Numpy基础(数组和矢量计算)
numpy功能
1 | 1.高性能科学计算和数据分析的基础包 |
多维数组对象(ndarray)
1 | 1.ndarray是一个通用的同构数据多维容器(所有元素必须是同类型的) |
创建ndarray
函数总结

1 | import numpy as np |
执行结果
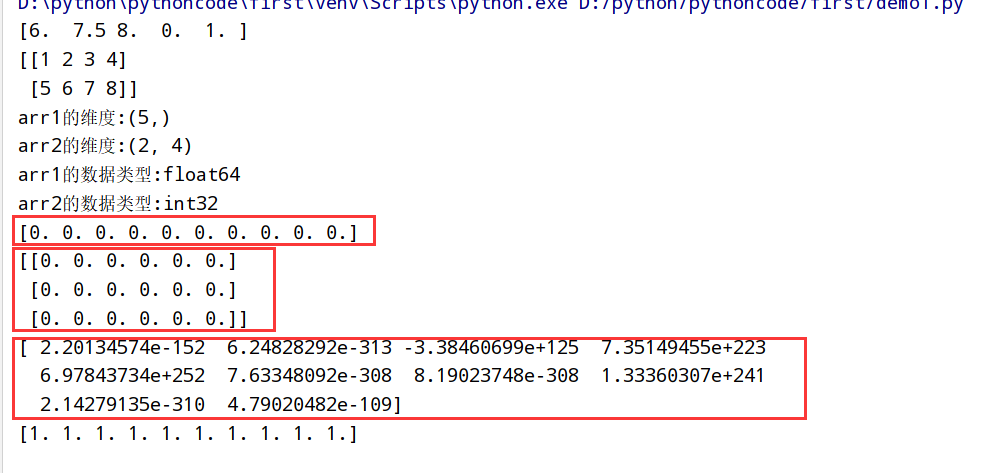
ndarray数据类型
数据类型总结
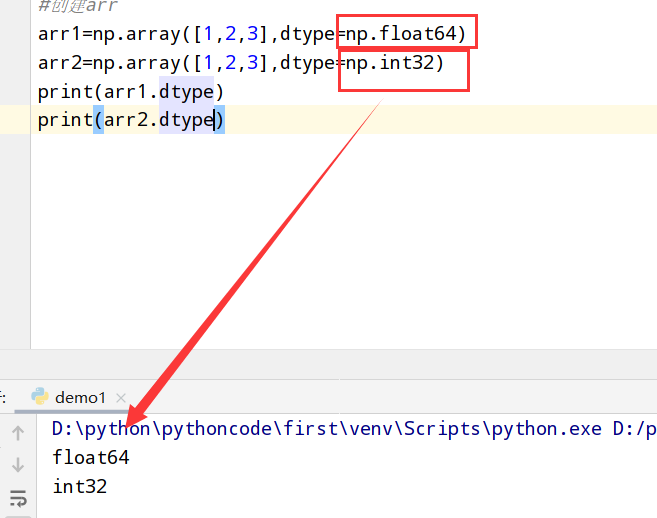
1 | import numpy as np |
执行结果
数组和标量之间的运算
1 | import numpy as np |
执行结果

基本的索引和切片
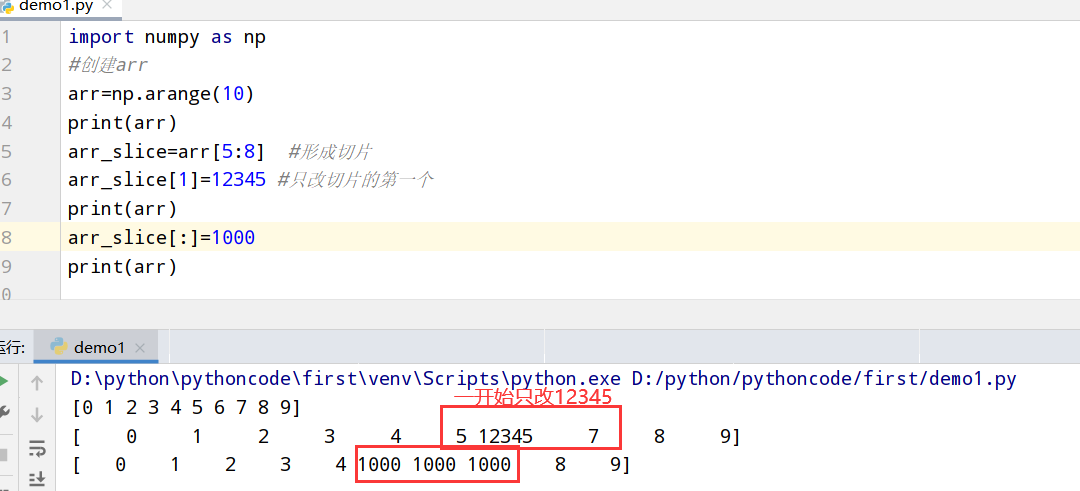
一维数组
1 | import numpy as np |
执行结果
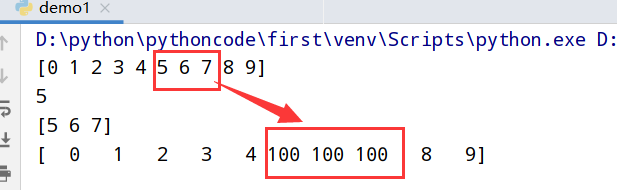
1 | import numpy as np |
执行结果
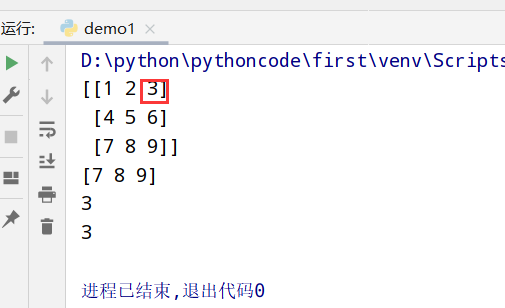
高维数组
索引列表
1 | import numpy as np |
执行结果
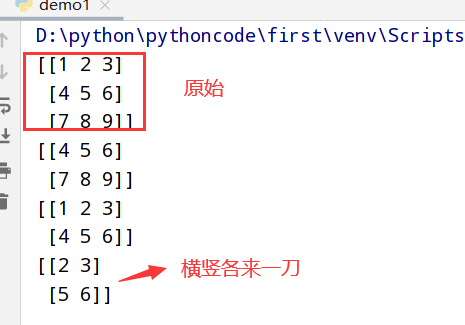
切片索引
1 | import numpy as np |
执行结果
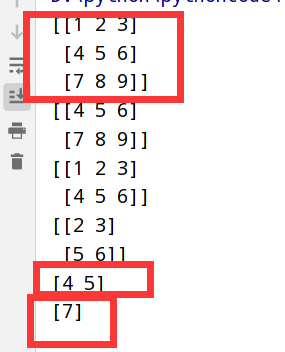
1 | import numpy as np |
执行结果
布尔型索引
1 | import numpy as np |
执行结果

花式索引
1 | import numpy as np |
执行结果
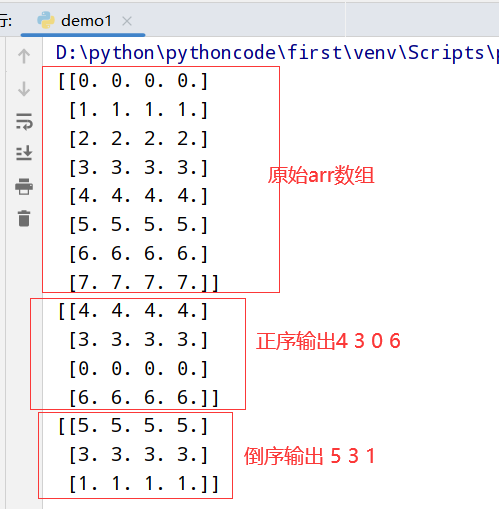
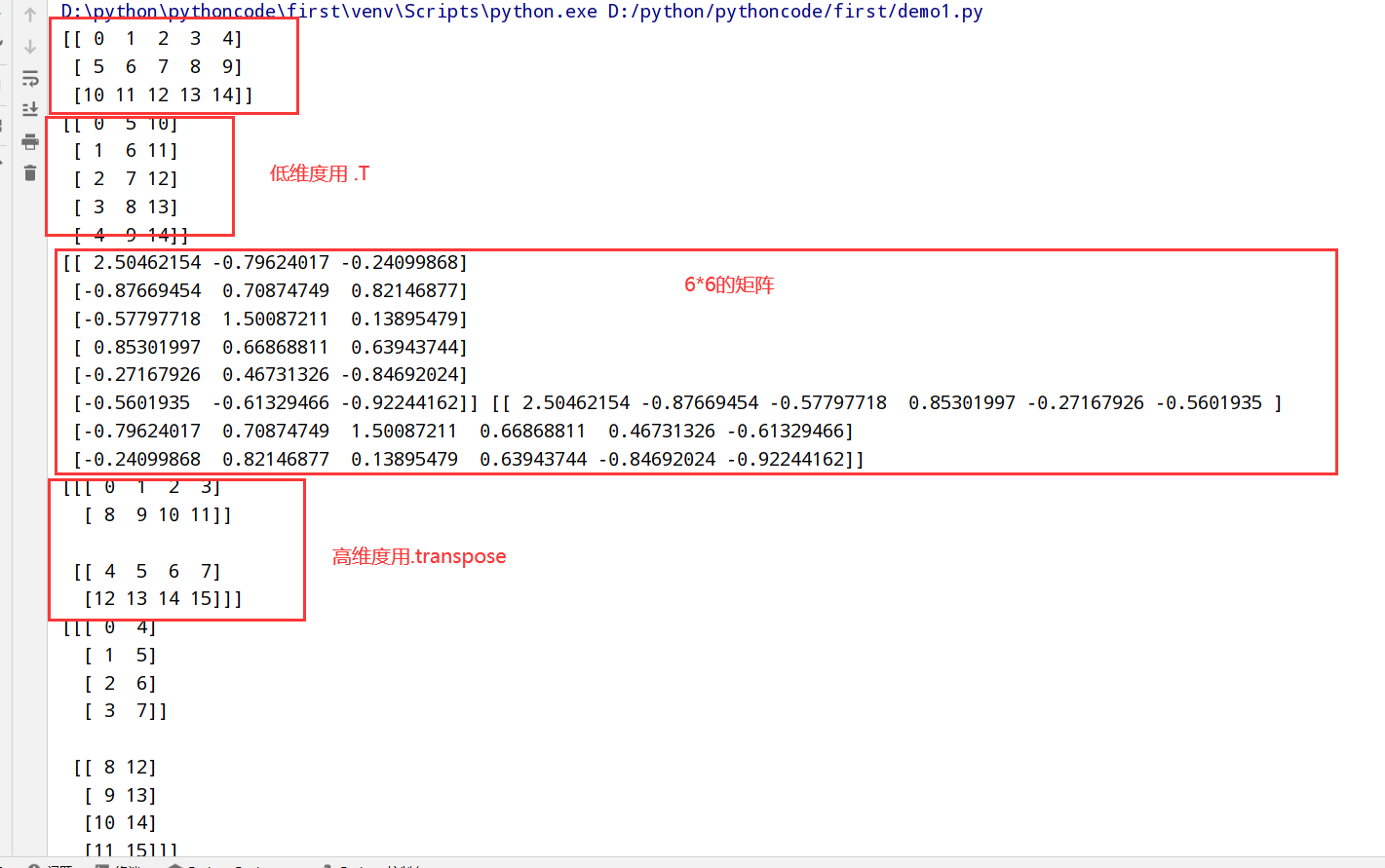
数组转置和轴对称
reshape函数
1 | import numpy as np |
执行结果
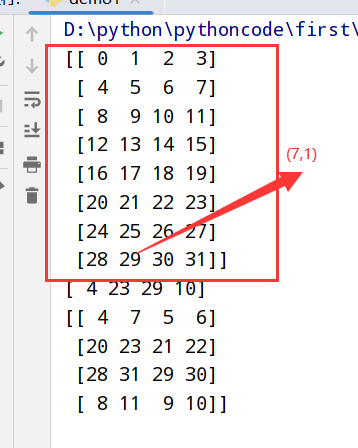
转置和轴对称函数
1 | import numpy as np |
执行结果
通用函数(元素级数组函数)
1 | 1.通用函数(ufunc):一种对ndarray中的数据执行元素级运算的函数 |
一元通用函数
二元通用函数
数组进行数据处理
1 | #假设我们想要在一组值(网格型)上计算函数sqrt(x^2+y^2) |
条件逻辑(数组运算)
1 | import numpy as np |
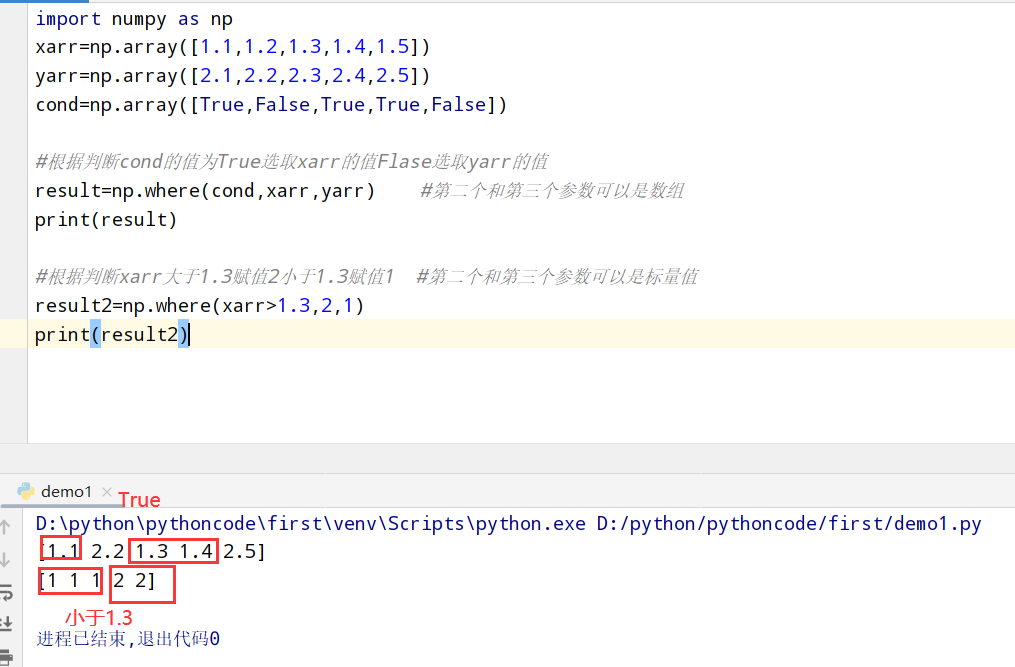
数学和统计方法
基本数组统计方法

