1.SQL基础知识
1.1 select执行顺序
| 顺序 | 说明 | 是否必须使用 |
|---|---|---|
| select all(默认)/distinct(找不同) | 要返回的列/表达式 | 是 |
| from | 检索数据的表 | 仅仅在从表中选择数据时使用 |
| where | 行级别过滤 | 否 |
| group by | 分组说明 | 仅仅在按照组计算聚集时使用 |
| having | 组级别过滤(选分组) | 否 |
| order by asc(默认)/desc(降序) | 输出排序顺序 | 否 |
| *limit * | 输出行数(limit x,y 就是从x行输出到y行) | 否 |

1.2 选择数据库(USE指令)
输入 : USE crashcourse
输出 : Database changed1.3 展示数据库和表(SHOW指令)
1. 数据库、表、列、用户、权限等信息被存储在数据库和表中(一般内部表不让直接访问)
2. 展示数据库: show databases;
3. 展示数据库内表: show tables; (返回当前选择的数据库内可用表的列表)
4. 展示表列: show columns from XXX;
5. 展示服务器状态信息: show status
6. 展示特定数据库mysql语句: show create database
7. 展示特定表mysql语句: show create table
8. 展示授予用户安全权限: show grants
9. 展示服务器错误/警告信息: show errors / show warnings 1.4 数据模型
1.4.1 关系型数据库(RDBMS)
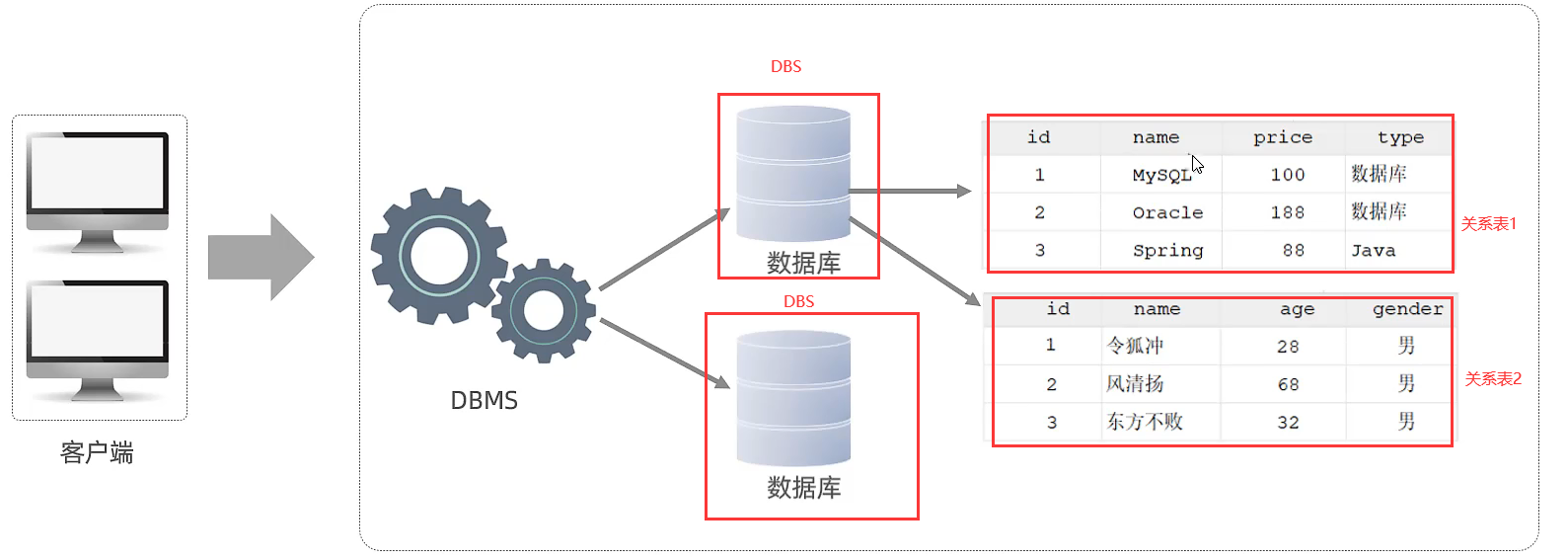
1.5 Mysql客户端启动方式
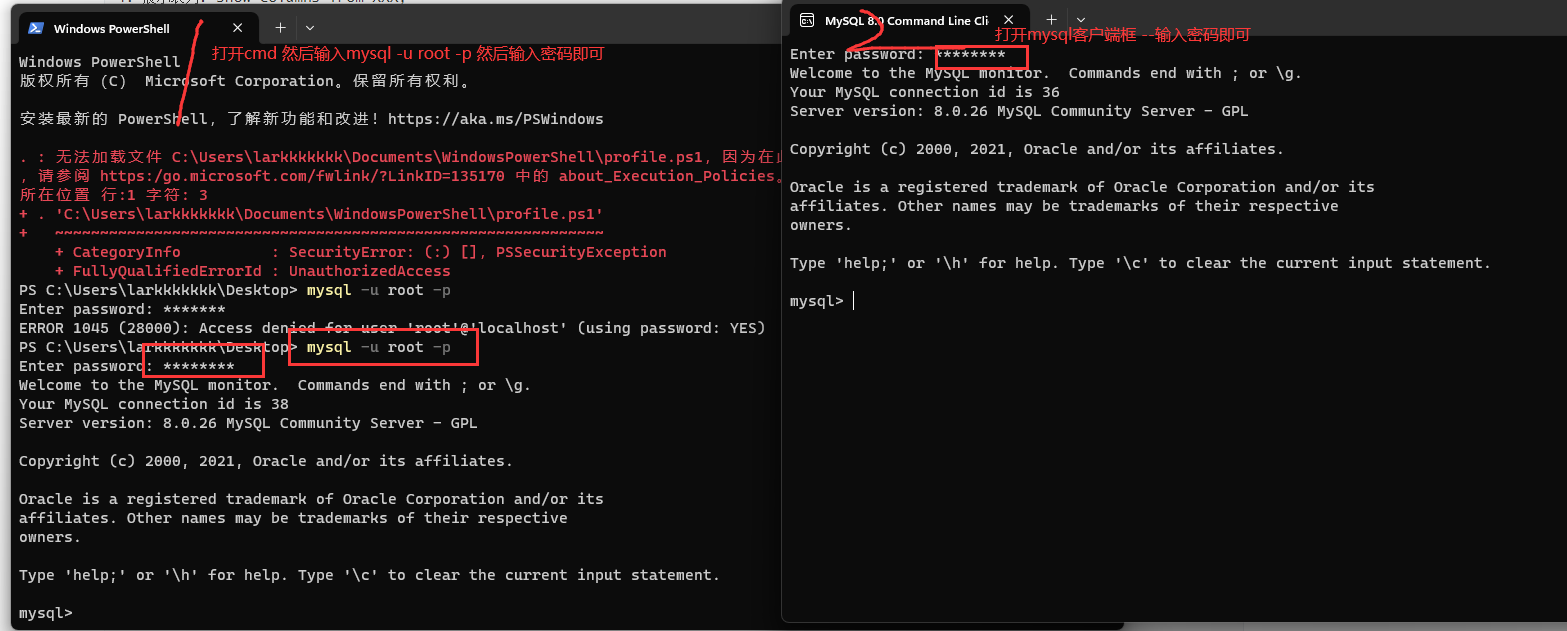
1.6 SQL通用语法和分类
1.6.1 语法

