1.同步调用和异步调用
1.1 同步调用
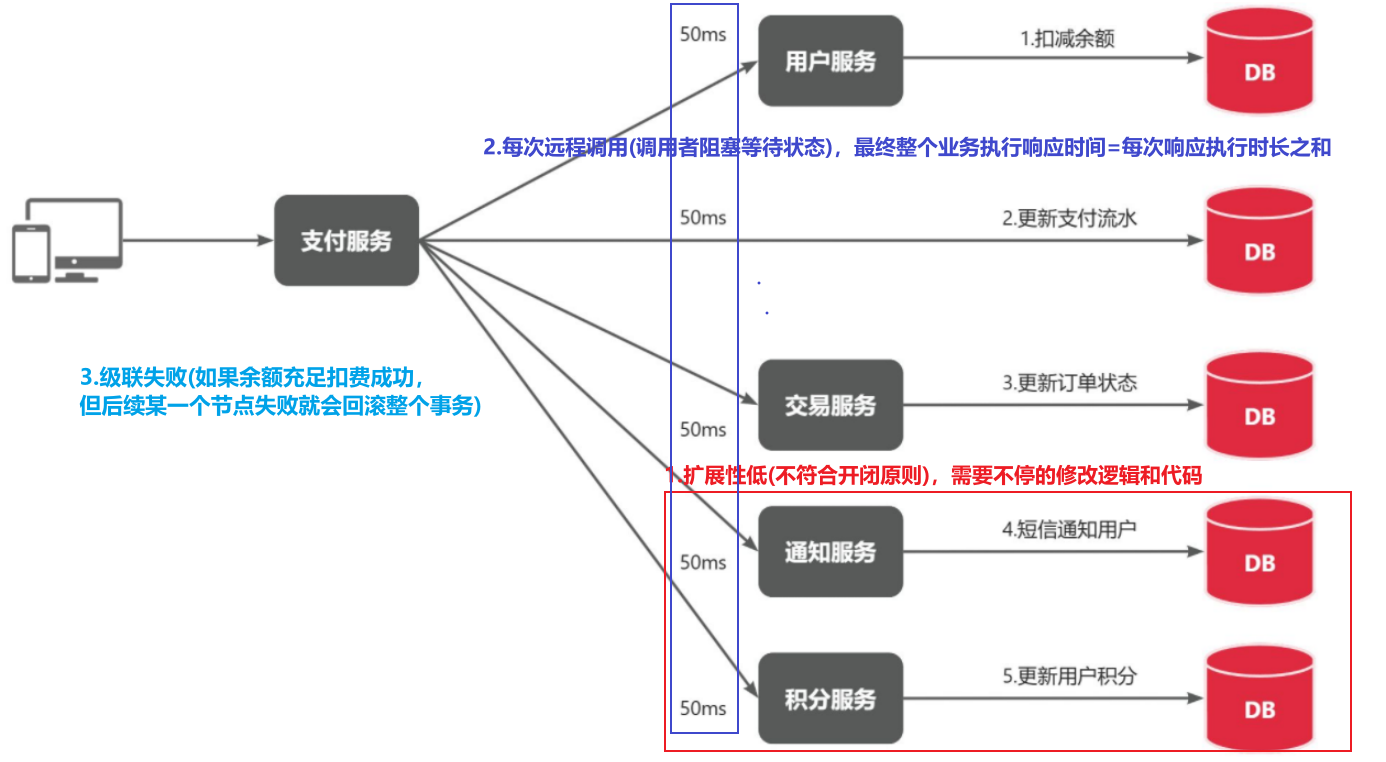
综上,同步调用的方式存在下列问题:
- 拓展性差(新增业务和逻辑就要修改,不符合开闭原则)
- 性能下降
- 级联失败
而要解决这些问题,我们就必须用异步调用的方式来代替同步调用
1.2 异步调用
异步调用方式其实就是==基于消息通知的方式==,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
- 消息接收者:接收和处理消息的人,就是原来的服务提供方
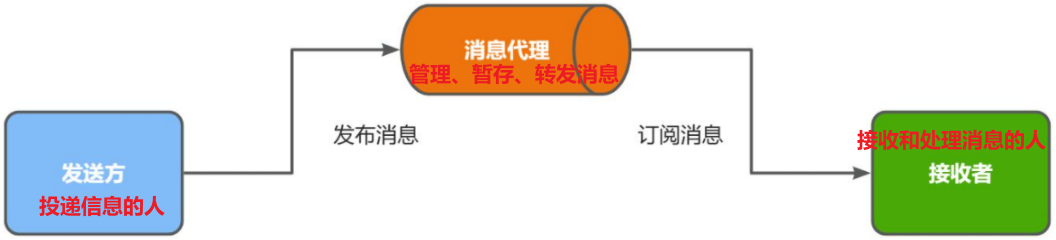
异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker(消息代理)。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理 —> 发送消息的人和接收消息的人就完全解耦了
如图所示:
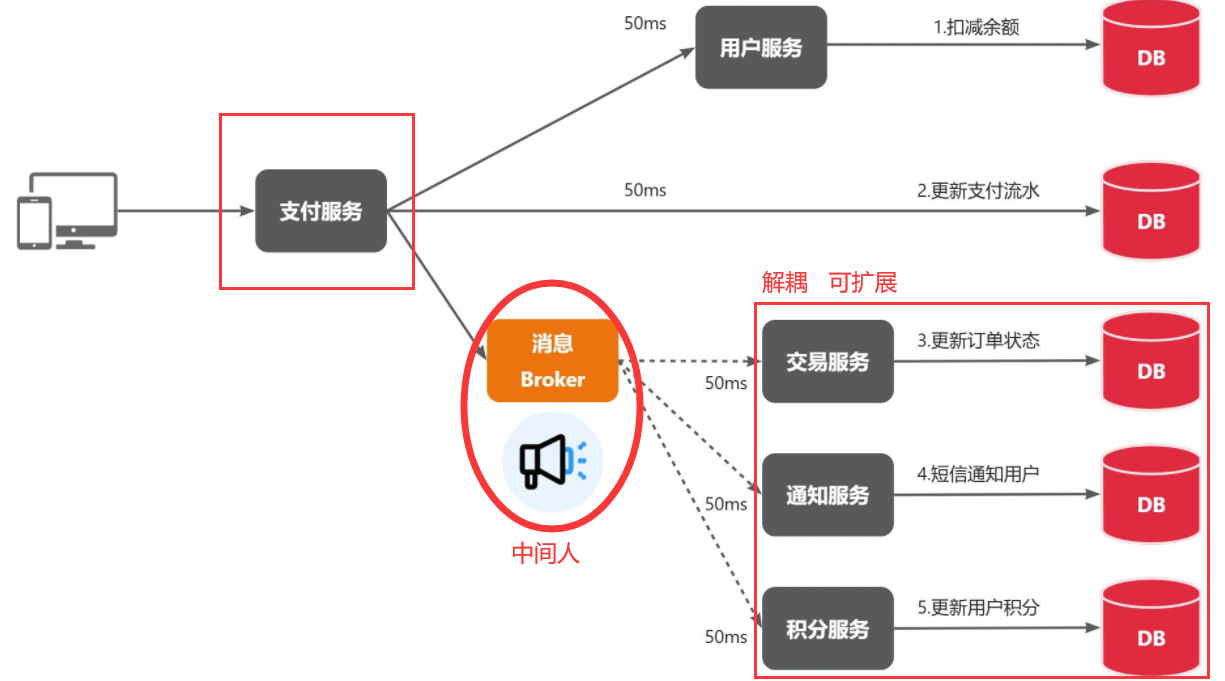
综上,异步调用的优势包括:
- 耦合度更低
- 性能更好
- 业务拓展性强
- 故障隔离,避免级联失败
当然,异步通信也并非完美无缺,它存在下列缺点:
完全依赖于Broker的可靠性、安全性和性能
架构复杂,后期维护和调试麻烦
1.3 MQ技术选型
消息Broker,目前常见的实现方案就是消息队列(MessageQueue),简称为MQ.
目比较常见的MQ实现:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
几种常见MQ的对比:
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP XMPP SMTP STOMP | OpenWire STOMP REST XMPP AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
据统计,目前国内消息队列使用最多的还是RabbitMQ,再加上其各方面都比较均衡,稳定性也好
2.RabbitMQ

RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官网地址:Messaging that just works — RabbitMQ
2.1 RabbitMQ安装
基于Docker来安装RabbitMQ,命令如下:
1 | docker run |
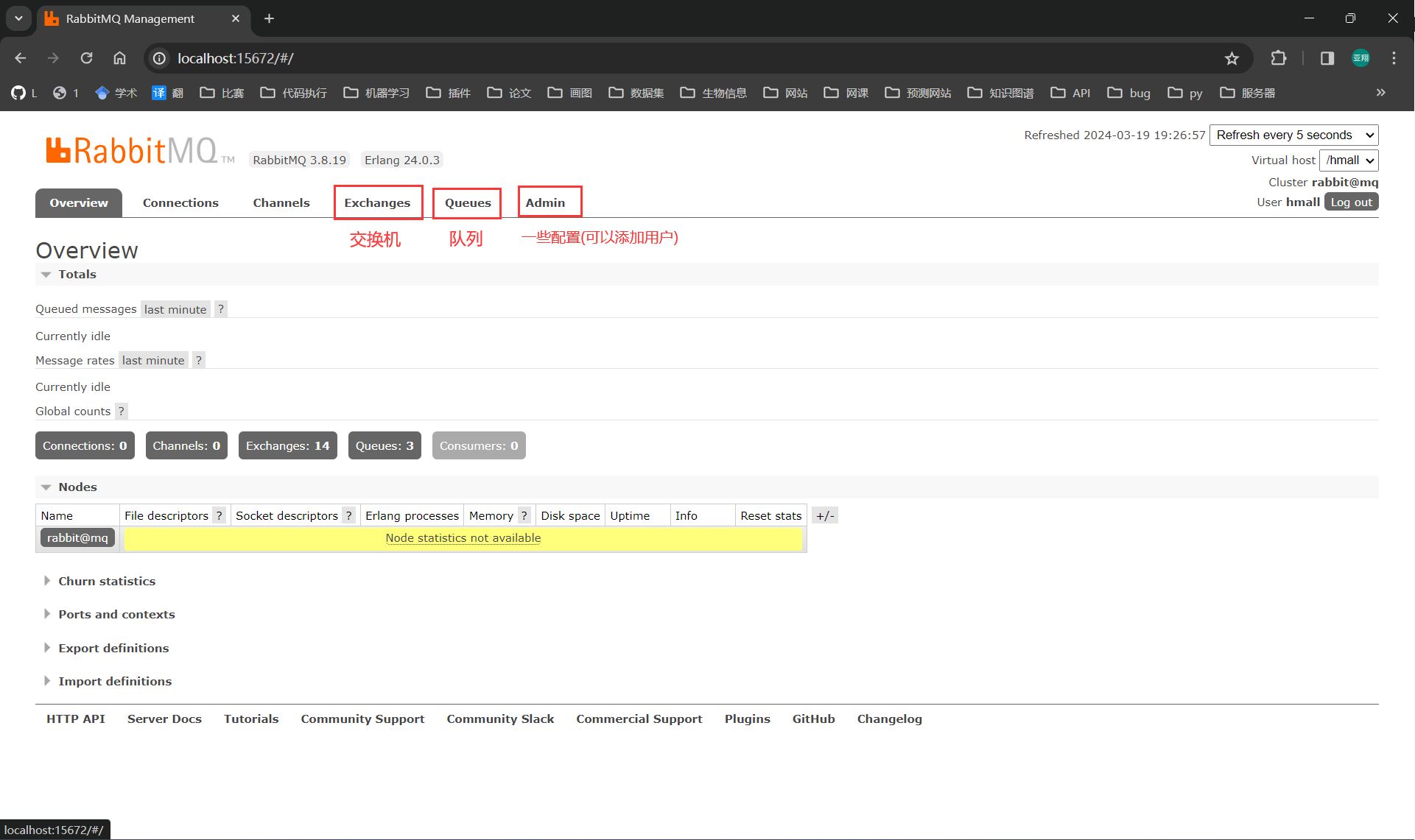
可以看到在安装命令中有两个映射的端口:
- 15672:RabbitMQ提供的管理控制台的端口
- 5672:RabbitMQ的消息发送处理接口
通过访问 http://localhost:15672即可看到管理控制台。首次访问登录,需要配置文件中设定的用户名和密码
2.2 RabbitMQ架构
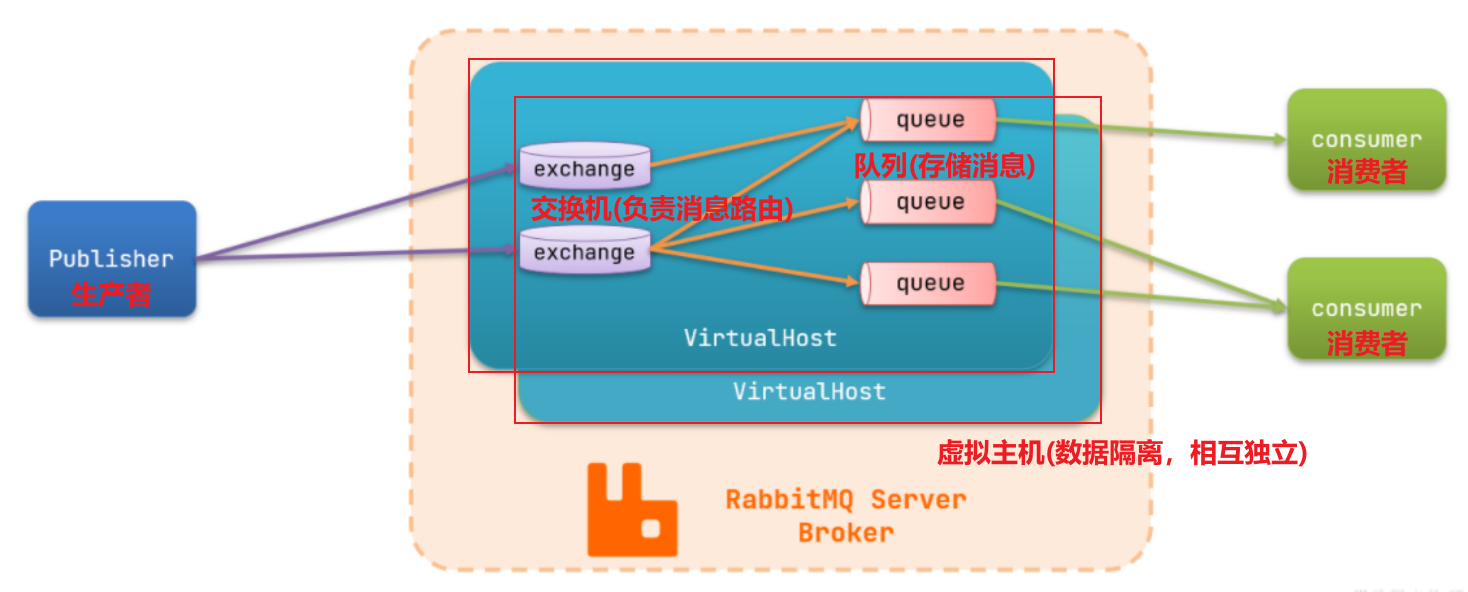
其中包含几个概念:
**publisher**:生产者,也就是发送消息的一方**consumer**:消费者,也就是消费消息的一方**queue**:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理**exchange**:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。**virtual host**:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue
上述这些东西都可以在RabbitMQ的管理控制台来管理
3.SpringAMQP
RabbitMQ采用AMQP协议,因此具有跨语言的特性。任何语言只要遵循AMQP协议收发消息,都可以与RabbitMQ交互【RabbitMQ官方提供了各种不同语言的客户端】
但是RabbitMQ官方提供的Java客户端编码复杂,一般生产环境下我们更多会结合Spring来使用,Spring提供模板工具和SpringBoot自动装配 –> ==SpringAMQP==
提供三个功能:
- 自动声明队列、交换机及其绑定关系
- 基于注解的监听器模式,异步接收消息
- 封装了RabbitTemplate工具,用于发送消息 -rabbitTemplate.convertAndSend(队列名,发送信息);
3.1 生产者-消费者(1-1)
3.1.1 导入Demo工程

