1.前言
在程序开发与运行过程中,出现Bug问题的几率无可避免,数据库出现问题一般会发生在下述几方面:
①撰写的
SQL语句执行出错,俗称为业务代码Bug。②开发环境执行一切正常,线上偶发
SQL执行缓慢的情况。③线上部署
MySQL的机器故障,如磁盘、内存、CPU100%,MySQL自身故障等。
1.1 线上排查和解决问题思路
相对而言,解决故障问题也好,处理性能瓶颈也罢,通常思路大致都是相同的,步骤如下:
- ①分析问题:根据理论知识+经验分析问题,判断问题可能出现的位置或可能引起问题的原因,将目标缩小到一定范围。
- ②排查问题:基于上一步的结果,从引发问题的“可疑性”角度出发,从高到低依次进行排查,进一步排除一些选项,将目标范围进一步缩小。
- ③定位问题:通过相关的监控数据的辅助,以更“细粒度”的手段,将引发问题的原因定位到精准位置。
- ④解决问题:判断到问题出现的具体位置以及引发的原因后,采取相关措施对问题加以解决。
- ⑤尝试最优解(非必须):将原有的问题解决后,在能力范围内,且环境允许的情况下,应该适当考虑问题的最优解(可以从性能、拓展性、并发等角度出发)。
我的解决方案:
当然,上述过程是针对特殊问题以及经验老道的开发者而言的,作为“新时代的程序构建者”,那当然得学会合理使用工具来帮助我们快速解决问题:
- ①摘取或复制问题的关键片段。
- ②打开百度或谷歌后粘贴搜索。
- ③观察返回结果中,选择标题与描述与自己问题较匹配的资料进入。
- ④多看几个后,根据其解决方案尝试解决问题。
- ⑤成功解决后皆大欢喜,尝试无果后“找人/问群”。
- ⑥“外力”无法解决问题时自己动手,根据之前的步骤依次排查解决。
1.2 线上排查方向
==①发生问题的大体定位,②逐步推导出具体问题的位置==
1.应用程序本身导致的问题
- 程序内部频繁触发GC,造成系统出现长时间停顿,导致客户端堆积大量请求。
- JVM参数配置不合理,导致线上运行失控,如堆内存、各内存区域太小等。【遇到启动项目OOM,在idea创建设置堆空间大小700到10000解决】
- Java程序代码存在缺陷,导致线上运行出现Bug,如死锁/内存泄漏、溢出等。
- 程序内部资源使用不合理,导致出现问题,如线程/DB连接/网络连接/堆外内存等。
2.上下游内部系统导致的问题
- 上游服务出现并发情况,导致当前程序请求量急剧增加,从而引发问题拖垮系统。
- 下游服务出现问题,导致当前程序堆积大量请求拖垮系统,如Redis宕机/DB阻塞等。
3.程序所部署的机器本身导致的问题
- 服务器机房网络出现问题,导致网络出现阻塞、当前程序假死等故障。
- 服务器中因其他程序原因、硬件问题、环境因素(如断电)等原因导致系统不可用。
- 服务器因遭到入侵导致Java程序受到影响,如木马病毒/矿机、劫持脚本等。
4.第三方的RPC远程调用导致的问题