1.6.2 分类

2.SQL四大语法
2.1 DDL 数据定义语言

2.2 DML 数据操作语言

2.3 DQL 数据查询语言
2.4 DCL 数据控制语言

3.检索数据(select语句)
3.1 检索单列
//检索user表中name列
select name
from user 3.2 检索多列(逗号分隔)
//检索user表中name还有id和price列
select name,id,price
from user3.3 检索所有列(通配符[*])
//检索user表中所有列
select *
from user3.4 检索不同行的值(distinct关键字)
//检索user表中不同的name列
select distinct name
from user满足条件
1. 必须放在列名前面 --- distinct 列名
2. 只能返回不同的值(唯一)
3. 应用于所有列3.5 检索前n行(limit子句)
//检索user表中name列的前五行
select name
from user
limit 5 //不多于5行
//为得出下一个5行,可以指定要检索的开始行和行数
select name
from user
limit 5,5 //从第五行开始检索5行 注意事项
1. 行0 --- 检索出来的第一行是行0 (limit 1,1将检索出第二行)
2. 行数不够 --- 有多少输出多少
3. 替换语句: limit 4 offset 3 <--> limit 3,4 (从行3开始取4行)3.6 检索特定表的列
//检索user表内的name列
select user.name
from user排序检索数据(order by子句)
单列排序
//从user表中查name列(根据字母顺序排序)
select name
from user
order by name; //order by子句多列排序(逗号分隔)
//先对三个列查询出来之后对name和price列进行排序
select name,id,price
from user
order by name,price //首先根据名字name 然后根据价格price
//注意:
对于上述例子输出:仅在多个行具有相同的name值时才对price值进行排序(name列中所有值都是唯一,就不会按照price排序)指定排序方向(desc/asc关键字)
//desc按照Z到A降序 --
//asc按照A到Z升序(默认)
//根据价格降序排序产品(最贵的排在前面)
select price,id,name
from user
order by price desc; //根据price排序 desc说明是降序
//多个列排序
select price,id,name
from user
order by price desc,id; //只有price降序!!!
//找到列中某几个行
select price,id,name
from user
order by price desc //desc是降序(从高到低)
limit 1; //找到最贵的!!!过滤数据(where子句)
举例
//语句顺序: select -- from -- where -- order by -- limit
select distinct name //找到不同的name
from user
where name='宋亚翔' //限定找name是宋亚翔
order by name desc //根据name降序排序
limit 5,5; //从第五行开始输出五行where子句操作符

