1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import * # 引入model.py里的模型
from torch import nn
from torch.utils.data import DataLoader
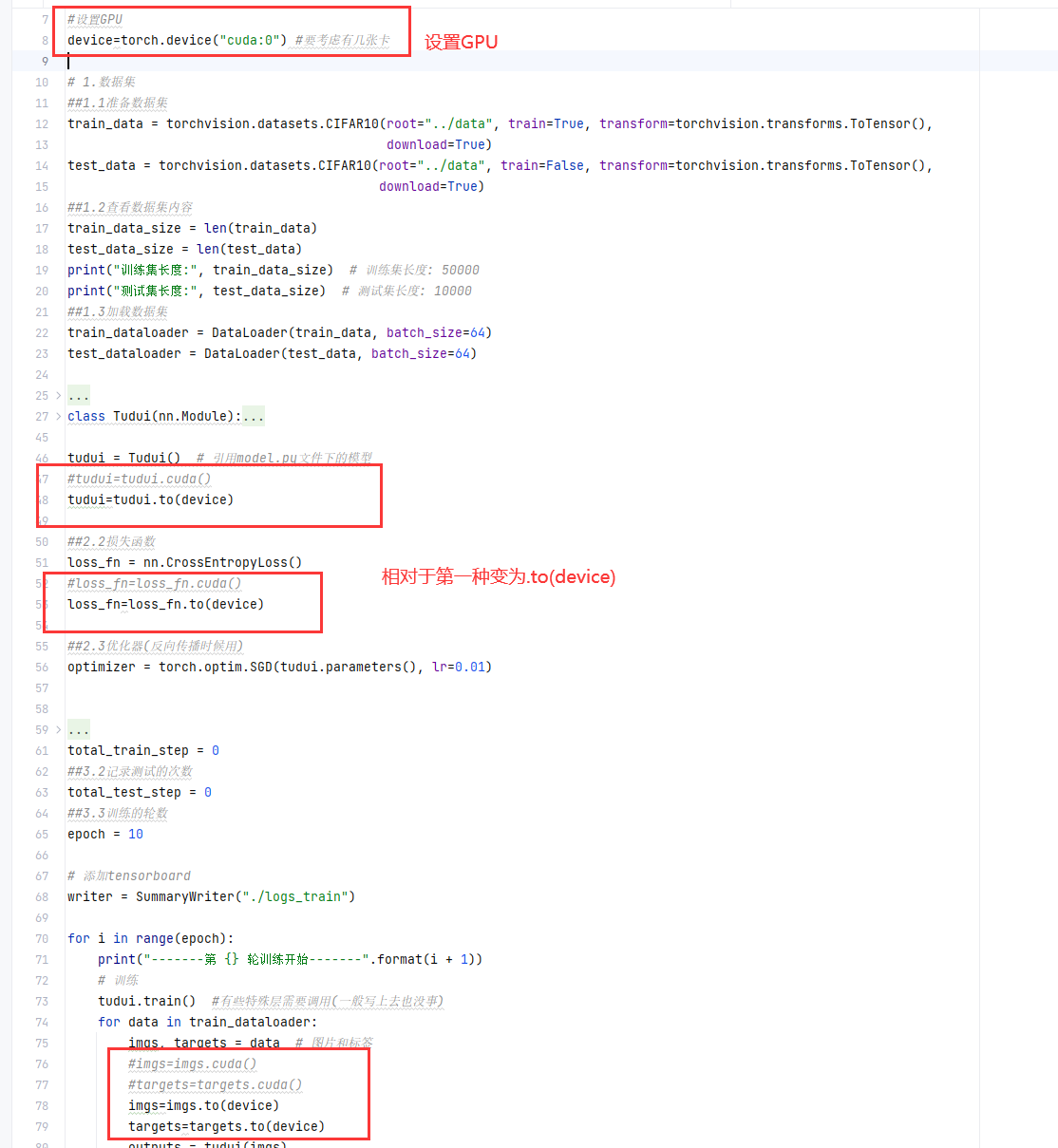
#设置GPU
device=torch.device("cuda:0") #要考虑有几张卡
# 1.数据集
##1.1准备数据集
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
##1.2查看数据集内容
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练集长度:", train_data_size) # 训练集长度: 50000
print("测试集长度:", test_data_size) # 测试集长度: 10000
##1.3加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 2.创建网络模型
##2.1搭建神经网络
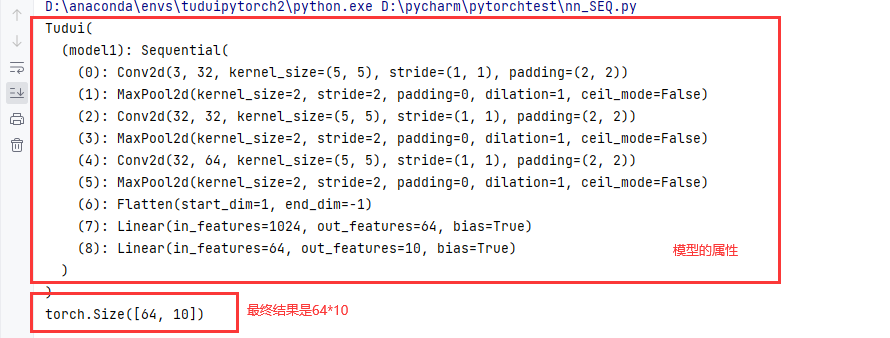
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
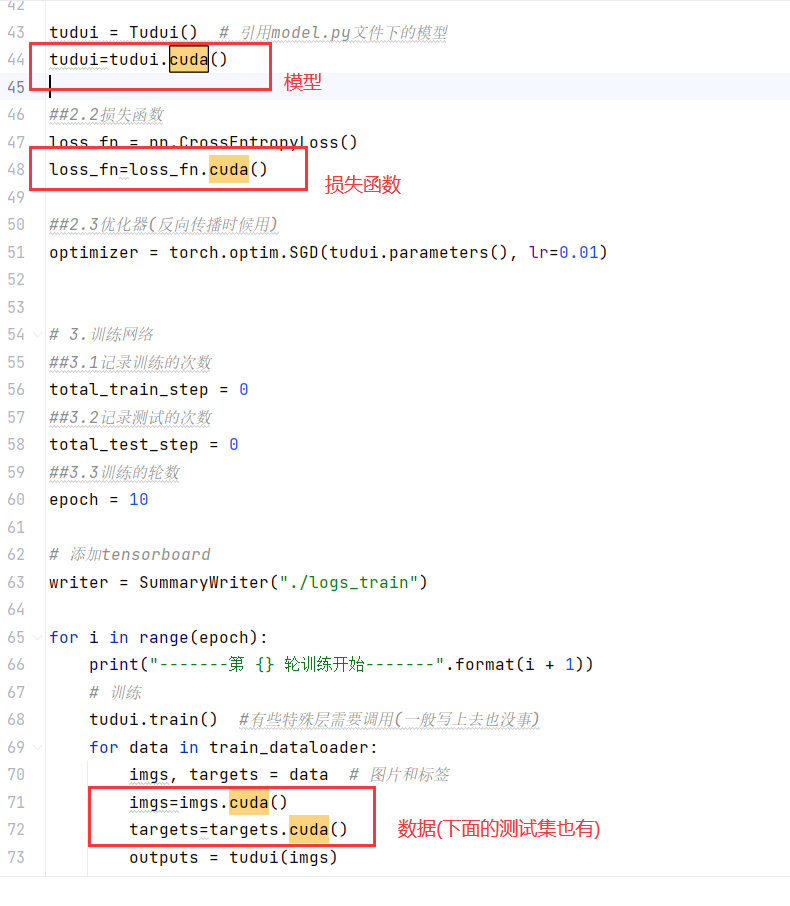
tudui = Tudui() # 引用model.py文件下的模型
#tudui=tudui.cuda()
tudui=tudui.to(device)
##2.2损失函数
loss_fn = nn.CrossEntropyLoss()
#loss_fn=loss_fn.cuda()
loss_fn=loss_fn.to(device)
##2.3优化器(反向传播时候用)
optimizer = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 3.训练网络
##3.1记录训练的次数
total_train_step = 0
##3.2记录测试的次数
total_test_step = 0
##3.3训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练
tudui.train() #有些特殊层需要调用(一般写上去也没事)
for data in train_dataloader:
imgs, targets = data # 图片和标签
#imgs=imgs.cuda()
#targets=targets.cuda()
imgs=imgs.to(device)
targets=targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
# 优化器
optimizer.zero_grad() # 每一轮梯度清0
loss.backward() # 反向传播 计算出要优化的值
optimizer.step() # 优化器优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试
tudui.eval() #有些特殊层需要调用(一般写上去也没事)
total_test_loss = 0 #整体loss
total_accuracy = 0 #整体准确率
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data # 图片和标签
# imgs=imgs.cuda()
# targets=targets.cuda()
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
# 一部分数据的损失
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item() # 每次损失增加
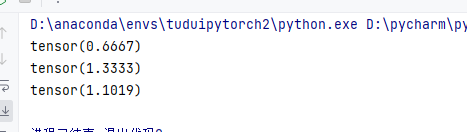
accuracy = (outputs.argmax(1) == targets).sum() #整体准确率 用argmax可以判断[False,True].sum()=1
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
|