1.海量数据存储策略[四种]
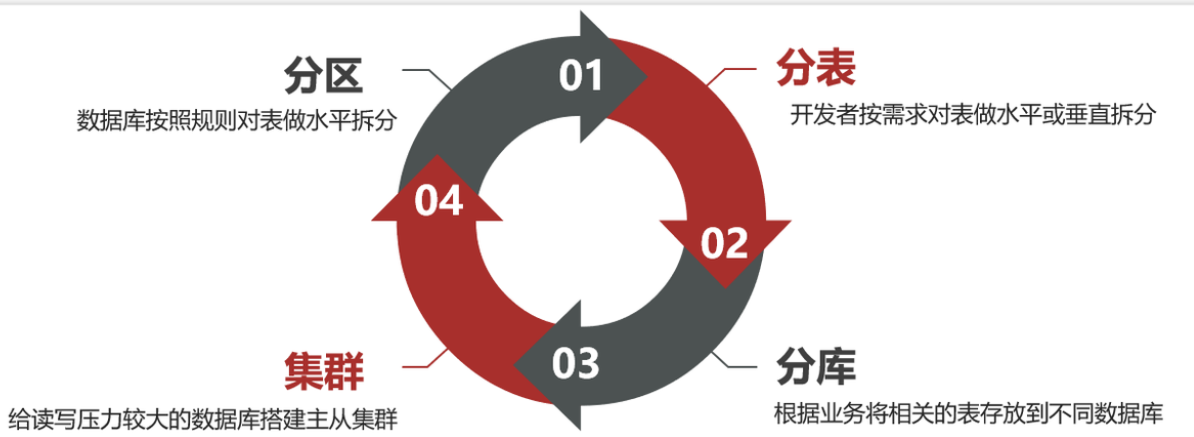
1.1 分区
表分区(Partition)是一种数据存储方案,可以解决单表数据较多的问题【MySQL5.1开始支持表分区功能】
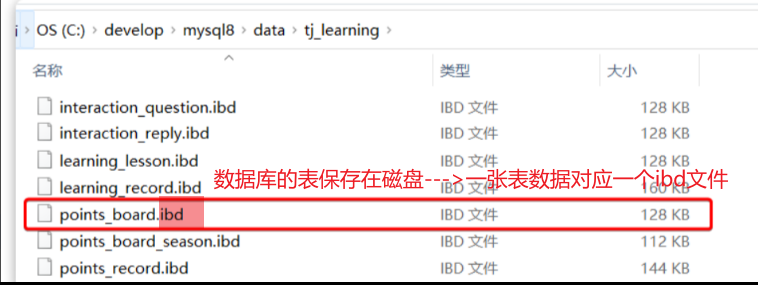
如果表数据过多 —> 文件体积非常大 —> 文件跨越多个磁盘分区 —> 数据检索时的速度就会非常慢 —>【Mysql5.1引入表分区】按照某种规则,把表数据对应的ibd文件拆分成多个文件来存储。
从物理上来看,一张表的数据被拆到多个表文件存储了【多张表】
从逻辑上来看,他们对外表现是一张表【一张表】 — CRUD不会变化,只是底层MySQL处理上会有变更,检索时可以只检索某个文件就可以
例如,我们的历史榜单数据,可以按照赛季切分:
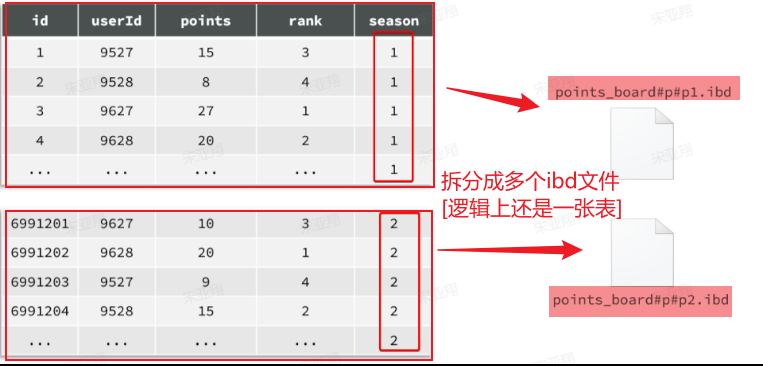
此时,赛季榜单表的磁盘文件就被分成了两个文件,但逻辑上还是一张表。CRUD不会变化,只是底层MySQL处理上会有变更,检索时可以只检索某个文件就可以
表分区的好处:
1.可以存储更多的数据,突破单表上限。甚至可以存储到不同磁盘,突破磁盘上限