检查单值
//检测出name叫宋亚翔的一行
select name,price
from user
where name='宋亚翔';不匹配检查(不等于操作符)
//在user表中找id不是1003的结果
select id,name
from user
where id<>1003; //where id!=1003范围值检查(between)
//在user标准中找price在5-10的信息 展示名字和对应价格
select name,price
from user
where price between 5 and 10;空值检查(is null)
//检查有没有人的价格是null
select name
from user
where price is null;数据过滤(组合where子句)
多个子句就需要用and/or方式使用
and操作符
//找到名字为宋亚翔并且购买物品价格小于10的所有产品的名字和价格
select name,id
from user
where id='宋亚翔' and price<=10;or操作符
//检索名字由任一个指定叫宋亚翔或者刘伟的产品name和id
select name,id
from user
where id='宋亚翔' or id='刘伟';or和and优先级
优先级: and > or (适当给与()区分)
//两者共同使用必须用括号()区分
select name,price
from user
where (id='宋亚翔' or id='刘伟') and price>=10;in操作符(功能和or一样)
//检索名字是宋亚翔或者刘伟的信息根据name升序排序出name和price
select name,price
from user
where id in('宋亚翔','刘伟')
order by name;
//in操作符优点:
1. 使用长的合法选项清单时,in操作符的语法更清楚而且直观
2. 使用in操作符,计算次序更容易管理
3. in操作符速度执行更快
4. in能动态建立where子句not操作符
//检索名字除宋亚翔和刘伟之外的所有信息根据name升序排序出name和price
select name,price
from user
where id not in('宋亚翔','刘伟')
order by name;通配符过滤(like操作符)
%(0-n个字符)
百分号%可以匹配0/1/n个字符(不能匹配null)
//找到jet起头的产品
select id,name
from user
where name like 'jet%'; //找到 jetxxxx 形式
//找到jet在中间的产品
select id,name
from user
where name like '%jet%'; //找到 XXXjetxXX 形式_(单个字符)
下划线_总能匹配一个字符(不能多也不能少)
//找到jet前面有一个字符的结果 (1jet 2jet等等)
select id,name
from user
where name like '_jet'; //找到 Xjet形式正则表达式搜索(regexp)
正则表达式用来匹配文本特殊的串(字符集合)
基本字符匹配(‘X’)
//检索列name包含文本1000的所有行
select name
from user
where name regexp '1000' //regexp替换了like位置
//where name regexp '.1000' //匹配任意一个字符(1000S 2000)
order by name;
//总结
1. 使用关键字regexp --> like
2. 匹配不区分大小写: 可以使用binary区分大小写(默认不区分)
3. . 用于匹配单个字符进行or匹配( | )
//匹配1000或者2000的结果
select name
from user
where name regexp '1000|2000'
order by name;匹配单个字符([])
[] 等价于 | 等价于 or (三者都是)
//匹配1或者2或者3
select name
from user
where name regexp '[123]Ton' //[123]Ton是[1|2|3]Ton缩写
order by name;匹配一个/多个字符( - )
//匹配0到9 [0123456789]等价于[0-9]
select name
from user
where name regexp '[1-9]Ton' //匹配数字0到9
order by name;匹配特殊字符( \\前导 )
// \\-表示查找-
select name
from user
where name regexp '\\-'
order by name; 找特殊字符必须要\转义(表示后面的字符当做普通字符被识别)
![]()
匹配字符类

匹配多个实例

// 第一个\\引导匹配特殊字符
// [0-9]就是匹配任意数字
// sticks?就是匹配stick或者sticks (?是匹配前面任何字符的0/1次)
select name
from user
where name regexp '\\([0-9] sticks?\\)'
order by name; 定位符(匹配一个串中任意位置文本)
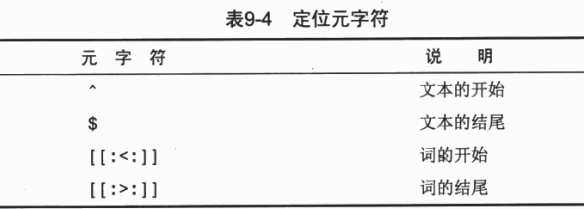
//匹配以一个数(包括小数点开始的数字)开始的所有产品
//简单搜索[0-9\\.]不行 必须要用^定位符
// where name regexp '^[0-9\\.]'计算字段
运行时在select语句内创建
1. 字段(field) 基本上和列意思相同
2. 数据库可以区分哪些列是实际的表列,哪些是计算字段
3. 客户机(应用程序)计算字段的数据和其他列数据相同方式返回拼接字段(Concat()函数)
将值联结到一起构成单个值
//多数DBMS使用 + 或者 || 实现拼接
//使用拼接从user表根据name升序排序 输出格式是 name(price)
select Concat(name,'(',price,')')
from user
order by name;
//例如:
宋亚翔(1200)
张三(230)删除数据右侧多余空格(RTrim()函数)
//拼接基础上删除右侧多余空格
select Concat(RTrim(name),'(',RTrim(price),')')
from user
order by name;别名/导出列(AS关键字)
一个字段/值的替换名
//拼接之后删除多余空格的字段 给个songyaxiang的别名就可以引用
select Concat(RTrim(name),'(',RTrim(price),')') AS songyaxiang
from user
order by name;算术计算

