title: Mysql分表分库-Sharding-Sphere
date: 2024-07-22 09:39:47
tags: Mysql
1.分表分库概念
1.1 分表
开发者自己对表的处理,与数据库无关
从物理上来看,一张表的数据被拆到多个表文件存储了【多张表】
从逻辑上来看,【多张表】 — CRUD会变化,需要考虑取哪张表做数据处理
在开发中我们很多情况下业务需求复杂,更看重分表的灵活性。因此,我们大多数情况下都会选择分表方案。
分表的好处:
1.拆分方式更加灵活【可以水平也可以垂直】
2.可以解决单表字段过多问题【垂直分表,分在多个表】
分表的坏处:
- 1.CRUD需要自己判断访问哪张表
- 2.垂直拆分还会导致事务问题及数据关联问题:【原本一张表的操作,变为多张表操作,要考虑长事务情况】
而分表有两种分法:
- 水平分表[根据一些维度横向]
水平分表是将表中的数据行拆分到多个不同的表/数据库,通常是根据某种键值来拆分
- 垂直分表[部分字段拆分到别的表]
垂直分表是将表中的列拆分到多个不同的表,通常是根据列的使用频率或者业务逻辑来拆分
- 两者区别
| 垂直分表 | 水平分表 | |
|---|---|---|
| 拆分依据 | 列的使用频率/业务逻辑 | 某种键值[用户ID,时间戳] |
| 目的 | 优化表结构,提高访问速度 | 解决单表数据量过大导致性能问题,分散数据到多个表提高查询和更新性能 |
| 优点 | 1.可以减少页面加载时间,只查询必要的列2.降低数据冗余,提高存储效率 | 1.减少单个表数据量,提高单表管理能力和访问速度2.易于实现,大多数据库中间件都支持水平分表 |
| 缺点 | 1.增加了数据库复杂性,需要更多join连接合并数据2.分表策略要根据业务仔细设计 | 1.例如联表查询就需要额外的逻辑处理[有的符合行在A,有的符合行在B]2.键值需要谨慎设计 |
| 应用场景 | 表中有大量列,访问只有少数 几个列情况 | 处理具有明显数据划分界限情况 |
| 注意事项 | 1.分表操作可能会影响数据库的事务管理,需要考虑跨表操作的一致性2.分表策略应该基于实际的业务需求和数据访问模式来设计3.分表后的数据迁移和数据完整性保持是实施过程中最难的挑战 |
1.1.1 水平分表
例如,对于赛季榜单,我们可以按照赛季拆分为多张表,每一个赛季一张新的表。如图:
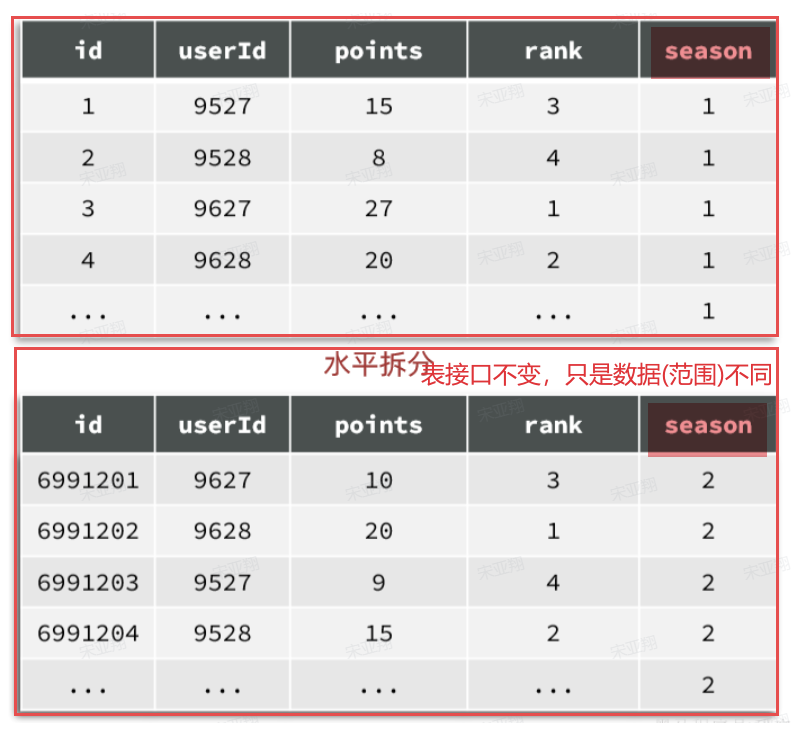
