1.wangEditor5
参考官网:快速开始 | wangEditor
1.1 安装
- 指令:
1 | npm install @wangeditor/editor --save |
1.2 引入和使用
- 指令:
1 | import '@wangeditor/editor/dist/css/style.css' |
参考官网:快速开始 | wangEditor
1 | npm install @wangeditor/editor --save |
1 | import '@wangeditor/editor/dist/css/style.css' |
基于《Vue框架》笔记中的项目和语法为基础,项目源码在github网址的vue_yufa的master分支
项目框架

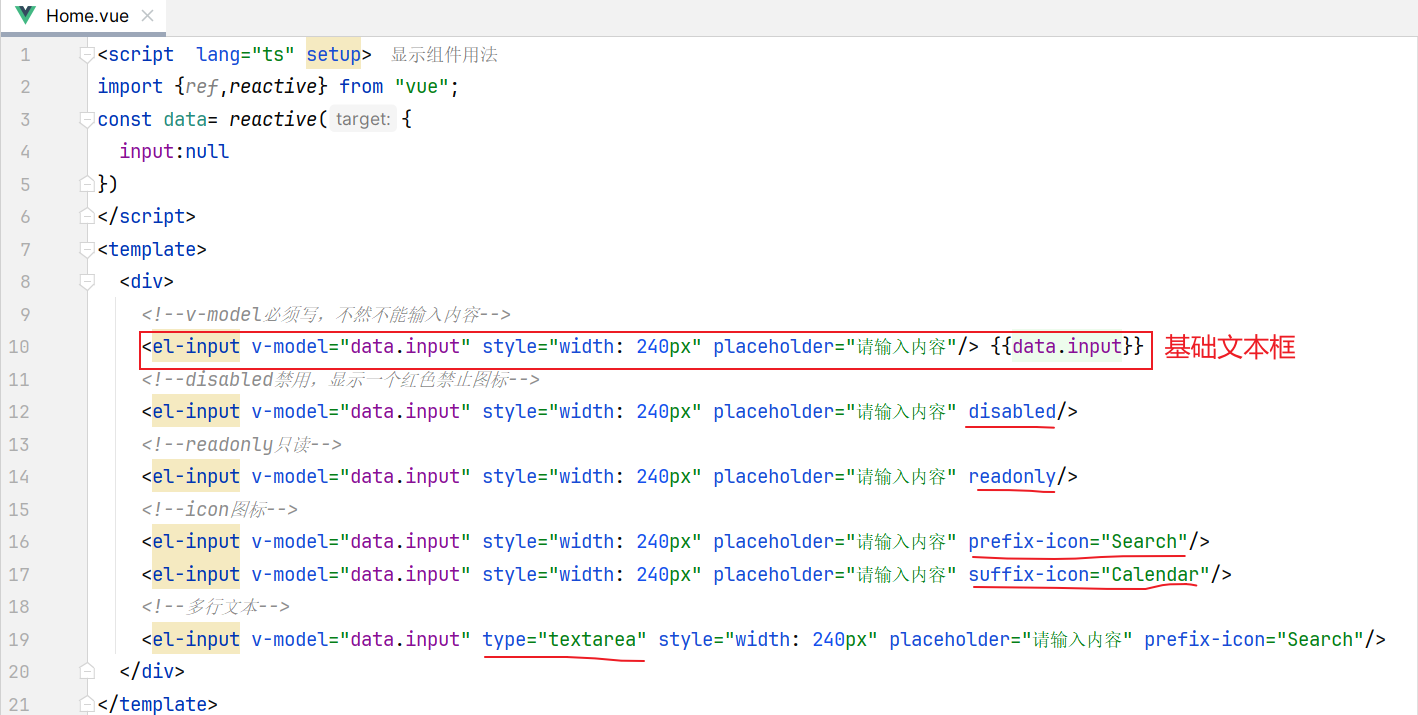
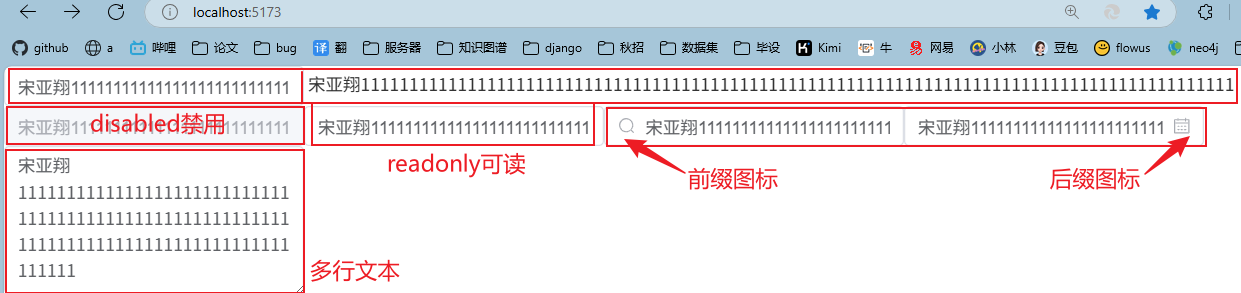
1 | <script setup> |
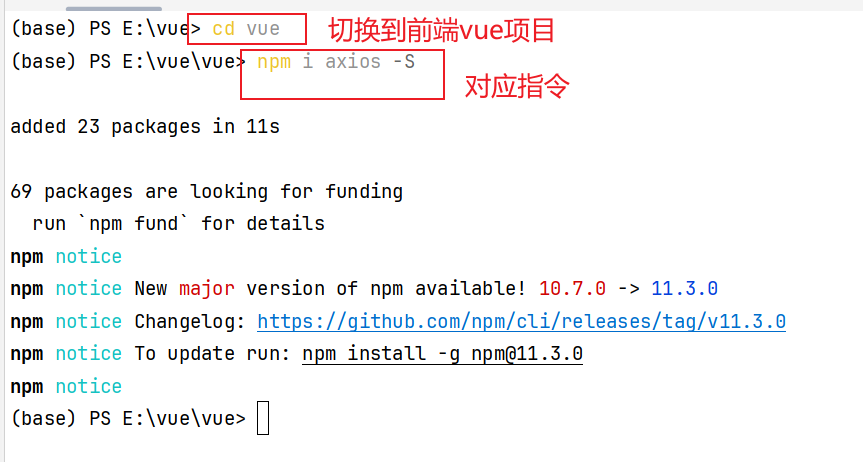
代码位置和内容:
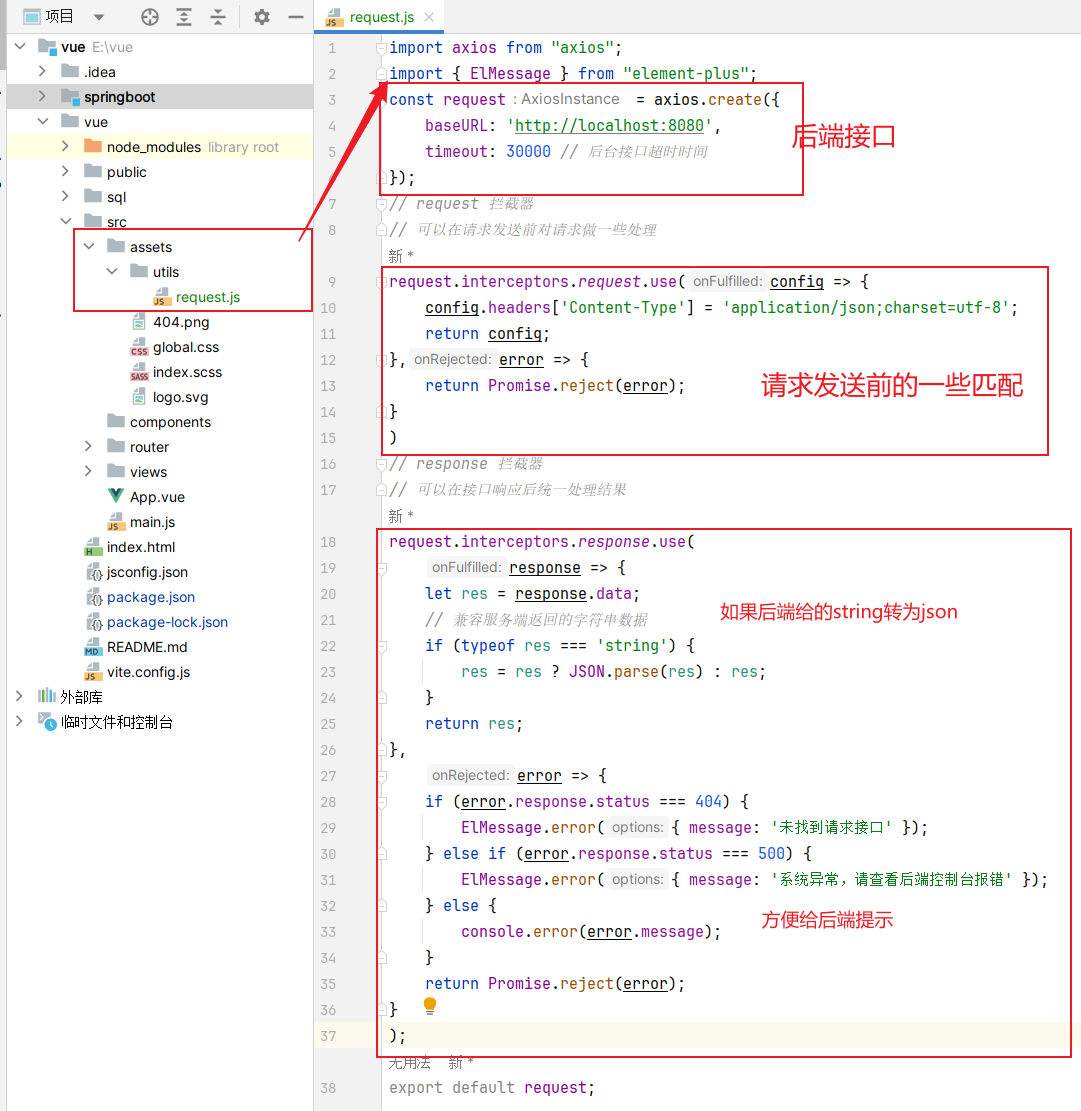
1 | import axios from "axios"; |
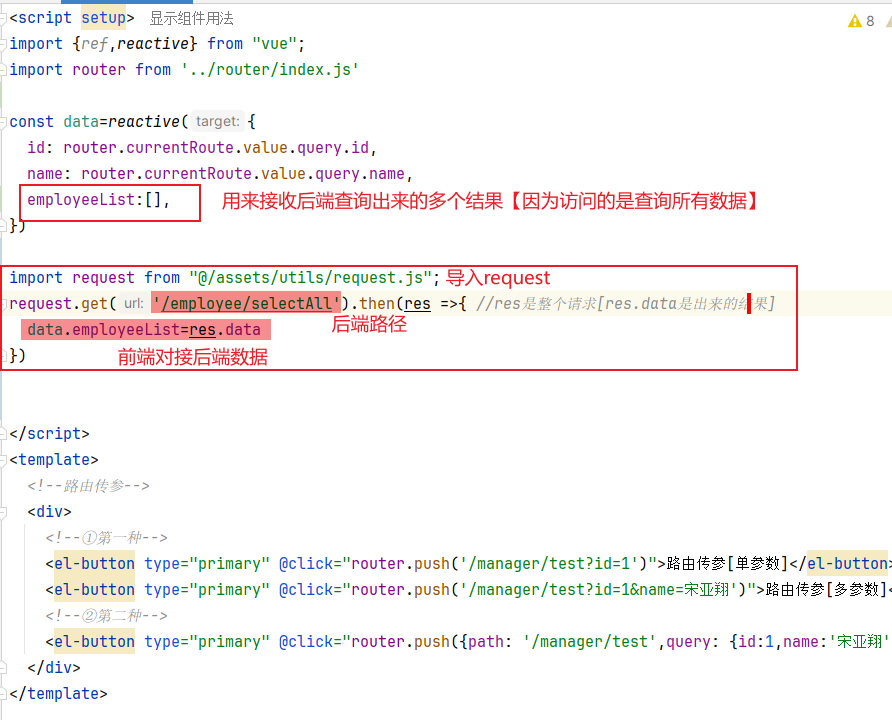
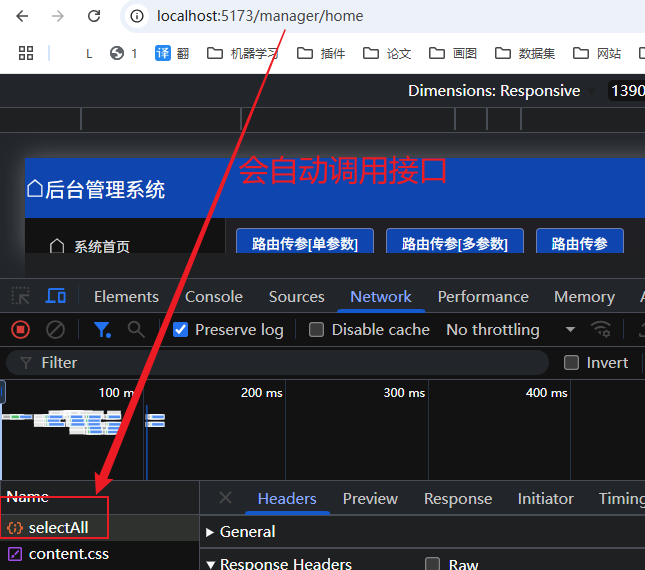

