==1.分布式事务产生原因==
首先我们看看项目中的下单业务整体流程:
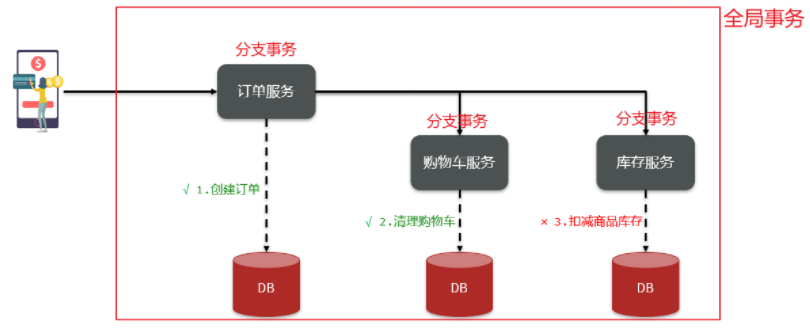
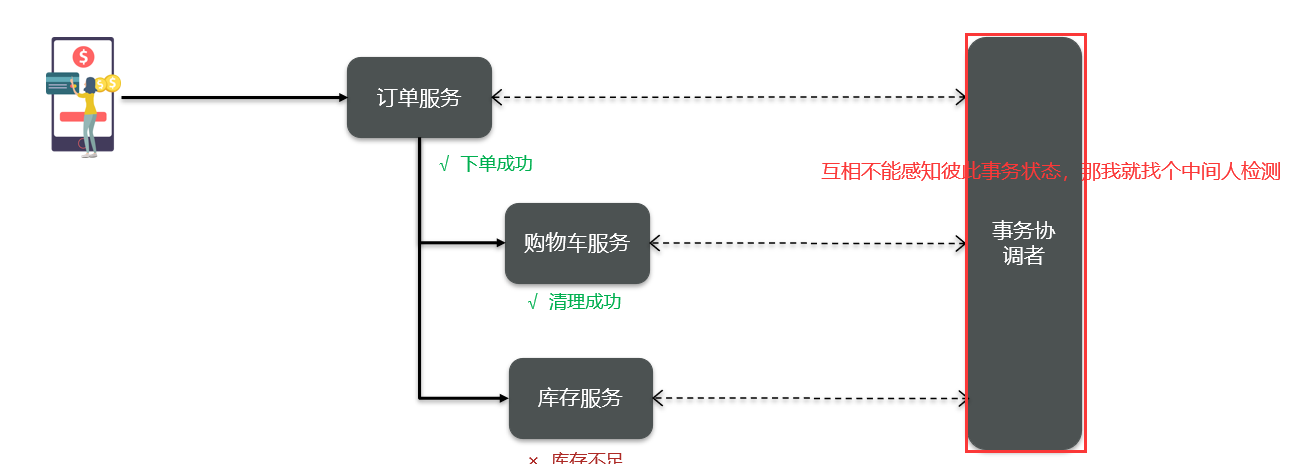
由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
- 交易服务:下单事务
- 购物车服务:清理购物车事务
- 库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
我们知道每一个分支事务就是传统的单体事务,都可以满足ACID特性,但全局事务跨越多个服务、多个数据库,不能满足!!!!!!!!!!!!
- 产生原因:
事务并未遵循ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
这就是分布式事务问题,出现以下情况之一就可能产生分布式事务问题:
- 业务跨多个服务实现
- 业务跨多个数据源实现
==2.CAP定理==
1998年,加州大学的计算机科学家Eric Brewer提出,分布式系统要有三个指标:
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
Availability(可用性):用户访问分布式系统时,读/写操作总能成功
Partition tolerance(分区容错性):即使系统出现网络分区,整个系统也要持续对外提供服务
他认为任何分布式系统架构方案都不能同时满足这三个目标,这个结论就是CAP定理。
2.1 一致性
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
2.2 可用性
Availability (可用性):用户访问分布式系统时,读或写操作总能成功。
只能读不能写,或者只能写不能读,或者两者都不能执行,就说明系统弱可用或不可用。
2.3 分区容错性
Partition tolerance(分区容错性):即使系统出现网络分区partition,整个系统也要持续对外提供服务tolerance。
其中partition(分区):当分布式系统节点之间出现网络故障导致节点之间无法通信的情况。
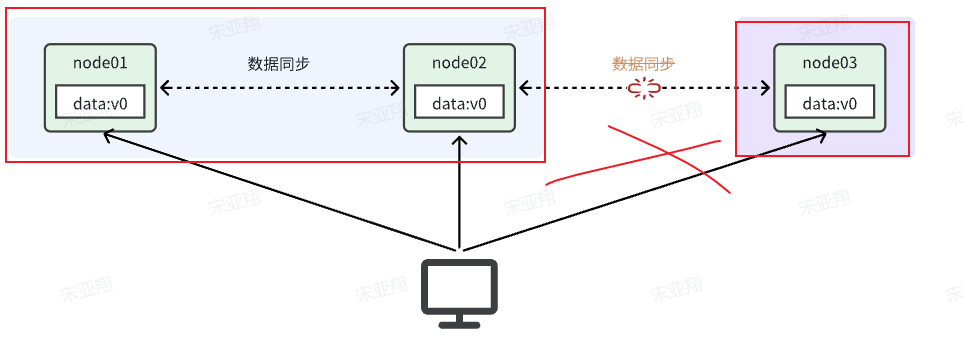
如上图,node01和node02之间网关畅通,但是与node03之间网络断开。于是node03成为一个独立的网络分区;node01和node02在一个网络分区。
其中tolerance(分区容错):当系统出现网络分区,整个系统也要持续对外提供服务。