//输出price和num乘积
select price*num
from user
where name='宋亚翔';数据处理函数
文本处理函数

//Soundex()函数就是匹配发音相似的函数
//现在user表里面有个人叫宋亚翔 其联络名叫laekkkkkkk(如果输入错误,实际应该是larkkkkkkk)
select name,lianluoming
from user
where Soundex(lianluoming)=Soundex(larkkkkkkk);
//因为larkkkkkkk和laekkkkkkk发音相似,所以Soundex值匹配日期和时间处理函数
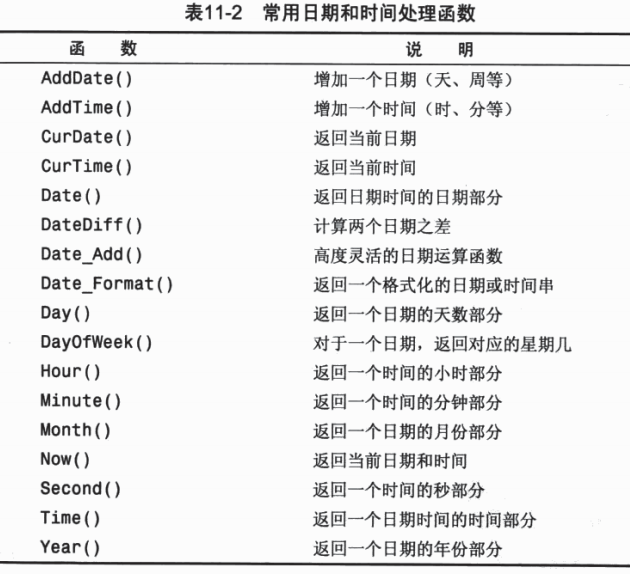
数值处理函数
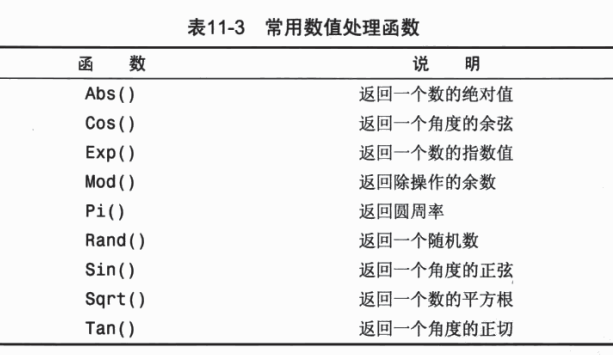
汇总数据
聚集函数(5个)
运行在行组上,计算和返回单值
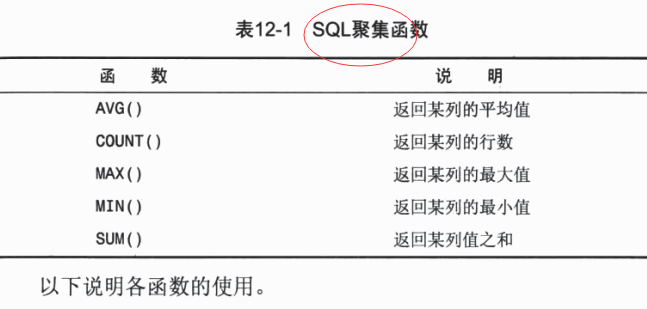
avg()某列平均值
通过对表中行数计数并计算特定列值之和,求该列平均值
//从user表中找到价格price列的平均值 结果起个jiage的别名
select avg(price) as jiage
from user;
//计算特定列/行的平均值(where语句确定)
//从user表中找到名字叫宋亚翔的所有价格price列的平均值 结果叫jiage别名
select avg(price) as jiage
from user
where id='宋亚翔';count()某列行数和
1. 使用count(*)对表中行的数目进行计数(不管列中包含的是null还是非空值)
2. 使用count(column)对特定列中具有值得行进行计数(忽略null值)
//从user表中记录所有用户总数 结果给zongshu这个别名
select count(*) as zongshu
from user;max()某列最大值
//从user表中找到最大价格price行 结果给max这个别名
select max(price) as max
from user;min()某列最小值
//从user表中找到最小价格price行 结果给min这个别名
select min(price) as min
from user;sum()某列总和
//从user表计算price总和 结果给sum这个别名
select sum(price) as sum
from user;聚集不同值(distinct/all)
1. all(默认) 所有的行执行计算
2. distinct() 只包含不同的值 必须用于列名组合聚集函数(select子句)
//使用四个函数
//从user表中算出行总数 最大最小和平均价格并且给与别名
select count(*) as count,
min(price) as min,
max(price) as max,
avg(price) as avg
from user;分组数据(group by和having子句)
创建分组(group by子句)
分组在select语句的group by子句中建立
//计算每个id对应的产品个数
//例如: 宋亚翔有7个产品 刘伟有3个产品
select id,count(*) as count
from user
group by id //根据id分组
order by id; //根据id升序
// 书写顺序:
group by
having
order by
limit过滤分组(having子句)
//where过滤行,having子句过滤分组
//从orders表中查找每个id和总数 然后按照id升序排序 给结果的每行给别名orders
//主要是我们只要count大于等于2的结果
select id,count(*) as orders
from orders
group by id
having count(*)>=2;分组(group by)和排序(order by)区别

