1.提出场景
目前,我们的定时任务都是基于SpringTask来实现的。但是SpringTask存在一些问题:
- 当微服务多实例部署时,定时任务会被执行多次。而事实上我们只需要这个任务被执行一次即可。
- 我们除了要定时创建表,还要定时持久化Redis数据到数据库,我们希望这多个定时任务能够按照顺序依次执行,SpringTask无法控制任务顺序(×)
不仅仅是SpringTask,其它单机使用的定时任务工具,都无法实现像这种任务执行者的调度、任务执行顺序的编排、任务监控等功能。这些功能必须要用到分布式任务调度组件。
2.原理[统一管理]
我们先来看看普通定时任务的实现原理,一般定时任务中会有两个组件:
- 任务:要执行的代码
- 任务触发器:基于定义好的规则触发任务
因此在多实例部署的时候,每个启动的服务实例都会有自己的任务触发器,这样就会导致各个实例各自运行,无法统一控制:
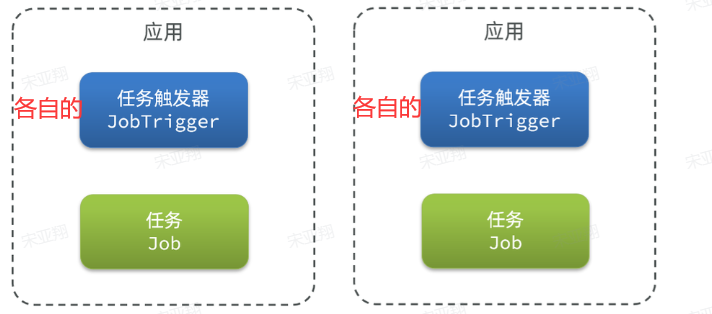
