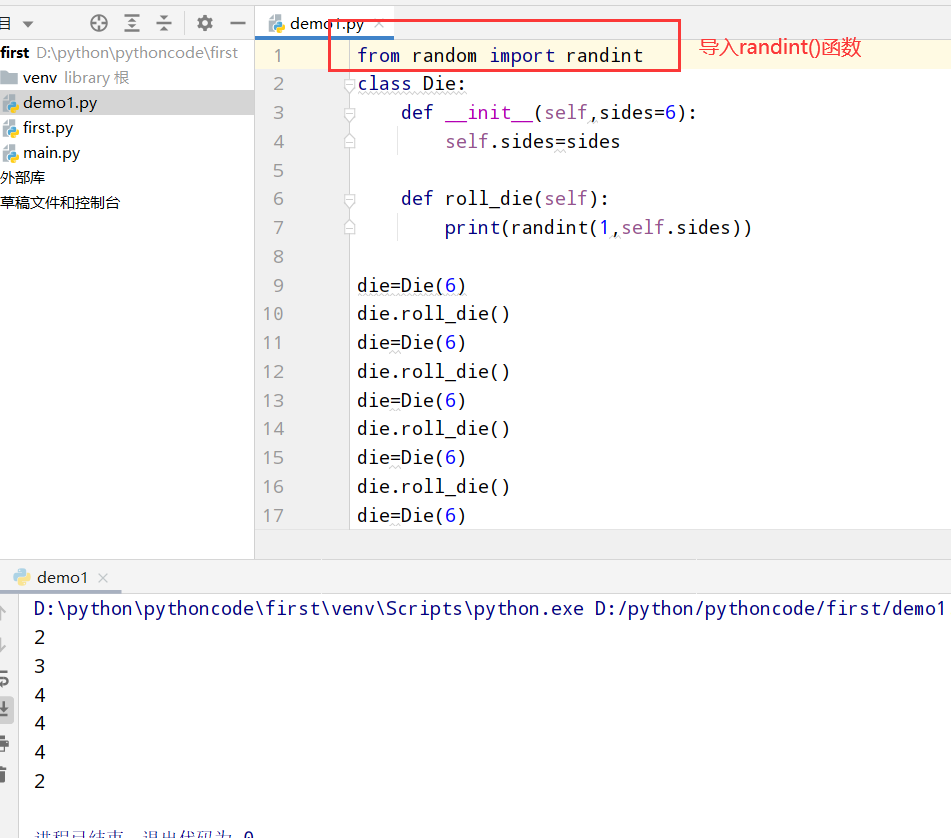
具体代码
1 |
|
执行结果

具体代码
1 |
|
执行结果
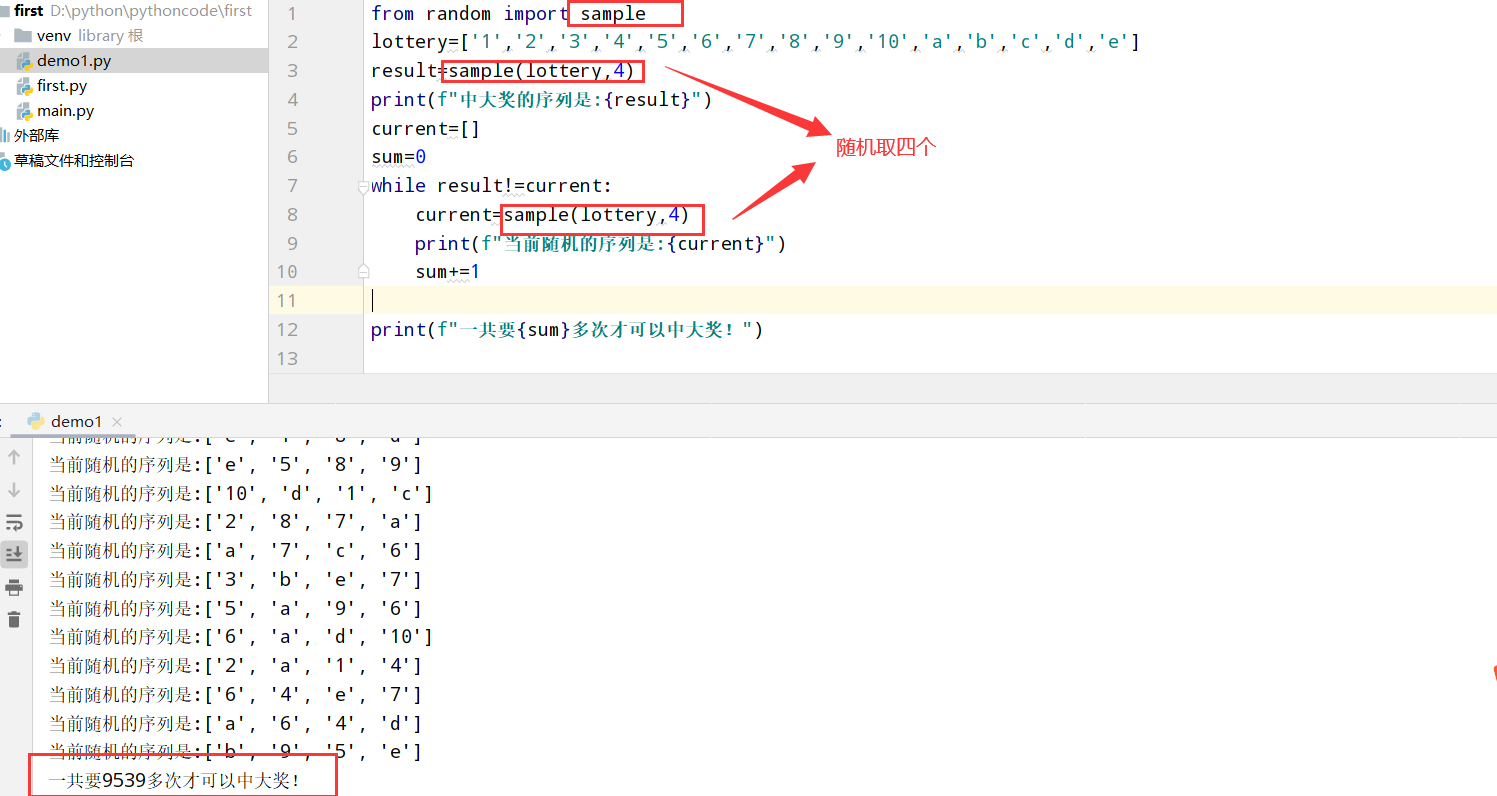