2.4 三者矛盾(P一定有)
在分布式系统中,网络不能100%保证畅通(partition网络分区的情况一定会存在)。而我们的系统必须要持续运行,对外提供服务。所以分区容错性(P)是硬性指标,所有的分布式系统都要满足。
而设计分布式系统的时候要取舍的就是一致性(C)和可用性(A)。
【P一定有,C和A不一定有】
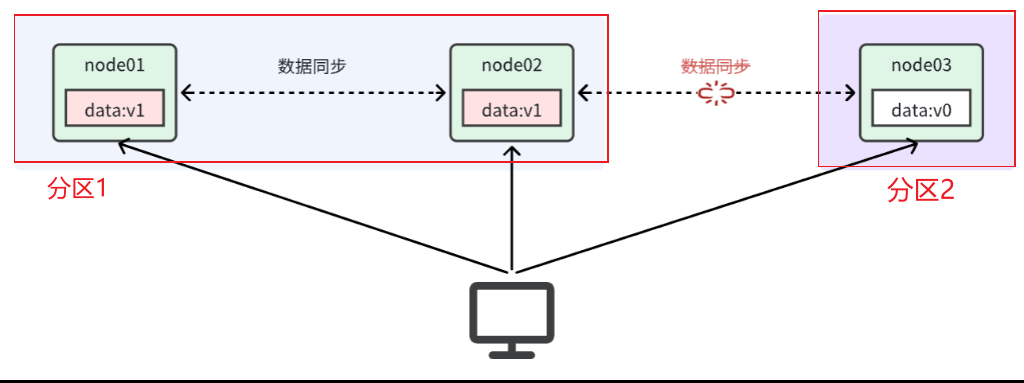
如果允许可用性(A):这样用户可以任意读写,但是由于node03不能同步数据,那就会出现数据不一致情况【只满足AP】
如果允许一致性(C):如果用户不允许随意读写(不允许写,允许读)一直到网络恢复,分区消失,只能满足数据一致性【只满足CP】
2.5 解决三者矛盾(BASE理论)
因为P一定有,C和A不一定有:所以要考虑到底是牺牲一致性还是可用性?—>BASE理论
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,【保证核心可用性】
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
总而言之,BASE理论其实就是一种取舍方案,不再追求完美,而是追求完成目标。
- AP思想:【AT模式】各个子事务分别执行和提交,无需锁定数据。允许出现结果不一致,然后采用弥补措施恢复,实现最终一致。
- CP思想:【XA模式】各个子事务执行后不要提交,而是等待彼此结果,然后同时提交或回滚。在这个过程中锁定资源,不允许其它人访问,数据处于不可用状态,但能保证一致性。
—————————————
==解决方案(中间人-事务协调者)==
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。
1.Seata
官方地址:Seata
分布式事务产生的一个重要原因:参与事务的多个分支事务互相无感知, 不知道彼此的执行状态。
解决方案:就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
1.1 Seata架构
Seata也不例外,在Seata的事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
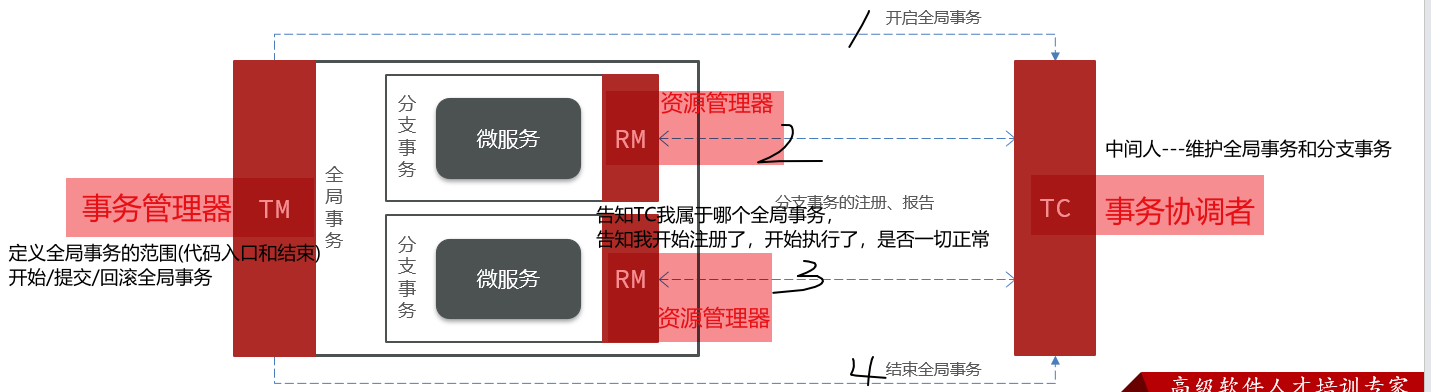
现来方式:直接执行全局事务,然后中途调用各个分支事务,执行结束就完成【各个分支不知道彼此是否正确】
