HTTPServletReauest和HTTPServletResponse
一、HTTPServletRequest(这个对象封装了客户端提交过来的一切数据)
1
2
3
4
5
6
7
8
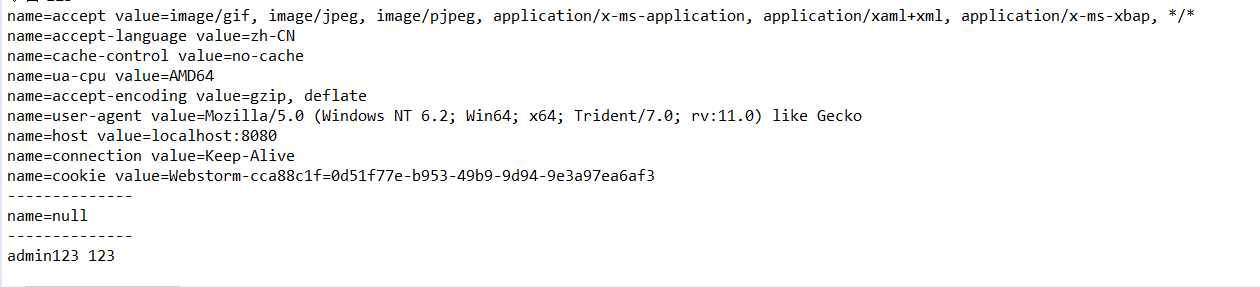
| //得到一个枚举集合
Enumeration<String> headerNames = request.getHeaderNames(); //用集合去存取所有的http头
while (headerNames.hasMoreElements()) {
String name = (String) headerNames.nextElement(); //每次取下一个
String value = request.getHeader(name); //取头就是给它的值
System.out.println(name+"="+value);
}
|
1
2
3
4
5
6
7
8
9
10
| //2.获取所有的参数---一个枚举集合(一个key对应多个value)
// Enumeration<String> headerNames = request.getHeaderNames(); //ctrl+1 提示左边的代码 获得所有的http头部
Map<String, String[]> map = request.getParameterMap();
Set<String> keySet = map.keySet(); //得到左边的key
Iterator<String> iterator = keySet.iterator();//得到加载器iterator
while(iterator.hasNext()) {
String key = iterator.next(); //加载器.get方法获得key值
String[] value = map.get(key); //request的对象调用.get方法获取value值
System.out.println("key="+key+" value="+value);
}
|
完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| public class Demo01 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//1.得到一个枚举集合
Enumeration<String> headerNames = request.getHeaderNames(); //ctrl+1 提示左边的代码 获得所有的http头部
while(headerNames.hasMoreElements())
{
String name=(String)headerNames.nextElement(); //while一次获取一次的http头部
String value=request.getHeader(name); //获取当对应的http头部的value值
System.out.println("name="+name+" value="+value);
}
System.out.println("--------------");
//获取的是客户端(html登录写的)提交上来的数据
String parameter = request.getParameter("name");
System.out.println("name="+parameter);
System.out.println("--------------");
//2.获取所有的参数---一个枚举集合(一个key对应多个value)
// Enumeration<String> headerNames = request.getHeaderNames(); //ctrl+1 提示左边的代码 获得所有的http头部
Map<String, String[]> map = request.getParameterMap();
Set<String> keySet = map.keySet(); //得到左边的key
Iterator<String> iterator = keySet.iterator();//得到加载器iterator
while(iterator.hasNext()) {
String key = iterator.next(); //加载器.get方法获得key值
String[] value = map.get(key); //request的对象调用.get方法获取value值
System.out.println("key="+key+" value="+value);
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
此外需要完成一个loginer.html代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<h2>请输入以下内容,完成登陆</h2>
<form action="LoginServleter" method="get"> <!--action找的是xml里面 url标签的内容-->
账号:<input type="text" name="username"/><br>