如果我们想统一控制各服务实例的任务执行和调度—>统一控制[统一出发、统一调度]
事实上,大多数的分布式任务调度组件都是这样做的:

这样一来,具体哪个任务该执行,什么时候执行,交给哪个应用实例来执行,全部都有统一的任务调度服务来统一控制。并且执行过程中的任务结果还可以通过回调接口返回,让我们方便的查看任务执行状态、执行日志。这样的服务就是分布式调度服务
3.技术对比
能够实现分布式任务调度的技术有很多,常见的有:【越往右越牛逼】
| Quartz | XXL-Job | SchedulerX | PowerJob | |
|---|---|---|---|---|
| 定时类型 | CRON | 频率、间隔、CRON | 频率、间隔、CRON、OpenAPI | 频率、间隔、CRON、OpenAPI |
| 任务类型 | Java | 多语言脚本 | 多语言脚本 | 多语言脚本 |
| 任务调度方式 | 随机 | 单机、分片 | 单机、广播、Map、MapReduce | 单机、广播、分片、Map、MapReduce |
| 管理控制台 | 无 | 支持 | 支持 | 支持 |
| 日志白屏 | 无 | 支持 | 支持 | 支持 |
| 报警监控 | 无 | 支持 | 支持 | 支持 |
| 工作流 | 无 | 有限 | 支持 | 支持 |
其中:
- Quartz由于功能相对比较落后,现在已经很少被使用了。
- SchedulerX是阿里巴巴的云产品,收费。
- PowerJob是阿里员工自己开源的一个组件,功能非常强大,不过目前市值占比还不高,还需要等待市场检验。
- XXL-JOB:开源免费,功能虽然不如PowerJob,不过目前市场占比最高,稳定性有保证。
扩展:多语言脚本–通过xxl-job平台,新增调度任务时候可以选择任务的运行模式【使用不同脚本语言编写任务】
==———–XXL-Job———–==
1.XXL-Job介绍
XXL-JOB的运行原理和架构如图:
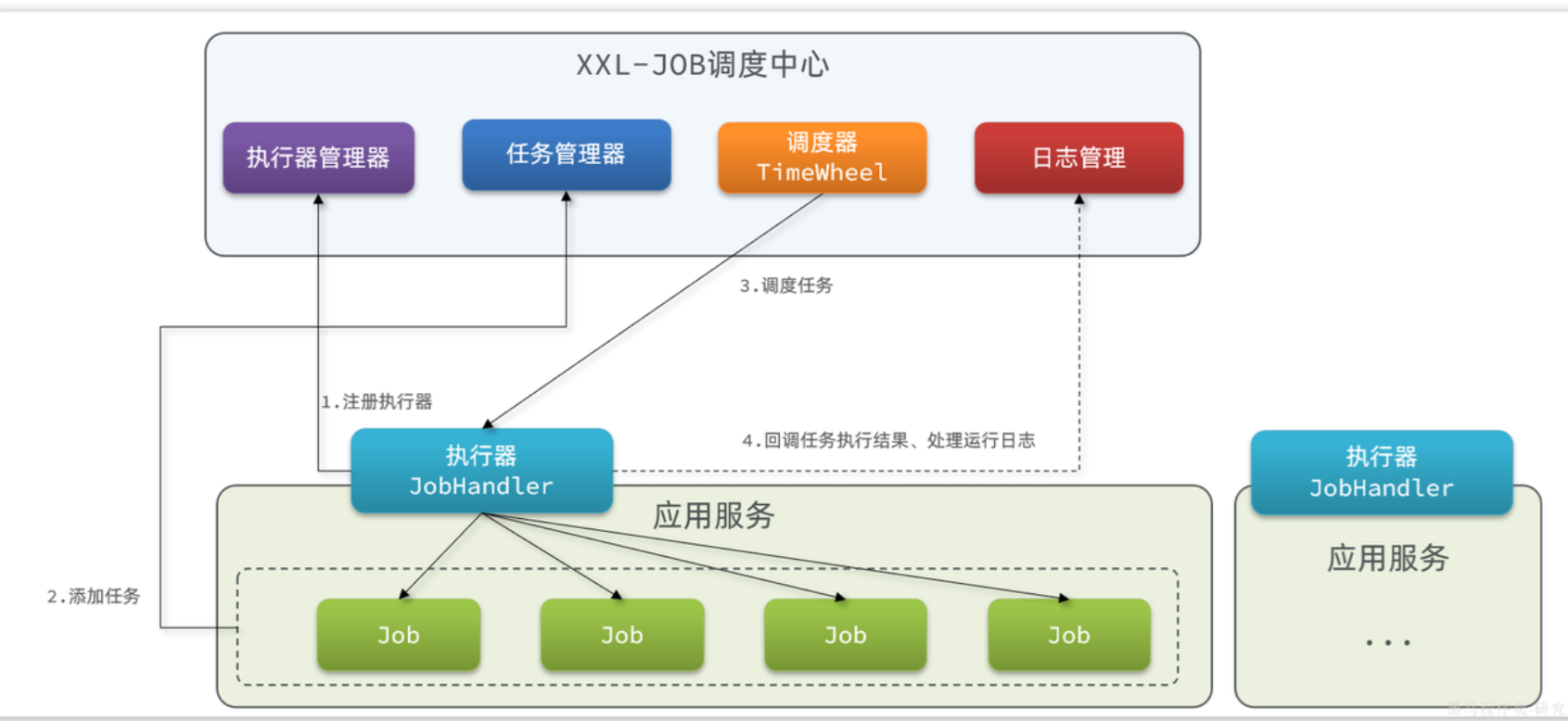