现在方式:直接执行全局事务(事务管理器TM管理开始和结束),然后中途调用各个分支事务(各个RM告知TC这个全局事务有我,我开始了,我结束了),执行结束就完成【中途有什么问题TC都知道,随时可能回滚】
1.2 代码实现思路(两个方面)
①TM和RM【Seata的客户端部分】,引入到参与事务的微服务依赖中即可。(将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。)
②TC【事务协调中心】,是一个独立的微服务,需要单独部署。
—————————————
==Seata具体操作(分两个部分)==
1.TC部署
1.1 准备数据库表
其中seata-tc.sql内容如下:
1 | CREATE DATABASE IF NOT EXISTS `seata`; |
1.2 准备配置文件
- 准备seata目录(包含application.yml配置文件),到时候docker容器可以挂载
其中application.yml信息:
1 | server: |
1.3 Docker部署
- 1.导入镜像文件和配置文件
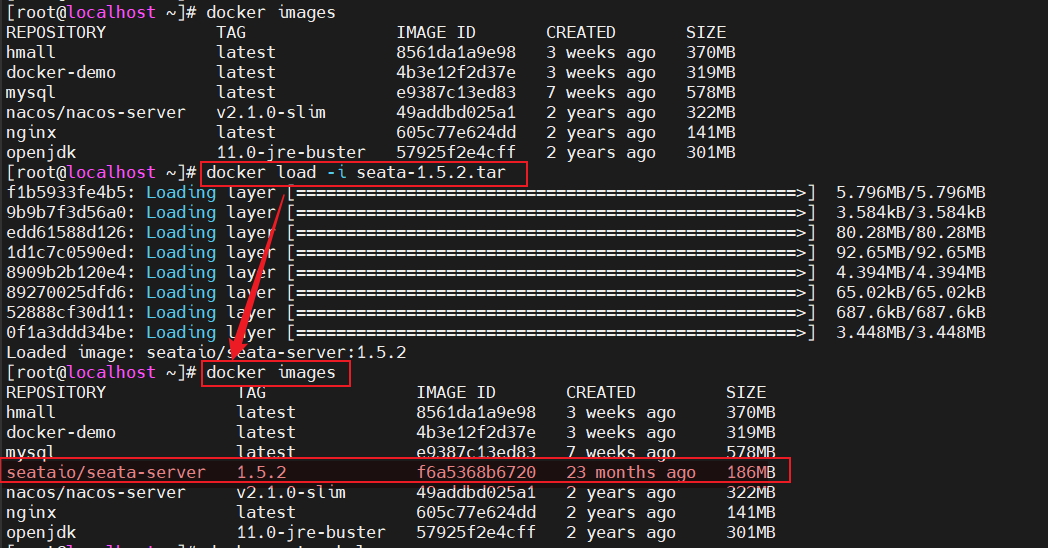
- 2.加载镜像文件
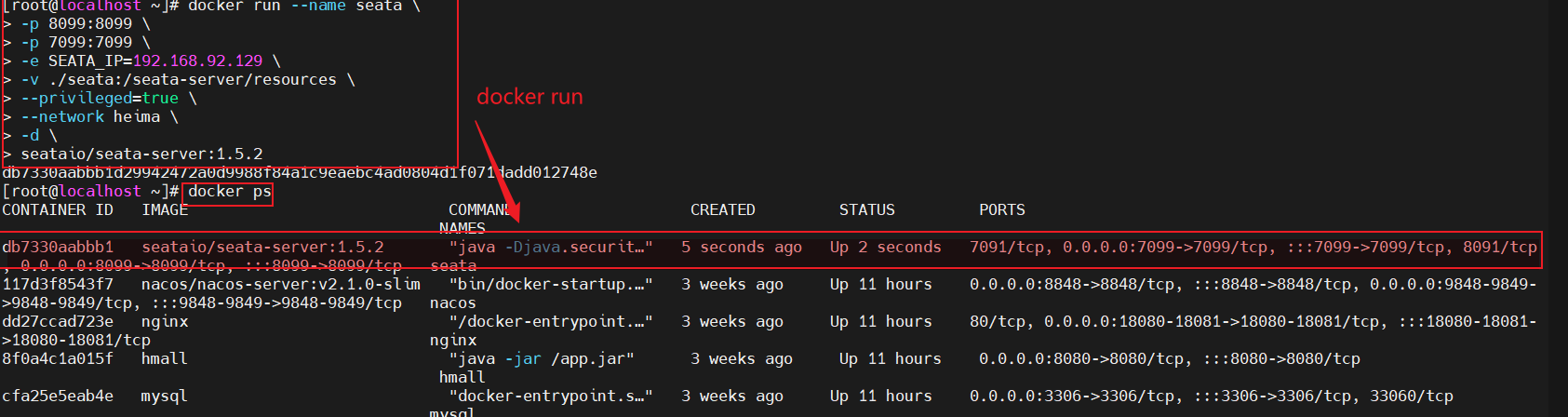
- 3.运行docker容器
1 | docker run --name seata \ |
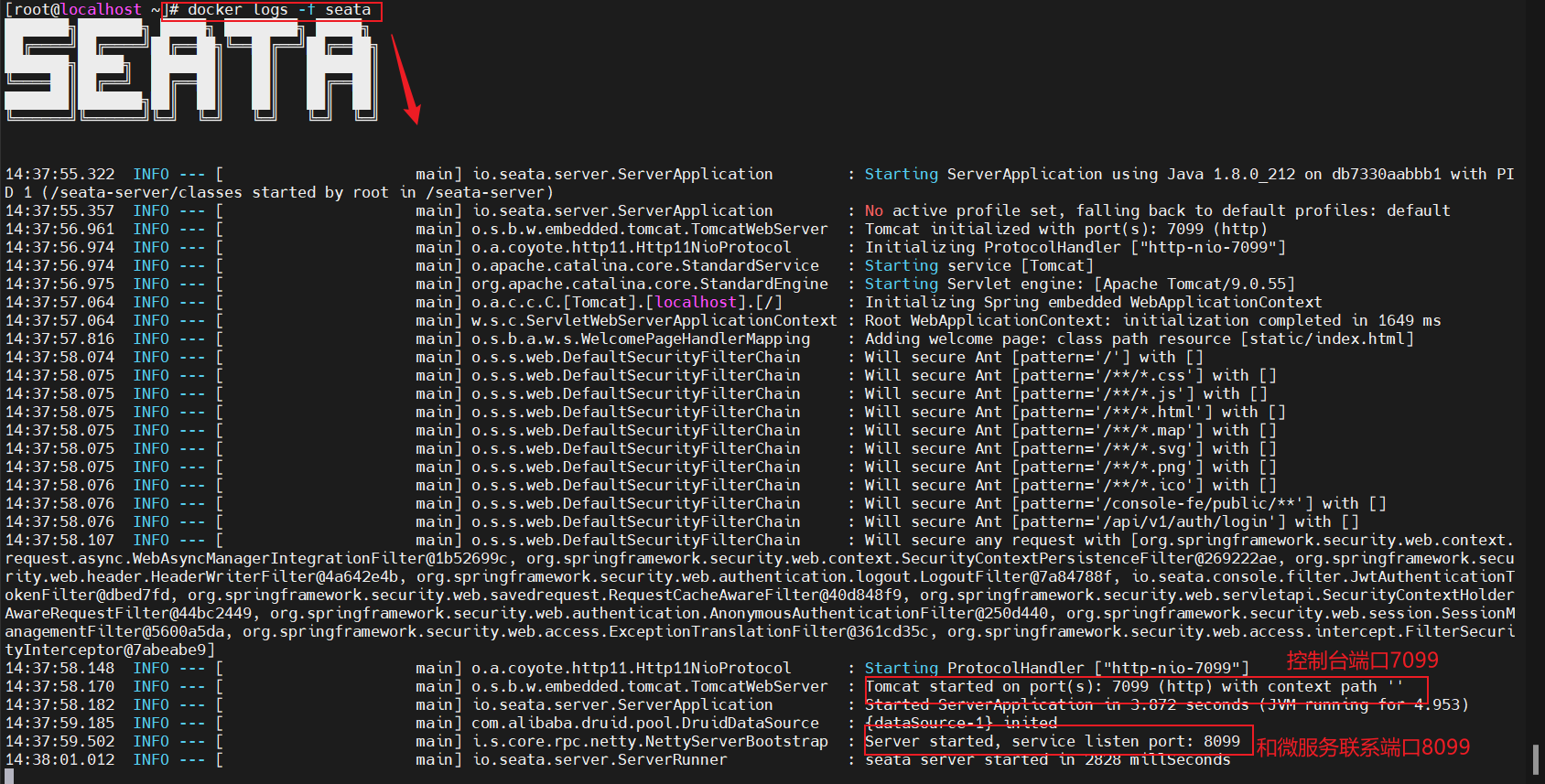
- 4.查看容器运行情况:docker logs -f seata
- 5.在浏览器输入IP:7099即可打开控制台
2.微服务集成Seata
2.1 引入依赖
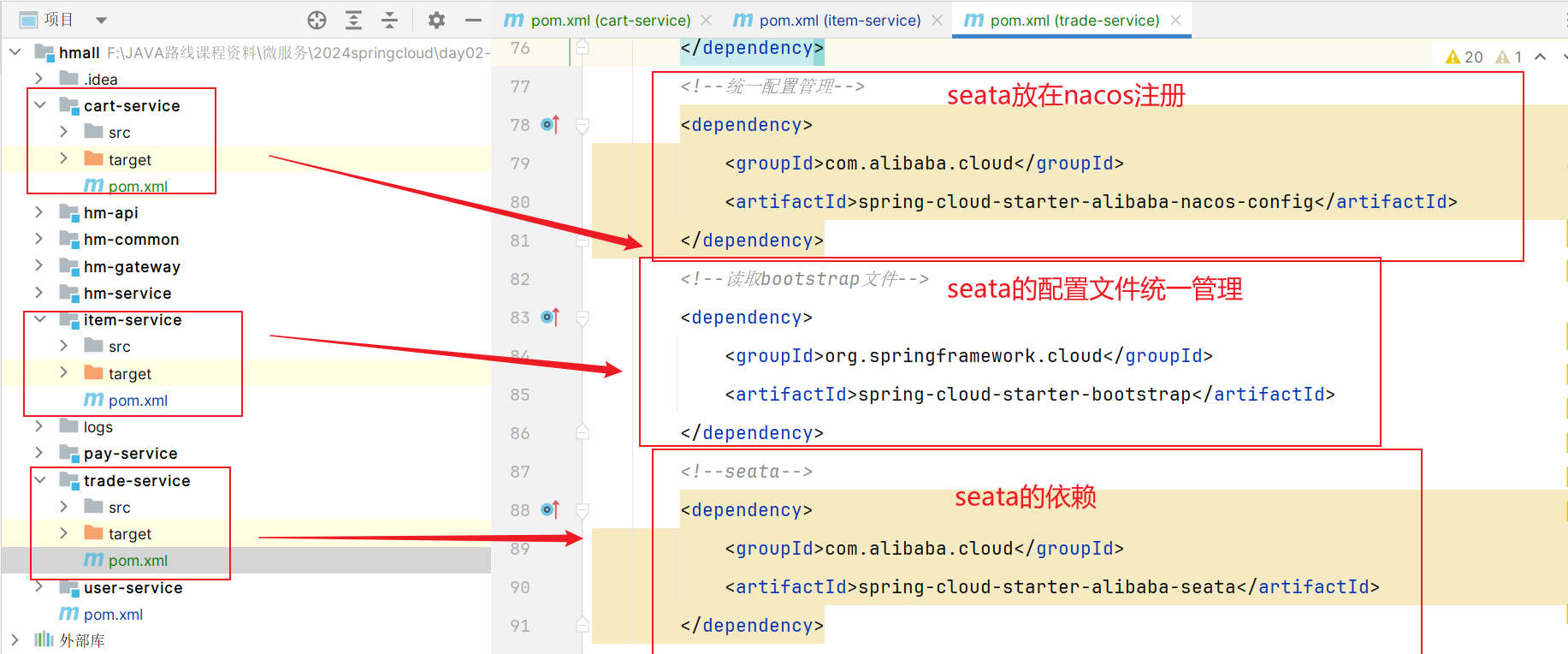
【所有分支事务都需要引入】为了方便各个微服务集成seata,我们需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖:
1 | <!--统一配置管理,读取nacos共享配置文件--> |
2.2 添加配置(统一配置到nacos)
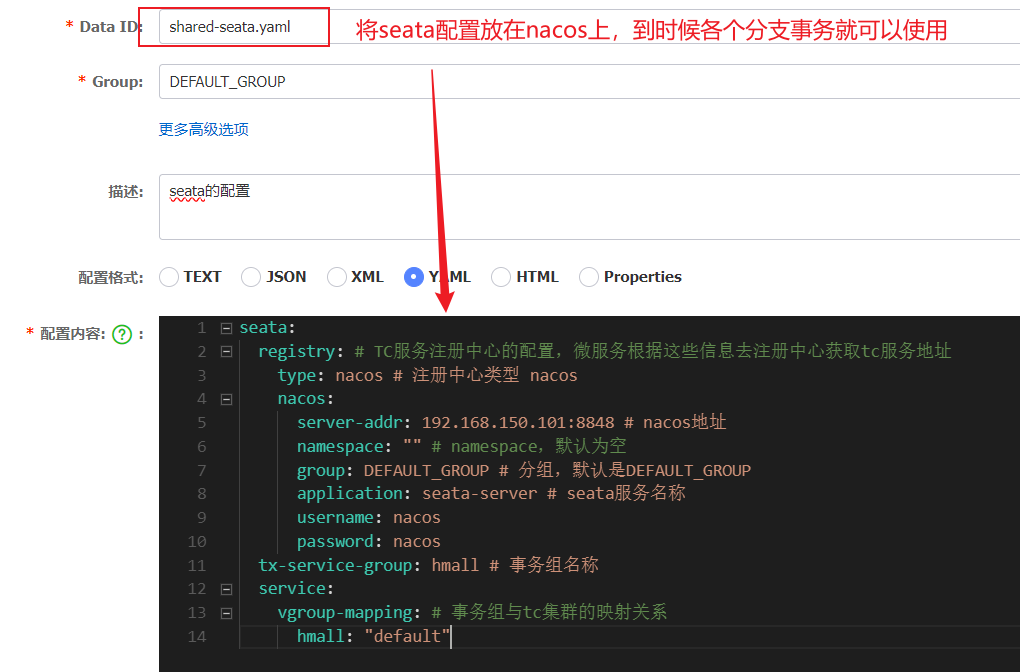
【一般直接配置到apolication.yml文件】因为多个分支事务都需要,那我就可以将seata的配置放在nacos统一配置,剩下的就是改造application.yml和bootstrap.yml文件信息。
2.2.1 配置公共配置
server-addr一定要配置自己的ip:【不然容易注册不到nacos上去!!!】
让微服务能找到TC的位置:
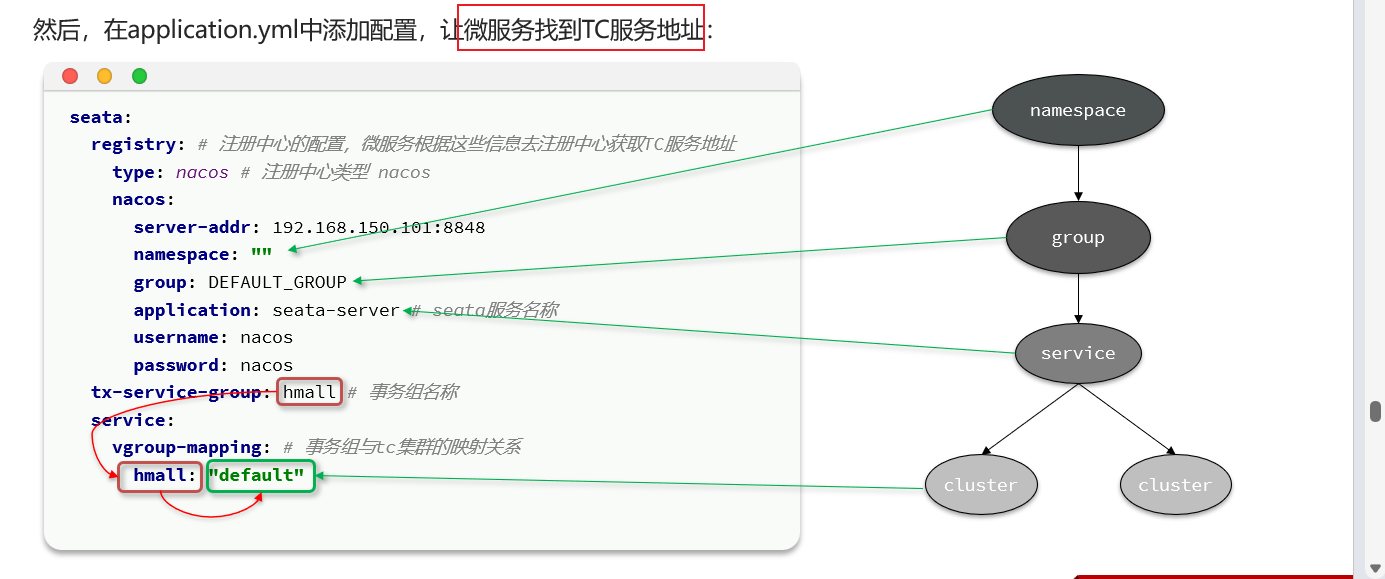