密码:<input type="text" name="password"/><br>
<input type="submit" value="登录"/>
</form>
</body>
</html>
|
第一个循环出来的是所有的http的头部/然后是输入的账号密码/展示输入的账户密码
二、HTTPServletRequest的中文乱码问题
由于tomcat收到使用getParameter()方法默认是ISO-8859-1去解码,所以必须要去转换。
- 1.1 通过(username.getBytes(“ISO-8859-1”))去更改
1
| username = new String(username.getBytes("ISO-8859-1") , "UTF-8");
|
- 1.2 在tomcat/conf/server.xml 加上URIEncoding=”utf-8”
1
| <Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443" URIEncoding="UTF-8"/>
|
第一种方式的具体代码(还需要上面的loginer.html代码)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class LoginServleter extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String username=request.getParameter("username"); //request 包括请求的信息
String password=request.getParameter("password");
System.out.println(username+" "+password);
//get请求过来的数据,在url地址栏上已经是编码过的,所以取到的是乱码
//tomcat收到使用getParameter()方法默认是ISO-8859-1去解码
//先让文字回到ISO-8859-1对应的字节数组 , 然后再按utf-8组拼字符串
username = new String(username.getBytes("ISO-8859-1") , "UTF-8");
System.out.println("userName="+username+"==password="+password);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
2.post方式(前端代码form表单里面是method=”post”)
- 2.1 直接在getParameter方法之前使用一个setCharacterEncoding(“UTF-8”);
1
2
| request.setCharacterEncoding("UTF-8");
这行设置一定要写在getParameter之前。
|
三、HTTPServletResponse(返回数据给客户端)
字符流/字节流方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
| public class Demo02 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOExceptio
//以字符流getWriter
response.getWriter().write("<h1>hello response...</h1>");
//以字节流getOutputStream
response.getOutputStream().write("hello response......".getBytes());
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
四、HTTPServletResponse 中文乱码问题
###不管是字节流还是字符流,直接使用一行代码就可以了。
1
2
3
| response.setContentType("text/html;charset=UTF-8");
然后在写数据即可。
|
五、下载资源
1.使用超链接的方式下载##
tomcat里面有一个默认的Servlet – DefaultServlet –专门用于处理放在tomcat服务器上的静态资源。
代码框架:
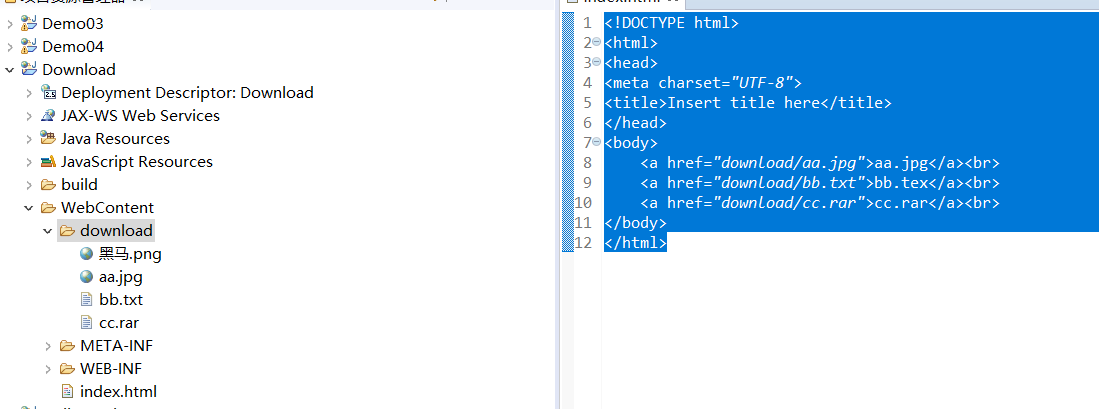
在WebContent里面放需要下载的资源download文件(准备好的文件)。新建的index.html文件去实现超链接下载。
1
2
3
4
5
6
7
8
9
10
11
12
| <!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<a href="download/aa.jpg">aa.jpg</a><br>
<a href="download/bb.txt">bb.tex</a><br>
<a href="download/cc.rar">cc.rar</a><br>
</body>
</html>
|
2.手写编码实现
代码框架:
有一个弹窗的操作:
1
2
| //让浏览器收到资源,弹出提醒!!!