这种方式就是水平分表,表结构不变,仅仅是每张表数据不同。查询赛季1,就找第一张表。查询赛季2,就找第二张表。
1.1.2 垂直分表
如果一张表的字段非常多(比如达到30个以上,这样的表我们称为宽表)。宽表由于字段太多,单行数据体积就会非常大,虽然数据不多,但可能表体积也会非常大!从而影响查询效率。
例如一个用户信息表,除了用户基本信息,还包含很多其它功能信息:
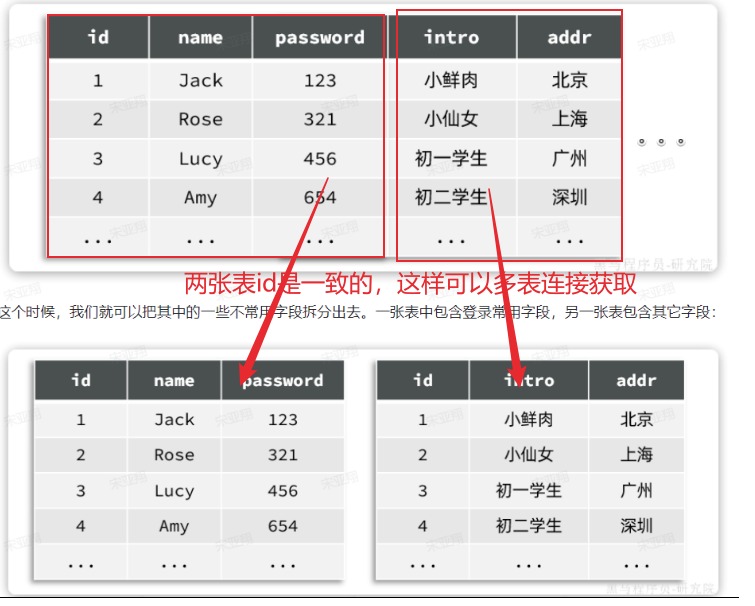
1.2 分库[垂直分库]

- 1.考虑分库的目标:提高读写性能,写入性能还是两者兼顾
- 2.考虑分片键的选择:通常是表中某个字段
- 3.考虑分片策略:①范围分片(基于数值范围)②哈希分片(基于哈希算法)③列表分片(基于枚举值)
无论是分区,还是分表,我们刚才的分析都是建立在单个数据库的基础上。但是单个数据库也存在一些问题:
- 单点故障问题:数据库发生故障,整个系统就会瘫痪【鸡蛋都在一个篮子里】
- 单库的性能瓶颈问题:单库受服务器限制,其网络带宽、CPU、连接数都有瓶颈【性能有限制】
- 单库的存储瓶颈问题:单库的磁盘空间有上限,如果磁盘过大,数据检索的速度又会变慢【存储有限制】
综上,在大型系统中,我们除了要做①分表、还需要对数据做②分库—>建立综合集群。
优点:【解决了单个数据库的三大问题】
1.解决了海量数据存储问题,突破了单机存储瓶颈
2.提高了并发能力,突破了单机性能瓶颈
3.避免了单点故障
缺点:
1.成本非常高【要多个服务器,多个数据库】
2.数据聚合统计比较麻烦【因为牵扯多个数据库,有些语句会很麻烦】
3.主从同步的一致性问题【主数据库往从数据库更新,会有不可取消的延误时间,只能通过提高主从数据库网络带宽,机器性能等操作(↓)延误时间】
4.分布式事务问题【因为涉及多个数据库多个表,使用seata分布式事务可以解决】
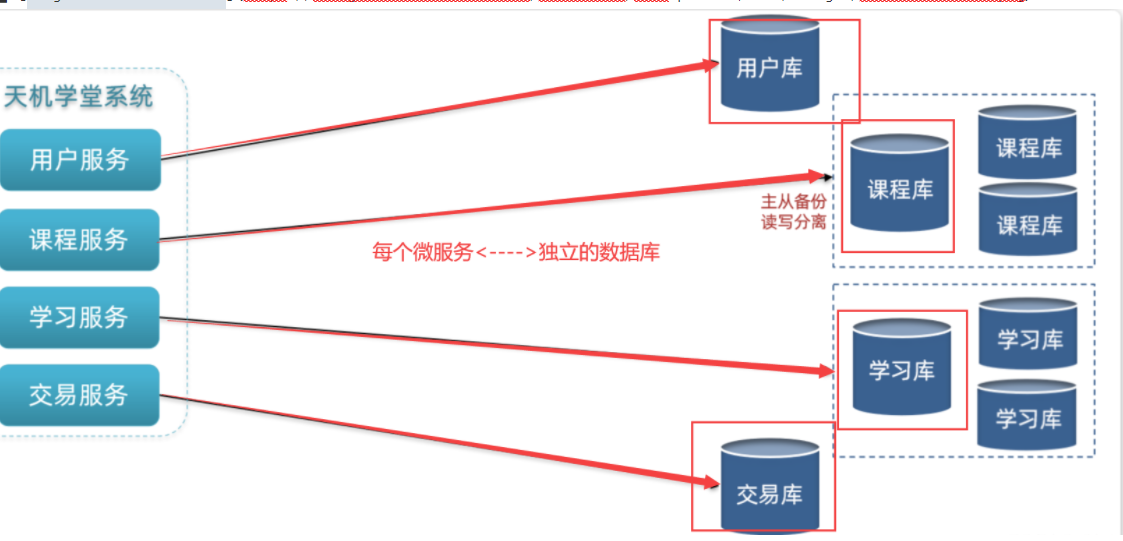
微服务项目中,我们会按照项目模块,每个微服务使用独立的数据库,因此每个库的表是不同的
2.Sharding-Sphere概念
2.1 Sharding-JDBC框架简介[配置麻烦]
Sharding-JDBC的定位是一款轻量级Java框架,它会以POM依赖的形式嵌入程序,运行期间会和Java应用共享资源,这款框架的本质可以理解成是JDBC的增强版,只不过Java原生的JDBC仅支持单数据源的连接,而Sharding-JDBC则支持多数据源的管理,部署形态如下:
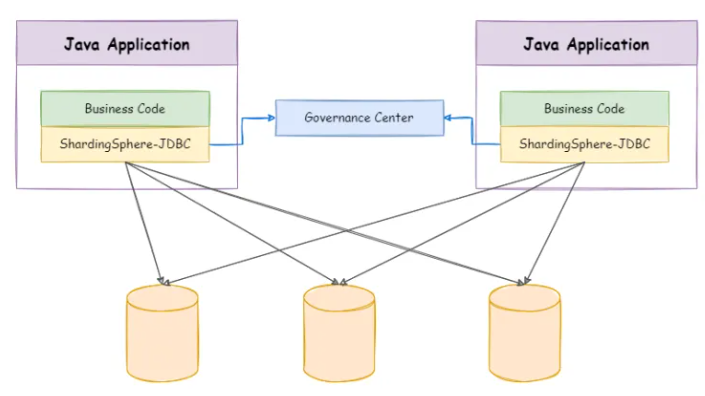
Java-ORM框架在执行SQL语句时,Sharding-JDBC会以切面的形式拦截发往数据库的语句,接着根据配置好的数据源、分片规则和路由键,为SQL选择一个目标数据源,然后再发往对应的数据库节点处理。
Sharding-JDBC在整个业务系统中对性能损耗极低,但为何后面又会推出Sharding-Proxy呢?因为Sharding-JDBC配置较为麻烦,比如在分布式系统中,任何使用分库分表的服务都需要单独配置多数据源地址、路由键、分片策略….等信息,同时它也仅支持Java语言,当一个系统是用多语言异构的,此时其他语言开发的子服务,则无法使用分库分表策略。
2.2 Sharding-Proxy中间件简介[成本过大]
也正是由于配置无法统一管理、不支持异构系统的原因,后面又引入Sharding-Proxy来解决这两个问题,Sharding-Proxy可以将其理解成一个伪数据库,对于应用程序而言是完全透明的,它会以中间件的形式独立部署在系统中,部署形态如下:
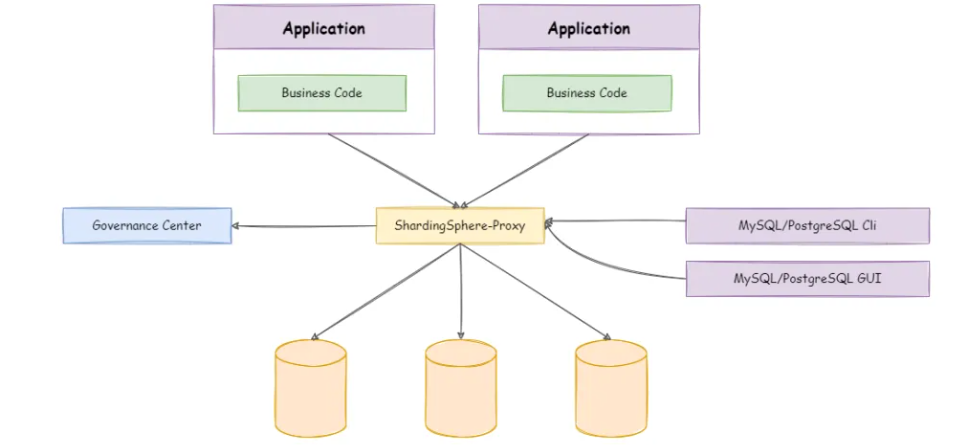
使用Sharding-Proxy的子服务都会以连接数据库的形式,与其先建立数据库连接,然后将SQL发给它执行,Sharding-Proxy会根据分片规则和路由键,将SQL语句发给具体的数据库节点处理,数据库节点处理完成后,又会将结果集返回给Sharding-Proxy,最终再由它将结果集返回给具体的子服务。
但
Sharding-Proxy虽然可以实现分库分表配置的统一管理,以及支持异构的系统,但因为需要使用独立的机器部署,同时还会依赖Zookeeper作为注册中心,所以硬件成本会直线增高,至少需要多出3~4台服务器来部署。
同时SQL执行时,需要先发给Proxy,再由Proxy发给数据库节点,执行完成后又会从数据库返回到Proxy,再由Proxy返回给具体的应用,这个过程会经过四次网络传输的动作,因此相较于原本的Sharding-JDBC来说,性能、资源开销更大,响应速度也会变慢。
2.3 JDBC、Proxy混合部署模式[取长补短]