- 作为被调用者提供给第三方调用,第三方流量突增,导致当前程序负载过重出现问题。
- 作为调用者调用第三方,但因第三方出现问题,引发雪崩问题而造成当前程序崩溃。
==——三大类错误排查——==
2.Sql语句执行出错—排查
作为一个程序员,对MySQL数据库而言,接触最多的就是SQL语句的撰写,和写业务代码时一样,写代码时会碰到异常、错误,而写SQL时同样如此,比如:
1 | ERROR 1064 (42000): |
Mysql的错误信息会由三部分组成:
ErrorCode:错误码【1064这种】
SQLState:Sql状态【42000这种】
ErrorInfo:错误详情【在;之后跟一长串描述具体错误详情】
Mysql的错误类型:
- 根据ErrorInfo位置根据错误类型定位,认真对准之后百度搜索
- 没有定位,只能通过SQLState和网上办法解决
3.Mysql线上慢查询语句—排查
有些SQL可能在开发环境没有任何问题,但放到线上时就会出现偶发式执行耗时较长的情况,所以这类情况就只能真正在线上环境才能测出来,尤其是一些不支持灰度发布的中小企业,也只能放到线上测才能发现问题。
3.1 打开Mysql慢查询日志
一般在上线前,Mysql手动打开慢查询日志:
1 | 开启慢查询日志需要配置两个关键参数: |
3.2 查看Mysql慢查询日志
查看慢查询日志的方式:
- 拥有完善的监控系统:【自动】读取磁盘中的慢查询日志,然后可以通过监控系统大屏观察
- 未拥有完善的监控系统:linux系统通过cat类指令查看本地日志文件/windows记事本打开

从上面日志中记录的查询信息来看,可以得知几个信息:
- • 执行慢查询
SQL的用户:root,登录IP为:localhost[127.0.0.1]。 - • 慢查询执行的具体耗时为:
0.014960s,锁等待时间为0s。 - • 本次
SQL执行后的结果集为4行数据,累计扫描6行数据。 - • 本次慢查询发生在
db_zhuzi这个库中,发生时间为1667466932(2022-11-03 17:15:32)。 - • 最后一行为具体的慢查询
SQL语句。
3.3 排查sql执行缓慢问题
通过3.2步骤我们读取慢查询日志后,能够精准定位到发生慢查询Sql的用户、客户端机器、执行耗时、锁阻塞耗时、结果集行数、扫描行数、发生的库和事件、具体的慢查询sql语句。
得到这些信息之后,其实排查引起慢查询的原因就通过以下步骤就可以:
- ①根据本地慢查询日志文件中的记录,得到具体慢查询sql执行的相关信息
- ②查看lock_time的耗时,判断本次执行缓慢是否由于并发事务导致的长时间阻塞【多半原因】