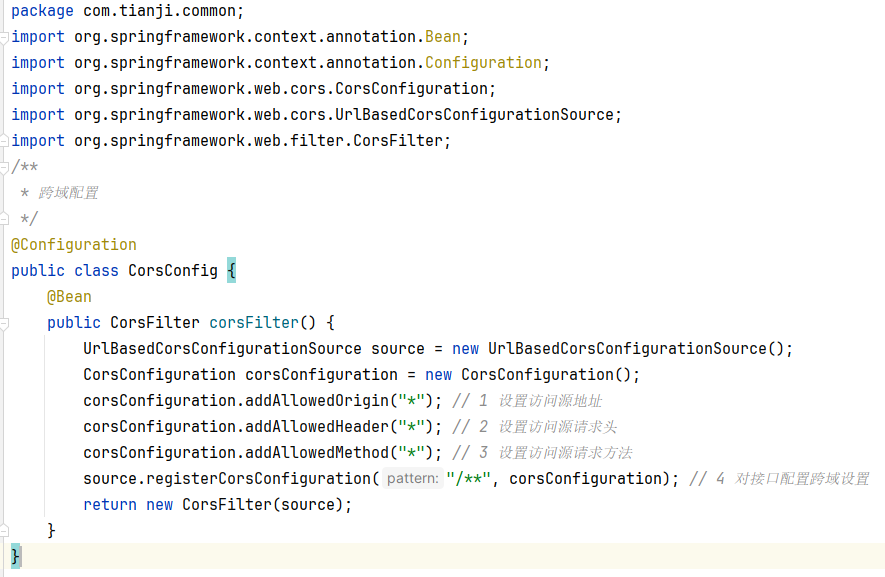
1 | package com.tianji.common; |
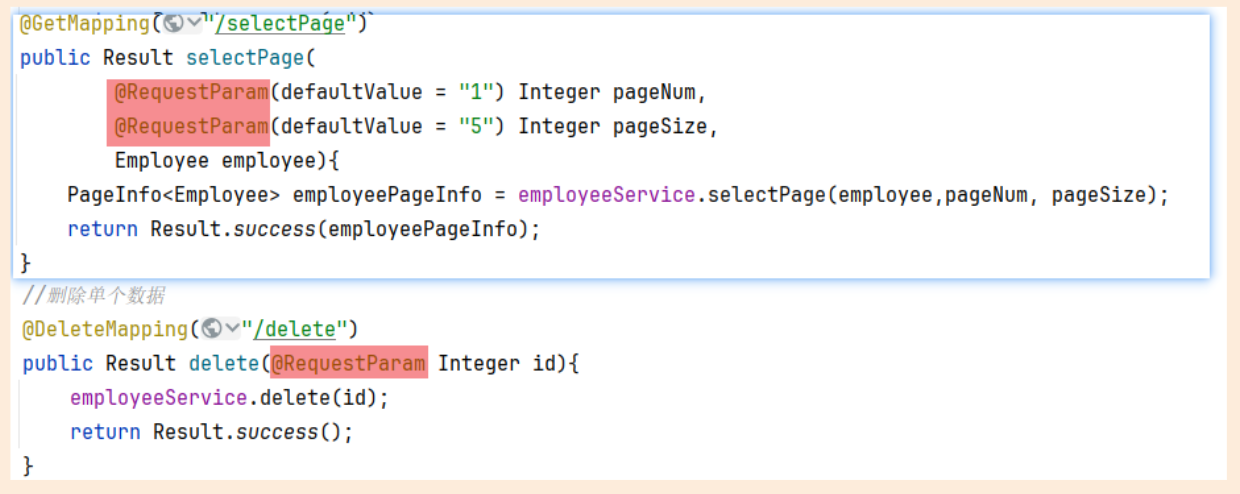
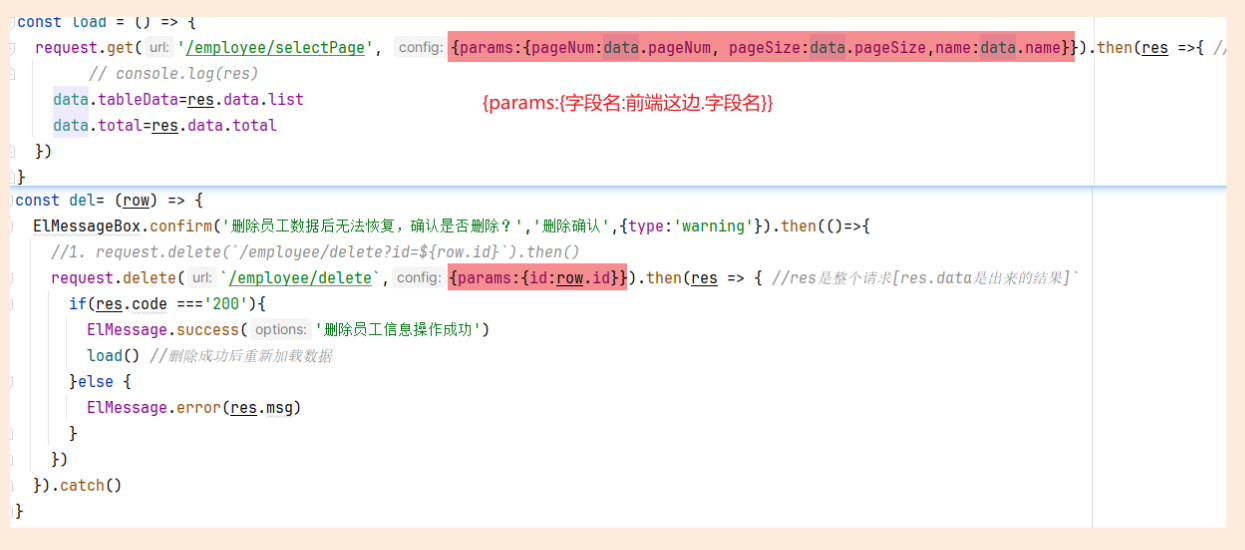
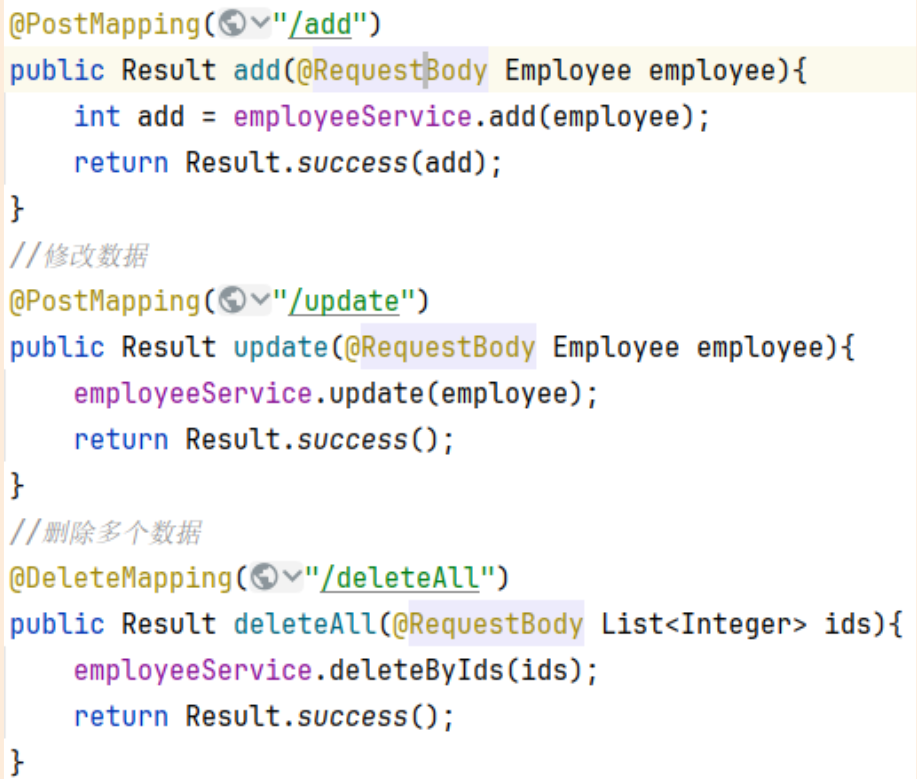
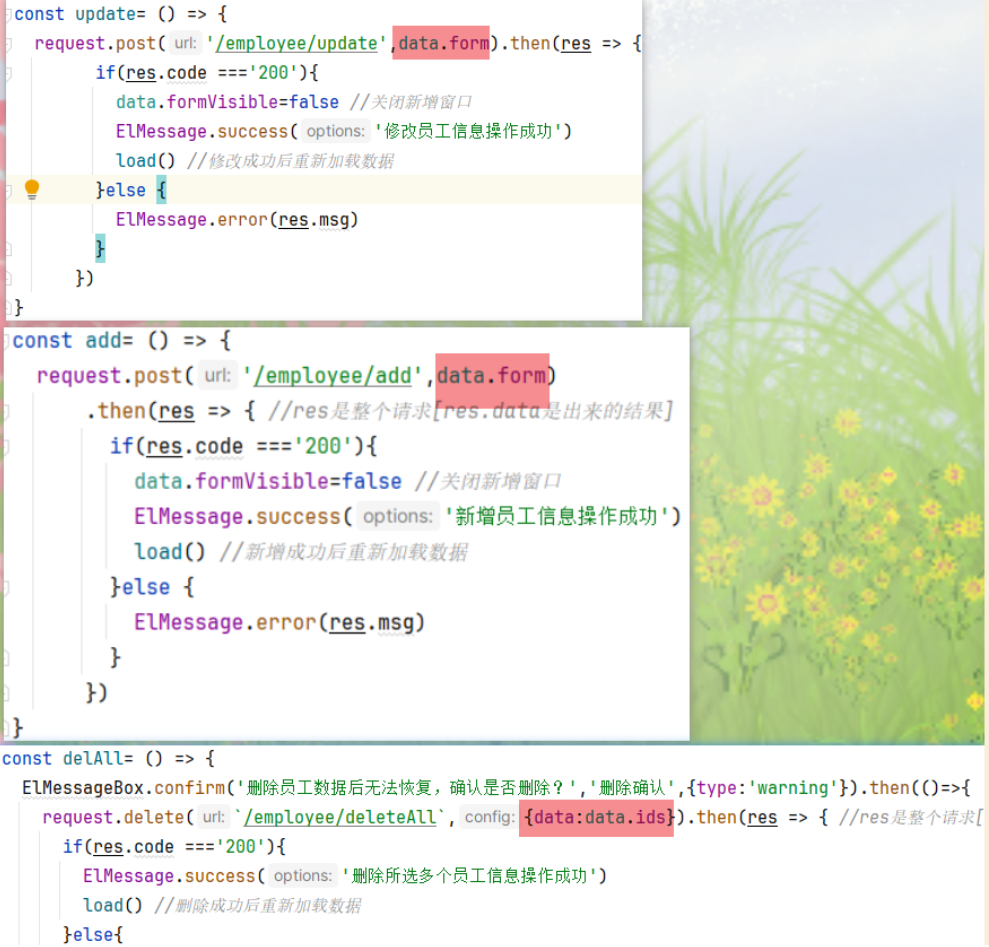
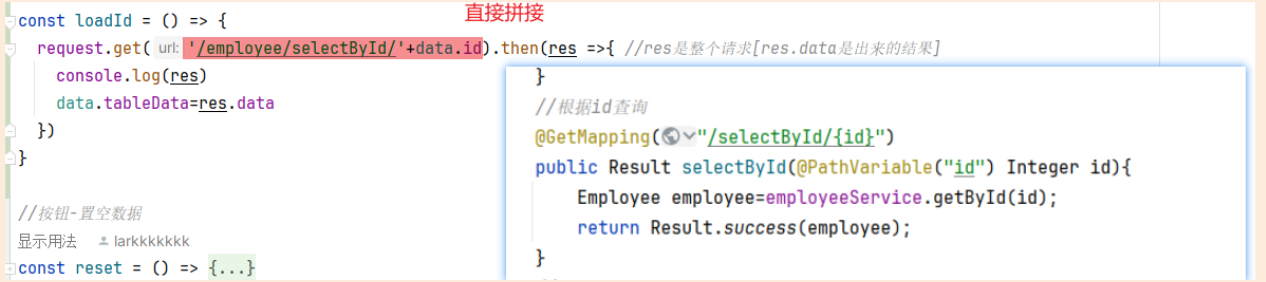
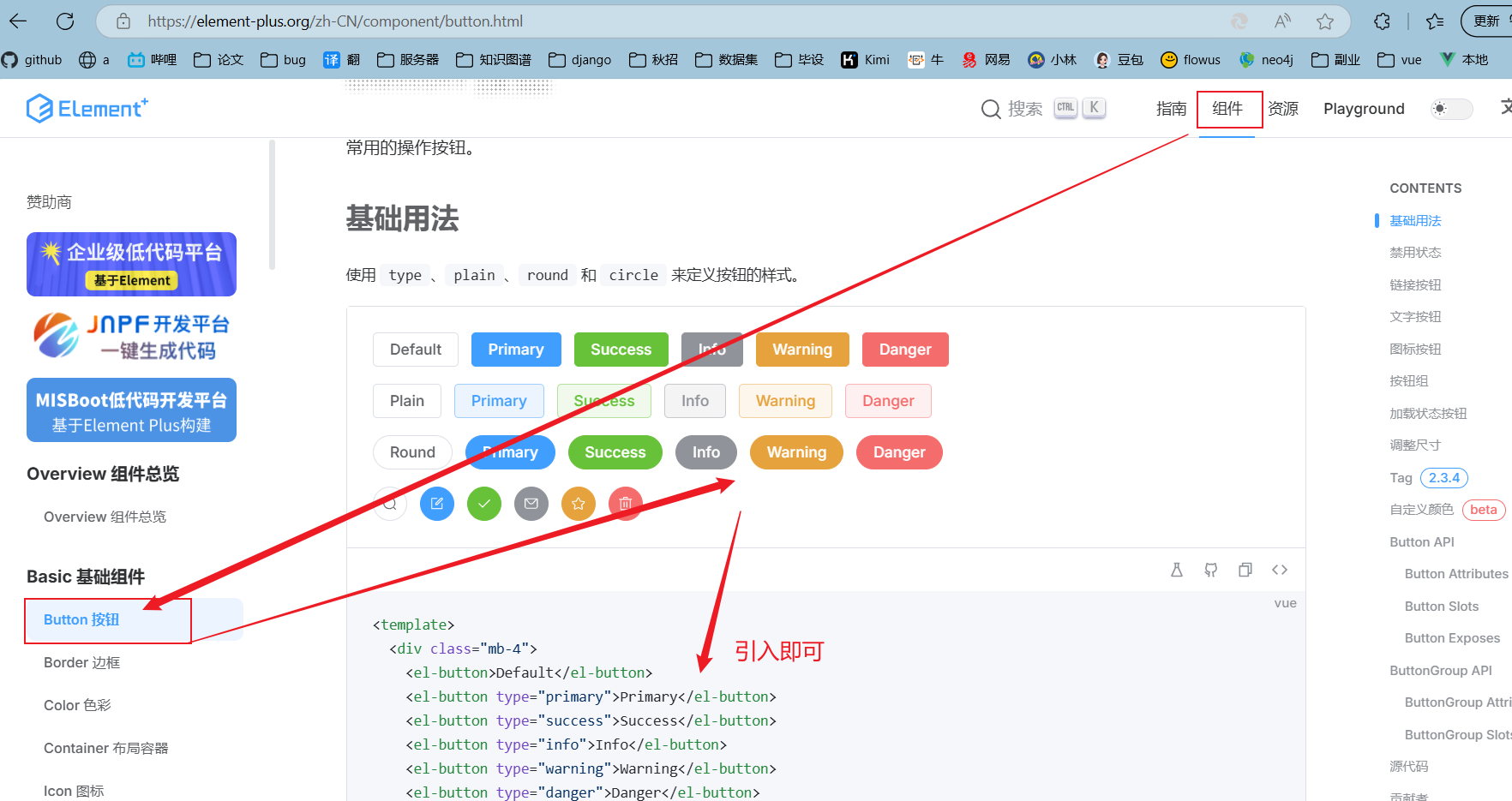
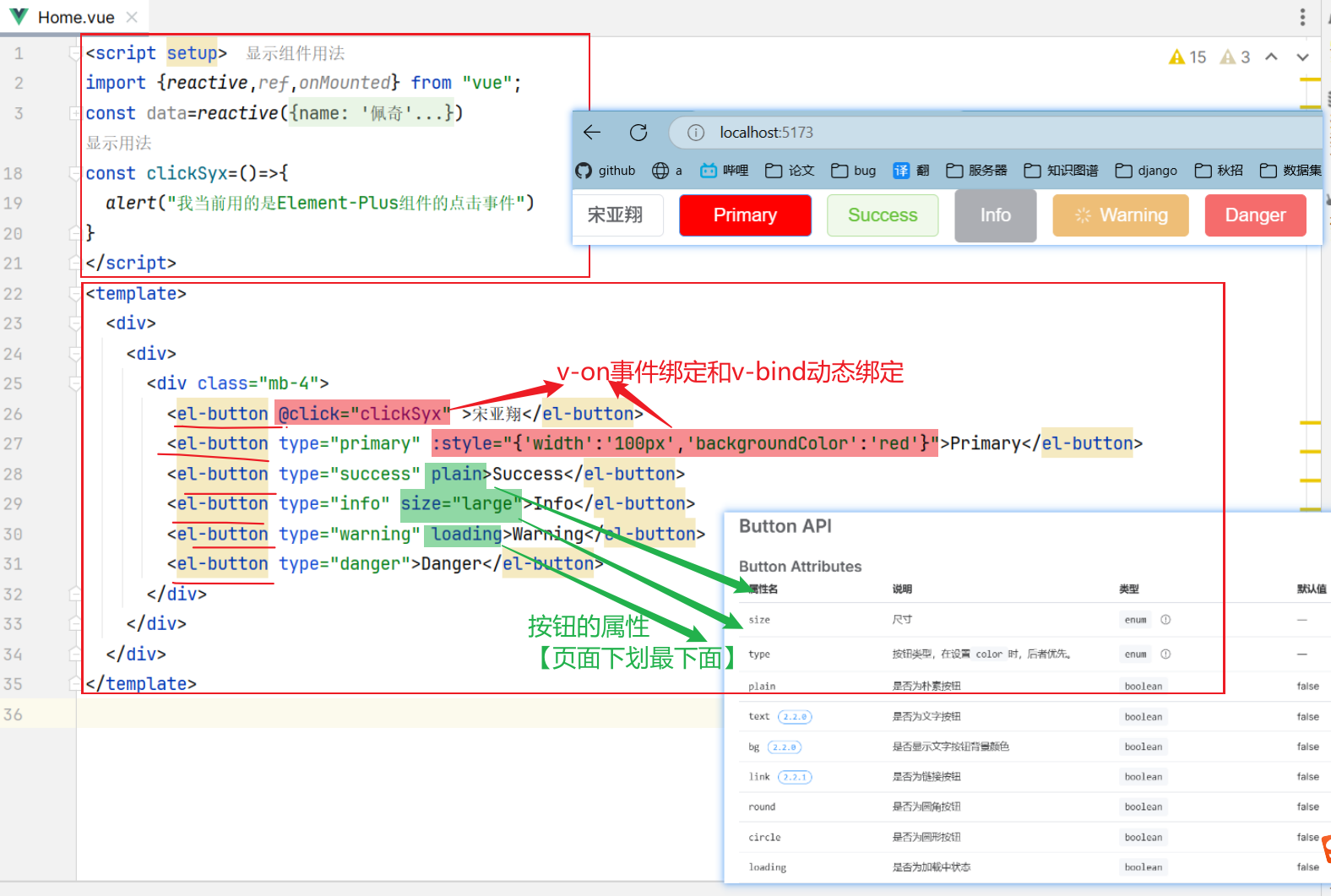
Element-Plus:Element-plus是一套为构建基于Vue3的组件库而设计的UI组件库(UI Kit)。它为开发者提供了一套丰富的UI组件和扩展功能,例如表格、表单、按钮、导航、通知等,让开发者能够快速构建高质量的Web应用。
安装依赖指令:
1 | npm i element-plus -S |
安装位置:
安装之后:
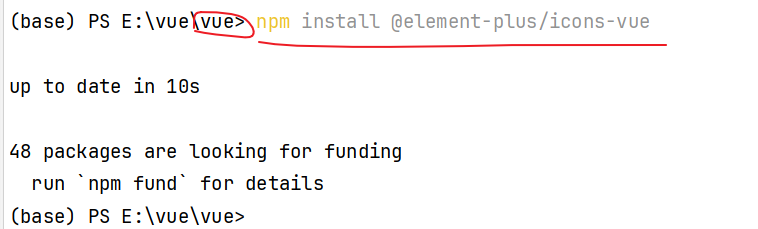
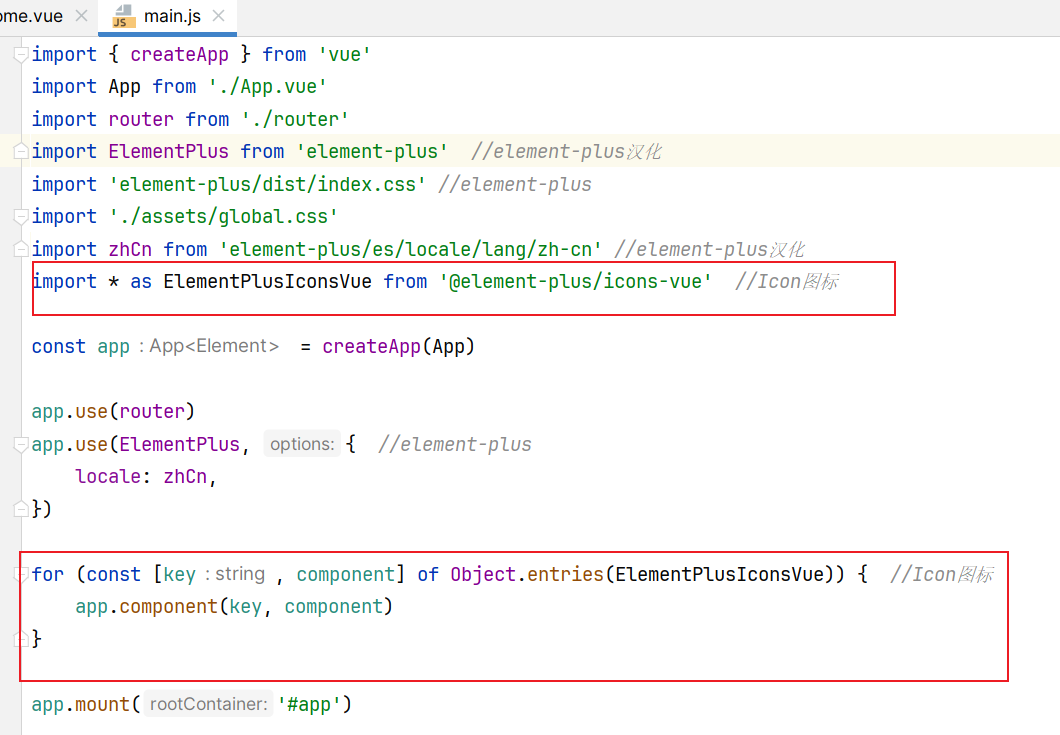
安装依赖指令:
1 | npm install @element-plus/icons-vue |