如果用驱动式分库分表,虽然能够让Java程序的性能最好,但无法支持多语言异构的系统,但如果纯用代理式分库分表,这显然会损害Java程序的性能,因此在Sharding-Sphere中也支持JDBC、Proxy做混合式部署,也就是Java程序用JDBC做分库分表,其他语言的子服务用Proxy做分库分表,部署形态如下:
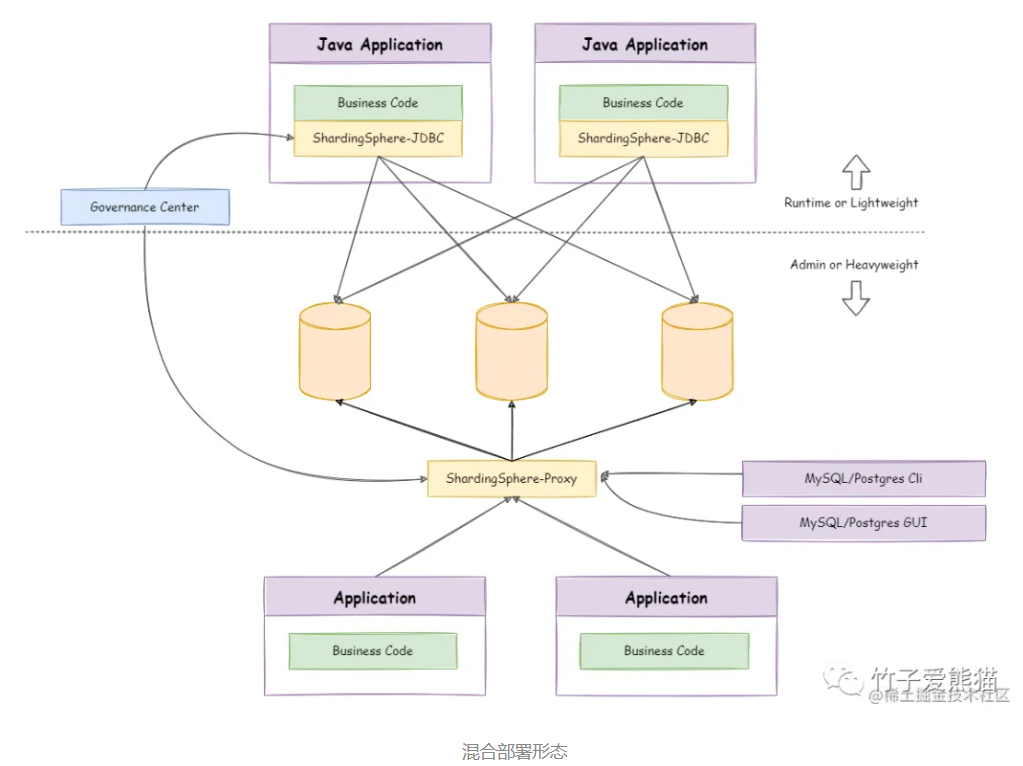
这种混合式的部署方案,所有的数据分片策略都会放到Zookeeper中统一管理,然后所有的子服务都去Zookeeper中拉取配置文件,这样就能很方便的根据业务情况,来灵活的搭建适用于各种场景的应用系统,这样也能够让数据源、分片策略、路由键….等配置信息灵活,可以在线上动态修改配置信息,修改后能够在线上环境中动态感知。
但
Sharding-Sphere还提供了一种单机模式,即直接将数据分片配置放在Proxy中,但这种方式仅适用于开发环境,因为无法将分片配置同步给多个实例使用,也就意味着会导致其他实例由于感知不到配置变化,从而造成配置信息不一致的错误。
3.Sharding-Sphere核心概念—路由键/分片算法
路由键/分片键:作为数据分片的基准字段[可以是一个/多个字段组成]
分片算法:基于路由键做一定逻辑处理,从而计算出一个最终节点位置的算法
举例:好比按user_id将用户表数据分片,每八百万条数据划分一张表。user_id就是路由键,而按user_id做范围判断则属于分片算法,一张表中的所有数据都会依据这两个基础,后续对所有的读写SQL进行改写,从而定位到具体的库、表位置。
4.Sharding-Sphere分表分库的工作流程
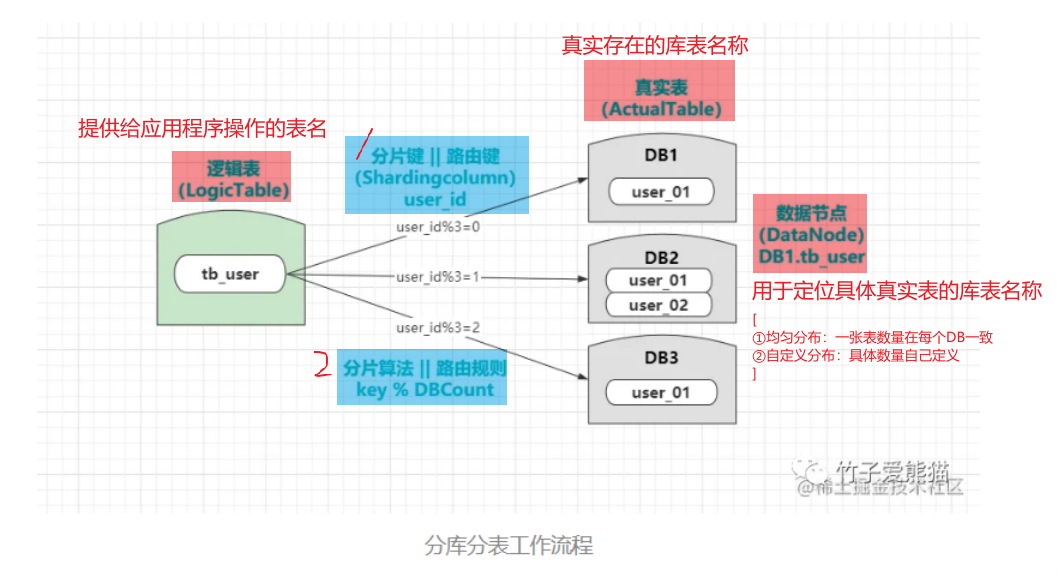
逻辑表:提供给应用程序操作的表名,程序可以像操作原本的单表一样,灵活的操作逻辑表(逻辑表并不是一种真实存在的表结构,而是提供给
Sharding-Sphere使用的)真实表:在各个数据库节点上真实存在的物理表,但表名一般都会和逻辑表存在偏差。
数据节点:主要是用于定位具体真实表的库表名称,如
DB1.tb_user1、DB2.tb_user2.....- 均匀分布:指一张表的数量在每个数据源中都是一致的。
- 自定义分布:指一张表在每个数据源中,具体的数量由自己来定义,上图就是一种自定义分布。
Java为例:
编写业务代码的SQL语句直接基于逻辑表操作;当Sharding-Sphere接收到一条操作某张逻辑表的SQL语句—–已配置好的路由键和分片算法—–>对相应的SQL语句进行解析,然后计算出SQL要落入的数据节点(是哪个真实表),最后再将语句发给具体的真实表上处理即可
JDBC和Proxy的主要区别就在于:解析SQL语句计算数据节点的时机不同
JDBC是在Java程序中就完成相应计算,从Java程序中发出SQL语句就已经是操作真实表的SQLProxy是在Java程序外做解析工作,它会接收程序操作逻辑表的SQL语句。然后再做解析得到具体要操作的真实表,然后再执行,同时Proxy还要作为应用程序和数据库之间,传输数据的中间人
5.Sharding-Sphere概念—表
5.1 绑定表[解决主外键数据落不同库产生跨库查询]
- 现有问题:
多张表之间存在物理或逻辑上的主外键关系,如果无法保障同一主键值的外键数据落入同一节点,显然在查询时就会发生跨库查询,这无疑对性能影响是极大的。

- 解决方案:
比如:前面案例中的order_id、order_info_id可以配置一组绑定表关系,这样就能够让订单详情数据随着订单数据一同落库,简单的说就是:配置绑定表的关系后,外键的表数据会随着主键的表数据落入同一个库中,这样在做主外键关联查询时,就能有效避免跨库查询的情景出现。
5.2 广播表[解决跨库join问题]
- 现有问题:
当有些表需要经常被用来做连表查询时,这种频繁关联查询的表,如果每次都走跨库Join,这显然又会造成一个令人头疼的性能问题。

- 解决方案:
对于一些经常用来做关联查询的表,就可以将其配置为广播表
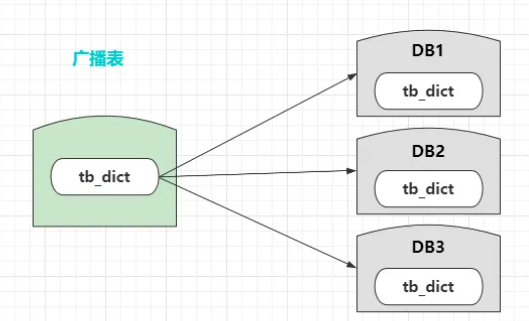
广播表是一种会在所有库中都创建的表,以系统字典表为例,将其配置为广播表之后,向其增、删、改一条或多条数据时,所有的写操作都会发给全部库执行,从而确保每个库中的表数据都一致,后续在需要做连表查询时,只需要关联自身库中的字典表即可,从而避免了跨库Join的问题出现。
5.3 单表[不分表分库]
单表的含义比较简单,并非所有的表都需要做分库分表操作,所以当一张表的数据无需分片到多个数据源中时,就可将其配置为单表,这样所有的读写操作最终都会落入这一张单表中处理。
5.4 动态表
动态表是指表会随着数据增长、或随着时间推移,不断的去创建新表,如下:
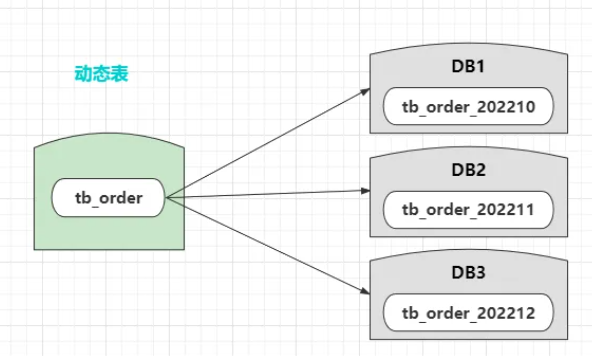