具体代码
1 |
|
执行结果
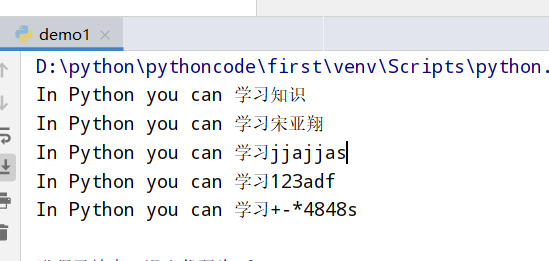
具体代码
1 |
|
执行结果
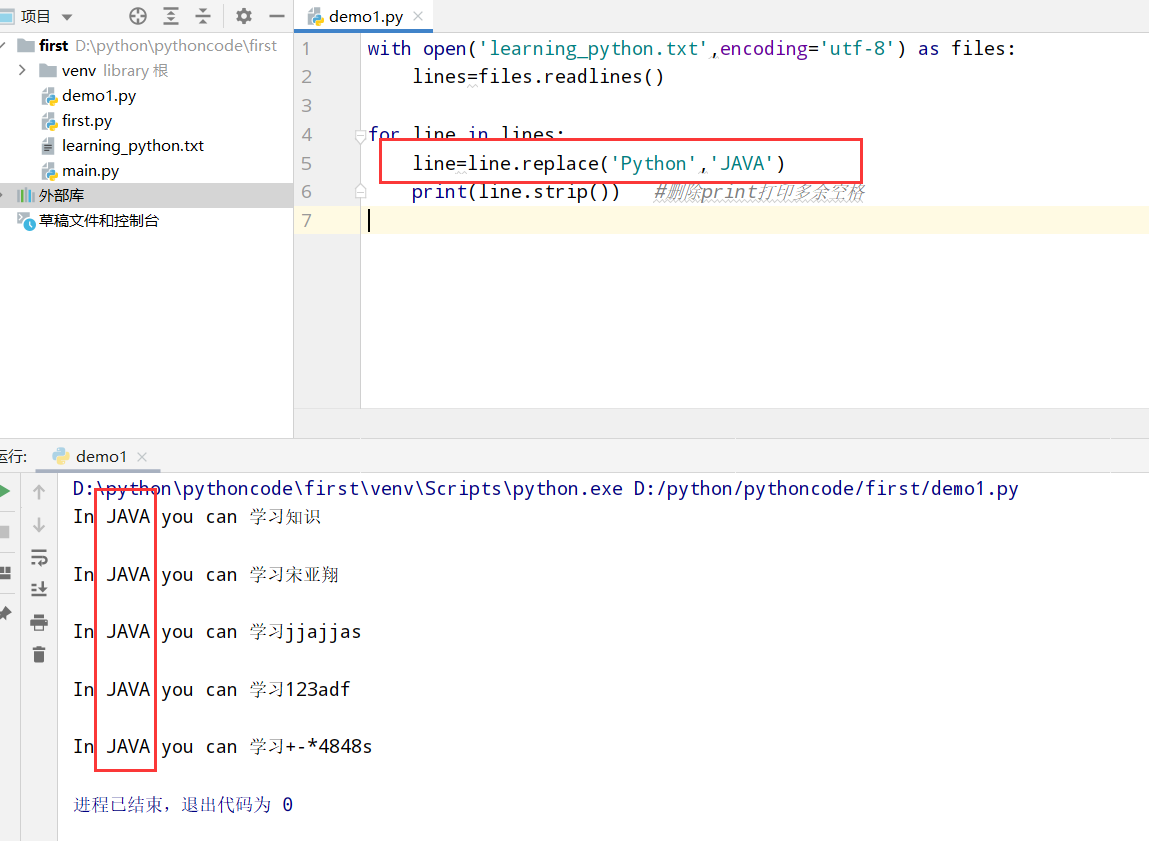
具体代码
1 |
|
执行结果
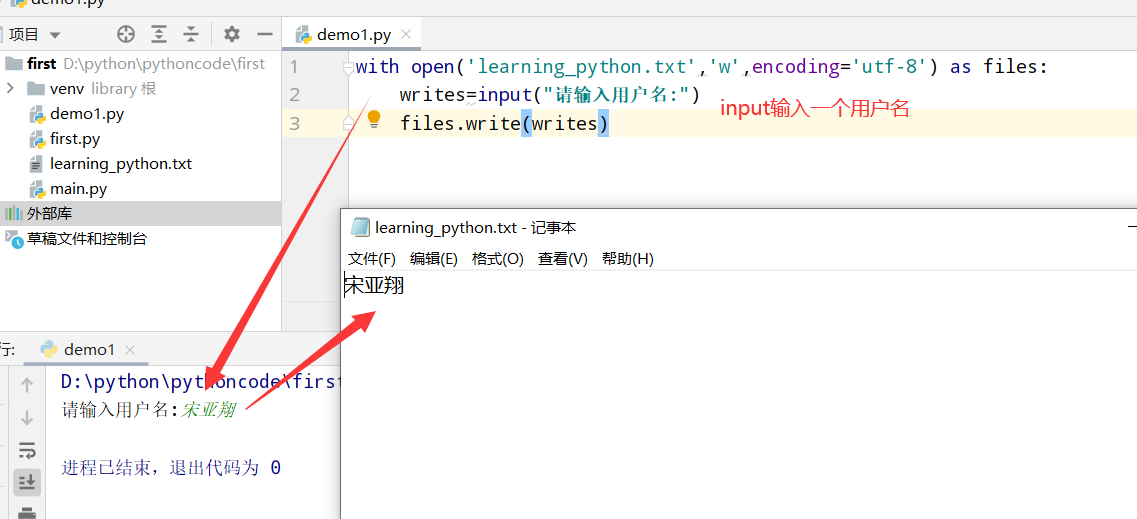