//检索总计订单价格大于等于50的订单的订单号和总计订单价格
select id,sum(quantity*price) as jiage
from user
group by num //根据num分组
having sum(quantity*price)>=50 //过滤分组
order by price; //根据价格升序排序子查询(嵌套在其他查询中的查询)
//说明情况:
orders表: 每个订单(订单号,客户ID,订单日期)
customers表: 实际的客户信息
orderitems表:各订单的物品存储
//子查询执行顺序:
从内向外处理利用子查询过滤
两个以上select语句嵌套作为计算字段使用子查询
//问题:
需要显示customers表中每个客户的订单总数
(订单和相应的客户ID存储在orders表)
//1. 从customers表中检索客户列表
//2. 对于检索出来的客户,统计其在orders表中订单的数目
//1.对客户10001的订单进行计数
select count(*) as orders
from orders
where id=10001;
//2.为了对每个客户执行count(*)计算,应该作为一个子查询
select name,state,(select count(*)
from orders
where orders.id=customers.id) as orders
from customers
order by name;相关子查询(涉及外部查询的子查询)
联结表(多表联系)
关系表
主键(primary key) : 唯一的标识
外键(foreign key) : 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之前的关系笛卡尔积(乘积)
由没有联结条件的表关系返回的结果(h表1*h表2)表别名
1. 列起名(select子句) + 表别名(from子句)
//列别名
select count(*) as jia //结果起别名叫jia
from user
where id='宋亚翔';
//表别名
select name,price
from customers as c,orders as o,orderitems as oi //给三个表起别名
where c.id=o.id and oi.num=c.num; //where子句直接就用了别名不同类型的联结(四种联结)
1. 内部联结/等值联结(简单联结)
2. 自联结
3. 自然联结
4. 外部联结
4.1 左外部联结
4.2 右外部联结 组合查询(union操作符)
并(union)/复合查询
//使用组合查询条件:
1. 在单个查询中从不同的表返回类似结构的数据
2. 对单个表执行多个查询,按单个查询返回数据创建组合查询(union操作符)
只是给出每条select语句,在各条语句之间放入关键字union
//价格<=5的所有物品的一个列表 + 包括供应商1001和1002生产的所有物品(不考虑价格)
//分开写select语句
//1. 找到价格<=5的所有物品的一个列表
select id,price
from products
where price<=5;
//2. 找到供应商1001和1002生产的所有物品
select id,price
from products
where id in(1001,1002);
//3. 组合两条语句
select id,price
from products
where price<=5;
union
select id,price
from products
where id in(1001,1002);
//4. 使用多条where子句
select id,price
from products
where price<=5 or id in(1001,1002);union规则
1. 必须两条以上的select语句组成
2. union中的每个查询必须包含相同的列,表达式或者聚集函数
3. 列数据类型必须兼容(不必完全相同,DBMS可以隐含转换的类型)包含重复行(union all)
查询结果集中自动去除重复行(和多个where子句组合一样)
组合查询结果排序(必须在最后一条select语句之后)
只能使用一条order by子句(但是排序却在所有select语句中起作用)

全文本搜索(比like和正则表达式更好!)
全文本搜索(建表时启用)
并非所有引擎都支持全文本搜索
1. MyISAM(5.5以前)
支持全文本搜索(√)
2. 和InnoDB(5.5以后)
不支持全文本搜索(×)启用全文本搜索支持(fulltext子句)
创建表的时候使用fulltext子句
//create table语句接受fulltext子句(给出被索引列的一个逗号分隔的列表)
create table user
(
note_id int not null
pro_id char(20) not null,
note_date datetime not null,
note_text text null,
primary key(note_id),
fulltext(note_text) //mysql根据fulltext子句指示给它进行索引,进行全文本搜索(索引会根据数据改变重新索引)
)ENGINE=MyISAM; //myisam引擎支持全文本搜索执行全文本搜索(Match()和Against()函数)
select的时候使用match()和against()函数
1. Match()指定被搜索的列
2. Against()指定要使用的搜索表达式
//检索单列
select note_text
from productnotes
where match(note_text) against('rabbit');
//match(note_text)表明mysql针对note_text列进行搜索
//against('rabbit')表明对制定此rabbit作为搜索文本搜索
注意:
match()里面的值必须和fulltext()里面的值相同(指定多列必须列出多列次序也要正确)
like匹配和全文本搜索对比
1. 全文本搜索可以对结果进行排序(较高等级的行先返回)
2. 全文本搜索中数据是索引的,速度v更快查询扩展(搜索相关结果 with query expansion)
能找到可能相关的结果,即使他们并不精确包含所查找的词
//检索note_text列里面和rabbit相关的
select note_text
from productnotes
where match(note_text) against('anvils' with query expansion);布尔文本搜索(in boolean mode)
不需要全文本搜索需要建立fulltext索引
1. 要匹配的词
2. 要排斥的词(如果某行包含这个词,则不返回该行,即使它包含其他指定的词也是如此)
3. 排列提示(更重要的词等级更高)
4. 表达式分组
5. 另外一些内容全文本布尔操作符

//匹配包含heavy但不包含任意以rope开始的词
// -排除一个词(词必须不出现!) *是截断操作符
select note_text
from productnotes
where match(note_text) against('heavy -rope*' in boolean mode)
全文本搜索使用说明
1. 许多次出现评率很高,搜索他们没有用处(返回太多结果)
1.1 所以规定一条50%规则(不用于in boolean mode): 如果一个词出现在50%以上的行,将它作为一个非用词忽略。
2. 如果表中行数<3:全文本搜索不返回结果
3. 忽略词中的单引号(don't索引为dont)
4. 不具有词分隔符(包括日语和汉语)的语言不能恰当地返回全文本搜索结果
5. mysql带有一个内建的非用词(stopword)列表,这些词在索引时候被忽略(出现次数50%以上) 如果想用就覆盖这个列表
6. 在索引全文本数据时,短词被忽略而且要从索引中排除(短语是具有<=3个字符的词)插入数据(insert语句)
提高整体性能(low_priority)