2.查询时可以根据规则只检索某一个文件,提高查询效率
3.数据统计时,可以多文件并行统计,最后汇总结果,提高统计效率【分而治之,各自统计】
4.对于一些历史数据,如果不需要时,可以直接删除分区文件,提高删除效率
表分区的方式:【对数据做水平拆分】
- Range分区:按照指定字段的取值范围分区 –保单表,根据1-10,11-20这样10个为一组区分
- List分区:按照指定字段的枚举值分区【必须提前制定所有分区值,否则会因为找不到报错】–保单表,根据保单是车险财/非车进行区分
- Hash分区:按照字段做hash运算后分区【字段一般是对数值类型】 –保单表,根据保单表%hash运算进行区分
- Key分区:按照指定字段的值做运算结果分区【不限定字段类型】 –保单表,根据保单号%9进行区分
1.2 分表
开发者自己对表的处理,与数据库无关
从物理上来看,一张表的数据被拆到多个表文件存储了【多张表】
从逻辑上来看,【多张表】 — CRUD会变化,需要考虑取哪张表做数据处理
在开发中我们很多情况下业务需求复杂,更看重分表的灵活性。因此,我们大多数情况下都会选择分表方案。
分表的好处:
1.拆分方式更加灵活【可以水平也可以垂直】
2.可以解决单表字段过多问题【垂直分表,分在多个表】
分表的坏处:
- 1.CRUD需要自己判断访问哪张表
- 2.垂直拆分还会导致事务问题及数据关联问题:【原本一张表的操作,变为多张表操作,要考虑长事务情况】
1.2.1 水平分表
例如,对于赛季榜单,我们可以按照赛季拆分为多张表,每一个赛季一张新的表。如图:
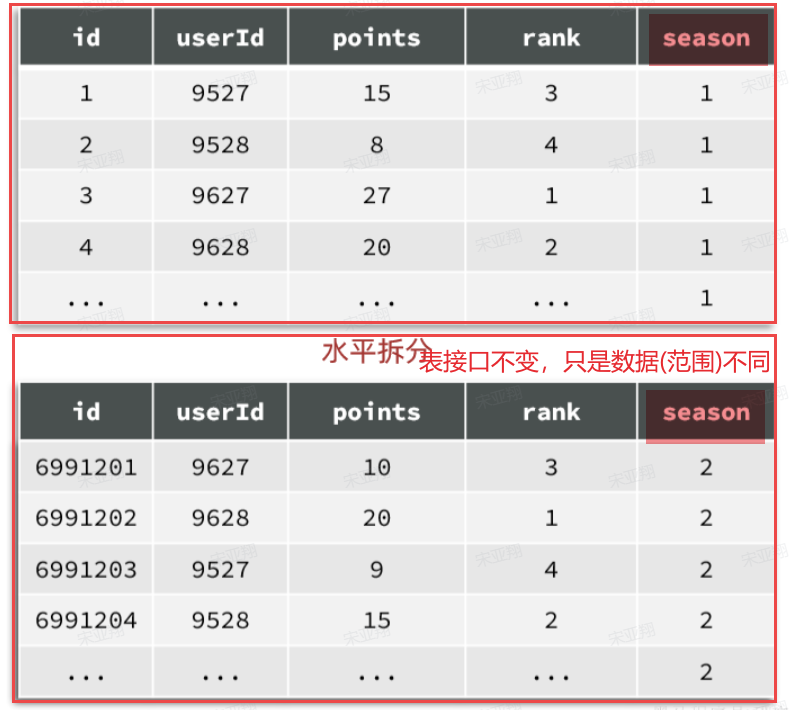
这种方式就是水平分表,表结构不变,仅仅是每张表数据不同。查询赛季1,就找第一张表。查询赛季2,就找第二张表。
1.2.2 垂直分表
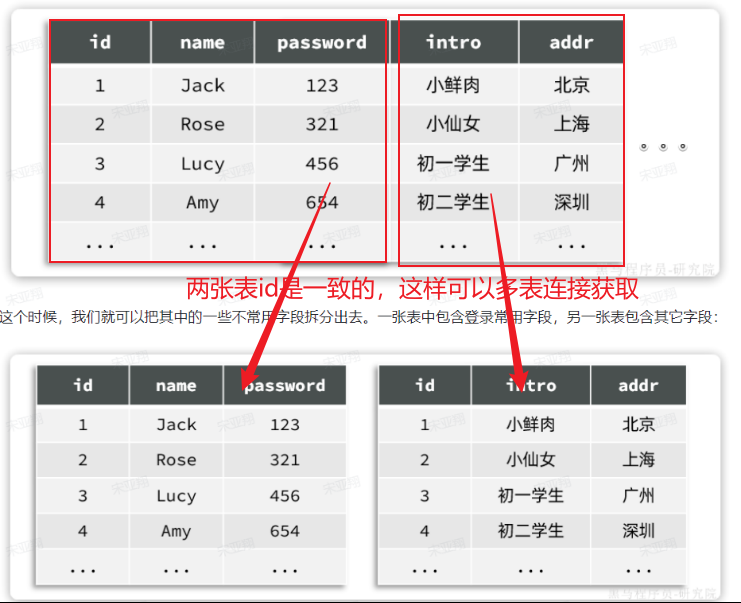
如果一张表的字段非常多(比如达到30个以上,这样的表我们称为宽表)。宽表由于字段太多,单行数据体积就会非常大,虽然数据不多,但可能表体积也会非常大!从而影响查询效率。
例如一个用户信息表,除了用户基本信息,还包含很多其它功能信息:
1.3 分库[垂直分库]
无论是分区,还是分表,我们刚才的分析都是建立在单个数据库的基础上。但是单个数据库也存在一些问题:
- 单点故障问题:数据库发生故障,整个系统就会瘫痪【鸡蛋都在一个篮子里】
- 单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈【性能有限制】
- 单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢【存储有限制】
综上,在大型系统中,我们除了要做①分表、还需要对数据做②分库—>建立综合集群。
优点:【解决了单个数据库的三大问题】
1.解决了海量数据存储问题,突破了单机存储瓶颈
2.提高了并发能力,突破了单机性能瓶颈
3.避免了单点故障
缺点:
1.成本非常高【要多个服务器,多个数据库】
2.数据聚合统计比较麻烦【因为牵扯多个数据库,有些语句会很麻烦】
3.主从同步的一致性问题【主数据库往从数据库更新,会有不可取消的延误时间,只能通过提高主从数据库网络带宽,机器性能等操作(↓)延误时间】
4.分布式事务问题【因为涉及多个数据库多个表,使用seata分布式事务可以解决】
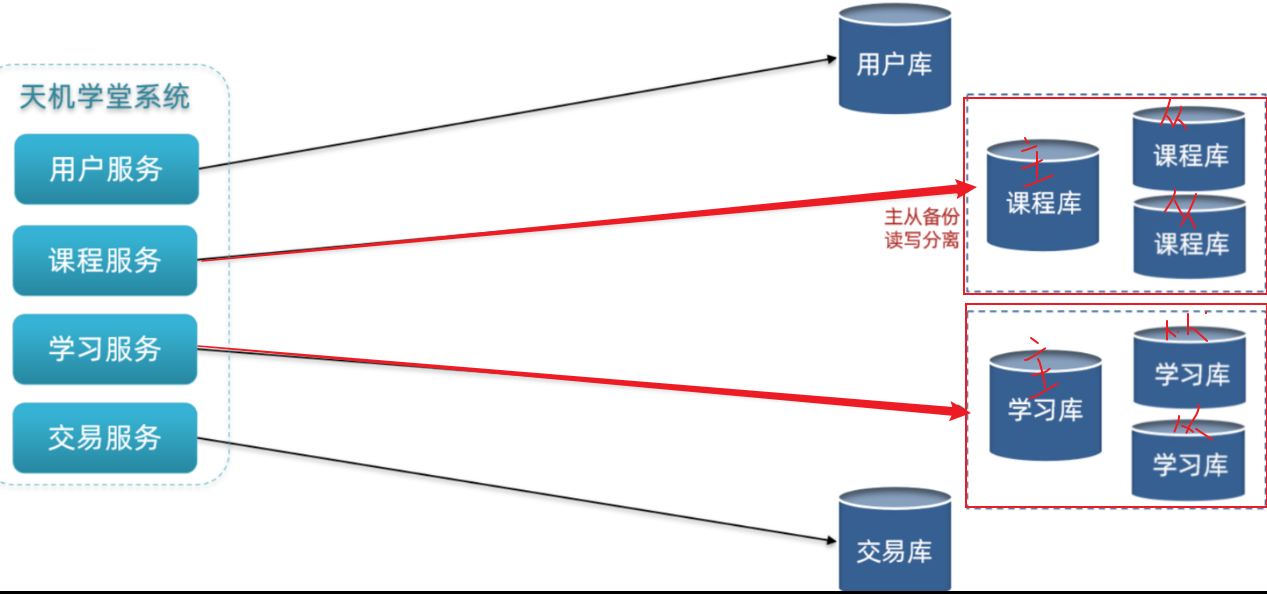
微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的
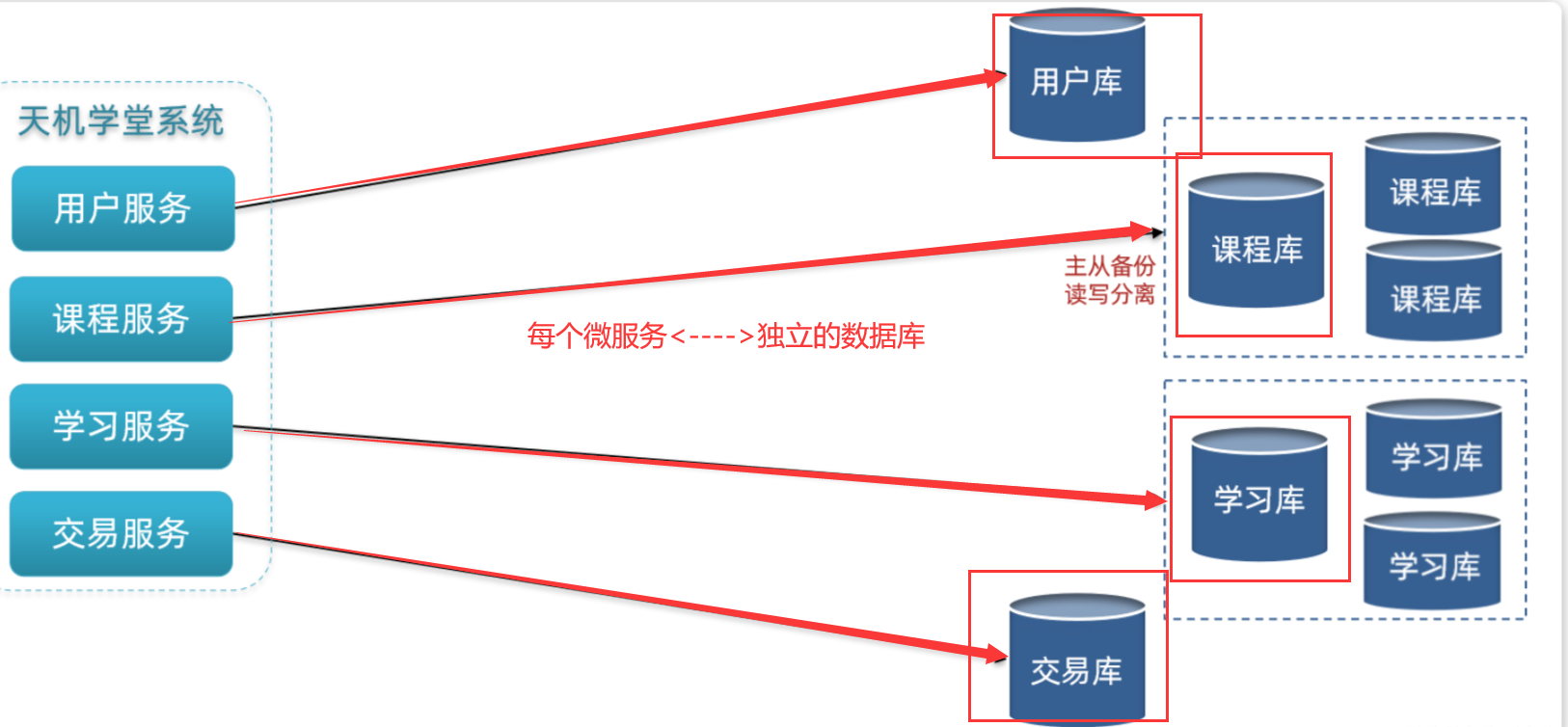
1.4 集群[主写从读]
[保证单节点的高可用性]给数据库建立主从集群,主节点向从节点同步数据,两者结构一样