- 2.1 如果是,是由于并发事务导致的长时间阻塞【并发事务抢占锁,造成当前事务长时间无法获取锁资源】,看到大量由于锁阻塞导致执行超过阈值,那就执行查看mysql锁状态,如果值都比较大意味着当前这个mysql节点承担的并发压力过大,急需mysql架构优化
- 2.2 如果不是,通过①explain索引分析工具,先判断索引使用情况,找到那些执行计划中扫描行数过多、
type=index/all的SQL语句,尝试优化掉即可;②人肉排查法解决
一般来说在开发环境中没有问题的SQL语句,放到线上环境出现执行缓慢的情况,多半原因是由于并发事务抢占锁,造成当前事务长时间无法获取锁资源,因此导致当前事务执行的SQL出现超时,这种情况下需要去定位操作相同行数据的大事务,一般长时间的阻塞是由于大事务持有锁导致的,找出对应的大事务并拆解或优化掉即可。【基本就是操作相同行数据的大事务持有锁】
3.3.1 长时间锁阻塞的排查方法[查看lock_time时间]
通过show status like 'innodb_row_lock_%';命令可以查询MySQL整体的锁状态,如下:
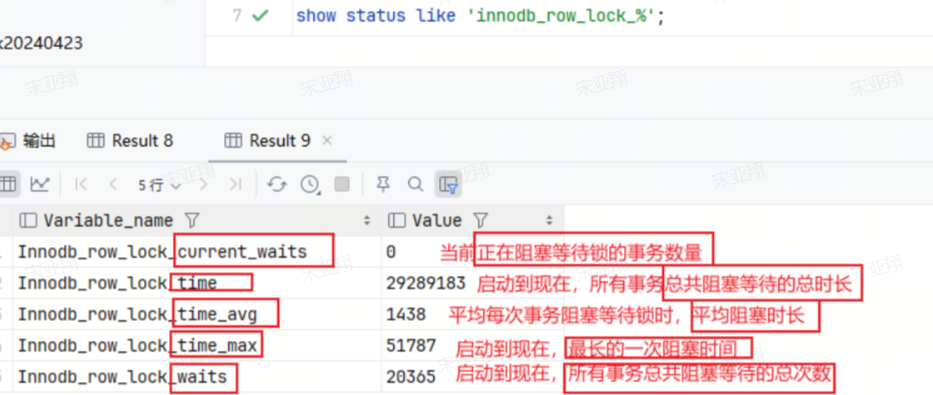
Innodb_row_lock_current_waits:当前正在阻塞等待锁的事务数量。Innodb_row_lock_time:MySQL启动到现在,所有事务总共阻塞等待的总时长。Innodb_row_lock_time_avg:平均每次事务阻塞等待锁时,其平均阻塞时长。Innodb_row_lock_time_max:MySQL启动至今,最长的一次阻塞时间。Innodb_row_lock_waits:MySQL启动到现在,所有事务总共阻塞等待的总次数。
3.3.2 非锁阻塞的排查方法[explain/拆分语句]
- 方法一:explain解释方法:
找到那些执行计划中扫描行数过多、type=index/all的SQL语句,尝试优化掉即可

select_type字段:展示查询的类型(简单查询,联合查询,子查询等)—可以往join连接,避免子查询
partitions字段:展示查询涉及的分区(mysql5.1引出的,解决单表问题)—-可以往分区上优化
type字段:展示链接类型,反映mysql如何查找表的行—可以往system(系统表查询)/const(主键/唯一索引)
possible_keys和key字段:mysql认为可以使用的索引和实际使用的索引—可以往一致优化
filtered字段:mysql认为where符合(返回结果的行数/总行数)的百分比—可以往100%优化[where字段优化]
extra字段:一些额外操作—可以往①Using index索引覆盖;②Using where使用where子句过滤行
- 方法二:人肉排查法:
【对于一些较为复杂或庞大的业务需求,可以采取拆分法去逐步实现,最后组装所有的子语句,最终推导出符合业务需求的SQL语句】