response.setHeader("Content-Disposition", "attachment; filename="+fileName); //response调用setHeader方法
|
index.html(客户端)代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| <!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
这是tomcat默认的servlet区提供下载:<br>
<a href="download/aa.jpg">aa.jpg</a><br>
<a href="download/bb.txt">bb.txt</a><br>
<a href="download/cc.rar">cc.rar</a><br>
<br>手动编码提供下载。:<br>
<a href="demo01?filename=aa.jpg">aa.jpg</a><br> <!--浏览器后面就是--filename=xxx-->
<a href="demo01?filename=bb.txt">bb.txt</a><br>
<a href="demo01?filename=cc.rar">cc.rar</a><br>
</body>
</html>
|
demo01代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
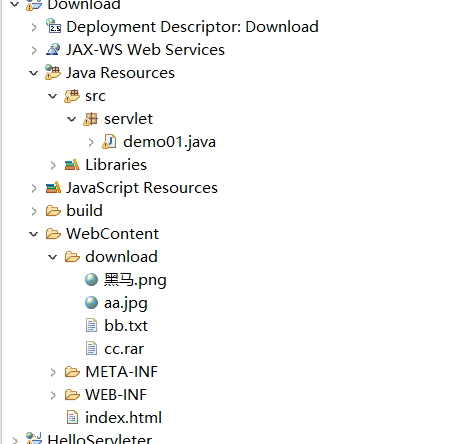
| public class demo01 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//1.获取要下载的文件
String fileName = request.getParameter("filename"); //使用getParameter获得filename
//2.获取这个文件正在tomcat的绝对路径getRealPath()
String path = getServletContext().getRealPath("download/"+fileName); //使用servletcontext去获得绝对路径(里面写"存放文件的名字/"+fileName)
//让浏览器收到资源,弹出提醒!!!
response.setHeader("Content-Disposition", "attachment; filename="+fileName);
//3.转换成输入流
InputStream is=new FileInputStream(path); //输入流获取
OutputStream os = response.getOutputStream(); //输出流由response获得
int len=0;
byte[]buffer =new byte[1024];
while((len=is.read(buffer))!=-1) //输入流不为-1
{
os.write(buffer,0,len); //有多长写多长
}
os.close(); //关闭
is.close();
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
最终结果(可以弹窗)
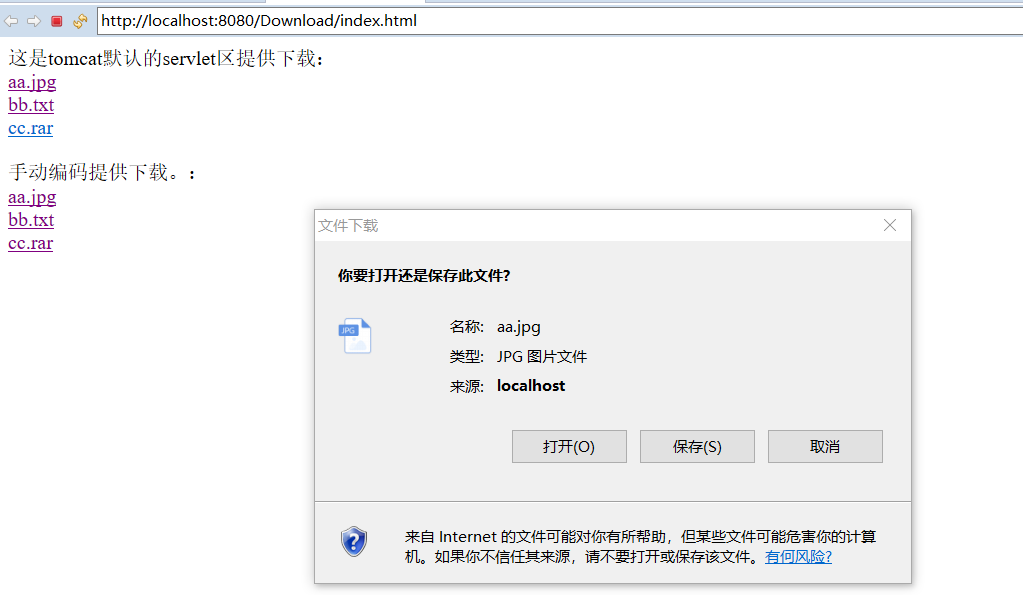
六、下载资源中文乱码问题
针对浏览器类型,对文件名字做编码处理:
Firefox ---使用的是UBase64
IE、Chrome ---使用的是URLEncoder
代码结构框架:

1.index.html里面只需要增加一行标签代码即可
1
| <a href="demo01?filename=黑马.png">黑马.png</a><br>
|
2.在上面的基础上新增一个DownLoadUtil类写一个帮助火狐firefox浏览器识别的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| package servlet;
import java.io.UnsupportedEncodingException;
import sun.misc.BASE64Encoder;
public class DownLoadUtil {
public static String base64EncodeFileName(String fileName) {
BASE64Encoder base64Encoder = new BASE64Encoder();
try {
return "=?UTF-8?B?"+ new String(base64Encoder.encode(fileName.getBytes("UTF-8"))) + "?=";
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
throw new RuntimeException(e);
}
}
}
|
3.原来的demo01里面需要增加中文编码环节:

主要代码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| //1.获取要下载的文件
String fileName = request.getParameter("filename"); //获取filename
//有中文转成UTF-8格式
fileName=new String(fileName.getBytes("ISO-8859-1"),"UTF-8"); //通过getBytes获得tomcat默认的ISO-8859-1的格式,然后更改为UTF-8
//2.获取这个文件正在tomcat的绝对路径getRealPath()
String path = getServletContext().getRealPath("download/"+fileName);
String clientType = request.getHeader("User-Agent"); //获取当前的用户端类型
if(clientType.contains("Firefox"))
{
fileName = DownLoadUtil.base64EncodeFileName(fileName); //调用DownLoadUtil类(新增的类)的方法
}
else //IE ,或者 Chrome (谷歌浏览器) ,
{
fileName = URLEncoder.encode(fileName,"UTF-8"); //使用URLEncoder类的encode方法更改
}
|
demo01完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class demo01 extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//1.获取要下载的文件
String fileName = request.getParameter("filename");
//有中文转成UTF-8格式
fileName=new String(fileName.getBytes("ISO-8859-1"),"UTF-8");
//2.获取这个文件正在tomcat的绝对路径getRealPath()
String path = getServletContext().getRealPath("download/"+fileName);
//获取来访的客户端类型
String clientType = request.getHeader("User-Agent");
if(clientType.contains("Firefox"))
{
fileName = DownLoadUtil.base64EncodeFileName(fileName);
}
else //IE ,或者 Chrome (谷歌浏览器) ,
{
fileName = URLEncoder.encode(fileName,"UTF-8");
}
//让浏览器收到资源,弹出提醒!!!
response.setHeader("Content-Disposition", "attachment; filename="+fileName);
//3.转换成输入流
InputStream is=new FileInputStream(path);
OutputStream os = response.getOutputStream();
int len=0;
byte[]buffer =new byte[1024];
while((len=is.read(buffer))!=-1){
os.write(buffer,0,len);
}
os.close();
is.close();
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
最终黑马.png也可以通过弹窗打开!
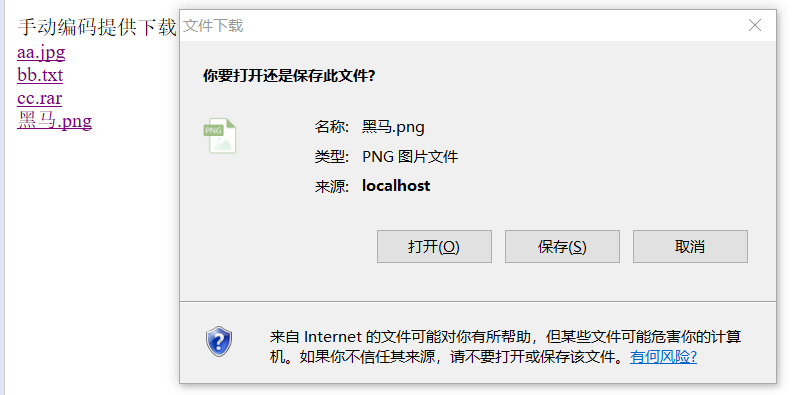
七、请求转发(原来的地方)和重定向(去新的地方)
主要代码(跳转)
1
2
3
4
5
6
7
8
9
| //早期的写法:
//response.setStatus(302); //添加一个状态
//response.setHeader("Location", "login_success.html"); //成功之后就可以直接跳转到login_success.html页面
//重定向写法:重新定位方向
response.sendRedirect("login_success.html");
//请求转发写法:
request.getRequestDispatcher("login_success.html").forward(request,response);
|
只展示java代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| public class LoginServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setContentType("text/html;charset=utf-8"); //解决中文乱码问题
String username=request.getParameter("username");
String password=request.getParameter("password");
if("admin".equals(username)&&"123".equals(password))
{
//response.getWriter().write("yes"); //使用字符流 但是要改中文的问题
//早期的写法:
//response.setStatus(302); //添加一个状态
//response.setHeader("Location", "login_success.html"); //成功之后就可以直接跳转到login_success.html页面
//重定向写法:重新定位方向
response.sendRedirect("login_success.html");
//请求转发写法:
request.getRequestDispatcher("login_success.html").forward(request,response);
}
else
{
response.getWriter().write("no");
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doGet(request, response);
}
}
|
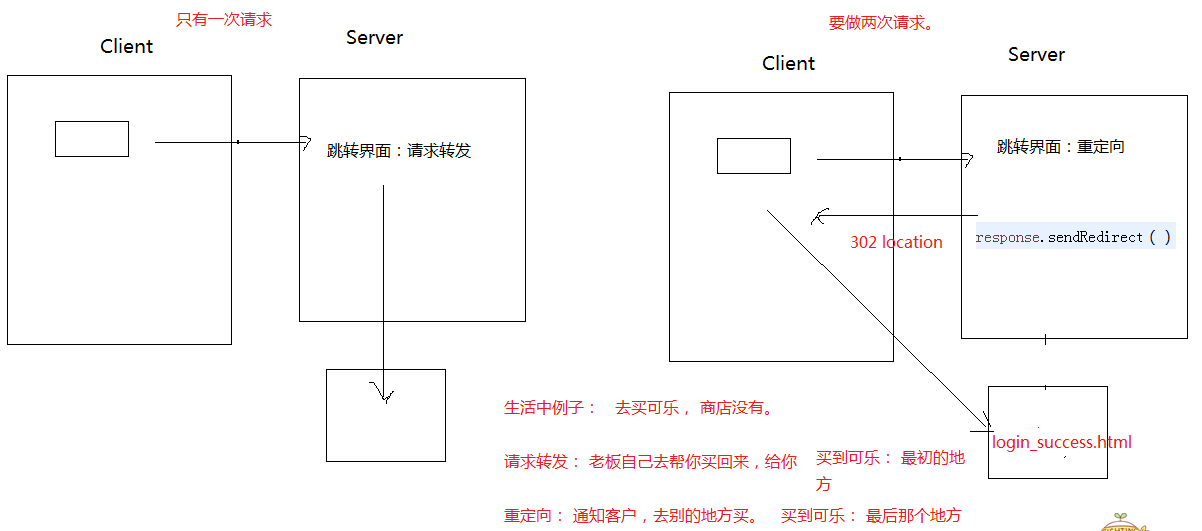
两者之间的区别和联系
| 区分项目 |
请求转发(request) |
重定位(response) |
| 请求次数 |
一次(服务器内部帮忙完成) |
两次(服务器在第一次请求后悔返回302和一个地址,然后浏览器根据地址去第二次访问) |
| 显示地址 |
请求的servlet地址(要去哪里) |
显示的最后的那个资源的地址(最终跳转的) |
| 跳转路径 |
只能去自己项目的路径 |
可以跳转到任意路径 |
| 效率 |
高效(1次) |
低效(2次) |
| *后续请求(上一次的request) * |
不可以使用(两次不同请求) |
可以使用(同一请求) |