插入单行
//不安全(高度依赖于列定义次序)
insert into customers
values(null,'123','15009272737',null);
//安全但是麻烦(说明自定义的次序和对应值)
insert into customers(id,glass,num,country)
values(null,'123','15009272737',null);插入多行
1. 第一个insert语句;第二个insert语句;
insert into user()
values();
insert into user()
values();
2. values语句(),(); -- 单条insert语句处理多个插入性能更好!!
insert into user()
values(),();插入检索出的数据(insert select)
一条insert语句和一条select语句组成
从另一表中合并客户列表到你的customers表,将它用insert插入
insert into customers(id,contact,email,name,address,city,state,zip,country)
select id,contact,email,name,address,city,state,zip,country
from custnew;更新数据(update语句)
1. 更新表中特定行(update set where)
2. 更新表中所有行(update set )更新特定行(where子句要有)
更新单列信息
//客户10005现在有了电子邮件地址,因此它的记录需要更新
update customers
set email='134506293@qq.com'
where id=10005;更新多列信息:(逗号分隔)
igonre关键字:保证就算发生错误,也继续更新!!!
//客户10005不仅有了电子邮件地址,而且有了班级信息
update ignore customers //ignore保证就算发生错误,也继续更新!!!
set email='134506293@qq.com',class='软件工程';
where id=10005;更新所有行(where子句没有)
//将所有人的邮箱都改成134506293@qq.com
update customers
set email='134506293@qq.com'删除某个列的值(set设置null)
//将10005客户的邮箱一栏删除 就是删除列的信息
update customers
set email=null
where id=10005;删除数据(delete)
delete从表中删除行(不删除表本身)
1. 从表中删除特定行()
2. 从表中删除所有行()删除特定行
//删除customers表中客户10005的信息
delete
from customers
where id=10005; //删除的是行(删除列是update中set设置null)删除所有行()
//删除customers表中所有行信息
delete
from customers更快删除所有行(truncate table)
删除原来表并且重新创建一个表
输入: truncate table
速度比delete语句删除所有行速度更快创建表(create table)
创建表方式(2种)
1. 使用具有交互式创建和管理表的工具(navicat)
2. 使用mysql语句操纵(create table语句)null值(建表默认null)
null值是没有值,不是空串
//创建orders表
create table orders
(
order_num int not null,
order_date datetime not null,
cust_id int not null,
primary key(order_num)
)ENGINE=InnoDB;auto_increment(自动增量)
一个表只允许一个auto_increment列,而且它必须索引(主键)
指定默认值(default关键字)
如果在插入行时没有给出值,mysql会使用默认值(不是null值)引擎类型(engine)
引擎具体创建表,隐藏在DBMS中
1. MyISAM (5.5以前) --性能极高引擎
支持全文本搜索
不支持事务处理
2. InnoDB (5.5以后) --可靠的事务处理引擎
不支持全文本搜索更新表(alter table)
给表添加一个列
alter table user
add id char(50);定义外键
alter table user
add constraint orders foreign key(order_num) references orders(order_num)删除表(drop table)
//删除表(删除的不是内容)
drop table user;重命名表(rename table)
多个表重命名用逗号隔开
//给user表换成usertwo名
rename table user to usertwo;视图(MYSQL5出现)
视图规则和限制
1. 试图必须唯一命名(不能和其他试图/表相同名字)
2. 试图数目没有限制
3. 创建视图必须由足够访问权限(数据库管理人员授予)
4. 试图可以嵌套(从其他试图中检索数据的查询来构建)
5. 试图可以使用order by排序
6. 试图不能索引/触发器/默认值
7. 试图可以和表一起使用视图SQL语句(create view)
1. 创建视图: create view
2. 查看创建视图的语句:show create view name
3. 删除视图: drop view name
4. 更新视图: 先drop然后再create / create or replace view 简化联结(查询可从视图找)
//创建一个名为productcustomers的视图
//联结三个表,返回已订购任意产品的所有客户的列表
create view productcustomers as
select cust_name,cust_contact,prod_id
from customers,orders,orderitems
where customers.cust_id=orders.cust_id and orderitems.order_num=orders.order_num;
//建立了视图(虚表),可以使用select语句查询任意产品的客户
select *
from productcustomers //从视图中查询存储检索结果方便查找
//单个组合计算列中返回供应商名和位置
//Concat是拼接函数 RTrim删除右边多余空格
select Concat(RTrim(name),'(',RTrim(country),')') as hhh //拼接结果起别名为hhh
from vendors //从vendors表
order by name; //根据名字name升序排序
//假设经常需要这个格式的结果,不必每次需要时候执行联结,可以创建一个视图,需要使用的视图即可
create view shitu as //添加视图名shitu
select Concat(RTrim(name),'(',RTrim(country),')') as hhh //拼接结果起别名为hhh
from vendors //从vendors表
order by name; //根据名字name升序排序
//之后使用就select查找shitu即可
select *
from shitu;过滤数据
应用于普通的where子句也很有用
//过滤没有电子邮件地址的客户
create view noemail as
select id,name,email
from customers
where email is not null; //where限定找到没有eamil的用户简化计算字段使用
之前的所有操作得到的结果赋给一个视图,然后每次查找去找视图即可(简化数据处理)更新视图(一般用于select语句)
视图可以更新,更新视图将更新其基表
更新视图条件
1. 由于视图本身是虚表(没有数据)所以还是对基表进行增删查改
2. 有以下操作则不能更新:
1. 分组(group by和having)
2. 联结
3. 子查询(嵌套select语句)
4. 并(union)
5. 聚集函数(min()/max()/count()/avg()/sum())
6. distinct(保证唯一)
7. 计算列(select语句有计算)存储过程(MySQL5出现)
为以后使用而保存的一条/多条Mysql语句的集合
创建存储过程(create procedure语句)
//一个返回产品平均价格的存储过程
create procedure productpricing() //创建存储过程名字为productpricing
begin
select avg(price) as priceaverage //起别名为priceaverage
from products;
end;参数
存储过程并不显示结果,只是把结果返回给你指定的变量
变量(variable)
//in 传递给存储过程
//out 从存储过程传出给调用者
//inout 对存储过程传入和传出
//创建有参数的存储过程
create procedure productpricing(
out p1 decimal(8,2), //out用来从存储过程传出一个值(返回给调用者)
out ph decimal(8,2),
out pa decimal(8,2),
)
begin
select min(price) //p1存储产品最低价格
into p1 //into插入
from products;
select max(price) //ph存储产品最高价格
into ph
from products;
select avg(price) //pa存储产品平均价格
into pa
from products;
end;
//调用productpricing存储过程(必须制定三个变量名)
//变量必须以@开始!!!!!!!!!!!!
call productpricing(@pricelow,@pricehigh,@priceaverage);使用存储过程(call语句)
//执行刚创建的存储过程并显示返回的结果(存储过程实际上是一种函数,所以调用要有()符号)
call productpricing();执行存储过程(call语句)
//执行名字叫productpricing的存储过程,并且返回产品的最低、最高和平均价格
call productipricing(@pricelow,@pricehigh,@priceaverage);删除存储过程(drop procedure语句)
创建之后被保存在服务器上以供使用,直到被删除
//删除刚创建的存储过程