1 | import numpy as np |
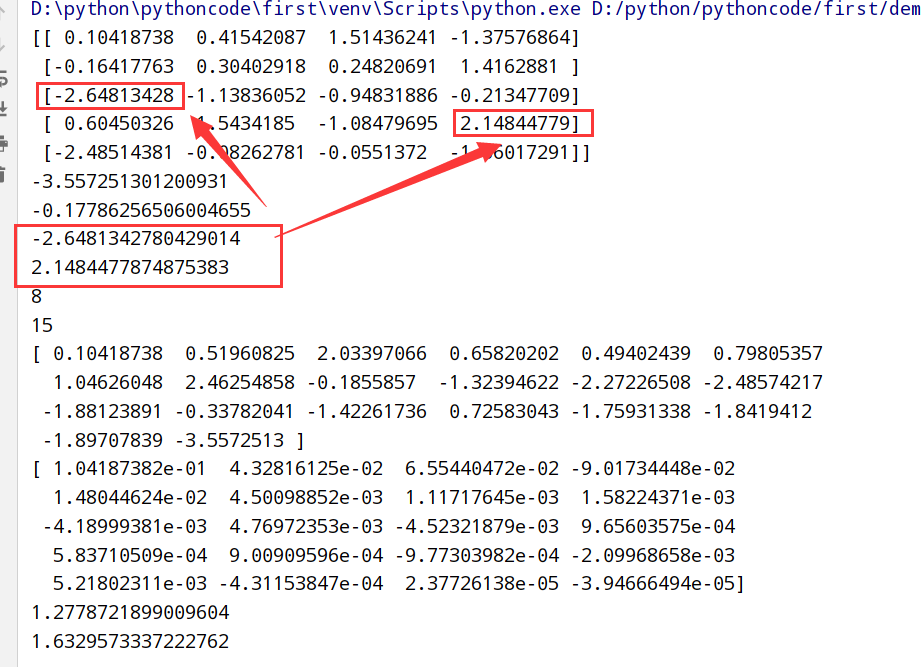
布尔型数组的方法
1 | import numpy as np |
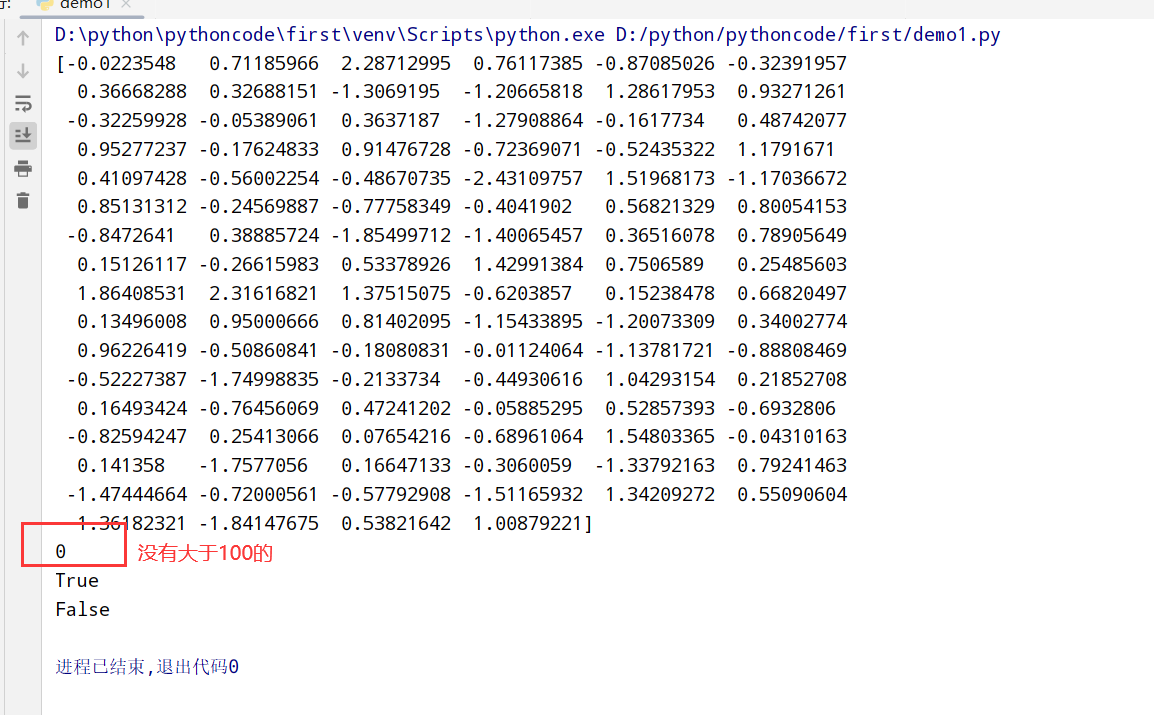
排序(sort方法)
1 | import numpy as np |
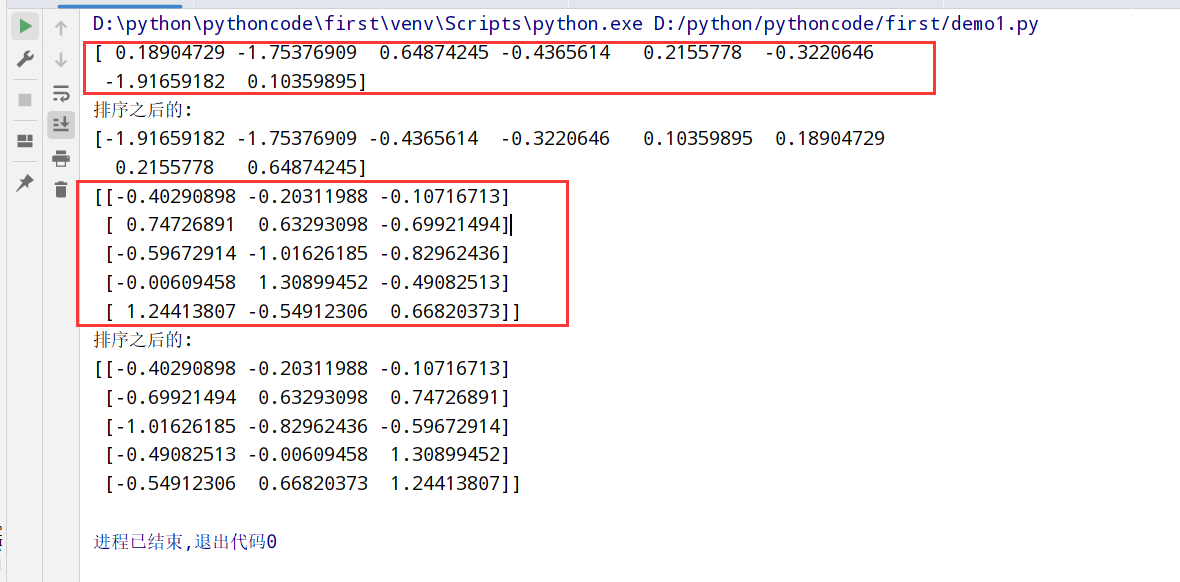
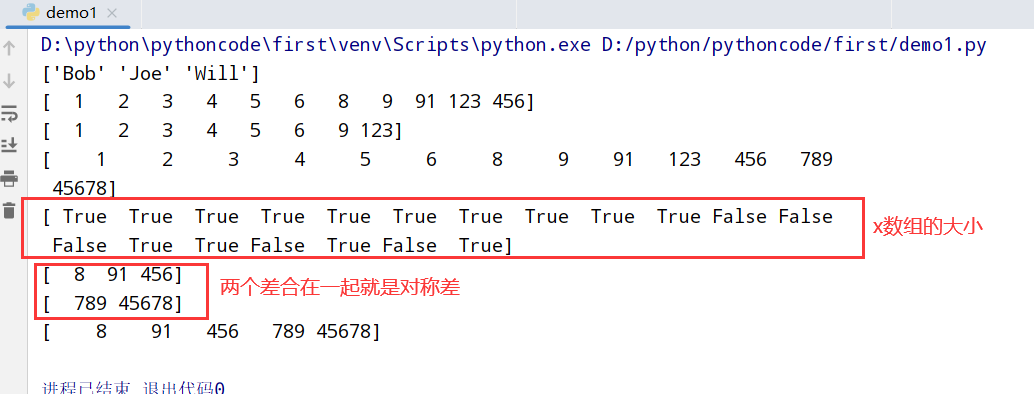
数组的集合运算

1 | import numpy as np |
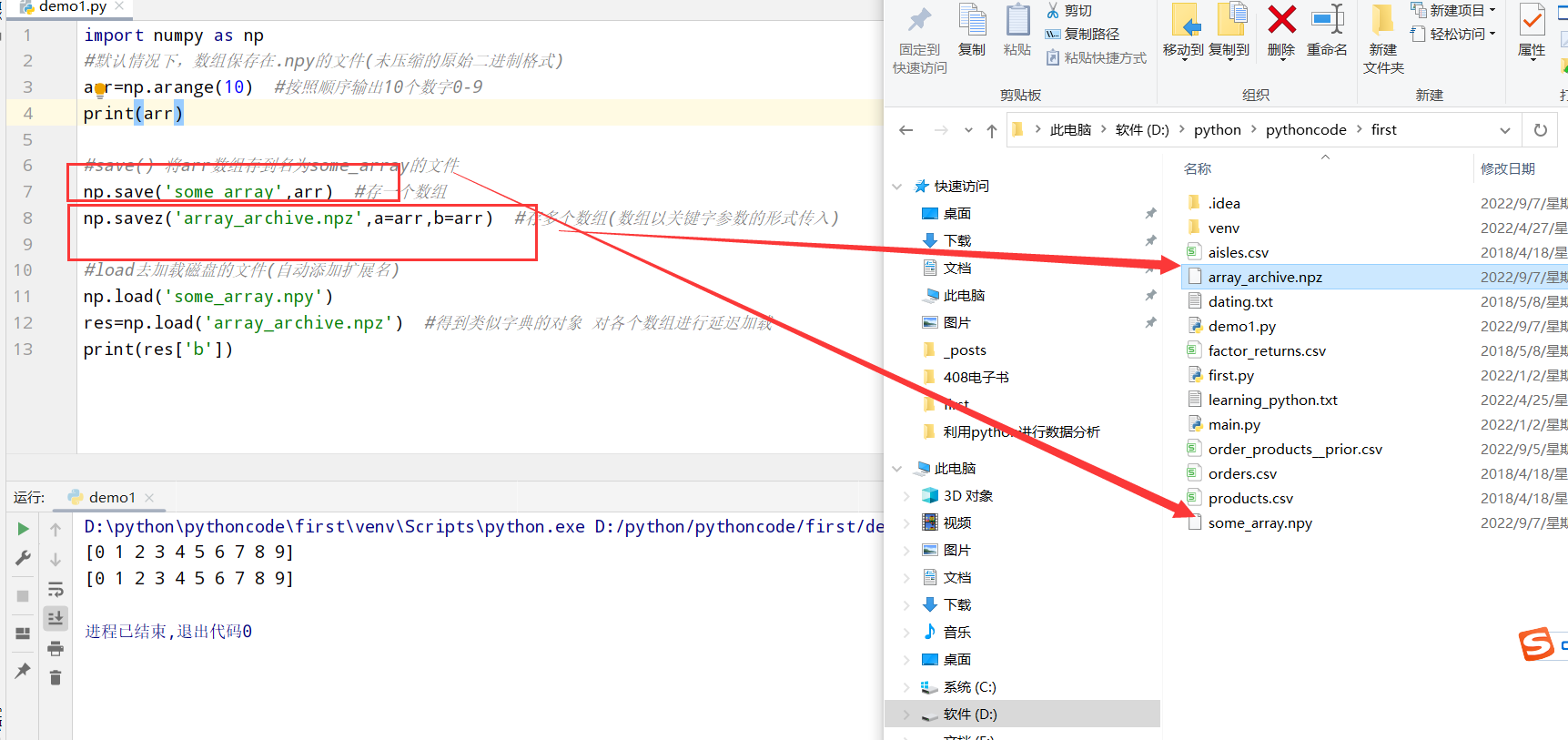
数组的文件输入输出(文本/二进制数据)
保存到磁盘(save和load)
1 | import numpy as np |
存取文本文件
1 | #1.python中的文件读写函数 |
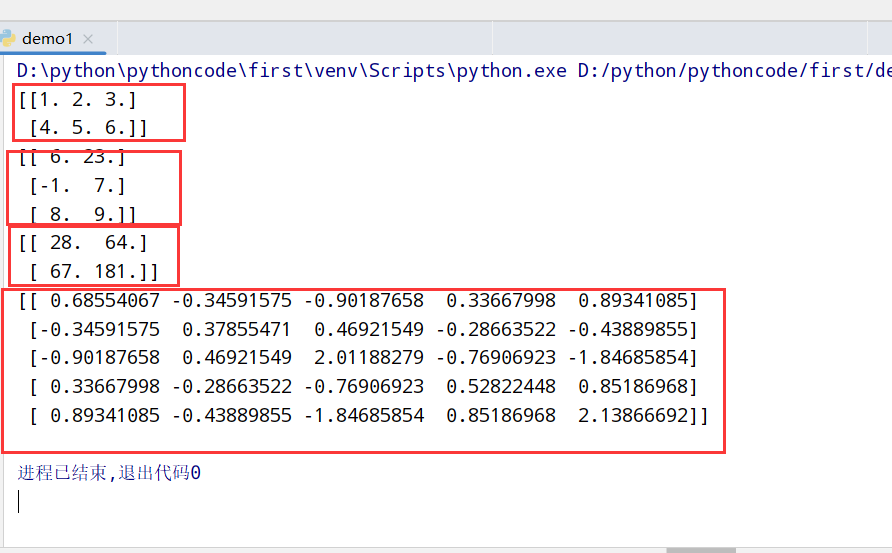
线性代数(linalg)
常用的numpy.linalg函数

1 | import numpy as np |
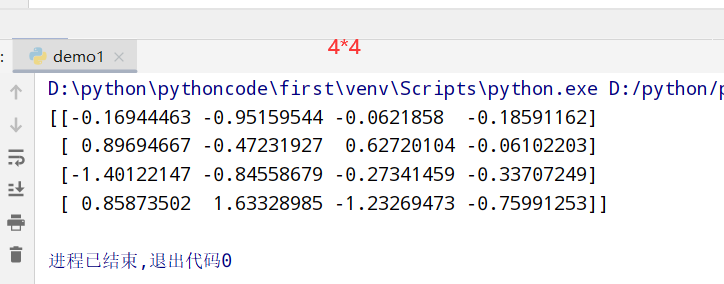
随机数生成(random)
random函数

1 |
|
pandas入门
1 |
|
Series(像字典)
1 | import numpy as np |

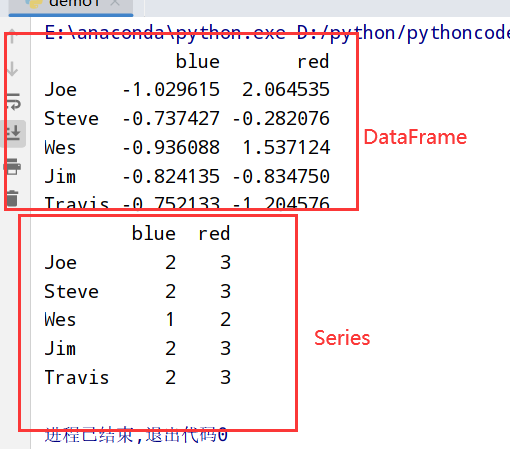
DataFrame(表格型)

DataFrame创建
1 | import numpy as np |
第一种方式
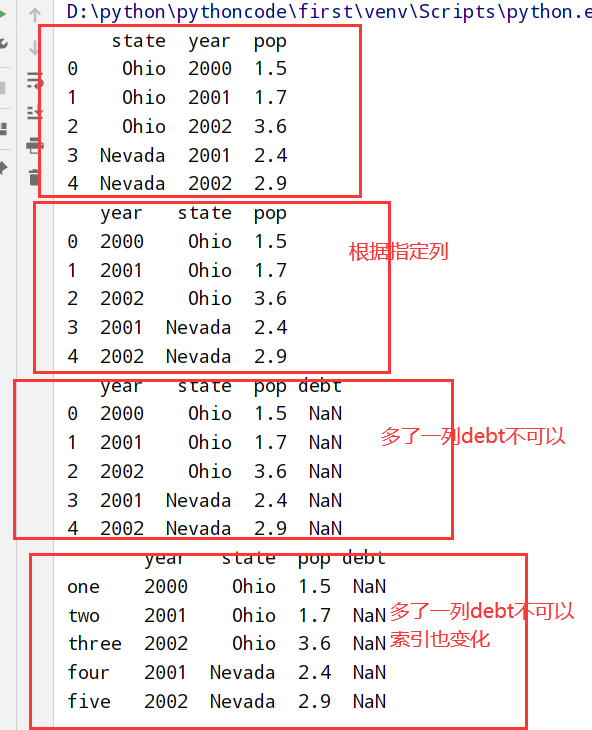
第二种方式
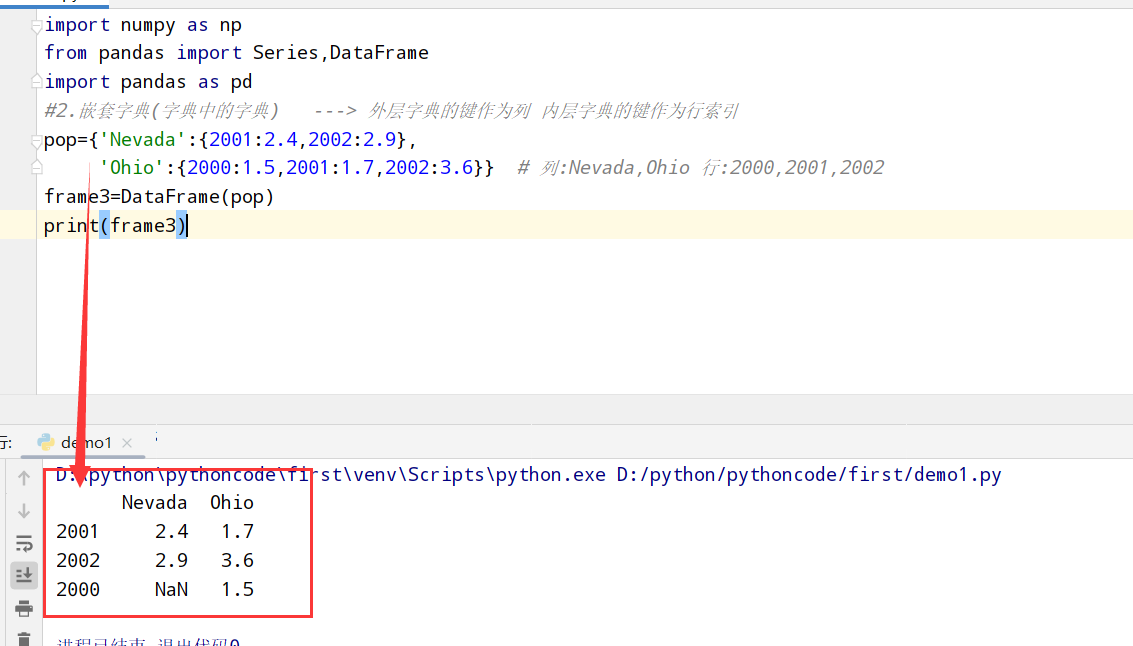
DataFrame使用
1 | import numpy as np |
索引对象
Index对象

