0.问题提出
关于创建xx数据库表,主键id的取值问题:如果自增可能会出现分库分表的麻烦,但是分库分表如果使用分布式id也有对应的缺点。因此,本文从①不分库分表②分库分表两个方面考虑
1.数据库自增ID
- 形式:使用数据库的id自增策略(Mysql的auto_increment)
- 优点:比较简单,天然有序
- 缺点:存在数量泄露,并发性能较差,数据库一旦故障就无法使用
- 解决方案:
1.1 数据库水平拆分
==每个数据库设置①不同的初始值和②相同的自增步长==
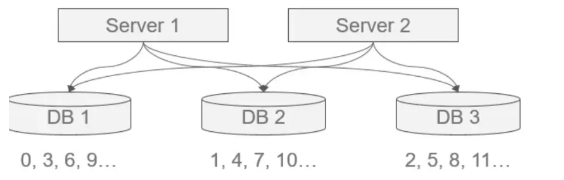
如图所示,这样可以保证DB123生成的ID是不冲突的,但是如果扩容,DB4数据库的话就没有初始值。
因此解决方案:
①根据扩容考虑决定步长,可以让多个数据库之间有空隙数字,可以扩容
②在其他未标记去扩容
1.2 批量缓存自增ID
==其实就是给数据库一批ID,不管多个DB之间的是否联系和连续,可能会出现多个数据库内连续,外不连续==
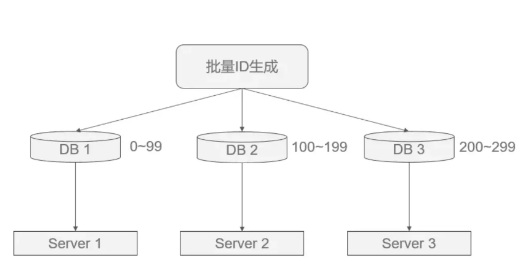
方案一步长的问题不好考虑,那我干脆一台机器分配,我分配的话肯定不会出现没法扩充,只是没办法保证多个数据库之间的ID是连续的。我DB4数据库来了,我可能忘了我就给他500-599的。
1.3 Redis生成ID
- 核心思路:Redis所有命令操作都是单线程的[本身提供像incr/increby这样的自增原子命令,能够保证Redis生成的ID唯一且有序]
- 优点:①不依赖数据库,灵活方便;②性能优于数据库;③数字天然有序
- 缺点:需要引入新的组件,增加系统复杂度;—》可以搭建redis集群提高吞吐量
- 适合场景:适合Redis生成每天从0开始的流水号。比如:订单号=日期+当前自增长号
2.UUID
形式:32个十六进制数字一共是128位【8-4-4-4-12】
优点:不是有序的,安全性更高
缺点:
①不是有序的,所以做主键的话innodb聚集索引内存消耗大,读写效率低;
②32个数字长度大,导致innodb叶子节点存储过大;
③因为无序,查找效率低下
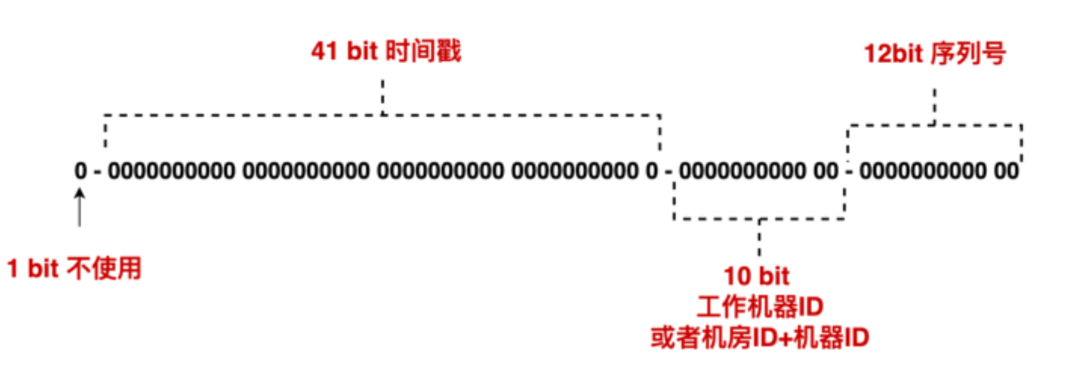
3.雪花算法
- 形式:最多长度为19一共是64位【1个64bit字节的整数】
第1个bit位:保留位,无实际作用
第2-42的bit位:这41位表示时间戳,精确到毫秒级别
第43-52的bit位:这10位表示专门负责生产ID的工作机器的id
第53-64的bit位:这12位表示序列号,也就是1毫秒内可以生成2 12 2^{12}2
优点:
①整体上按照时间趋势增加,后续插入索引树的性能较好;
②整个分布式系统不会发生ID碰撞;
③本地生成,且不依赖数据库,没有网络消耗
缺点:
①强依赖时间容易发生时种回拨【Map存储<机器ID,max_id>服务器出故障就从max_id重新生成】