drop procedure productpricing (if exists);建立智能存储过程
目前使用的所有存储过程基本上是封装mysql简单的select语句
检查存储过程(show create procedure语句)
//展示ordertotal存储过程
show create procedure ordertotal;
//展示存储过程何时、谁创建等详细信息的存储过程列表
show procedure status (like 'xxx'); //like制定过滤模式游标(cursor)
存储在mysql服务器上的数据库查询,是select语句检索出来的结果集
游标适用范围
1. mysql游标只能用于存储过程(上章讲解)和函数
2. mysql游标主要用于交互式应用,可以根据需要滚动/浏览其中的数据游标使用步骤
1. 使用前必须定义要使用的select语句
2. 一旦定义,必须打开游标以供使用(用定义好的select语句把数据实际检索出来)
3. 对于填有数据的游标,根据需要取出索引各行
4. 游标使用结束之后,必须关闭游标创建游标(declare)
//定义名为ordernumbers的游标,使用检索所有订单的select语句
create procedure processorders() //创建processorders存储过程
begin
declare ordernumbers cursor //创建游标
for
select order_num //select语句
from orders;
end;打开/关闭游标(open cursor语句)
//打开ordernumbers游标
open ordernumbers;
//关闭ordernumbers游标
close ordernumbers; //释放游标使用的所有内部内存和资源使用游标数据(fetch语句)
//从游标中检索单行(第一行)
create procedure processorders() //创建存储过程
begin
declare o int; //局部声明的变量
declare ordernumbers cursor //创建游标
for
select order_num //书写的select语句
from orders;
open ordernumbers; //打开游标
fetch ordernumbers //检索当前行的order_num列到一个名为0的局部声明的变量中
into o; //插入o游标
close ordernumbers; //关闭游标
end;
//循环检索数据(从第一行到最后一行)
create procedure processorders() //创建存储过程
begin
declare done boolean default 0;
declare o int;
declare ordernumbers cursor //定义游标
for
select order_num
from orders
declare cotinue handler for sqlstate '02000' set done=1;
open ordernumbers; //打开游标
repeat
fetch ordernumbers
into o;
until done end repeat; //反复执行到done为真
close ordernumbers; //关闭游标
end; 触发器(MYSQL5支持)
响应增删改三种语句而自动执行的一条mysql语句
触发器定义条件
1. 只能按照每个表每个事件每次地定义(每次只能有一个)
2. 每个表最多支持6个触发器(增删改的之前和之后)
3. 如果需要对一个insert和update操作执行,就必须要定义两个
4. 触发器不能识别执行存储过程的call语句(需要的存储过程代码需要复制到触发器内)创建触发器(create trigger)
只有表支持触发器(视图和临时表也不可以)
//创建newproduct的新触发器
create trigger newproduct //创建触发器名
after insert on products //定义是插入语句成功执行后执行
for each row //定义每个插入行执行
select 'chenggong'; //对每个成功的插入显示成功的消息删除触发器(drop trigger)
//删除刚才的newproduct触发器
drop trigger new product;使用触发器(三类六种)
insert触发器(NEW虚拟表)
1. insert触发器代码中,可引用一个名字叫NEW的虚拟表(访问被插入的行)
2. 在before insert触发器中,new的值可以被更新
3. 对于auto_increment列,new在insert执行之前包含0,insert执行之后包含新的自动生成值
//创建一个名叫neworder的触发器 按照after insert on orders执行
create trigger neworder
after insert on orders //插入一个新订单到orders表
for each row
select new.order_num; //mysql生成一个新订单号保存到order_numdelete触发器(OLD虚拟表)
1. delete触发器代码中,可引用一个名字叫OLD的虚拟表(访问被删除的行)
2. OLD中的值全是只读,不能更新
//创建一个名叫deleteorder的触发器
create trigger deleteorder
before delete on orders //插入一个新订单到orders表
for each row
begin
insert into achive_orders(num,data,id)
values(OLD.num,OLD.data,OLD.id)
end;
//用一条insert将要删除的订单保存到achive_orders表update触发器(OLD虚拟表)
1. update触发器代码中,可引用一个名字叫OLD的虚拟表访问更新的值
2. before update触发器中,new的值可能会被更新
3. OLD中的值全是只读,不能更新管理事务处理(commit和rollback语句)
MYSQL5.5以后支持的InnoDB引擎支持事务管理
事务知识点
事务(transaction) : 一组sql语句
回退(rollback) : 撤销指定sql语句的过程
提交(commit) : 将未存储的sql语句结果写入数据库表
保留点(savepoint) : 事务处理中设置的临时占位符,你可以对它发布回退事务开始
会在commit/rollback语句执行后,事务自动关闭
start transactionrollback命令回退
只能增删改语句(create/drop不能回滚)
//举例
select *
from ordertotals; //展示ordertotals表内信息
start transaction; //打开事务
delete
from ordertotals; //删除ordertotals表中所有行
select *
from ordertotals; //检验是否为空
rollback; //回滚打开事务之后的所有语言
select *
from ordertotals; //显示该表不是空(回滚成功!)commit语句
//事务处理块中,必须明确提交(使用commit语句)
start transaction; //事务开始
delete
from order //从order表中删除订单20010
where num=20010;
delete
from orders //从orders表中删除订单20010
where num=20010;
commit; //提交保留点(savepoint)
设置保留点进行部分提交/回滚
//设置保留点
savepoint d1;
//回滚到d1点
rollback to d1;
保留点越多越好:
更加灵活地进行回退
释放保留点(事务处理完成后自动释放)
release savepoint(mysql5之后)更改默认的提交行为(autocommit自动提交)
//mysql默认是自动提交所有更改
//为了让mysql不自动提交更改
set autocommit=0;全球化和本地化
字符集(character)和校对顺序(collation)
//重要术语:
字符集: 为字母和符号的集合
编码: 为某个字符集成员的内部表示
校对 : 为规定字符如何比较的指令(影响排序和搜索)
//决定级别:
服务器/数据库/表级进行字符集和校对顺序(sql语句)
//显示所有可用的字符集和每个字符集的描述和默认校对
show character set;
//查看所支持校对的完整列表
show collation;
//修改所用的字符集和校对
show variables like 'character%';
show variables like 'collation%';
//建表时设置字符集和校对
create table user
(
id int,
name varchar(10)
)default character set hebrew
collate hebrew_general_ci;
//以下三种情况:
1. 如果两个都设置,就使用这些设置
2. 只设置字符集,则使用字符集默认的校对
3. 如果两个都没设置,则使用数据库默认安全管理
管理用户(存储在名mysql数据库中)
//需要获取所有用户账号列表
use mysql; //进入mysql数据库
selet user
from user; //从user数据库中查找user(结果是root)创建用户账号(create user)
//创建用户名为song
create uesr song (identified by 'p@$$w0rd');
//identified by 'p@$$w0rd' 纯文本指定口令
//identified by password 散列值指定口令重命名用户账号(rename user)
//将上面的song用户改名为ya
rename user song to ya;删除用户账号(drop user)
//删除上面的ya用户(5以后也删除相关权限)
drop user ya;
//5之前只能删除用户账号
1. 先用revoke删除相关权限
2. 然后使用drop user删除账号设置访问权限(grants)
//查看赋予用户账号的权限
show grants for ya;
//设置权限(允许ya用户在user所有表上可以使用select语句)
grant select on user to ya;撤销访问权限(revoke)
//撤销上面设置的权限
revoke select on user from ya;控制访问权限(层次)