1 | import numpy as np |
Index的方法和属性

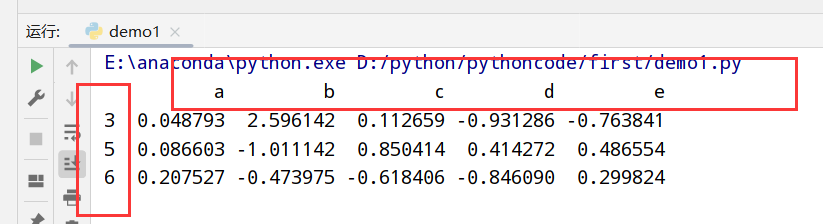
基本功能
重新索引(reindex)
reindex函数的参数

method选项(前向/后向填充)

1 | import numpy as np |

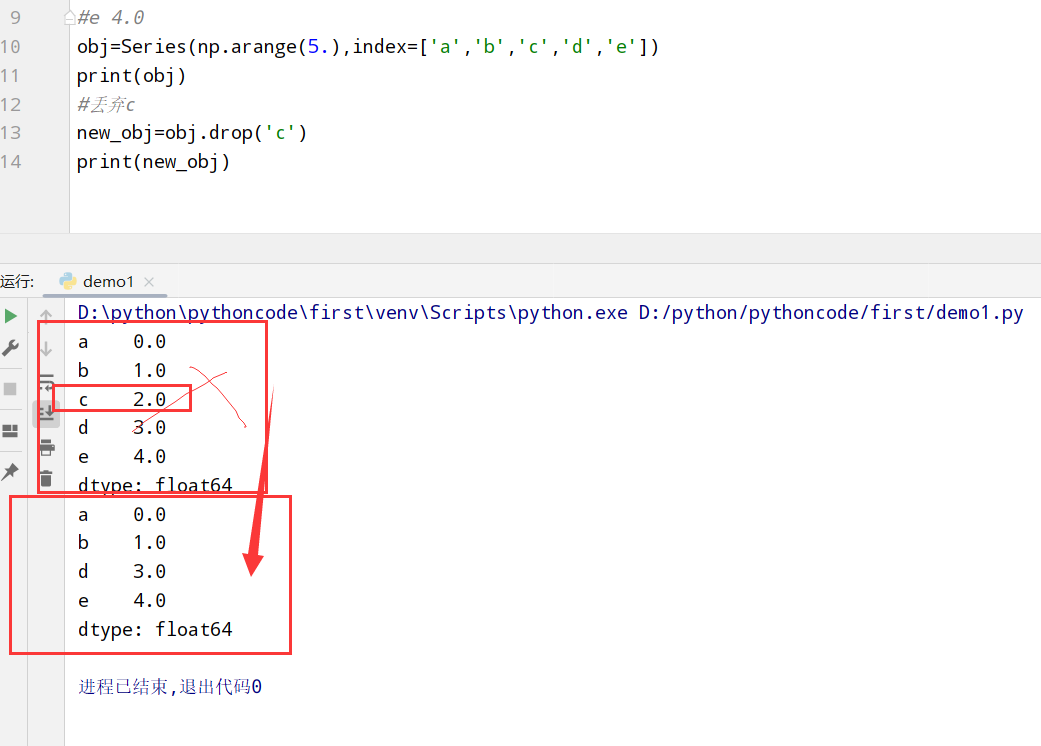
丢弃指定轴上的项(drop)
1 | import numpy as np |
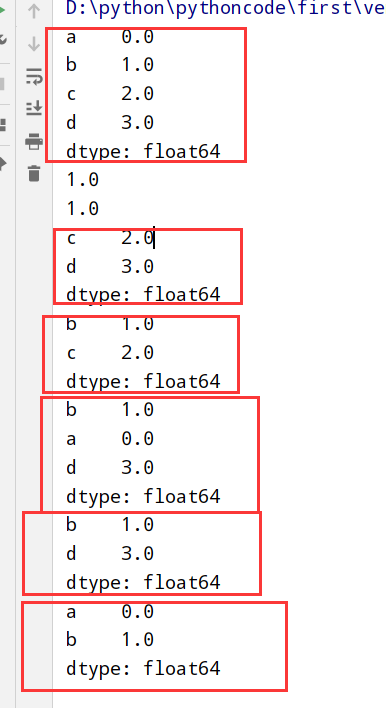
索引+选取+过滤
Series索引(啥都有)
1 | import numpy as np |
DataFrame索引(一个/多个列)
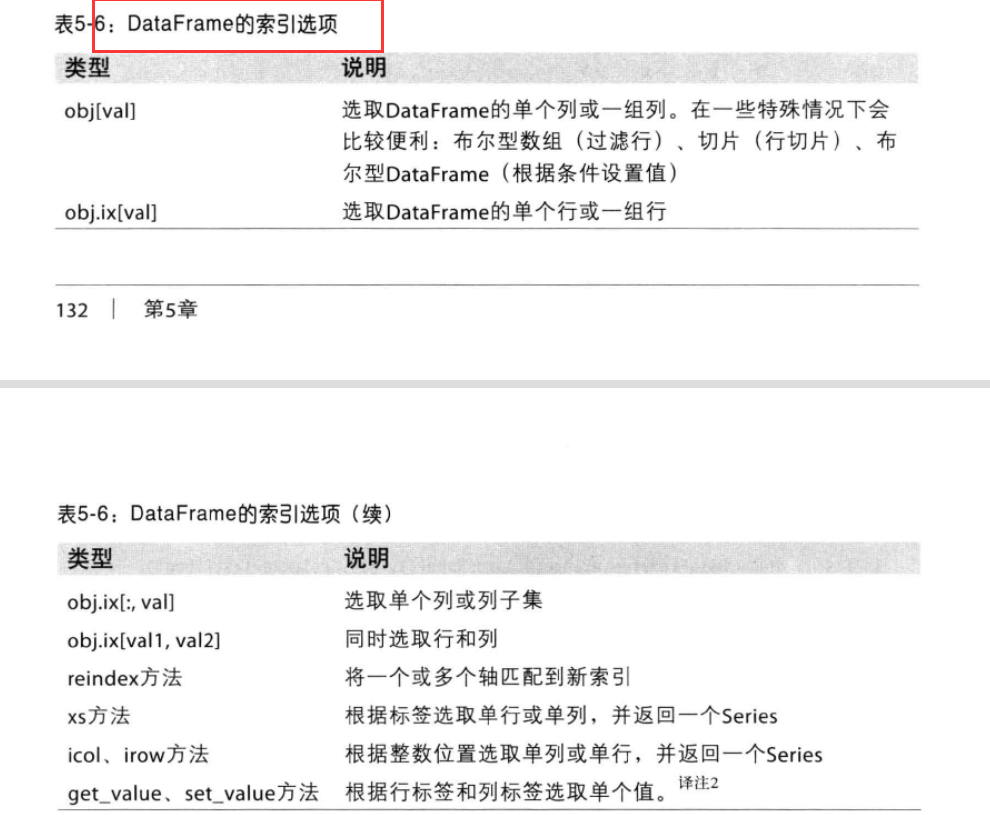
1 | import numpy as np |

算术运算和数据对齐
算数方法

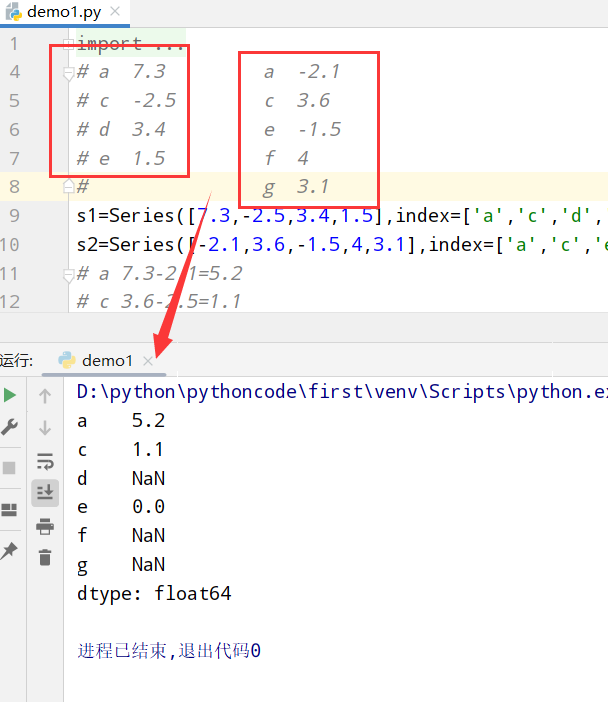
Series(不同就赋值NaN)
1 | import numpy as np |
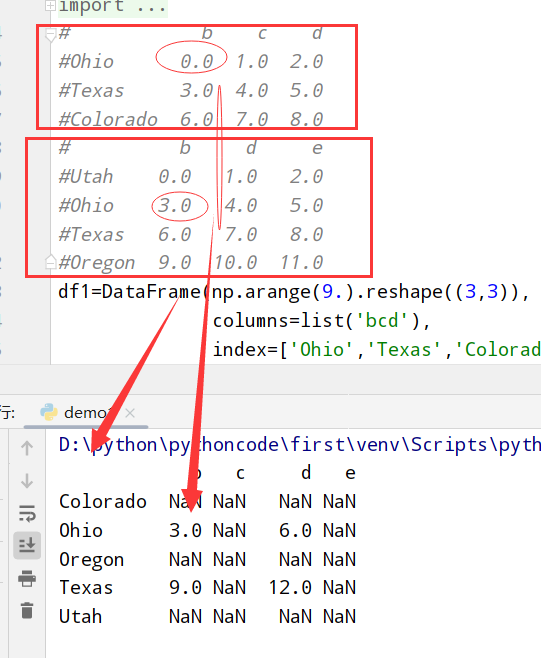
DataFrame(不同就赋值NaN)
1 | import numpy as np |
函数应用和映射(apply和ufuns方法)
1 | import numpy as np |
排序和排名(sort_index和sorting)
Series(根据index排序)
1 | import numpy as np |

DataFrame(根据任意轴index排序)
1 | import numpy as np |

排名(rank)
分析rank()怎么执行
https://blog.csdn.net/justinlonger/article/details/90646111
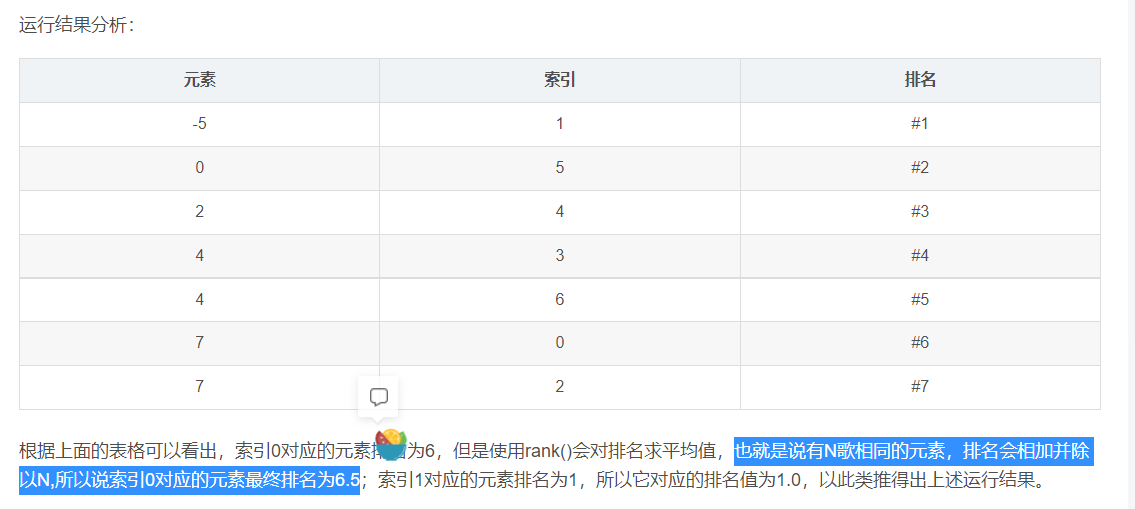
Series
1 | import numpy as np |
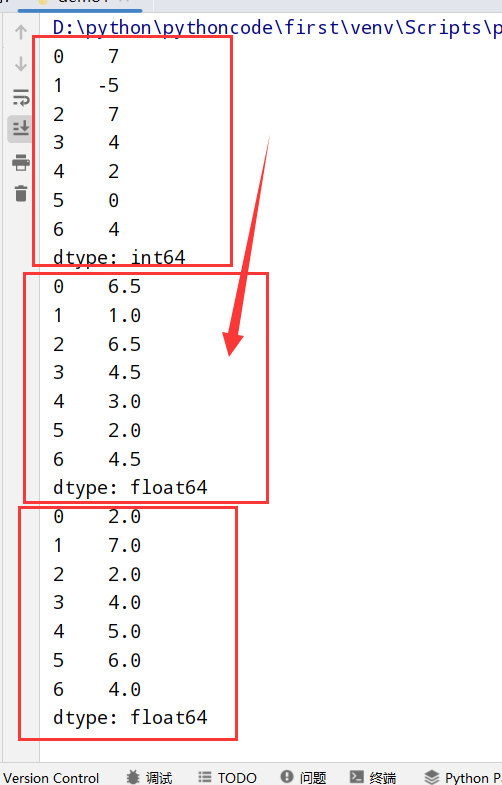
DataFrame
1 | import numpy as np |

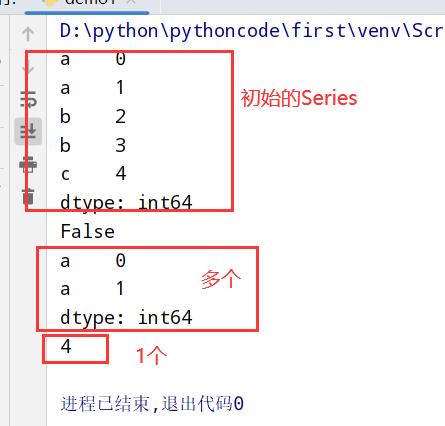
带有重复值的轴索引
Series
1 |
|
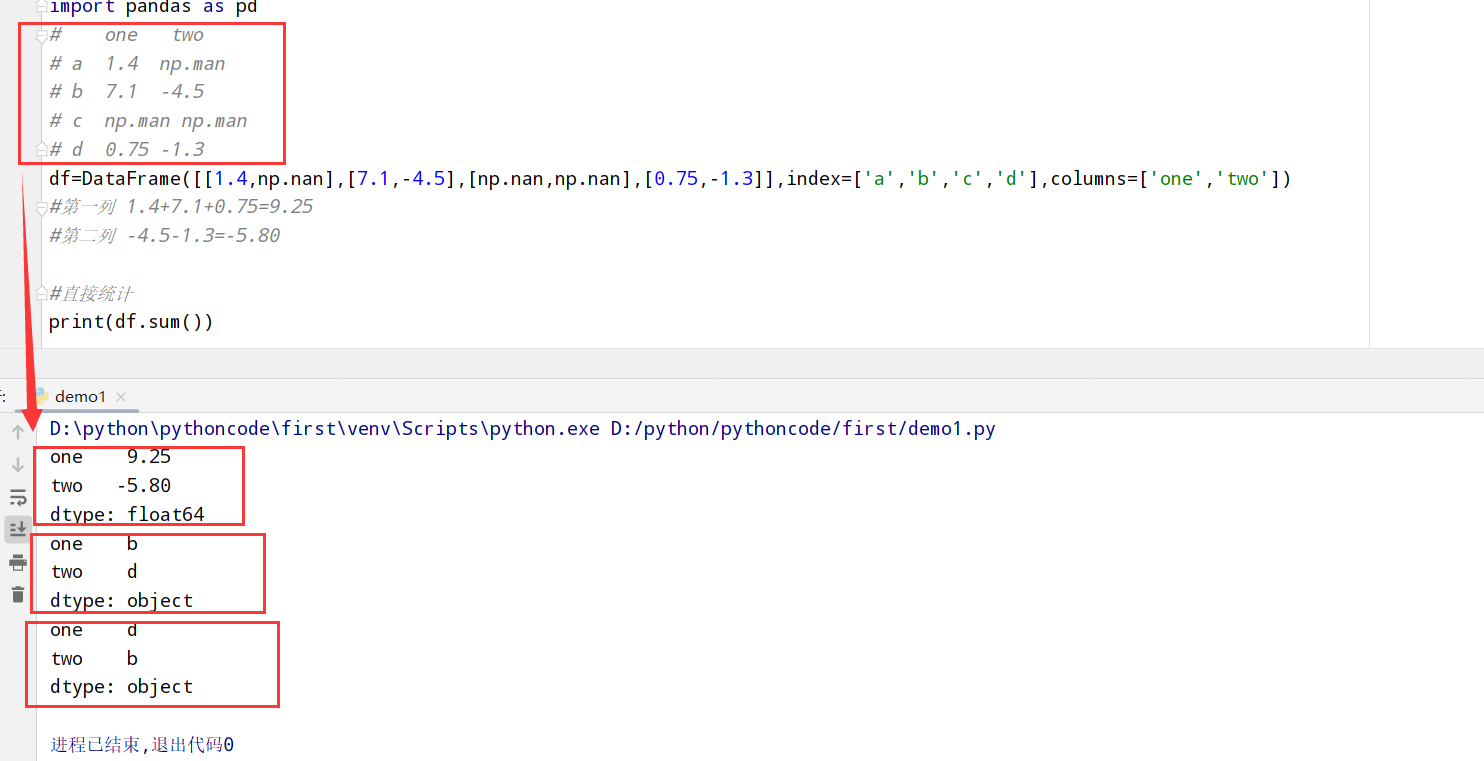
汇总和统计
描述和汇总统计:

1 |
|
相关系数(corr)和协方差(cov)
1 | 1.Series: |
唯一值(unique)和值计数(value_counts)和成员资格(isin)

1 | 1. obj.value_counts() |
处理缺失数据
NA处理方法

1 | 1.滤除: dropna() 默认丢弃任何含有Na的行 |

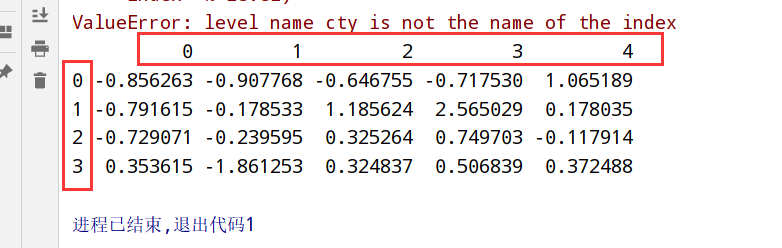
层次化索引
1 | import numpy as np |

重排分级顺序(sortlevel)
1 | 1.swaplevel 根据两个级别的编号/名称 |
根据级别汇总统计(groupby)
1 | 1.在统计和汇总(sum) --> sum(level='xxx') |
使用DataFrame的列(set_index)
1 | 1.一个/多个列 --> 行索引 |
数据(加载/存储/文件格式)
1 | 1.输入输出: |
读取数据(文本格式)
读取函数介绍
pandas解析函数
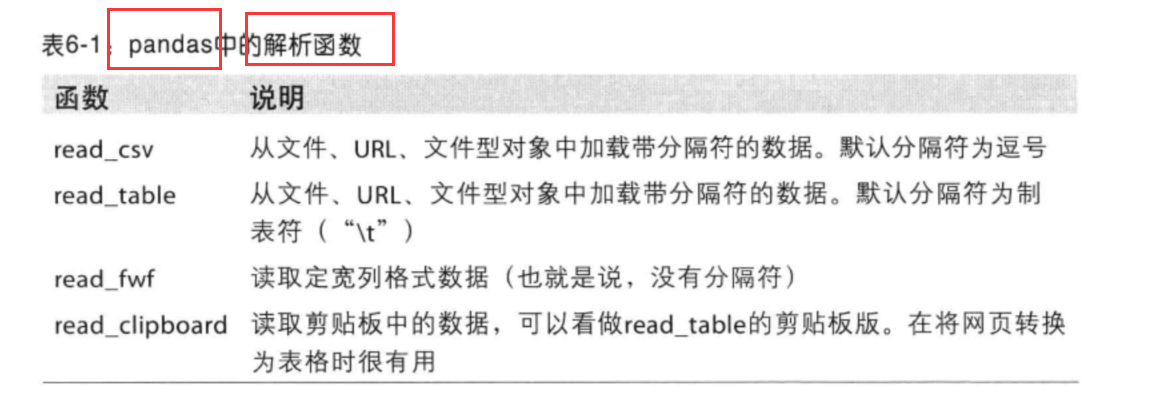
1 | 1. 表格型数据 --> DataFrame对象 |
read_csv/read_table函数的参数

逐块读取文本文件(属性nrows和属性chunksize)
1 | 1.pd.read_csv('xx.csv',nrows=xx) |
数据写出到文本格式(to_csv)
1 | 1.data.to_csv('xx.csv') # (默认) ,分隔符 |
手工处理分隔符格式(csv.Dialect子类)
Dialect属性:

1 |
|
JSON数据(loads和dumps方法)
1 |
|
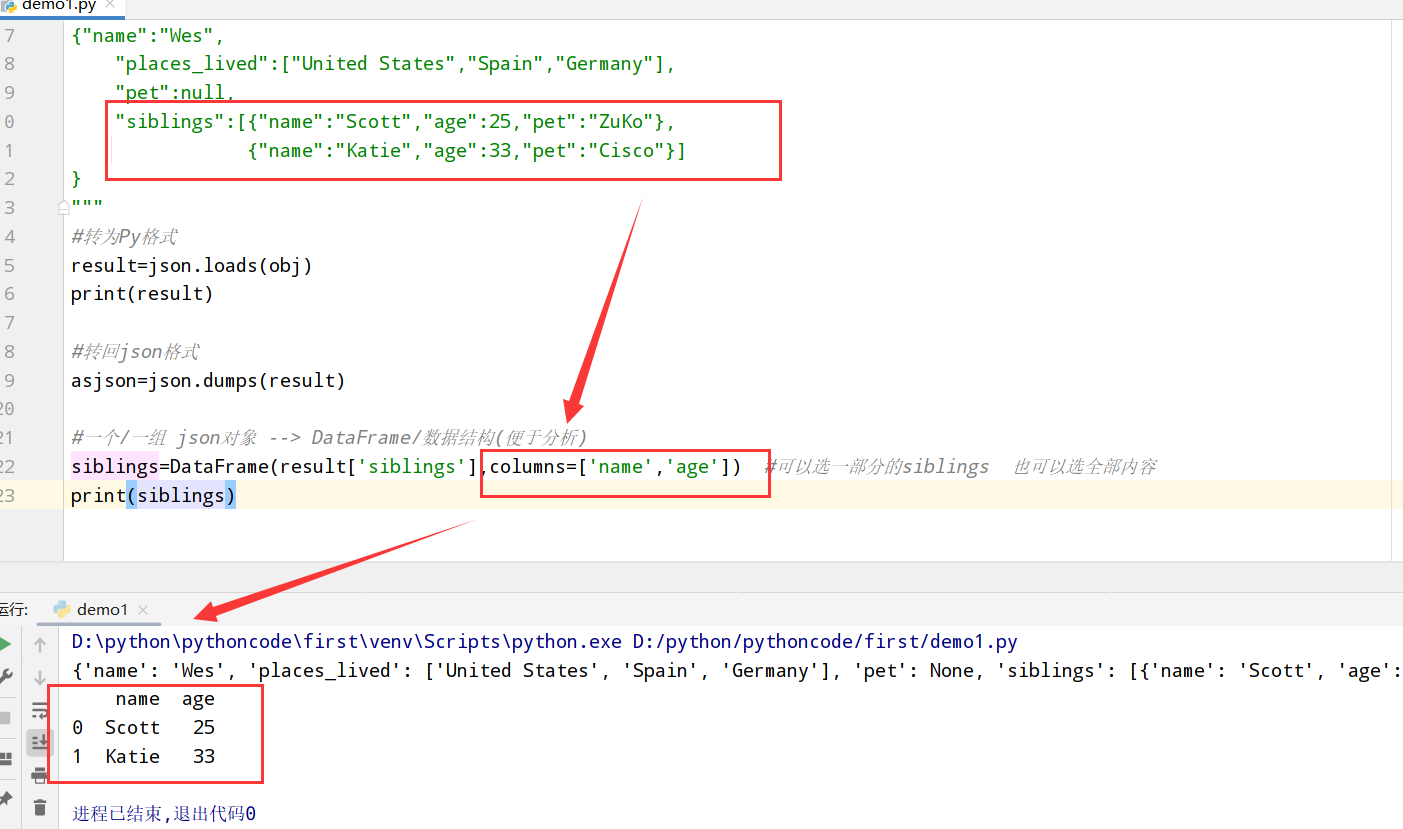
XML和HTML(get和text_content方法)
1 | 1.python有许多可以读写html和xml格式数据的库(比如:lxml) |
解析XML(lxml.objectify)
1 |
|
二进制数据格式(save和load方法)
1 |
|
HDF5格式(层次型数据格式HDFStore类)
1 |
|
1 | #h5适合"一次写 多次读"的数据集 |
读取Microsoft Excel文件(ExcelFile类的xlrd和openpyxl包)
1 | #1.传入xls或xlsx文件 |
HTML和Web API(requests包)
1 | import pandas as pd |
数据库()
关系型数据库(pandas.io.sql模块的read_frame函数)
两种方式:
1 | 目前而言有两种方法: |
1 | import pandas as pd |

非关系型数据库(MongoDB为例)
1 | import pandas as pd |
数据规整化(清理/转换/合并/重塑)
合并数据集
三种合并方法
1 | 1.pandas.merge 根据1个/多个键将不同的DataFrame中的行连接起来(像极了数据库连接操作 选几个行) |
DataFrame的合并(merge和join)
merge函数参数

1 | import pandas as pd |

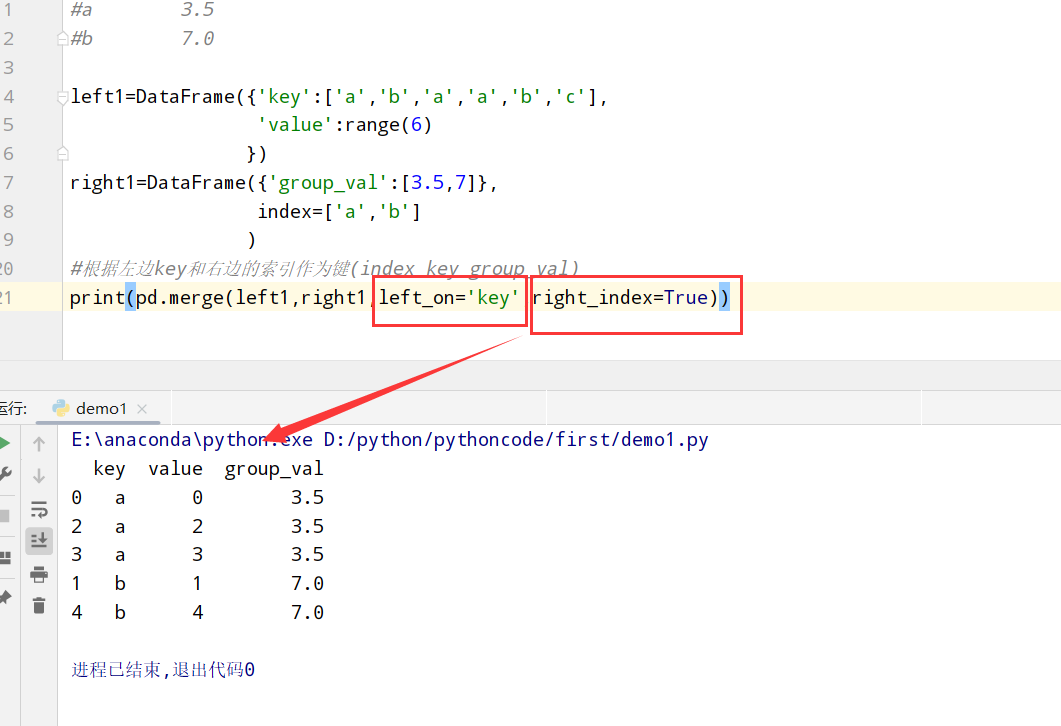
索引上的合并(merge和join只不过更改属性)
1 | 1.普通索引: 设置left_index或者right_index=True表明索引作为连接键 |
代码举例:
1 | import pandas as pd |
轴向连接(concat)
concat函数参数

1 |
|

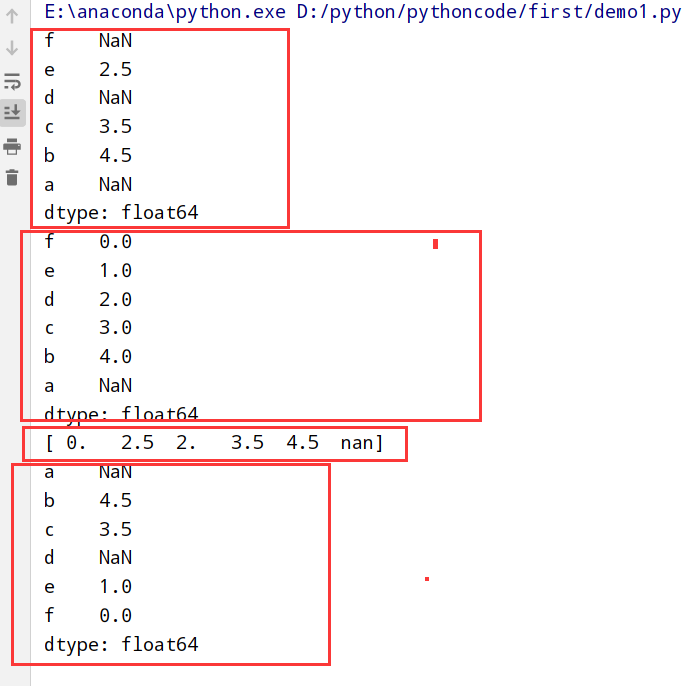
重叠数据的合并(combine_first)
方法总结
1 | 1. numpy中的where方法 |
1 | import pandas as pd |
重塑(reshape)和轴向旋转(pivot)
1 | 1.重塑 reshape方法 |
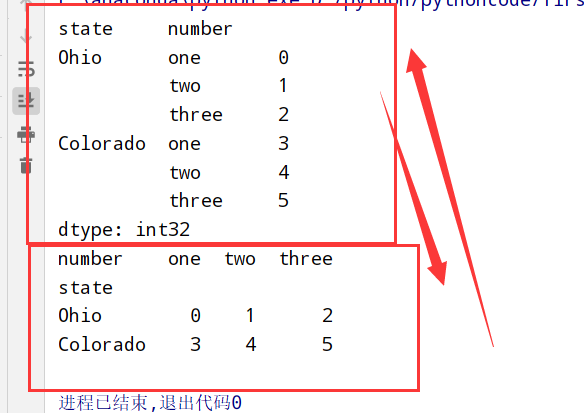
重塑层次化索引(stack和unstack)
1 | 1.stack: 将数据的列"旋转"为行 【列-->行】 |
1 | import pandas as pd |
长格式–> 宽格式
概述
1 | 1.时间序列数据[长格式(long)/堆叠格式(stacked)]存储在数据库和CSV |
数据转换
移除重复数据(duplicated和drop_duplicataes)
1 |
|