在Sharding-Sphere中可以直接支持配置,无需自己去从头搭建,因此实现起来尤为简单,配置好之后会按照时间或数据量动态创建表。
6.Sharding-Sphere数据分片策略
分库分表之后读写操作具体会落入哪个库中,这是根据路由键和分片算法来决定的
Sharding-Sphere中的数据分片策略又分为:
1.内置的自动化分片算法:[取模分片、哈希分片、范围分片、时间分片等这积累常规算法]
2.用户自定义的分片算法:[标准分片、复合分片、强制分片]
2.1 标准分片算法:适合基于单一路由键进行
=、in、between、>、<、>=、<=...进行查询的场景。2.2 复合分片算法:适用于多个字段组成路由键的场景,但路由算法需要自己继承接口重写实现。
2.3 强制分片算法:适用于一些特殊
SQL的强制执行,在这种模式中可以强制指定处理语句的节点。
综上所述,在Sharding-Sphere内部将这四种分片策略称为:Inline、Standard、Complex、Hint,分别与上述四种策略一一对应,但这四种仅代表四种策略,具体的数据分片算法,可以由使用者自身来定义。
7.Sharding-Sphere分库方式
在Sharding-Sphere生态中,支持传统的主从集群分库,[如搭建出读写分离架构、双主双写架构],同时也支持按业务进行垂直分库,也支持对单个库进行横向拓展,做到水平分库。
但通常都是用它来实现水平分库和读写分离,因为分布式架构的系统默认都有独享库的概念,也就是分布式系统默认就会做垂直分库,因此无需引入
Sharding-Sphere来做垂直分库。
==Sharding-Sphere实际操作==
之前提到过,Sharding-Sphere的所有产品对业务代码都是零侵入的,无论是Sharding-JDBC也好,Sharding-Proxy也罢,都不需要更改业务代码,这也就意味着大家在分库分表环境下做业务开发时,可以像传统的单库开发一样轻松。
Sharding-Sphere中最主要的是对配置文件的更改Sharding-JDBC主要修改application.properties/yml文件Sharding-Proxy主要修改自身的配置文件
1.配置yml文件[业务代码零侵入]
1 | //后期补充 |
==Sharding-Sphere工作原理==
1.核心工作步骤
其核心工作步骤会分为如下几步:
- • 配置加载:在程序启动时,会读取用户的配置好的数据源、数据节点、分片规则等信息。
- •
SQL解析:SQL执行时,会先根据配置的数据源来调用对应的解析器,然后对语句进行拆解。 - •
SQL路由:拆解SQL后会从中得到路由键的值,接着会根据分片算法选择单或多个数据节点。 - •
SQL改写:选择了目标数据节点后,接着会改写、优化用户的逻辑SQL,指向真实的库、表。 - •
SQL执行:对于要在多个数据节点上执行的语句,内部开启多线程执行器异步执行每条SQL。 - • 结果归并:持续收集每条线程执行完成后返回的结果集,最终将所有线程的结果集合并。
- • 结果处理:如果
SQL中使用了order by、max()、count()...等操作,对结果处理后再返回。
整个Sharding-Sphere大致工作步骤如上,这个过程相对来说也比较简单,但具体的实现会比较复杂,针对于不同的数据库,内部都会实现不同的解析器,如MySQL有MySQL的解析器,PgSQL也会有对应的解析器,同时还会做SQL语句做优化。而SQL路由时,除开要考虑最基本的数据分片算法外,还需要考虑绑定表、广播表等配置,来对具体的SQL进行路由。
2.分库分表产品对比
| 对比项 | Sharding-JDBC | Sharding-Proxy | MyCat |
|---|---|---|---|
| 性能开销 | 较低 | 较高 | 高 |
| 异构支持 | 不支持 | 支持 | 支持 |
| 网络次数 | 最少一次 | 最少两次 | 最少两次 |
| 异构语言 | 仅支持Java | 支持异构 | 支持异构 |
| 数据库支持 | 任意数据库 | MySQL、PgSQL | 任意数据库 |
| 配置管理 | 去中心化 | 中心化 | 中心化 |
| 部署方式 | 依赖工程 | 中间件 | 中间件 |
| 业务侵入性 | 较低 | 无 | 无 |
| 连接开销 | 高 | 低 | 低 |
| 事务支持 | XA、Base、Local事务 | 同前者 | XA事务 |
| 功能丰富度 | 多 | 多 | 一般 |
| 社区活跃性 | 活跃 | 活跃 | 一言难尽 |
| 版本迭代性 | 高 | 高 | 极低 |
| 多路由键支持 | 2 | 2 | 1 |
| 集群部署 | 支持 | 支持 | 支持 |
| 分布式序列 | 雪花算法 | 雪花算法 | 自增序列 |