一条复杂的查询语句,拆解成一条条子语句,对每条子语句使用explain工具分析,精准定位到:复杂语句中导致耗时较长的具体子语句,最后将这条子语句优化后重新组装即可。
【拆解排除法有一个最大的好处是:有时组成复杂SQL的每条子语句都不存在问题,也就是每条子语句的执行效率都挺不错的,但是拼到一起之后就会出现执行缓慢的现象,这时拆解后就可以一步步的将每条子语句组装回去,每组装一条子语句都可以用explain工具分析一次,这样也能够精准定位到是由于那条子语句组合之后导致执行缓慢的,然后进行对应优化即可。】
4.Mysql线上机器故障排查
MySQL数据库线上的机器故障主要分为两方面,①是由于MySQL自身引起的问题,比如连接异常、死锁问题等,②是部署MySQL的服务器硬件文件,如磁盘、CPU100%等现象,对于不同的故障问题排查手段也不同,下面将展开聊一聊常见的线上故障及解决方案。
4.1 客户端连接异常
当数据库出现连接异常时,基本上就是因为四种原因导致:
【①②比较简单,设置两者参数就行】
- ①数据库总体的现有连接数,超出了
MySQL中的最大连接数,此时再出现新连接时会出异常。【遇到过,直接更新参数,加大核心线程数即可】 - ②客户端数据库连接池与
MySQL版本不匹配,或超时时间过小,也可能导致出现连接中断。
【③④比较特殊】
- ③
MySQL、Java程序所部署的机器不位于同一个网段,两台机器之间网络存在通信故障。 - ④部署
MySQL的机器资源被耗尽,如CPU、硬盘过高,导致MySQL没有资源分配给新连接。
其中,介绍一下③④情况:
③MySQL、Java程序所部署的机器不位于同一个网段,两台机器之间网络存在通信故障
这种情况,问题一般都出在交换机上面,由于Java程序和数据库两者不在同一个网段,所以相互之间通信需要利用交换机来完成,但默认情况下,交换机和防火墙一般会认为时间超过3~5分钟的连接是不正常的,因此就会中断相应的连接,而有些低版本的数据库连接池,如Druid只会在获取连接时检测连接是否有效,此时就会出现一个问题:
交换机把两个网段之间的长连接嘎了,但是Druid因为只在最开始检测了一次,后续不会继续检测连接是否有效,所以会认为获取连接后是一直有效的,最终就导致了数据库连接出现异常(后续高版本的Druid修复了该问题,可以配置间隔一段时间检测一次连接)
一般如果是由于网络导致出现连接异常,通常排查方向如下:
- • 检测防火墙与安全组的端口是否开放,或与外网机器是否做了端口映射。
- • 检查部署
MySQL的服务器白名单,以及登录的用户IP限制,可能是IP不在白名单范围内。 - • 如果整个系统各节点部署的网段不同,检查各网段之间交换机的连接超时时间是多少。
- • 检查不同网段之间的网络带宽大小,以及具体的带宽使用情况,有时因带宽占满也会出现问题。
- • 如果用了