安装位置:
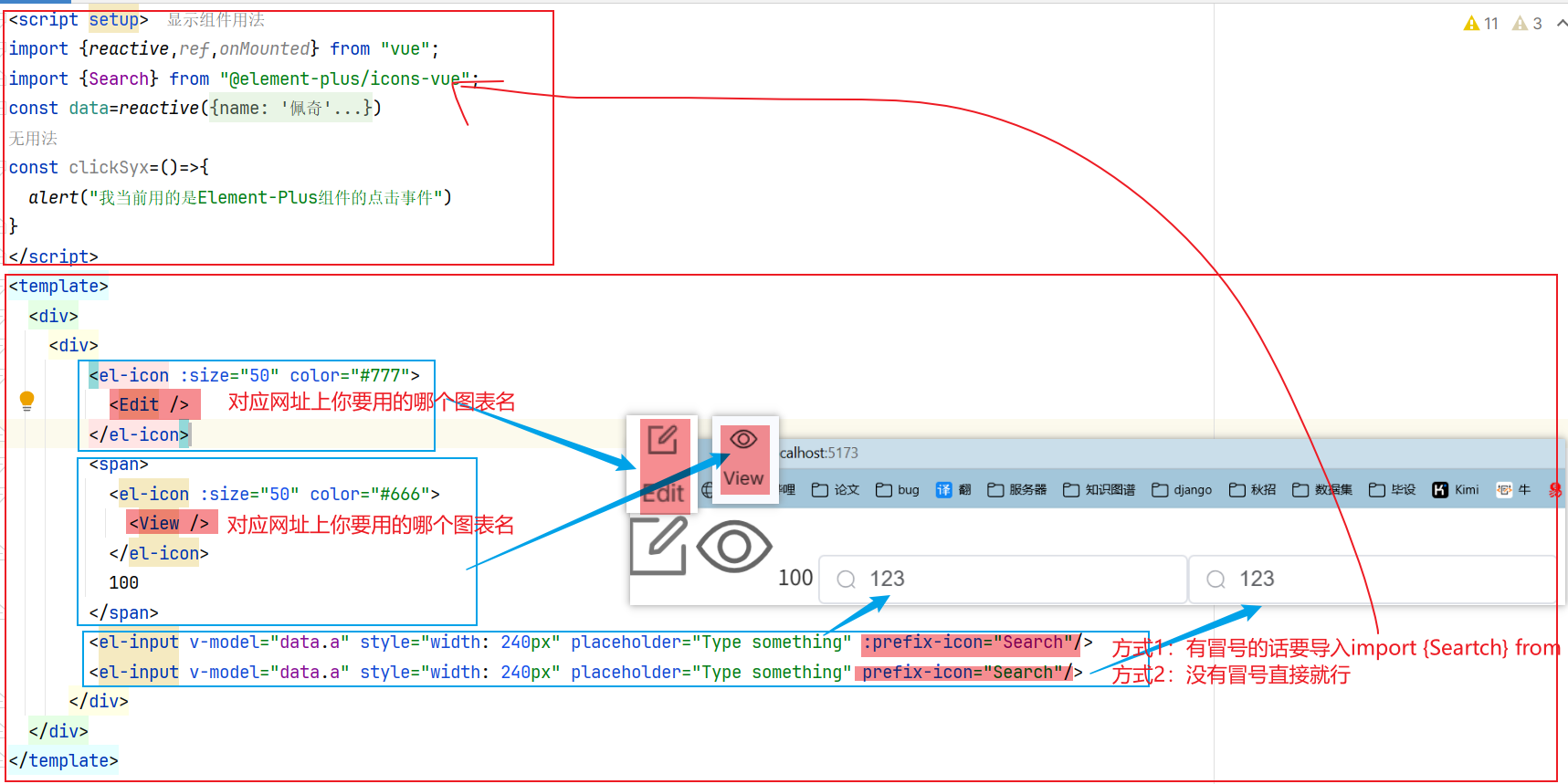
安装依赖指令:
1 | npm i sass@1.71.1 -D 【我的后面出现报错,更新到了1.86.3】--使用指令npm install sass@latest --save-dev |
安装位置:

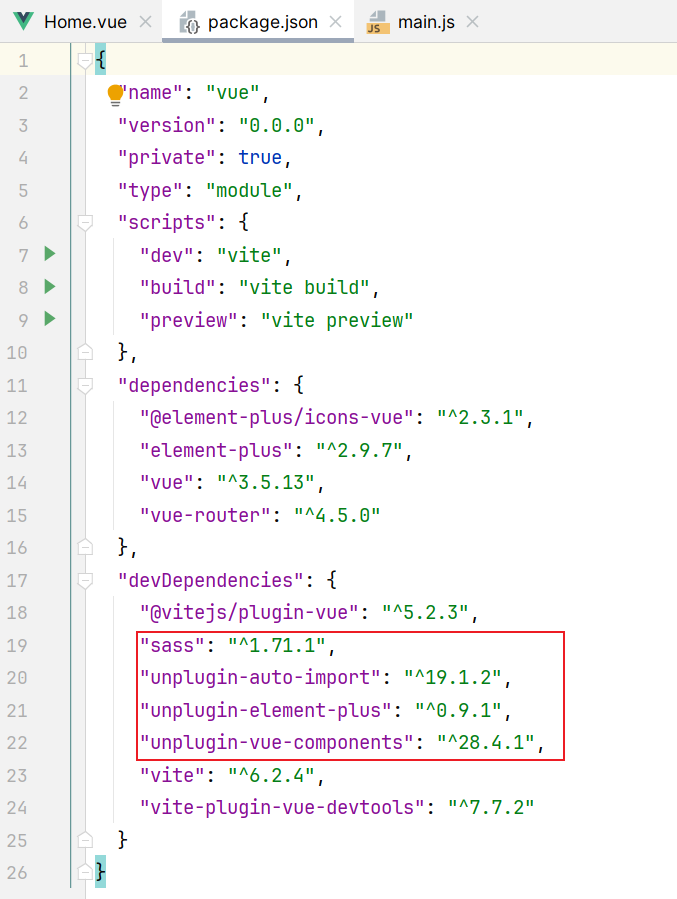
安装之后:在总项目的package.json查看
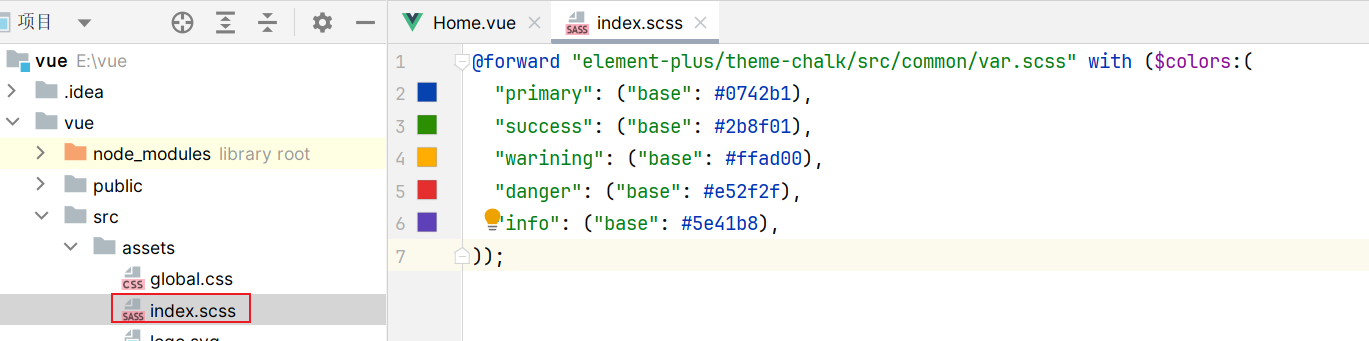
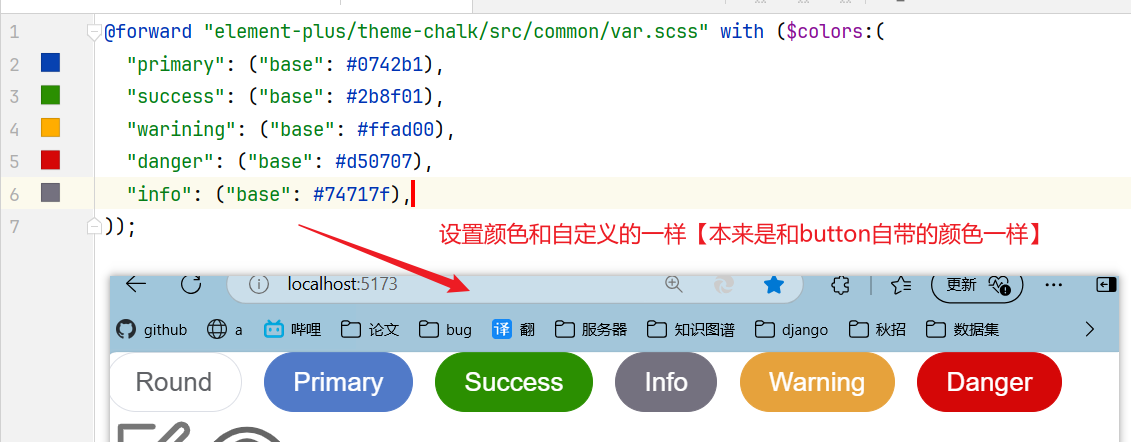
1 | @forward "element-plus/theme-chalk/src/common/var.scss" with ($colors:( |
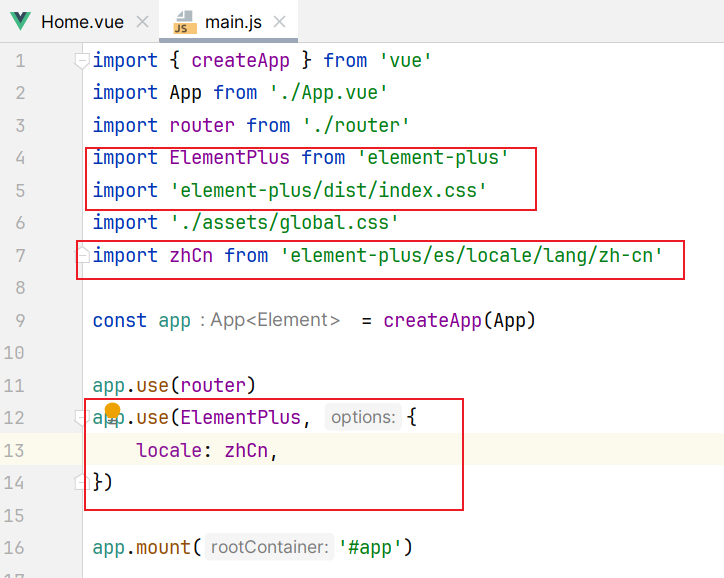
在src-assets文件下创建index.scss文件:
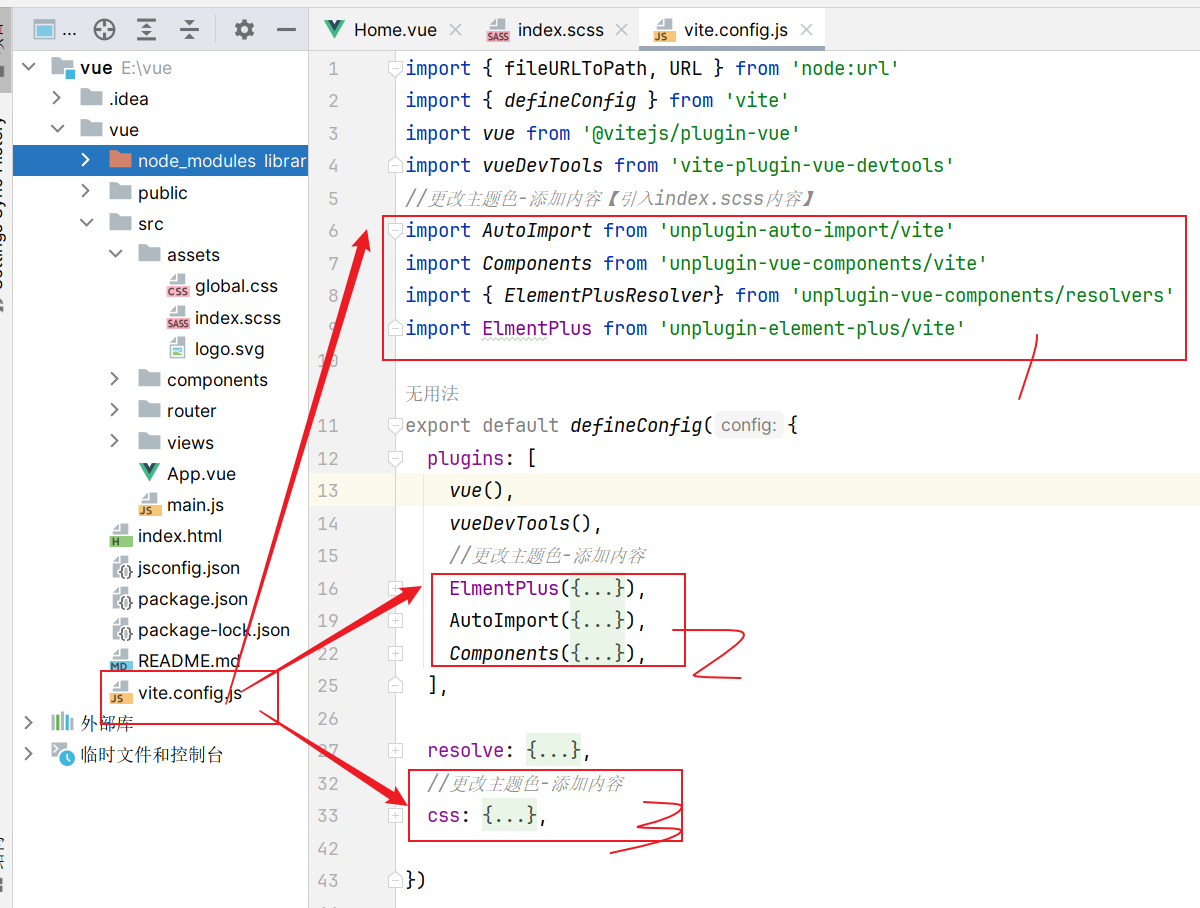
修改三处位置:
具体代码:
1 | import { fileURLToPath, URL } from 'node:url' |
参考内容:Select 选择器 | Element Plus
两个核心:v-model绑定data的value【下拉选中之后就可以绑定到value】,v-for的遍历绑定options【可以是数组,也可以是对象】