这样配置之后,各个分支事务都去配置这个TC信息:
2.2.2 分支事务新建bootstrap.yml文件
这样配置之后,各个分支事务都去配置这个TC信息:

2.2.3 分支事务调整application.yml文件

2.3 添加数据库保存快照
seata的客户端(TM和RM)在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此我们要先准备一个这样的表。
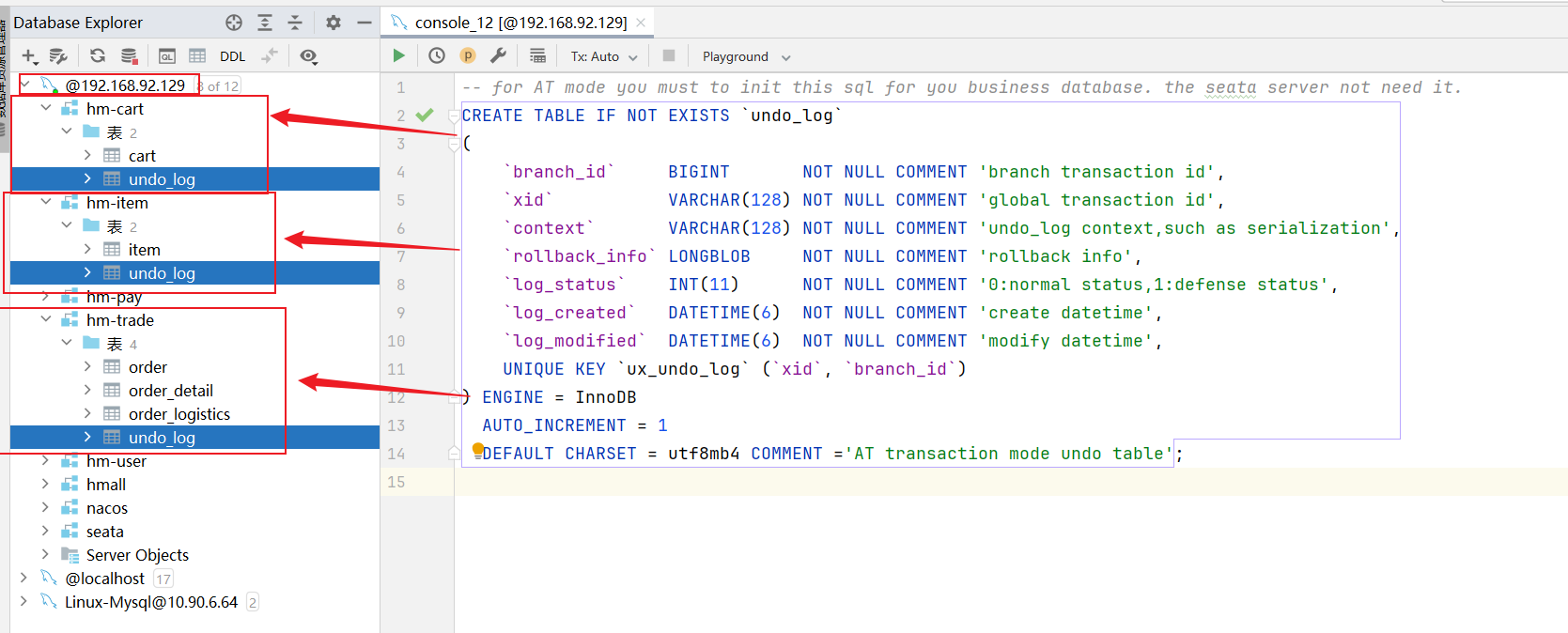
对三个分支事务hm-trade、hm-cart、hm-item三个数据库加入一个undo_log日志表:
1 | -- for AT mode you must to init this sql for you business database. the seata server not need it. |
添加完成之后:
2.4 修改具体业务
我们重新启动项目之后,可以查看seata日志:
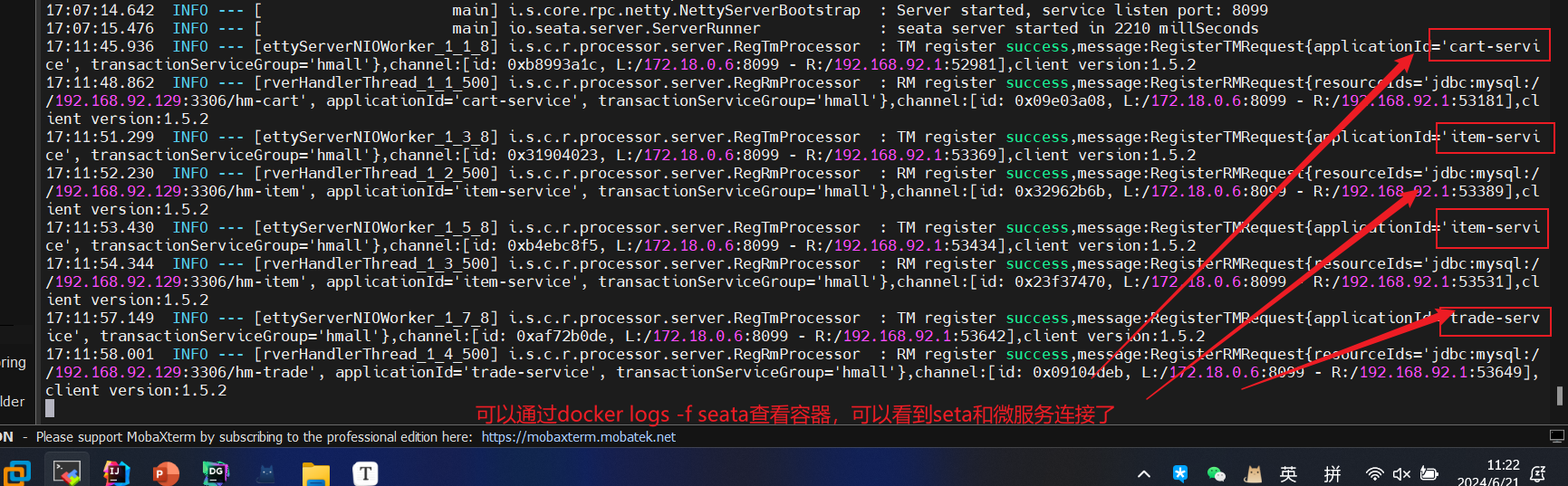
然后针对出问题的方法进行修改【修改为GlobalTransactional注解】:

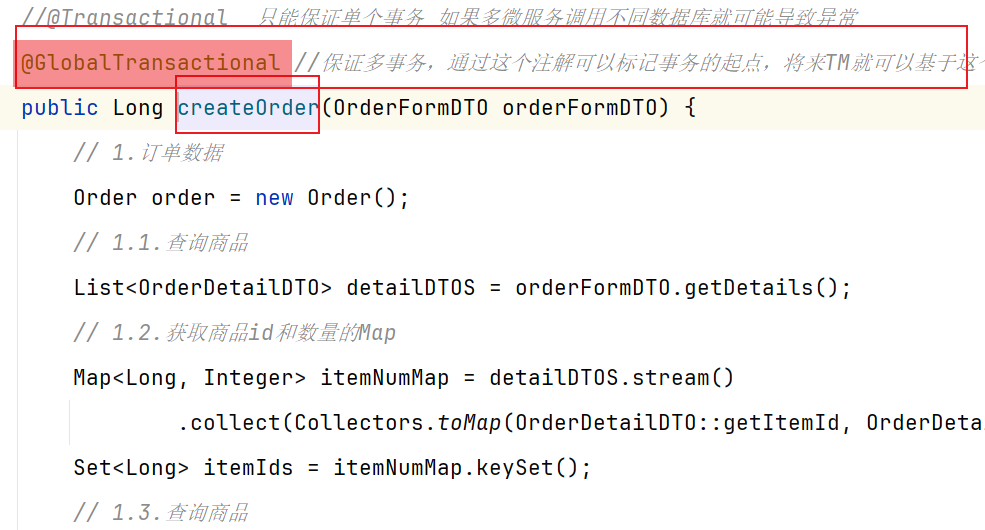
@GlobalTransactional注解就是在标记事务的起点,将来TM就会基于这个方法判断全局事务范围,初始化全局事务。如果中途有分支事务出现问题,我们就可以告知TC进行回滚操作,保证全局事务要么成功/要么失败。
3.实现步骤
- 1.准备TC所需要的数据库,准备配置文件和镜像文件 —【可以直接去服务器利用docker配置TC】
- 2.微服务继承Seata
- 2.1 引入seata依赖
- 2.2 在yml配置seata信息 【因为涉及多个分支事务,所以一般配置到nacos】
- 2.3 原有出现问题的方法替换@Tradtional注解为@GlobalTransactional注解解决分布式事务
==Seate四种底层原理-[四种]==
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC(Try-Confirm-Cancel)
- AT(Automatic Transaction)
- SAGA
代码使用思路
【使用过程中,只是yml配置多一个属性】
其实就是Seata实现步骤:
①导入依赖
②yml配置(基础配置+模式配置属性) —-多了一个配置data-source-proxy-mode