MyCat、MySQL-Proxy这类代理中间件,记得检查中间件的白名单、超时时间配置。
一般来说上述各方面都不存在问题,基本上连接异常应该不是由于网络导致的问题,要做更为细致的排查,可以在请求链路的各节点上,使用网络抓包工具,抓取对应的网络包,看看网络包是否能够抵达每个节点,如果每个节点的出入站都正常,此时就可以排除掉网络方面的原因。
④部署MySQL的机器资源被耗尽,如CPU、硬盘过高,导致MySQL没有资源分配给新连接。
这种情况更为特殊,网络正常、连接数未满、连接未超时、数据库和客户端连接池配置正常….,在一切正常的情况下,有时候照样出现连接不上MySQL的情况咋整呢?在这种情况下基本上会陷入僵局,这时你可以去查一下部署MySQL服务的机器,其硬件的使用情况,如CPU、内存、磁盘等,如果其中一项达到了100%,这时就能够确定问题了!
1 | 因为数据库连接的本质,在MySQL内部是一条条的工作线程,要牢记的一点是:操作系统在创建一条线程时,都需要为其分配相关的资源,如果一个客户端尝试与数据库建立新的连接时,此刻正好有一个数据库连接在执行某个操作,导致CPU被打满,这时就会由于没有资源来创建新的线程,因此会向客户端直接返回连接异常的信息。 |
先找到导致资源耗尽的连接/线程,然后找到它当时正在执行的SQL语句,最后需要优化相应的SQL语句后才能彻底根治问题。
4.2 Mysql死锁频发[查看innodb存储引擎运行状态日志]
MySQL内部其实会【默认】开启死锁检测算法,当运行期间出现死锁问题时,会主动介入并解除死锁,但要记住:虽然数据库能够主动介入解除死锁问题,但这种方法治标不治本因为死锁现象是由于业务不合理造成的,能出现一次死锁问题,自然后续也可能会多次出现,因此优化业务才是最好的选择,这样才能根治死锁问题。
从业务上解决死锁问题:①先定准定位到产生死锁的SQL语句,根据查看innodb存储引擎的运行状态日志【找到内部latest detected deadlock区域日志】
例如: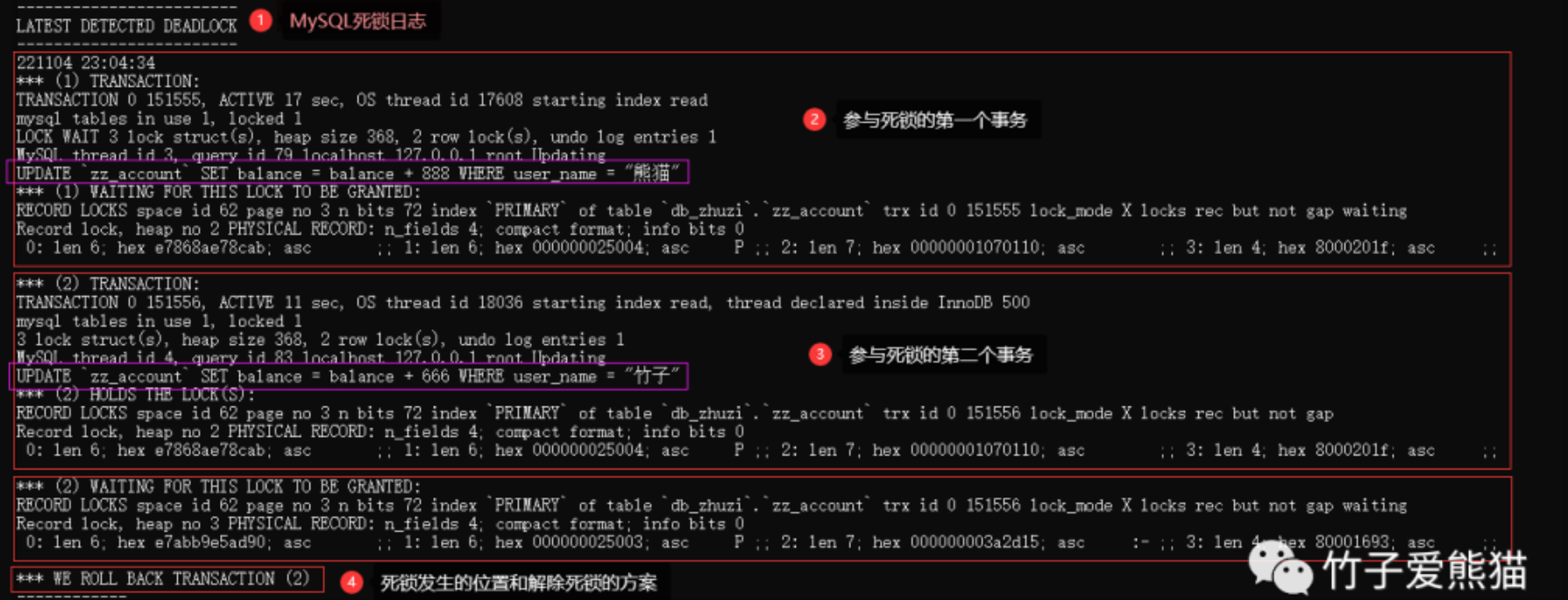
在上面的日志中,基本上已经写的很清楚了,在2022-11-04 23:04:34这个时间点上,检测到了一个死锁出现,该死锁主要由两个事务产生,SQL如下:
- •
(1):UPDATEzz_accountSET balance = balance + 888 WHERE user_name = "熊猫"; - •
(2):UPDATEzz_accountSET balance = balance + 666 WHERE user_name = "竹子";
在事务信息除开列出了导致死锁的SQL语句外,还给出了两个事务对应的线程ID、登录的用户和IP、事务的存活时间与系统线程ID、持有的锁信息与等待的锁信息….