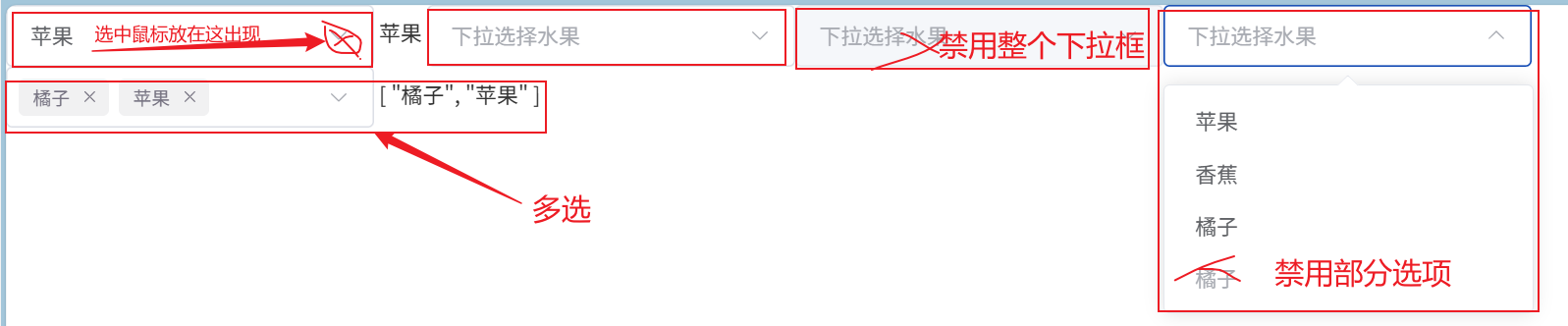
两种写法要确认自己的element-plus版本,我的是2.9.7对应使用第一种写法
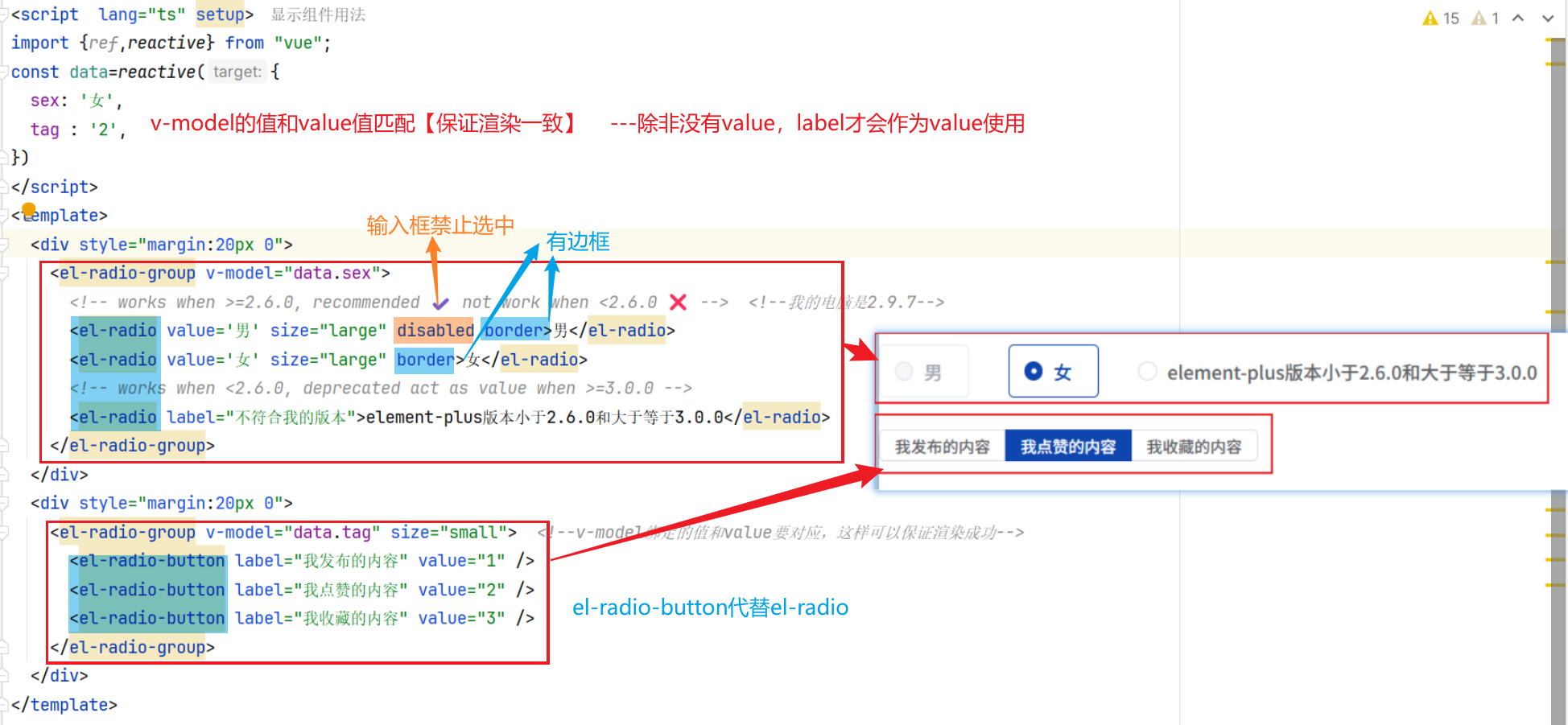
要注意v-model绑定的值和value值要对应【保证能够渲染成功】–例如sex是女,那单选框默认就标到女的位置

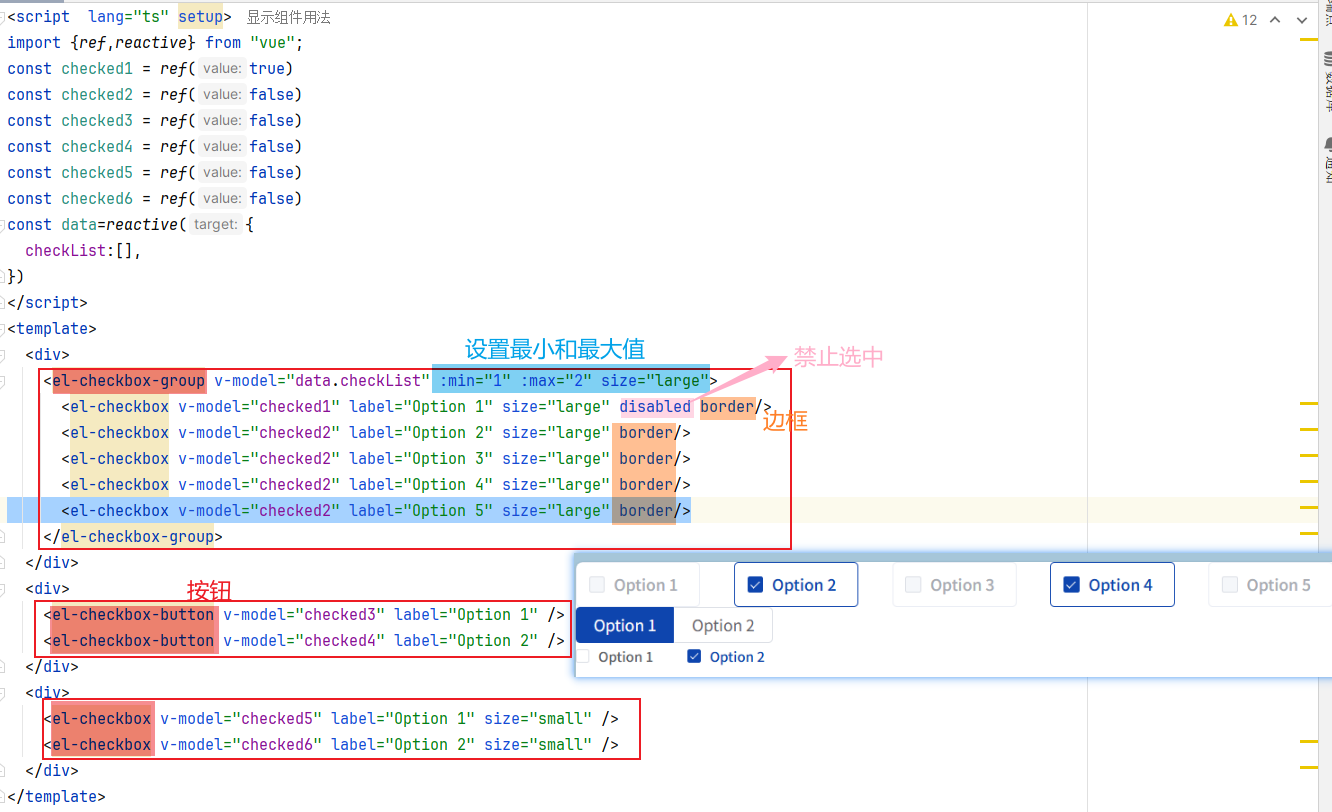
参考内容:Checkbox 多选框 | Element Plus

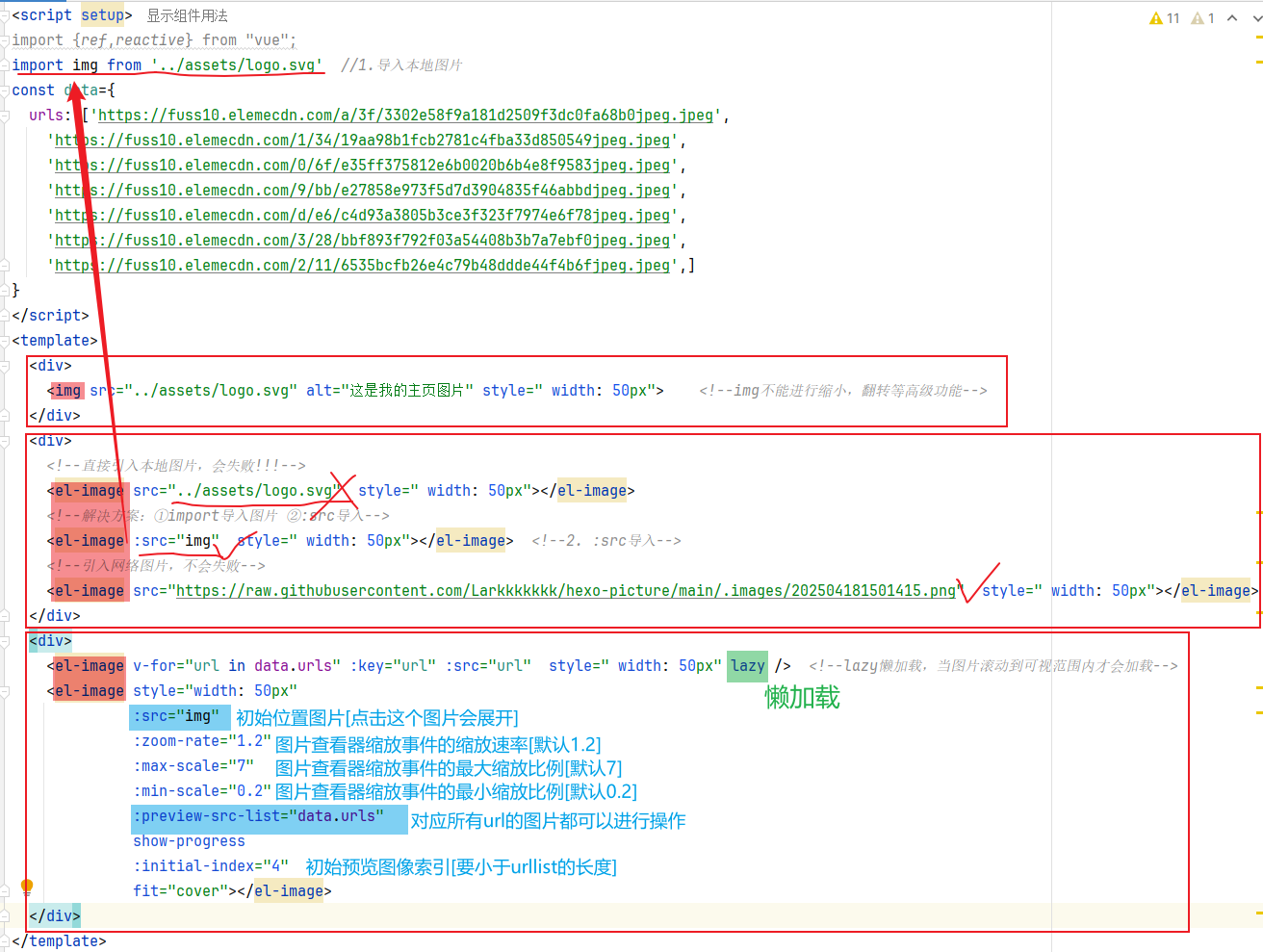
相比于img而言,能够进行高级操作【懒加载,翻转,和缩放等功能】

参考内容:Carousel 走马灯 | Element Plus
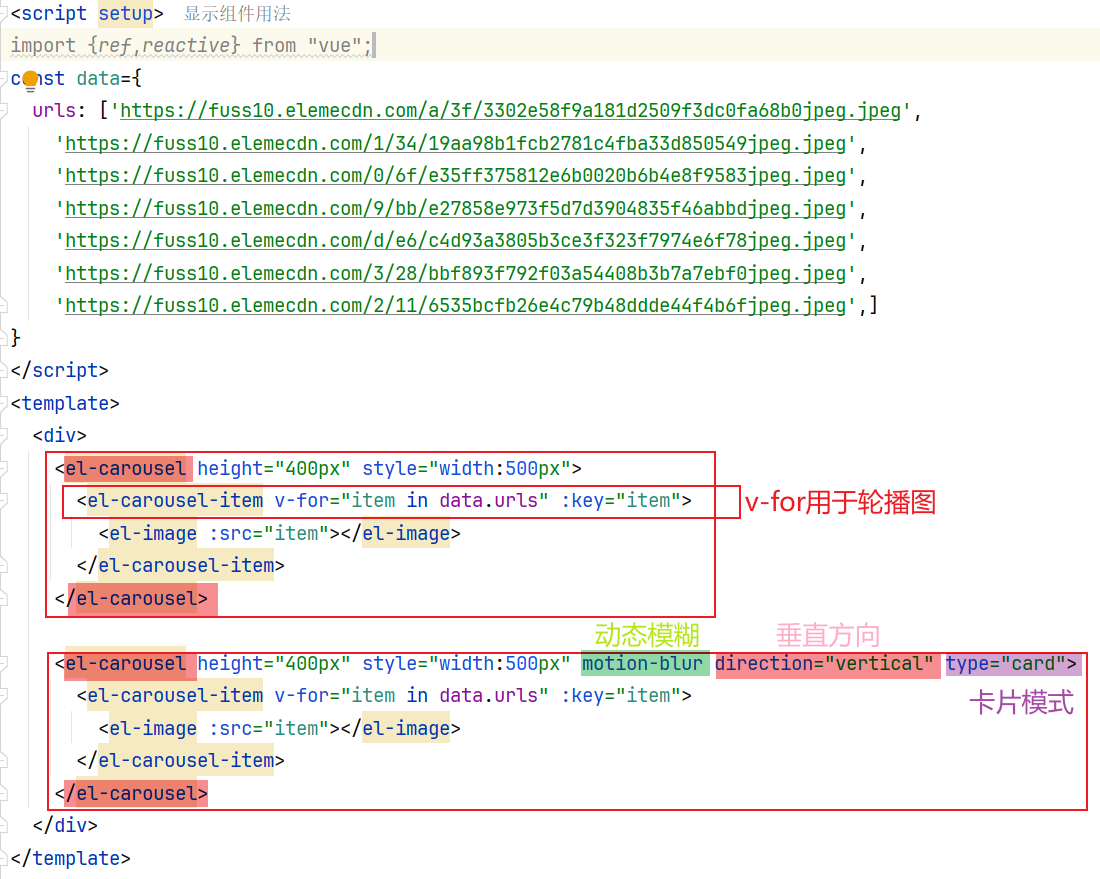
可以在el-carousel里面添加各种属性值

参考内容:DateTimePicker 日期时间选择器 | Element Plus
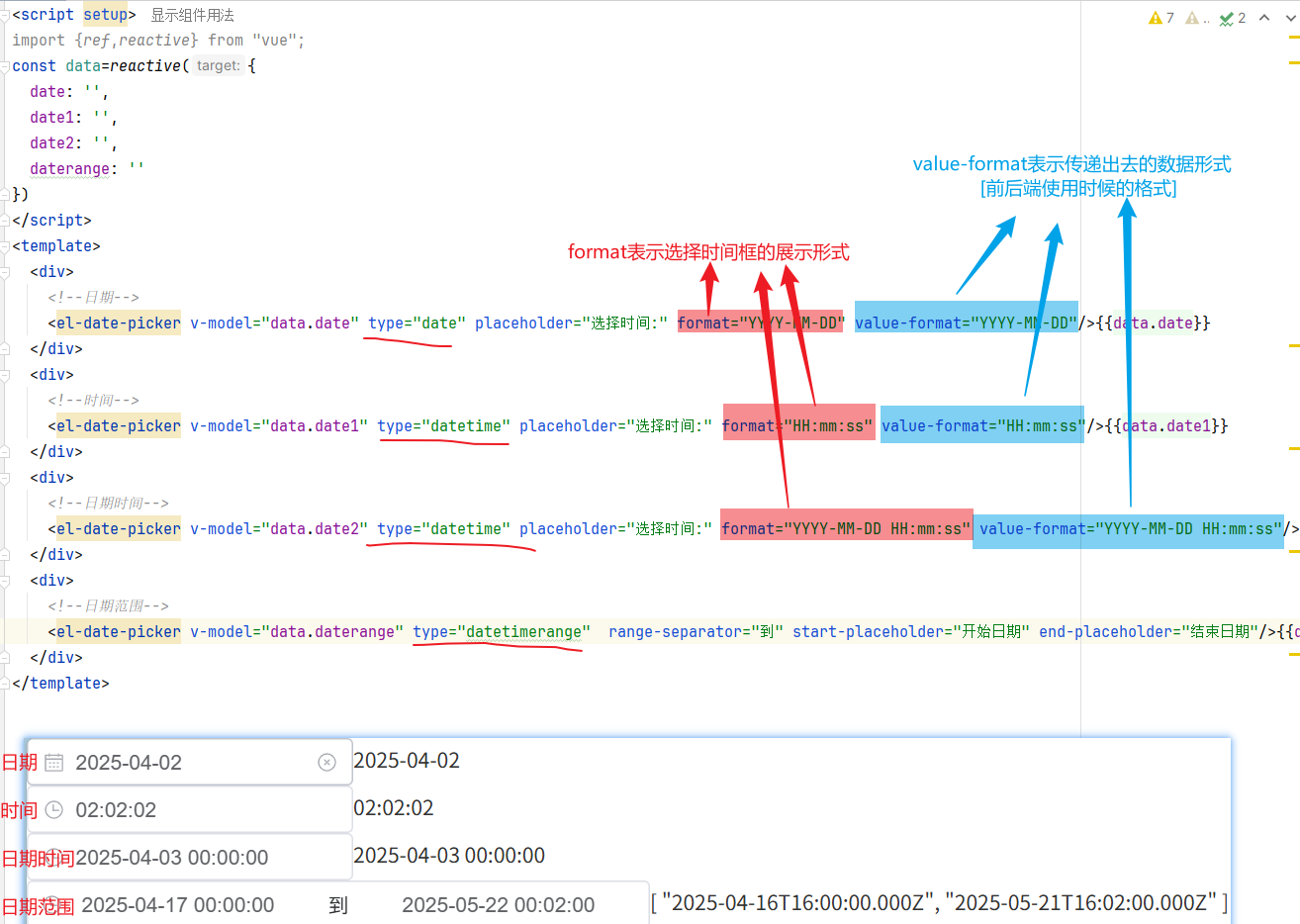
具体的对应情况:
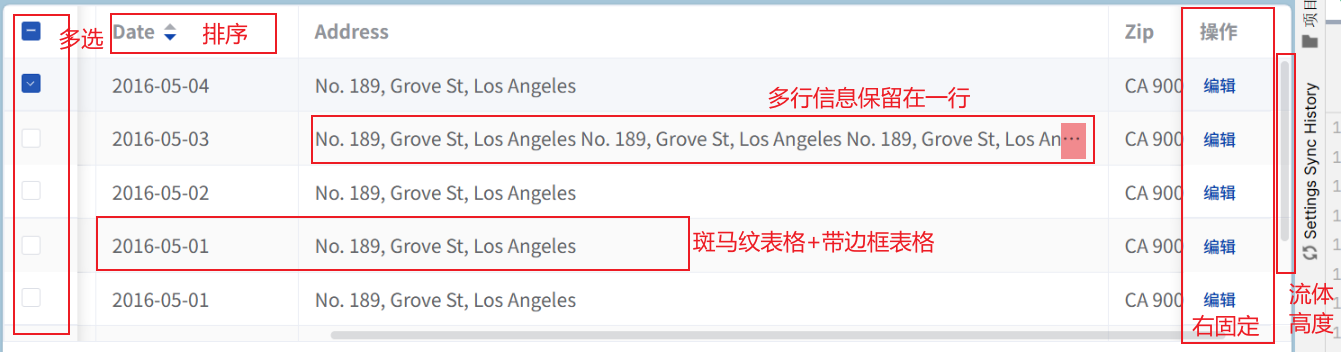
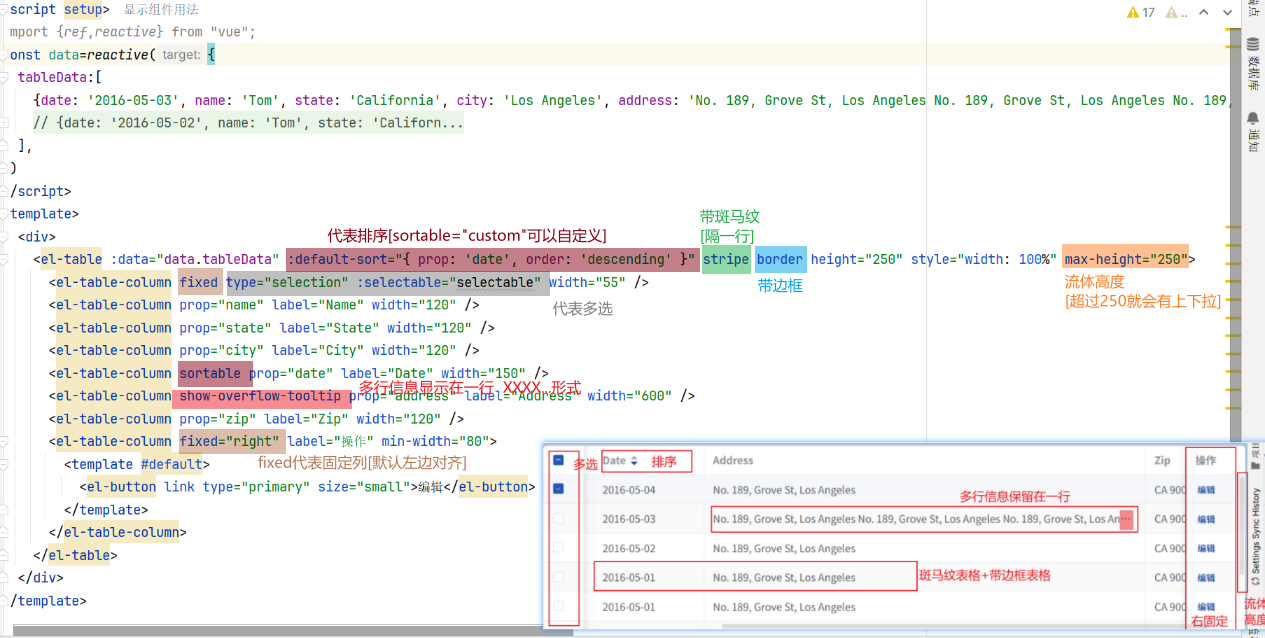