③全局事务位置加注解@GlobalTransactional,分支事务加@Transactional
1.XA模式[统一控制,统一提交]
==①各事务执行完都锁住②统一判断是全部提交/全部撤回==
XA 规范 是X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范提供了支持。
1.1 基本概念
主要分为==两个阶段==提交:
一阶段的工作:【TM通知各个RM执行本地事务,RM向TC注册和报告完成情况,但是不提交保持数据库锁】
①RM注册分支事务到TC【告知我是哪个TM的,我完成什么任务】
②RM执行分支业务sql但不提交【完成任务了】tryPayOrderByBalance
③RM报告执行状态到TC【告诉你我完成了】
二阶段的工作:【TC基于一阶段RM提交事务状态来判断下一步操作是回滚还是提交】
①TC检测各分支事务执行状态【看看各个RM完成如何】
a.如果都成功,通知所有RM提交事务【ok,提交吧】
b.如果有失败,通知所有RM回滚事务【no,回滚吧】
②RM接收TC指令,提交或回滚事务【TC告诉我其他人好了/有问题,就提交/回滚】
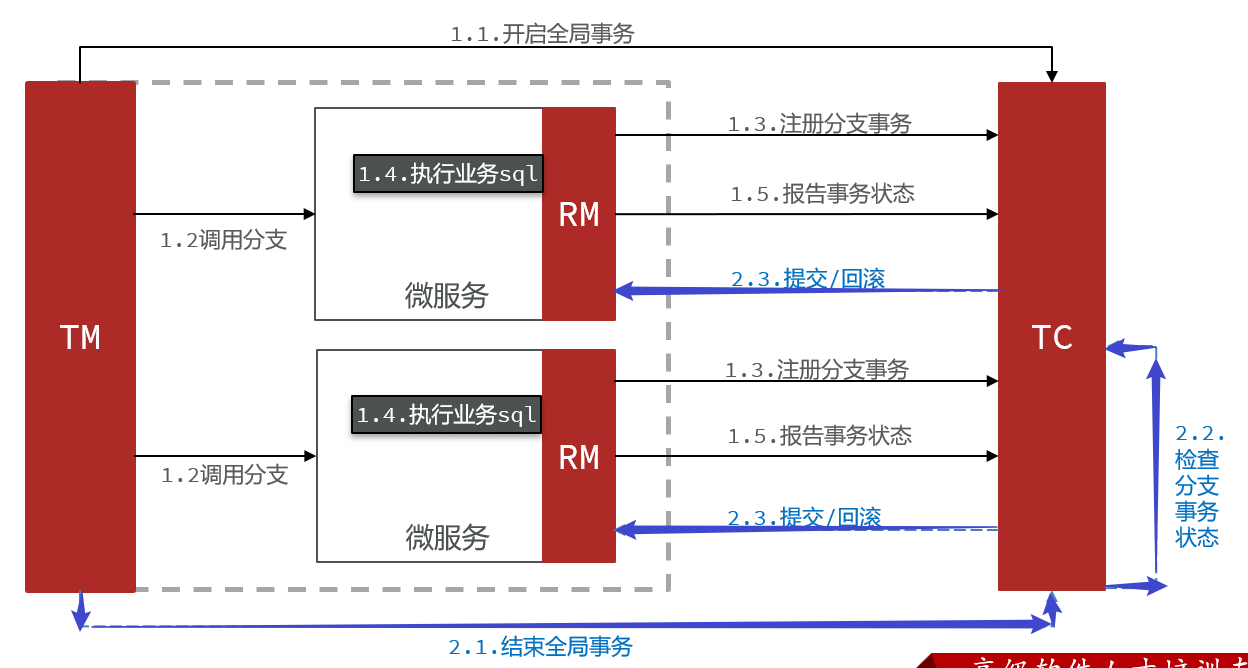
1.1 我们启动服务通过注解@GlobalTranscational开启全局事务
1.2 我们操作的时候调用多个分支事务
1.3 分支事务先向TC进行注册,告知TC我的哪个TM负责的,我要完成什么【告知之后可以进行业务逻辑】
1.4 开始执行业务,进行sql语句的完成【但是不提交!!!!】
1.5 执行业务sql完成之后报告TC我已经完成我自己的任务了,报告事务状态【TC就知道分支业务完成状态(有的完成了,有的失败了)】
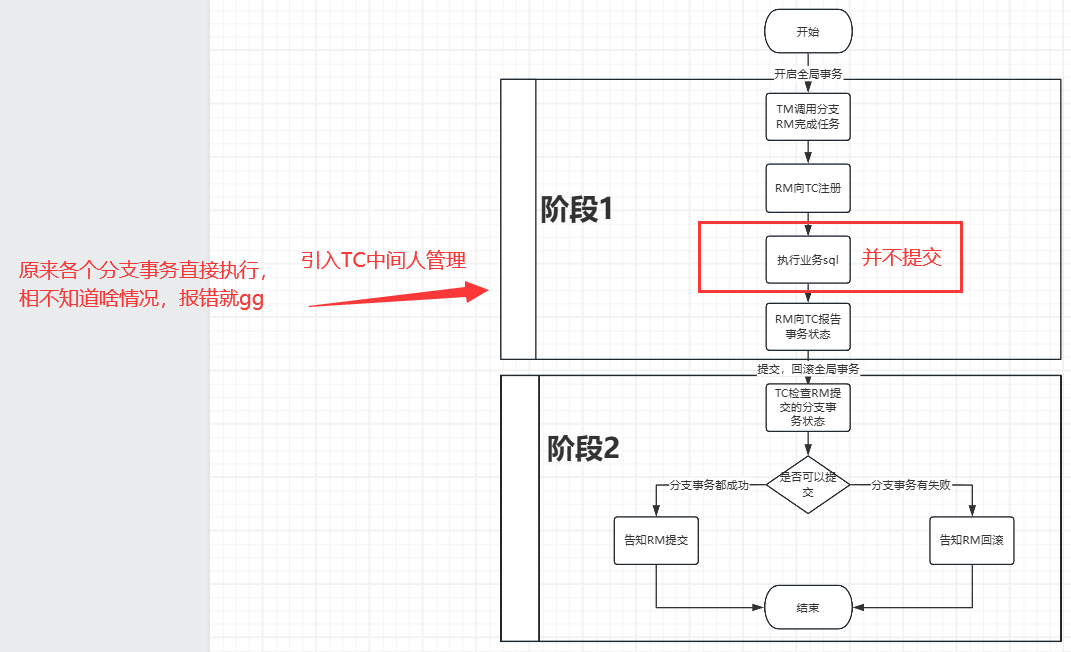
因为第一阶段结束我们可以进行结束全局事务,后续看看是回滚还是提交
2.1 结束全局事务
2.2 TM告知TC检查一下第一阶段各分支事务执行状态,看是不是所有都完成
2.3 因为要全局事务要么提交/要么回滚,如果都成功,通知所有RM提交事务,如果有失败,通知所有RM回滚事务
流程图如下:
1.2 具体实现操作
1.2.1 yml配置
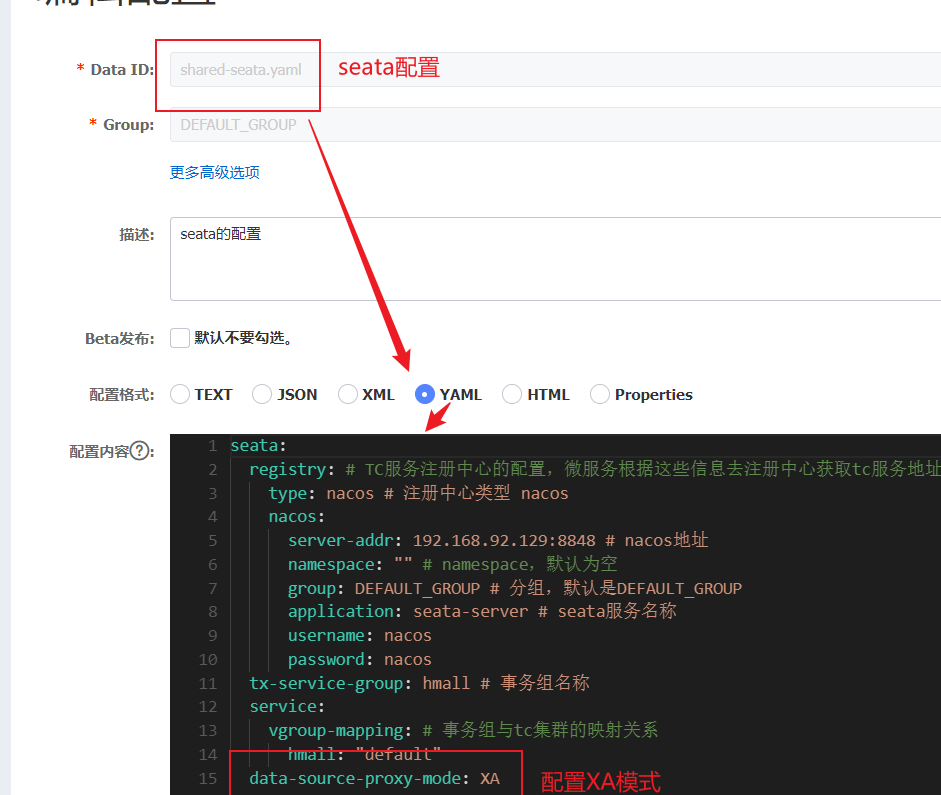
1.2.2 修改具体业务
对应全局事务位置添加@GlobalTranscational:
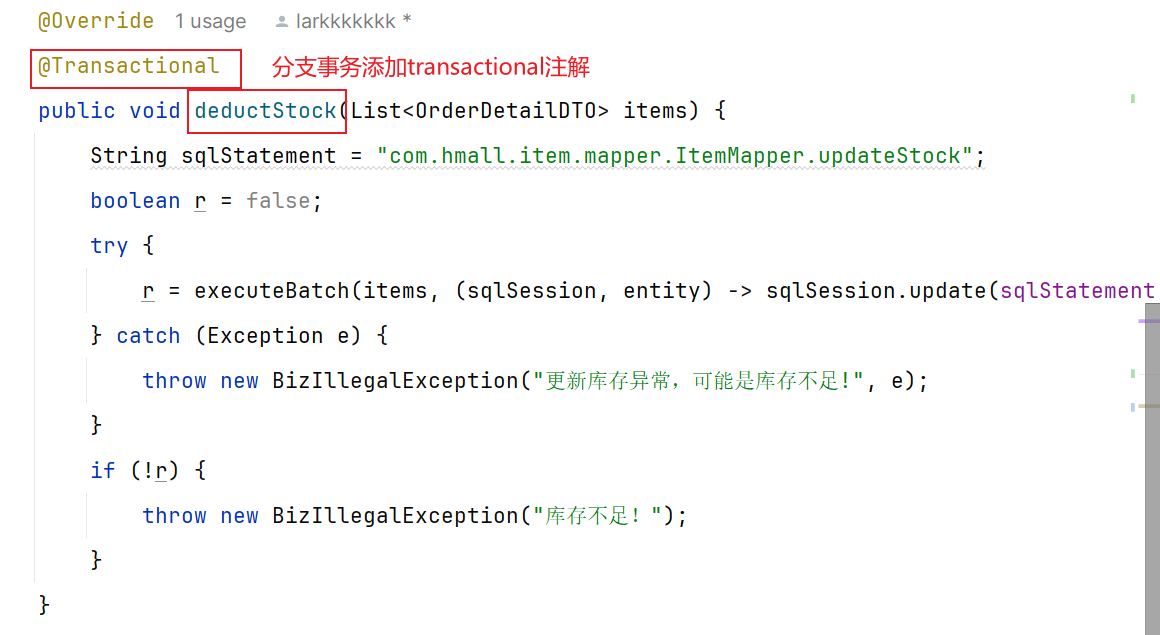
针对各个分支事务添加@transactional:
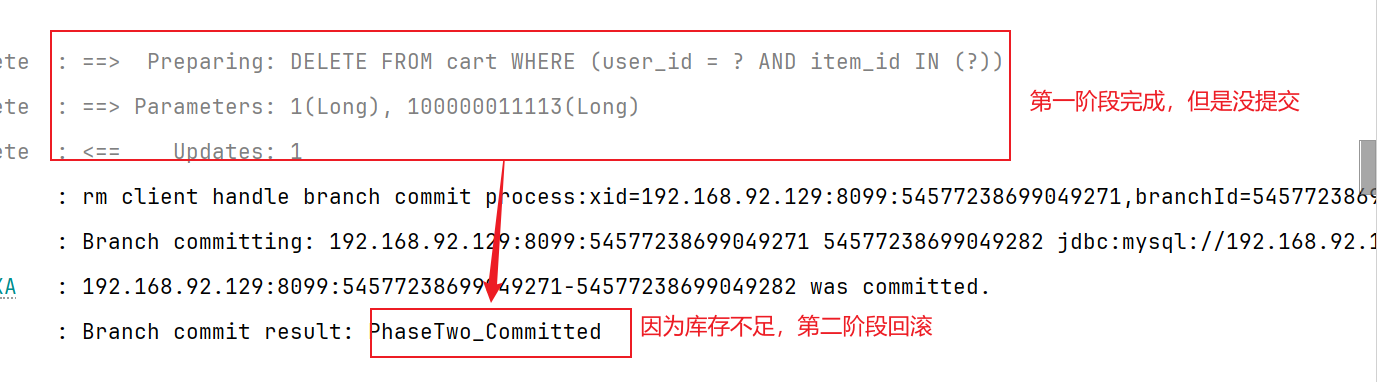
1.2.3 测试
我们加入手机到购物车,然后修改手机库存stock=0下单之后trade-service会提示:
1.3 XA使用总结
1.4 XA优缺点
XA模式的优点是什么?
事务的强一致性,满足ACID原则【第一阶段只完成不提交,只有第二阶段才告知一起回滚,还是一起提交】
常用数据库都支持,实现简单,并且没有代码侵入【比较好理解,而且比较规整】
XA模式的缺点是什么?
因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差【第一阶段只能等第二阶段指令,阻塞时间长】
依赖关系型数据库实现事务【关系型数据库】
1.5 XA模式和AT模式对比
| XA模式【模式强一致,一步一步来】 | AT模式【模式最终一致,可以第二阶段回退】 | |
|---|---|---|
| 第一阶段 | 只完成不提交(锁定资源,阻塞) | 直接提交(不锁定资源) |
| 第二阶段 | 数据库机制完成回滚 | 数据快照完成回滚(第一阶段执行业务之前生成快照) |
| 性能 | 低(只有第二阶段才决定事务提交/回退) | 高(第一阶段就提交,第二阶段可以恢复) |
2.AT模式[各自提交,有问题快照恢复]
分阶段提交的事务模型,不过弥补了XA模型中资源锁定周期过长的缺陷(一直阻塞等到第二阶段TC告知RM才可以进行操作)
==①你可以自己提交,然后提交的时候搞个快照(备份),不用锁定资源②如果都成功就删除快照(备份),不成功就用快照(备份)恢复==
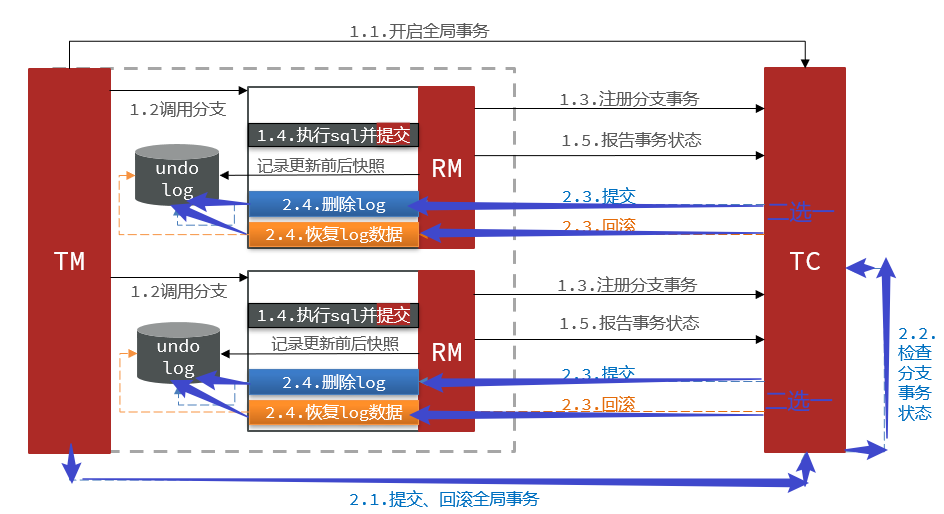
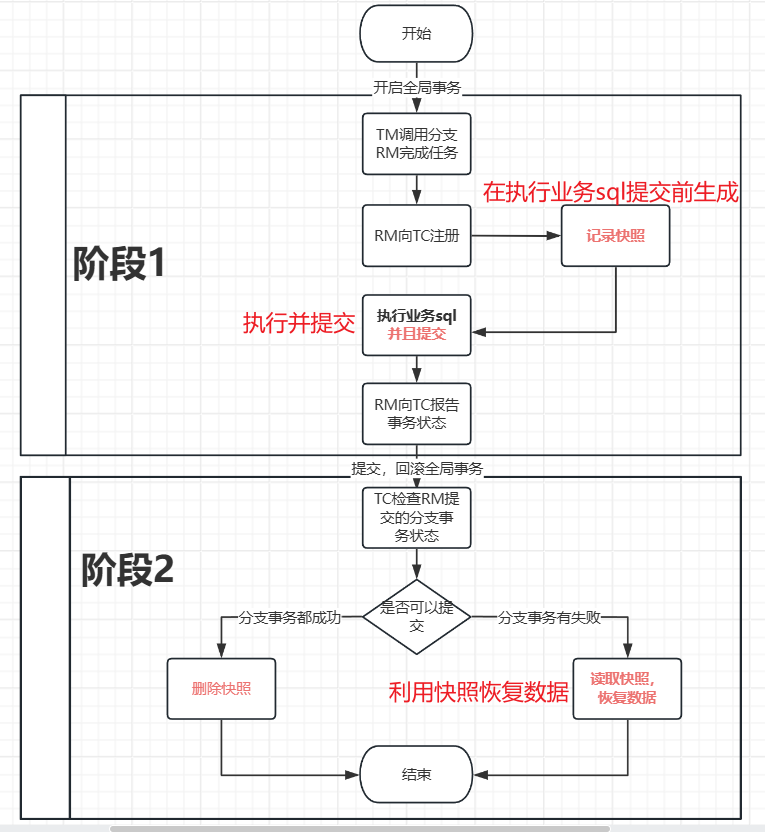
2.1 基本概念
主要分为==两个阶段==提交:
一阶段的工作:
TM发起并注册全局事务到TCTM调用分支事务- 分支事务准备执行业务SQL
RM拦截业务SQL,根据where条件查询原始数据,形成快照。【在执行业务sql之前生成快照】
1 | { |
RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90【我已经完成了自己的任务,并且提交了】RM报告本地事务状态给TC
二阶段的工作:
TM通知TC事务结束【ok了,你判断一下吧】TC检查分支事务状态【如果都成功删除快照,如果有失败就用快照恢复数据库回滚】- 如果都成功,则立即删除快照
- 如果有分支事务失败,需要回滚。读取快照数据({“id”: 1, “money”: 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图如下:
2.2 具体实现操作
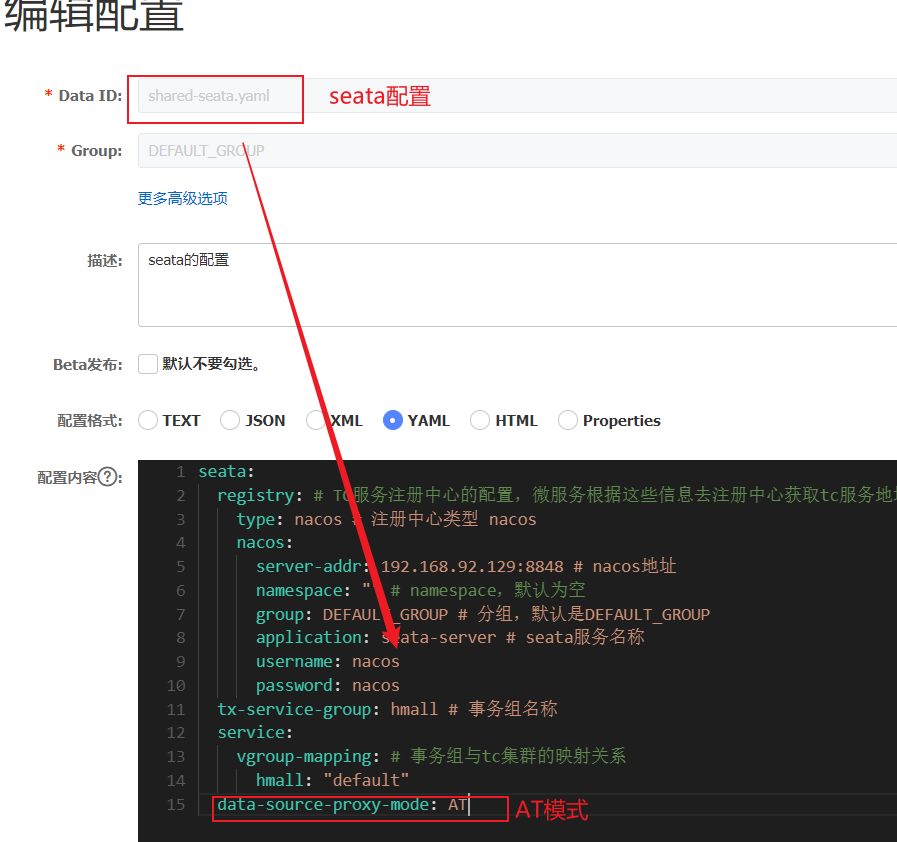
2.2.1 yml配置
类似于XA,就是将属性改为AT
2.2.2 修改具体业务
类似与XA,就是全局事务位置加注解@GlobalTransanctional,分支事务位置加注解@Transanctional
2.2.3 添加快照undo表
1 | -- for AT mode you must to init this sql for you business database. the seata server not need it. |
2.2.4 测试
类似于XA测试,只不过多了快照数据进入到undo表
2.3 AT使用总结
1.yml添加配置
2.业务添加注解@GlobalTransanctional即可
3.添加快照表【比XA模式就多一个这个】
2.4 AT优缺点
XA模式的优点是什么?
- 第一阶段就直接提交了,性能较好【后续如果需要就使用快照恢复】
XA模式的缺点是什么?
- 第一阶段就提交,在第二阶段完成的极小时间段内可能出现数据不一致【用空间换时间】—99%没问题,极端情况下【特别是多线程并发访问AT模式的分布式事务时,有可能出现脏写问题(丢失一次更新)】
2.5 AT模式—脏写问题
这种模式在大多数情况下(99%)并不会有什么问题,不过在极端情况下,特别是多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:

- 解决思路:引入全局锁【在释放DB锁之前,先拿到全局锁】,避免同一时刻有另外一个事务来操作当前数据。
【全局锁(TC管理):记录这行数据,其他事务可以CRUD】
【DB锁(数据库管理):锁住这行数据,其他事务不可以CRUD】

就是在原来基础上,增加获取全局锁部分[记录当前操作这行数据的事务];其他的事务获取全局锁(失败重试30次,间隔10ms一次)
2.6 XA模式和AT模式对比
| XA模式【模式强一致,第二阶段统一处理】 | AT模式【模式最终一致,可以第二阶段回退】 | |
|---|---|---|
| 第一阶段 | 只完成不提交(锁定资源,阻塞) | 直接提交(不锁定资源) |
| 第二阶段 | 数据库机制完成回滚 | 数据快照完成回滚(第一阶段执行业务之前生成快照) |
| 性能 | 低(只有第二阶段才决定事务提交/回退) | 高(第一阶段就提交,第二阶段可以恢复) |
3.TCC模式[各自提交,有问题人工恢复]
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
try:检测和预留资源;confirm:完成资源操作业务;要求try成功confirm一定要能成功。cancel:释放预留资源,【try的反向操作】
3.1 流程分析[举例]
例子:一个扣减用户余额的业务。假设账户A原来余额是100,需要余额扣减30元。
- 阶段一(try):检查余额是否充足,如果充足则冻结金额增加30元,可用余额扣减30
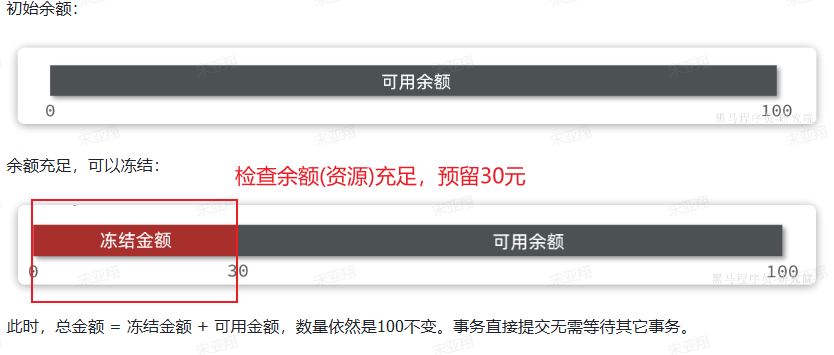
- 阶段二(Confrim):假设要提交,之前可用金额已经扣减,并且转移到冻结金额。因此可用金额不变,直接冻结金额-30即可:

- 阶段三(Cancel):如果要回滚,则释放之前冻结的金额(冻结金额-30,可用金额+30)

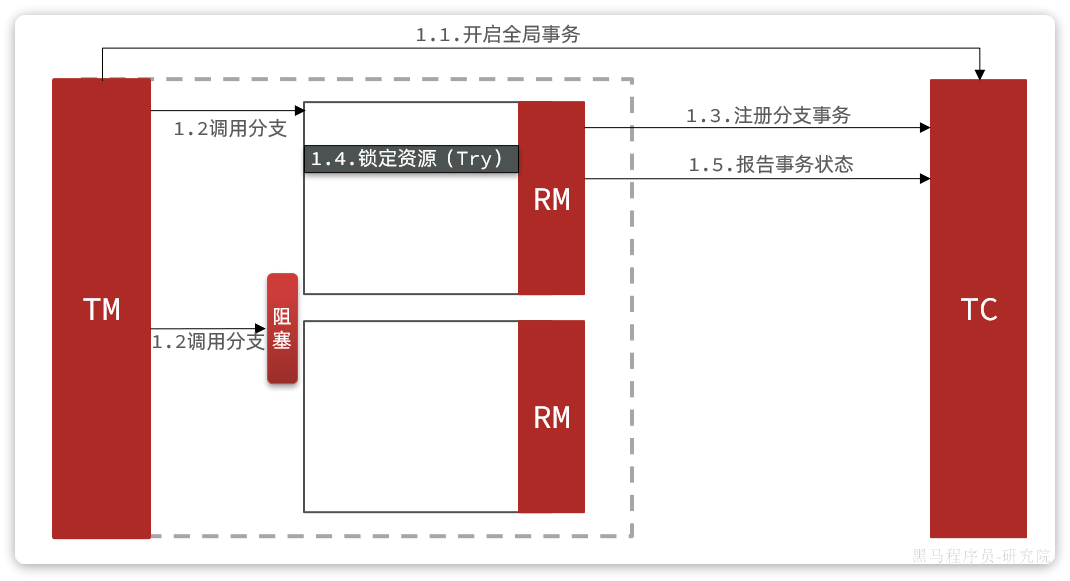
3.2 事务悬挂和空回滚
假如一个分布式事务中包含两个分支事务,try阶段,一个分支成功执行,另一个分支事务阻塞:
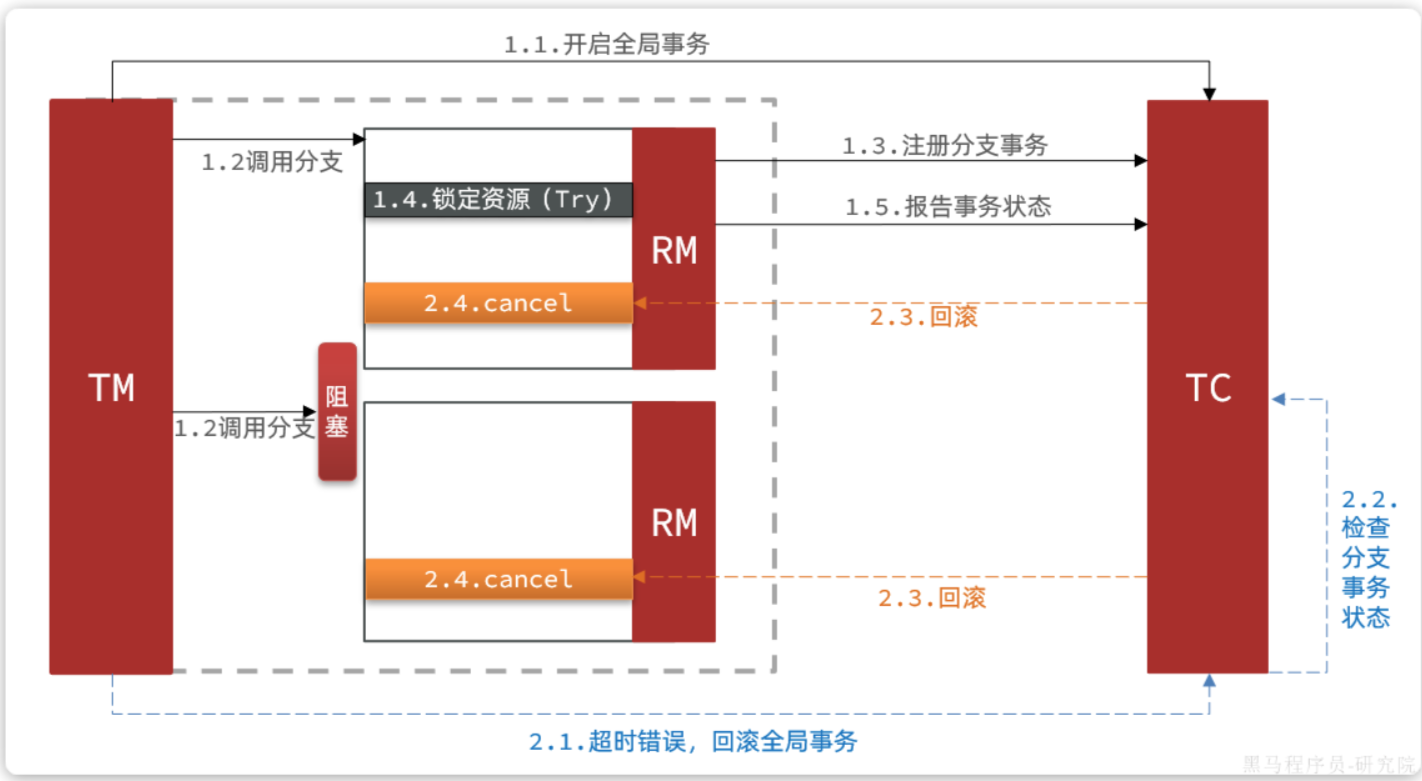
如果阻塞时间太长,可能导致全局事务超时而触发三阶段的cancel操作。两个分支事务都会执行cancel操作:
其中一个分支是未执行try操作的,直接执行了cancel操作,反而会导致数据错误。因此,这种情况下,尽管cancel方法要执行,但其中不能做任何回滚操作,这就是空回滚【一个分支事务没执行try操作,但要被牵连执行cancel操作,需要执行cancel操作但是不能做任何回滚操作(不应该回滚)】
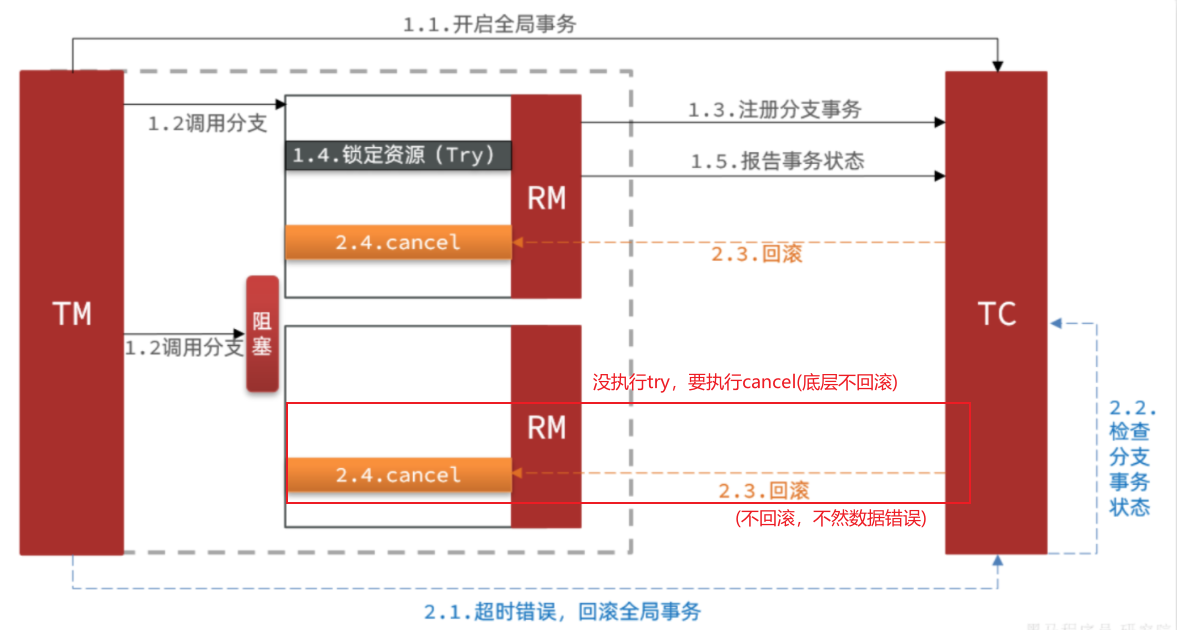
对于整个空回滚的分支事务,将来阻塞结束try方法依然会执行。但是整个全局事务其实已经结束了,因此永远不会再有confirm或cancel,也就是说这个事务执行了一半,处于悬挂状态【阻塞结束,try执行,但是整体全局事务已经结束,无后续】
3.3 TCC使用总结
CC的优点是什么?
- 一阶段完成直接提交事务,释放数据库资源,性能好
- 相比AT模型,无需生成快照,无需使用全局锁,性能最强【不需要快照,人工恢复】
- 不依赖数据库事务,而是依赖补偿操作,可以用于非事务型数据库【人工补偿,不依赖数据库事务】
TCC的缺点是什么?
- 有代码侵入,需要人为编写try、Confirm和Cancel接口,太麻烦【人工恢复,需要代码入侵】
- 软状态,事务是最终一致【不是强一致性,BASE理论】
- 需要考虑Confirm和Cancel的失败情况,做好幂等处理、事务悬挂和空回滚处理