除开两个发生死锁的事务信息外,倒数第二段落还给出了两个事务在哪个锁上产生了冲突,以上述日志为例,发生死锁冲突的地点位于db_zhuzi库中zz_account表的主键上,两个事务都在尝试获取对方持有的X排他锁,后面还给出了具体的页位置、内存地址….。
最后一条信息中,给出了MySQL介入解除死锁的方案,也就是回滚了事务(2)的操作,强制结束了事务(2)并释放了其持有的锁资源,从而能够让事务(1)继续运行。
经过查看上述日志后,其实MySQL已经为我们记录了产生死锁的事务、线程、SQL、时间、地点等各类信息,因此想要彻底解决死锁问题的方案也很简单了,根据日志中给出的信息,去找到执行相应SQL的业务和库表,优化SQL语句的执行顺序,或SQL的执行逻辑,从而避免死锁产生即可。
最后要注意:如果是一些偶发类的死锁问题,也就是很少出现的死锁现象,其实不解决也行,毕竟只有在一些特殊场景下才有可能触发,重点是要关注死锁日志中那些频繁出现的死锁问题,也就是多次死锁时,每次死锁出现的库、表、字段都相同,这种情况时需要额外重视并着手解决。
4.3 服务器CPU100%[两种思路]
可能出现两种情况:
①业务活动:突然大量流量进来活动后cpu占用率就会下降
②cpu长期占用率过高:程序有那种循环次数超级多,甚至出现死循环
排查思路:
①先找到
CPU过高的服务器。②然后在其中定位到具体的进程。【top指令】
③再定位到进程中具体的线程。【top -Hp xxxx】 xxxx就是②查出来的PID进程号
④再查看线程正在执行的代码逻辑–会显示线程是属于Java/Mysql
- 4.1 Java层面:该线程的
PID转换为16进制,然后进一步排查日志grep 查询接口信息 - 4.2 Mysql层面:mysql5.7以下查找innodb运行状态日志的某个部分/mysql5.7以上通过threads表信息查找】
- 4.1 Java层面:该线程的
⑤最后从代码层面着手优化掉即可。
②先使用top指令查看系统后台的进程状态:
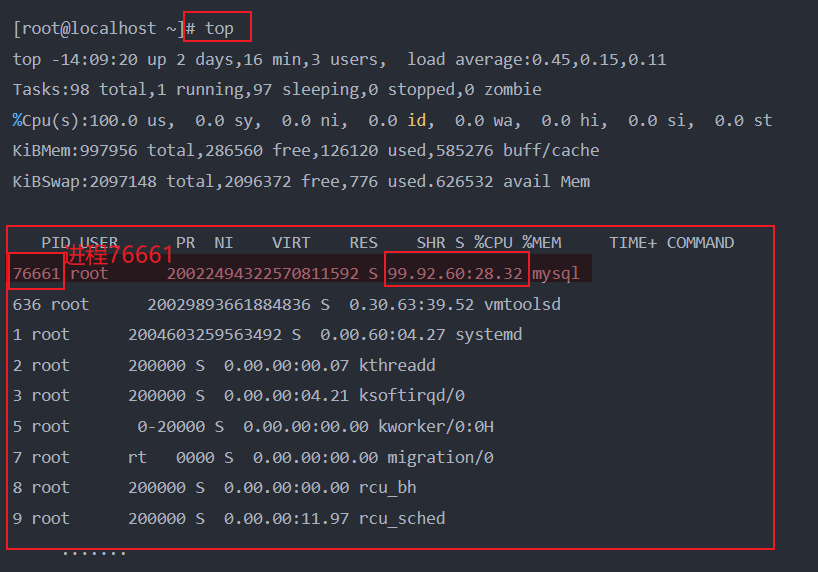
从如上结果中不难发现,PID为76661的MySQL进程对CPU的占用率达到99.9%,此时就可以确定,机器的CPU利用率飙升是由于该进程引起的。
③根据top -Hp [PID]指令查看进程中cpu占用率最高的线程:
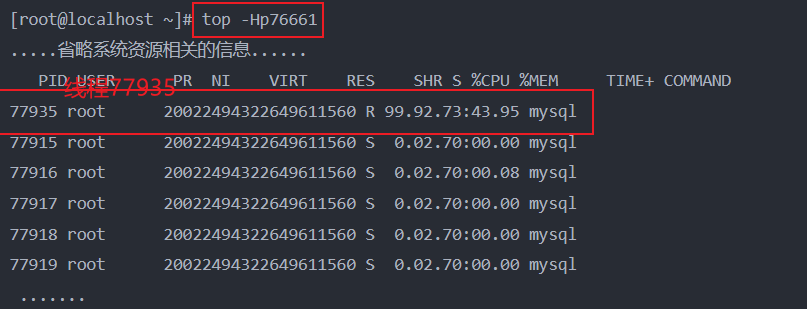
从top -Hp 76661命令的执行结果中可以看出:其他线程均为休眠状态,并未持有CPU资源,而PID为77935的线程对CPU资源的占用率却高达99.9%!