5.11的数据因为设置了max-height的流体高度:但是如果行很多的情况应该采用分页:
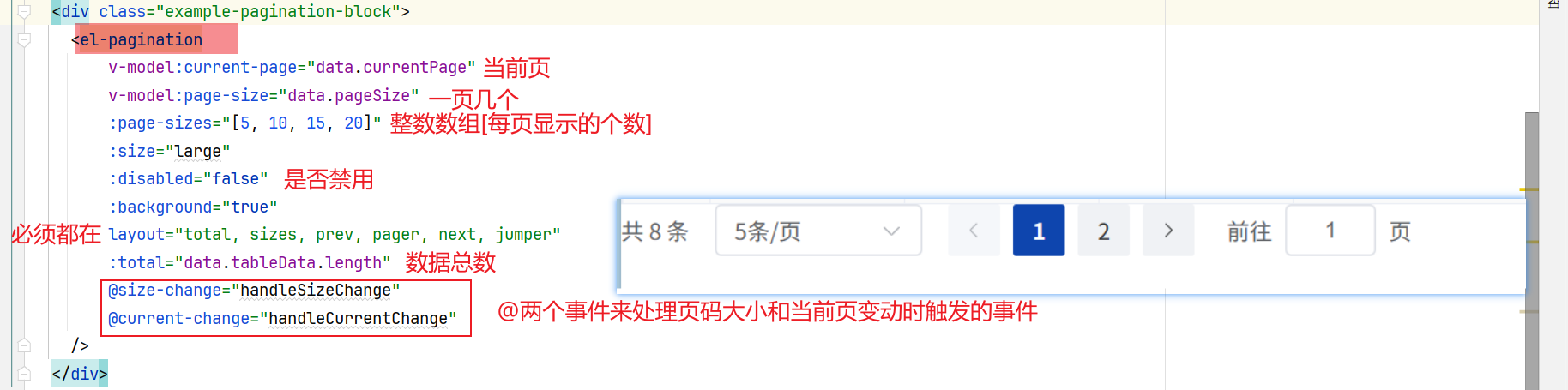
参考内容:Pagination 分页 | Element Plus
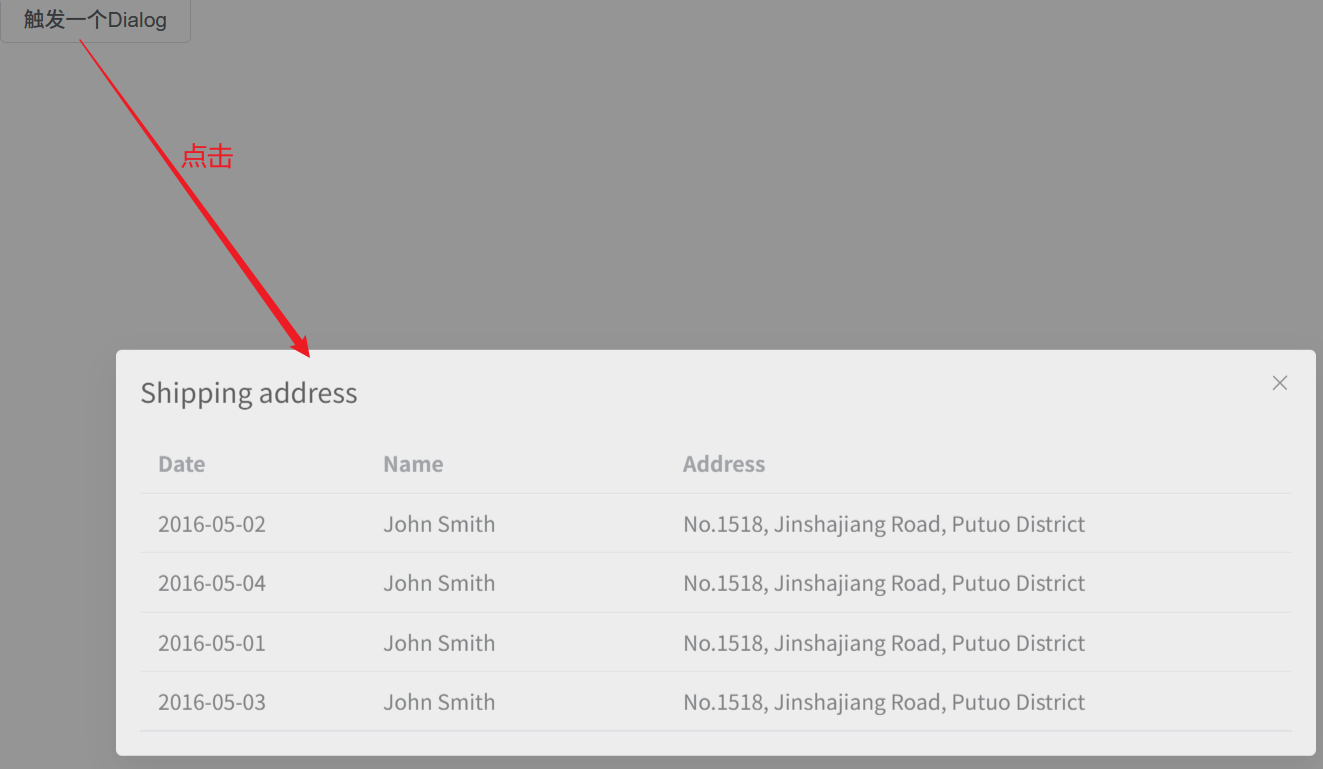
参考内容:Dialog 对话框 | Element Plus
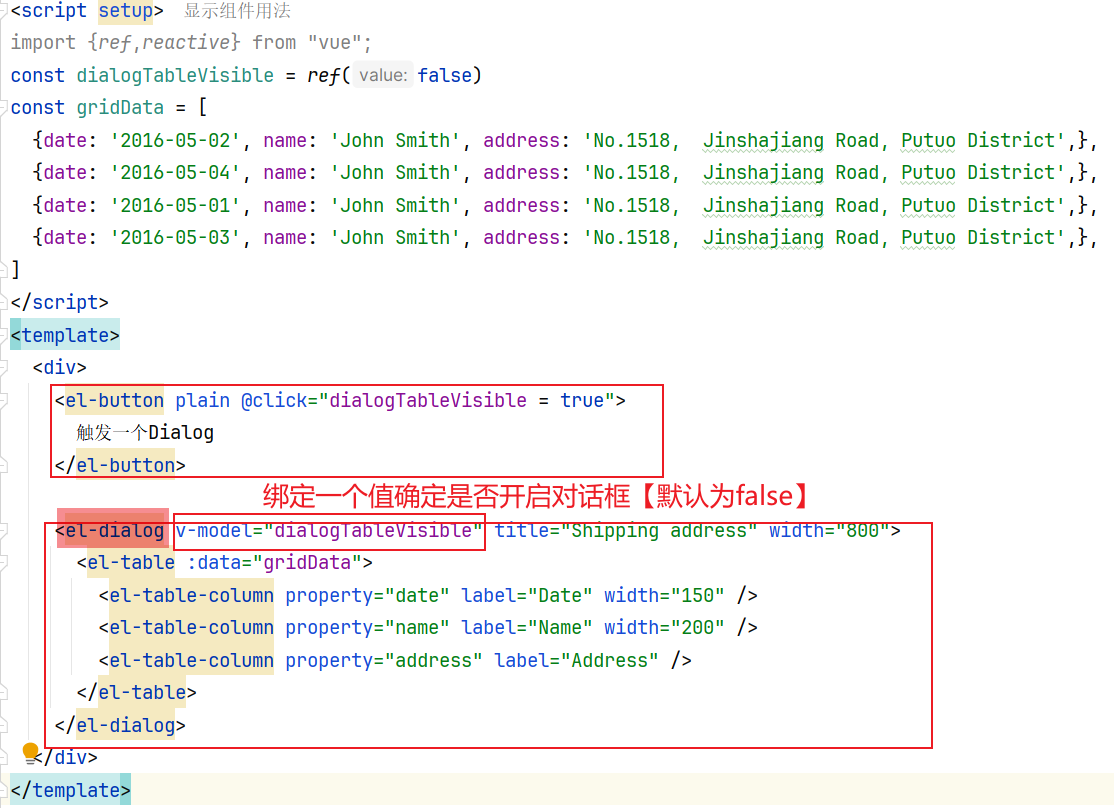
点击对话框之后:
后端内容:
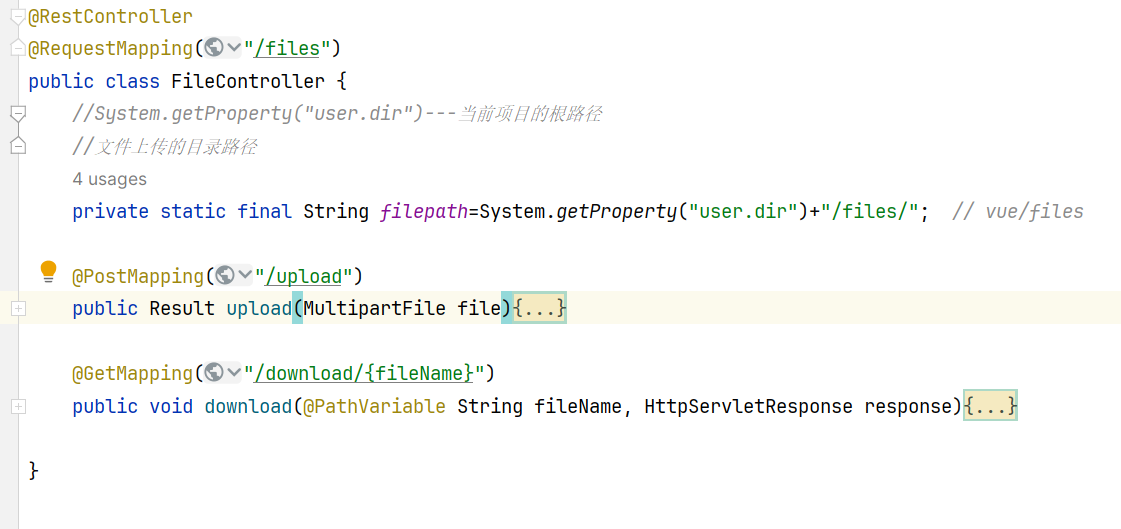
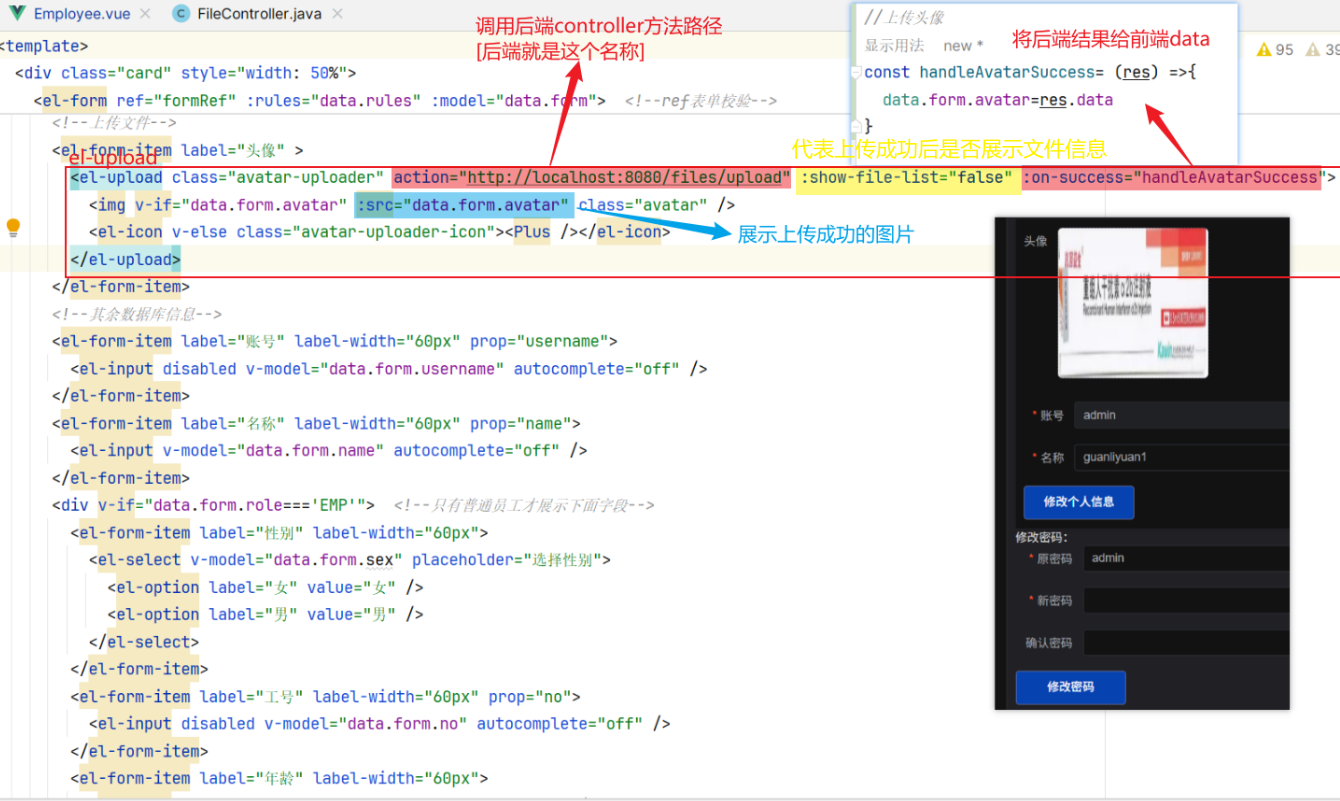
前端内容:【1.创建handleAvatarSuccess函数(需要放在最上面,最好是const data上面);2.写el-upload标签】
Vue (发音为 /vjuː/,类似 view) 是一款用于构建用户界面的 JavaScript 框架。它基于标准 HTML、CSS 和 JavaScript 构建,并提供了一套声明式的、组件化的编程模型,帮助你高效地开发用户界面。无论是简单还是复杂的界面,Vue 都可以胜任。
举例:
1 | import { createApp, ref } from 'vue' |
1 | <div id="app"> |
结果展示:
Vue是一个框架(生态),能够覆盖大部分前端开发常见的需求。Vue 的设计非常注重灵活性和“可以被逐步集成”这个特点。根据你的需求场景,你可以用不同的方式使用 Vue:
在大多数启用了构建工具的 Vue 项目中,我们可以使用一种类似 HTML 格式的文件来书写 Vue 组件,它被称为单文件组件 (也被称为 *.vue 文件,英文 Single-File Components,缩写为 SFC)。顾名思义,Vue 的单文件组件会将一个组件的逻辑 (JavaScript),模板 (HTML) 和样式 (CSS) 封装在同一个文件里。下面我们将用单文件组件的格式重写上面的计数器示例:
1 | <script setup> |
单文件组件是 Vue 的标志性功能。如果你的用例需要进行构建,我们推荐用它来编写 Vue 组件。
Vue 的组件可以按两种不同的风格书写:选项式 API 和组合式 API
data、methods 和 mounted。选项所定义的属性都会暴露在函数内部的 this 上,它会指向当前的组件实例。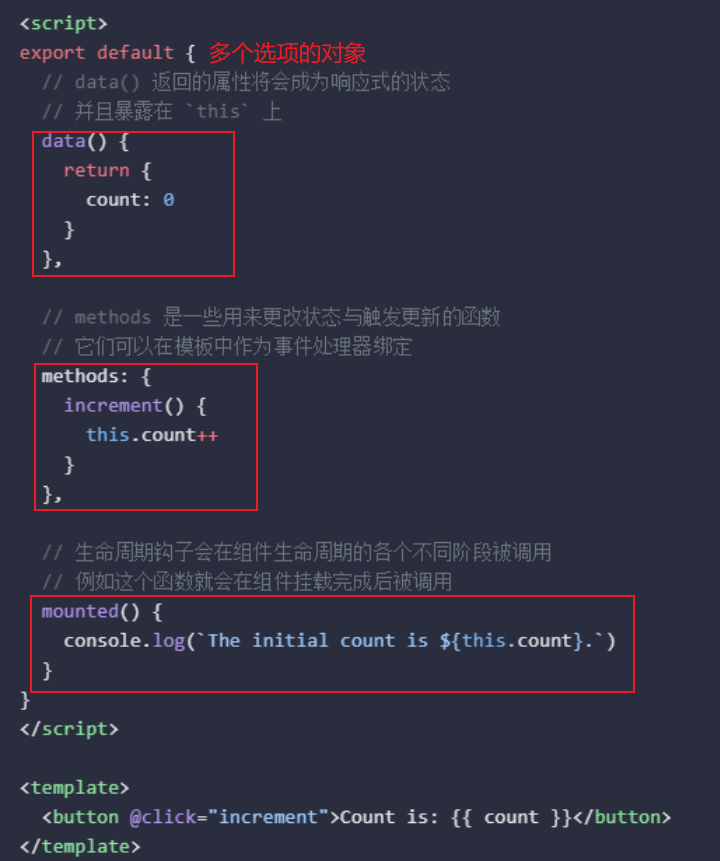
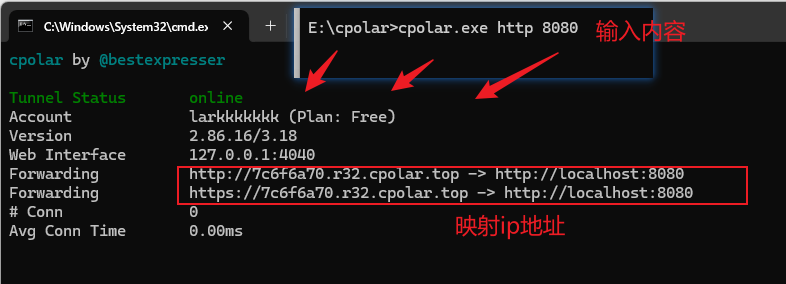
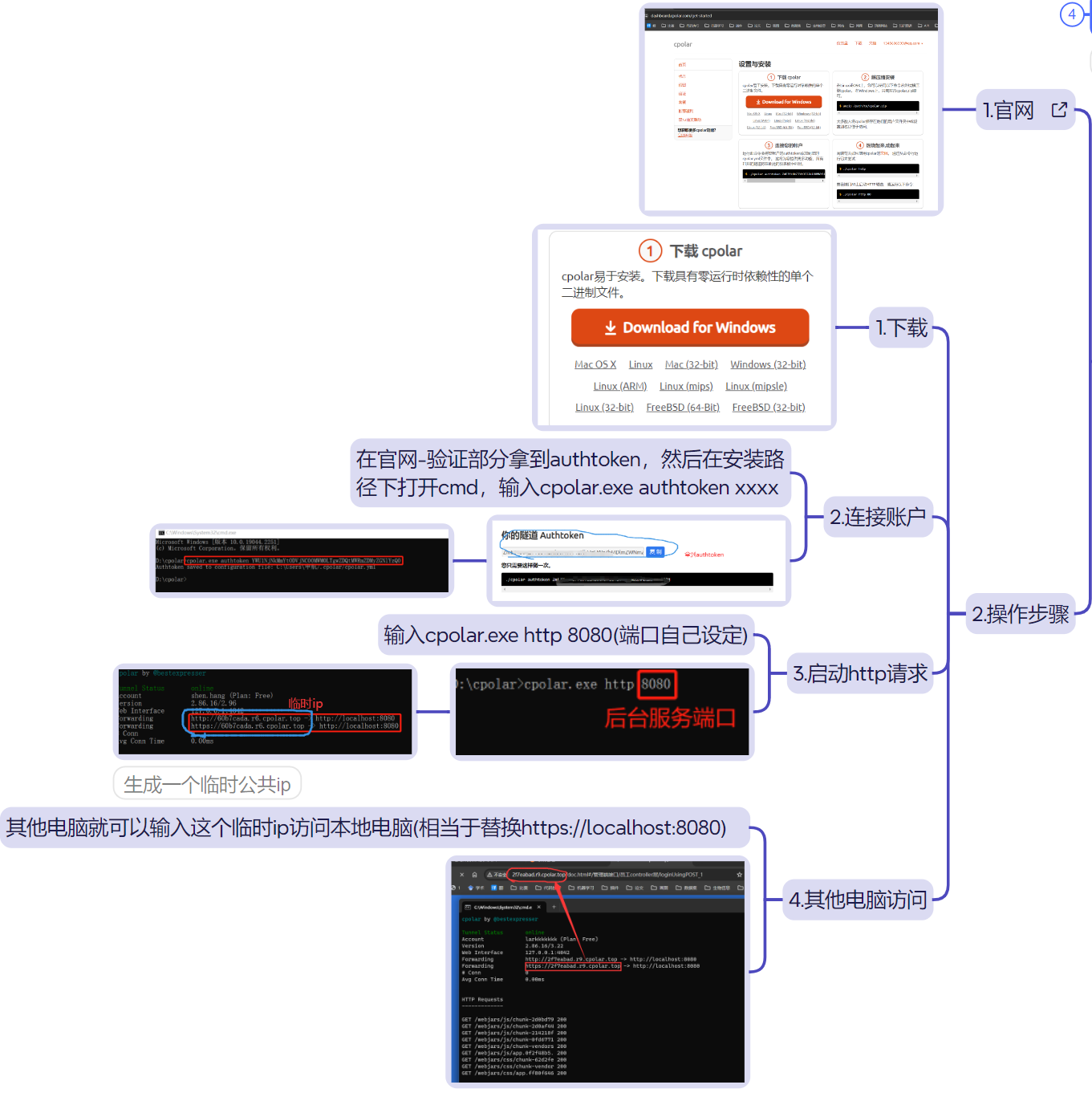
我在做毕业设计和老师横向课题时,遇到我自己电脑写后端,其他人的前端调用我的场景:因此需要内网穿透【创建一个临时ip】,让其他人访问
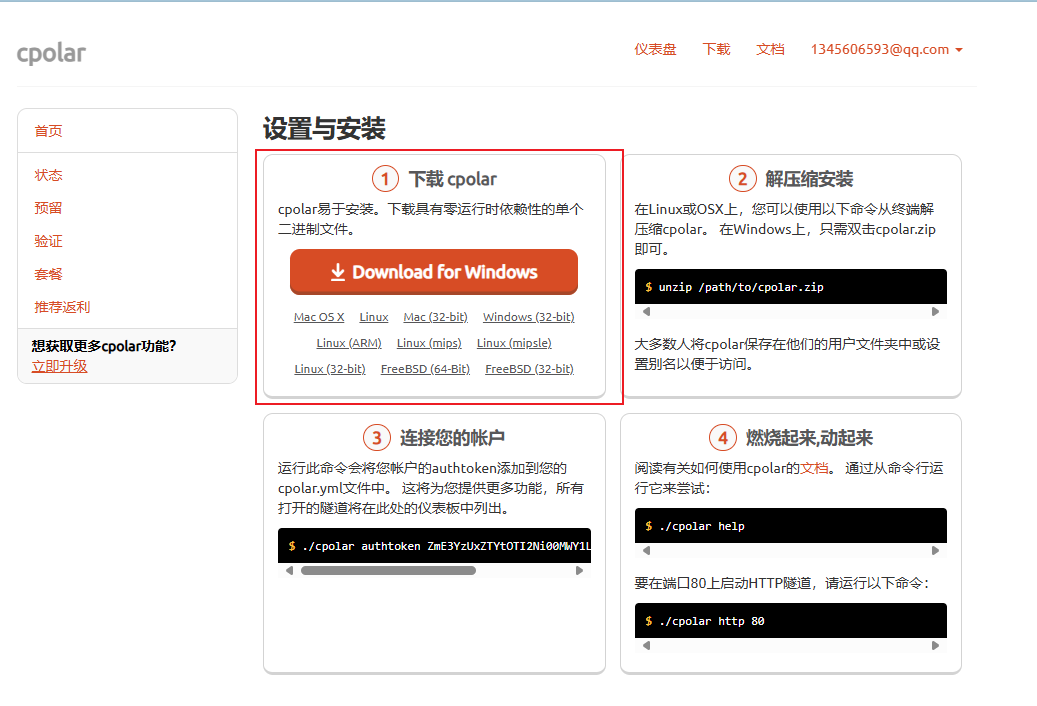

看到这样的提示语即证明成功!