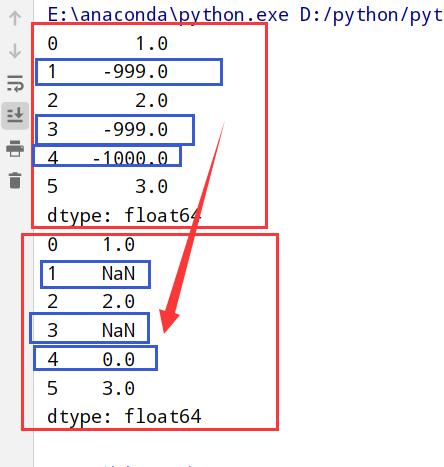
利用函数/映射进行数据转换(Series的map方法)
1 | import pandas as pd |
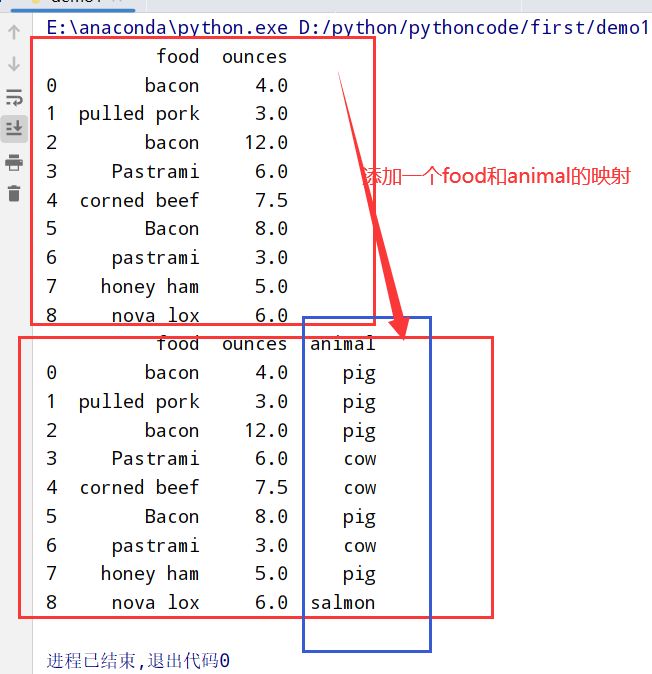
替换值(replace方法)
1 | import pandas as pd |
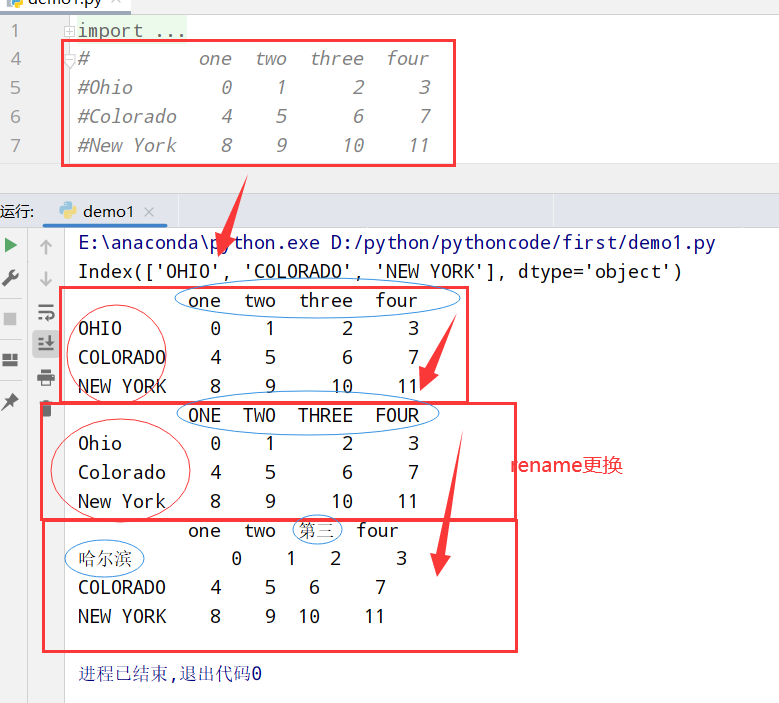
轴索引重命名(map全体更新和rename全体更新/部分更新)
1 | import pandas as pd |
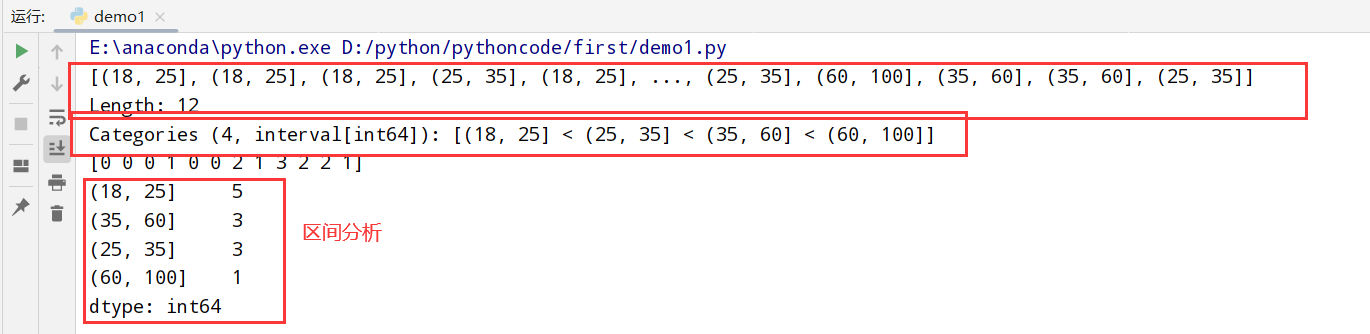
离散化和面元(bin)划分(cut函数和qcut)
cut函数
1 | import pandas as pd |
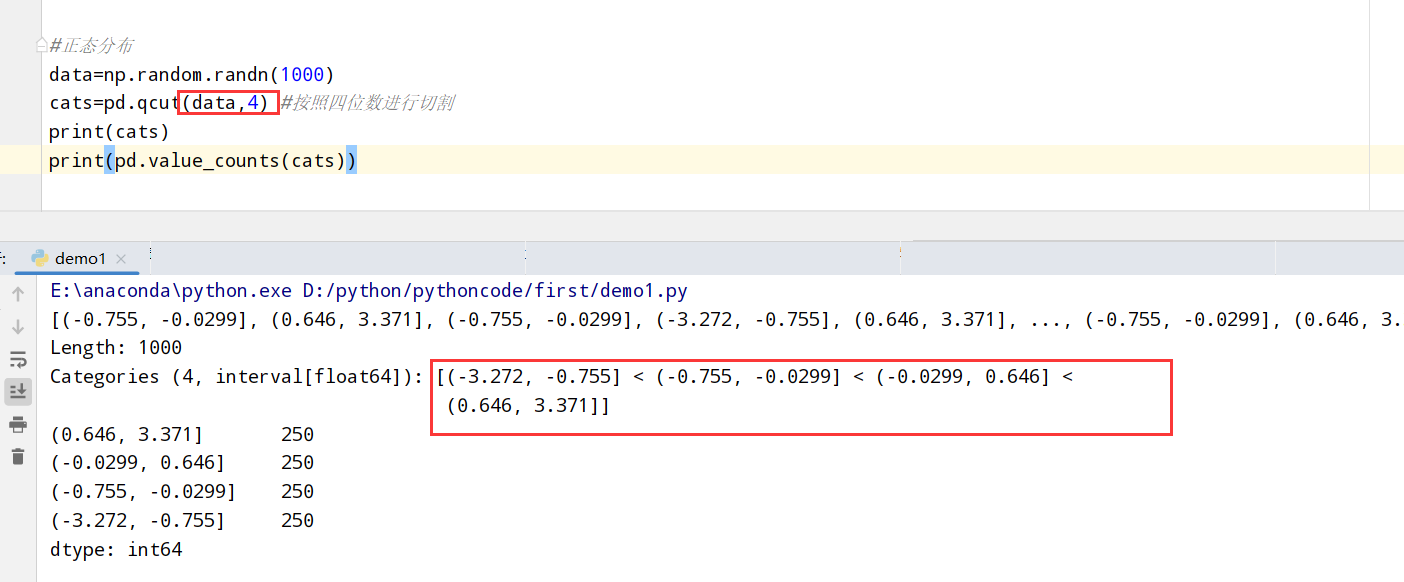
qcut函数
1 | import pandas as pd |
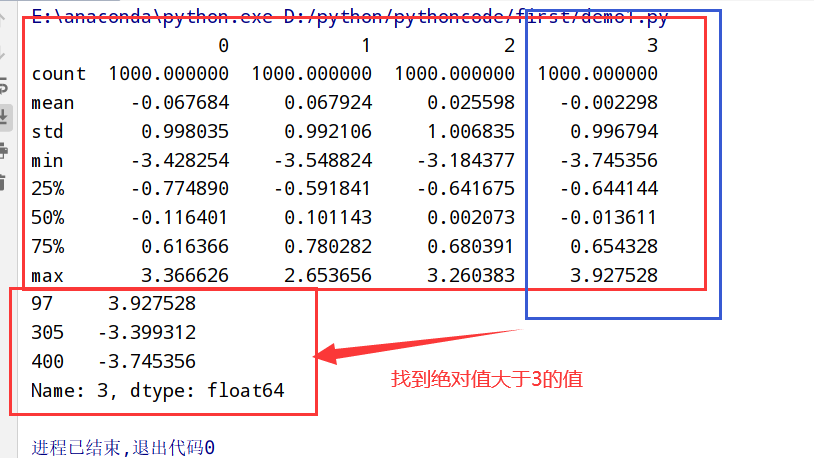
异常值(检测和过滤)
1 | import pandas as pd |
排列(np.random.permutation)和随机采样(np.random.randint)
1 | import pandas as pd |

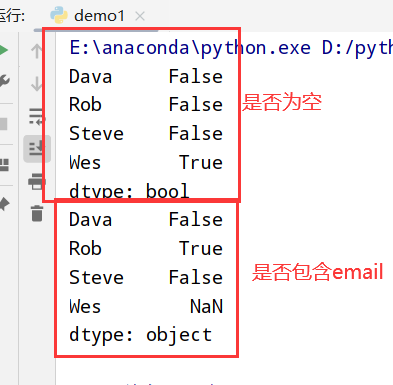
指标/哑变量(get_dummies方法)
1 | 1.分类变量(categorical variable) --> 哑变量矩阵(dummy matrix)/指标矩阵(indicator matrix) |
1 | import pandas as pd |

字符串操作
字符串对象方法
py内置的字符串方法

1 | import pandas as pd |

正则表达式(regex)
1 | 1.py内置的re模块负责对字符串应用正则表达式 |

pandas中矢量化的字符串函数

1 | import pandas as pd |
绘图和可视化(matplotlib)
matplotlib API入门
1 | 1.matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面) |
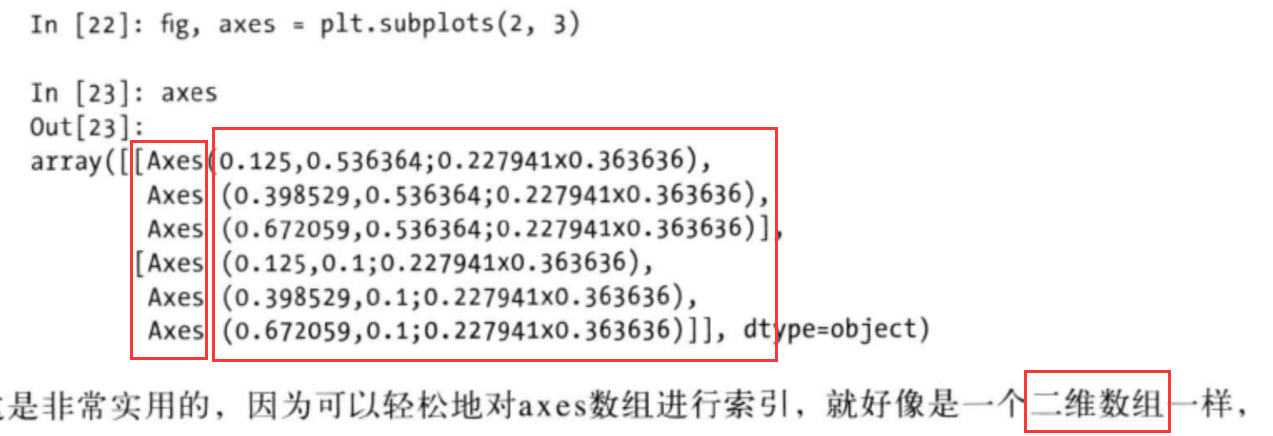
Figure和Subplot(更方便的plt.subplots方法)
旧的figure和subplot
1 | import numpy as np |
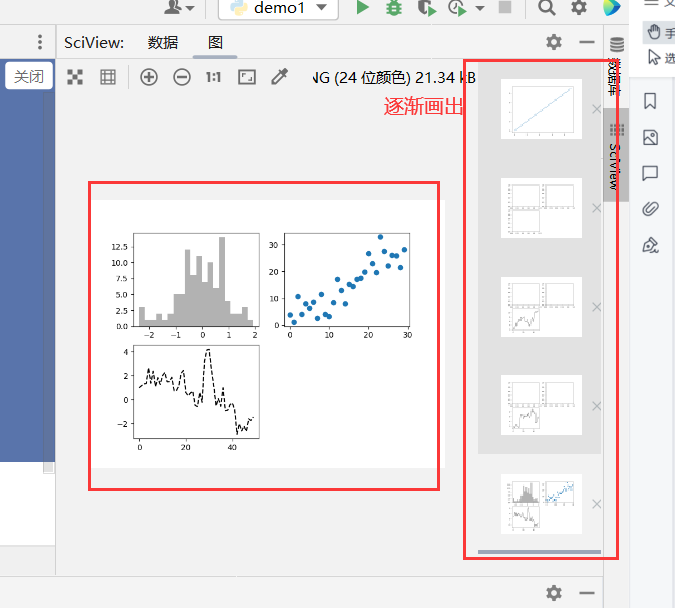
新的subplots

1 | import numpy as np |
调整subplot周围的间距(Figure的subplots_adjust方法)
1 | # wspace和hspace用于控制宽度和高度的百分比(用作subplot之间的间距) |
颜色(color)、标记(marker)、线型(linestyle)
1 | import numpy as np |
刻度(xticks)、标签(xticklabels)、图例(xlim)
1 | 大多数的图表装饰项: |
设置标题(set_title)、轴标签(set_xlabel)、刻度(set_xticks)、刻度标签(set_xticklabels)
1 | import numpy as np |
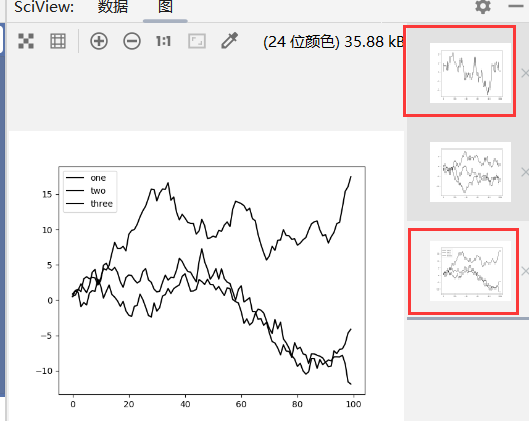
添加图例(ax.legend/plt.legend)
1 | import pandas as pd |
注解以及在Subplot上绘图(matplotlib.pyplot/matplotlib.patches)
1 | 1.matplotlib有一些表示常见图形的对象(对象被称为块[patch]) |
1 | import pandas as pd |
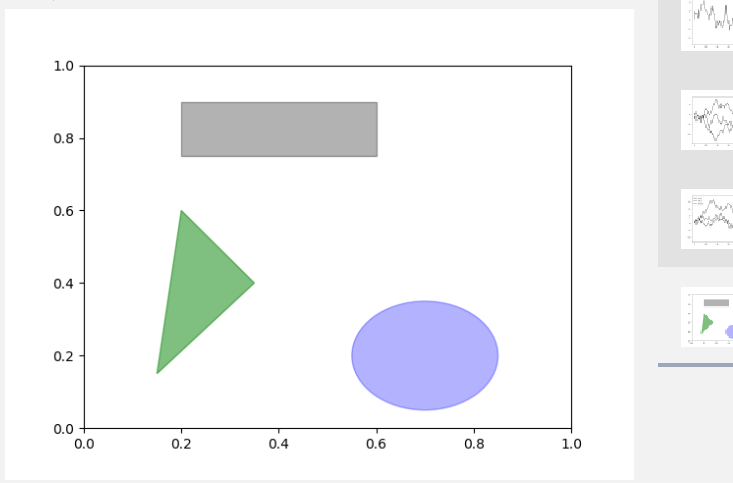
将图标保存到文件(plt.savefig)
1 | import numpy as np |

matplotlib配置
1 | 操作matplotlib配置系统的方式 |
pandas中的绘图函数
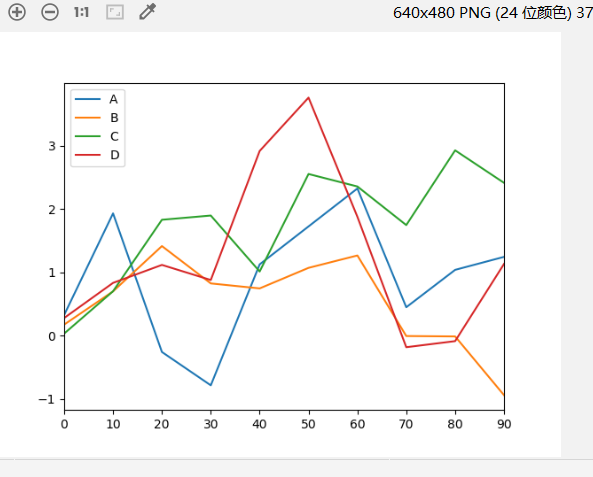
线型图(默认kind=’line’)
1 | 1.Series和DataFrame都有一个用于生成各类图表的plot方法(默认是线形图) |
Series的plot参数:

DataFrame的plot参数:
1 | import pandas as pd |
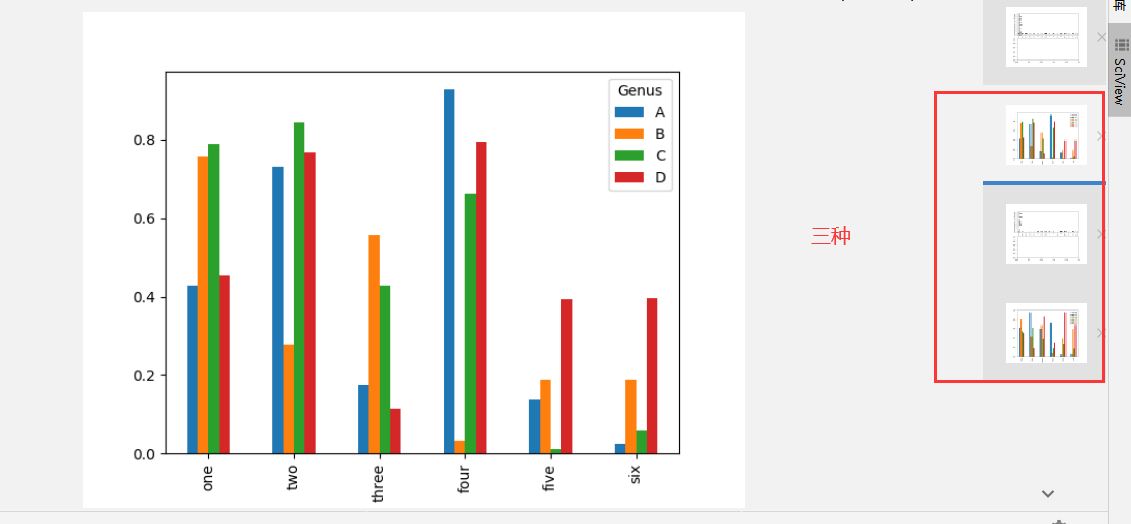
柱状图(kind=’bar’/‘barh’)
1 | 1.Series.plot( 设置kind='bar'(垂直柱状图) / kind='barh'(水平柱状图) ) |
1 | import numpy as np |
直方图(Series的hist方法)和密度图(kind=’kde’)
1 | 1.直方图(histogram):是一种可以对值频率进行离散化显示的柱状图[数据点被拆分到离散的、间隔均匀的面元中,绘制的是各面元中数据点的数量] |
1 | tips['tip_pct']=tips[tip] / tips['total_bill'] |
散布图(plt.scatter方法和pd.scatter_matrix函数)
1 | 1.散布图(scatter plot):是观察两个一维数据序列之间的关系 |
Python图形化工具生态系统
1 | 1.Chaco: 静态图+交互式图形 |
数据聚合与分组运算
GroupBy技术
1 | 1.分组(split) : pandas对象(Series/DataFrame) --> 根据一个/多个键拆分(split)为多组 [对象特定轴上执行的,DataFrame可以在其行(axis=0)其列(axis=1)进行分组] |
流程:
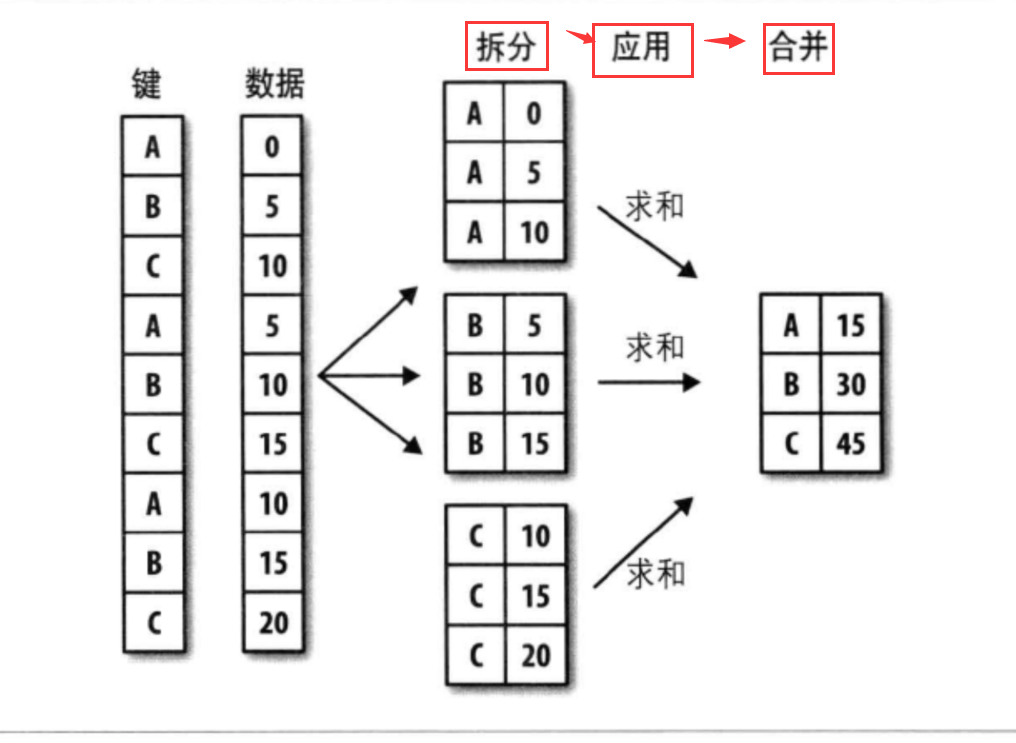
1 | import pandas as pd |
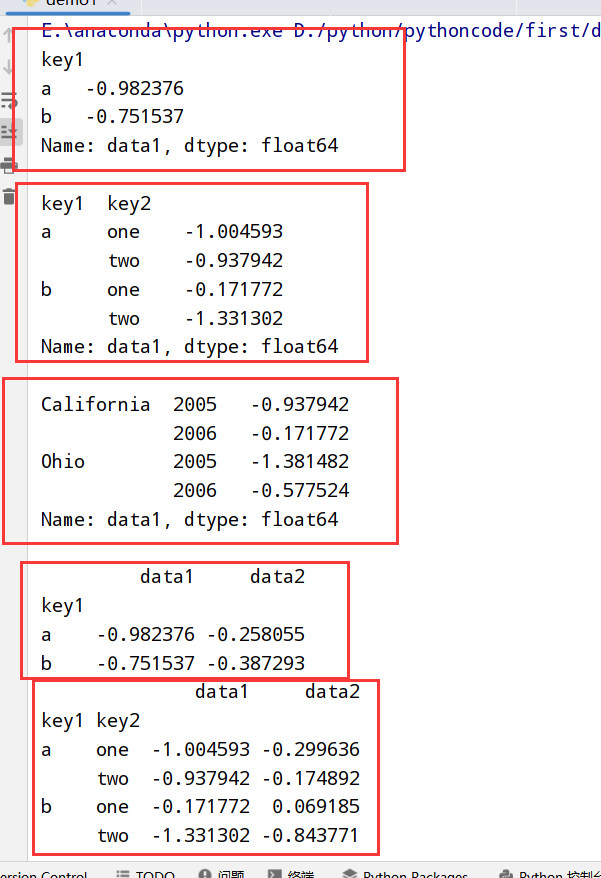
分组迭代(groupby方法)
1 | 1.GroupBy对象支持迭代 --> 一组二元元组(分组名+数据块) |
执行结果:
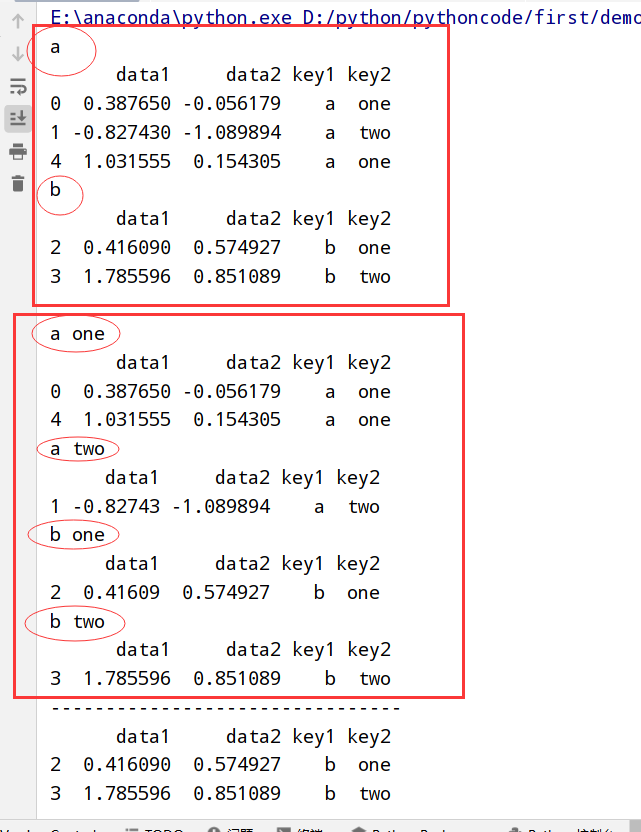

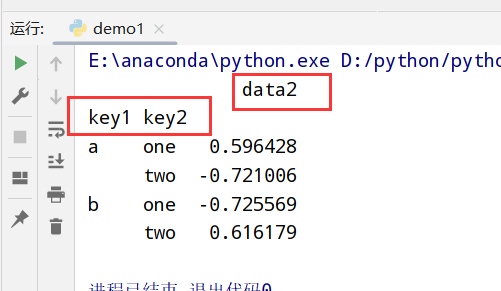
选取一个/一组列(groupby([‘x1’,’x2’]))
1 | #两种转换 |
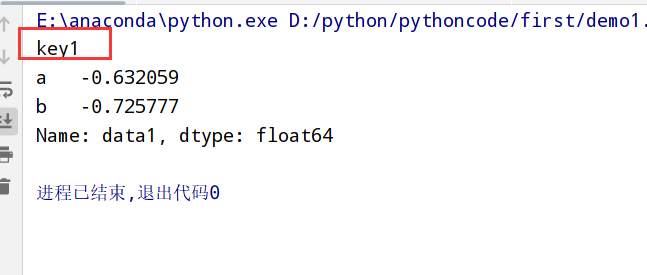
通过字典/Series进行分组(groupby(字典名))
1 | import pandas as pd |
通过函数进行分组(groupby(函数))
1 | import pandas as pd |
通过索引级别分组(level关键字)
1 | import pandas as pd |
数据聚合
groupby聚合函数

1 | import pandas as pd |
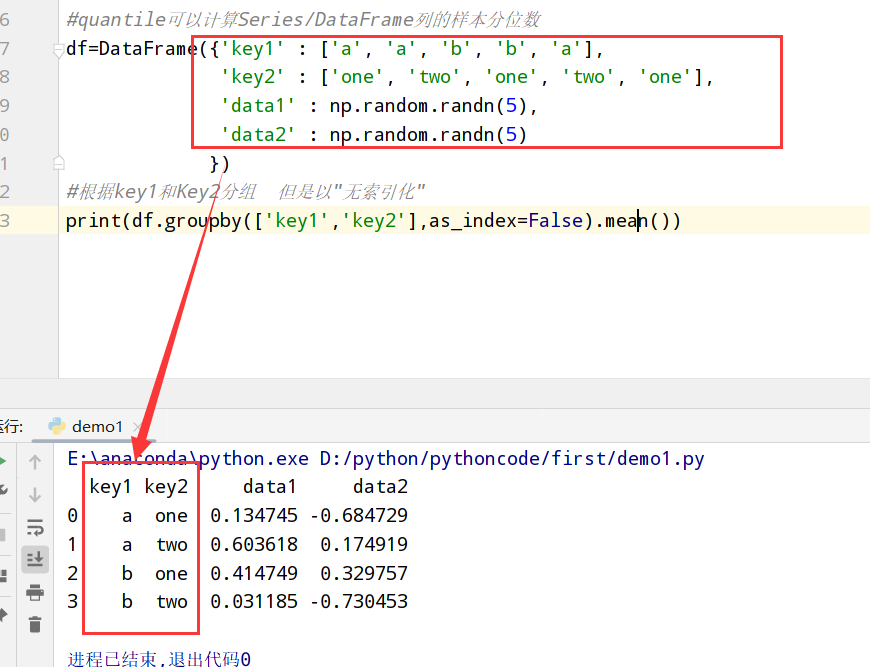
无索引的形式返回聚合数据(as_index=False禁用)
1 | import pandas as pd |
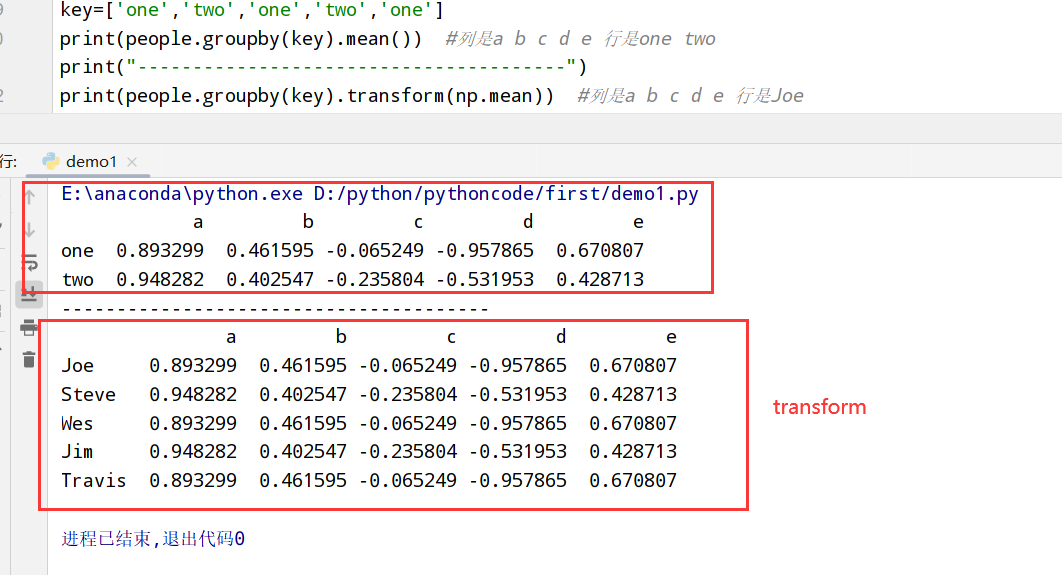
分组级运算和转换
transform和apply
1 | import pandas as pd |
禁止分组键(group_keys=False)
1 | data.groupby('key1',group_keys=False).apply(top) |
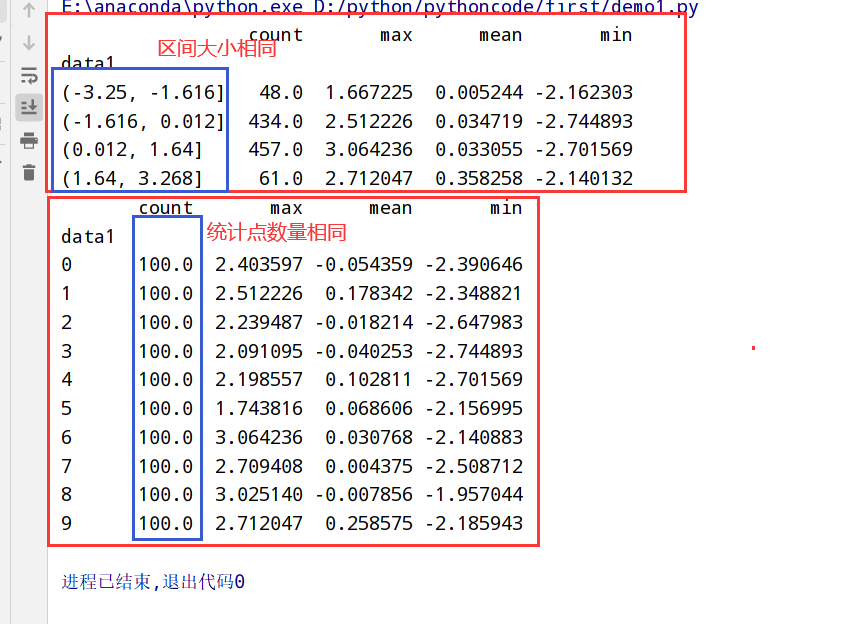
分位数(quantile)和桶(bucket)分析
1 | 1.pandas有一些能根据指定面元/样本分位数-->数据拆分为多块的工具(cut和qcut) |
两种不同的分别方法(cut和qcut):
1 | import pandas as pd |
(示例)用特定于分组的值填充缺失值(fillna方法)
1 | import pandas as pd |

(示例)随机采样和排列(random.permutation方法)
1 | import pandas as pd |
透视表(pivot table)和交叉表(crosstab)
pivot_table参数:

1 | 透视表: |
时间序列(time series)
1 | 具体应用场景: |
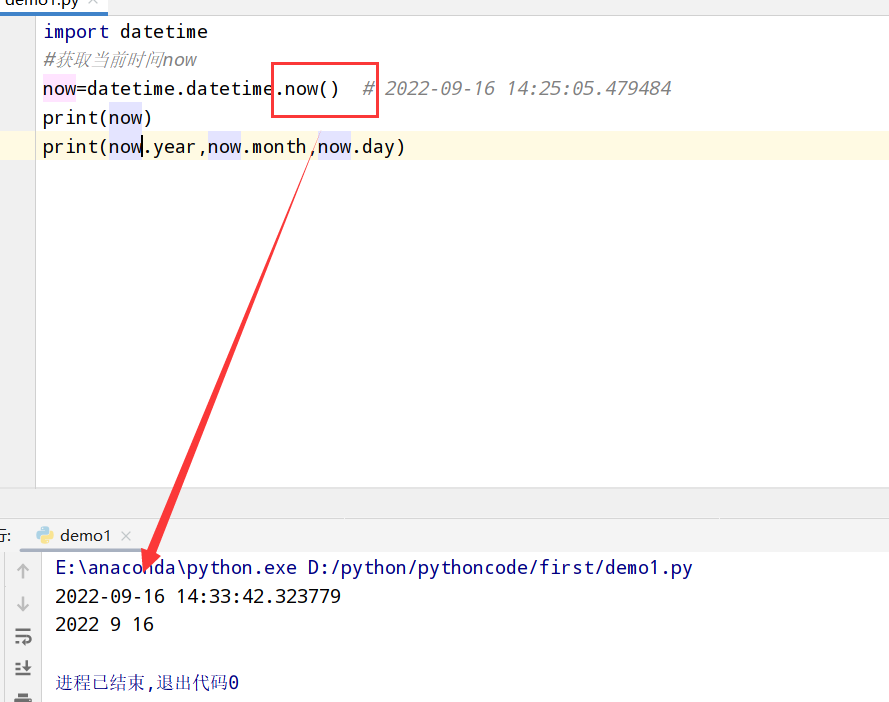
日期和时间数据类型及工具(datetime模块)
1 | 1.python标准库:日期(data)、时间(time)数据的数据类型、日历方面的功能 |
datetime模块中的数据类型

1 | import datetime |
字符串和datetime之间的转换(strptime/strftime方法)
datetime格式定义:

1 | import datetime |
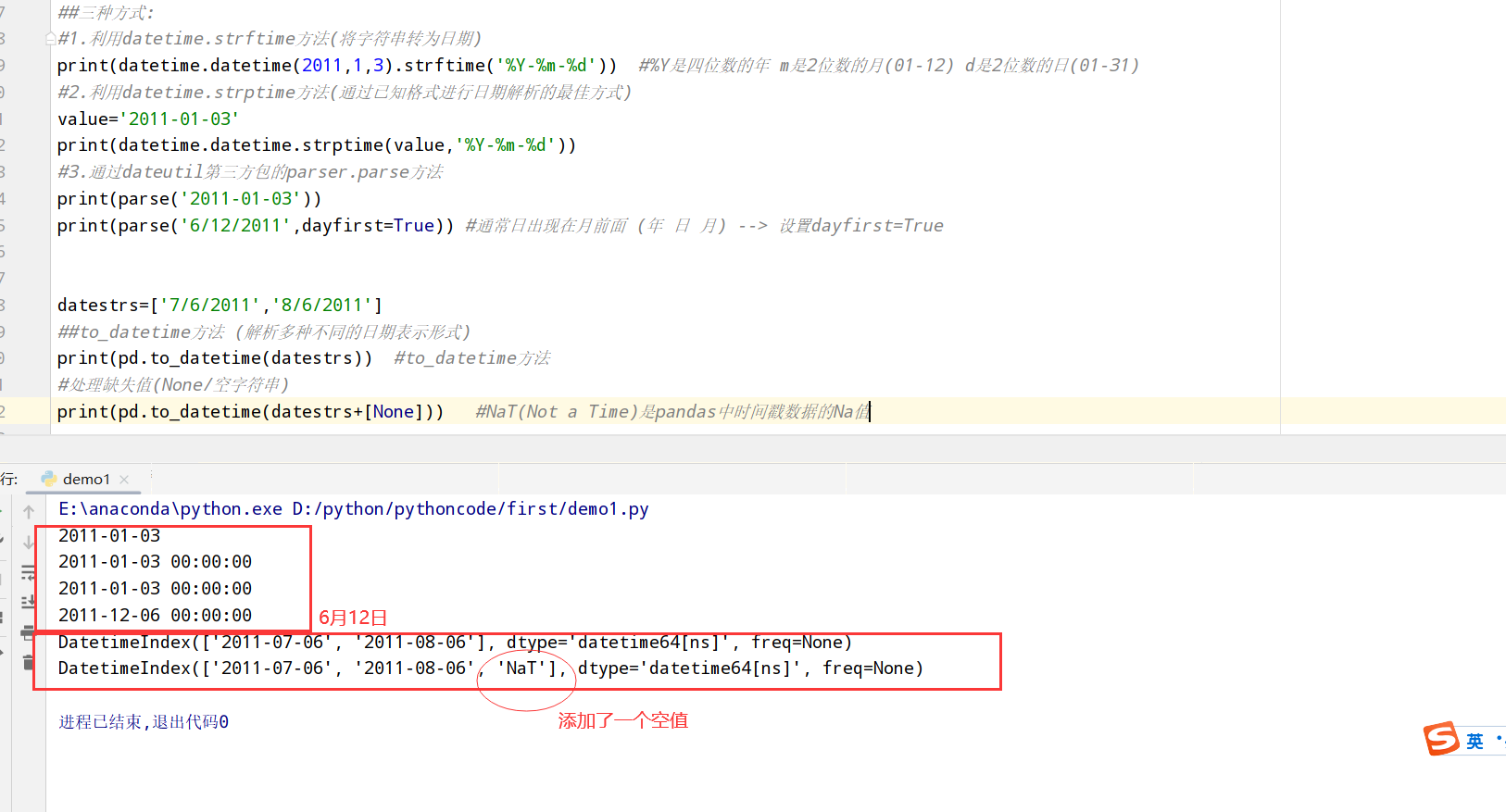
时间序列基础
索引更换为datetime数据
1 | import datetime |
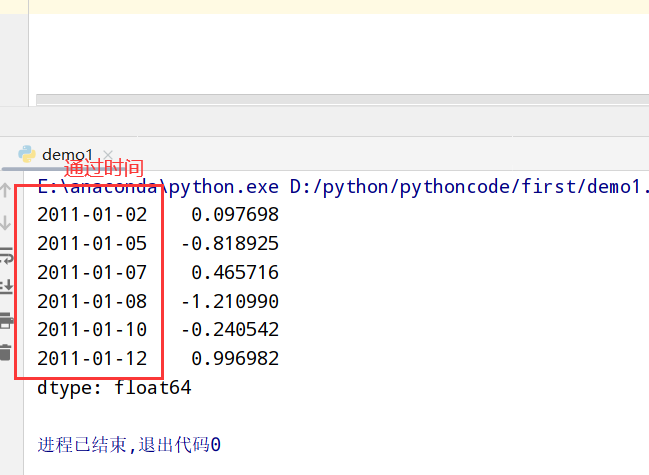
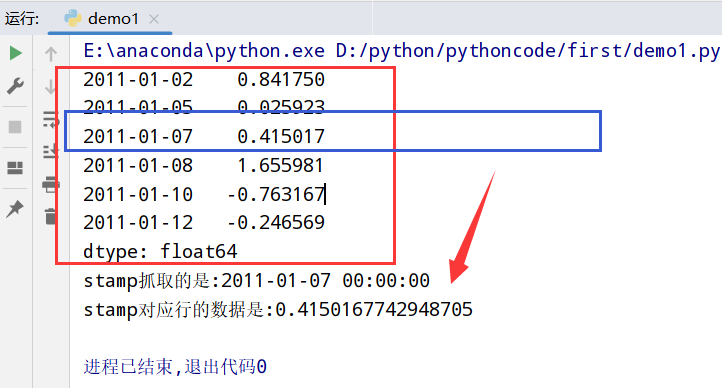
索引、选取、子集构造(和Series一致)
1 | import datetime |
日期的范围/频率/移动
生成日期范围(pandas.data_range)
1 | import datetime |
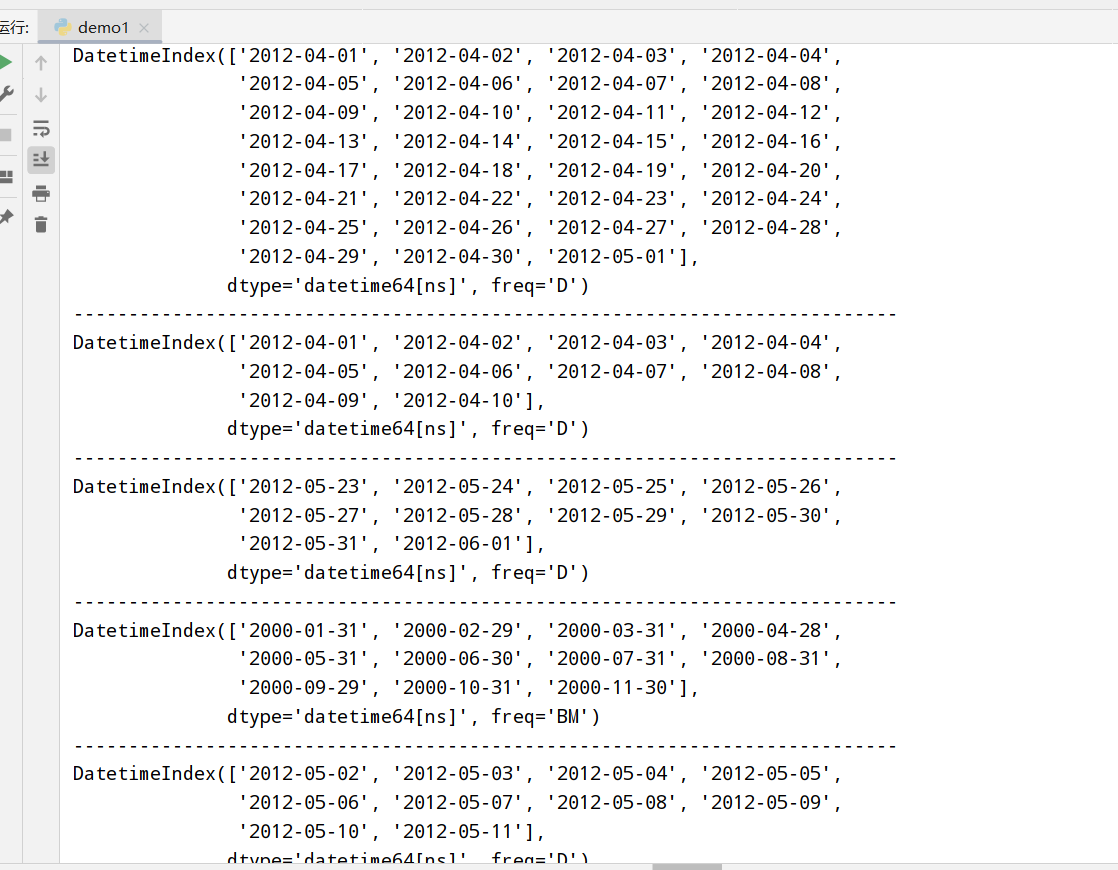
频率和日期偏移量(freq属性)
时间序列的基础频率

1 | import datetime |
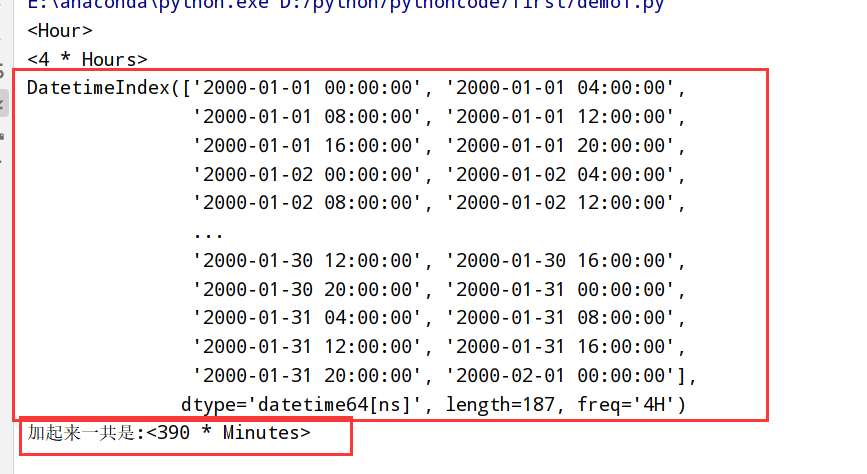
移动(超前和滞后)数据(shift方法)
1 | import datetime |
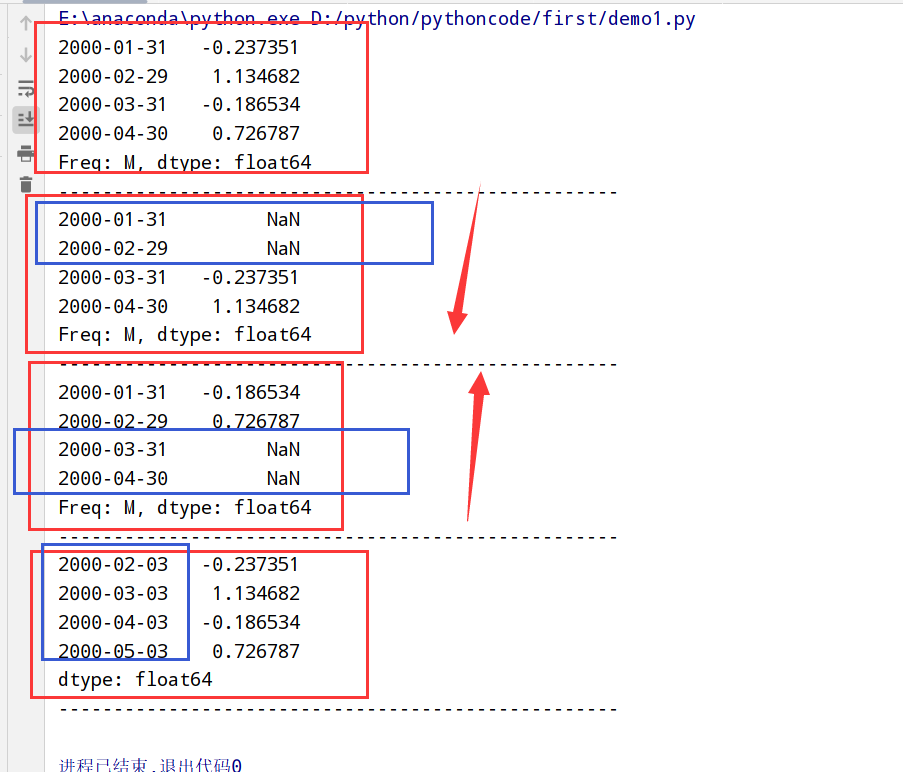
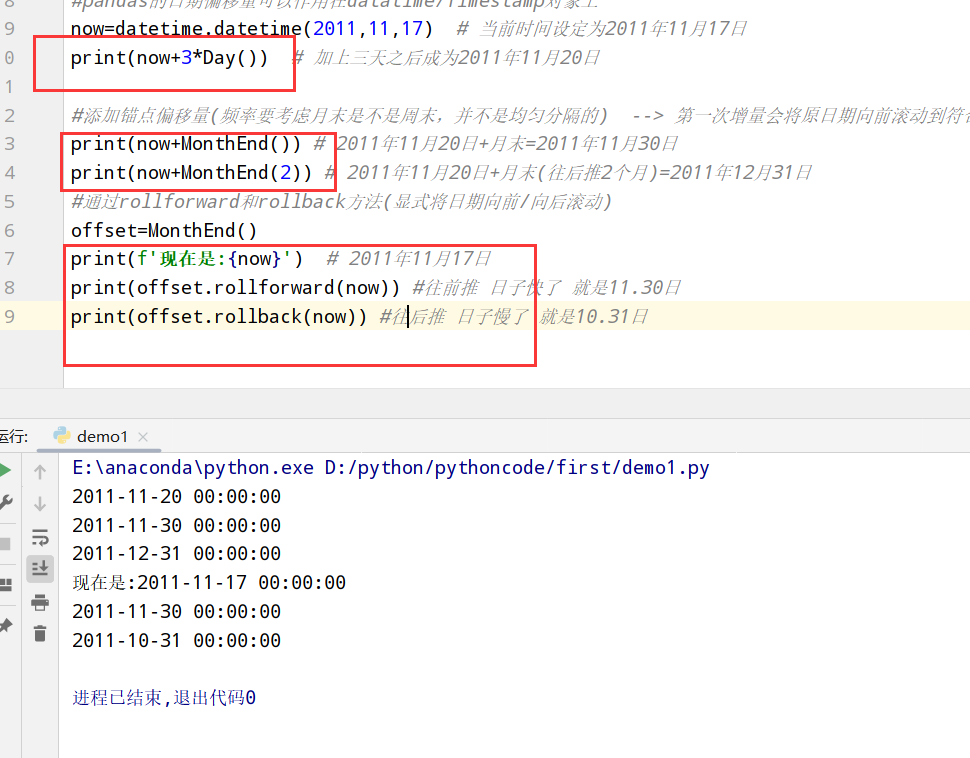
通过偏移量对日期进行位移(rollback和rollforward方法)
1 | import datetime |
时区处理(第三方库pytz)
1 | 1.在Python中时区信息来自第三方库pytz --> 使得Python可以使用Olson数据库(汇编了世界时区信息) |
pandas中的方法可以接受时区名(建议)/对象
1 | import pytz |