到此时,导致CPU利用率飙升的“罪魁祸首”已经浮现水面,但此时问题来了!在如果这里是Java程序,此时可以先将该线程的PID转换为16进制的值,然后进一步排查日志信息来确定具体线程执行的业务方法。但此时这里是MySQL程序,咱们得到了操作系统层面的线程ID后,如何根据这个ID在MySQL中找到对应的线程呢?
④分为Mysql5.7以上和Mysql5.7以下两种情况:
- 在
MySQL5.7及以上的版本中,MySQL会自带一个名为performance_schema的库,在其中有一张名为threads的表,其中表中有一个thread_os_id字段,其中会保存每个连接/工作线程与操作系统线程之间的关系(在5.7以下的版本是隐式的,存在于MySQL内部无法查看)。
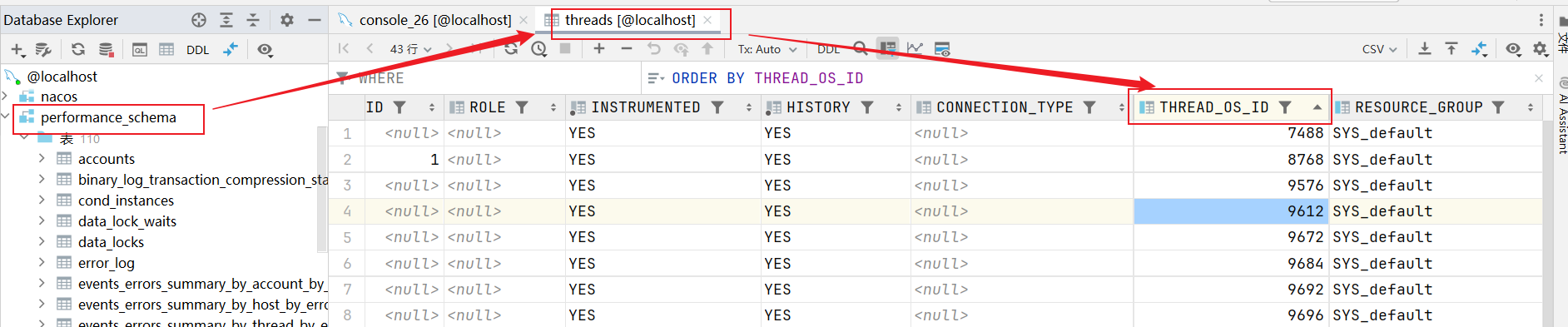
可以通过查询threads表,输出所有已经创建的线程:【select查询–对应processlist_info就是对应的sql语句】
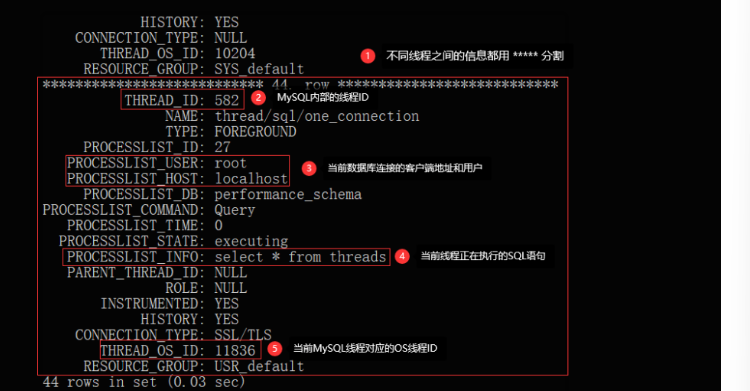
从上述中可以明显看出MySQL线程和OS线程之间的关系,当通过前面的top指令拿到CPU利用率最高的线程ID后,在再这里找到与之对应的MySQL线程,同时也能够看到此线程正在执行的SQL语句,最后优化对应SQL语句的逻辑即可。
- 在
MySQL5.7以下的版本中,我们只能通过Innodb存储引擎状态表的transactions板块查看,
统计着所有存活事务的信息,此时也可以从中得到相应的OS线程、MySQL线程的映射关系
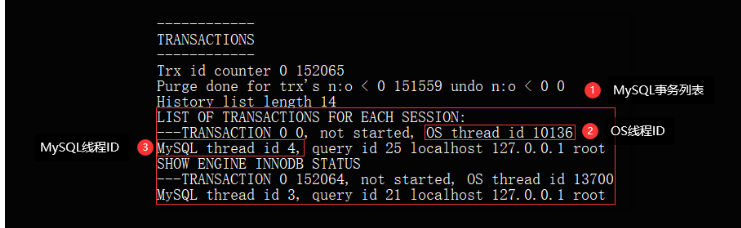
是这种方式仅能够获取到OS线程、MySQL线程之间的映射关系,无法获取到对应线程/连接正在执行的SQL语句,此时如果线程还在运行,则可以通过show processlist;查询,如下:

但这种方式只能看到正在执行的SQL语句,无法查询到最近执行过的语句,所以这种方式仅适用于:==线上SQL还在继续跑的情况==。