不同公司中对Git的使用分支命名规范也略有差异,不过整体都会分为;上线、预发、开发、测试,这样几个分支。如图是一种比较简单使用的拉取分支方式。
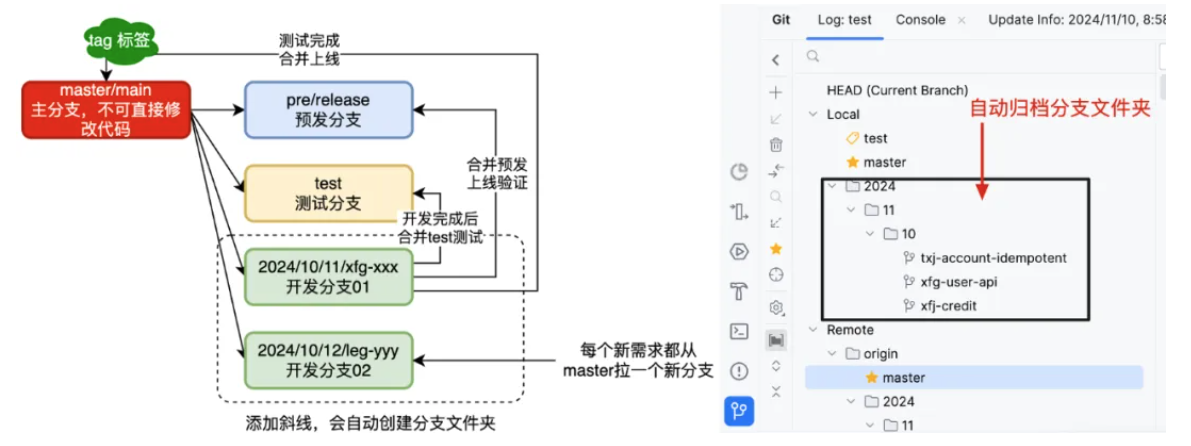
2024/10/11/xfg-xxx 使用带有斜线的分支命名会自动创建文件夹,对于多人开发的项目,可以直接归档。fix-用户名缩写-具体功能保持一个标准的统一的规范提交代码,在后续的评审、检查、合并,都会非常容易处理。
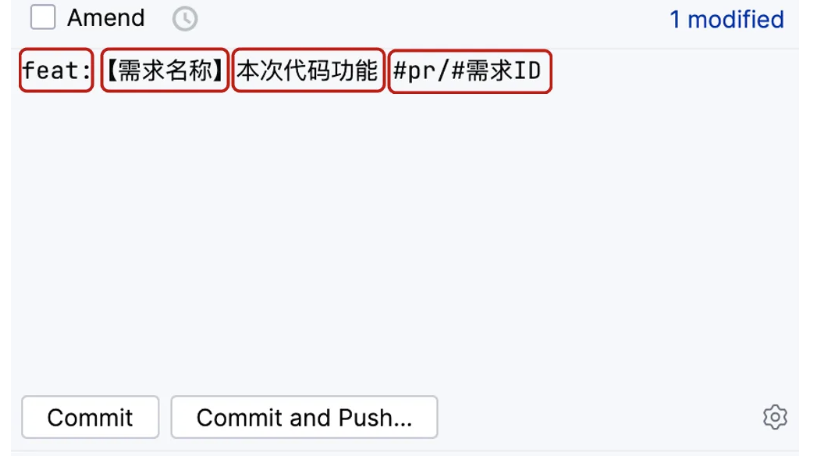
1 | # 主要type |
在公司中很多时候是大家一起在一个工程开发代码,那么这个时候就会涉及合并代码的。如果有多人共同开发一个接口方法,就会在合并的时候产生冲突。所以要特别注意。
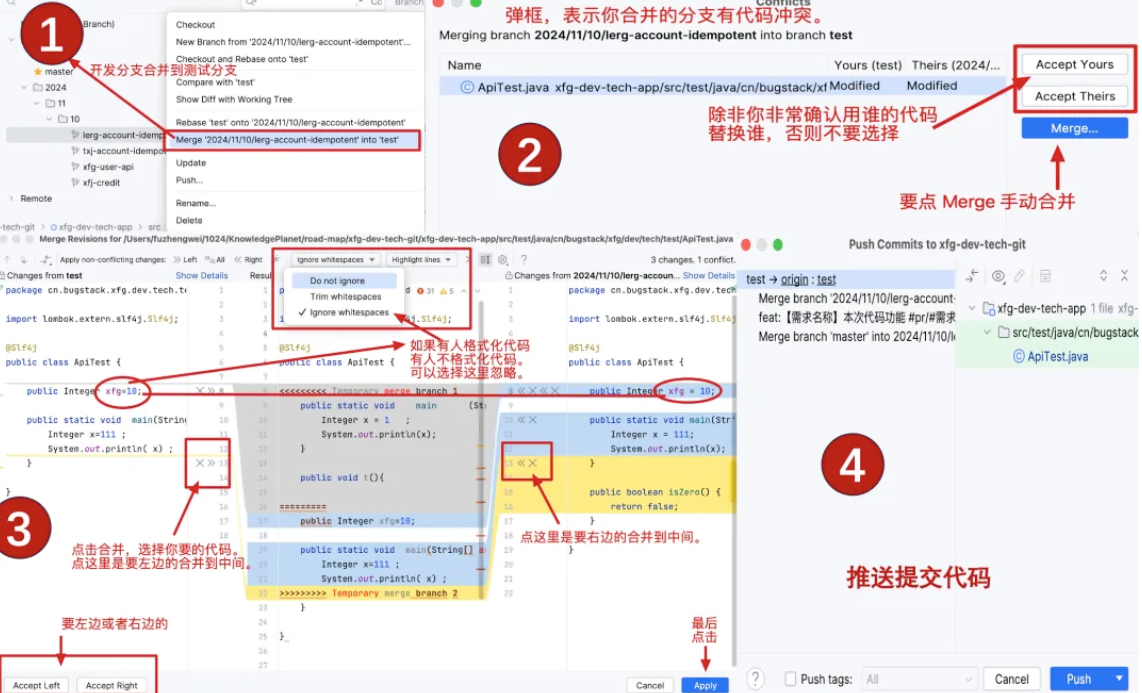
如果出现了合并代码冲突后,丢失了代码,那么这个时候一般要进行回滚操作,重新合并。
虽然 Git 提供了回滚代码的功能,但一定要谨慎使用。怎么谨慎?第一个谨慎就是 push 的代码一定确保可以构建和运行,否则不要 push!第二个谨慎是要回滚代码,需要和团队中对应的伙伴打招呼,避免影响别人测试或者上线。
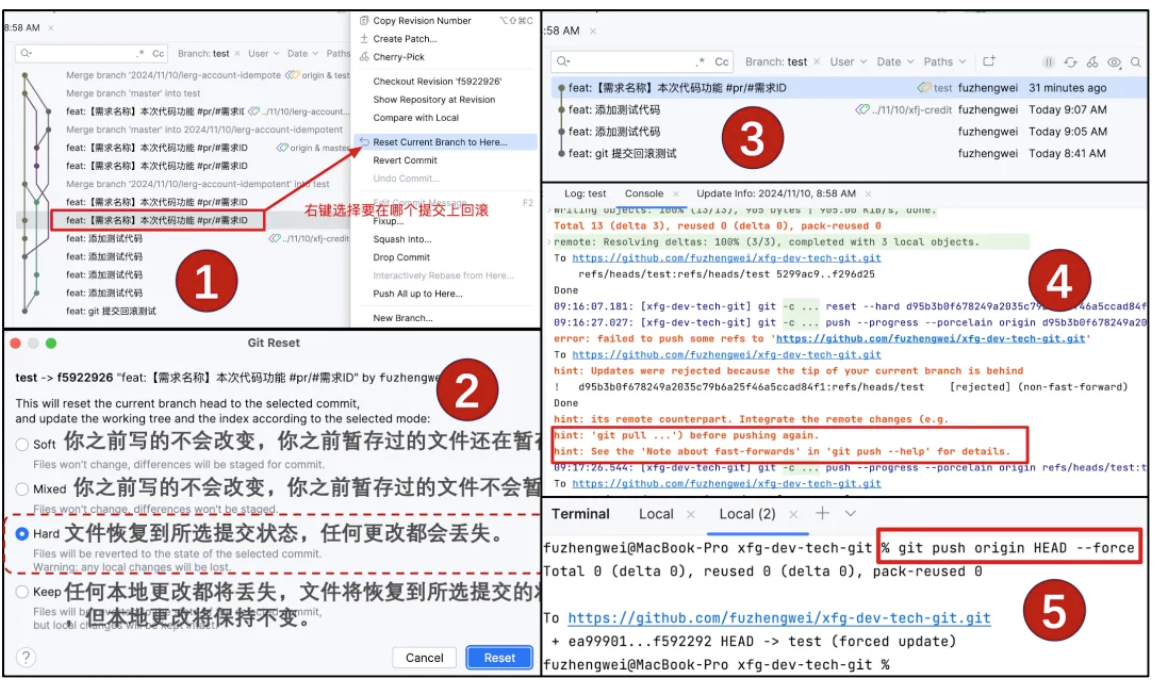
fast-forward 因为此时本地分支落后于远程分支。git push origin HEAD --force 进行强制提交。或者你可以把 test 的远程分支删掉,之后在提交。只把我修改的部分合并上去,使用cheery pick

在开发Web应用时,我们经常需要处理大量的数据展示,而分页功能几乎成了标配。它不仅提升了用户体验,还减轻了服务器的负担。今天,咱们就来聊聊一个在Java圈里非常流行的分页插件——PageHelper,看看它是如何在不动声色间帮我们搞定分页难题的。
PageHelper是MyBatis的一个分页插件,它能够在不修改原有查询语句的基础上,自动实现分页功能。
简单来说,就是你在查询数据库时,告诉PageHelper你想看第几页、每页多少条数据,它就会帮你把结果集“裁剪”好。
它首先会作为一个拦截器注册到MyBatis的执行流程中。这个拦截器就像是个守门人,会在SQL语句执行前和执行后进行一些“小动作”。
拦截到SQL语句后,PageHelper并不会直接修改你的原始SQL,而是通过动态生成一段分页SQL来实现分页功能。这个过程大致如下:
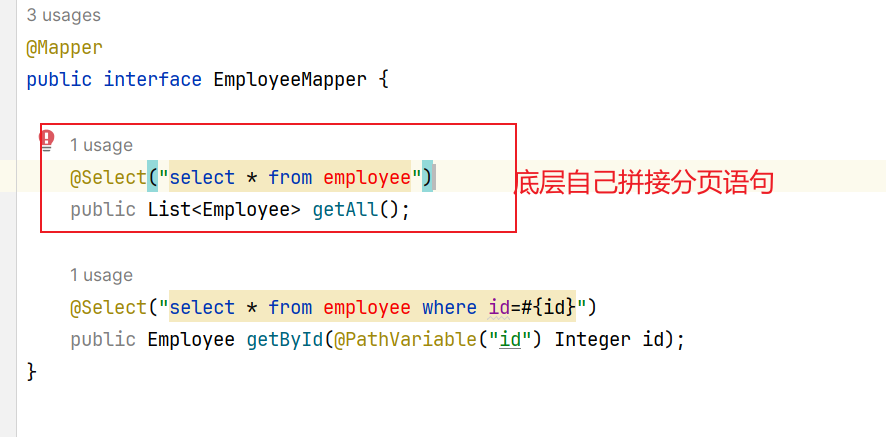
LIMIT和OFFSET(或者数据库特定的分页语法,比如MySQL的LIMIT,Oracle的ROWNUM等),从而实现对结果集的裁剪。【如果要查询第20-30行数据。 limit 19,10 或者 limit 10 offset 19】具体操作网页:如何使用分页插件
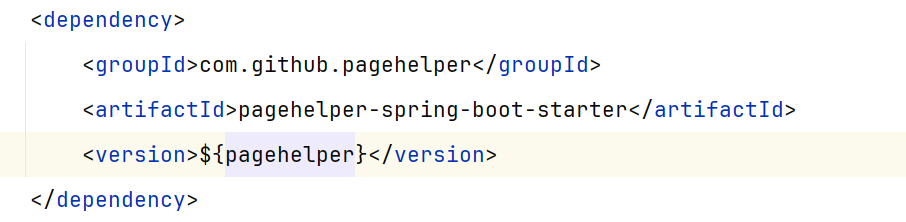
2.配置PageHelper:在MyBatis配置文件中简单配置一下PageHelper插件。
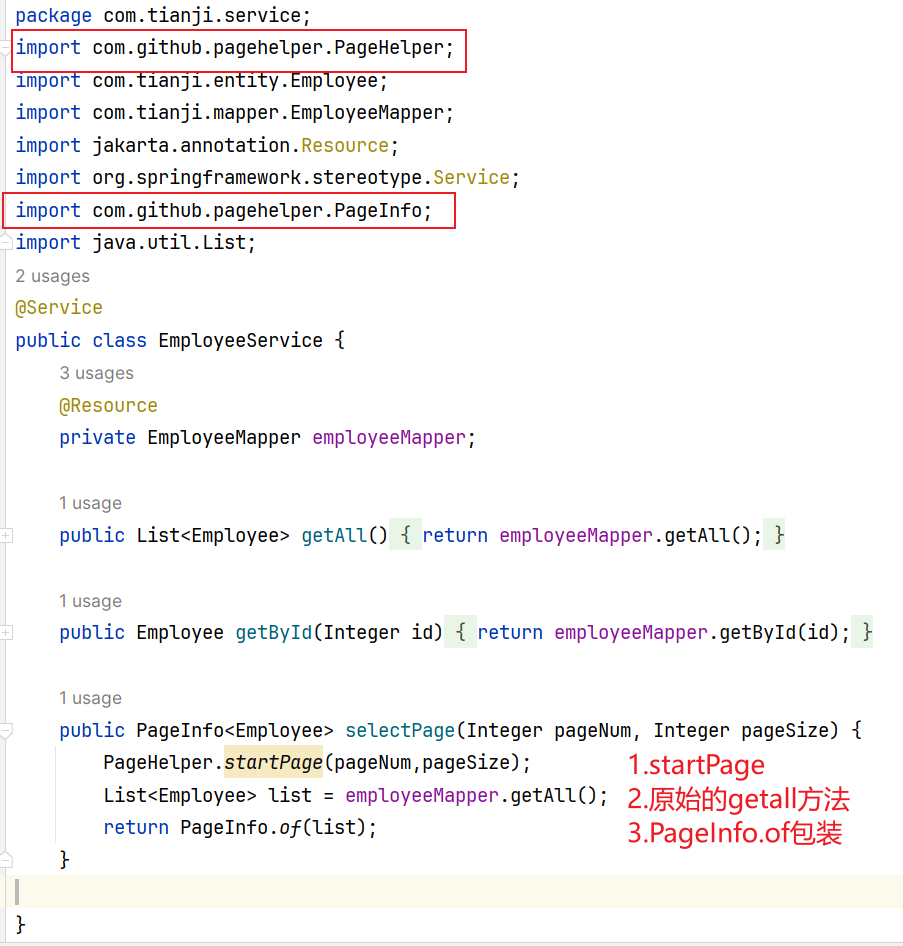