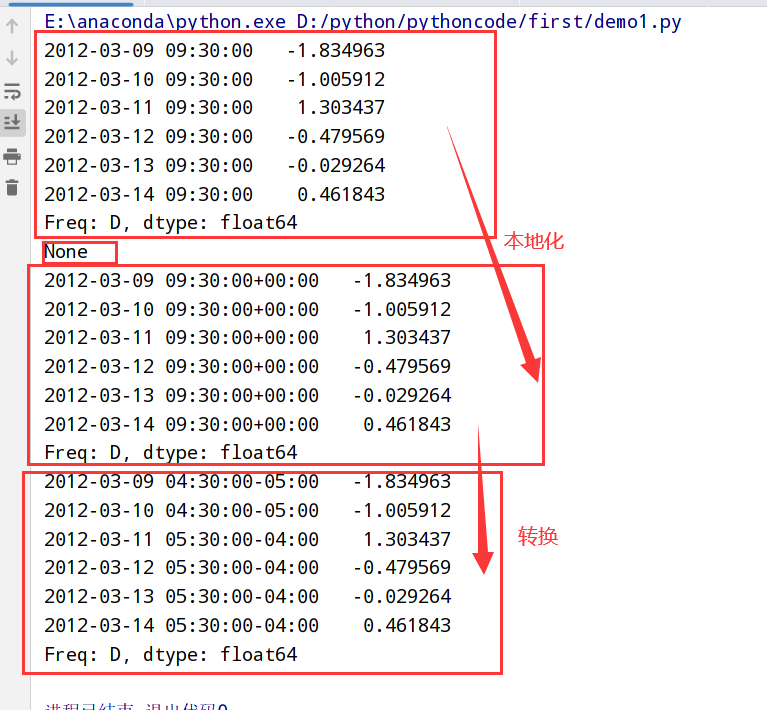
本地化(tz_localize)和转换(tz_convert)
1 | import datetime |
时期+算数运算(pd.Period类)
1 | 1.时期:时间区间(比如:数日,数月,数季,数年等) |
Period类
1 | import datetime |

时期的频率转换(asfreq方法)
1 | import datetime |
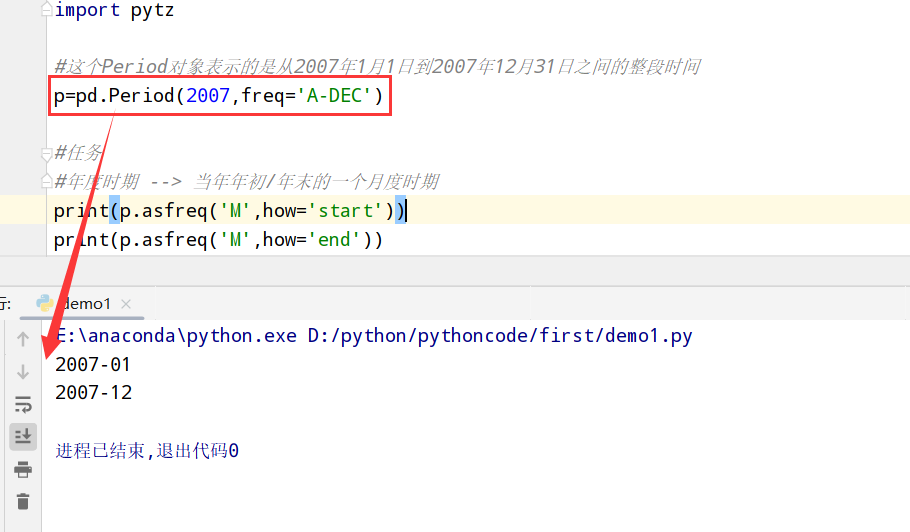
通过数组创建PeriodIndex
1 | index=pd.PeriodIndex(xxx,freq='Q-DEC') |
重采样(resampling)+频率转换
1 | 重采样(resampling):将时间序列从一个频率 --> 另一个频率的处理过程 |
重采样(resample方法)
resample方法的参数

1 | import datetime |
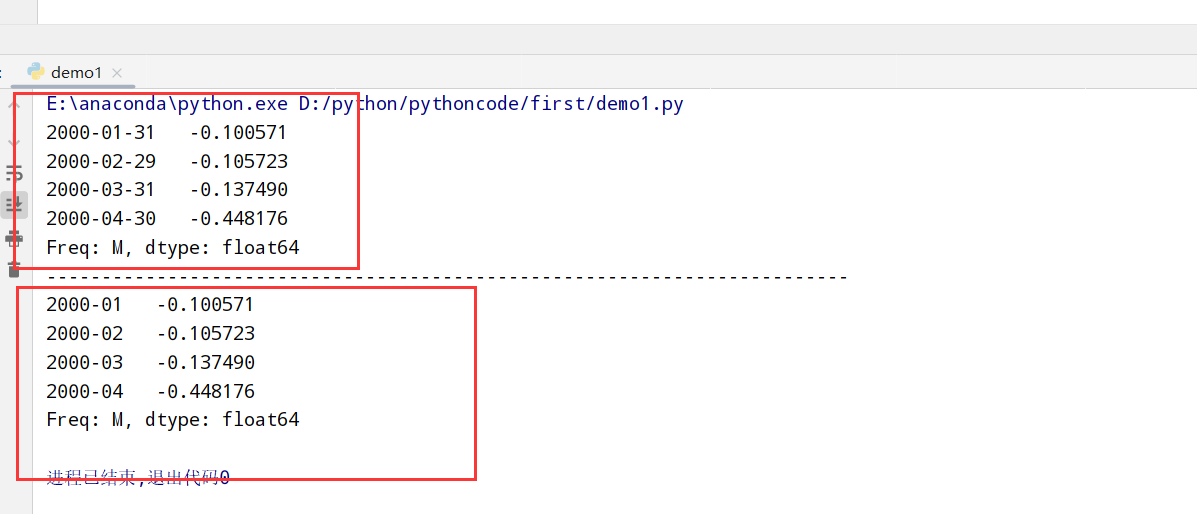
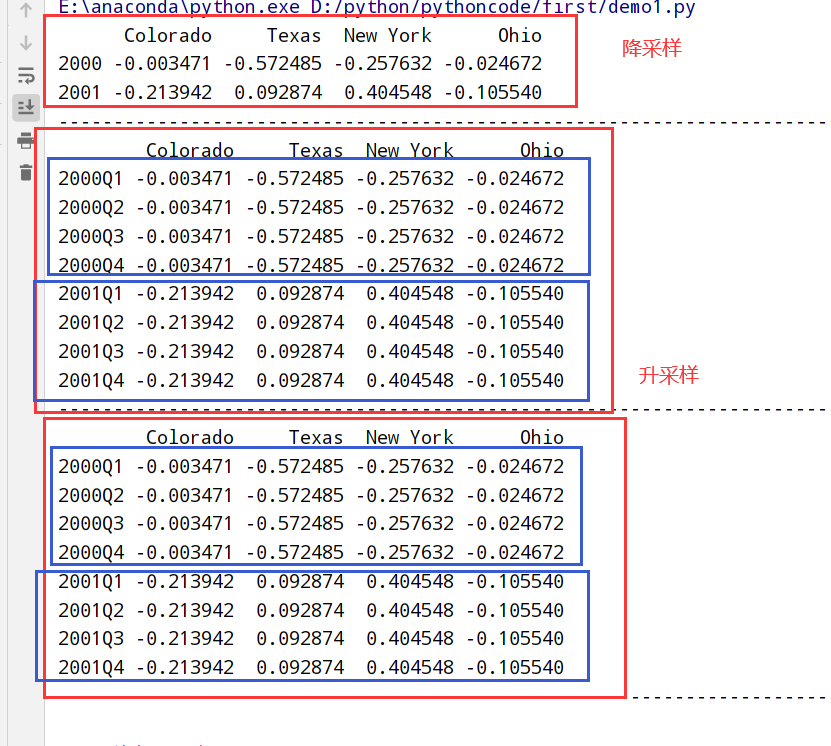
降采样(resample方法更改属性)
1 | import datetime |
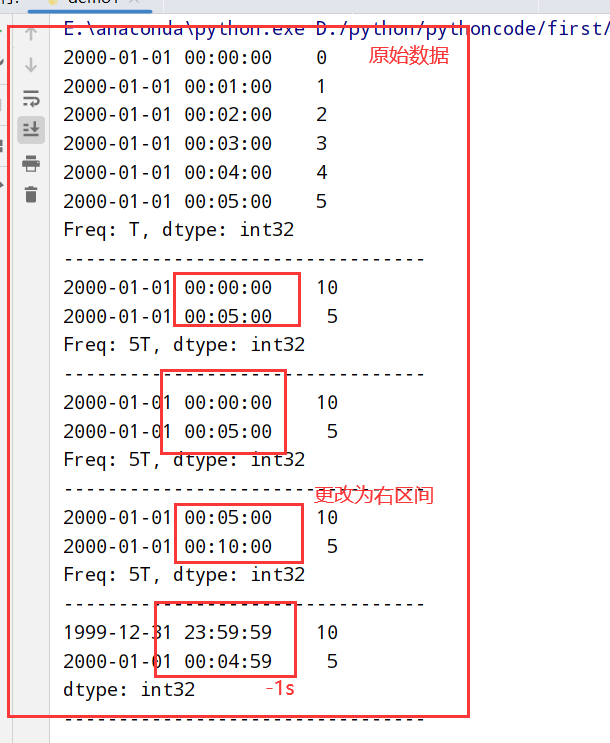
OHLC降采样(属性how=’ohlc’)
1 | import datetime |
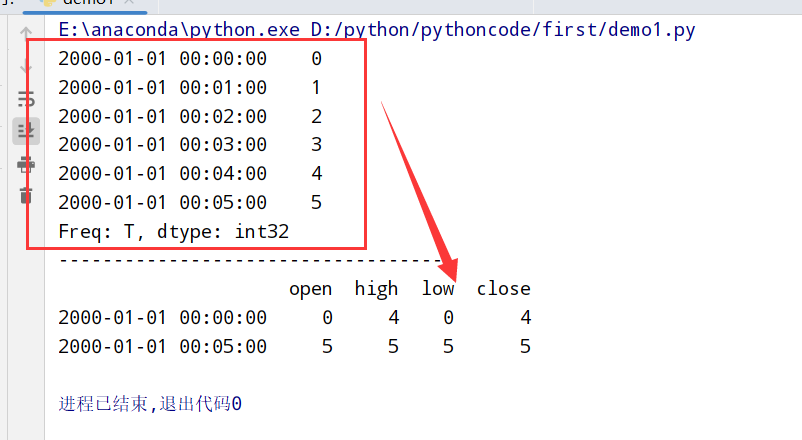
groupby降采样(groupby加上lambda字符串)
1 | import datetime |
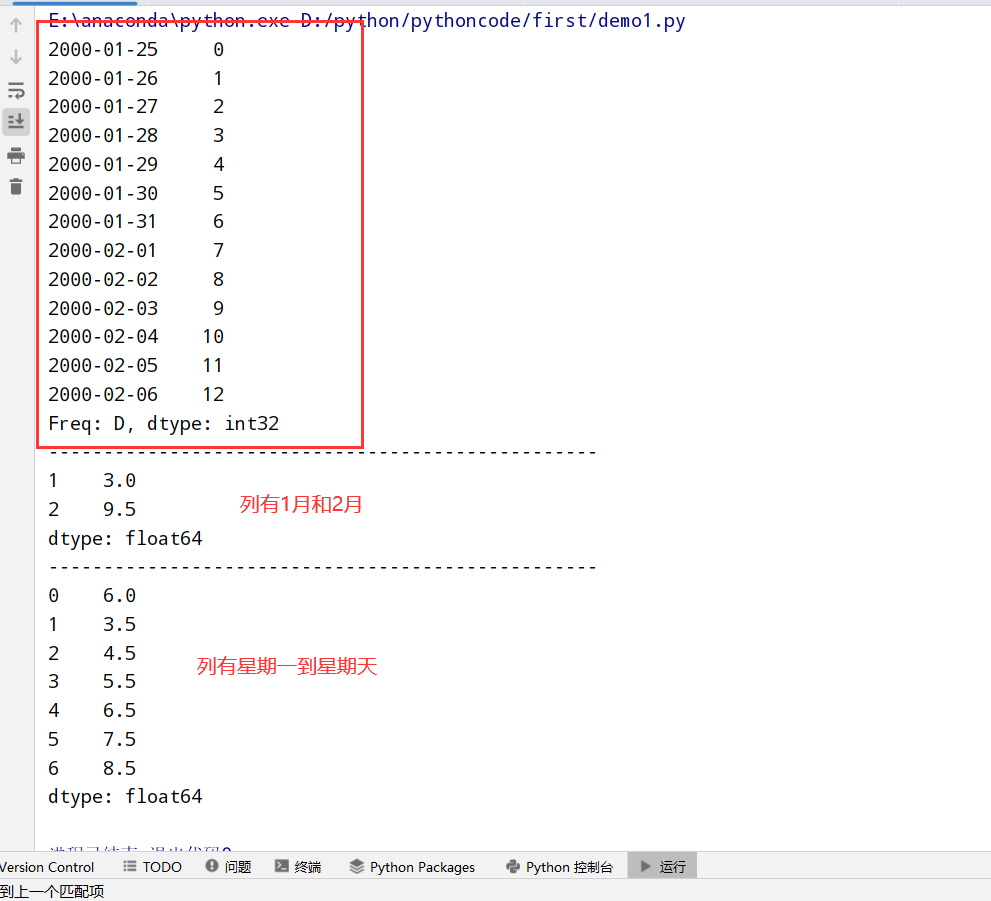
升采样和插值(fill_method属性和limit属性)
1 | import datetime |
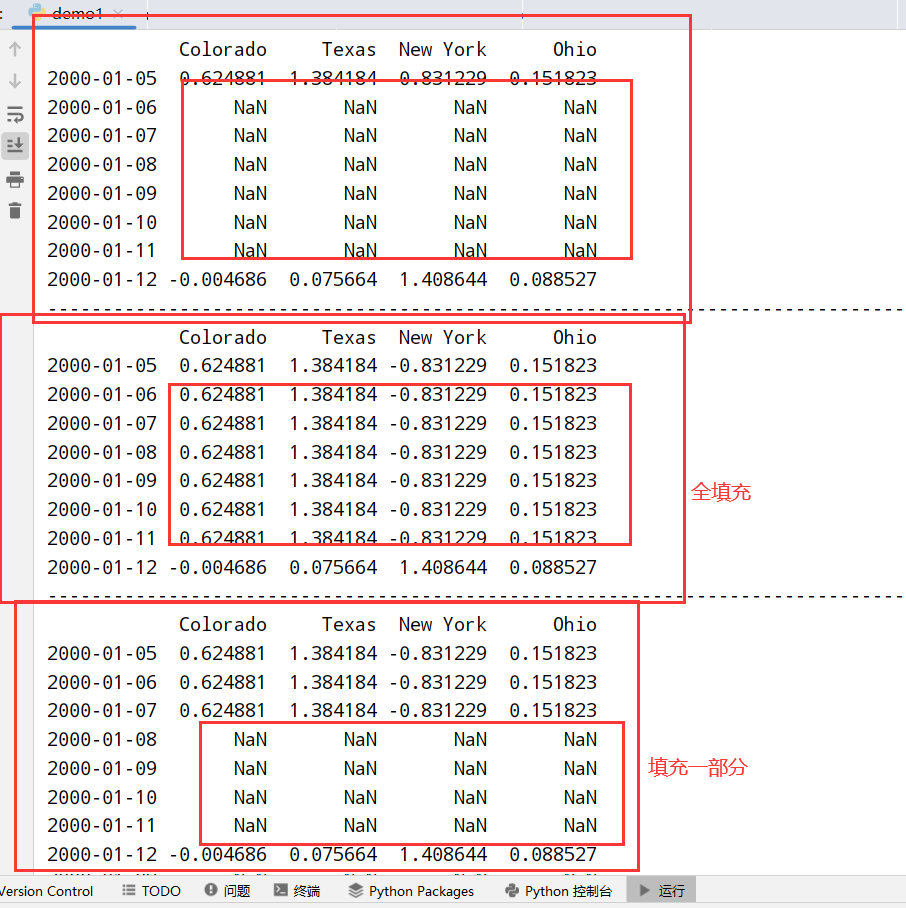
通过时期进行重采样
1 | import datetime |
移动窗口函数
移动窗口和指数加权函数:




{kind=link}
{kind=link}