XXL-JOB分为两部分:
- 执行器:我们的服务引入一个XXL-JOB的依赖,就可以通过配置创建一个执行器。负责与XXL-JOB调度中心交互,执行本地任务。
- 调度中心:一个独立服务,负责管理执行器、管理任务、任务执行的调度、任务结果和日志收集。
其中,我们可以打开xxl-job页面:
- 页面:
2.XXL-Job部署[调度中心]
自己部署,分为两步:
- 运行初始化SQL,创建数据库表
- 利用Docker命令,创建并运行容器
2.1 创建数据库表
sql语句在对应github文件夹下:

2.2 Docker部署
docker命令:
1 | docker run \ |
3.XXL-Job实战
3.1 需求
每10s打印一次hello…
3.2 实现步骤

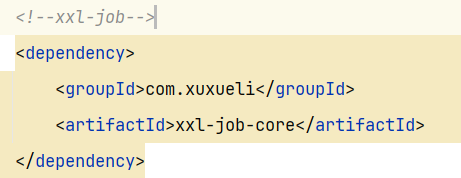
3.2.1 引入xxl-job依赖(微服务)
1 | <!--xxl-job--> |
3.2.2 yml配置xxl-job(微服务)
- 配置文件内容【nacos共享文件地址】
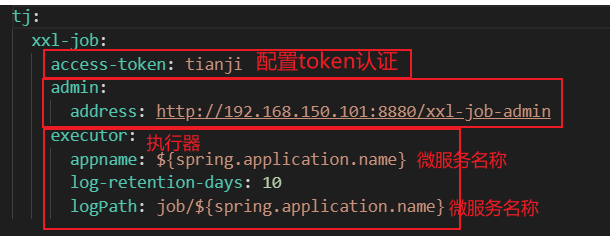
- 配置文件【因为我们使用nacos配置,所以需要bootstrap.yml配置nacos共享文件地址】
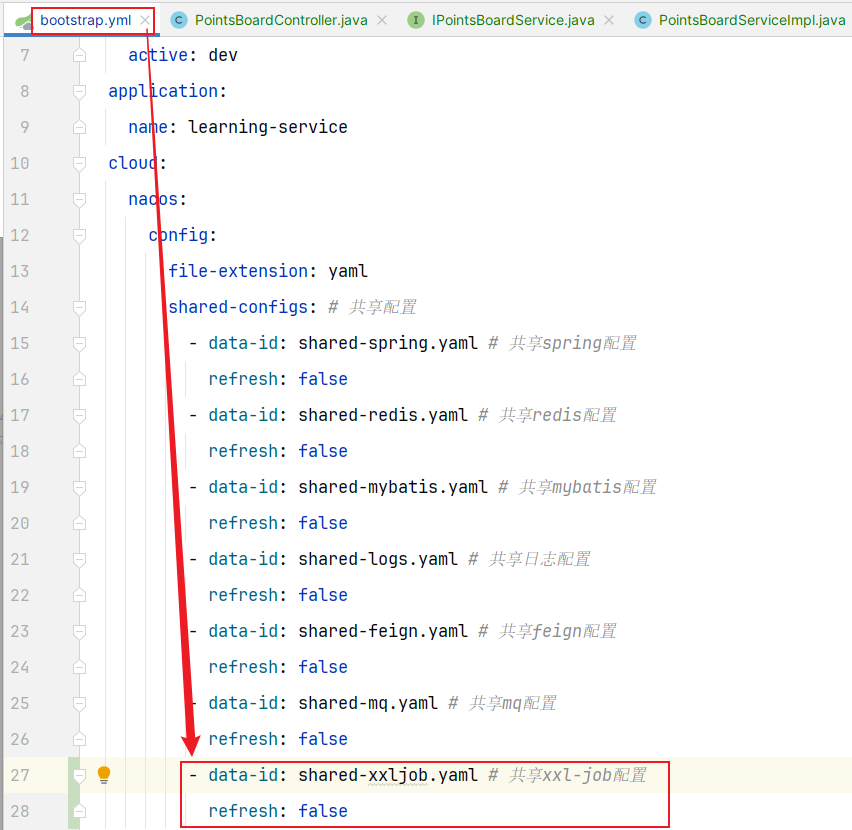
- 配置类
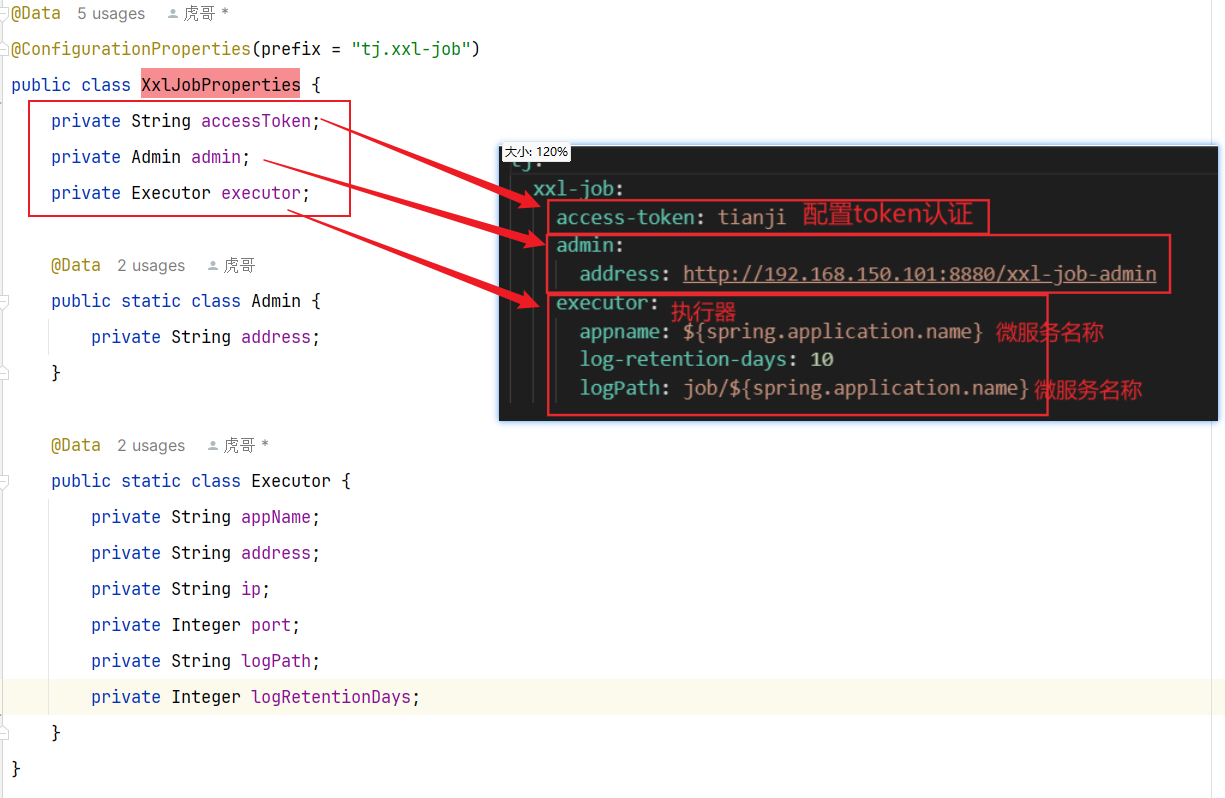
3.2.3 配置执行器类–XxlJobConfig(微服务)
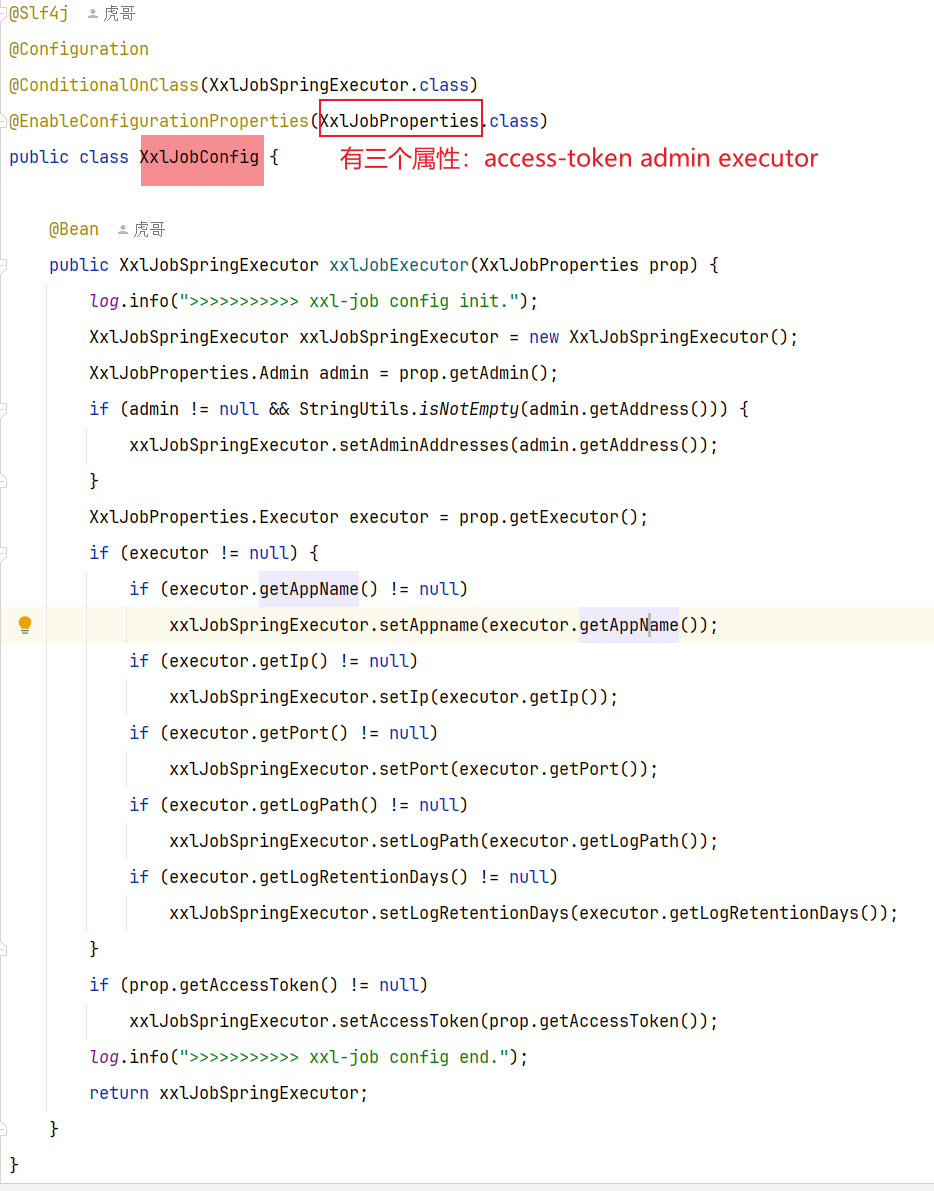
1 | - adminAddress:调度中心地址,天机学堂中就是填虚拟机地址 |
3.2.4 配置执行器和任务(页面)
- 新建执行器【微服务名称和yml配置一致】
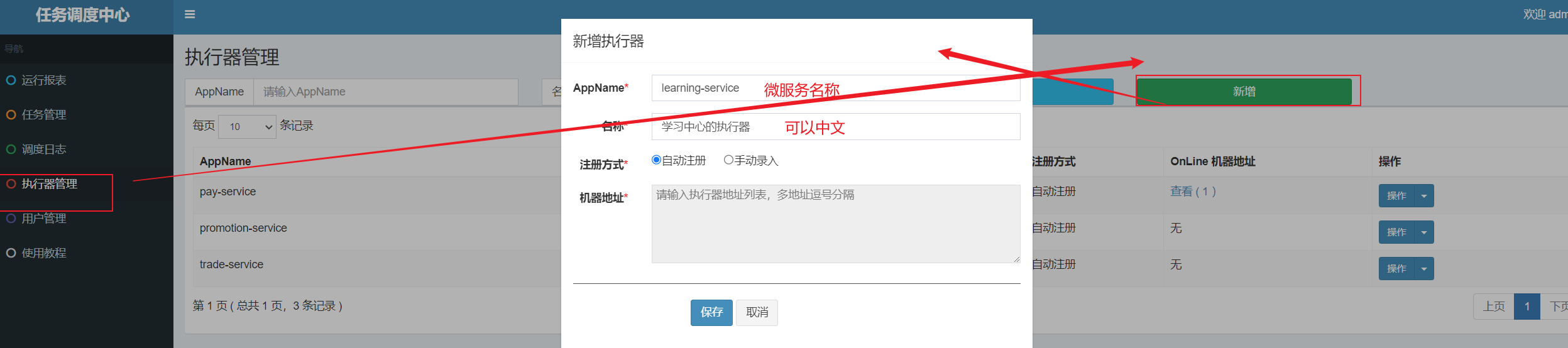
- 新建任务【JobHandler一定要和方法@XXlJob内容一致】
