一、XML解析方式(面试考点)
其实就是获取元素里面的字符数据或者属性数据
其中常用的两种解析方式:
DOM(document object model)
将整个xml全部读到内存当中,形成树形结构(所有的对象都叫做Node节点。)
整个文档---document对象
属性(标签内描述属性)---attribute对象
所有元素节点(stu/name/age等标签)---element对象
文本(文字等描述)---text对象
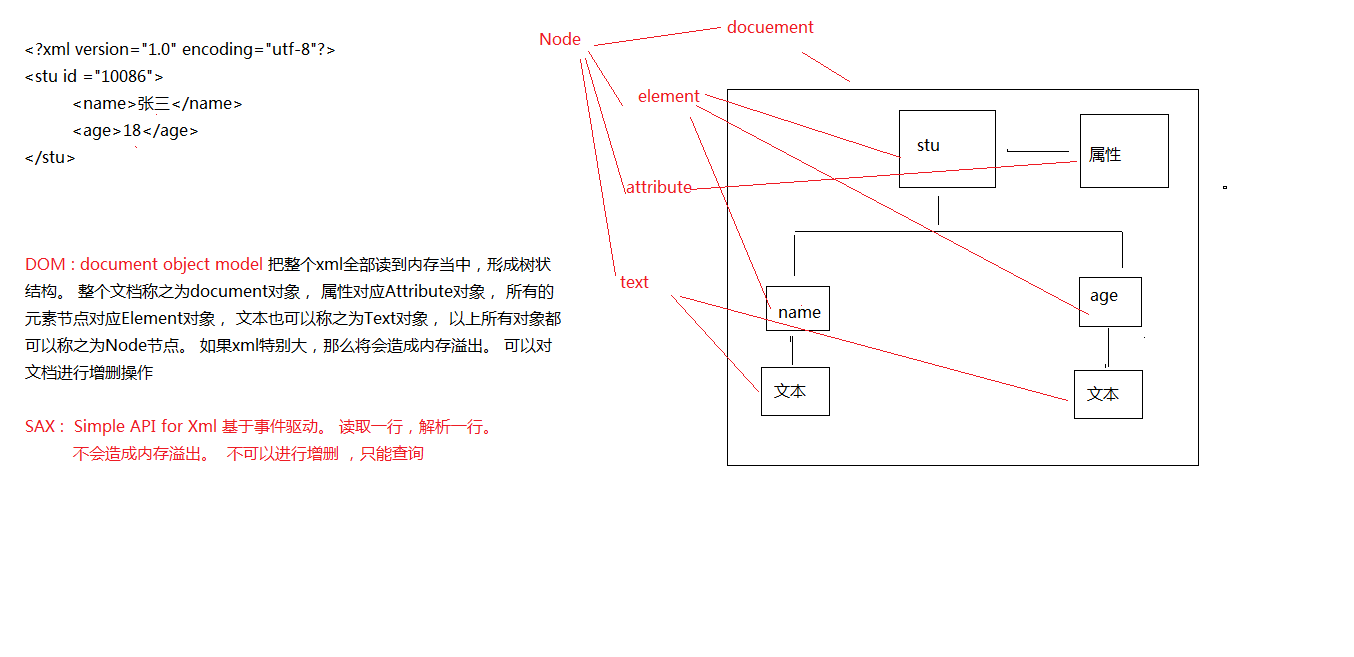
SAX(simple API for Xml)
基于事件驱动(读一行解析一行)
二、针对两种解析方式的API(Dom4j 入门)
- jaxp sun公司(比较繁琐)
- jdom
- dom4j 使用广泛
Dom4j 基本用法(导入jar)
1.创建SAXReader对象
1
| SAXReader reader=new SAXReader();
|
2.指定解析的xml原地址(SAXReader调用read方法)
1
| Document document=reader.read(new File("src/xml/demo.xml")); //整个文档叫做document对象
|
3.获取根元素(文档document对象调用getRootElement方法)
1
| Element rootElement=document.getRootElement();
|
4.根据根元素—下面的元素
element.element //一个stu元素
element.elements(); //所有stu元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| //得到根元素的子元素 age (找两层element)
rootElement.element("stu").element("age");
//得到根元素下面的所有子元素(所有的stu)
List<Element> elements=rootElement.elements(); //泛型(stu/name/age)返回子元素stu
//遍历所有的stu元素
for(Element element :elements)
{
//获取stu元素下面的name元素
String name = element.element("name").getText();
String age = element.element("age").getText();
String desc = element.element("desc").getText();
System.out.println("name="+name+" age+"+age+" desc="+desc);
}
|
具体实现::
demo.xml内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <?xml version="1.0" encoding="UTF-8"?>
<stus>
<stu>
<name>李四</name>
<age>15</age>
<desc>我是老大</desc>
</stu>
<stu>
<name>网名</name>
<age>15</age>
<desc>我是老大</desc>
</stu>
</stus>
|
MainTest.java实现类内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| package xml;
import java.io.File;
import java.util.List;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import com.sun.xml.internal.txw2.Document;
public class MainTest {
public static void main(String[] args){
//1.创建sax读取对象
SAXReader reader=new SAXReader();
try {
//2.指定解析的xml源
org.dom4j.Document document=reader.read(new File("src/xml/demo.xml")); //整个文档叫做document对象
//3.得到元素(element)
//得到根元素 getRootElement
Element rootElement=document.getRootElement();
//得到根元素的子元素 age (找两层element)
rootElement.element("stu").element("age");
//得到根元素下面的所有子元素(所有的stu)
List<Element> elements=rootElement.elements(); //泛型(stu/name/age)返回子元素stu
//遍历所有的stu元素
for(Element element :elements)
{
//获取stu元素下面的name元素
String name = element.element("name").getText();
String age = element.element("age").getText();
String desc = element.element("desc").getText();
System.out.println("name="+name+" age+"+age+" desc="+desc);
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
|
通过泛型遍历所有的文本text内容(getText())
三 、Dom4j中的Xpath入门(导入jar)
dom4j里面支持Xpath的写法。 xpath其实是xml的路径语言,支持我们在解析xml的时候,能够快速定位到具体的某一个元素。
如果需要获得单个的name:
1
2
3
4
5
| Dom4j里面是根节点.element()方法:
rootElement.element("stu").element("age");
Xpath里面是根节点.selectSingleNode("具体的//或者/行为")方法;
Element nameElement=(Element) rootElement.selectSingleNode("//name");
|
如果需要获得所有的name:
1
2
3
4
5
| Dom4j里面是根节点.elements()方法:
List<Element> elements=rootElement.elements(); //泛型(stu/name/age)返回子元素stu
Xpath里面是根节点.selectNodes("具体的//或者/行为")方法;
List<Element> elements= rootElement.selectNodes("//name"); //泛型(stu/name/age)返回子元素stu
|
完整代码如下(xml一样只是展示Xpath的不同):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| package xml;
import java.io.File;
import java.util.List;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class XpathTest {
public static void main(String[] args){
//1.创建sax读取对象
SAXReader reader=new SAXReader();
try {
//2.指定解析的xml源
org.dom4j.Document document=reader.read(new File("src/xml/demo.xml")); //整个文档叫做document对象
//3.得到元素(element)
//得到根元素 getRootElement
Element rootElement=document.getRootElement();
//要想使用Xpath,还需要支持的jar(获取的是第一个,只返回一个)
Element nameElement=(Element) rootElement.selectSingleNode("//name");
System.out.println(nameElement.getText());
System.out.println("-----------");
List<Element> elements= rootElement.selectNodes("//name"); //泛型(stu/name/age)返回子元素stu
//遍历所有的stu元素
for(Element element :elements)
{
System.out.println(element.getText());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
|
两者对比如下:

四、XML约束