4.4 Mysql刷盘100%
指磁盘IO达到100%利用率,这种情况下一般会导致其他读写操作都被阻塞,因为操作系统中的IO总线会被占满,无法让给其他线程来读写数据,先来总结一下出现磁盘IO占用过高的原因:
- • ①突然大批量变更库中数据,需要执行大量写入操作,如主从数据同步时就会出现这个问题。
- • ②
MySQL处理的整体并发过高,磁盘I/O频率跟不上,比如是机械硬盘材质,读写速率过慢。 - • ③内存中的
BufferPool缓冲池过小,大量读写操作需要落入磁盘处理,导致磁盘利用率过高。 - • ④频繁创建和销毁临时表,导致内存无法存储临时表数据,因而转到磁盘存储,导致磁盘飙升。
- • ⑤执行某些
SQL时从磁盘加载海量数据,如超12张表的联查,并每张表数据较大,最终导致IO打满。 - • ⑥日志刷盘频率过高,其实这条是①、②的附带情况,毕竟日志的刷盘频率,跟整体并发直接挂钩。
一般情况下,磁盘IO利用率居高不下,甚至超过100%,基本上是由于上述几个原因造成的,当需要排查磁盘IO占用率过高的问题时,可以先通过iotop工具找到磁盘IO开销最大的线程,然后利用pstack工具查看其堆栈信息,从堆栈信息来判断具体是啥原因导致的,如果是并发过高,则需要优化整体架构。如果是执行SQL加载数据过大,需要优化SQL语句……
磁盘利用率过高的问题其实也比较好解决,方案如下:
- • ①如果磁盘不是
SSD材质,请先将磁盘升级成固态硬盘,MySQL对SSD硬盘做了特殊优化。 - • ②在项目中记得引入
Redis降低读压力,引入MQ对写操作做流量削峰。 - • ③调大内存中
BufferPool缓冲池的大小,最好设置成机器内存的70~75%左右。 - • ④撰写
SQL语句时尽量减少多张大表联查,不要频繁的使用和销毁临时表。
基本上把上述工作都做好后,线上也不会出现磁盘IO占用过高的问题,对于前面说到的:利用iotop、pstack工具排查的过程,就不再做实际演示了,其过程与前面排查CPU占用率过高的步骤类似,大家学习iotop、pstack两个工具的用法后,其实实操起来也十分简单。