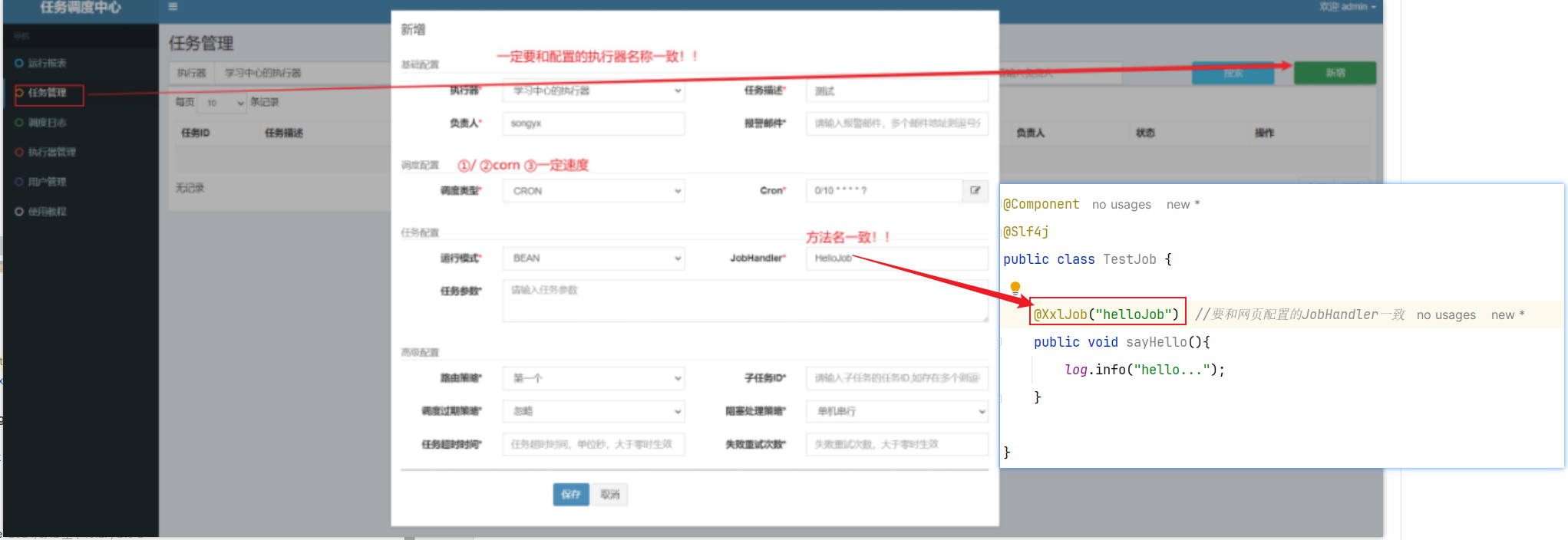
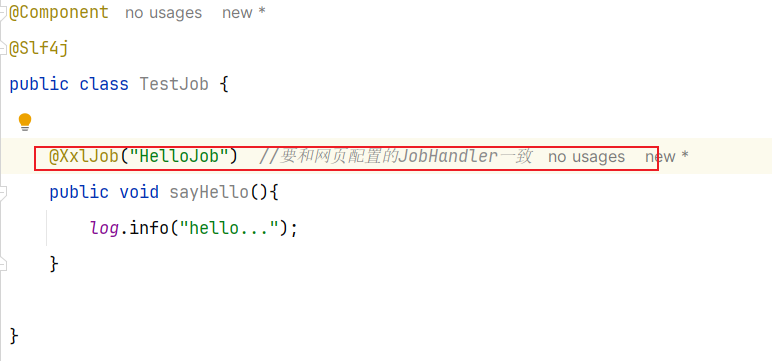
3.2.5 创建方法–添加@XxlJob注解(微服务)
JobHandler一定要和方法@XXlJob内容一致
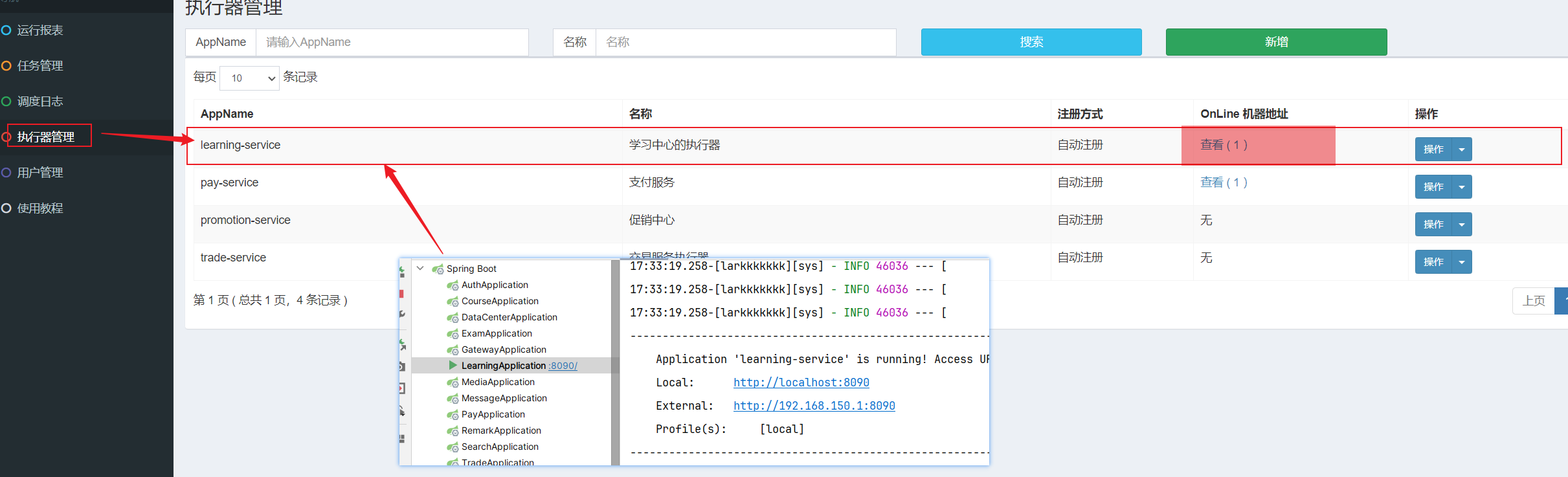
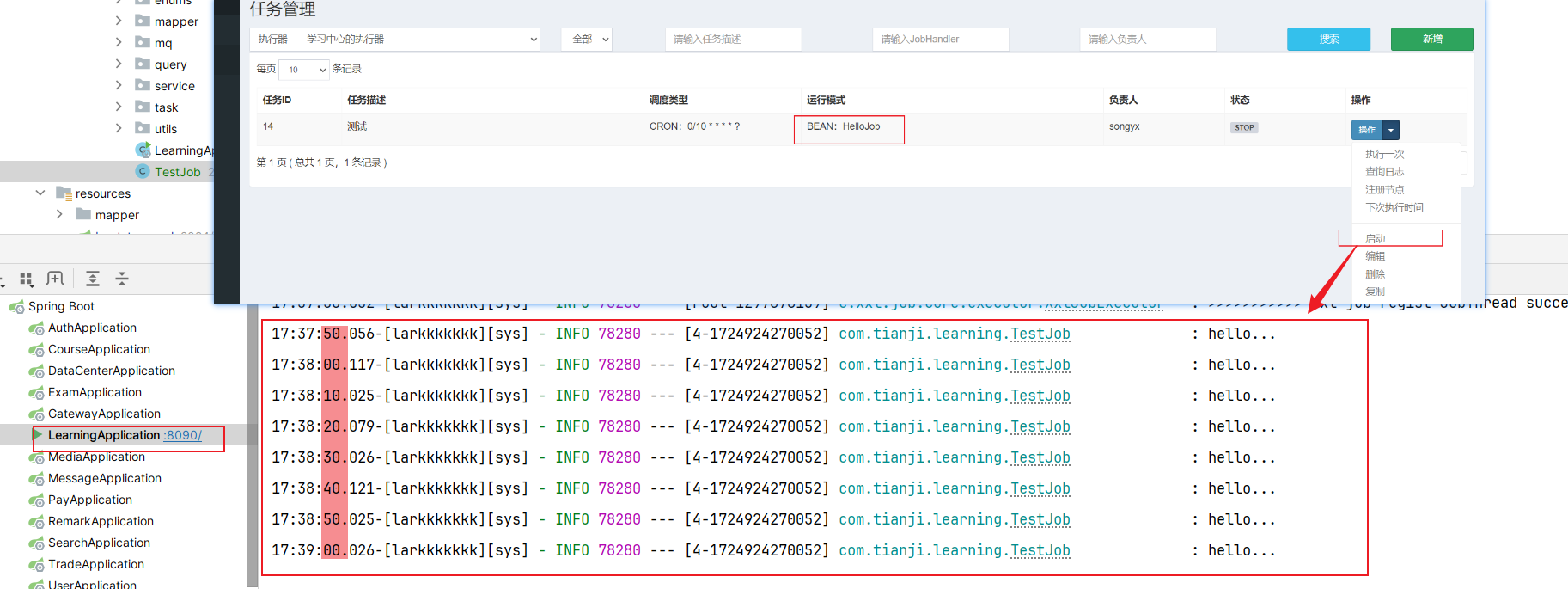
3.2.6 启动测试(页面)
- 启动本地微服务,会发现网页端执行器变化
- 启动任务
【想要测试的话也可以手动执行一次任务,但是要设置好调度策略】
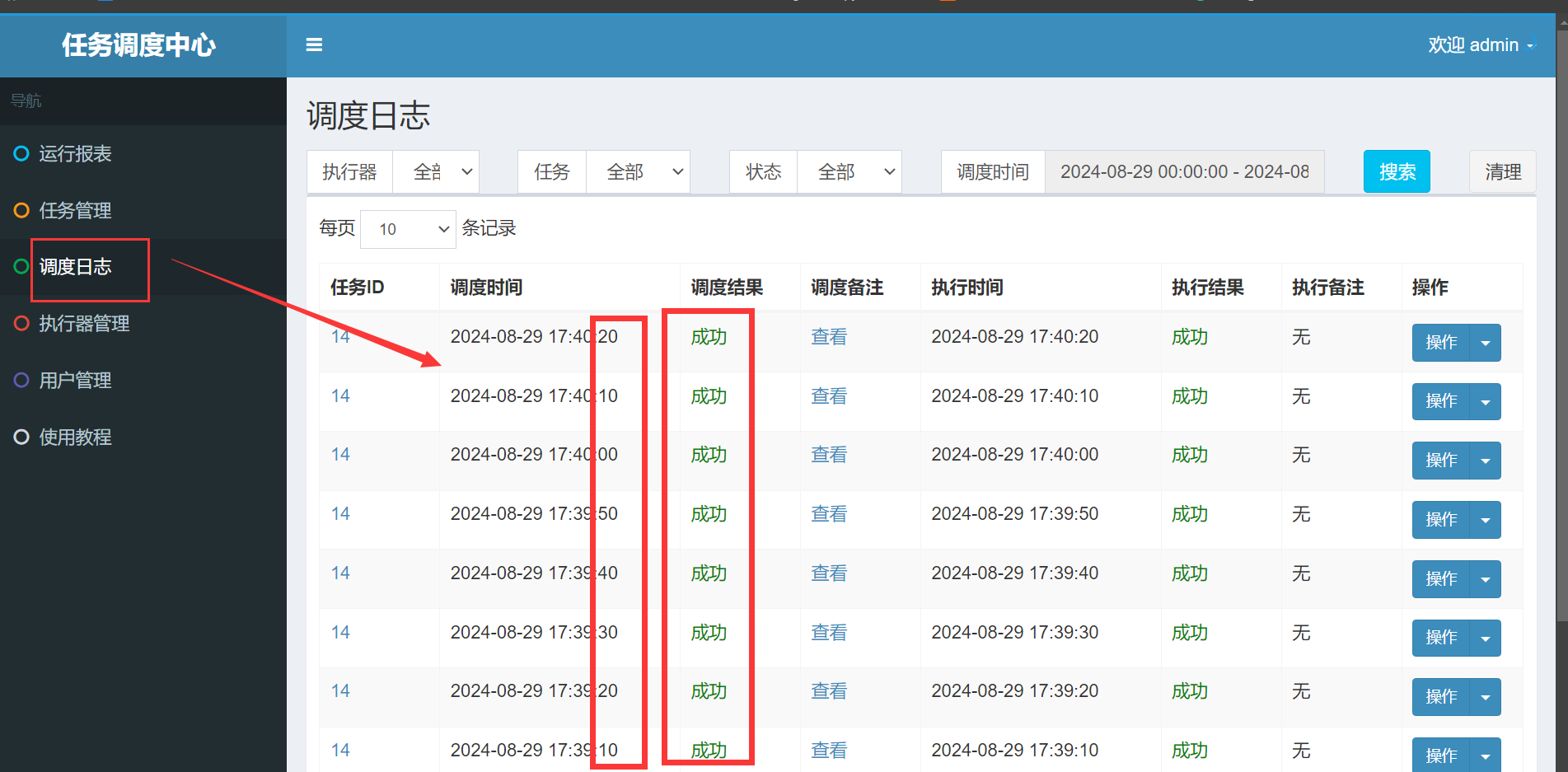
也可以在页面看到日志:
4.XXL-Job任务分片[不同部署处理不同数据]
3.1 原理
刚才定义的定时持久化任务,通过while死循环,不停的查询数据,直到把所有数据都持久化为止。