更改口令(set password)
set password for ya=password('自己的口令');
set password (不指定用户名,就更新当前登录用户口令)数据库维护
备份数据(flush tables之后备份)
刷新未写数据(保证所有数据被写到磁盘)
1. 先flush tables语句
2. 然后备份数据库维护(SQL语句)
//1. 检查表键是否正确
analyze table user; //返回状态信息
//2. check table 检查许多有问题的表并且修改
(MyISAM(5.5以前)表还对索引进行检查)
//3. changed 检查自最后一次检查以来改动过的表
//4. extended 执行最彻底的检查
//5. fast 只检查未正常关闭的表
//6. medium 检查所有被删除的联结并且进行键检查
//7. quick 只进行快速扫描MyISAM表访问不一致(repair table语句修复)
可能需要使用repair table来修复相应的表(不能经常使用,否则会有更大问题需要解决)表中删除大量数据(optimize table回收空间)
诊断启动问题(mysqld命令行)

查看日志文件

改善性能(遵守规则)
1. 遵守硬件建议(学习和研究mysql)
2. 关键的生产DBMS应该放在自己的专用服务器上
3. Mysql是一系列默认设置预先配置的,过一段时间就需要调整内存大小等
4. Mysql是一个多用户多线程的DBMS,经常同时执行多个任务,如果出现性能不良等可以使用show processlist 展示所有活动进程/kill命令终结某个进程
5. 尽量找到最优sql语句
6. 一般来说,存储过程 > 一条一条执行其中的各条mysql语句
7. 使用正确的数据类型
8. 要检索多少就检索多少(不要select *)
9. 导入数据时,应该关闭自动提交
10. 必须索引数据库表(提高检索性能)
11. or条件 ---> 多条select语句和union语句
12. 索引尽量使用在常用表上参考用书
参考《MySQL必知必会》