具体代码
1 |
|
执行结果
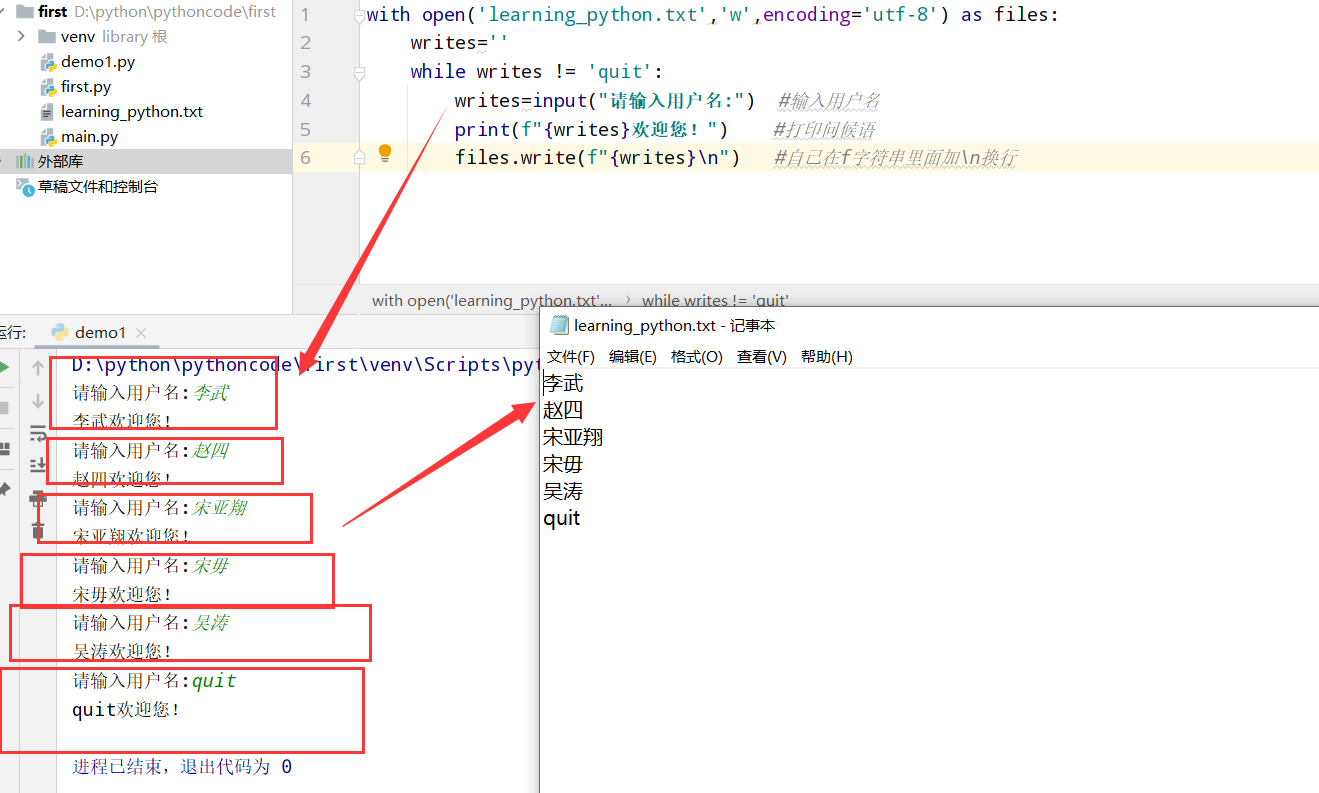
具体代码
1 |
|
执行结果
{kind=link}
{kind=link}