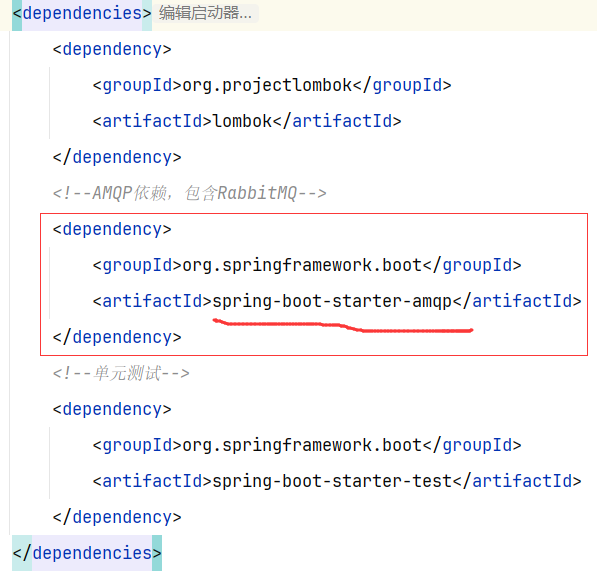
3.1.2 导入maven坐标
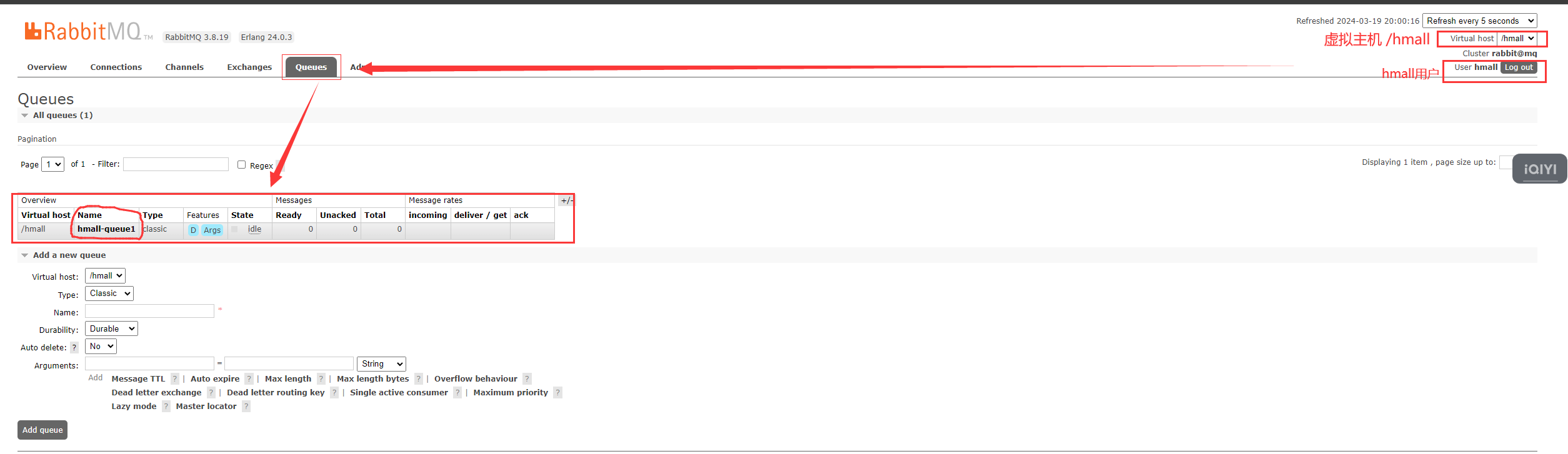
3.1.3 新建队列
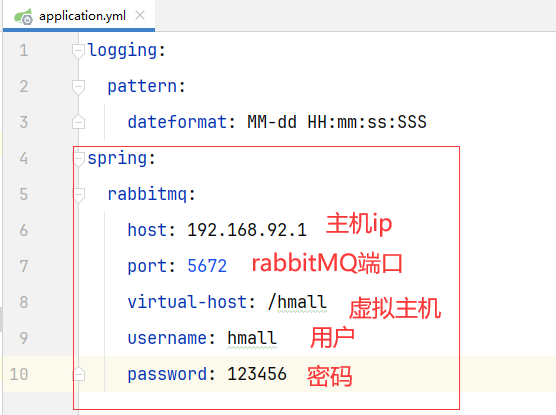
3.1.4 每个子工程配置RabbitMQ信息
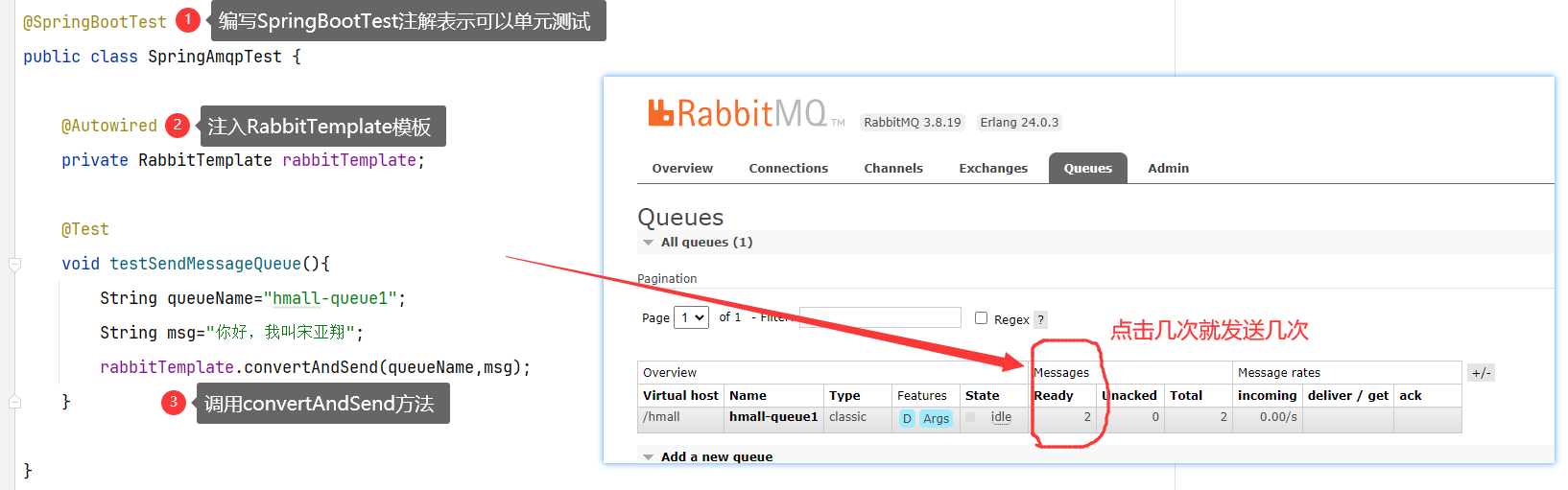
3.1.5 生产者发送消息
1 | 1.注入RabbitTemplate对象 |
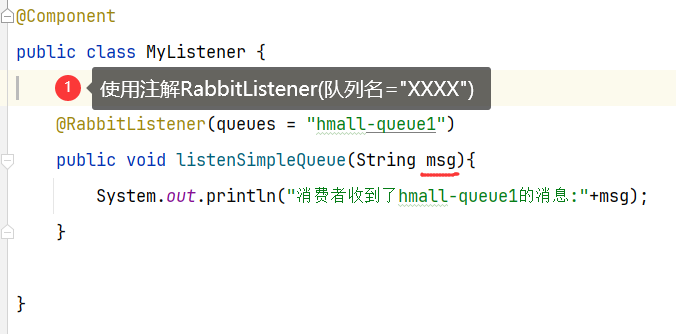
3.1.6 消费者接收消息
1 | 1.使用注解RabbitListener(队列名=“xxx”) |
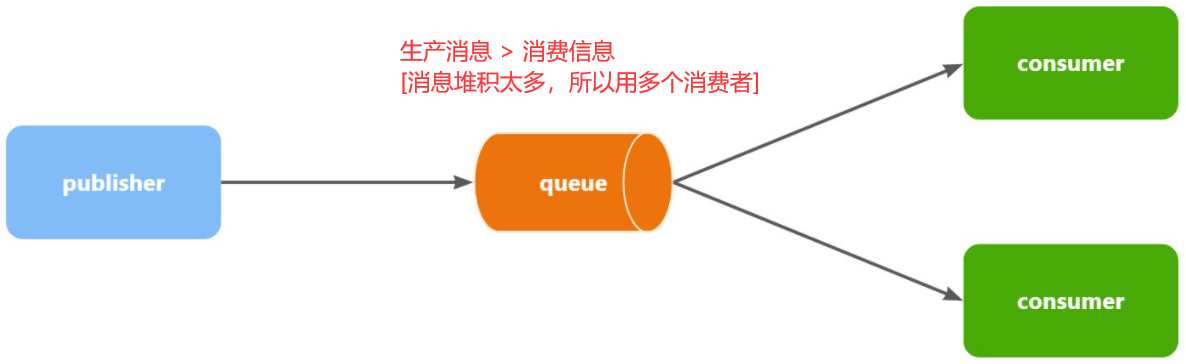
3.2 生产者-消费者(1-n) -WorkQueues任务模型
Work queues任务模型 –> 让多个消费者绑定到一个队列,共同消费队列中的消息 –> ==解决消息堆积太多==
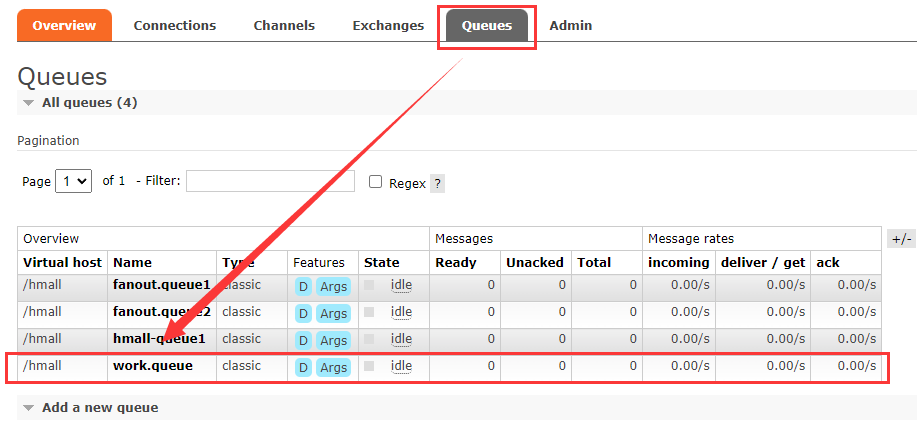
3.2.1 新建队列
3.2.2 生产者发送消息
一个发送者,循环发送50次消息
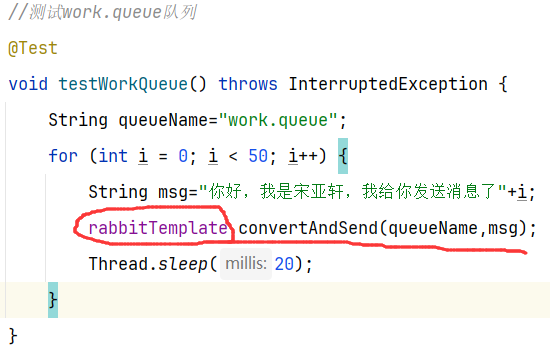
3.2.3 消费者接收消息
两个消费者接收消息,一个休眠20ms(每秒钟处理50个消息),一个休眠200ms(每秒钟处理5个消息)

3.2.4 均匀分配
启动消费者子工程项目,再发送消息就可以接受消息:

可以看到消费者1和消费者2竟然每人消费了25条消息:
- 消费者1很快完成了自己的25条消息
- 消费者2却在缓慢的处理自己的25条消息。
也就是说消息是==平均分配==给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的
3.2.5 能者多劳(yml配置prefetch)
修改==listener.simple.prefetch:1==可以保证==能者多劳==,每个消费者每次只能获取一条消息,处理完成才能获取下一条消息
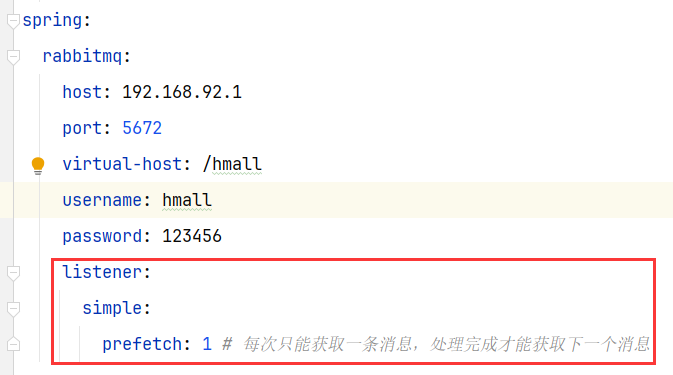
更改之后重新发送消息:

可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。
正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题
4.交换机(Exchange)
在3.1和3.2部分没有添加交换机,生产者直接发送消息到队列。但是引入交换机之后消息发送的模式会有很大的变化:
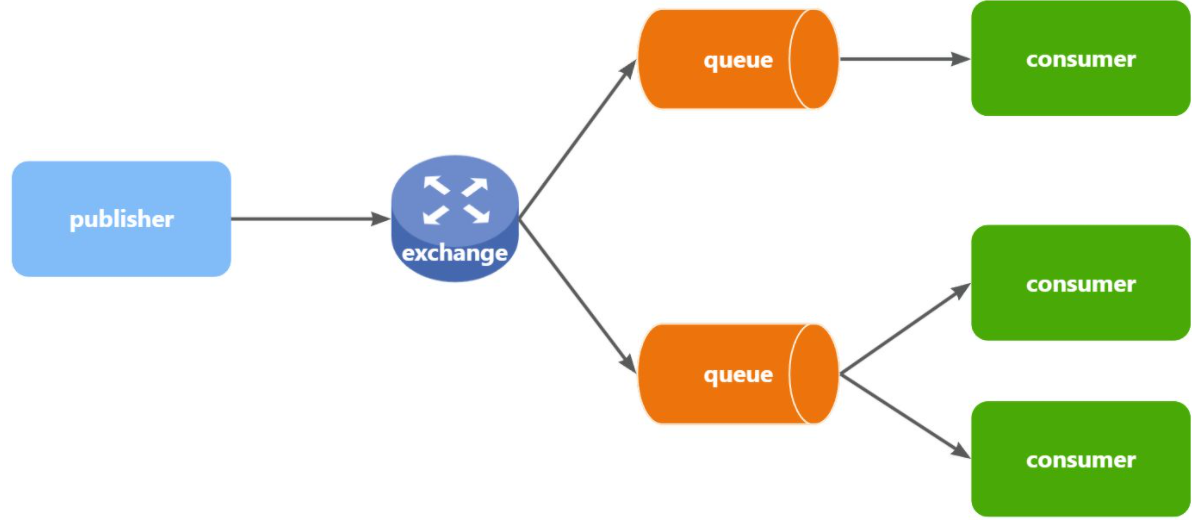
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息(递交给某个特别队列、递交给所有队列、或是将消息丢弃)
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,【没有变化】
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
Exchange(交换机)的类型有四种:
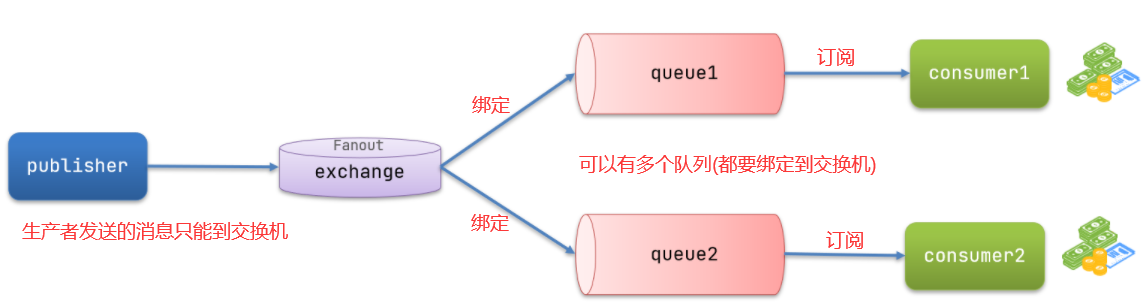
- Fanout:广播,将消息交给所有绑定到交换机的队列。【最早在控制台使用】
- Direct:订阅,基于RoutingKey(写死的路由key)发送给订阅了消息的队列
- Topic:通配符订阅,基于RoutingKey(符合通配符的路由key)发送给订阅了消息的队列
- Headers:头匹配,基于MQ的消息头匹配,【用的较少】
4.1 Fanout交换机(广播)
在广播(Fanout)模式下,消息发送流程是这样的
4.1.1 声明交换机和队列
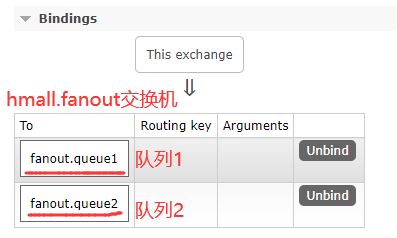
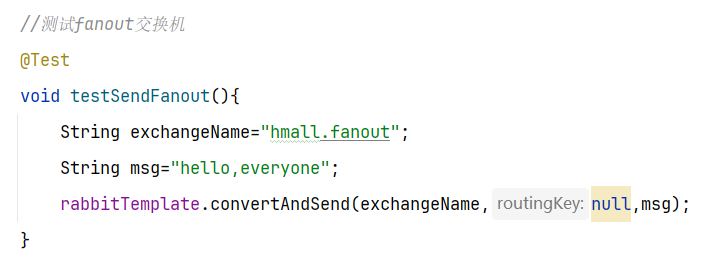
4.1.2 消息发送
4.1.3 消息接收
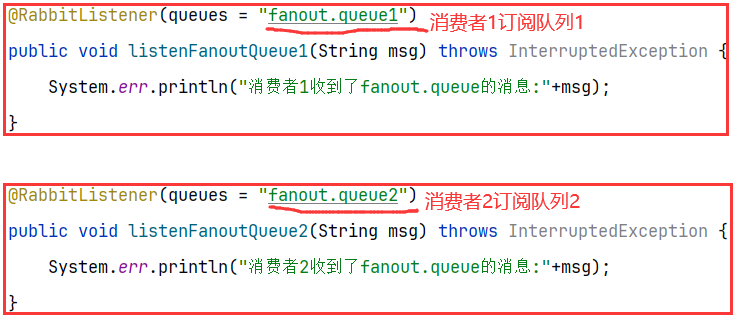
启动消费者子工程之后发送消息

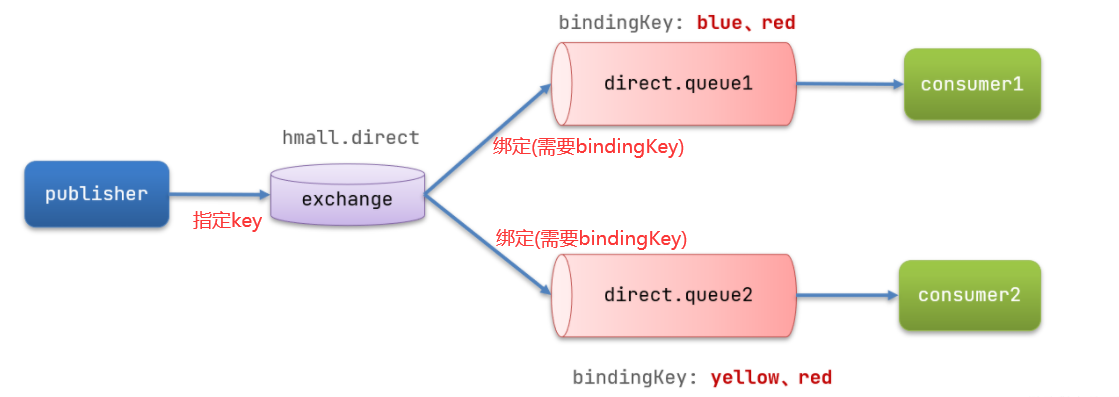
4.2 Direct交换机(订阅)
4.2.1 声明交换机和队列
官网在线创建:
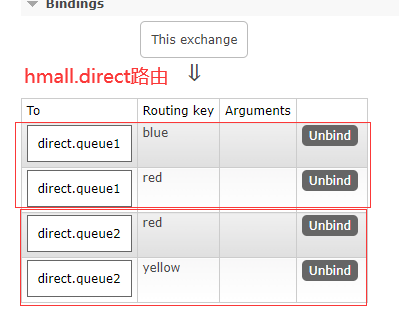
4.2.2 消息发送
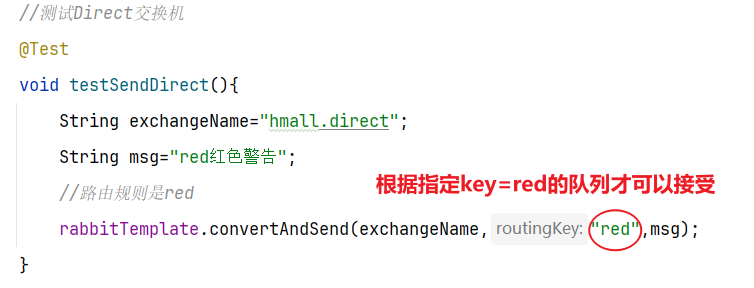
4.2.3 消息接收

4.3 Topic交换机(通配符订阅)
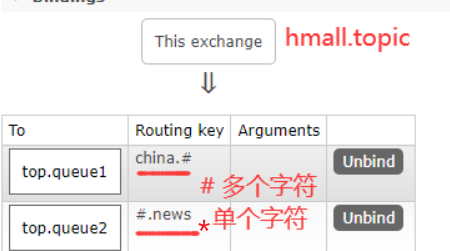
4.3.1 声明交换机和队列
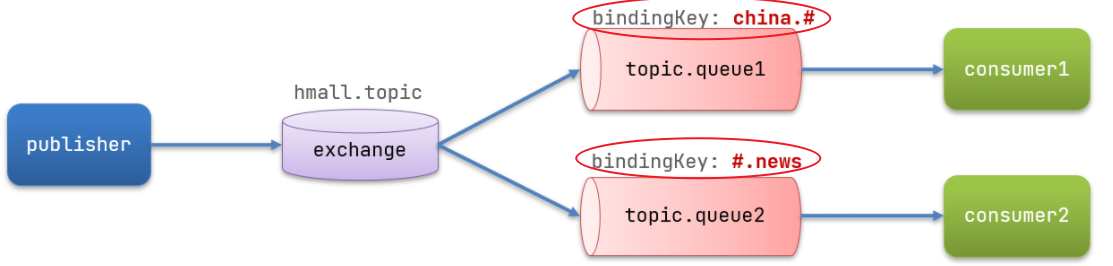
官网在线创建:
4.3.2 消息发送
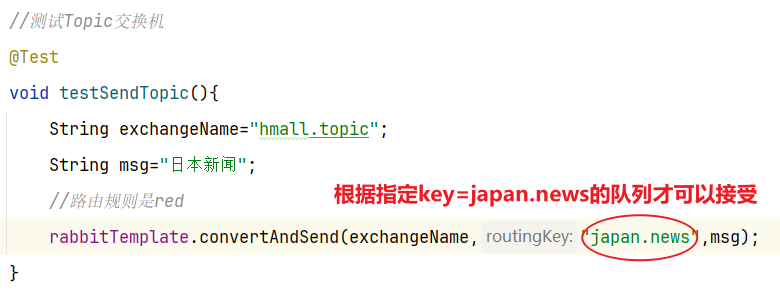
4.3.3 消息接收
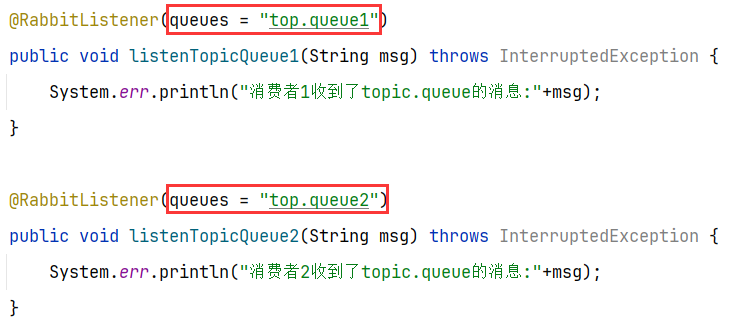
4.3.4 总结
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用==通配符==!
BindingKey一般是一个/多个单词组成,多个单词之间用.分割
通配符规则:
通配符规则:
#:匹配0个或者多个词*:匹配1个词
举例:
item.#:能够匹配item.spu.insert或者item.spu或者item(#可以是0个词到多个词)item.*:只能匹配item.spu(*只能是一个词)
5. API-队列和交换机(替换网页手动创建)
SpringAMQP提供了声明队列,交换机和绑定关系的API:
- Queue:队列
- Exchange:交换机
- Binding:绑定关系

5.1 @Bean方式声明(不推荐)
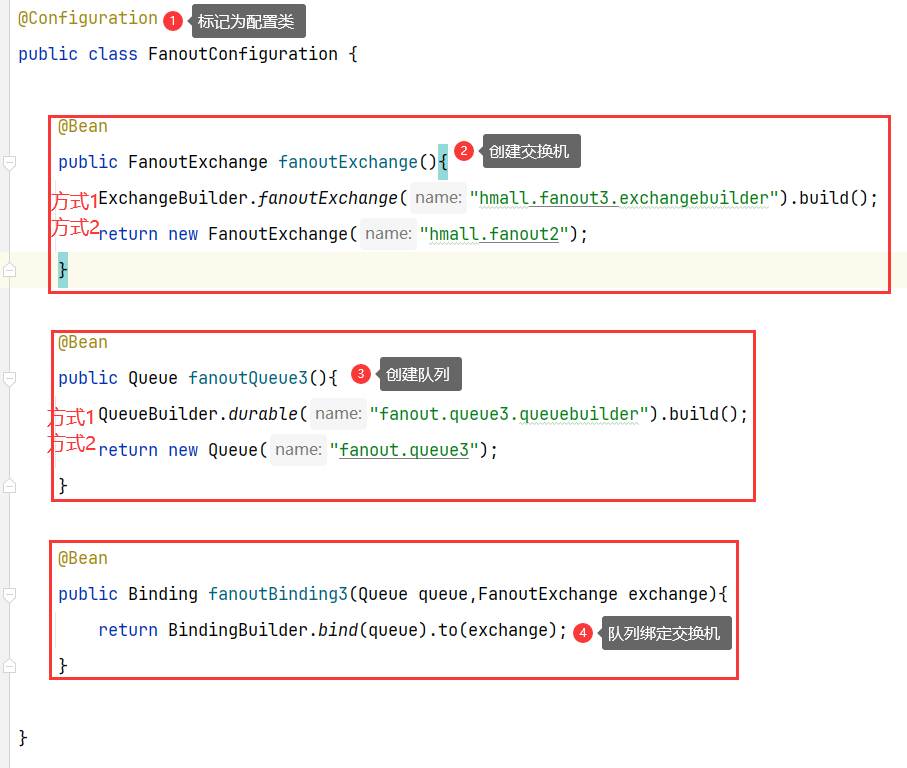
这样创建很繁琐,因此提供了基于注解的方式
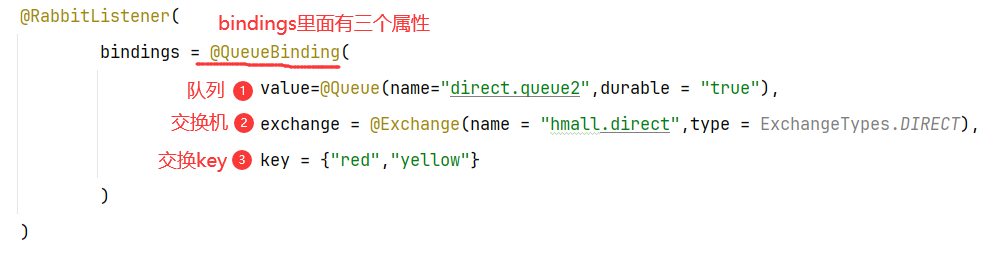
5.2 注解方式声明(推荐)
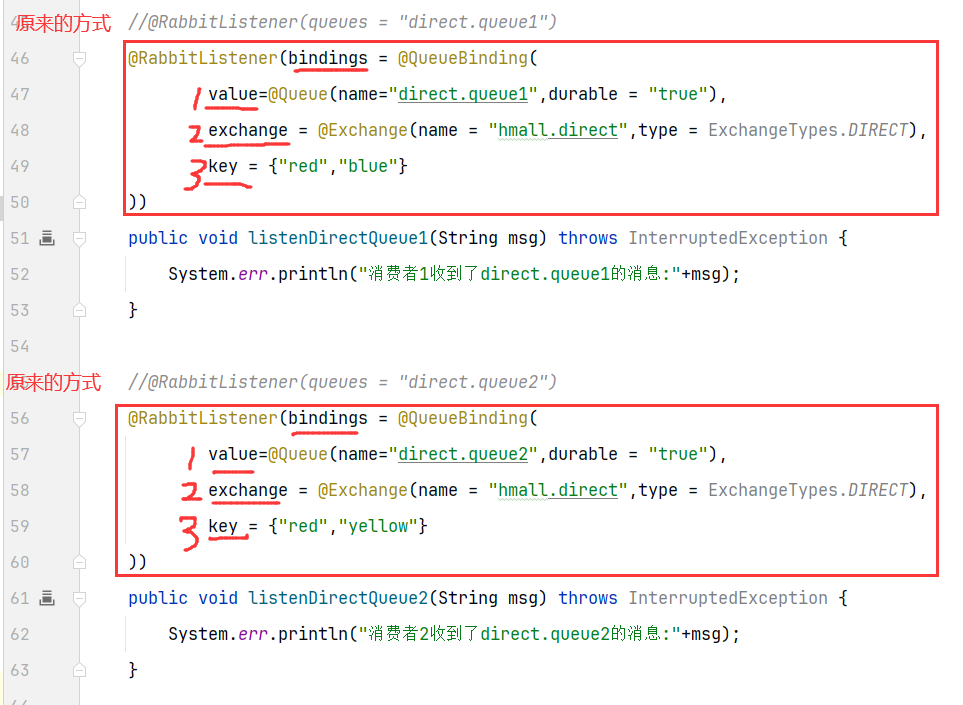
其实就是@RabbitListener注解里面配置关系(@QueueBinding),然后里面具体的就是交换机(@Exchange),队列(@Queue)以及路由key(key)
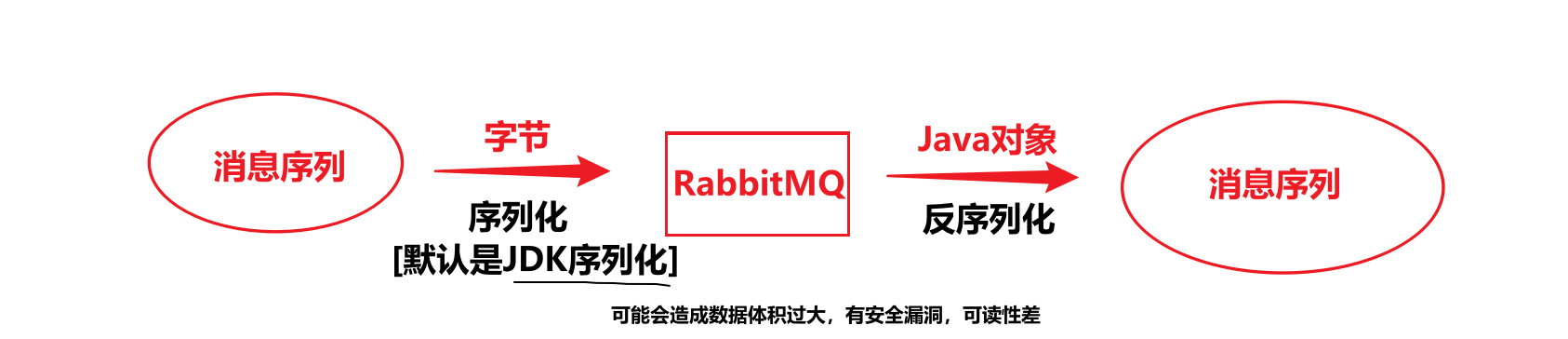
6.消息转换器[解决发送消息的JDK序列化]
Spring的convertAndSend()方法接收的是一个Object类型:

而在数据传输时,可能会因为默认的==JDK序列化==导致数据体积过大(乱码一样的序列化结果),安全漏洞,可读性差等问题。
因此可以考虑使用==Json序列化和反序列化==:
6.1 配置JSON转换器
- 1.在生产者和消费者两个服务中都要引入依赖
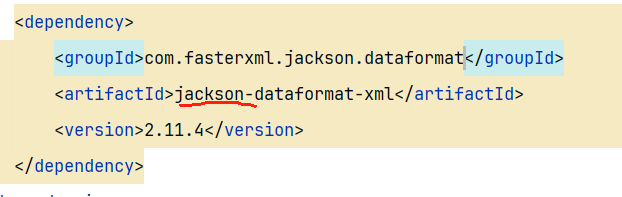
注意:如果项目中引入了Spring-boot-starter-web依赖,则无需再次引入Jackson依赖
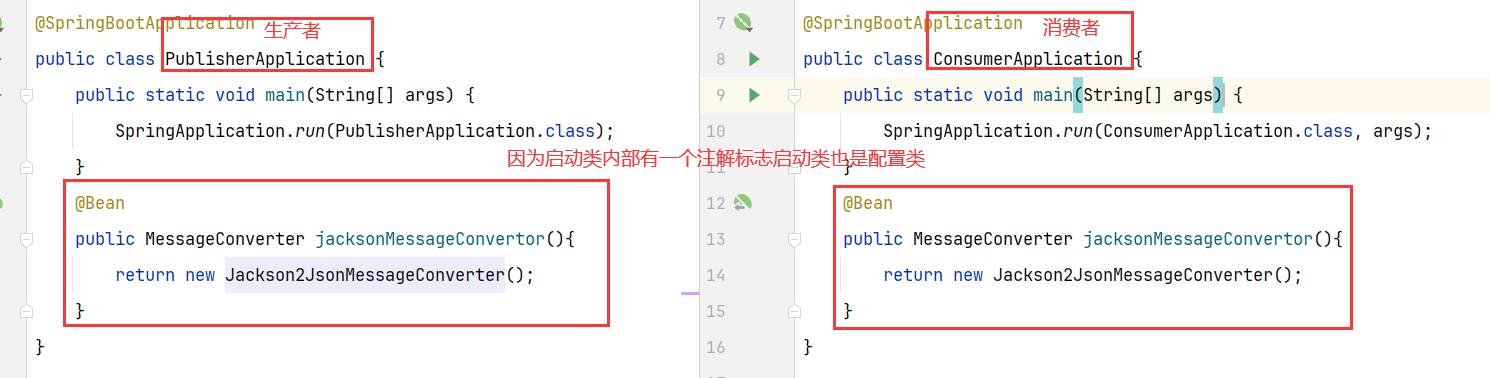
2.在生产者和消费者两个服务的启动类中添加一个Bean:配置消息转换器
==7.RabbitMQ使用总结==【直接看这里写代码】
==可以参考<RabbitMQ-黑马商城为例>这篇文章,有详细的操作介绍和步骤==
7.1 maven引入maven坐标
在生产者和消费者的pom.xml文件中配置:
1 | <!--消息发送--> |
7.2 子工程配置RabbitMQ信息
在生产者和消费者的application.yml文件中配置:
1 | spring: |
7.3 配置消息转换器[解决发送消息的JDK序列化]
可以在公共模块添加bean
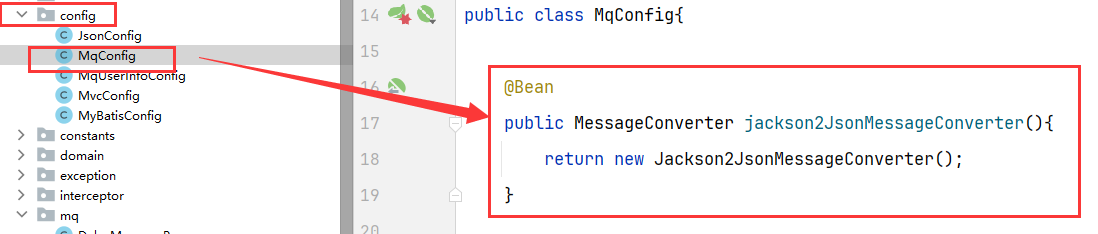
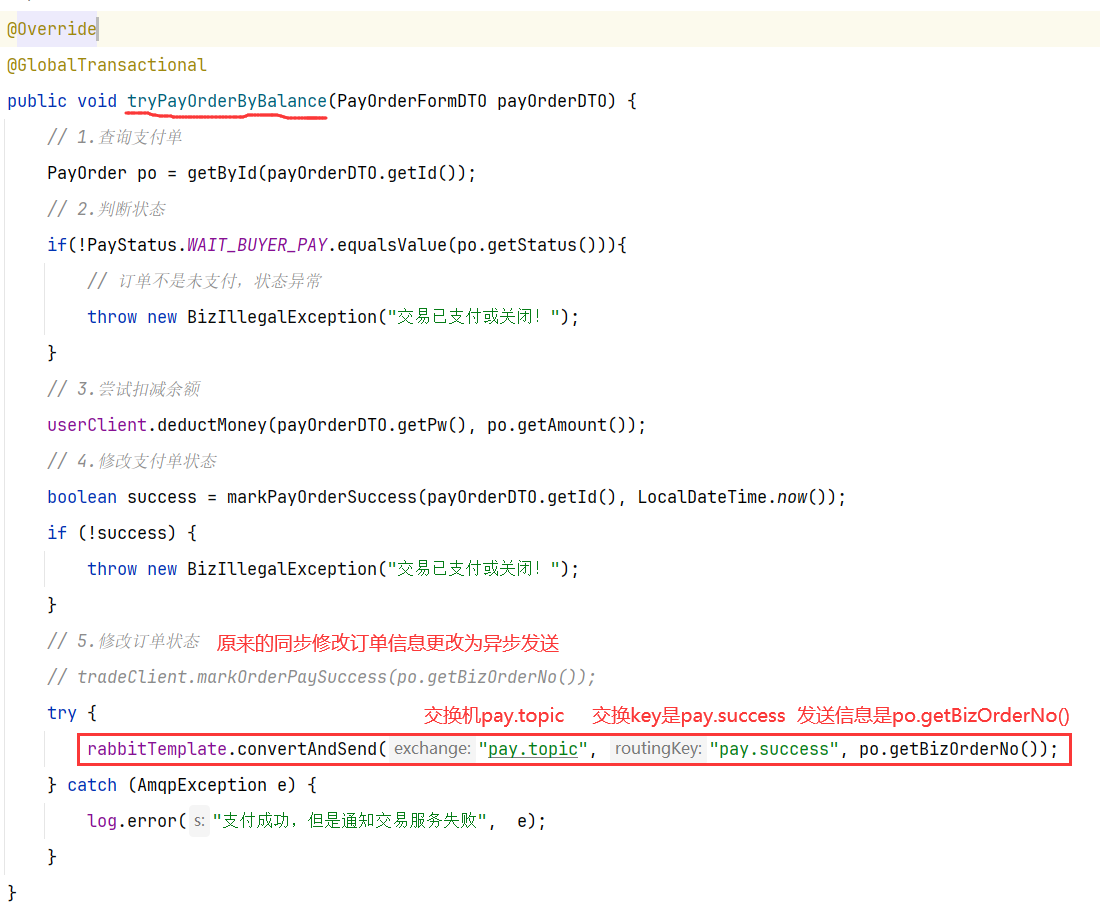
7.4 生产者-发送消息
将原始的同步修改订单信息更改为异步修改
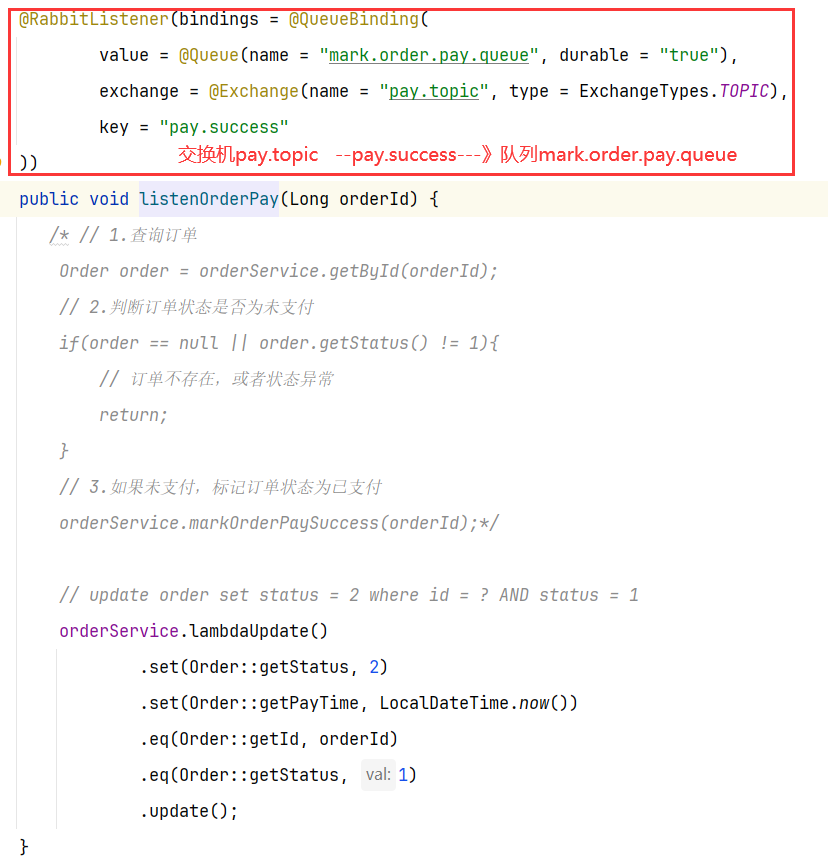
7.5 消费者-接收消息
消费者可以添加消息监听,添加好交换机和路由key和队列
==总结如下:==

大致就是导入maven,子工程配置一些属性,然后生产者调用rabbitMQ的rabbitTemplate.convertAndSend()方法发送消息【里面可以添加各种】,在消费者方面可以①使用bean进行声明交换机,队列和关系②使用@RabbitListener注解进行声明【里面可以添加一些属性,例如持久化的,lazyqueue的,延迟消息的】
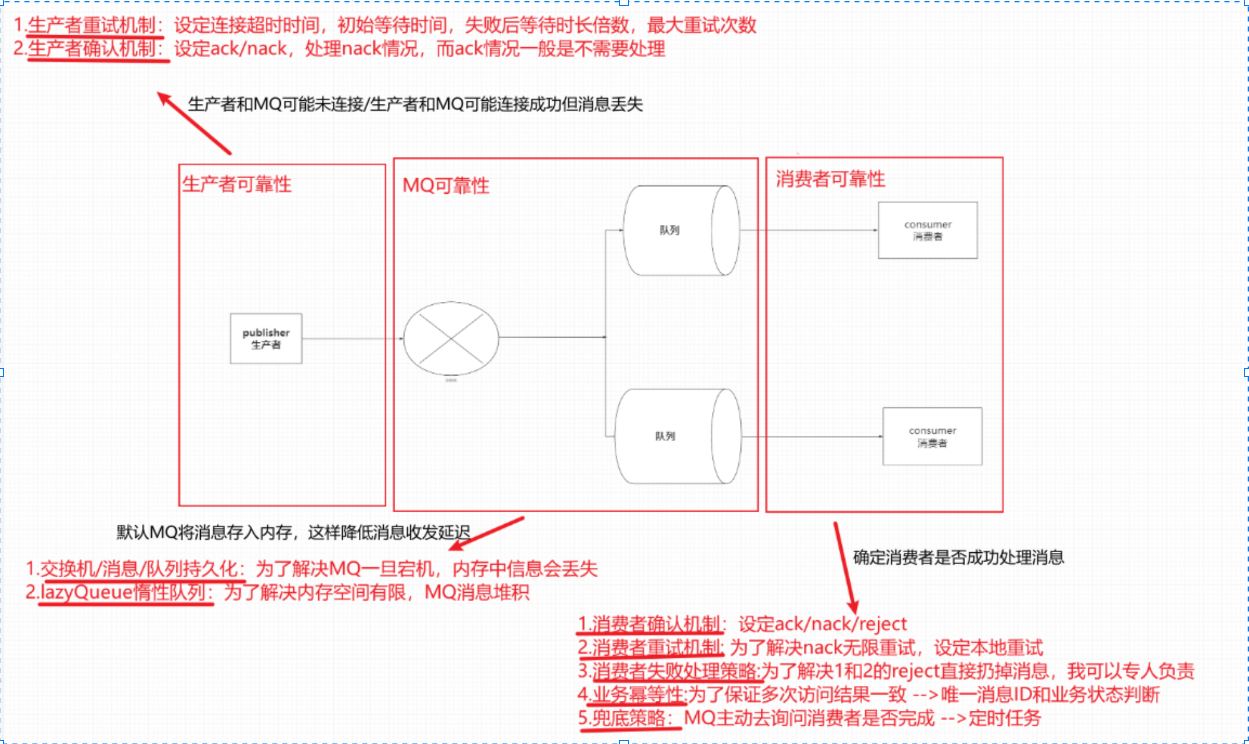
==高级进阶 –保证消息可靠性(三个方面)==
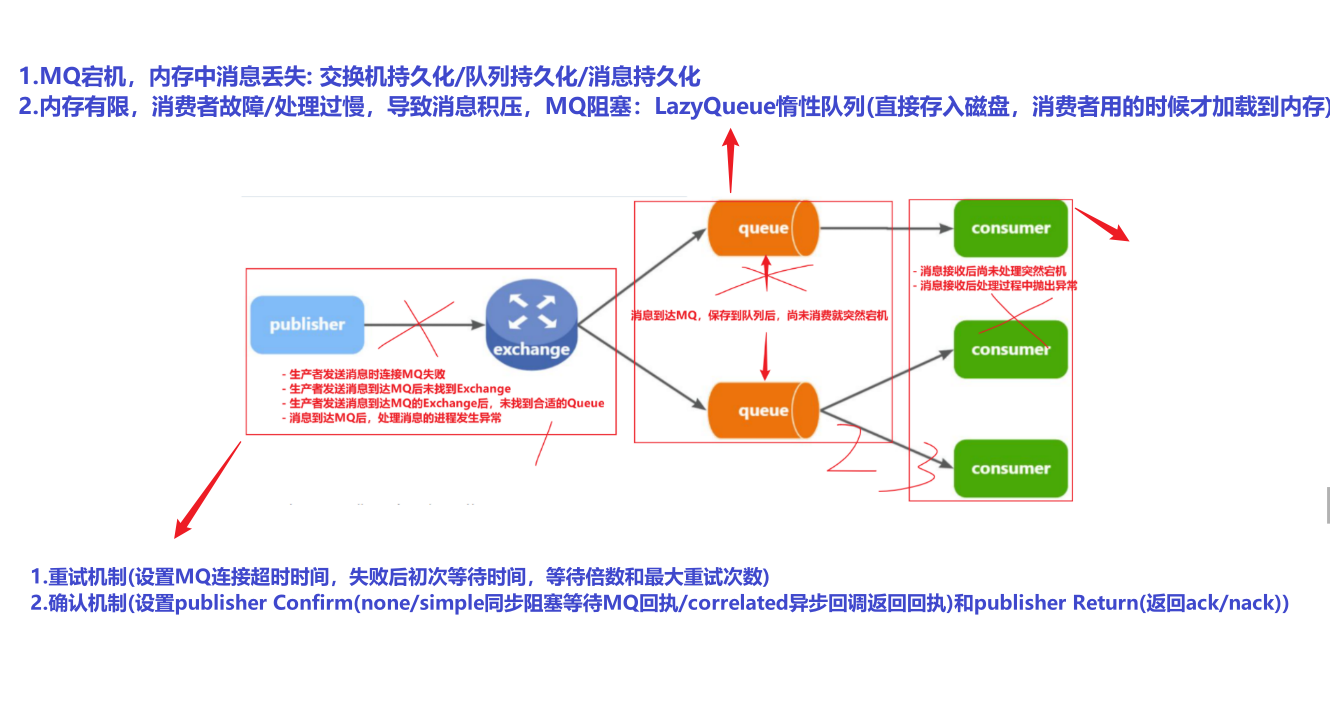
异步结构可能会在发送者,MQ,消费者三个地方出现问题!!!因此要考虑这三个位置的可靠性和兜底方案(延迟消息)
消息从发送者发送消息,到消费者处理消息,需要经过的流程是这样的:
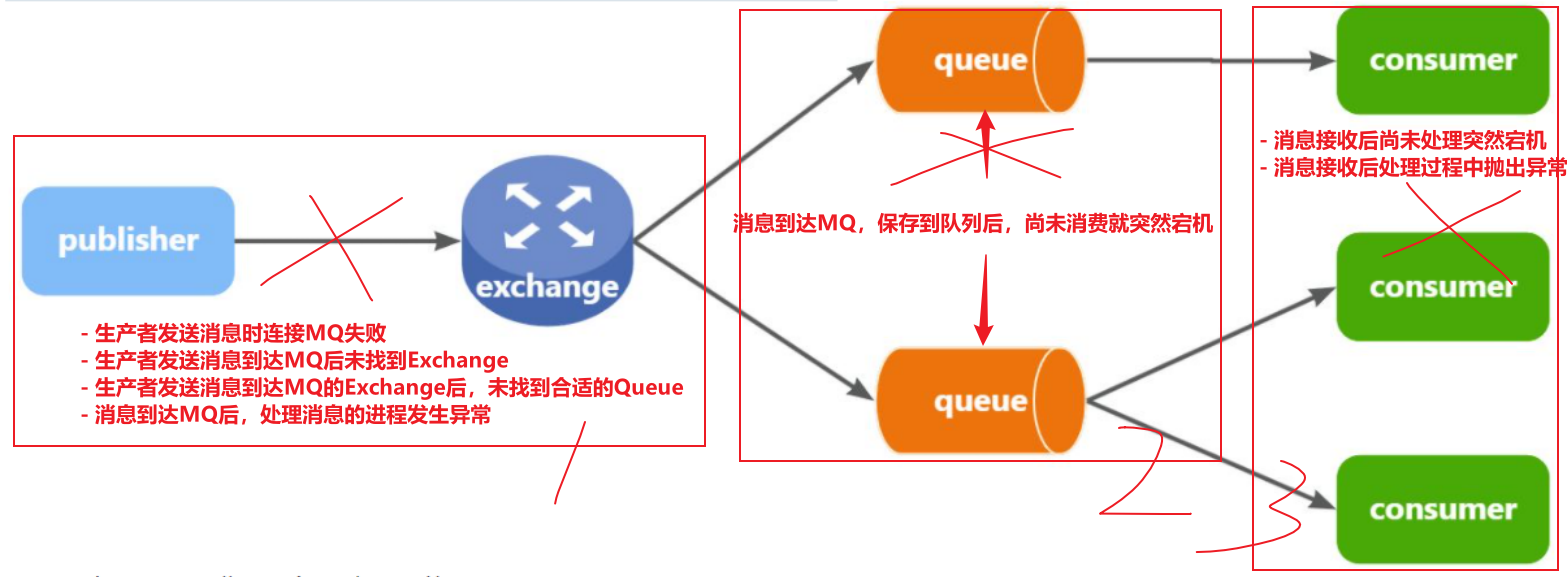
消息从生产者到消费者的每一步都可能导致消息丢失:
- 发送消息时丢失:
- 生产者发送消息时连接MQ失败
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue - 消息到达MQ后,处理消息的进程发生异常
- MQ导致消息丢失:
- 消息到达MQ,保存到队列后,尚未消费就突然宕机
- 消费者处理消息时:
- 消息接收后尚未处理突然宕机
- 消息接收后处理过程中抛出异常
综上,我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手:
确保生产者一定把消息发送到MQ —> ==生产者的可靠性(生产者重试机制,生产者确认机制)==
确保MQ不会将消息弄丢 —> ==MQ的可靠性(数据持久化,lazy queue)==
确保消费者一定要处理消息 —> ==消费者的可靠性(消费者确认机制,失败重传机制,失败处理策略,业务幂等性)==
==总汇总(复习图)==
8.可靠性——-发送者
8.1 生产者重试机制(建议禁用)
生产者发送消息时,出现网络故障,导致与MQ连接中断 ———-> SpringAMQP提供的消息发送时的==重试机制==
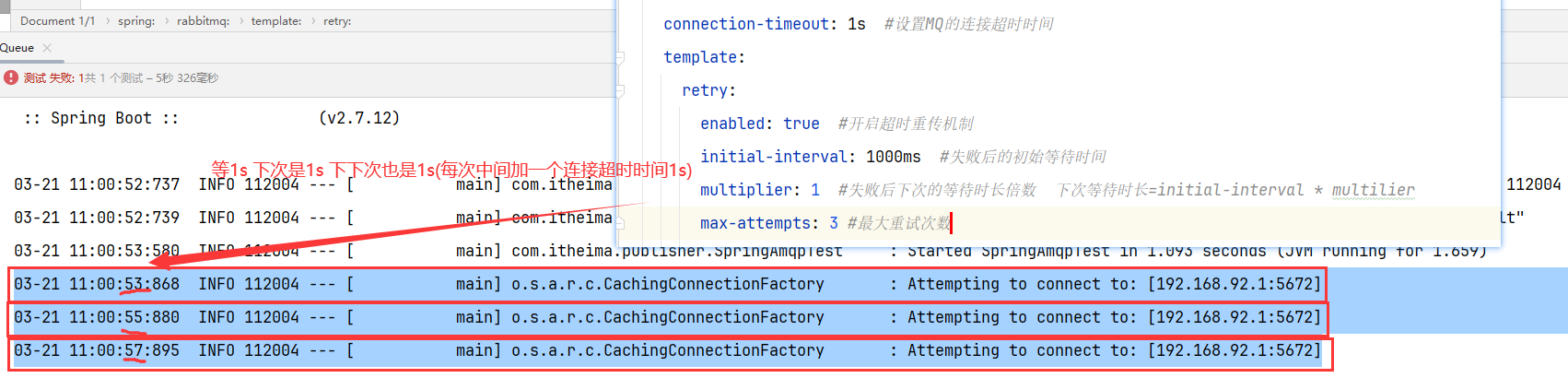
注意:
当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是==阻塞式重试==(也就是说多次重试等待的过程中,当前线程是被阻塞的)
如果对业务性能有要求的,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
8.2 生产者确认机制(默认不开启)
一般情况下,只要生产者与MQ之间的网络连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
- MQ内部处理消息的进程发生了异常
- 生产者发送消息到达MQ后未找到交换机
- 生产者发送消息到达MQ的交换机之后,未找到合适的队列,因此无法路由
针对上述三种情况,RabbitMQ提供了==生产者消息确认机制==,包括了Publisher Confirm和Publisher Return两种方式。
在开启确认机制的情况下,当生产者发送消息给MQ之后,MQ会根据消息处理的情况返回不同的回执:
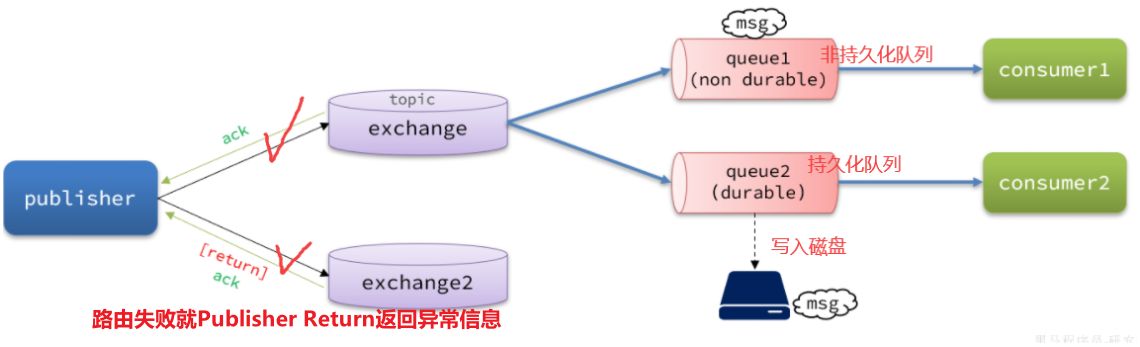
总结如下:
- 1.只要消息投递到MQ,就返回ACK,告知投递成功(基本上这三种ack我们可以考虑不处理,直接只关注nack的情况)
1.1 当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
1.2 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
1.3 持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
- 2.其它情况都会返回NACK,告知投递失败
【其中ack(投递成功)和nack(投递失败)都属于Publisher Confirm机制;return是属于Publisher Return机制】
【(默认)两种机制都是关闭状态,需要通过配置文件来开启,因为是需要额外的网络和系统资源开销】
【一定要使用的话,无需开启Publisher-Return机制(一般路由失败是自己业务问题)】
8.2.1 配置文件添加

这里publisher-confirm-type有三种模式可选:
none:关闭confirm机制simple:同步阻塞等待MQ的回执correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
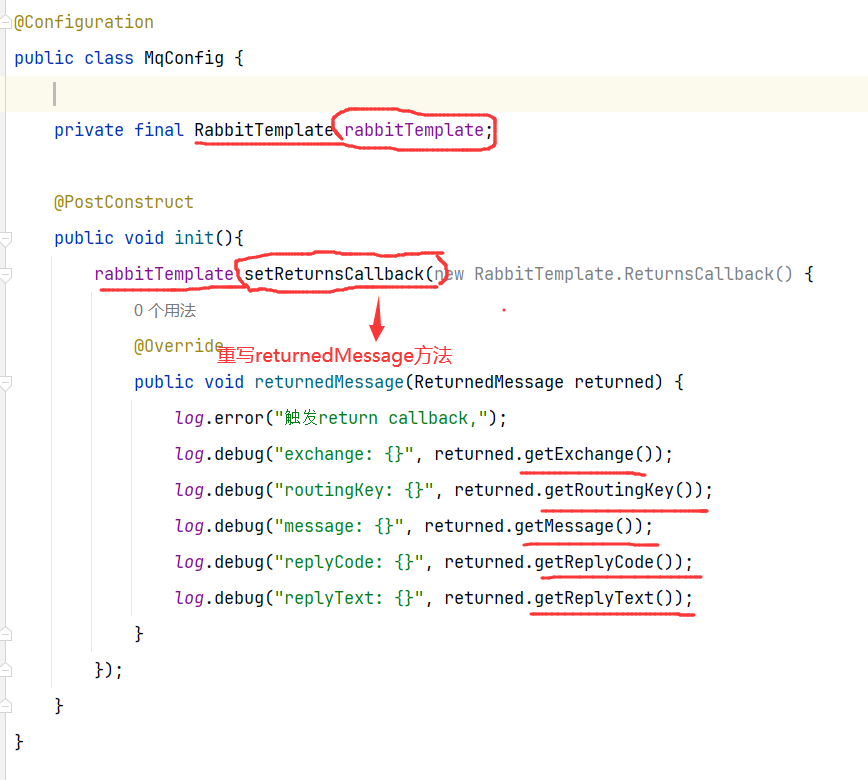
8.2.2 定义ReturnCallback(返回信息)
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置
我们在publisher模块定义一个配置类:rabbitTemplate对象调用setReturnsCallback()方法,方法参数是一个匿名内部类(重写returnedMessage方法)
8.2.3 定义ConfirmCallback(确定ack/nack)
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发送消息时定义。
就是在发送消息时,调用RabbitTemplate.convertAndSend()时多传递一个参数:

这里的CorrelationData中包含两个核心的东西:
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
将来MQ的回执就会通过这个Future来返回,我们可以提前给CorrelationData中的Future添加回调函数来处理消息回执:
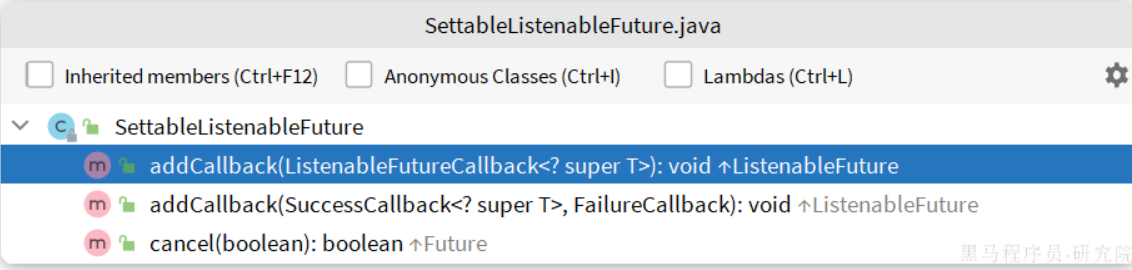
发送者位置发送消息(新增字段为了获取MQ给的结果):
注意:
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
- 路由失败:一般是因为RoutingKey错误导致,往往是编程导致
- 交换机名称错误:同样是编程错误导致
- MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以
9.可靠性——–RabbitMQ
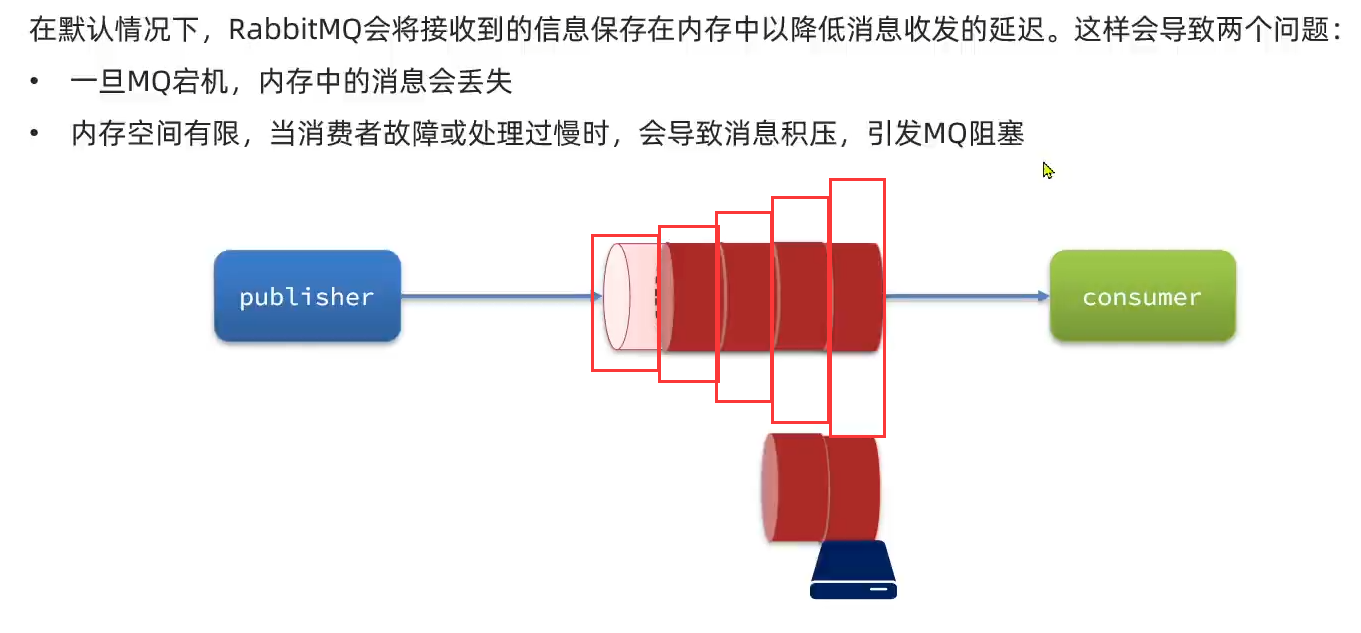
在默认情况下,RabbitMQ会将接收到的信息保存在==内存==中(降低消息收发延迟)。这样会导致两个问题:
- 一旦RabbitMQ宕机,内存中的消息会丢失 –> ==交换机持久化,队列持久化,消息持久化==
- 内存空间有限,当消费者故障或者处理过慢,会导致消息积压,引发RabbitMQ阻塞 –> ==Lazy Queue==
9.1 三种持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
- 1.交换机持久化
- 2.队列持久化
- 3.消息持久化
其中以控制台界面为例:
- 1.交换机持久化:
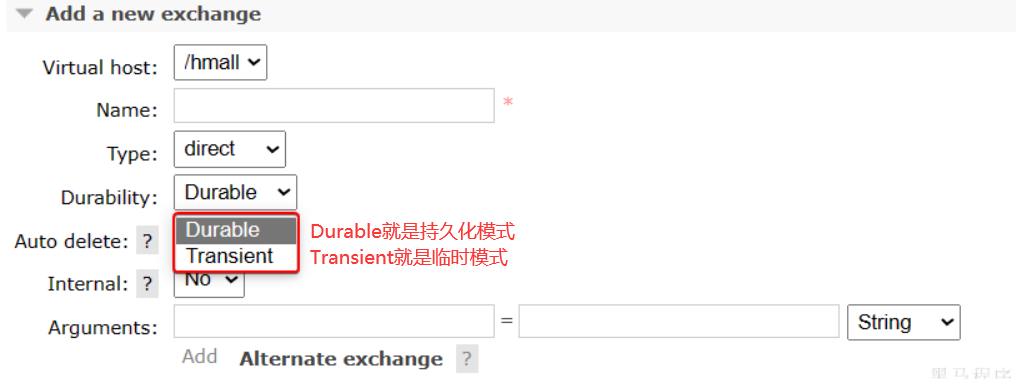
- 2.队列持久化:
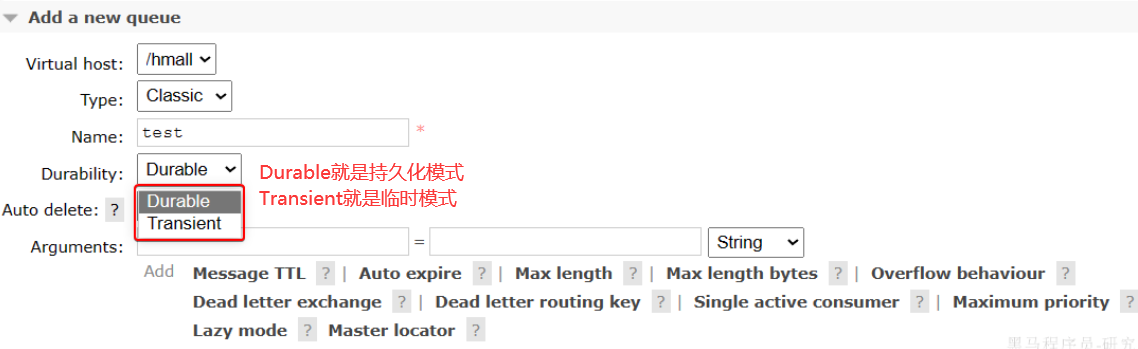
- 3.消息持久化:
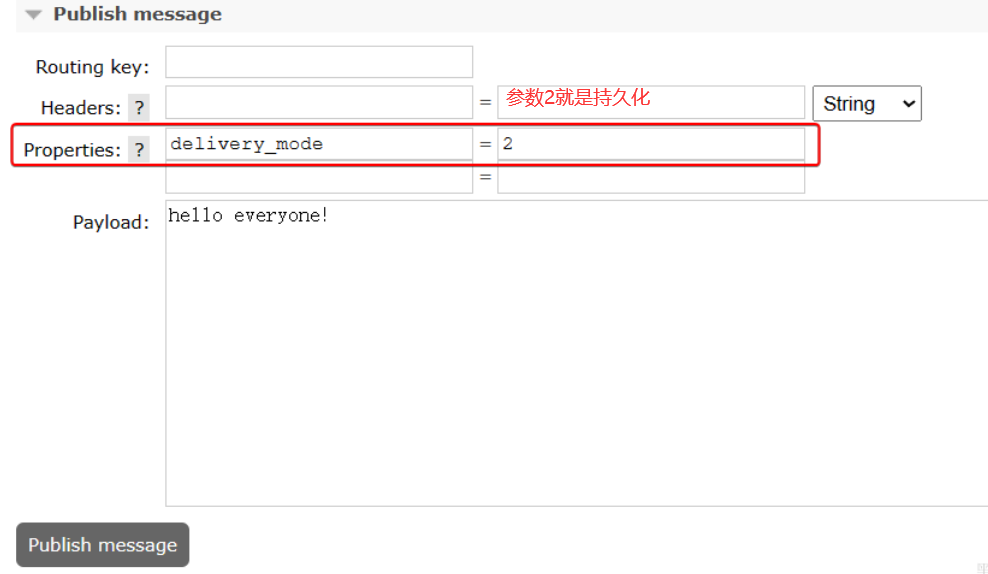
说明:
在开启持久化机制以后,如果同时还开启了生产者确认机制,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性
不过出于性能考虑,为了减少IO次数,发送到RabbitMQ的消息是每隔一段时间(100ms左右)批量持久化,这会导致后续的ACK回执有一定的延迟,因此建议生产者确认全部采用异步方式
9.2 LazyQueue惰性队列
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
- 消费者宕机或出现网络故障(后续崩了)
- 消息发送量激增,超过了消费者处理速度(前面发的太快了,后面接不住)
- 消费者处理业务发生阻塞(后续阻塞)
一旦出现消息堆积问题,RabbitMQ的内存占用会越来越高 —> 触发内存预警上限,此时RabbitMQ会将内存消息 –刷–> 磁盘,这个行为叫==PageOut==,PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞
为了解决这个问题,从3.6.0版本开始,增加了Lazy Queues(惰性队列)。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存 (直接存磁盘,就不会刷盘造成阻塞队列进程)
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载,需要了我才加载内存)
- 支持数百万条的消息存储
而在3.12版本之后,LazyQueue已经成为了所有队列的默认格式。因此官方推荐升级RabbitMQ为3.12版本/所有队列都设置为LazyQueue模式
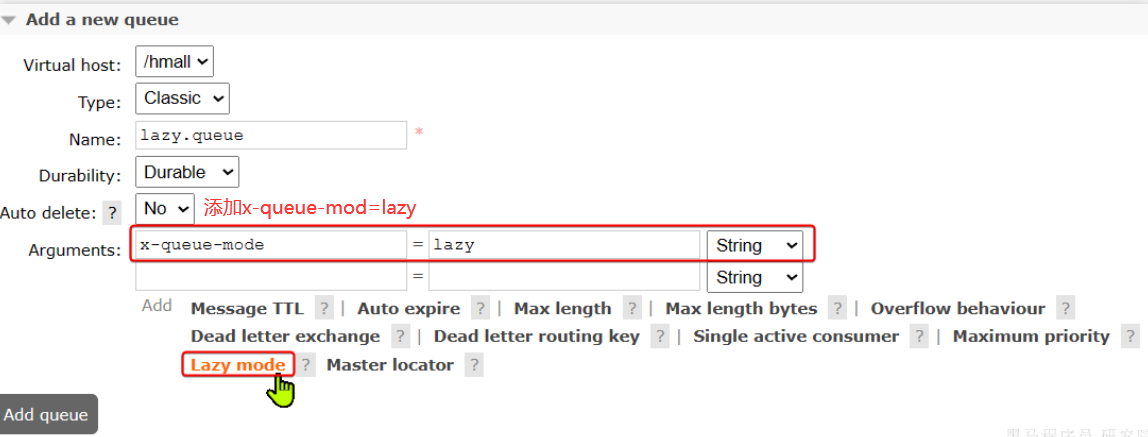
9.2.1方式一— 控制台配置Lazy模式
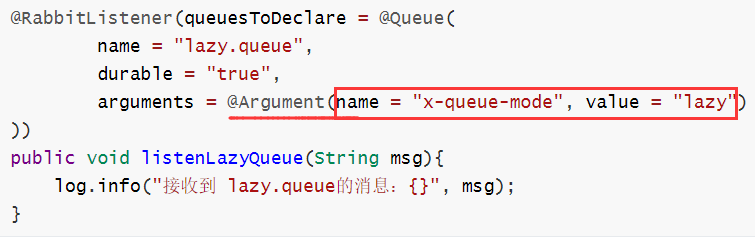
9.2.2 方式二—代码配置Lazy模式
基本原理都是设置属性:==x-queue-mode=lazy==
- 基于@Bean注解(配置类)

QueueBuilder底层源码为:

- 基于@RabbitListener注解(消费者子工程)
9.2.3 更新已有队列为Lazy模式
- 基于控制台:
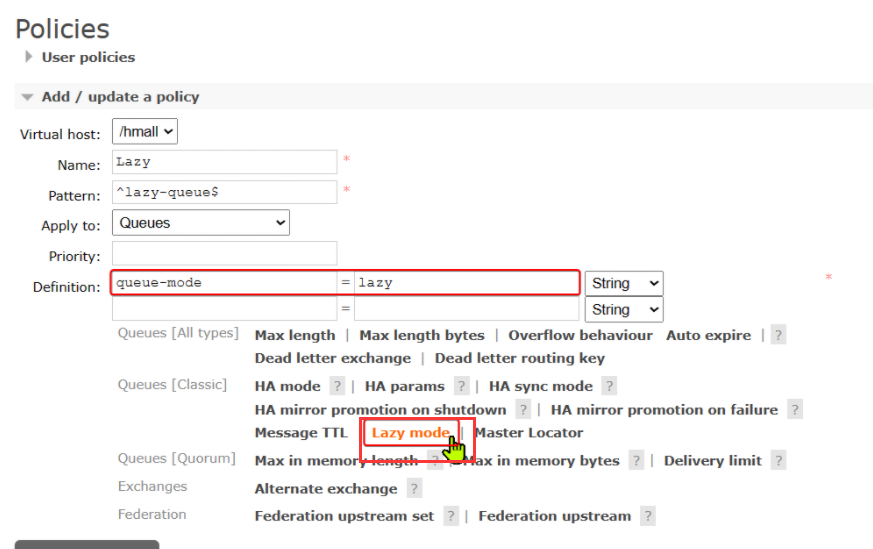
- 基于命令行:
可以基于命令行设置policy:
1 | rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues |
命令解读:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一个策略Lazy:策略名称,可以自定义"^lazy-queue$":用正则表达式匹配队列的名字'{"queue-mode":"lazy"}':设置队列模式为lazy模式--apply-to queues:策略的作用对象,是所有的队列
10.可靠性——-消费者
10.1 消费者确认机制
为了确定消费者是否成功处理消息,RabbitMQ提供了消费者确认机制(Consumer Acknowledgement)
就是说当消费者处理消息结束后,应该向+RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。这时候回执有三种可选值:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ再次投递消息
- reject(很少使用):消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般第三种reject方式比较少,除非是消息格式问题(那就是开发问题),因此大多数情况下我们需要将消息处理的代码通过try-catch机制捕获,消息处理成功就返回ack,处理失败就返回nack。
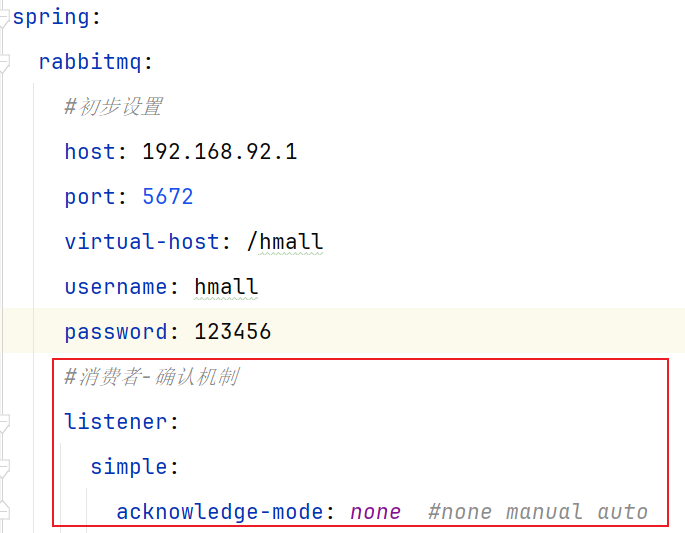
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并且允许我们通过配置文件(yml)设置ACK处理方式,有三种模式:
- none:不处理。就是将消息投递给消费者后立刻回调ack,消息会立刻从MQ中删除。【非常不安全,不建议使用】
- manual:手动模式。需要自己在业务代码中调用api,回调发送ack/reject【存在业务入侵,但更灵活】
- auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强。
- 当业务正常执行时则自动返回ack(RabbitMQ删除消息)
- 当业务出现异常时根据异常判断返回不同的结果
- 如果是业务异常,自动返回nack(RabbitMQ再次投递消息) —> 可能会出现不停重复投递(导致消息堆积)
- 如果是消息处理/校验异常,自动返回reject(RabbitMQ删除消息)
配置消费者的xml文件可以修改SpringAMQP的ack处理方式:
但是,如果auto模式下是业务异常回执给nack,那就会不断从MQ中投递消息,会导致MQ消息处理飙升带来不必要的压力(这种极端情况就是消费者一直无法执行成功,发生概率很低,但是不怕万一就怕一万)
10.2 消费者失败重试机制
因为10.1如果是收到nack回执,那么就会不断从MQ中投递消息,可能会导致消息堆积,导致mq的消息处理飙升,带来不必要的压力
我们可以利用Spring的retry机制—>==当消费者异常就利用本地重试(×无限制重试)==
配置消费者的xml文件可以修改SpringAMQP的本地重试机制:
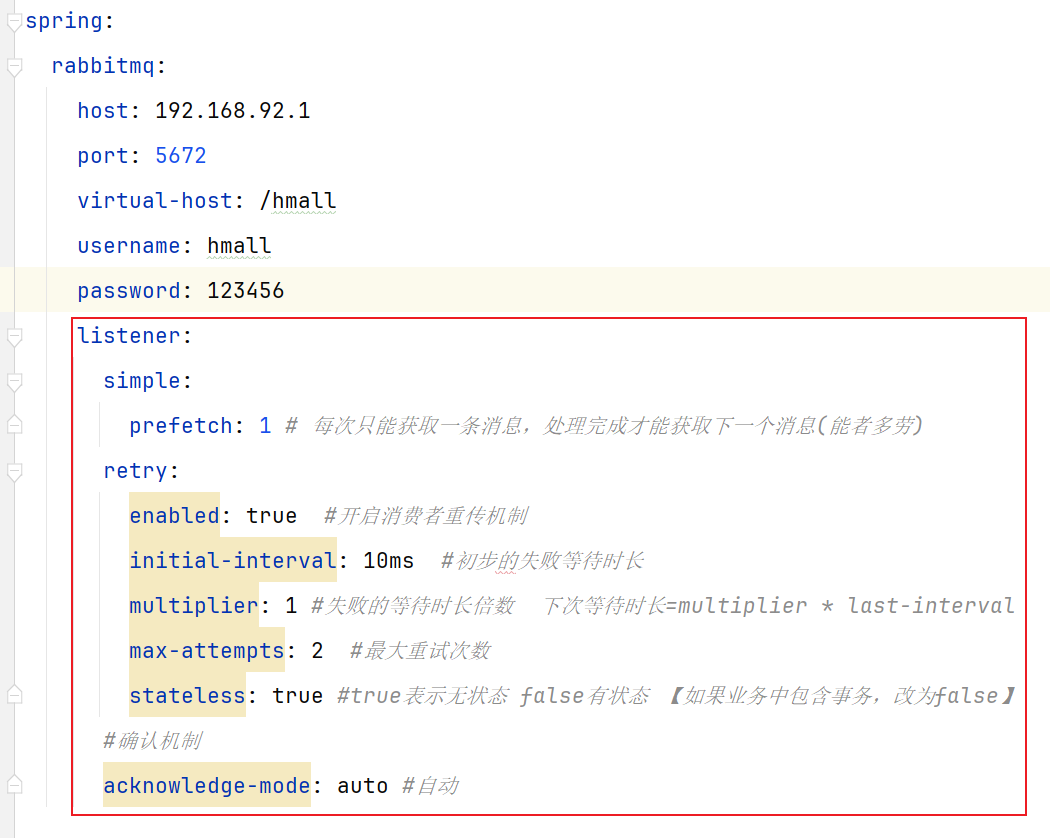
在开启重试机制后,重试次数耗尽之后,如果消息依然失效,则会默认直接丢弃消息!!!!!!!!!!!!!
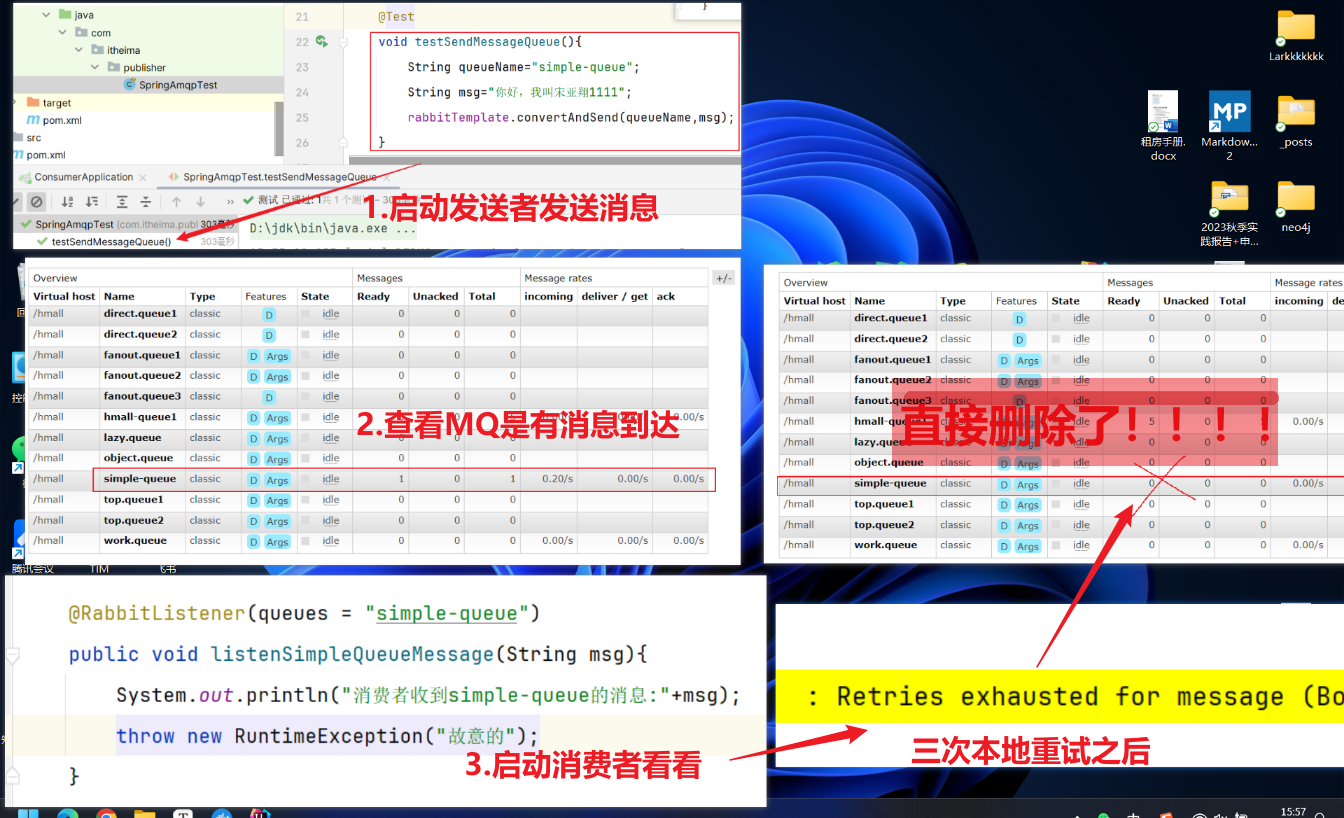
可以发现:
消费者在失败后消息并没有重新回到MQ无限重新投递,而是重试3次
本地重试3次之后,抛出了AmqpRejectAndDontRequeueException异常(说明直接reject丢弃了)
10.3 失败处理策略[解决10.2重试后reject丢弃消息情况]
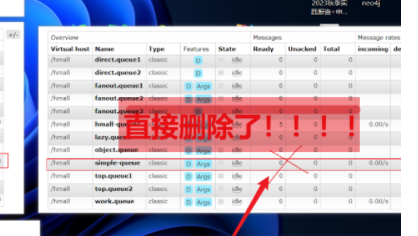
因为10.2本地重试之后如果消息失效就直接丢弃,因此我们可以考虑==加上自定义重试次数之后的策略==。只需要==MessageRecoverer接口==来处理,它包含了三种不同的实现:
- RejectAndDontRequeueRecoverer(默认):重试耗尽后,直接reject,丢弃消息
- *ImmediateRequeueMessageRecoverer *:重试耗尽后,返回nack,消息重新入队 【减缓重试的速度,就还是要重新投递到前一步】
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机(最后人工校验/特殊校验)
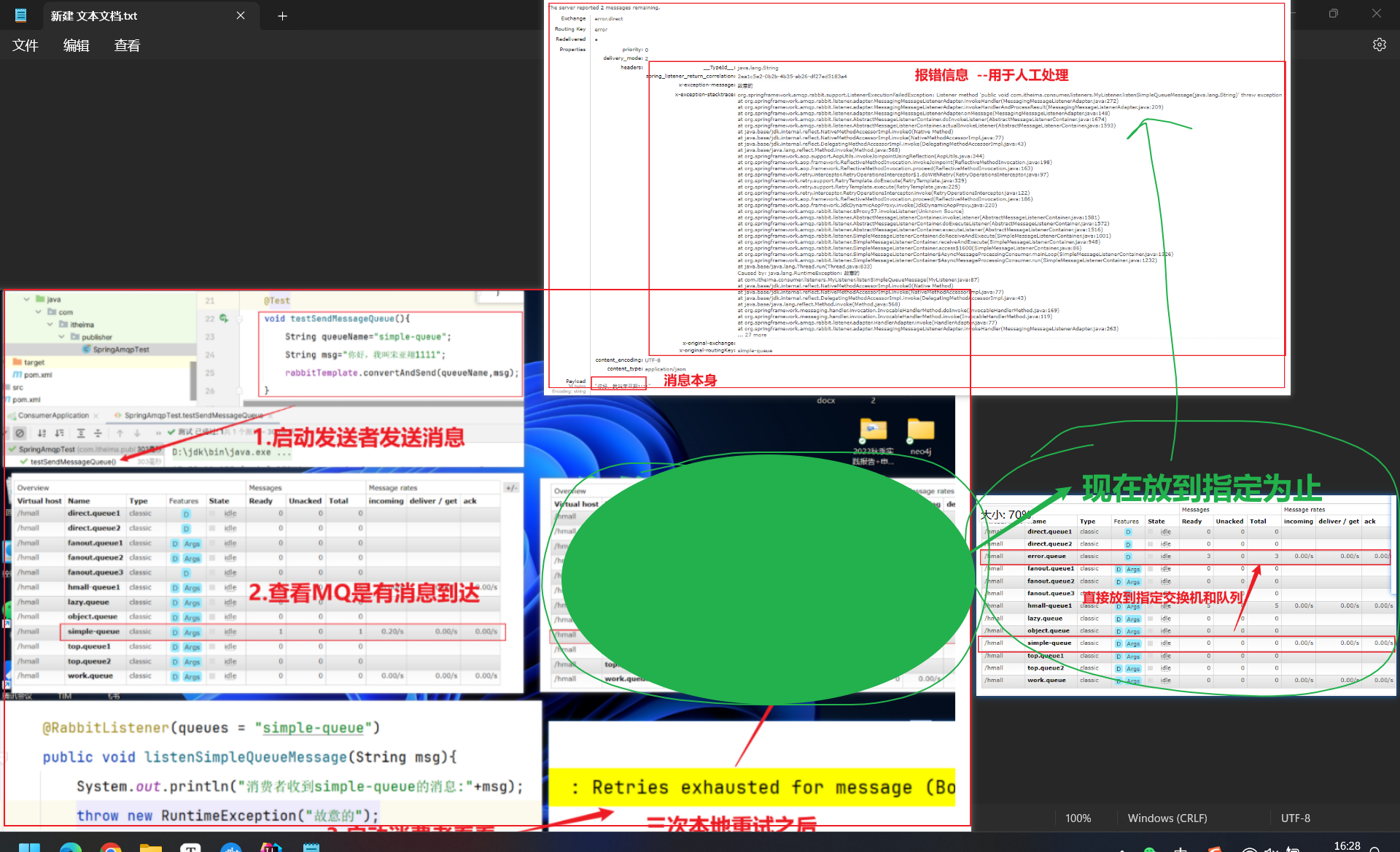
10.3.1 第三种策略为例
①定义接受失败消息的交换机,队列和绑定关系
②定义RepublishMessageRecoverer:
1 | package com.itheima.consumer.config; |
③在10.2基础上会将消息直接传递到对应交换机上最后进行人工处理
总结:
自定义的三种方式,第一种默认直接拒绝(不好),第二种相当于往前重试了一个环节(减缓了重试速度,但是也不好),第三种相当于交给专门队列和交换机,最后交给人工处理(也不是很好)
10.4 业务幂等性[解决10.2多次重新投递消息情况]
幂等性
用函数表达式来描述是这样的:
f(x) = f(f(x)),例如求绝对值函数。在程序开发中,则是指==同一个业务,执行一次或多次对业务状态的影响是一致的==。例如:
- 根据id删除数据
- 查询数据
- 新增数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
- 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况
- 退款业务。重复退款对商家而言会有经济损失。
所以,我们要尽可能避免业务被重复执行。然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
- 页面卡顿时频繁刷新导致表单重复提交
- 服务间调用的重试
- MQ消息的重复投递
我们在用户支付成功后会发送MQ消息到交易服务,修改订单状态为已支付,就可能出现消息回
复投递的情况。如果消费者不做判断,很有可能导致消息被消费多次,出现业务故障。
举例:
- 假如用户刚刚支付完成,并且投递消息到交易服务,交易服务更改订单为已支付状态。
- 由于某种原因,例如网络故障导致生产者没有得到确认,隔了一段时间后重新投递给交易服务。
- 但是,在新投递的消息被消费之前,用户选择了退款,将订单状态改为了已退款状态。
- 退款完成后,新投递的消息才被消费,那么订单状态会被再次改为已支付。业务异常。
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
- 唯一消息ID
- 业务状态判断
10.4.1 唯一消息ID(存在业务侵入)
这个思路非常简单:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
- 1.SpringAMQP的MeesageConverter自带MessageID的功能
1 | //以Jackson的消息转换器为例: |
我们在生产者位置添加:
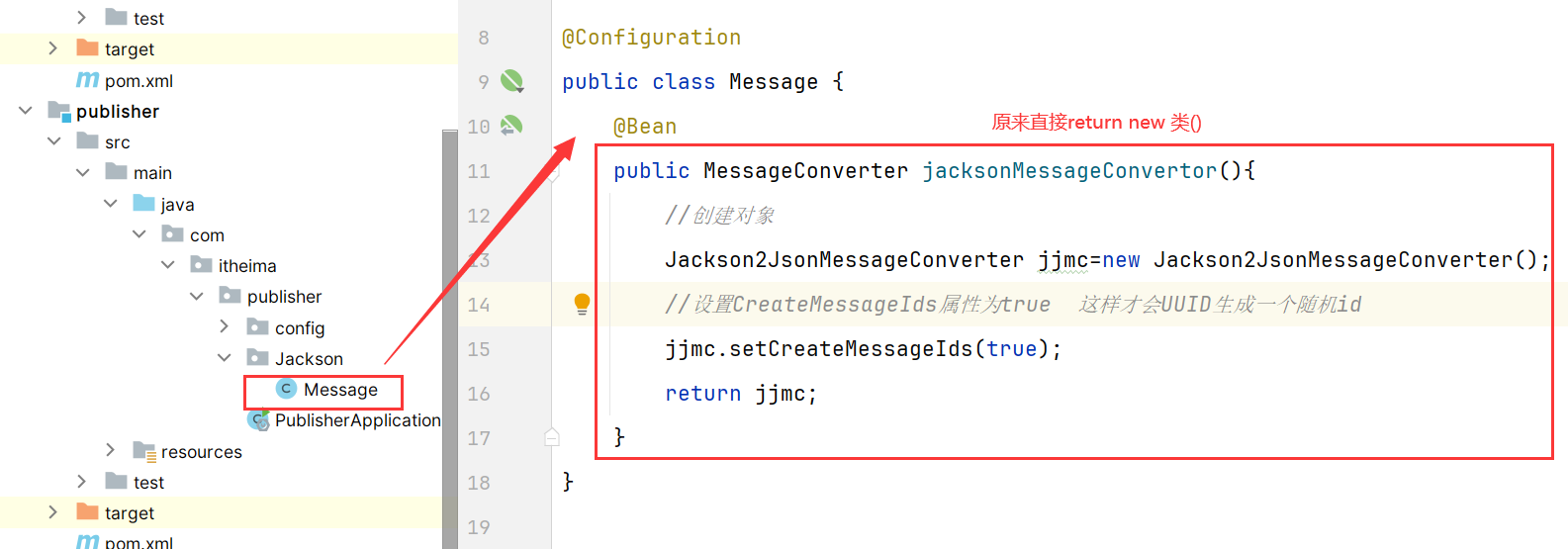
打开源码可以看到,生成随机id的底层源码:

最终发送一条消息如下:

2.使用Redis缓存(tk使用)
在调用接口的时候+调用生成随机数的接口生成id(全局唯一)两者合二为一,然后判断是否第一次调用,第一次调用的话业务处理完成之后将{key:id,value:操作结果}+过期时间存入redis数据库;之后每次进行的时候判断是否key存在,存在的话说明重复提交返回错误
10.4.2 业务状态判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。
相比较而言,消息ID的方案需要改造原有的数据库(会存在业务侵入问题),所以我更推荐使用业务判断的方案。
以支付修改订单的业务为例,我们需要修改OrderServiceImpl中的markOrderPaySuccess方法:处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理
1 | //在原有基础上添加判断订单状态 ---如果不符合直接消息reject了!!!!!!! |
根据上述代码逻辑可以完成幂等判断需求,但是由于判断和更新是两步动作,可能会在极小概率下可能存在线程安全问题 –> 可以考虑使用==乐观锁(CAS机制)==
1 | //可以将上述三步直接合并为一条sql语句 |
注意看,上述代码等同于这样的SQL语句:
1 | UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1 |
我们在where条件中除了判断id以外,还加上了status必须为1的条件。如果条件不符(说明订单已支付),则SQL匹配不到数据,根本不会执行。
10.5 兜底方案[消费者定时主动询问]
上述机制可能增加了消息的可靠性,但是也不好说能保证消息100%的可靠。
其实思想很简单:既然MQ通知不一定发送到交易服务(消费者),那么交易服务(消费者)就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致
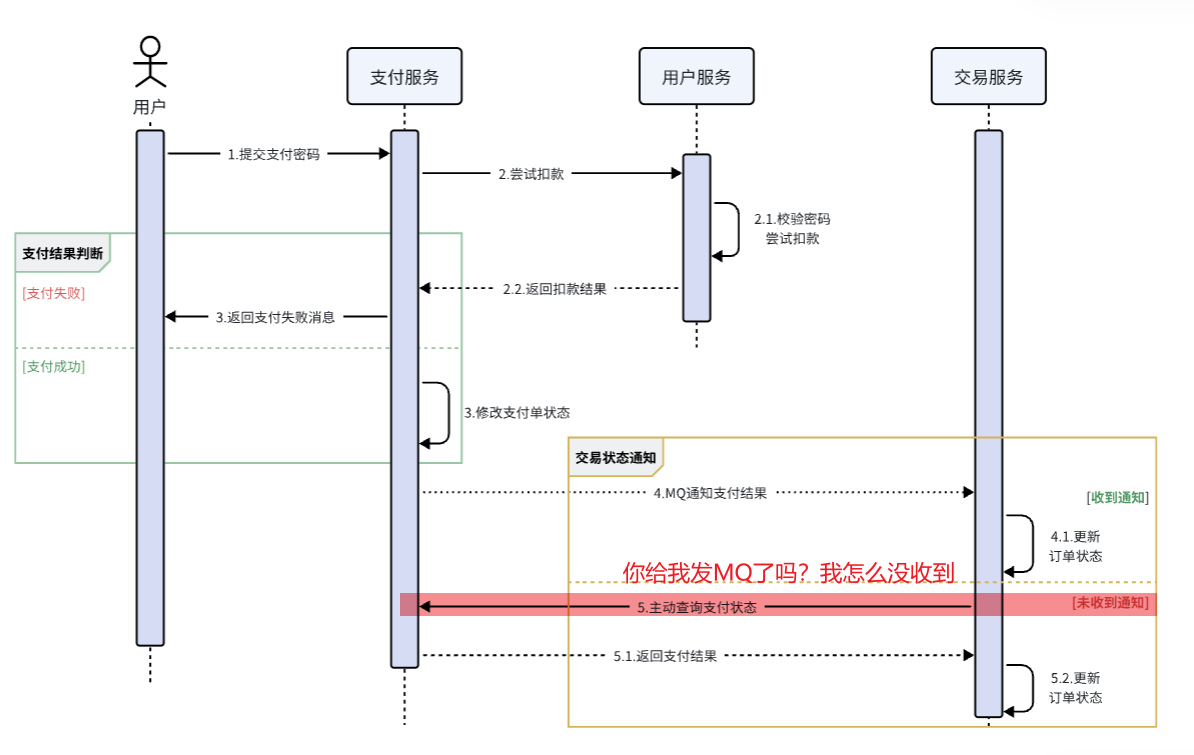
图中黄色线圈起来的部分就是MQ通知失败后的兜底处理方案,由交易服务自己主动去查询支付状态。
什么时候去查询是无法确定的,因此我们通常采用的措施是利用定时任务(例如:SpringTask框架)定期查询。
==可靠性总结图==
综上,支付服务与交易服务之间的订单状态一致性是如何保证的?
- 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递的可靠性
- 最后,我们还在交易服务设置了定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
==高级进阶 –延迟消息(两种方式)==
在电商的支付业务中,对于一些库存有限的商品,为了更好的用户体验,通常都会在用户下单时立刻扣减商品库存。例如电影院购票、高铁购票,下单后就会锁定座位资源,其他人无法重复购买。
但是这样就存在一个问题,假如用户下单后一直不付款,就会一直占有库存资源,导致其他客户无法正常交易,最终导致商户利益受损!
因此,电商中通常的做法就是:对于超过一定时间未支付的订单,应该立刻取消订单并释放占用的库存。
例如,订单支付超时时间为30分钟,则我们应该在用户下单后的第30分钟检查订单支付状态,如果发现未支付,应该立刻取消订单,释放库存。
但问题来了:如何才能准确的实现在下单后第30分钟去检查支付状态呢?
像这种在一段时间以后才执行的任务,我们称之为延迟任务,而要实现延迟任务,最简单的方案就是利用MQ的延迟消息了。
11.延迟消息
延迟消息:生产者发送消息时指定一个时间,消费者不会立刻收到消息,而在指定时间之后才收到消息
延迟任务:设置一定时间之后才执行的任务,(最简单的方案就是利用MQ的延迟消息)
在RabbitMQ中实现延迟消息也有两种方案:
- 死信交换机+TTL
- 延迟消息插件
11.1 死信交换机和延迟消息
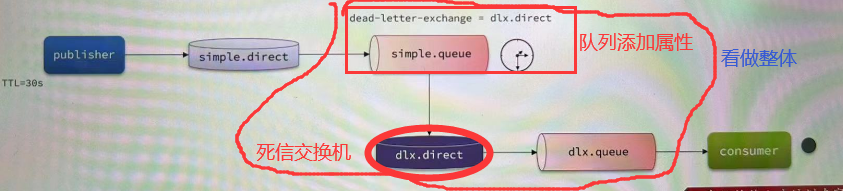
11.1.1 死信交换机
死信(dead letter)?
- 消费者使用
basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false - 消息是一个过期消息,超时无人消费
- 要投递的队列消息满了,无法投递
如果队列设置属性dead-letter-exchange指定交换机 –>该队列的死信就会投递到这个交换机。
这个交换机就叫做死信交换机(Dead letter Exchange,简称DLX)
死信交换机的作用?
收集那些因处理失败而被拒绝的消息
收集那些因队列满了而被拒绝的消息
收集因TTL(有效期)到期的消息
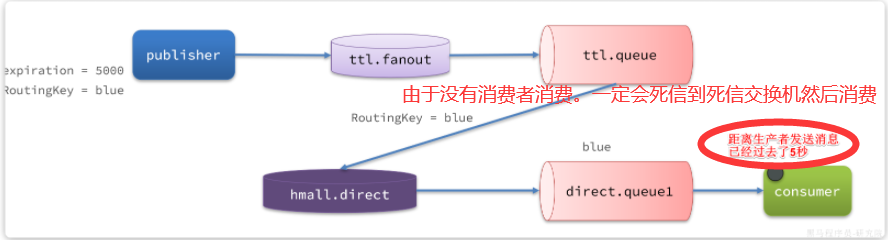
11.1.2 延迟消息
总结来说:宏观上看到就是内部做了一个延迟一样
进一步说:变相的让发送消息到消费多了5s
11.2 延迟消息插件(DelayExchange)
RabbitMQ官方提供一款插件,==原生支持延迟消息功能==。
插件原理就是设计了一种支持延迟消息功能的交换机,当消息投递到交换机后可以存放一定时间,到期后再投递到队列。
11.2.1 下载
插件下载地址:
GitHub - rabbitmq/rabbitmq-delayed-message-exchange: Delayed Messaging for RabbitMQ
由于我们安装的MQ是3.8版本,因此这里下载3.8.17版本:
11.2.2 安装
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷
1 | docker volume inspect mq-plugins |
结果如下:
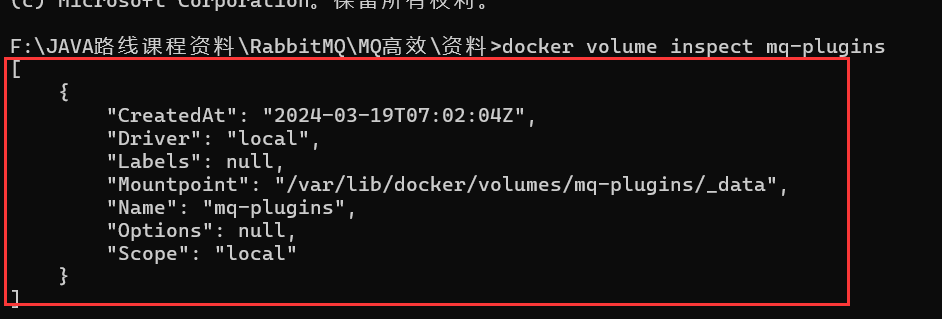
插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。
接下来执行命令,安装插件:
1 | docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange |
结果如下:
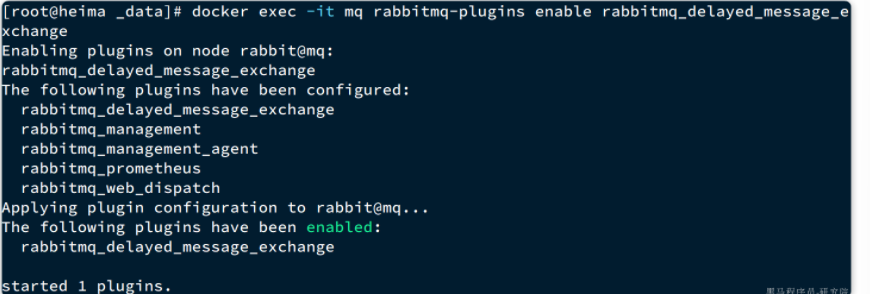
11.2.3 声明延迟交换机
- 方式一:基于注解方式

方式二:基于@Bean方式
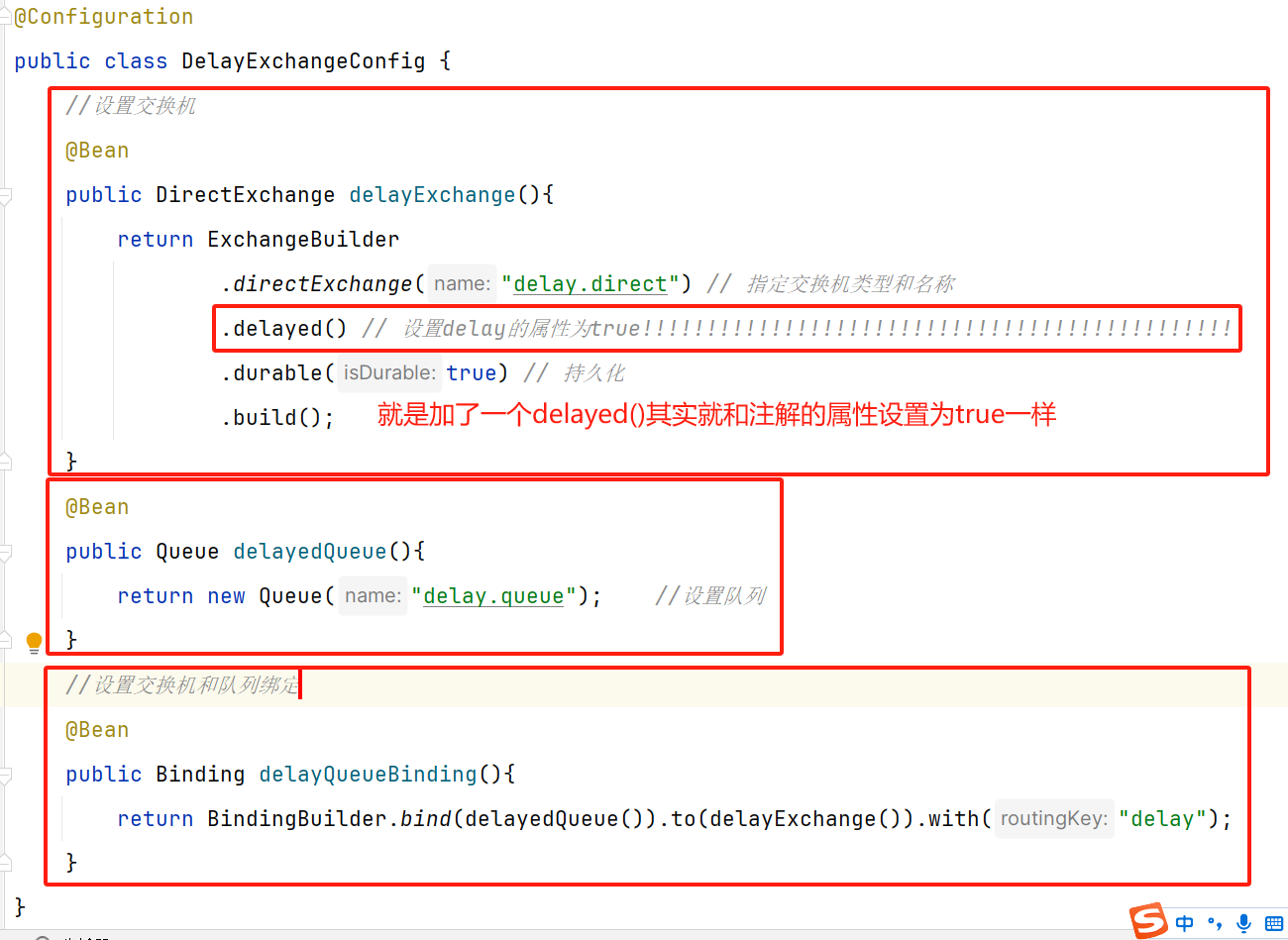
11.2.4 发送延迟消息
发送消息时:只需要通过设定x-delay属性设定延迟时间:

延迟消息插件内部会维护一个本地数据库表,同时使用Elang Timers功能实现计时。如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的CPU开销,同时延迟消息的时间会存在误差。
因此,不建议设置延迟时间过长的延迟消息。
12. 实际操作(日后补充)
==可以参考<RabbitMQ-黑马商城为例>这篇文章,有详细的操作介绍和步骤==