这样如果数据量达到数百万,交给一个任务执行器来处理会耗费非常多时间—->实例多个部署,这样就会有多个执行器并行执行(但是多个执行器执行相同代码,都从第一页开始也会重复处理)—->任务分片【分片查询】
举例[类似于发牌]:
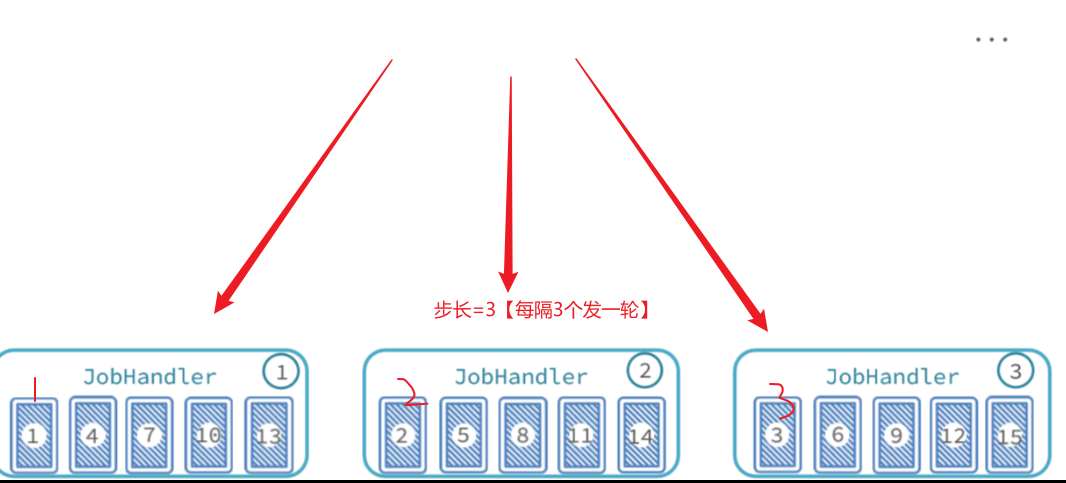
最终,每个执行器处理的数据页情况:
- 执行器1:处理第1、4、7、10、13、…页数据
- 执行器2:处理第2、5、8、11、14、…页数据
- 执行器3:处理第3、6、9、12、15、…页数据
要想知道每一个执行器执行哪些页数据,只要弄清楚两个关键参数即可:
- 起始页码(1,2,3):pageNo【执行器编号是多少,起始页码就是多少】
- 下一页的跨度(步长3):step【执行器有几个,跨度就是多少。也就是说你要跳过别人读取过的页码,类似于分布式ID的步长】
因此,现在的关键就是获取两个数据:
- 执行器编号
- 执行器数量
这两个参数XXL-JOB作为任务调度中心,肯定是知道的,而且也提供了API帮助我们获取:
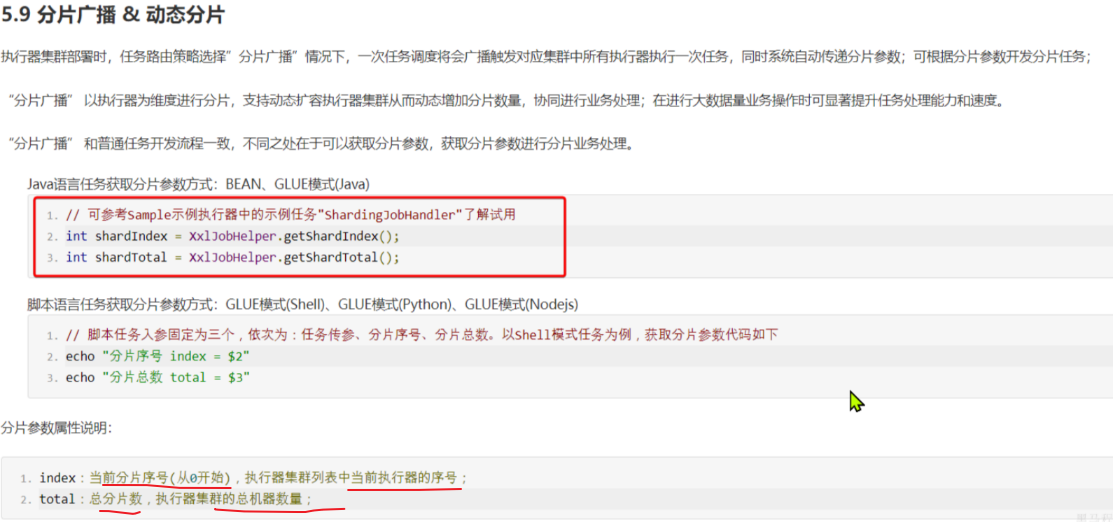
这里的分片序号其实就是执行器序号,不过是从0开始,那我们只要对序号+1,就可以作为起始页码了
3.2 业务优化
根据实际情况,分成多个机器[这个用例,分片1,2,3;步长为1]

3.3 引发问题解决方案
使用xxl-job定时每月初进行持久化:
①根据计算上个月时间创建上赛季mysql表
②根据查询出来上赛季redis数据,数据库新表名通过mp动态表名插件(本质是一个拦截器,在与mapper数据库接触过程中通过threadlocal更改数据库名)】然后查询数据
③根据非阻塞语句del删除redis上赛季数据—但是我考虑使用分片,这样导致分片1执行完异步执行删除,但是分片2执行完数据好像又回来了【针对②查询结果分页用xxlJob分片,log查日志没解决,我就打断点发现是分片次数问题,我就redis添加一个总数,一个分片执行次数,然后将删除逻辑放在一个新的定时任务,判断总数==分片执行次数,符合的情况才删除】