3.代码中分页:在需要分页的查询方法前,调用PageHelper.startPage(pageNum, pageSize),其中pageNum是页码,pageSize是每页数量。
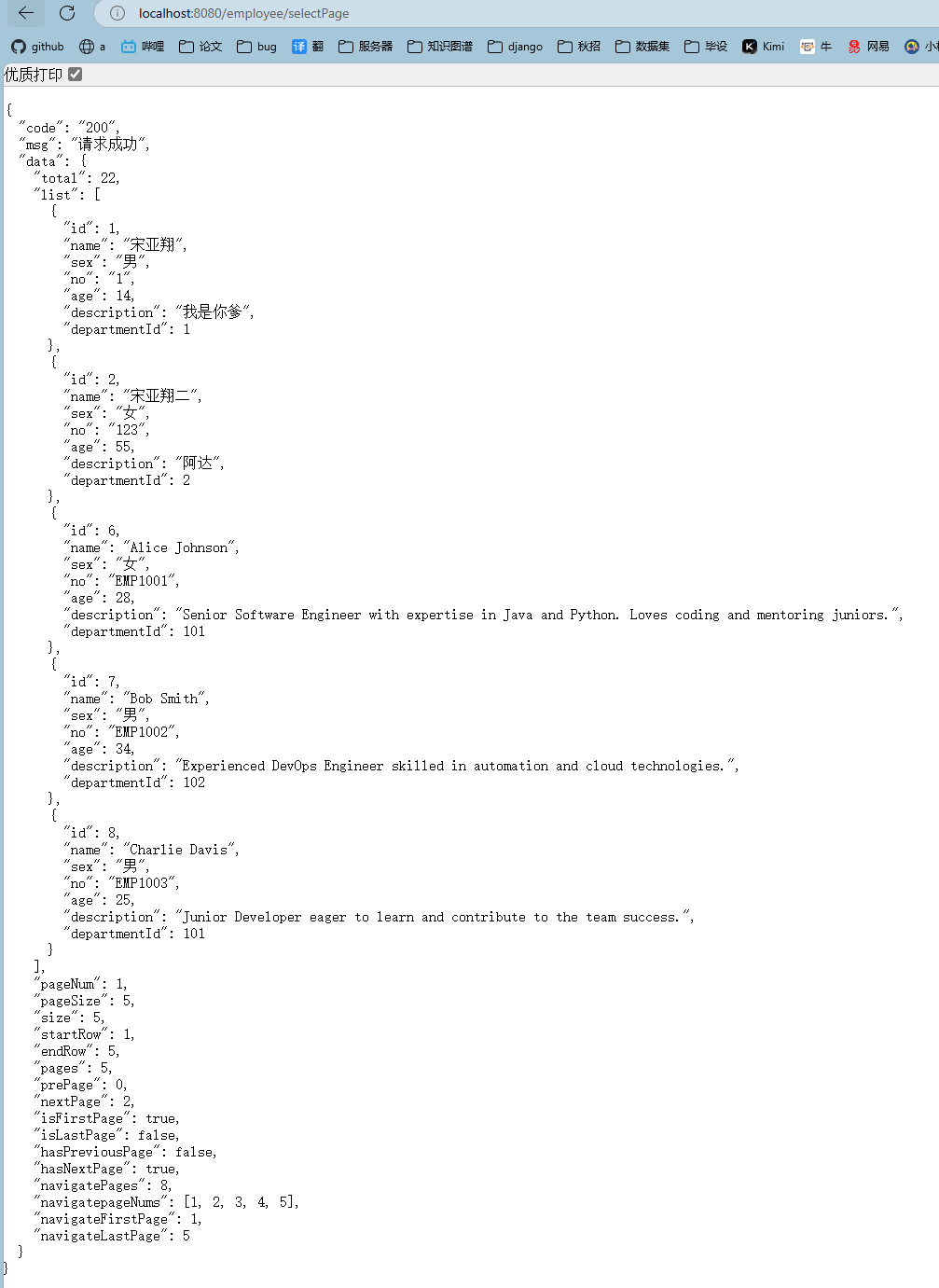
4.获取分页结果:执行查询后,你可以直接从返回的结果中获取分页信息,比如总记录数、当前页数据等。
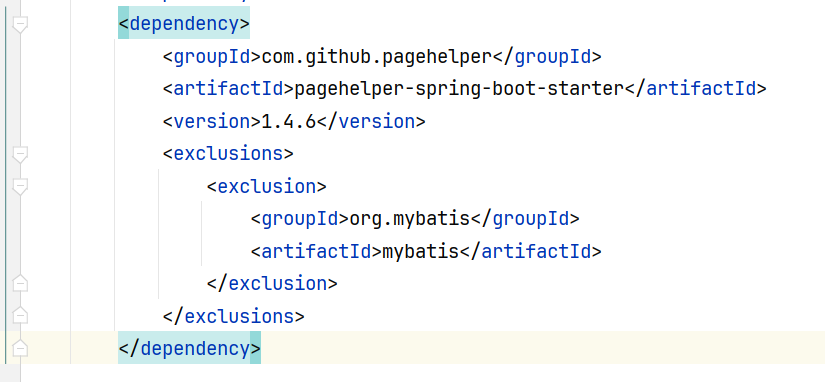
1 | <dependency> |


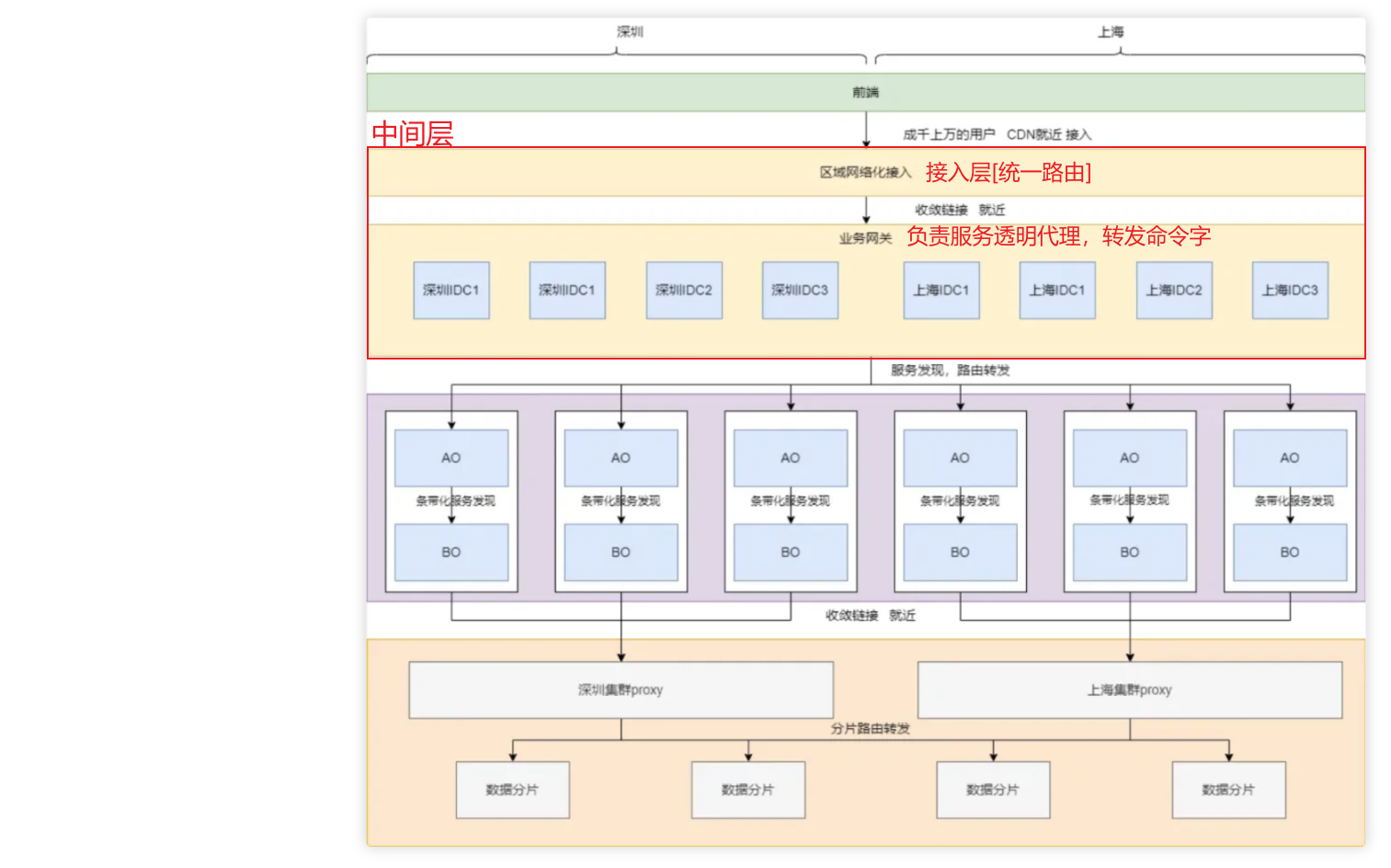
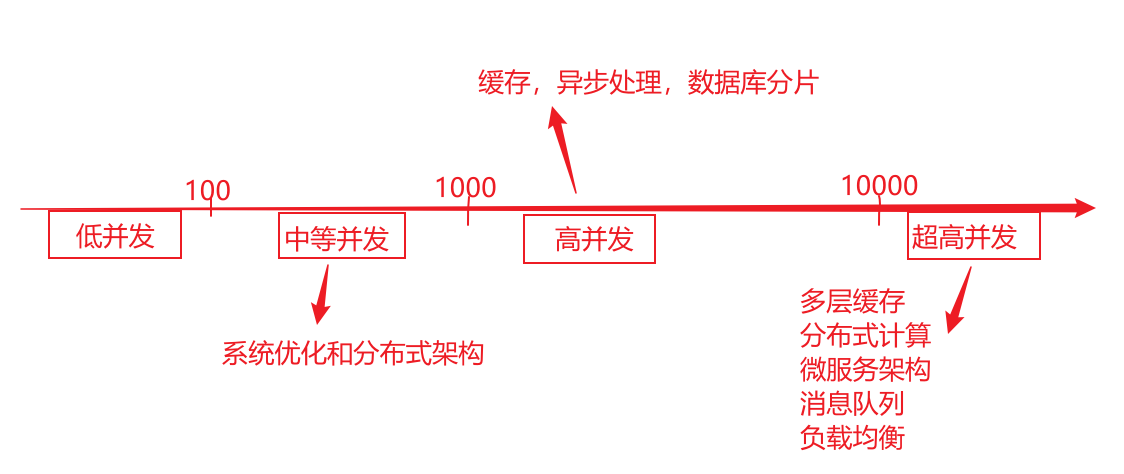
后台分布式架构形形色色,特别是微服务和云原生的兴起,诞生了一批批经典的分布式架构,然而在公司内部,或者其他大型互联网企业,都是抛出自己的架构,从接入层Controller,逻辑层Service,数据层Mapper都各有特点,但这些系统设计中到底是出于何种考量,有没有一些参考的脉络呢,本文将从云原生和微服务,有状态服务,无状态服务以及分布式系统等维度探讨这些脉络。
定义:《Designing Data-Intensive Application》指出分布式系统:通过网络进行通信的多台机器的系统
好处:
【DDIA这本书主要是基于有数据有状态来讨论分布式。】
但是,现实的实践中,分布式系统存在①有状态和②无状态:


AO:【微服务的顶层】封装应用程序的业务逻辑和处理流程;负责处理用户请求,调用相关的原子服务来完成特定任务;与其他对象进行交互,协调不同的功能模块。
BO:【微服务中相关的原子服务】,负责业务原子化的服务[特定业务/数据打交道];通常被各种AO服务调用
实现有状态的分布式系统,通常有以下三种:
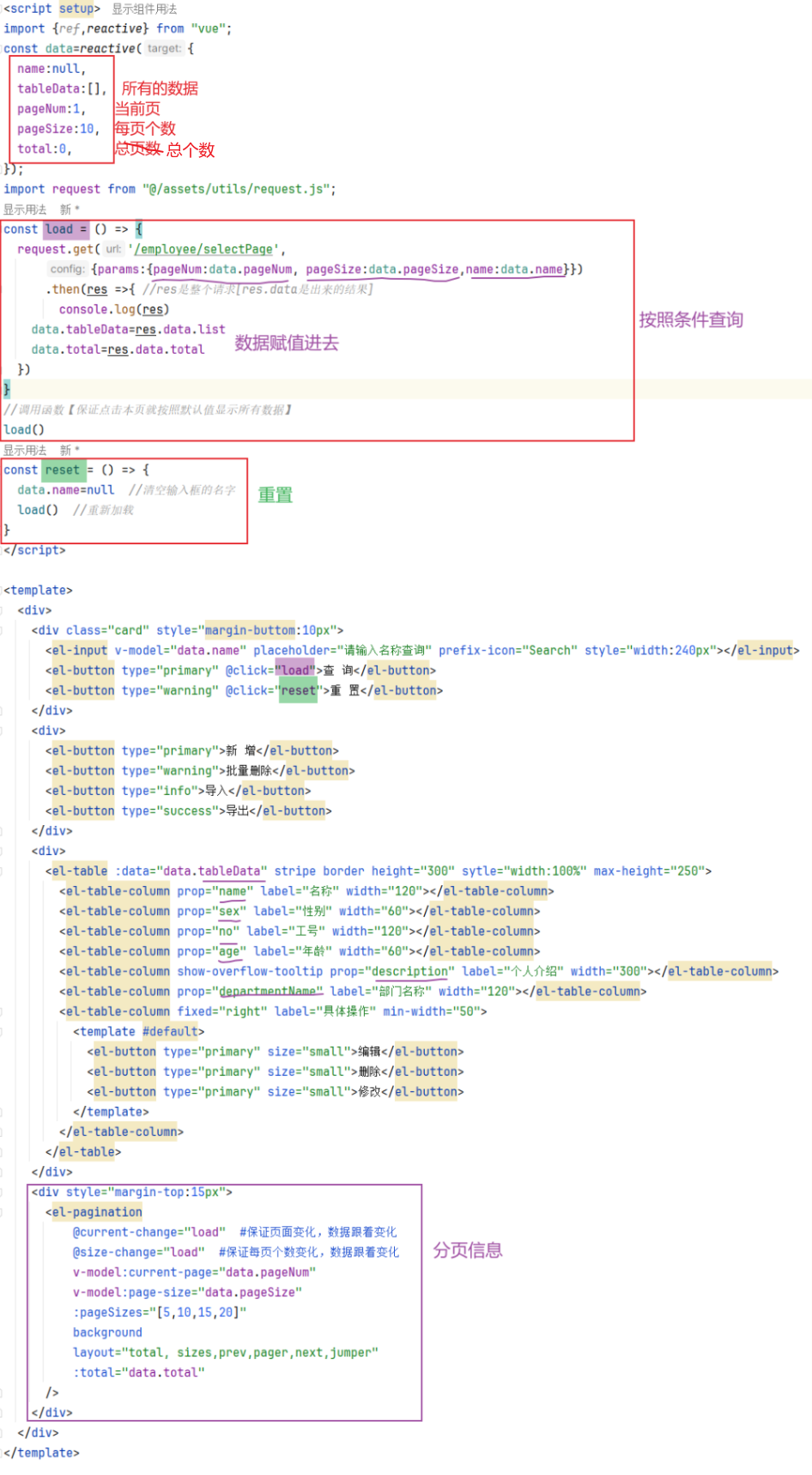
应用程序作为一个整体进行开发,测试和部署:
优点:
缺点:
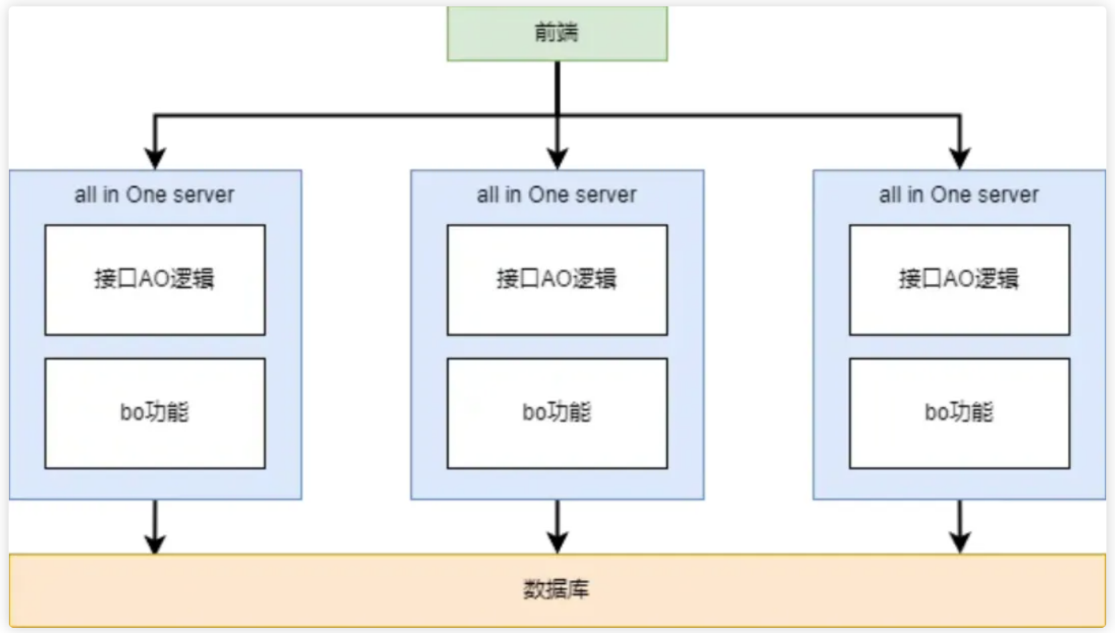
SOA架构关注于改变IT服务在企业范围内的工作方式,定义一种可通过服务接口复用软件组件并实现其互操作的方法。
优点:
缺点:
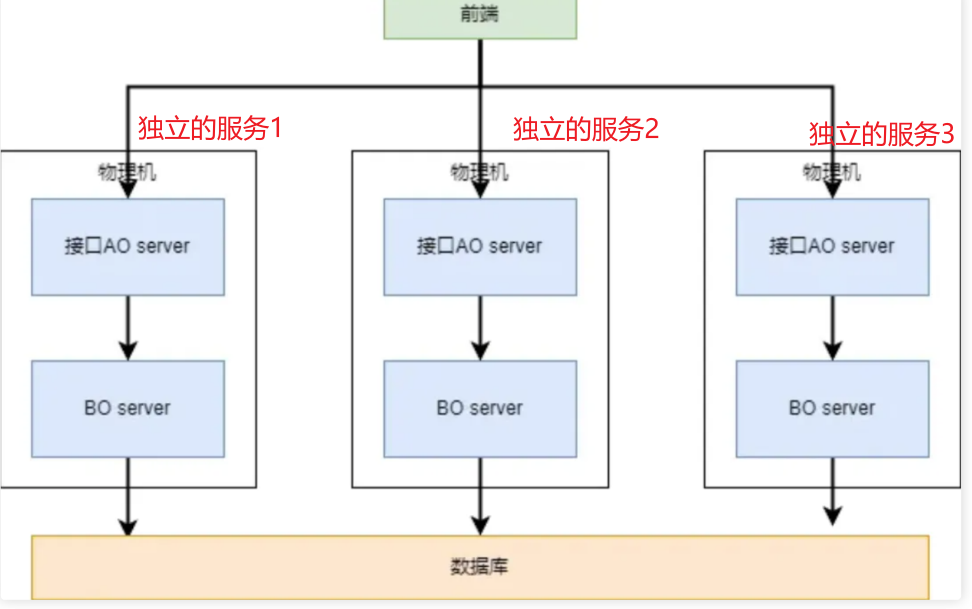
【SOA架构的一种变体】微服务架构是一种云原生架构常用的实现方式—更强调基于云原生,独立部署,Devops,持续交付。
优点:
可扩展性和灵活性:SOA 架构将系统拆分成独立的服务,可以按需组合和重组这些服务,从而实现系统的快速扩展和灵活部署。
提高系统的可重用性:每个服务都是独立的功能单元,可以在不同的系统中复用,提高了系统的开发效率和维护成本。
降低系统的耦合性:SOA 架构通过服务之间的松耦合关系,降低了服务之间的依赖性,有利于系统的模块化和维护。
提高系统的稳定性和可靠性:SOA 架构采用了服务注册与发现机制、负载均衡、故障恢复等机制,提高了系统的稳定性和可靠性
【基于SOA架构新增的优点】
独立性:每个服务可以独立部署和更新,提高了系统的灵活性和可靠性。
可扩展性:根据需求,可以独立扩展单个服务,而不是整个应用程序。
容错性:单个服务的故障不会影响其他服务,提高了系统的稳定性。
缺点:
【基于SOA架构,主要在运维和部署上增加了难度!!!】
需要处理的问题:
而整体解决微服务问题的思路: